Source Operator
Flink的API层级 为流式/批式处理应用程序的开发提供了不同级别的抽象
-
第一层是最底层的抽象为有状态实时流处理,抽象实现是 Process Function,用于底层处理
-
第二层抽象是 Core APIs,许多应用程序不需要使用到上述最底层抽象的 API,而是使用 Core APIs 进行开发
- 例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等,此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
-
第三层抽象是 Table API。 是以表Table为中心的声明式编程API,Table API 使用起来很简洁但是表达能力差
- 类似数据库中关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等
- 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用
-
第四层最顶层抽象是 SQL,这层程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式
- SQL 抽象与 Table API 抽象之间的关联是非常紧密的
-
注意:Table和SQL层变动多,还在持续发展中,大致知道即可,核心是第一和第二层
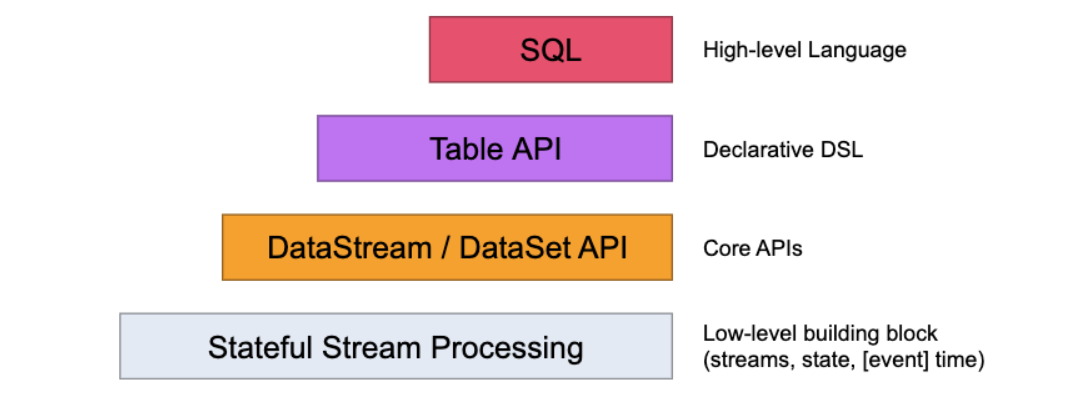
- Flink编程模型
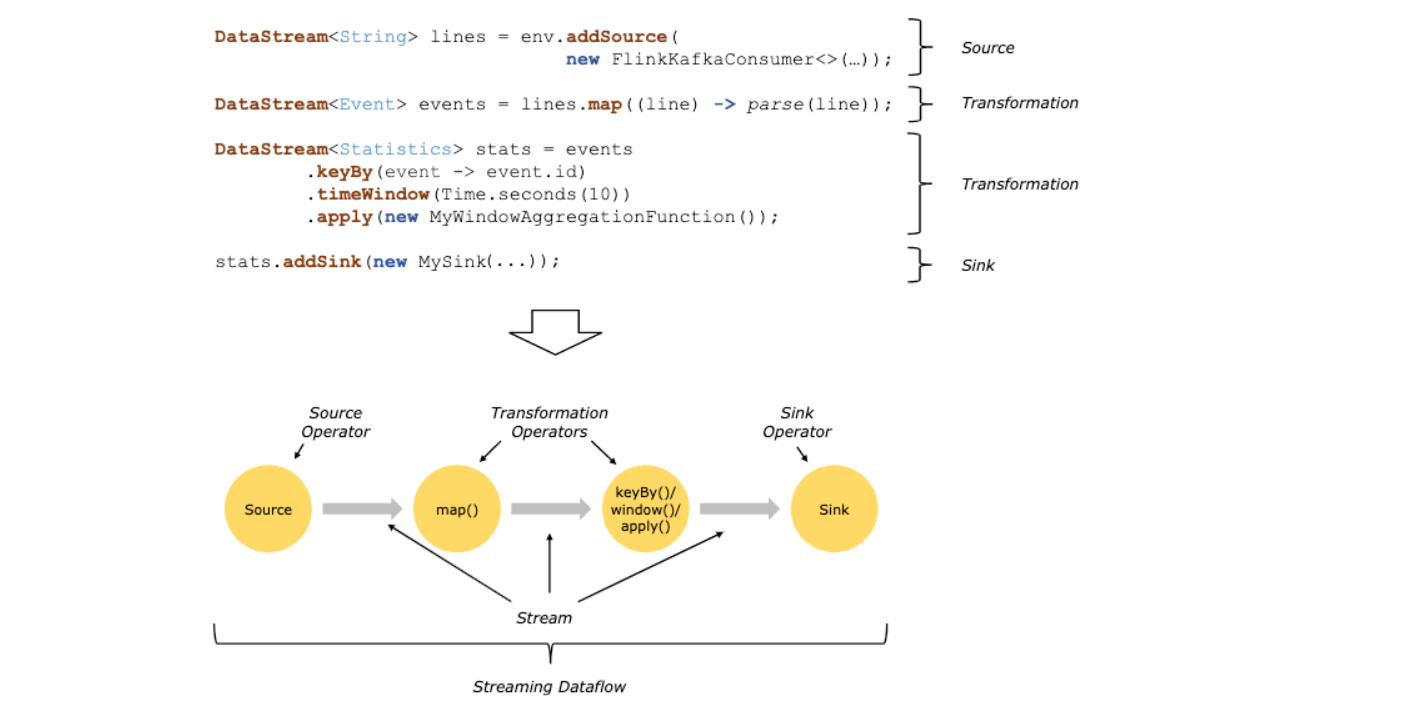
Source来源
-
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
-
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS文件);
-
基于Socket
- env.socketTextStream(“ip”, 8888)
-
自定义Source,实现接口自定义数据源,rich相关的api更丰富
- 并行度为1
- SourceFunction
- RichSourceFunction
- 并行度大于1
