@Author : Spinach | GHB
@Link : http://blog.csdn.net/bocai8058
����Ŀ¼
ǰ��
Spark��רΪ���ģ���ݴ�������ƵĿ���ͨ�õļ�������,�����ٶȿ졢֧�ֶ����ԡ���ֲ�Ըߵ��ص㡣����ֲ�Ըߵ����־�����Spark�IJ���ʽ�ж���ģʽ,��:����local��Standalone��Apache Mesos��Hadoop YARN�ȵȡ�
ֵ��˵����,������Spark����ʲô����,���Ĵ��붼��һ����,�����������ύjarʱ��,�Cmaster����ָ���IJ�����һ��,����:
# ʹ��spark-submit�ύһ��������ͨ��Spark Standalone��Ⱥ:
./bin/spark-submit
�Cclass org.apache.spark.examples.mainTest
�Cmaster spark://hadoop01:7070
�Cexecutor-memory 512m
�Ctotal-executor-cores 1
~/jars/spark-examples_2.11-2.3.1.jar
# ʹ��spark-submit�ύһ�����߿��õ�YARN��Ⱥ,ʹ��clientģʽ:
./bin/spark-submit
�Cclass org.apache.spark.examples.mainTest
�Cmaster yarn
�Cdeploy-mode client
�Cexecutor-memory 512m
�Ctotal-executor-cores 1
~/jars/spark-examples.jar
# ʹ��spark-submit�ύһ�����߿��õ�YARN��Ⱥ,ʹ��clusterģʽ:
./bin/spark-submit
�Cclass org.apache.spark.examples.mainTest
�Cmaster yarn
�Cdeploy-mode cluster
�Cexecutor-memory 512m
�Ctotal-executor-cores 1
~/jars/spark-examples.jar
����,Spark on YARN�ǹ����л��������õıȽ϶��һ������ģʽ,������Ҫ��Spark on Yarn���ַ�ʽ����ϸͼ�⡣
SparkOnYarn��Ⱥ�ڵ�ֲ�
SparkOnYarn��Ⱥ,��HDFSΪ�ļ��洢ϵͳ,��YARNΪ��Դ��������Դ���佨��Spark��Ⱥ,���弯Ⱥ��3���ڵ�,����1��master�ڵ㡢2��slave�ڵ㡣
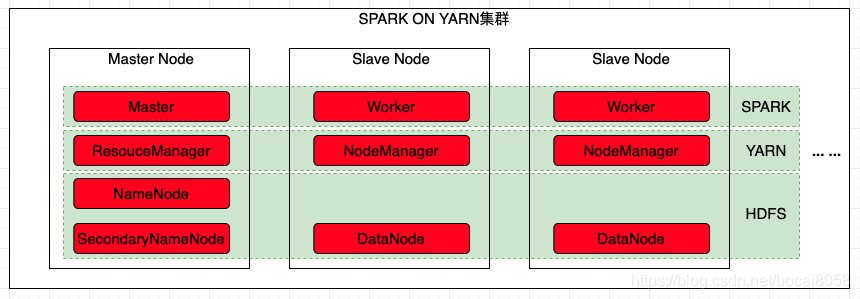
Spark����ģʽ����
Spark����ģ�����̷�����ģʽ:1.Yarn-Clusterģʽ; 2.Yarn-Clientģʽ��
�ڽ���Spark����ģ������֮ǰ,����Ϥһ��Sparkԭ���еĻ��������ϵ��,�ο���Spark Master\Worker��Driver\Executor��Job\Stage\Task�ȸ������ϵ����
Yarn-Clusterģʽ��
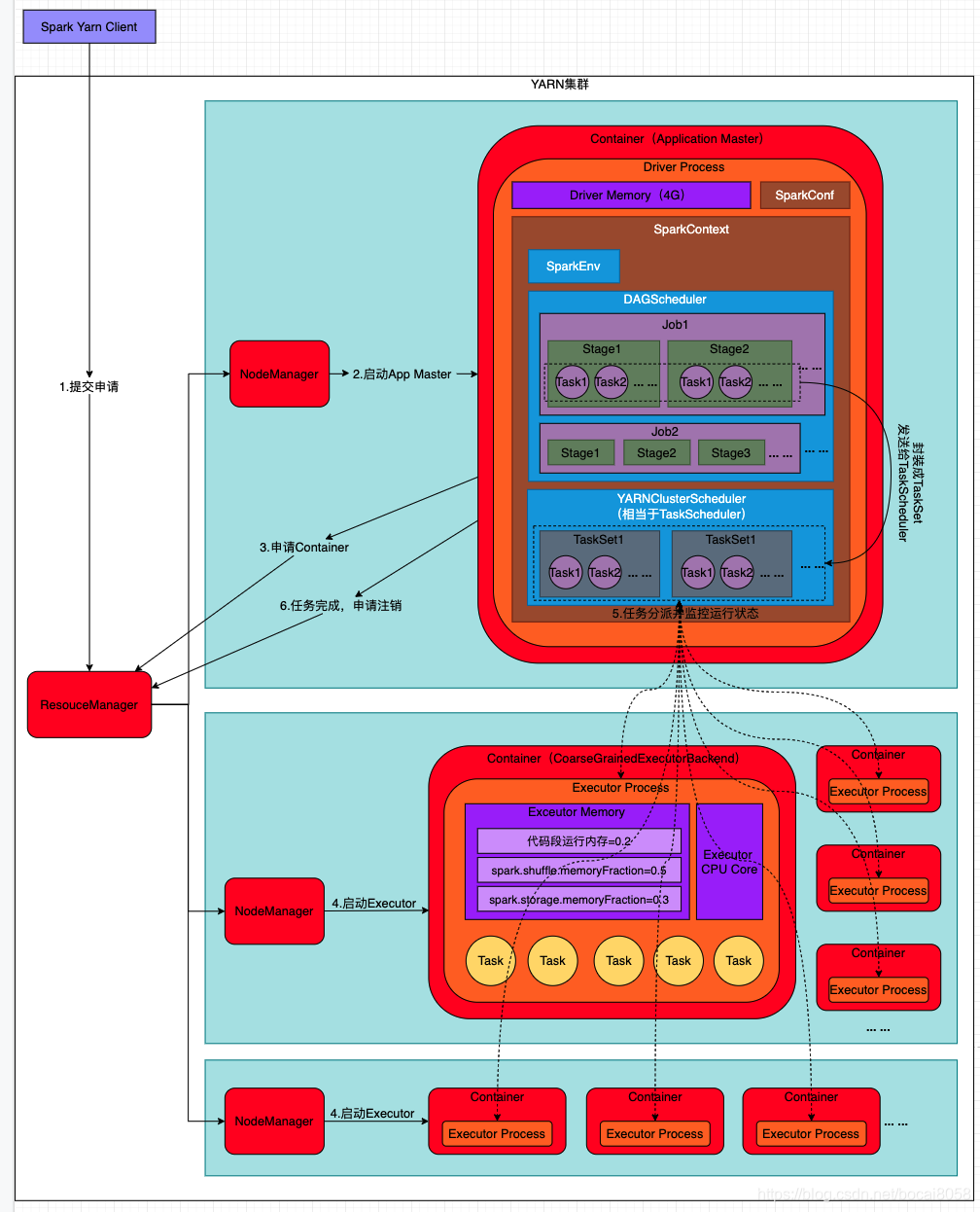
��YARN-Clusterģʽ��,���û���YARN���ύһ��Ӧ�ó����,YARN�������������и�Ӧ�ó���:
��һ�����ǰ�Spark��Driver��Ϊһ��ApplicationMaster��YARN��Ⱥ��������;
�ڶ���������ApplicationMaster����Ӧ�ó���,Ȼ��Ϊ����ResourceManager������Դ,������Executor������Task,ͬʱ��������������й���,ֱ���������
����˵������:
- Spark Yarn Client��YARN���ύӦ�ó���,����ApplicationMaster��������ApplicationMaster�������Ҫ��Executor�����еij����;
- ResourceManager�յ������,�ڼ�Ⱥ��ѡ��һ��NodeManager,Ϊ��Ӧ�ó�������һ��Container,Ҫ���������Container������Ӧ�ó����ApplicationMaster,����ApplicationMaster����SparkContext�ȵij�ʼ��;
- ApplicationMaster��ResourceManagerע��,�����û�����ֱ��ͨ��ResourceManage�鿴Ӧ�ó��������״̬,Ȼ������������ѯ�ķ�ʽͨ��RPCЭ��Ϊ��������������Դ,��������ǵ�����״ֱ̬�����н���;
