文章目录
背景
在一些业务系统中,模块之间通过引入Kafka解藕,拿IM举例(图来源):
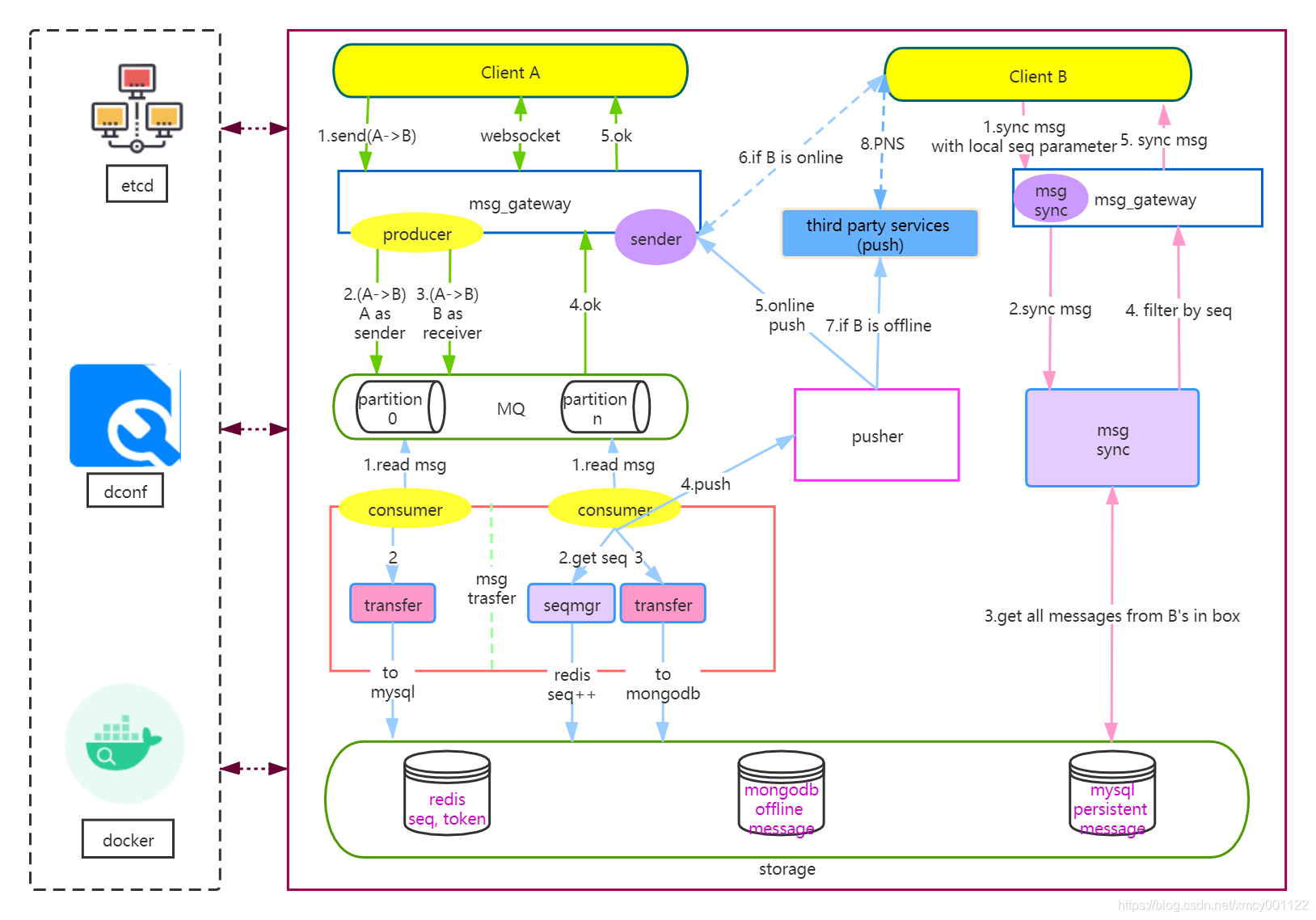
用户A给B发送消息,msg_gateway收到消息后,投递消息到Kafka后就给A返回发送成功。这个时候,其实还没有持久化到mysql中,虽然最终会保持一致性。所以,试想如果Kafka丢消息了,是不是就出大问题了?A认为给B发送消息成功了,但是在服务器内部消息丢失了B并没有收到。
所以,在使用Kafka的时候,有一些业务对消息丢失问题非常的关注。
同样,常见的问题还有:
- 重复消费的问题。
- 乱序的问题。
下面我们来一起看一下如何使用sarama包来解决这些问题。
Kafka消息丢失问题描述
以下内容来源:kafka什么时候会丢消息
上面我们担心的点需要进一步明确一下丢消息的定义:kafka集群中的部分或全部broker挂了,导致consumer没有及时收到消息,这不属于丢消息。broker挂了,只要消息全部持久化到了硬盘上,重启broker集群之后,使消费者继续拉取消息,消息就没有丢失,仍然全量消费了。所以我的理解,所谓丢消息,意味着:开发人员未感知到哪些消息没有被消费。
作者把消息的丢失归纳了以下几种情况:
1) producer把消息发送给broker,因为网络抖动,消息没有到达broker,且开发人员无感知。
解决方案:producer设置acks参数,消息同步到master之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这种方式一定程度保证了消息的可靠性,producer等待broker确认信号的时延也不高。
2)producer把消息发送给broker-master,master接收到消息,在未将消息同步给follower之前,挂掉了,且开发人员无感知。
解决方案:producer设置acks参数,消息同步到master且同步到所有follower之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这样设置,在更大程度上保证了消息的可靠性,缺点是producer等待broker确认信号的时延比较高。
3)producer把消息发送给broker-master,master接收到消息,master未成功将消息同步给每个follower,有消息丢失风险。
解决方案:同上。
4)某个broker消息尚未从内存缓冲区持久化到磁盘,就挂掉了,这种情况无法通过ack机制感知。
解决方案:设置参数,加快消息持久化的频率,能在一定程度上减少这种情况发生的概率。但提高频率自然也会影响性能。
5)consumer成功拉取到了消息,consumer挂了。
解决方案:设置手动sync,消费成功才提交。
