0 结果展示
scala上的运行结果:

在hadoop上查到文件:
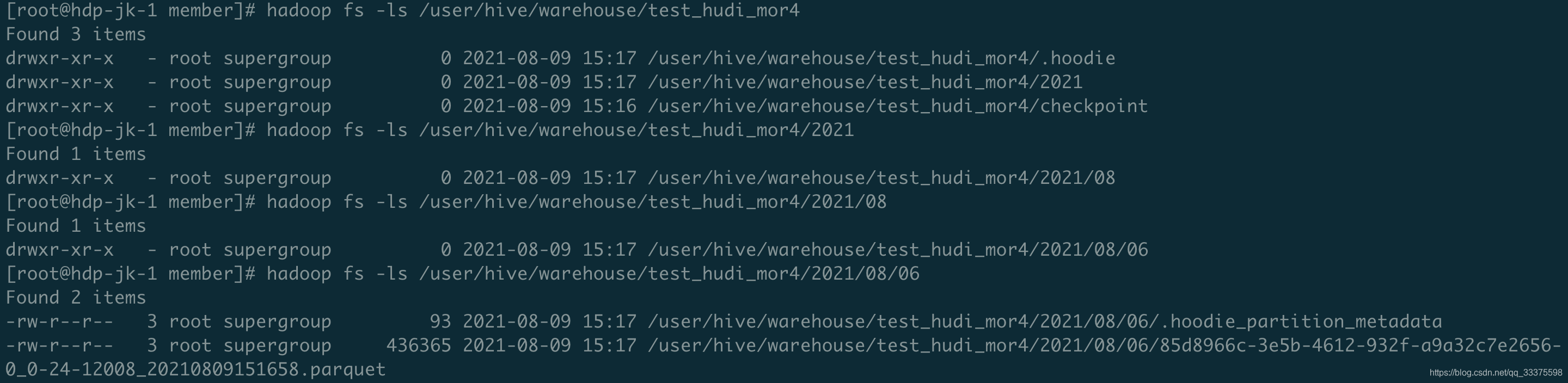
在scala中查询HDFS中的结果:

1 连接kafak
在spatk上启动scala Shell:
spark-shell --packages org.apache.hudi:hudi-spark-bundle_2.11:0.8.0,org.apache.spark:spark-avro_2.11:2.4.4,org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.8 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --jars $HUDI_SPARK_BUNDLE --master spark://10.20.3.72:7077 --driver-class-path $HADOOP_CONF_DIR:/usr/app/apache-hive-2.3.8-bin/conf/:/software/mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar --deploy-mode client --driver-memory 1G --executor-memory 1G --num-executors 3
其中比较重要的是kafaka包(spark-sql-kafka-0-10_2.11:2.4.8)和Hudi包(org.apache.hudi:hudi-spark-bundle_2.11:0.8.0)
常见的由于kafka包引起的错误:
org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
java.lang.NoClassDefFoundError: org/apache/spark/sql/sources/v2/reader/SupportsScanUnsafeRow
java.lang.NoClassDefFoundError: org/apache/spark/sql/kafka010/KafkaContinuousReader
创建Structured Streaming(用到了配置文件中config/kafka-source.properties信息):
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val kafkaAddress = "10.20.3.75:9092"
val topic = "spjk21.test_hudi.test17.output"
def createStream(spark:SparkSession) = {
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaAddress)
.option("subscribe", topic)
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", 100000)
.option("enable.auto.commit", "false")
.option("failOnDataLoss", false)
.option("includeTimestamp", true)
df
}
参数解析:
- startingOffsets:开始读取kafka中的offset的起始位置;
- endingOffsets:开始读取kafka中的offset的结束位置;
- latest:最新的offset位置;
- earliest:最早的offset位置;
- maxOffsetsPerTrigger:最大处理条数;
- failOnDataLoss:在流处理时,当数据丢失时(比如topic被删除了,offset在指定的范围之外),查询是否报错,默认为true
- includeTimestamp:是否添加时间戳
如果查询kafka中的所有结果,可以使用:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql._
val kafkaAddress = "10.20.3.75:9092"
val topic = "spjk21.test_hudi.test17.output"
//创建Structured Streaming
def createStreamDF(spark:SparkSession):DataFrame = {
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaAddress)
.option("subscribe", topic)
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", 100000)
.option("enable.auto.commit", "false")
.option("failOnDataLoss", false)
.option("includeTimestamp", true)
.load()
df
}
//参数
//.option("endingOffsets", "latest")
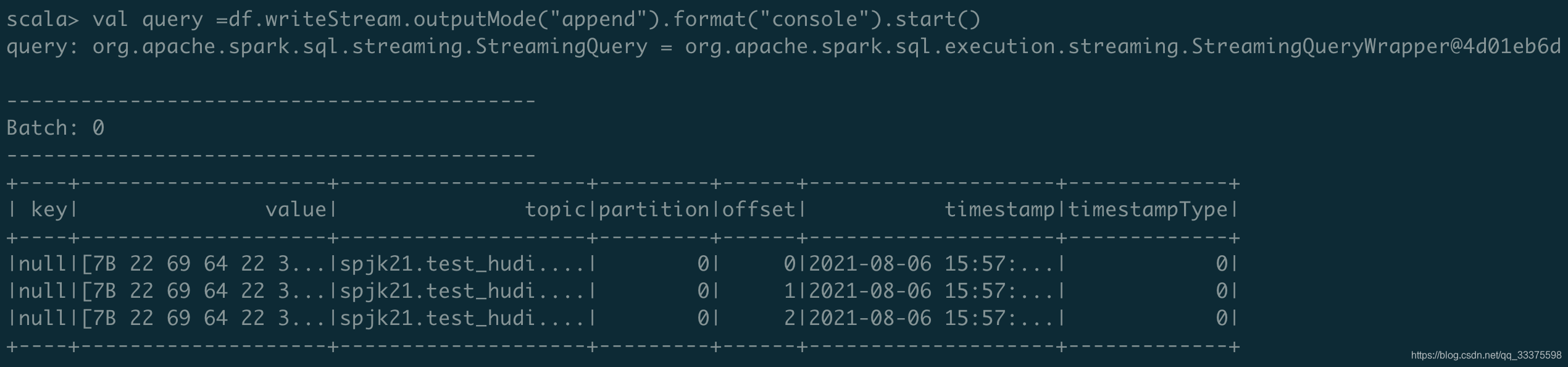
var df = createStreamDF(spark)
val query =df.writeStream.outputMode("append").format("console").start()
如果是要查询多个kafka主题,则传入的kafka的topic应该是"主题1,主题2,主题3",例如:val topic = "spjk21.test_hudi.test17.output,spjk21.test_hudi.test16,spjk21.test_hudi.test15,spjk21.test_hudi.test14"
2 拆分kafka中json格式value为Dataframe
续前面的文件,使用schama拆分Dataframe的json为新的Dataframe(相当于用到了前面的Schame.avsc):
val schema = StructType(List(
StructField("id", StringType),
StructField("transaction_code", StringType),
StructField("shop_id", StringType),
StructField("transaction_time", StringType),
StructField("price", DoubleType),
StructField("cost", DoubleType),
StructField("hudi_delta_streamer_ingest_date", StringType),
StructField("create_time", StringType)))
val data=createStream(spark).load().select(from_json('value.cast("string"), schema) as "value").select($"value.*")
参数解析:
- Schema中用到的基本数据类型:

三个复合类型:

3 写入数据到Hudi
真正的获取kafak中数据,只有在运行writeStream时才会去查询数据。
val query = data.writeStream.queryName("demo").foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist();
batchDF.show();
batchDF.write.format("org.apache.hudi").option(TABLE_TYPE_OPT_KEY,"MERGE_ON_READ").option(PRECOMBINE_FIELD_OPT_KEY,"create_time").option(RECORDKEY_FIELD_OPT_KEY,"id").option(PARTITIONPATH_FIELD_OPT_KEY,"hudi_delta_streamer_ingest_date").option(TABLE_NAME, "test_hudi_mor4").mode(SaveMode.Append).save("/user/hive/warehouse/test_hudi_mor4/")
}
}.option("checkpointLocation", "/user/hive/warehouse/test_hudi_mor4/checkpoint/").start()
参数解析:
- persist():spark对同一个RDD执行多次算法的默认原理为,每次对一个RDD执行一个算子操作时,都会重新从源头处计算一遍。如果某一部分的数据在程序中需要反复使用,这样会增加时间的消耗。为了改善这个问题,spark提供了一个数据持久化的操作,我们可通过persist()或cache()将需要反复使用的数据加载在内存或硬盘当中,以备后用。如果需要添加,则使用unpersist()方法。
- foreachBatch(…):允许指定一个函数,该函数对流式查询的每个微批次的输出数据执行。
- checkpointLocaion(必须拥有):设置一个checkpointLocaion,Structured Streaming就是在这个目录下来管理offset。如果程序中断之后再重启,虽然在读入流的时候设置的是某一个offset,但是在写入流的时候,如果已经存在了checkpointLocation,那么流会从之前中断的地方继续处理,即读入流对offset的设置只是针对checkpointLocation第一次初始化的时候有效。
4 完整代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val kafkaAddress = "10.20.3.75:9092"
val topic = "spjk21.test_hudi.test17.output"
def createStream(spark:SparkSession) = {
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaAddress)
.option("subscribe", topic)
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", 100000)
.option("enable.auto.commit", "false")
.option("failOnDataLoss", false)
.option("includeTimestamp", true)
df
}
val schema = StructType(List(
StructField("id", StringType),
StructField("transaction_code", StringType),
StructField("shop_id", StringType),
StructField("transaction_time", StringType),
StructField("price", DoubleType),
StructField("cost", DoubleType),
StructField("hudi_delta_streamer_ingest_date", StringType),
StructField("create_time", StringType)))
val data=createStream(spark).load().select(from_json('value.cast("string"), schema) as "value").select($"value.*")
val query = data.writeStream.queryName("demo").foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist();
batchDF.show();
batchDF.write.format("org.apache.hudi").option(TABLE_TYPE_OPT_KEY,"MERGE_ON_READ").option(PRECOMBINE_FIELD_OPT_KEY,"create_time").option(RECORDKEY_FIELD_OPT_KEY,"id").option(PARTITIONPATH_FIELD_OPT_KEY,"hudi_delta_streamer_ingest_date").option(TABLE_NAME, "test_hudi_mor4").mode(SaveMode.Append).save("/user/hive/warehouse/test_hudi_mor4/")
}
}.option("checkpointLocation", "/user/hive/warehouse/test_hudi_mor4/checkpoint/").start()
