在Windows中安装PySpark环境
安装Python
可以选择安装官方版本的Python,或是Anaconda,对应的地址如下。
- 下载地址
Python:https://www.python.org/
Anaconda: https://www.anaconda.com/download/#windows
MiniConda:https://docs.conda.io/en/latest/miniconda.html
安装Java运行环境
安装Java运行环境
- 下载地址
在线安装包: https://www.java.com/en/download/
离线安装包:https://www.java.com/zh-CN/download/windows_offline.jsp
下载Spark和winutils工具
由于Hadoop开发是针对类Unix系统的,所以在Windows平台中没有原生的Hadoop安装包,但可以通过winutils工具作为替代。
-
spark下载地址: http://spark.apache.org/downloads.html
-
winutils下载地址: https://github.com/steveloughran/winutils
解压spark,将winutils拷贝到解压目录的bin目录下,如下所示。
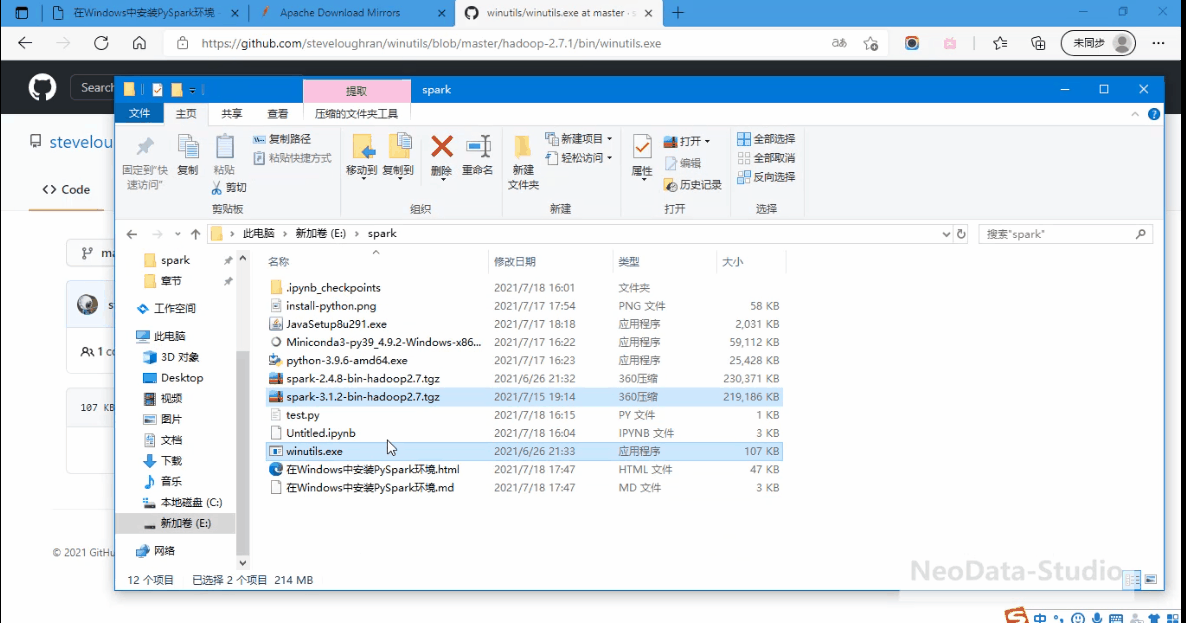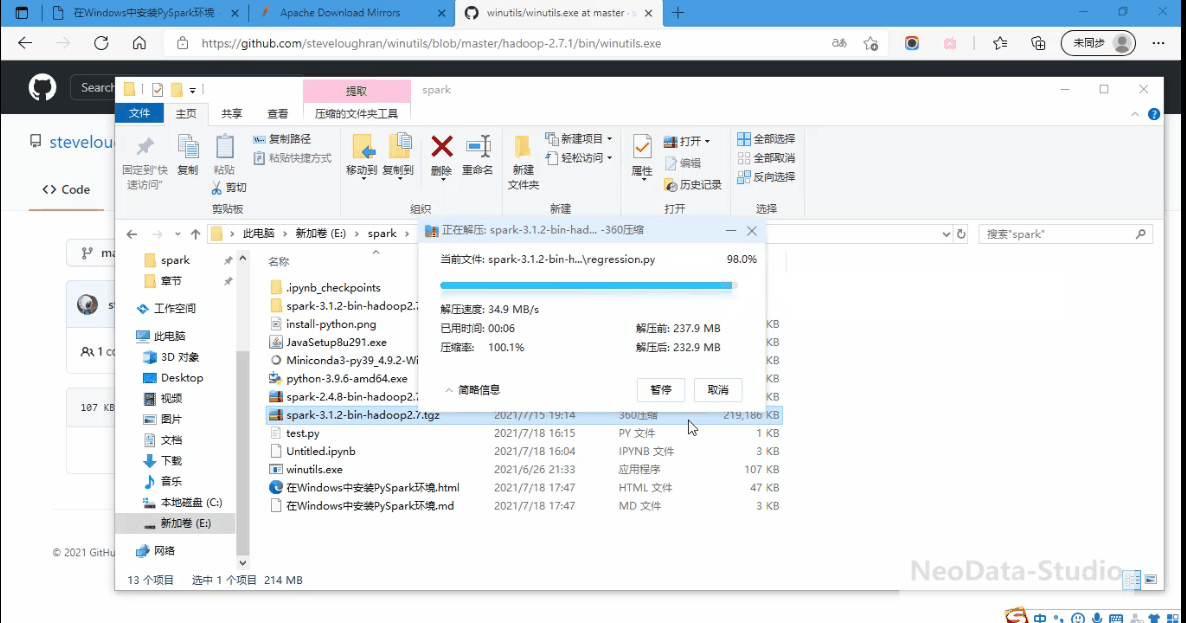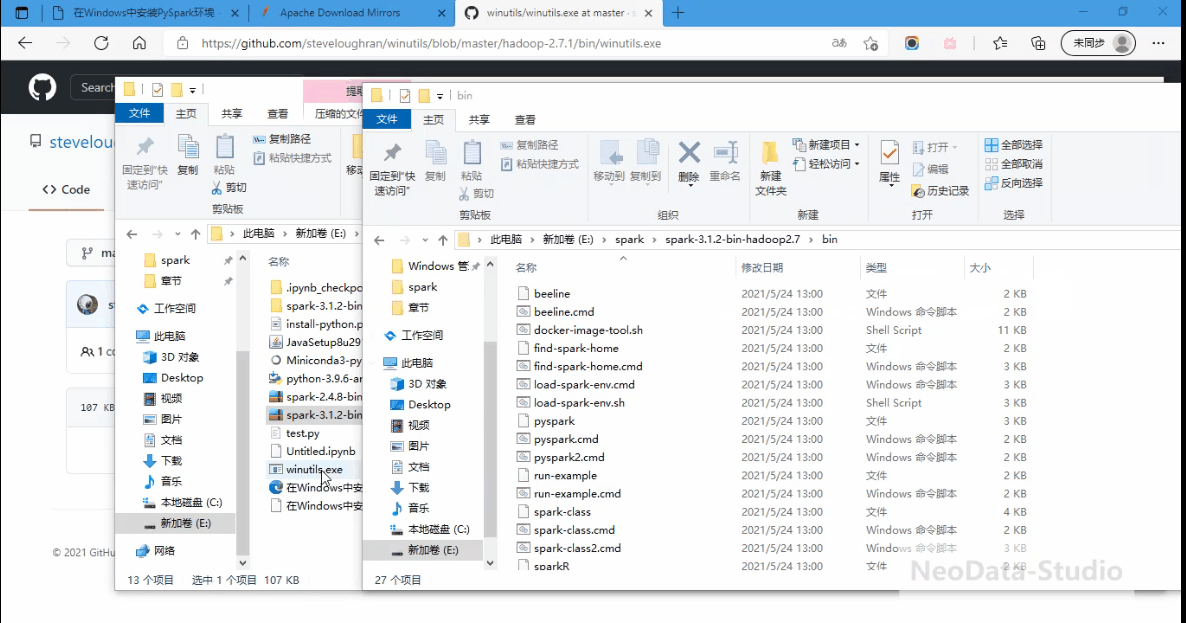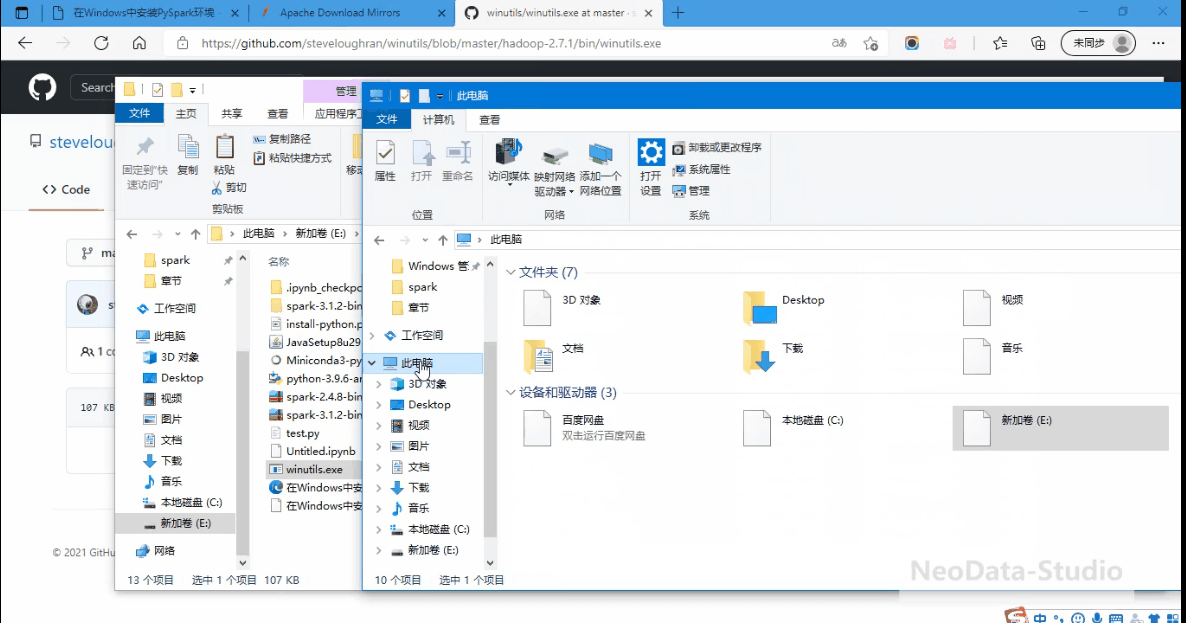