综上所述,集群/项目运转正常的情况下,kafka不会丢消息。一旦集群出现问题,消息的可靠性无法完全保证。要想尽可能保证消息可靠,基本只能在发现消息有可能没有被消费时,重发消息来解决。所以在业务逻辑中,要考虑消息的重复消费问题,对于关键环节,要有幂等机制。
作者的几条建议:
1)如果一个业务很关键,使用kafka的时候要考虑丢消息的成本和解决方案。
2)producer端确认消息是否到达集群,若有异常,进行重发。
3)consumer端保障消费幂等性。
4)运维保障集群运转正常且高可用,保障网络状况良好。
生产端丢消息问题解决
上面说了,只需要把producer设置acks参数,等待Kafka所有follower都成功后再返回。我们只需要进行如下设置:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
ack参数有如下取值:
const (
// NoResponse doesn't send any response, the TCP ACK is all you get.
NoResponse RequiredAcks = 0
// WaitForLocal waits for only the local commit to succeed before responding.
WaitForLocal RequiredAcks = 1
// WaitForAll waits for all in-sync replicas to commit before responding.
// The minimum number of in-sync replicas is configured on the broker via
// the `min.insync.replicas` configuration key.
WaitForAll RequiredAcks = -1
)
消费端丢消息问题
通常消费端丢消息都是因为Offset自动提交了,但是数据并没有插入到mysql(比如出现BUG或者进程Crash),导致下一次消费者重启后,消息漏掉了,自然数据库中也查不到。这个时候,我们可以通过手动提交解决,甚至在一些复杂场景下,还要使用二阶段提交。
自动提交模式下的丢消息问题
默认情况下,sarama是自动提交的方式,间隔为1秒钟
// NewConfig returns a new configuration instance with sane defaults.
func NewConfig() *Config {
// …
c.Consumer.Offsets.AutoCommit.Enable = true. // 自动提交
c.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 间隔
c.Consumer.Offsets.Initial = OffsetNewest
c.Consumer.Offsets.Retry.Max = 3
// ...
