Elasticsearch学习(一)
Elasticsearch简介
Elasticsearch是一个建立在全文搜索引擎Apache Lucene?基础上搜索引擎, 是Lucene当今最先进、最高效的全功能开源搜索引擎框架。
Elasticsearch是一个实时分布式和开源的全文搜索和分析引擎。可以使用RESTful Web服务接口访问;基于java语言开发,这一特性使得Elasticsearch能在不同的平台上运行。
Elasticsearch特性
Elasticsearch的一般特性:
- Elasticsearch可扩展PB级的结构化和非结构化数据。
- Elasticsearch可以用来替代MongoDB和RavenDB等做文档存储。
- Elasticsearch使用非标准化来提高搜索性能。
- Elasticsearch是受欢迎的企业搜索引擎之一。目前被许多大型组织使用,如:Wikipedia、StackOverflow、GitHub等
- Elasticsearch是开放源代码,可在Apache许可证版本
2.0下提供。
Elasticsearch概念
- 节点 - 指的是Elasticsearch的单个正在运行的实例。
- 集群 - 一个或多个节点的集合。
- 索引 - 不同类型文档和文档属性的集合。索引还使用分片的概念来提高性能。
- 类型/映射 - 共享同一索引中存在的一组公共字段的文档集合。
- 文档 - 以JSON格式定义的特定方式的字段集合。每个文档都属于一个类型并驻留在索引中,每个文档都与唯一标识符(UID)相关联。
- 碎片 - 索引被水平细分为碎片。这意味着每个碎片包含文档的所有属性,但包含的数量比索引少。水平分隔使碎片成为一个独立的节点,可以存储在任何节点中。主碎片是索引的原始水平部分,然后这些主碎片被复制到副本碎片中。
- 副本 - Elasticsearch允许用户创建其索引和分片的副本。复制不仅有助于在故障情况下增加数据的可用性,而且还通过在这些副本中执行并行搜索操作来提高搜索的性能。
Elasticsearch优点
- Elasticsearch是基于java开发的,这使得它在几乎每个平台上都兼容。
- Elasticsearch是实时的。
- Elasticsearch是分布式的,易于在任何大型组织中扩展和集成。
- 通过使用Elasticsearch中的网关概念,创建完整备份很容易。
- 与Apache Solr相比,在Elasticsearch中处理多租户非常容易。
- Elasticsearch使用JSON对象作为响应,这使得可以使用不同的编程语言调用Elasticsearch服务器。
- Elasticsearch支持几乎大部分文档类型,但不支持文本呈现的文档类型。
Elasticsearch缺点
- Elasticsearch在处理请求和响应数据方面没有多语言和数据格式支持(仅能使用JSON格式数据),与Apache Solr不同,Elasticsearch不可以使用CSV、XML等格式。
- Elasticsearch也有一些伤脑筋的问题发生,虽然在极少数情况下才会发生。
Elasticsearch安装(windows环境)