配置环境变量
-
添加环境变量 HADOOP_HOME
变量值是安装Spark的目录,如 E:\spark\spark-3.1.2-bin-hadoop2.7\ -
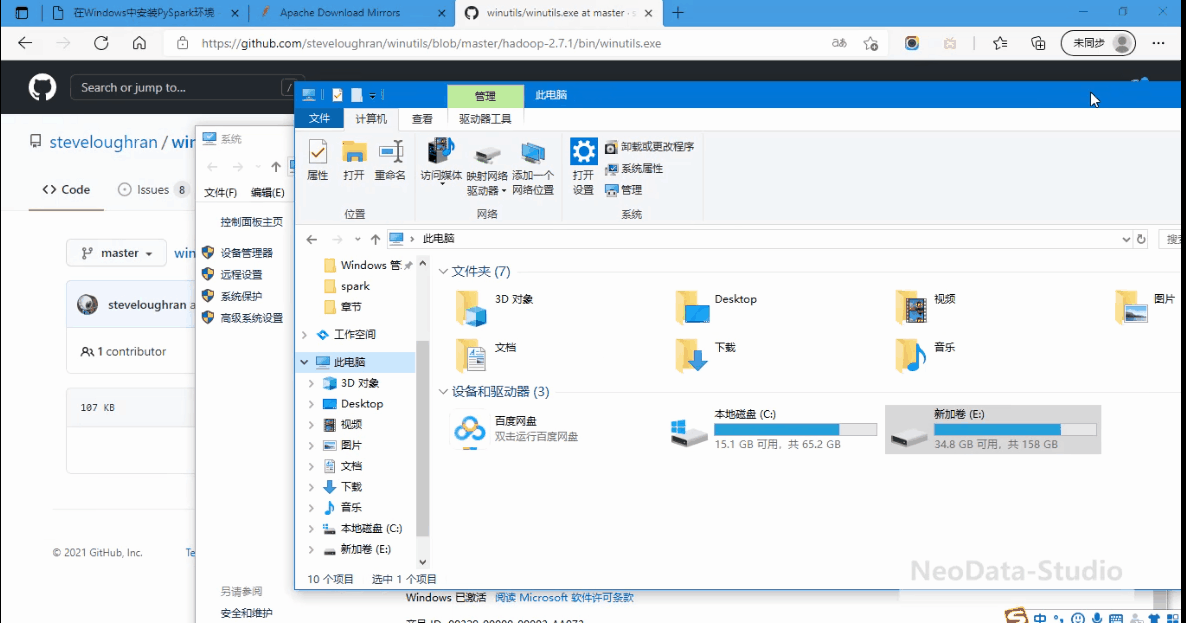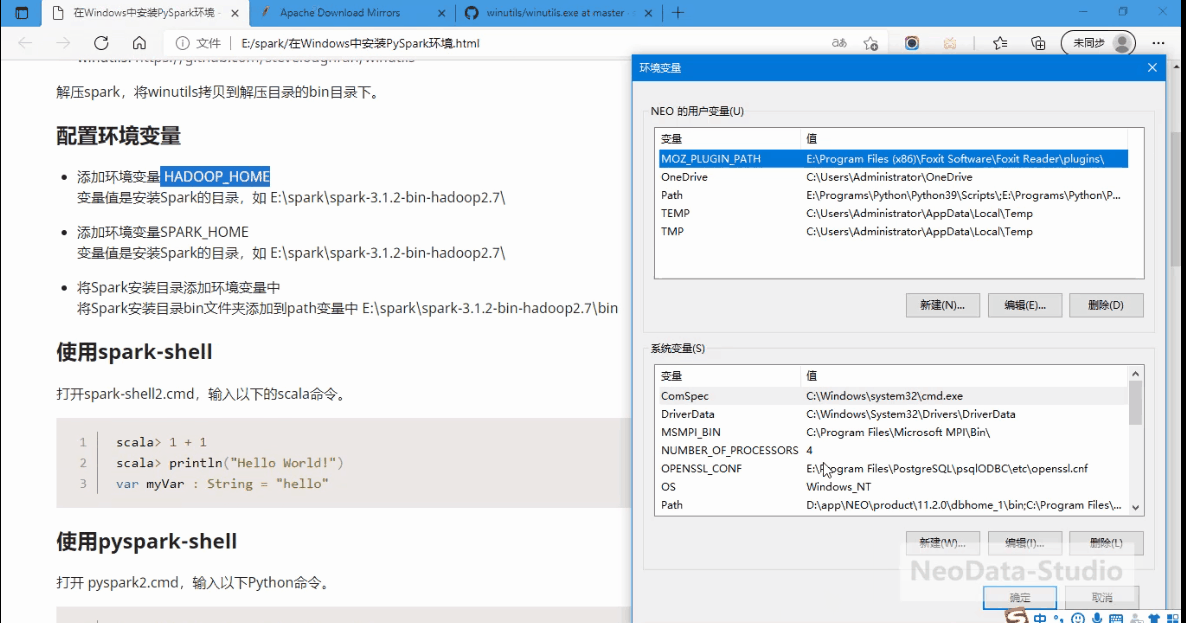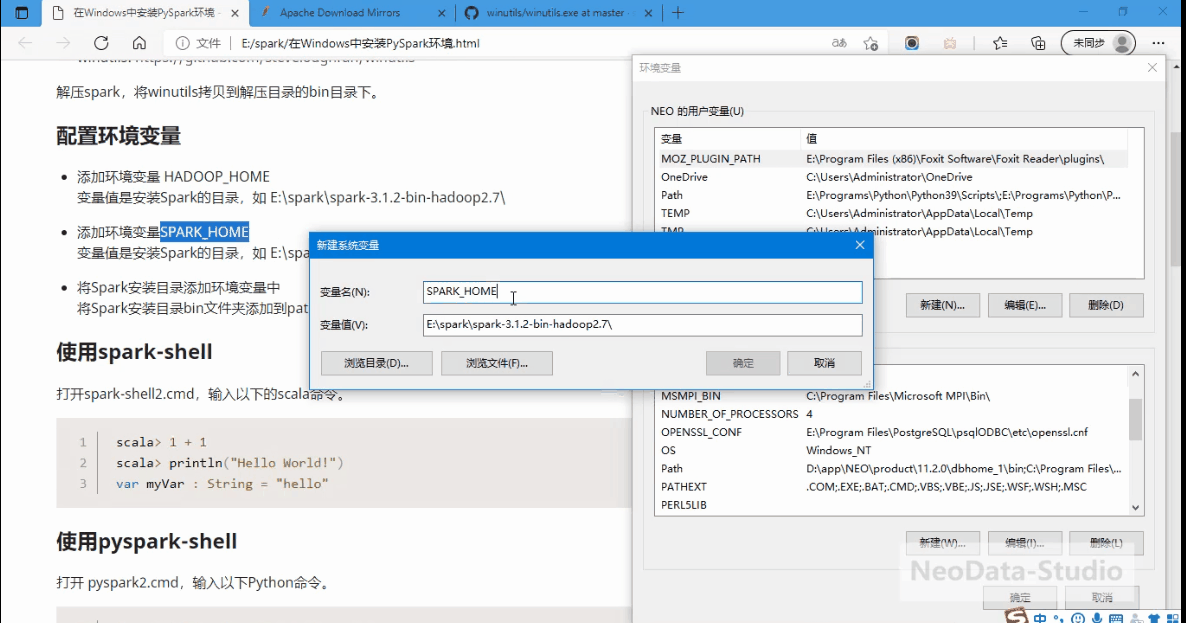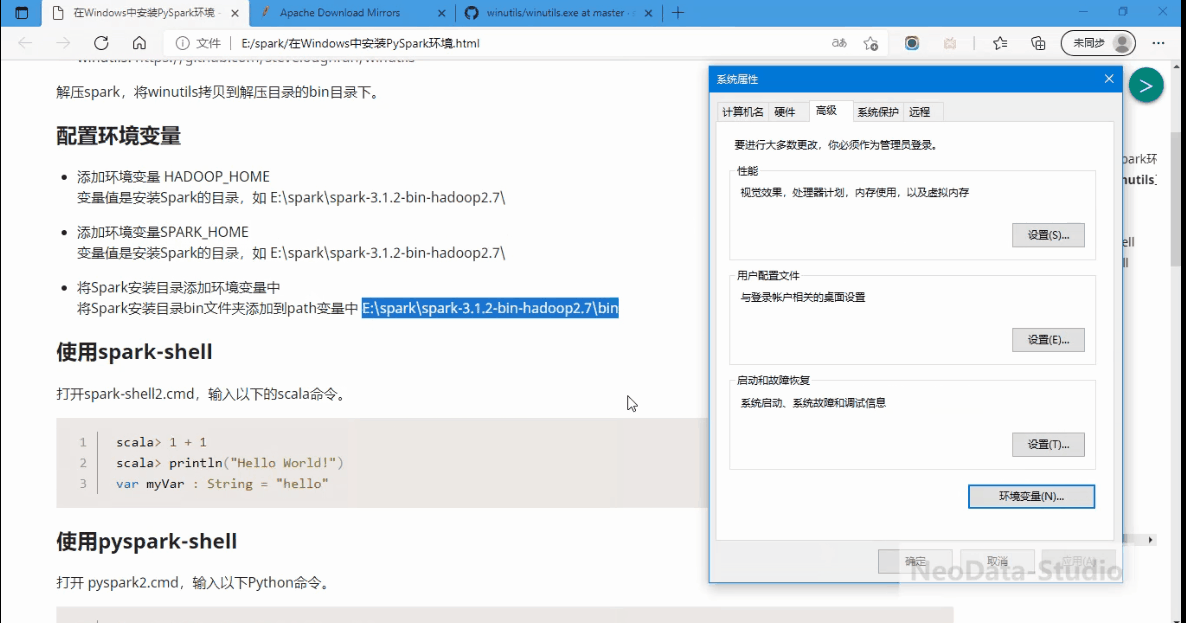