}
这里的自动提交,是基于被标记过的消息(sess.MarkMessage(msg, “"))
type exampleConsumerGroupHandler struct{}
func (exampleConsumerGroupHandler) Setup(_ ConsumerGroupSession) error { return nil }
func (exampleConsumerGroupHandler) Cleanup(_ ConsumerGroupSession) error { return nil }
func (h exampleConsumerGroupHandler) ConsumeClaim(sess ConsumerGroupSession, claim ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("Message topic:%q partition:%d offset:%d\n", msg.Topic, msg.Partition, msg.Offset)
// 自动提交
sess.MarkMessage(msg, "")
}
return nil
}
如果不调用sess.MarkMessage(msg, “"),即使启用了自动提交也没有效果,下次启动消费者会从上一次的Offset重新消费,我们不妨注释掉sess.MarkMessage(msg, “"),然后打开Offset Explorer查看:
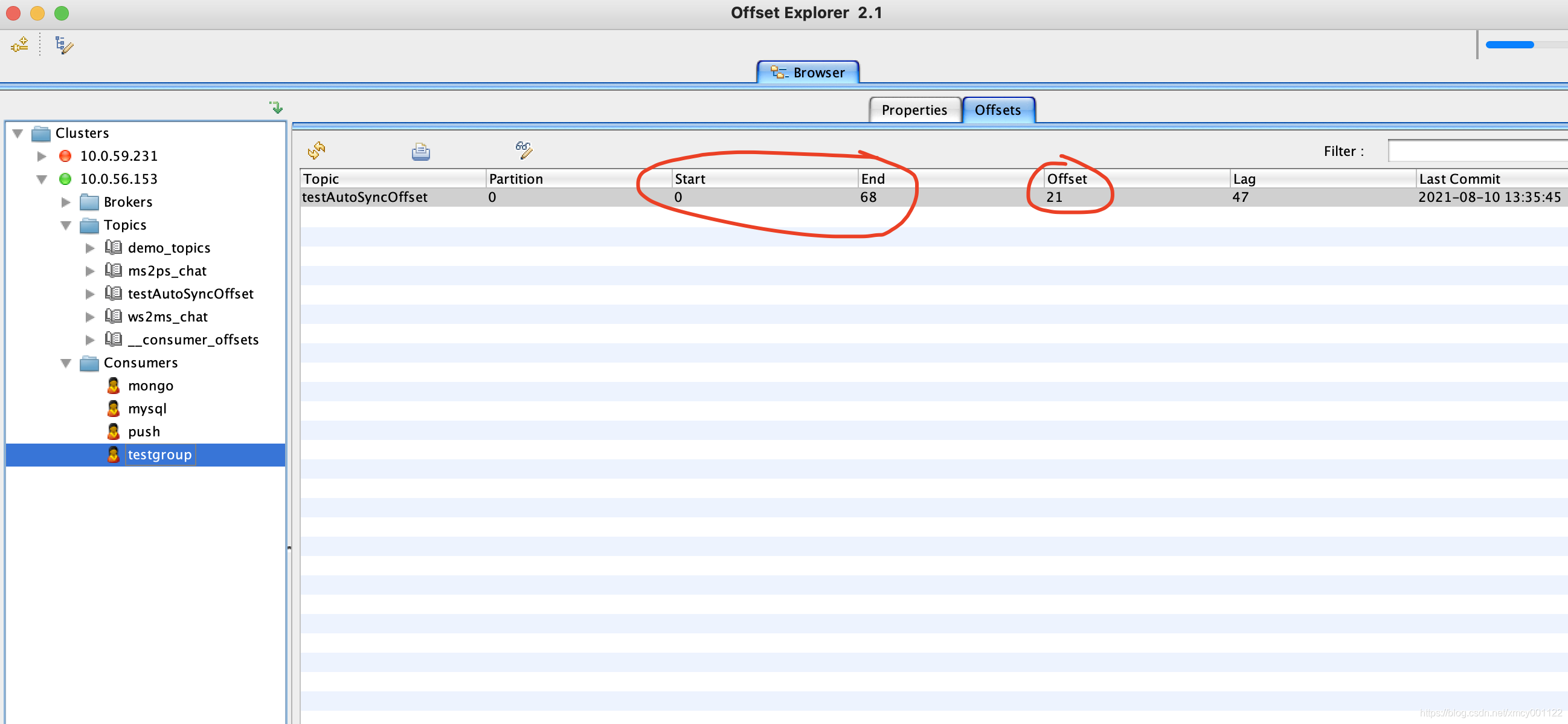
那么这样,我们大概理解了sarama自动提交的原理:先标记再提交。我们只需要保持标记逻辑在插入mysql代码之后即可确保不会出现丢消息的问题:
正确的调用顺序:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 插入mysql
insertToMysql(msg)
// 正确:插入mysql成功后程序崩溃,下一次顶多重复消费一次,而不是因为Offset超前,导致应用层消息丢失了
sess.MarkMessage(msg, “")
}
return nil
}
错误的顺序:
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
// 错误1:不能先标记,再插入mysql,可能标记的时候刚好自动提交Offset,但mysql插入失败了,导致下一次这个消息不会被消费,造成丢失
// 错误2:干脆忘记调用sess.MarkMessage(msg, “"),导致重复消费
sess.MarkMessage(msg, “")
// 插入mysql
insertToMysql(msg)
}
return nil
}
sarama手动提交模式