- ParallelSourceFunction
- RichParallelSourceFunction
- 并行度为1
-
Connectors与第三方系统进行对接(用于source或者sink都可以)
- Flink本身提供Connector例如kafka、RabbitMQ、ES等
- 注意:Flink程序打包一定要将相应的connetor相关类打包进去,不然就会失败
-
Apache Bahir连接器
- 里面也有kafka、RabbitMQ、ES的连接器更多
Sink Operator
- Sink 输出源
- 预定义
- writeAsText (过期)
- 自定义
- SinkFunction
- RichSinkFunction
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
- flink官方提供 Bundle Connector
- kafka、ES 等
- Apache Bahir
- kafka、ES、Redis等
- 预定义
Transformation
-
Map和FlatMap
-
KeyBy
-
filter过滤
-
sum
-
reduce函数
-
sum
窗口滑动
- 背景
- 数据流是一直源源不断产生,业务需要聚合统计使用,比如每10秒统计过去5分钟的点击量、成交额等
- Windows 就可以将无限的数据流拆分为有限大小的“桶 buckets”,然后程序可以对其窗口内的数据进行计算
- 窗口认为是Bucket桶,一个窗口段就是一个桶,比如8到9点是一个桶,9到10点是一个桶
- 分类
- time Window 时间窗口,即按照一定的时间规则作为窗口统计
- time-tumbling-window 时间滚动窗口 (用的多)
- time-sliding-window 时间滑动窗口 (用的多)
- session WIndow 会话窗口,即一个会话内的数据进行统计,相对少用
- count Window 数量窗口,即按照一定的数据量作为窗口统计,相对少用
- time Window 时间窗口,即按照一定的时间规则作为窗口统计
窗口属性
- 滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
