ElasticSearch
ElasticSearch
term��ѯ
- term��ѯkeyword�ֶΡ�
term����ִʡ���keyword�ֶ�Ҳ���ִʡ���Ҫ��ȫƥ��ſɡ� - term��ѯtext�ֶΡ�
��Ϊtext�ֶλ�ִ�,��term���ִ�,����term��ѯ������������text�ֶηִʺ��ijһ����
match��ѯ
- match��ѯkeyword�ֶ�
match�ᱻ�ִ�,��keyword���ᱻ�ִ�,match����Ҫ��keyword����ȫƥ����ԡ� - match��ѯtext�ֶ�
match�ִ�,textҲ�ִ�,ֻҪmatch�ķִʽ����text�ķִʽ������ͬ�ľ�ƥ�䡣
Elasticsearch�ܹ�ԭ��
Elasticsearch�Ľڵ����ͷ�Ϊ���ֽڵ�:һ����Master,һ����DataNode;
Master�ڵ�
��ElasticSearch��Ⱥ����ʱ,��ѡ�ٳ���һ��Master�ڵ�,��ij���ڵ�������,Ȼ��ʹ��Zen Discovery�����ҵ���Ⱥ�е������ڵ�,���������ӡ�
discovery.seed_hosts: [��192.168.21.130��, ��192.168.21.131��, ��192.168.21.132��]
���Ӻ�ѡ���ڵ���ѡ�ٳ�һ�����ڵ㡣
cluster.initial_master_nodes: [��node1��, ��node2��,��node3��]
Master�ڵ����Ҫ����:
- ��������(��������,ɾ������),�����Ƭ
- ά��Ԫ����(ӳ����Ϣ);
- ������Ⱥ�ڵ�״̬
- ���������ݵ�д��Ͳ�ѯ
һ��ElasticSearch��Ⱥ��,ֻ��һ��Master�ڵ㡣������������,�ڴ�������
Сһ��,������Ҫ�ȶ���
DataNode�ڵ�
��ElasticSearch��Ⱥ��,����N��DataNode�ڵ㡣
��Ҫ���� ���ݵ�д��,���ݼ���,��ѹ������DataNode�ڵ��ϡ�
���,������������,�ڴ�������ô�һЩ��
��Ƭ(Shard)
ES����������Ҳ�Ƿֳ����ɲ���,�ֲ��ڲ�ͬ�ķ������ڵ��С�
�ֲ��ڲ�ͬ�������е���������,���Ƿ�Ƭ;
ES���Զ�������Ƭ,������ַ�Ƭ�ֲ�������,�ͻ��Զ�Ǩ��;
һ�������ɶ��shard���,����Ƭ�ֲ��ڲ�ͬ�������ϡ�
����
Ϊ�˶�ES�ķ�Ƭ�����ݴ�,����ij���ڵ㲻����,�ᵼ�����������ⶼ�����á�
����,��Ҫ�Է�Ƭ���и����ݴ�,ÿһ����Ƭ�����ж�Ӧ�ĸ�����
��ES��,Ĭ�ϴ���������Ϊһ����Ƭ,ÿ����Ƭ��1������Ƭ,һ��������Ƭ��
Primary Shard��Replica Shard����ͬһ���ڵ���
ָ����Ƭ����������
PUT /job_shard
{
"mappings": {
"properties": {
"id":{
"type":"long","store": true
},
"area":{
"type": "keyword","store": true
},
"exp":{
"type": "keyword","store": true
},
"edu":{
"type": "keyword","store": true
},
"salary":{
"type": "keyword","store": true
},
"job_type":{
"type": "keyword","store": true
},
"cmp":{
"type": "keyword","store": true
},
"pv":{
"type": "keyword","store": true
},
"title":{
"type": "text","store": true
},
"jb":{
"type": "text","store": true
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
//�鿴��Ƭ��������Ϣ
GET /_cat/indices?v
Elasticsearch��Ҫ��������
Elasticsearch�ĵ�д��ԭ��
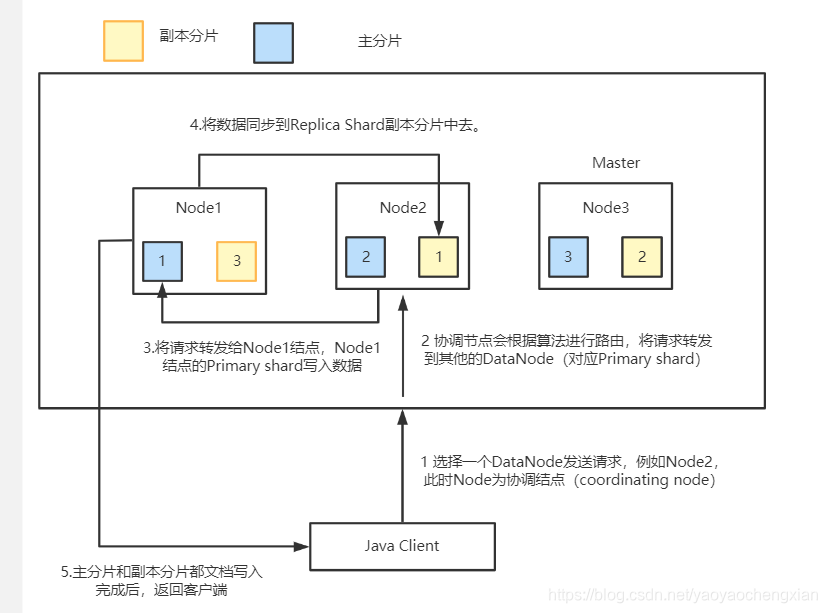
- ѡ������һ��DataNode��������,����:node2����ʱ,node2�ͳ�Ϊһ��
coordinating node(Э���ڵ�) - ����õ��ĵ�Ҫд��ķ�Ƭ
shard = hash(routing) % number_of_primary_shards
routing ��һ���ɱ�ֵ,Ĭ�����ĵ��� _id - coordinating node�����·��,������ת������Ӧ��primary shard���ڵ�
DataNode(����primary shard��node1��replica shard��node2) - node1�ڵ��ϵ�Primary Shard��������,д�����ݵ���������,��������ͬ����
Replica shard - Primary Shard��Replica Shard����������ĵ�,����client
Elasticsearch����ԭ��
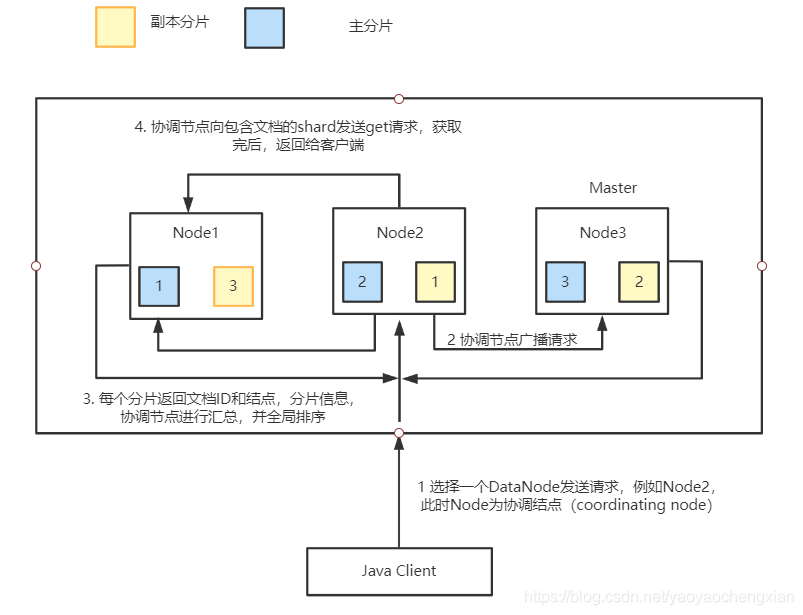
- client�����ѯ����,ij��DataNode���յ�����,��DataNode�ͻ��ΪЭ���ڵ�
(Coordinating Node) - Э���ڵ�(Coordinating Node)����ѯ����㲥��ÿһ�����ݽڵ�,��Щ���ݽ�
��ķ�Ƭ�ᴦ���ò�ѯ���� - ÿ����Ƭ�������ݲ�ѯ,���������������ݷ���һ�����ȶ�����,������Щ����
���ĵ�ID���ڵ���Ϣ����Ƭ��Ϣ���ظ�Э���ڵ㡣 - Э���ڵ㽫���еĽ�����л���,������ȫ������
- Э���ڵ��������Щ�ĵ�ID�ķ�Ƭ����get����,��Ӧ�ķ�Ƭ���ĵ����ݷ��ظ�Э
���ڵ�,���Э���ڵ㽫���ݷ��ظ��ͻ���
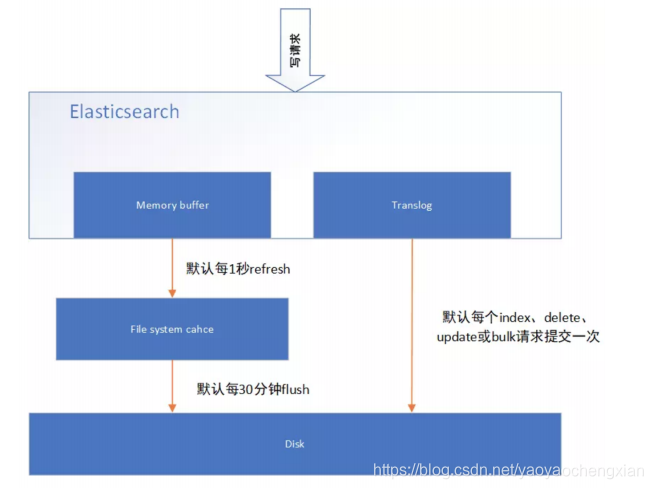
Elasticsearchʵʱ����ʵ��
- ��д���ļ�ϵͳ����
������д�뵽ES��Ƭʱ,������д�뵽�ڴ���,Ȼ��ͨ���ڴ��buffer����һ��
segment,��ˢ���ļ�ϵͳ������,���ݿ��Ա�����(ע�ⲻ��ֱ��ˢ������)
ES��Ĭ��1��,refreshһ�� - дtranslog�����ݴ�
��д�뵽�ڴ��е�ͬʱ,Ҳ���¼translog��־��
��refresh�ڼ�����쳣,�����translog�������ݻָ����ȵ��ļ�ϵͳ�����е�segment����ˢ������,���translog�ļ��� - flushˢ��
ESĬ��ÿ��30���ӻὫ�ļ�ϵͳ���������ˢ�뵽���� - segment�ϲ�
Segment̫��ʱ,ES���ڻὫ���segment�ϲ���Ϊ���segment,����������ѯʱ
IO����,�˽�ES������������ɾ��(֮ǰִ�й���delete������)
�ֹ����������������
����������,���document�е�book�ֶΰ���java���ʹ���,����������������
GET /users2/_search
{
"query": {
"match": {
"book": "java ����"
}
}
}