当然,另外也可以通过手动提交来处理丢消息的问题,但是个人不推荐,因为自动提交模式下已经能解决丢消息问题。
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0
consumerConfig.Consumer.Return.Errors = false
consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 插入mysql
insertToMysql(msg)
// 手动提交模式下,也需要先进行标记
sess.MarkMessage(msg, "")
consumerCount++
if consumerCount%3 == 0 {
// 手动提交,不能频繁调用,耗时9ms左右,macOS i7 16GB
t1 := time.Now().Nanosecond()
sess.Commit()
t2 := time.Now().Nanosecond()
fmt.Println("commit cost:", (t2-t1)/(1000*1000), "ms")
}
}
return nil
}
Kafka消息顺序问题
投递Kafka之前,我们通过一次gRPC调用解决了消息序号的生成问题,但是这里其实还涉及一个消息顺序问题:订阅Kafka的消费者如何按照消息顺序写入mysql,而不是随机写入呢?
我们知道,Kafka的消息在一个partition中是有序的,所以只要确保发给某个人的消息都在同一个partition中即可。
全局一个partition
这个最简单,但是在kafka中一个partition对应一个线程,所以这种模型下Kafka的吞吐是个问题。
多个partition,手动指定
msg := &sarama.ProducerMessage{
Topic: “msgc2s",
Value: sarama.StringEncoder(“hello”),
Partition: toUserId % 10,
}
partition, offset, err := producer.SendMessage(msg)
生产消息的时候,除了Topic和Value,我们可以通过手动指定partition,比如总共有10个分区,我们根据用户ID取余,这样发给同一个用户的消息,每次都到1个partition里面去了,消费者写入mysql中的时候,自然也是有序的。
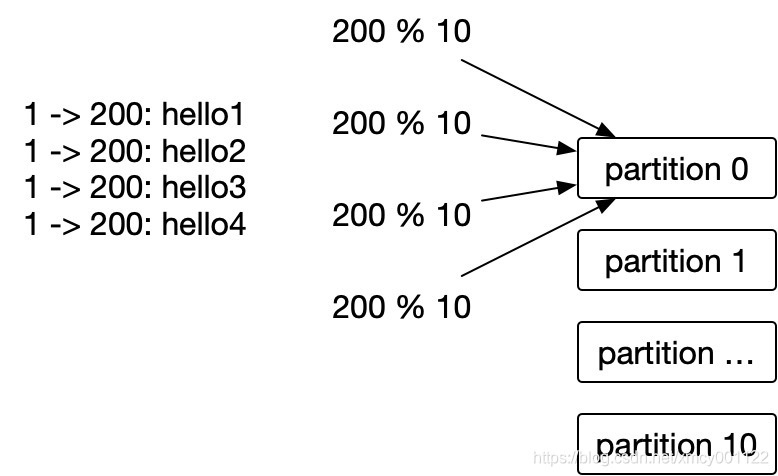
但是,因为分区总数是写死的,万一Kafka的分区数要调整呢?那不得重新编译代码?所以这个方式不够优美。
多个partition,自动计算
kafka客户端为我们提供了这种支持。首先,在初始化的时候,设置选择分区的策略为Hash