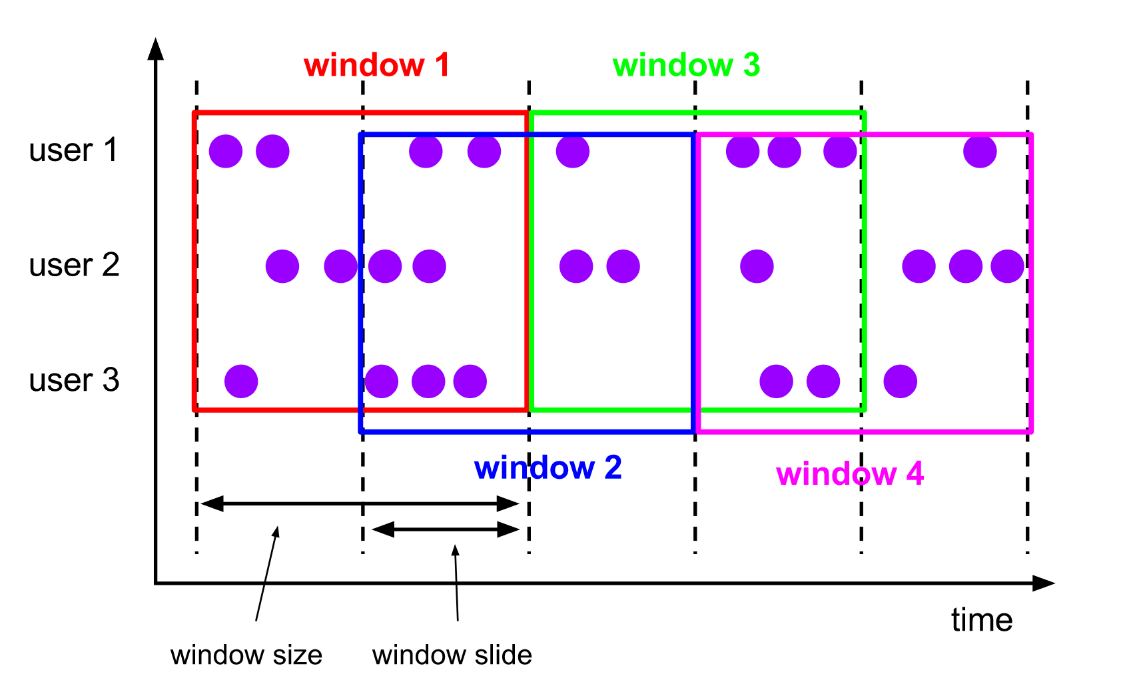
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
- 例子:每10s统计一次最近10s内的订单数量
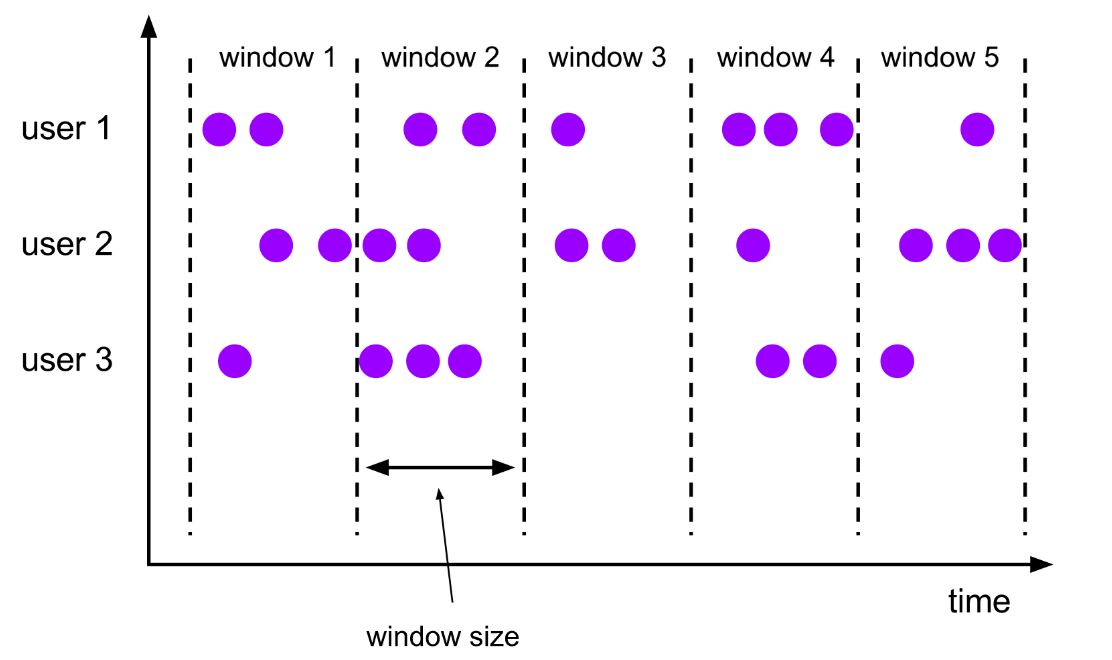
- 窗口大小size 和 滑动间隔 slide
- tumbling-window:滚动窗口: size=slide,如:每隔10s统计最近10s的数据
- sliding-window:滑动窗口: size>slide,如:每隔5s统计最近10s的数据
- size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所以开发中不用
Flink的状态State管理
- 什么是State状态
- 数据流处理离不开状态管理,比如窗口聚合统计、去重、排序等
- 是一个Operator的运行的状态/历史值,是维护在内存中
- 流程:一个算子的子任务接收输入流,获取对应的状态,计算新的结果,然后把结果更新到状态里面
-
有状态和无状态介绍
- 无状态计算: 同个数据进到算子里面多少次,都是一样的输出,比如 filter
- 有状态计算:需要考虑历史状态,同个输入会有不同的输出,比如sum、reduce聚合操作
-
状态管理分类
- ManagedState(用的多)
- Flink管理,自动存储恢复
- 细分两类
- Keyed State 键控状态(用的多)
- 有KeyBy才用这个,仅限用在KeyStream中,每个key都有state ,是基于KeyedStream上的状态
- 一般是用richFlatFunction,或者其他richfunction里面,在open()声明周期里面进行初始化
- ValueState、ListState、MapState等数据结构
- Operator State 算子状态(用的少,部分source会用)
- ListState、UnionListState、BroadcastState等数据结构
- Keyed State 键控状态(用的多)
- RawState(用的少)
- 用户自己管理和维护
- 存储结构:二进制数组