�����Ҫ������document�е�book�ֶ�,����java�ͷ��ʹ���,����Ҫʹ
�������
GET /users2/_search
{
"query": {
"match": {
"book":{
"query":"java ����",
"operator": "and"
}
}
}
}

�������,�����operator��ֵ��Ϊor�������һ�����������Ч��һ�¡�Ĭ
�ϵ�ESִ��������ʱ��,operator����or��
��������������document��,��Ҫremark�ֶ��а���һ�������������ʡ������ʹ��minimum_should_match,�����ʹ�ðٷֱȻ�̶����֡��ٷֱȴ���query���������д����ٷֱ�,���������,����ƥ��(��,query������3������,���ʹ�ðٷֱ��ṩ���ȼ���,��ô����������,�����Ҫ����ƥ����������,����Ҫ��67%���������������ʹ��66%����,ES
����Ϊƥ��һ�����ʼ��ɡ�)���̶����ִ���query���������еĴ���,������Ҫƥ����ٸ���
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java �߳� ����",
"minimum_should_match": "68%"
}
}
}
}

���ʹ��should+bool�����Ļ�,Ҳ���Կ�������������ƥ��ȡ���������:����
��������������document�е�remark�ֶ���,����ƥ��java��developer��
assistant�������������2����
POST /users2/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"book": "java"
}
},
{
"match": {
"book": "�߳�"
}
},
{
"match": {
"book": "����"
}
}
],
"minimum_should_match": 2
}
}
}

match �ĵײ�ת��
��ʵ��ES��,ִ��match������ʱ��,ES�ײ�ͨ������������������еײ�ת��,
��ʵ�����յ������������:
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java �߳�"
}
}
}
}
//ת��
POST /users2/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"book": {
"value": "java"
}
}
},
{
"term": {
"book": {
"value": "�߳�"
}
}
}
]
}
}
}
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java ����",
"operator": "and"
}
}
}
}
GET /users2/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"book": {
"value": "java"
}
}
},
{
"term": {
"book": {
"value": "����"
}
}
}
]
}
}
}
����,��������鷳,����ʹ��ת������ִ������,Ч�ʸ��ߡ�
����������ڶ�,��������,ʹ�ü�д����
boostȨ�ؿ���
����document��remark�ֶ��а���java������,���remark�а���developer
��architect,�����architect��document������ʾ��(���ǽ�architect����ƥ
��ʱ����ضȷ�������)��
һ����������ʱ��ض�����ʹ�á���:�����е��ۺ�����һ����Ʒ����
��,���Ͷ��,����ֵ,���,���۱Ƚ��ۺ�����������������Ԫ����,���Ͷ
��Ȩ�����,���Ȩ����͡�
GET /users2/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"book": "java"
}
}
],
"should": [
{
"match": {
"book": {
"query": "�߳�",
"boost": 2
}
}
},
{
"match": {
"book": {
"query": "����",
"boost": 1
}
}
}
]
}
}
}

����dis_maxʵ��best fields���Խ��ж��ֶ�����
-
best fields����: ������document�е�ijһ��field,�����ܶ��ƥ������
������ -
��֮�෴����,�����ܶ���ֶ�ƥ�䵽��������(most fields����)����
�ٶ�����ʹ�����ֲ��ԡ� -
�ŵ�:��ȷƥ������ݿ��Ծ����ܵ���������ǰ��,�ҿ���ͨ��
minimum_should_match��ȥ����β����,���ⳤβ�����ֶζ���������Ӱ�졣 -
��β���ݱ���˵��������4���ؼ���,���ܶ��ĵ�ֻƥ��1��,Ҳ��ʾ������,��Щ��
����ʵ����������Ҫ��
ȱ��:��������ȡ� -
dis_max�: ֱ�ӻ�ȡ�����Ķ������е�,������query��ضȷ�����
�ߵ�����,�������������ض�����
�����İ�����,������name�ֶ���rodƥ����ضȷ�����remark�ֶ���java
developerƥ����ضȷ���,�ĸ���,��ʹ����һ����ضȷ������н������
GET /users2/_search
{
"query": {
"dis_max": {
"queries": [{
"match": {
"address": "��"
}
},{
"match": {
"book": "java ����"
}
}]
}
}
}

����tie_breaker�����Ż�dis_max����Ч��
dis_max�ǽ��������query��������ضȷ�����ߵ����ڽ������,��������
query����,��ijЩ�����,���ܻ���Ҫ����query�����е���ضȽ������յĽ��
����,���ʱ�����ʹ��tie_breaker�������Ż�dis_max������tie_breaker����
�����ĺ�����:������query������������ضȷ������Բ���ֵ,�ٲ��뵽�����
���С����������˲���,�൱�ڲ���ֵΪ0����������query��������ضȷ�����
���ԡ�
GET /users2/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [{
"match": {
"address": "����"
}
},{
"match": {
"book": "java ����"
}
}]
}
}
}
ʹ��multi_match��dis_max+tie_breaker
ES����ͬ���������Ҳ����ʹ�ò�ͬ��������ʵ�֡�����Ҫ�ر��ע,ֻ
Ҫ�ܹ�ʵ������,�����������!
POST /users2/_search
{
"query": {
"multi_match": {
"query": "Java ���� �߳� ����",
"fields": ["address","book"],
"type": "best_fields",
"tie_breaker": 0.7,
"minimum_should_match": 4
}
}
}
cross fields����
cross fields : һ��Ψһ�ı�ʶ,�ֲ��ڶ��fields��,ʹ������Ψһ��ʶ
�������ݾͳ�Ϊcross fields���� (������������)��
��:�������Է�Ϊ�պ���,��ַ���Է�Ϊʡ���С����ء��ֵ��ȡ���ôʹ���������ַ������document,�ͳ�Ϊcross fields������
ʵ����������,һ�㶼��ʹ��most fields�������ԡ���Ϊ��Ͳ���һ��field
�����⡣
**Cross fields��������,�ǴӶ���ֶ��������������ݡ�Ĭ�������,��most
fields����������һ�µ�,������ضȷ����Ǻ�best fields����һ�µġ�**һ��
��˵,���ʹ��cross fields��������,��ô����Я��һ������IJ���operator��
�������������������ڶ���ֶ���ƥ�䡣
��Ȼ,��ES��Ҳ��cross fields�������ԡ����������:
POST /users2/_search
{
"query": {
"multi_match": {
"query": "Java ���� �߳� ����",
"fields": ["address","book"],
"type": "cross_fields",
"operator": "and"
}
}
}