第1步: 检查系统中java的版本,Elasticsearch要求在java 7以上的版本中才可以安装使用。
第2步: 从www.elastic.co下载最新的Elasticsearch包,注意选择ZIP文件。
第3步: 下载完解压就完事了。
第4步: 进入解压后的主目录下的bin目录下,双击elasticsearch.bat
第5步: Elasticsearch Web界面的默认端口是9200, 或者可以通过更改config目录中的elasticsearch.yml文件中http.port字段值来更改。在浏览器上通过访问:http://localhost:9200来检查服务器是否已启动并正在运行。如果没有问题,它将返回一个JSON对象,其中包含有关安装的Elasticsearch信息。如下:
{
"name" : "DESKTOP-IISOMA5",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "71HBupSgSfW5dE8gCehRew",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
第6步: 可以使用任何接口访问工具如:postman等工具来进行对Elasticsearch的操作
Elasticsearch的文档管理(CRUD)
创建索引
在Elasticsearch索引中,对应的CRUD中的“创建”和“更新”,如果对具有给定类型的文档进行索引,并且要插入原先不存在的ID。如果具有相同类型和ID的文档存在,则会覆盖。
要索引第一个JSON对象,我们对REST API创建一个PUT请求到一个由索引名称、类型名称和ID组成的URL。也就是:http://localhost:9200/索引名/类型名/id。
索引和类型是必需的,而id部分是可选的。如果不指定ID,Elasticsearch会为我们生成一个ID。但是如果不指定id,应该使用HTTP的POST而不是PUT请求。
索引名称是任意的。如果服务器上没有此名称的索引,则将使用默认配置来创建一个索引。
至于类型名称,也是任意的。主要有以下几个用途:
- 每种类型都有自己的ID空间
- 不同类型具有不同的映射(“模式”,定义属性、字段应如何编制索引)。
- 搜索多种类型是可以的,并且也很常见,但很容易搜索一种或多种指定类型。
现在开始索引一些内容:
PUT - http://localhost:9200/movies/movie/1
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}
使用postman的话:
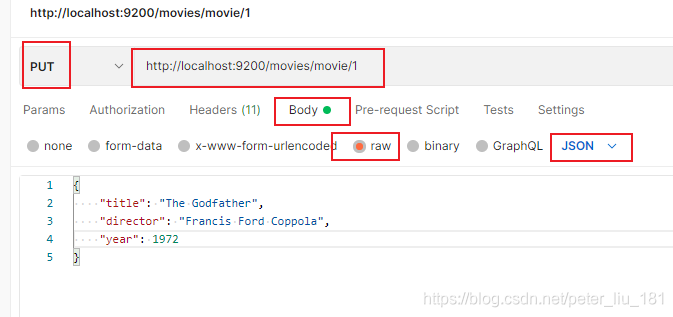
以上;movies为索引的名称,movie为类型名称,1就是id。
执行请求后,可以看到接收到来自Elasticsearch响应的JOSN对象。如下
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
响应对象中包含有关索引和类型以及文档id的信息。
更新索引
Elasticsearch中已经有了一些数据信息,接下来了解如何更新它:
PUT - http://localhost:9200/movies/movie/1