添加环境变量SPARK_HOME
变量值是安装Spark的目录,如 E:\spark\spark-3.1.2-bin-hadoop2.7\ -
将Spark安装目录添加环境变量中
将Spark安装目录bin文件夹添加到path变量中 E:\spark\spark-3.1.2-bin-hadoop2.7\bin
配置过程如下所示:
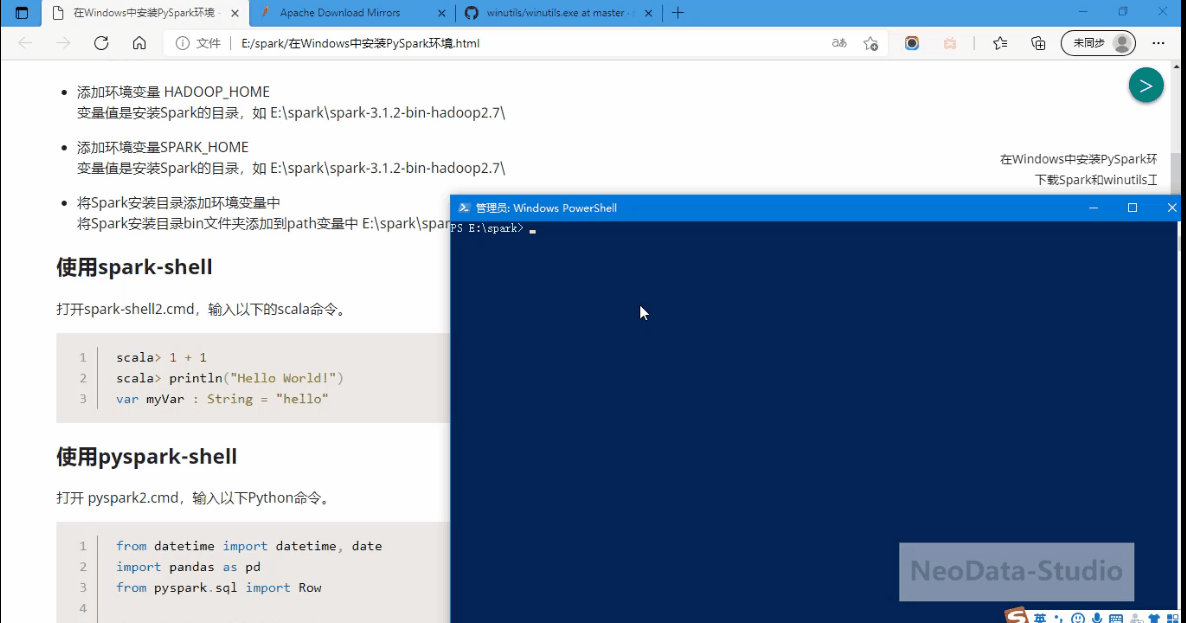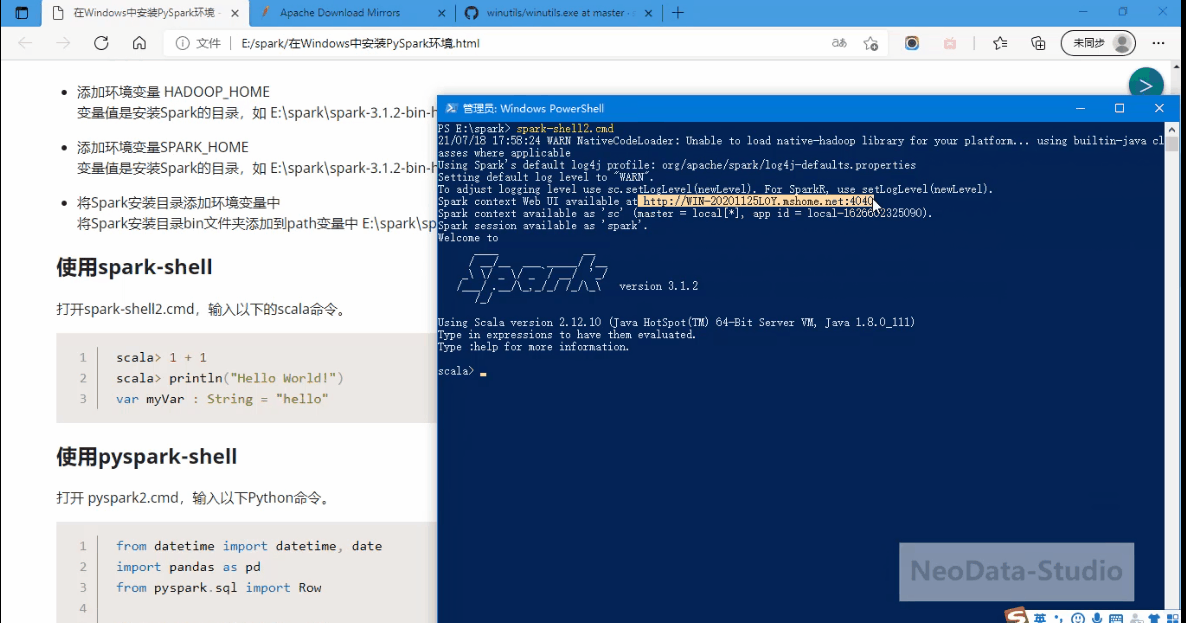