�������������,���������е�java������book��address�ֶ���ƥ��,
�����ס�Ҳ������book��book�ֶ���ƥ�䡣���̡߳�Ҳ������book��book�ֶ���ƥ�䡣
�����ݡ�Ҳ������book��book�ֶ���ƥ�䡣
most field��������:most fields�����Ǿ�����ƥ�������ֶ�,���Իᵼ��
��ȷ��������������⡣����Ϊcross fields����,����ʹ��
minimum_should_match��ȥ����β���ݡ�
������ʹ��most fields��cross fields�����������ݵ�ʱ��,���в�ͬ��ȱ
�ݡ�������ҵ��Ŀ������,���Ƽ�ʹ��best fields����ʵ��������
copy_to���fields
������,����������������롰�ֻ���,�������,��ô������Ʒ��������
�ơ���Ʒ�����ơ���Ʒ�����㡢��Ʒ���������ֶ���,��һ���ֶ��ڽ������ݵ�ƥ
��?���ʹ��ijһ���ֶ�������������,��ôʹ��_all�������Ƿ����?Ҳ����
��,��Ϊ_all�ֶ��п��ܰ���ͼƬ,�۸���ֶΡ�
����,��һ���ֶ�,���е����ݰ���(��������):��Ʒ�������ơ���Ʒ���ơ�
��Ʒ������ֶε��������ݡ��Ƿ���������������ֶ��Ͻ�����������ƥ��?
������������Ƭ
copy_to : ���ǽ�����ֶ�,���Ƶ�һ���ֶ���,ʵ��һ�����ֶ���ϡ�copy_to
���Խ��cross fields��������,����ҵ��Ŀ��,Ҳ���ڽ����������Ĭ���ֶ���
�⡣
�����Ҫʹ��copy_to�,����Ҫ�ڶ���index��ʱ��,�ֹ�ָ��mappingӳ���
�ԡ�
copy_to�:
PUT /escopy
{
"mappings": {
"properties": {
"province":{
"type":"text","store": true,"analyzer": "standard","copy_to": "address"
},
"city":{
"type": "text","store": true,"analyzer": "standard","copy_to": "address"
},
"street":{
"type": "text","store": true,"analyzer": "standard","copy_to": "address"
}, "address":{
"type": "text","store": true,"analyzer": "standard"
}
}
}
}
������escopy������,��������4���ֶ�,�ֱ���provice��city��street��
address,����provice��city��street�����ֶε�ֵ,���Զ����Ƶ�address�ֶ�
��,ʵ��һ���ֶε���ϡ���ô��������ַ��ʱ��,�Ϳ�����address�ֶ�������
��ƥ��,�Ӷ�����most fields���Ե��µ����⡣��ά�����ݵ�ʱ��,�����
address�ֶ������ά������Ϊaddress�ֶ���һ������ֶ�,����ES�Զ�ά���ġ�
����java�����е��Ƶ����ԡ��ڴ洢��ʱ��,δ�ش���,������������һ������
��,��Ϊaddress����3���������ڵ�����province��city��street��ɵġ�
����ƥ��
ǰ�Ķ��Ǿ�ȷƥ�䡣��doc��������java assistant,��ô����jave����������
���ݵġ���Ϊjave������doc���Dz����ڵġ�
������������:
GET _search
{
"query": {
"match": {
"name": "jave"
}
}
}
�����Ҫ�Ľ����������Ҫ��,��:hello world������һ�������Ķ���,��
�ɷָ�;��document�е�field��,������hello��world����,����������֮����
��Խ��,��ضȷ���Խ�ߡ���ô��������Ҫ����������ǽ�������������hell����
������hello world����������,����h������ʾ�ȶ����ݽ���������һ���֡�
�����������Ҫ�������,ʹ��match���������ʵ���ˡ�
match phrase
�������������������������ִʡ����������������ɷָ
���hello world��һ�����ɷָ�Ķ���,���ǿ���ʹ��ǰ��ѧ���Ķ�������
match phrase��ʵ�֡������:
POST /users2/_search
{
"query":{
"match_phrase": {
"book": "java����"
}
}
}
POST /users2/_search
{
"query":{
"match_phrase": {
"book": "java�����߳�"
}
}
}