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}
使用相同id索引它,但是扩展了请求的JSON对象。
Elasticsearch返回的响应如下:
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 2,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
_version的属性值变为2,版本号_version可用于跟踪文档已编入索引的次数。它的主要目的是允许乐观的并发控制,因为可以在索引请求中提供一个版本,如果提供的版本高于索引中的版本,Elasticsearch将只覆盖文档内容,ID值不变,版本号自动添加。
由ID获取文档/索引
简单的做法是想同一个URL发出GET请求,URL的ID部分是强制性的。通过ID从Elasticsearch中检索文档可发出URL的GET请求:http://localhost:9200/索引名/类型名/id。
即:
GET - http://localhost:9200/movies/movie/1
执行结果如下:
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 2,
"_seq_no": 11,
"_primary_term": 1,
"found": true,
"_source": {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": [
"Crime",
"Drama"
]
}
}
正如所看到的,结果对象包含与索引时所看到的类似的元数据,如索引、类型和版本信息。最后最重要的是,它有一个名称_source的属性,它包含实际获取的文档信息。
删除文档
使用与获取索引文档相同的URL,只是将这里的HTTP方法改为DELETE。
DELETE - http://localhost:9200/movies/movie/1
删除后返回的响应信息:
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 1
}
文档搜索
先创建一些索引
PUT - http://localhost:9200/movies/movie/1
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}
PUT - http://localhost:9200/movies/movie/2
{
"title": "Lawrence of Arabia",
"director": "David Lean",
"year": 1962,
"genres": ["Adventure", "Biography", "Drama"]
}
PUT - http://localhost:9200/movies/movie/3
{
"title": "To Kill a Mockingbird",
"director": "Robert Mulligan",
"year": 1962,