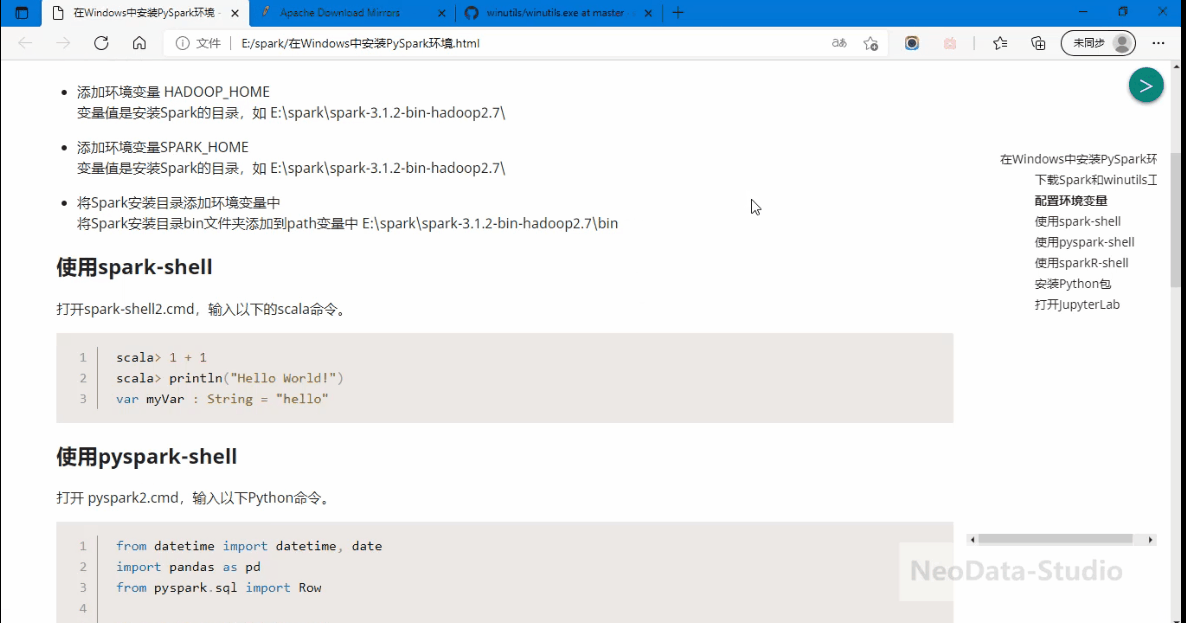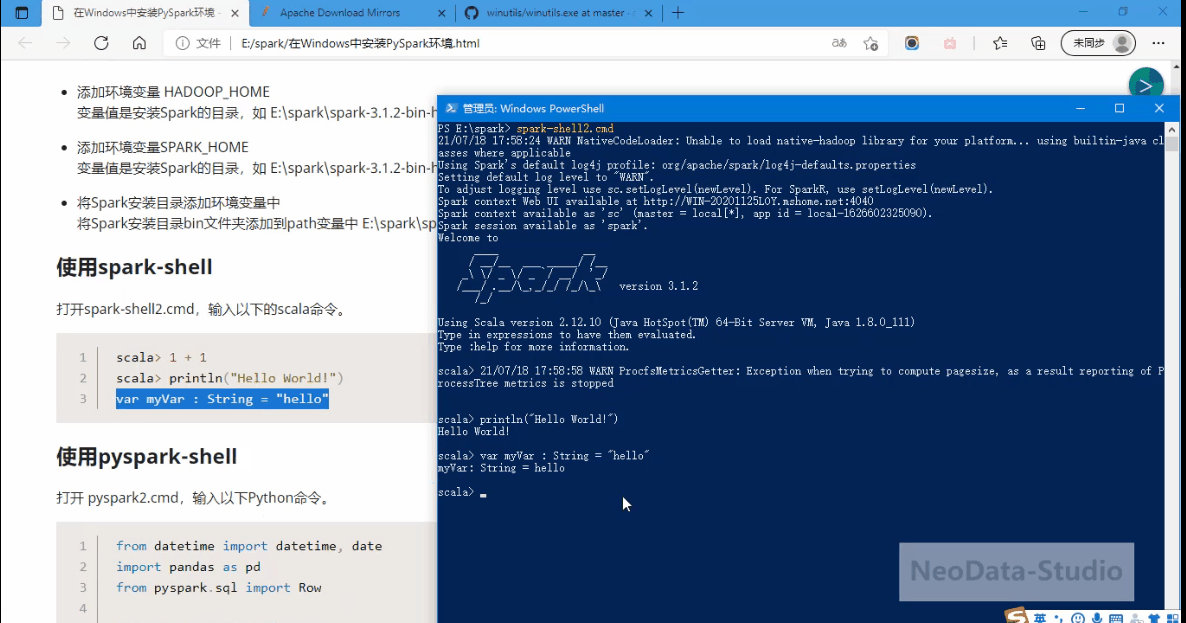
使用spark-shell
安装配置完毕后,对Spark Shell使用,以验证成功的安装。
- 打开spark-shell2.cmd,输入以下的scala命令。
打开一个Power Shell,然后输入命令:spark-shell2.cmd
scala> 1 + 1
scala> println("Hello World!")