match phraseԭ�� �C term position
ES�����ʵ��match phrase����������?��ʵ��ES��,ʹ��match phrase����
����ʱ��,Ҳ�Ǻ�match����,���ȶ������������зִ�-analyze��������������
�ֳ�hello��world����Ȼ�Ƿִʺ�������,ES�����ʵ�ֶ���������?
�����漰���˵��������Ľ������̡��ڵ�������������ʱ��,ES���ȶ�
document���ݽ��зִ�,��:
GET _analyze
{
"text": "hello world , java thread",
"analyzer": "standard"
}

�����������,���Կ�����ES�����ִʵ�ʱ��,���˽������з���,���ᱣ��
һ��position��position������������������������е��±ꡣ��ESִ��match
phrase������ʱ��,���Ƚ���������hello world�ִ�Ϊhello��world��Ȼ���ڵ�
�������м�������,���hello��world����ij��document��ij��field����ʱ,��
ô���������ƥ�䵽�ĵ��ʵ�position�Ƿ���������,�����������,����ƥ���
��,����Dz�������,��ƥ��ʧ�ܡ�
ǰ���� prefix search
ʹ��ǰƥ��ʵ������������ͨ�����keyword�����ֶ�,Ҳ���Dz��ִʵ���
�Ρ�
GET /users2/_search
{
"query": {
"prefix": {
"name": {
"value": "d"
}
}
}
}

ע��:���ǰ����,�Ƕ�keyword�����ֶζ��ԡ���keyword�����ֶ����ݴ�С
���
ǰ����Ч�ʱȽϵ͡�ǰ�������������ضȷ�����ǰԽ��,Ч��Խ�͡�
���ʹ��ǰ����,����ʹ�ó�ǰ����Ϊǰ������Ҫɨ����������������,��
��ǰԽ��,���Ч��Խ�ߡ�
��������
ES֧���������ʽ�������ڵ���������keyword�����ֶ���ʹ�á�
���÷���:
[] - ��Χ,��: [0-9]��0~9�ķ�Χ����
. - һ���ַ�
-
- ǰ��ı���ʽ���Գ��ֶ�Ρ�
GET /users2/_search
{
"query": {
"regexp": {
"name":"[A�\z].+"
}
}
}
fuzzyģ����������
������ʱ��,�������������ı��������,��:hello world -> hello
word������ƴд�����Ǻܳ����ġ�fuzzy�����������ڽ������ƴд��(��Ӣ��
�к���Ч,�������м�����Ч��)������fuzziness����value��ֵword�����Ķ�
�ٸ���ĸ������ƴд����ľ���(����ĸ������������ĸ���,���ӻ������
ĸ)��f����Ҫ�������ֶ����ơ�
GET /users2/_search
{
"query": {
"fuzzy": {
"name": {
"value": "toa",
"fuzziness": 2
}
}
}
}

ͨ�������
ES��Ҳ��ͨ��������Ǻ�java�������ݿⲻ̫һ����ͨ��������ڵ���������
ʹ��,Ҳ������keyword�����ֶ���ʹ�á�
����ͨ���:
? - һ�������ַ�
* - 0~n�������ַ�
GET /users2/_search
{
"query": {
"wildcard": {
"name": {
"value": "*o*"
}
}
}
}

�ܽ�
���˸о�ES��ʵս�Խ�ǿ�ļ���,û�ж���ʵ��,���Ѽǵ�ס,��סһЩ���õļ��ɡ