"genres": ["Crime", "Drama", "Mystery"]
}
PUT - http://localhost:9200/movies/movie/4
{
"title": "Apocalypse Now",
"director": "Francis Ford Coppola",
"year": 1979,
"genres": ["Drama", "War"]
}
PUT - http://localhost:9200/movies/movie/5
{
"title": "Kill Bill: Vol. 1",
"director": "Quentin Tarantino",
"year": 2003,
"genres": ["Action", "Crime", "Thriller"]
}
PUT - http://localhost:9200/movies/movie/6
{
"title": "The Assassination of Jesse James by the Coward Robert Ford",
"director": "Andrew Dominik",
"year": 2007,
"genres": ["Biography", "Crime", "Drama"]
}
使用PUT请求这些接口,并发送对应的数据,这样就创建好了一些索引。
_search端点
使用_search端点,可选择使用索引和类型,按照这种格式:http://localhost:9200/索引/类型/_search请求数据。其中index和type都是可选的。
换句话说,可以使用一下任一URL进行POST请求:
- http://localhost:9200/_search - 搜索所有索引和类型的文档。
- http://localhost:9200/movies/_search - 在movies索引中搜索所有类型的文档。
- http://localhost:9200/movies/movie/_search - 在movies索引中显式搜索movie类型的文档。
搜索请求正文和Elasticsearch查询DSL
使用上面的URL,发送json类型的参数中,包含一个名为query的属性,这就是使用Elasticsearch的查询DSL。例:
{
"query":{
//Query DSL here
}
}
DSL是Elasticsearch基于JSON的域特定语言,可以在其中表达查询和过滤器。
基本自由文本搜索
查询DSL具有一长列不同类型的查询可以使用。 对于“普通”自由文本搜索,最有可能使用一个名称为“字符串查询”。
字符串查询是一个高级查询,有很多不同的选项,Elasticsearch将解析和转换为更简单的查询树。如果忽略了所有的可选参数,并且只需要给它一个字符串用于搜索,它可以很容易使用。
现在尝试在我们添加的数据中搜索有 “kill” 这个词的信息:
POST - http://localhost:9200/movies/movie/_search
{
"query":{
"query_string":{
"query":"kill"
}
}
}
返回两个命中结果,每个结果中title中都带有 “kill” 单词。