p.config.Producer.Partitioner = sarama.NewHashPartitioner
然后,在生成消息之前,设置消息的Key值:
msg := &sarama.ProducerMessage{
Topic: "testAutoSyncOffset",
Value: sarama.StringEncoder("hello"),
Key: sarama.StringEncoder(strconv.Itoa(RecvID)),
}
Kafka客户端会根据Key进行Hash,我们通过把接收用户ID作为Key,这样就能让所有发给某个人的消息落到同一个分区了,也就有序了。
扩展知识:多线程情况下一个partition的乱序处理
我们上面说了,Kafka客户端针对一个partition开一个线程进行消费,如果处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟就只能处理几十条消息,这吞吐量太低了。这个时候,我们可能就把逻辑移动到其他线程里面去处理,这样的话,顺序就可能会乱。
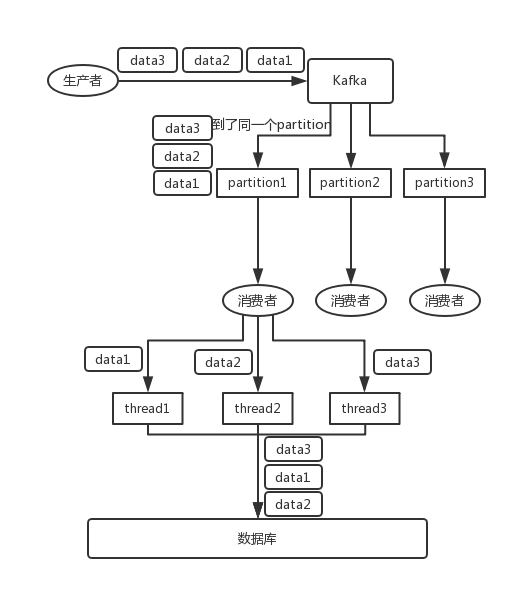
我们可以通过写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。PS:就像4 % 10 = 4,14 % 10 = 4,他们取余都是等于4,所以落到了一个partition,但是key值不一样啊,我们可以自己再取余,放到不同的queue里面。
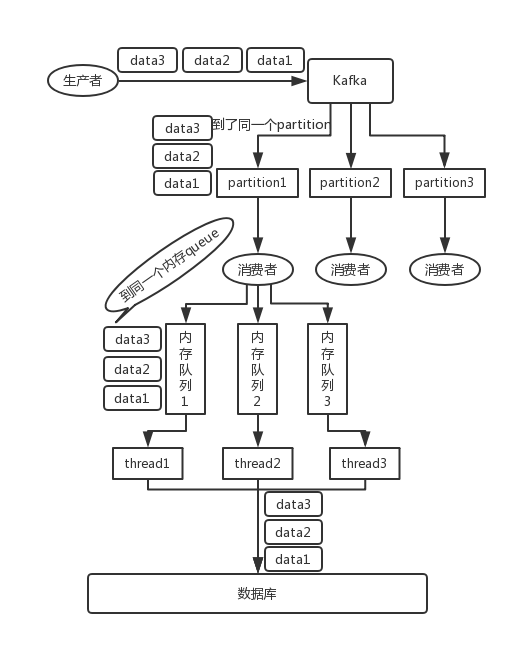
重复消费和消息幂等
这篇文章中:kafka什么时候会丢消息 详细了描述了各种丢消息的情况,我们通过设置 RequiredAcks = sarama.WaitForAll(-1),可以解决生产端丢消息的问题。第六节中也对消费端丢消息进行了说明,只需要确保在插入数据库之后,调用sess.MarkMessage(msg, "”)即可。
如果出现了插入Mysql成功,但是因为自动提交有1秒的间隔,如果此时崩溃,下次启动消费者势必会对者1秒的数据进行重复消费,我们在应用层需要处理这个问题。
常见的有2种思路:
- 如果是存在redis中不需要持久化的数据,比如string类型,set具有天然的幂等性,无需处理。
- 插入mysql之前,进行一次query操作,针对每个客户端发的消息,我们为它生成一个唯一的ID(比如GUID),或者直接把消息的ID设置为唯一索引。
第2个方案的难点在于,全局唯一ID的生成,理论上GUID也是存在重复的可能性的,如果是客户端生成,那么插入失败,怎么让客户端感知呢?所以,这里我认为还是需要自定义ID生产,比如通过组合法:用户ID + 当前时间 + 32位GUID,是不是几乎不会重复了呢(试想,1个人发1亿条文本需要多少年。。。)?