var myVar : String = "hello"
- 演示动态图
使用pyspark-shell
- 打开 pyspark2.cmd,输入以下Python命令。
打开一个Power Shell,然后输入命令:pyspark2.cmd
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df.printSchema()
- 演示动态图

使用sparkR-shell
- 打开 sparkR2.cmd,输入以下R语言命令。
打开一个Power Shell,然后输入命令:sparkR2.cmd
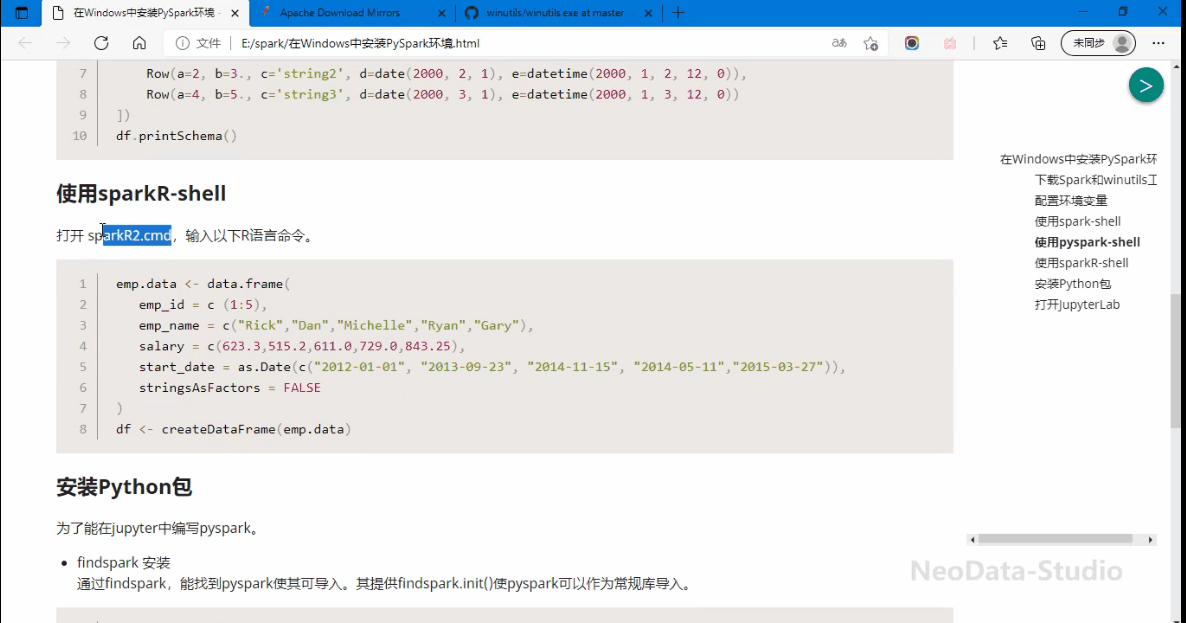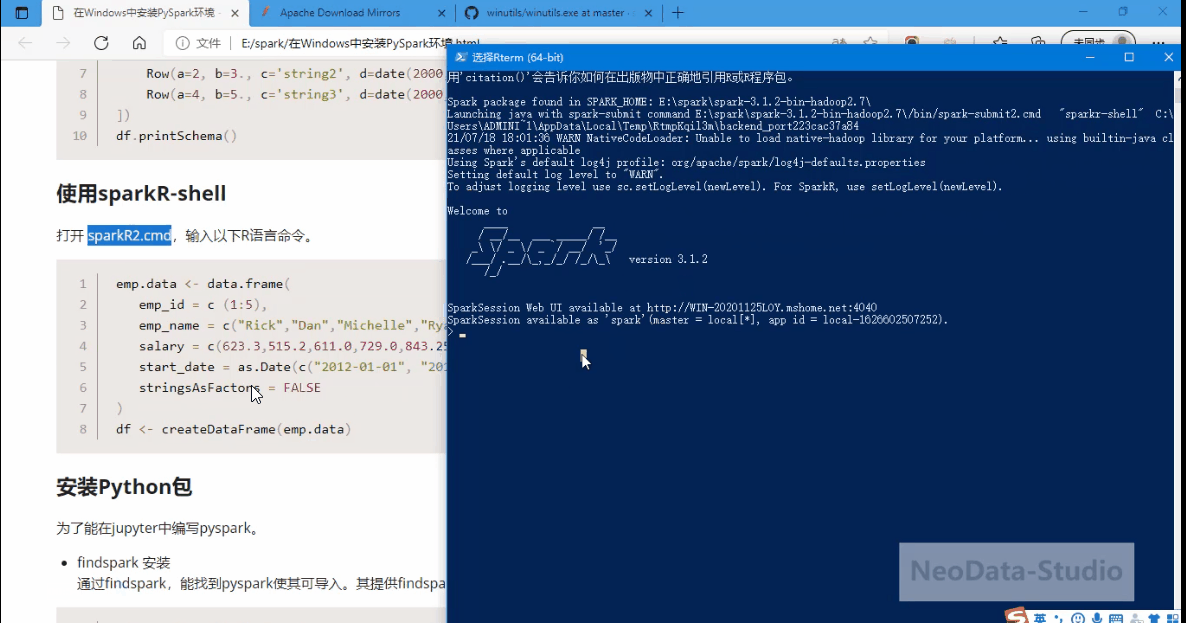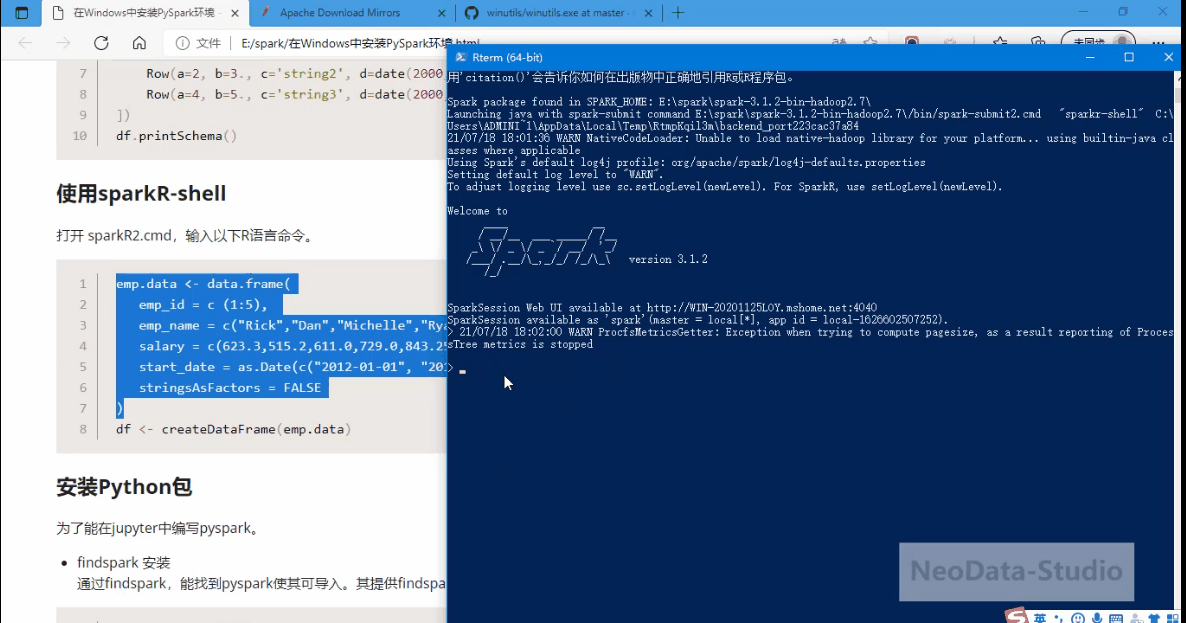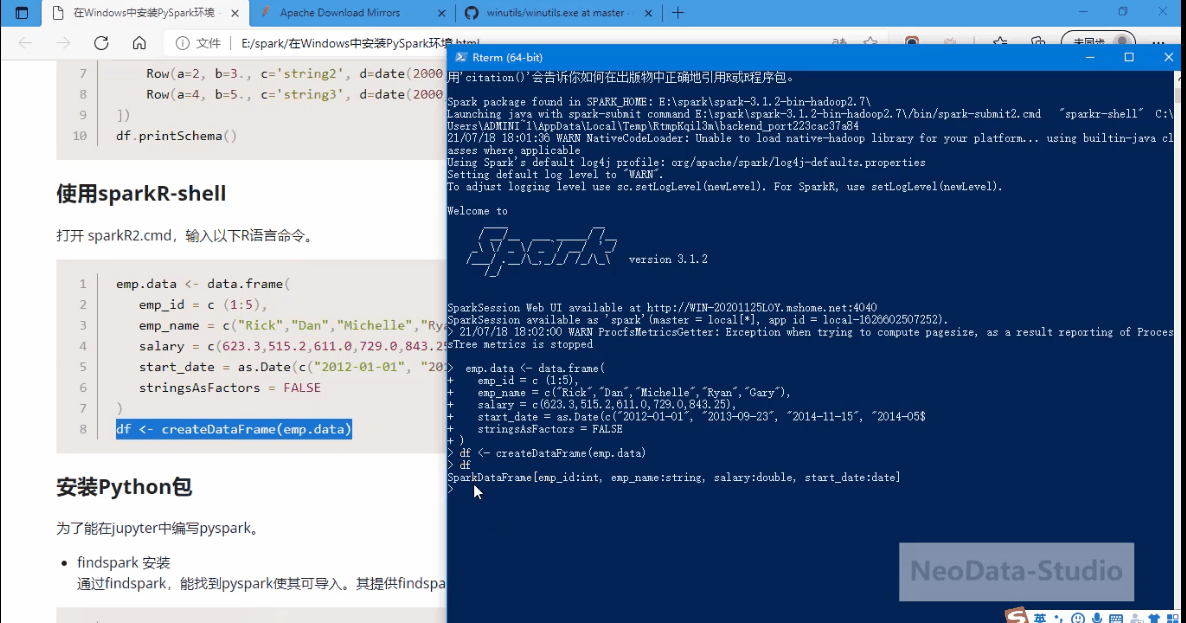
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11","2015-03-27")),
stringsAsFactors = FALSE
)
df <- createDataFrame(emp.data)
- 演示动态图