数据获取和处理详见上一篇文章:https://blog.csdn.net/qq_42754919/article/details/119493103
这一节主要介绍基于隐语义模型的协同过滤推荐算法,根据用户评价商品计算用户和商品之间的关系。最后生成用户推荐商品列表和商品相似度列表。
1.创建文件+配置文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>recommender</artifactId>
<groupId>com.root</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>OfflineRecommender</artifactId>
<groupId>com.root.recommender</groupId>
<dependencies>
<dependency>
<groupId>org.scalanlp</groupId>
<artifactId>jblas</artifactId>
<version>${jblas.version}</version>
</dependency>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<!-- 加入MongoDB的驱动 -->
<!-- 用于代码方式连接MongoDB -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.11</artifactId>
<version>${casbah.version}</version>
</dependency>
<!-- 用于Spark和MongoDB的对接 -->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>${mongodb-spark.version}</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
2. 模型+算法
2.1 隐语义模型
基于协同过滤的隐语义模型算法主要思想为:输入的用户id和商品id之间只存在评分关联,并不知道为什么当前用户对此商品的评分规则。因此,隐语义模型算法假设存在K个隐含特征使得用户id和商品id之间的评分产生影响。
将输入数据R(m*n)转化为P(m *k)×U(k *n),其中m表示用户数量,n表示商品数量,k表示隐含特征。 在spark
MLlib库中有已经定义的隐语义模型算法,直接调用就可以。
2.2 商品相似度矩阵
一般使用余弦相似度,将隐语义模型计算出来的隐含特征作为当前商品的特征向量,根据两个商品的特征向量计算余弦相似度作为两个商品的相似度。

2.3 算法
package com.root.offline
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
case class ProductRating(UserId:Int, ProductId:Int, Score:Double, Time:Int)
//MongoDB的连接配置
case class MongoConfig(uri:String, db:String)
//定义推荐标准对象
case class Recommenderdation(productId:Int, score:Double)
//定义用户推荐列表
case class UserRecs(userId:Int, recs:Seq[Recommenderdation])
//定义商品相似度列表
case class ProductRecs(productId:Int,recs:Seq[Recommenderdation])
object OfflineRecommender {
val MongoDB_Rating="Rating"
val USER_RECS = "UserRecs"
val PRODUCT_RECS = "ProductRecs"
val USER_MAX_RECOMMENDATION = 20
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("OfflineRecommender")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"),config("mongo.db"))
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MongoDB_Rating)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRating]
.rdd
.map(rating=>(rating.UserId,rating.ProductId,rating.Score)).cache()
//提取出用户和商品的数据集,并去重
val UserRDD = ratingRDD.map(_._1).distinct()
val productRDD = ratingRDD.map(_._2).distinct()
//TODO:核心计算过程
//1.训练隐语义模型。输入格式必须为RDD[Rating]形式
val trainData = ratingRDD.map(x => Rating(x._1, x._2, x._3))
//rank表示隐特征个数,模型中潜在因素的数量
val model = ALS.train(trainData, rank = 5, iterations = 10, lambda = 0.01)
//2.获得预测评分矩阵,得到用户的推荐列表
//用userRDD和productRDD做笛卡尔积,得到空的userproductRDD
val userproduct = UserRDD.cartesian(productRDD)//输入格式RDD[user:Int,product:In]
val preRating = model.predict(userproduct)//输出格式Rating[user:Int,product:Int,rating:Double]
//从预测评分矩阵中提取到用户推荐列表
val userRecs = preRating.filter(_.rating > 0).map(rating => (rating.user, (rating.product, rating.rating)))
.groupByKey()
.map{case (userId,recs)=>UserRecs(userId,recs.toList.sortWith(_._2>_._2).take(USER_MAX_RECOMMENDATION)
.map(x=>Recommenderdation(x._1,x._2)))}.toDF()//转化成UserRecs表,数组集合的形式
userRecs.write
.option("uri",mongoConfig.uri)
.option("collection",USER_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//3.利用商品的特征向量,计算商品的相似度列表
val productFeatures = model.productFeatures.map {
case (productId, features) => (productId, new DoubleMatrix(features))
}
//两两配对商品,计算余弦相似度
val productRecs = productFeatures.cartesian(productFeatures).filter(x => x._1 != x._2)
.map{case(a,b) => val simScore = consinSim(a._2,b._2)
(a._1,(b._1,simScore))
}
.filter(_._2._2>0.4)
.groupByKey()
.map{case (productId,recs)=>ProductRecs(productId,recs.toList.sortWith(_._2>_._2).map(x=>Recommenderdation(x._1,x._2)))}//转化成UserRecs表,数组集合的形式
.toDF()
productRecs.write
.option("uri",mongoConfig.uri)
.option("collection",PRODUCT_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//计算笛卡尔积并过滤合并
}
def consinSim(product1: DoubleMatrix, product2: DoubleMatrix): Double ={
product1.dot(product2) / ( product1.norm2() * product2.norm2() )
}
}
3. 模型调参
- 将数据集分为测试集和训练集
- 输入不同rank(隐含特征值)和lambda(模型参数)
- 计算均方根误差,察预测评分与实际评分之间的误差。

package com.root.offline
import breeze.numerics.sqrt
import com.root.offline.OfflineRecommender.MongoDB_Rating
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object ALSTrainer {
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("ALSTrainer")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"),config("mongo.db"))
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MongoDB_Rating)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRating]
.rdd
.map(rating=>Rating(rating.UserId,rating.ProductId,rating.Score)).cache()
//切分数据集
val splitdata = ratingRDD.randomSplit(Array(0.8, 0.2))
val trainData = splitdata(0)
val testData = splitdata(1)
//核心实现,输出最优参数
adjustALSParams(trainData,testData)
spark.stop()
}
def adjustALSParams(trainData: RDD[Rating], testData: RDD[Rating]): Unit ={
val result = for ( rank <- Array(5,10,20,30); lambda <- Array(1,0.1,0.01))
yield {
val model = ALS.train(trainData, rank, 10, lambda)
val rmse = getRMSE(model,testData)
(rank,lambda,rmse)
}
println(result.minBy(_._3))
}
def getRMSE(model: MatrixFactorizationModel, testData: RDD[Rating]): Double = {
val useproduct = testData.map(x=>(x.user,x.product))
val predictRating = model.predict(useproduct)
val predict = predictRating.map(x => ((x.user, x.product), x.rating))
val real = testData.map(x => ((x.user, x.product), x.rating))
sqrt(
real.join(predict).map{case ((useID,productID),(real,predict))=>
val loss = real -predict
loss*loss
}.mean())
}
}
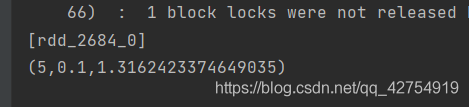
结果展示rank=5,lambda=0.1时误差最小。