完整代码实例
consumer.go
type msgConsumerGroup struct{}
func (msgConsumerGroup) Setup(_ sarama.ConsumerGroupSession) error { return nil }
func (msgConsumerGroup) Cleanup(_ sarama.ConsumerGroupSession) error { return nil }
func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value))
// 查mysql去重
if check(msg) {
// 插入mysql
insertToMysql()
}
// 标记,sarama会自动进行提交,默认间隔1秒
sess.MarkMessage(msg, "")
}
return nil
}
func main(){
consumerConfig := sarama.NewConfig()
consumerConfig.Version = sarama.V2_8_0_0 // specify appropriate version
consumerConfig.Consumer.Return.Errors = false
//consumerConfig.Consumer.Offsets.AutoCommit.Enable = true // 禁用自动提交,改为手动
//consumerConfig.Consumer.Offsets.AutoCommit.Interval = time.Second * 1 // 测试3秒自动提交
consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest
cGroup, err := sarama.NewConsumerGroup([]string{"10.0.56.153:9092", "10.0.56.153:9093", "10.0.56.153:9094"},"testgroup", consumerConfig)
if err != nil {
panic(err)
}
for {
err := cGroup.Consume(context.Background(), []string{"testAutoSyncOffset"}, consumerGroup)
if err != nil {
fmt.Println(err.Error())
break
}
}
_ = cGroup.Close()
}
producer.go
func main(){
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 等待所有follower都回复ack,确保Kafka不会丢消息
config.Producer.Return.Successes = true
config.Producer.Partitioner = sarama.NewHashPartitioner // 对Key进行Hash,同样的Key每次都落到一个分区,这样消息是有序的
// 使用同步producer,异步模式下有更高的性能,但是处理更复杂,这里建议先从简单的入手
producer, err := sarama.NewSyncProducer([]string{"10.0.56.153:9092"}, config)
defer func() {
_ = producer.Close()
}()
if err != nil {
panic(err.Error())
}
msgCount := 4
// 模拟4个消息
for i := 0; i < msgCount; i++ {
rand.Seed(int64(time.Now().Nanosecond()))
msg := &sarama.ProducerMessage{
Topic: "testAutoSyncOffset",
Value: sarama.StringEncoder("hello+" + strconv.Itoa(rand.Int())),
Key: sarama.StringEncoder("BBB”),
}
t1 := time.Now().Nanosecond()
partition, offset, err := producer.SendMessage(msg)
t2 := time.Now().Nanosecond()
if err == nil {
fmt.Println("produce success, partition:", partition, ",offset:", offset, ",cost:", (t2-t1)/(1000*1000), " ms")
} else {
fmt.Println(err.Error())
}
}
}
关于作者
推荐下自己的开源IM,纯Golang编写:
CoffeeChat:https://github.com/xmcy0011/CoffeeChat
opensource im with server(go) and client(flutter+swift)
参考了TeamTalk、瓜子IM等知名项目,包含服务端(go)和客户端(flutter+swift),单聊和机器人(小微、图灵、思知)聊天功能已完成,目前正在研发群聊功能,欢迎对golang感兴趣的小伙伴Star加关注。