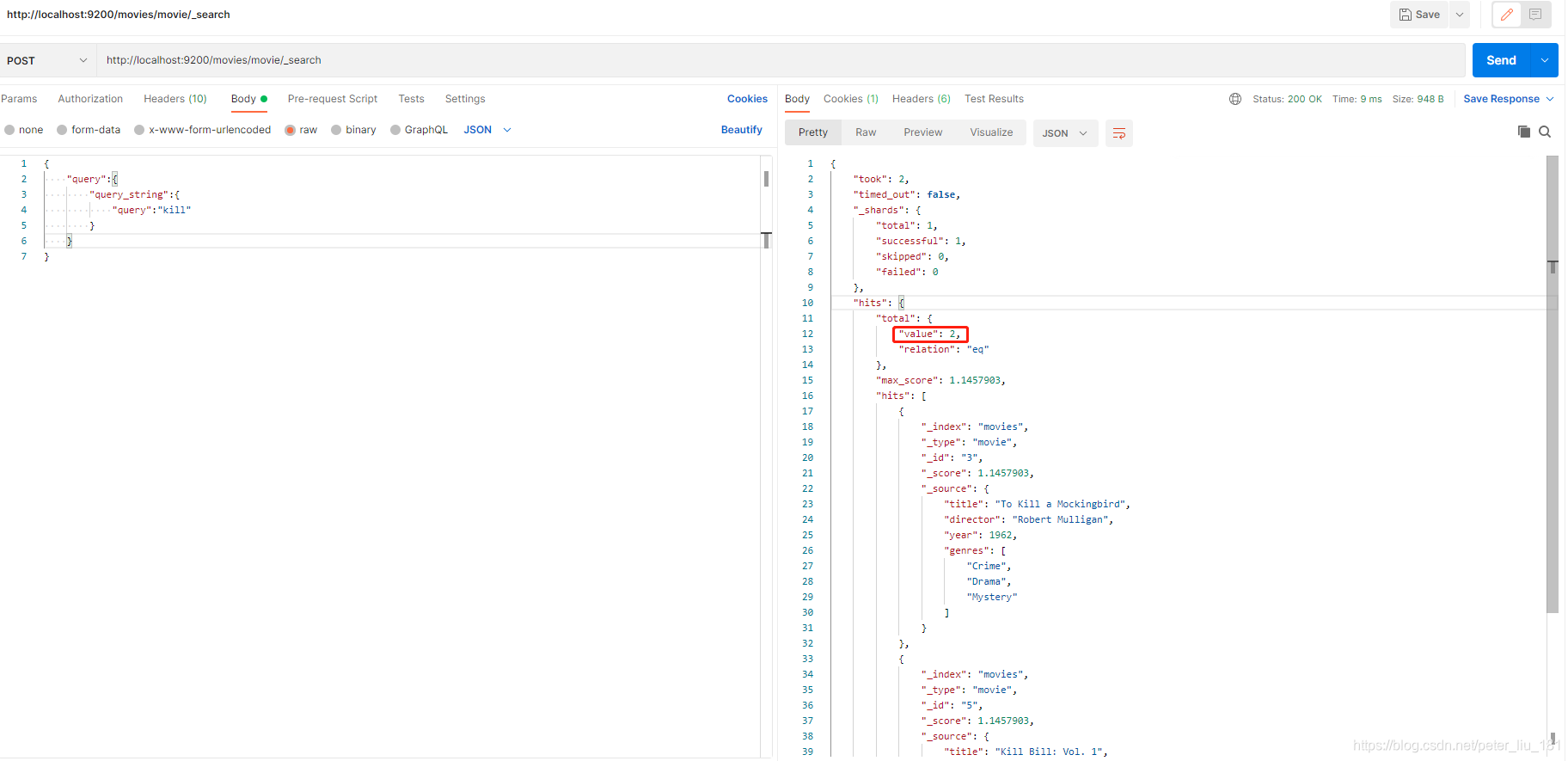
指定搜索的字段
在前面的例子中,使用了一个非常简单的查询,只有一个属性“query”的字符串查询。字符串查询有一些可以指定设置,如果不使用,它将会使用默认设置。
我们设置“fields”,可以用于指定要搜索的字段列表。如果不使用“fields”字段,Elasticsearch查询将默认自动生成名为“_all”的特殊字段,来基于所有文档中的各个字段匹配搜索。
POST - http://localhost:9200/movies/movie/_search
{
"query":{
"query_string":{
"query":"ford",
"fields":["title"]
}
}
}
返回结果只命中一条数据

过滤
现在来看另一种示例,搜索“drama”,不明确指定字段:
POST - http://localhost:9200/movies/movie/_search
{
"query":{
"query_string":{
"query":"drama"
}
}
}
执行这个请求,返回5条数据:

如果我们想要限制year为1962。这时我们需要一个过滤器,要求year字段等于1962。
过滤器的添加方法为:
{
"query":{
"bool":{
"must":{
"query_string":{
"query":"drama"
}
},
"filter":{
//Filter to apply to the query
}
}
}
}
所以查询year为1962的数据请求方式为:
POST - http://localhost:9200/movies/movie/_search
{
"query":{
"bool":{
"must":{
"query_string":{
"query":"drama"
}
},
"filter":{
"term":{
"year":1962
}
}
}
}
}
当执行上面请求,只得到两个命中,这个两个命中的数据的 year字段的值都是等于 1962。
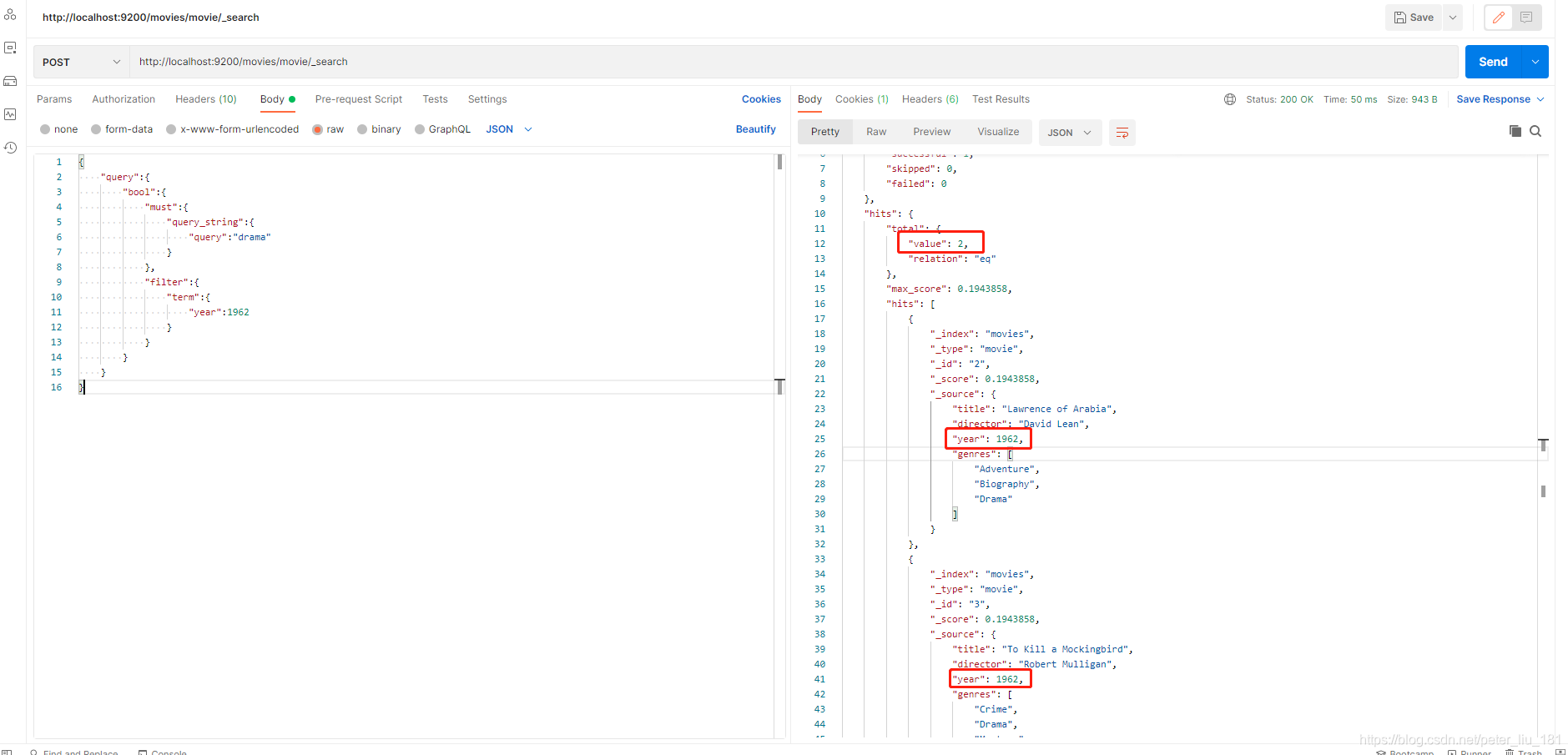
无需查询即可进行过滤
在上面的示例中,使用过滤器限制字符串查询的结果。如果想要做的是应用一个过滤器呢? 也就是说,我们希望所有的数据符合一定的标准。
在这种情况下,我们仍然在搜索请求正文中使用“query”属性。但是,我们不能只是添加一个过滤器,需要将它包装在某种查询中。
一个解决方案是修改当前的搜索请求,替换查询字符串 query 过滤查询中的match_all查询,这是一个查询,只是匹配一切。类似下面这个:
POST - http://localhost:9200/movies/movie/_search
{
"query":{
"bool":{
"must":{
"match_all":{
}
},
"filter":{
"term":{
"year":1962
}
}
}
}
}
或是更简单的常数分数查询:
{
"query":{
"constant_score":{
"filter":{
"term":{
"year":1962
}
}
}
}
}
好了,收工!