- ManagedState(用的多)
-
State数据结构(状态值可能存在内存、磁盘、DB或者其他分布式存储中)
- ValueState 简单的存储一个值(ThreadLocal / String)
- ValueState.value()
- ValueState.update(T value)
- ListState 列表
- ListState.add(T value)
- ListState.get() //得到一个Iterator
- MapState 映射类型
- MapState.get(key)
- MapState.put(key, value)
- ValueState 简单的存储一个值(ThreadLocal / String)
Flink的Checkpoint-SavePoint和端到端(end-to-end)状态一致性
-
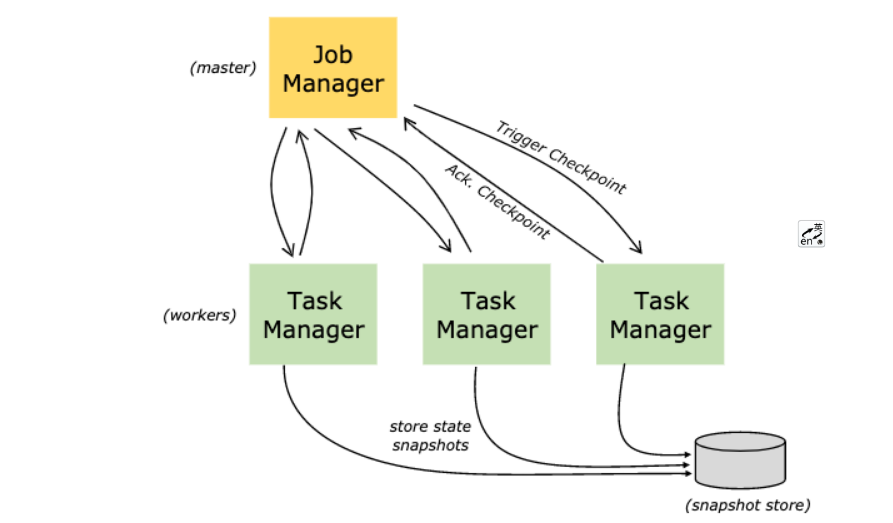
什么是Checkpoint 检查点
- Flink中所有的Operator的当前State的全局快照
- 默认情况下 checkpoint 是禁用的
- Checkpoint是把State数据定时持久化存储,防止丢失
- 手工调用checkpoint,叫 savepoint,主要是用于flink集群维护升级等
- 底层使用了Chandy-Lamport 分布式快照算法,保证数据在分布式环境下的一致性
-
开箱即用,Flink 捆绑了这些检查点存储类型:
- 作业管理器检查点存储 JobManagerCheckpointStorage
- 文件系统检查点存储 FileSystemCheckpointStorage
-
Savepoint 与 Checkpoint 的不同之处
- 类似于传统数据库中的备份与恢复日志之间的差异
- Checkpoint 的主要目的是为意外失败的作业提供【重启恢复机制】,
- Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交互
- Savepoint 由用户创建,拥有和删除, 主要是【升级 Flink 版本】,调整用户逻辑
- 除去概念上的差异,Checkpoint 和 Savepoint 的当前实现基本上使用相同的代码并生成相同的格式