- һ��ApplicationMaster���뵽��Դ(Ҳ����Container)��,�����Ӧ��NodeManagerͨ��,Ҫ�����ڻ�õ�Container������CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend���������ApplicationMaster�е�SparkContextע�Ტ����Task����һ���Standaloneģʽһ��,ֻ����SparkContext��Spark Application�г�ʼ��ʱ,ʹ��CoarseGrainedSchedulerBackend���YarnClusterScheduler��������ĵ���,����YarnClusterSchedulerֻ�Ƕ�TaskSchedulerImpl��һ����װ,�����˶�Executor�ĵȴ�����;
- ApplicationMaster�е�SparkContext����Task��CoarseGrainedExecutorBackendִ��,CoarseGrainedExecutorBackend����Task����ApplicationMaster�㱨���е�״̬�ͽ���,����ApplicationMaster��ʱ���ո������������״̬,�Ӷ�����������ʧ��ʱ������������;
- Ӧ�ó���������ɺ�,ApplicationMaster��ResourceManager����ע�����ر��Լ�;
��Ⱥ�ύ��������:
# ʹ��spark-submit�ύһ�����߿��õ�YARN��Ⱥ,ʹ��clusterģʽ:
./bin/spark-submit
�Cclass org.apache.spark.examples.mainTest
�Cmaster yarn
�Cdeploy-mode cluster
�Cexecutor-memory 512m
�Ctotal-executor-cores 1
~/jars/spark-examples.jar
Yarn-Clientģʽ��
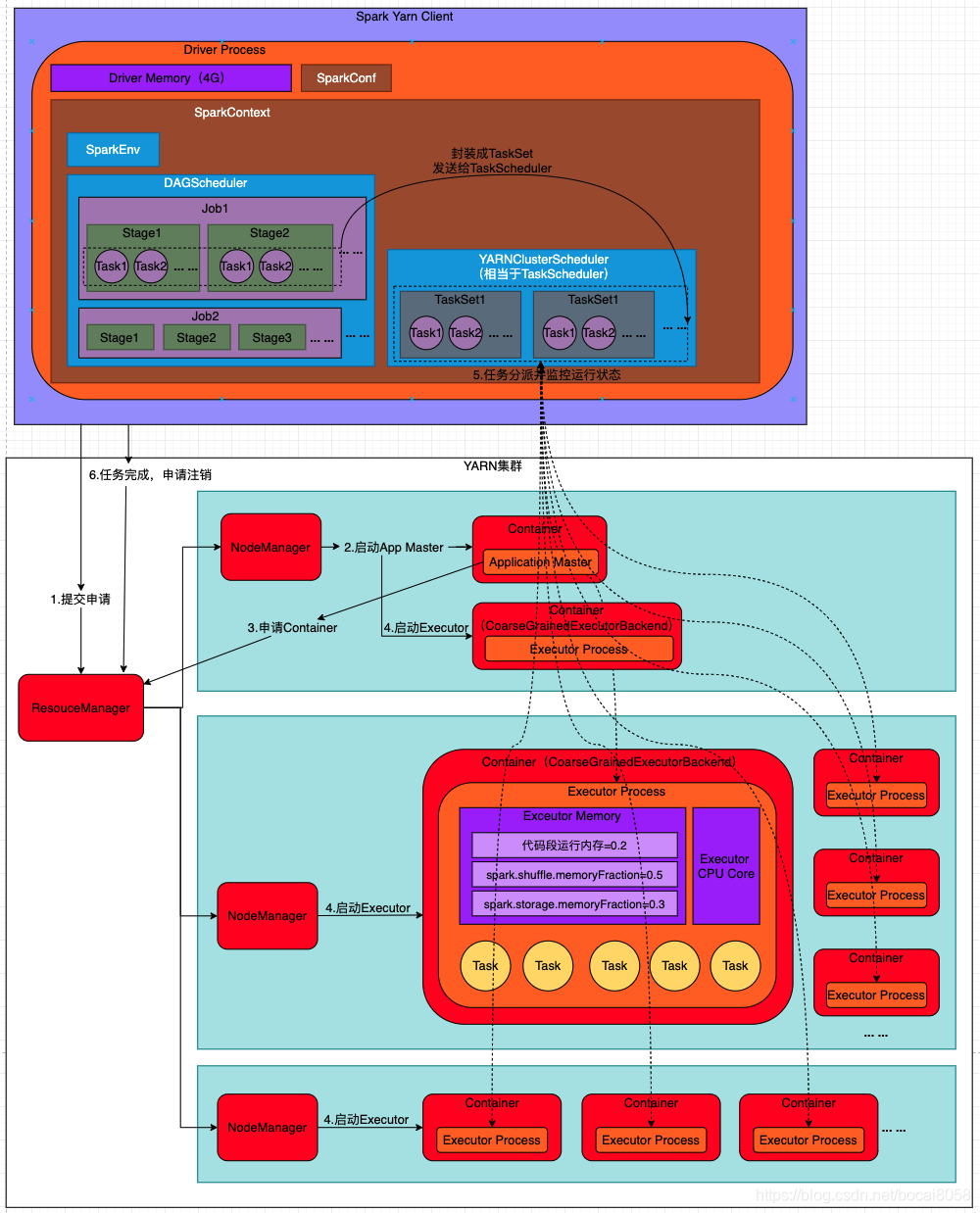
����˵������:
- Spark Yarn Client��YARN��ResourceManager��������Application Master��ͬʱ��SparkContent��ʼ���н�����DAGScheduler��TASKScheduler��SparkEnv�����,����ѡ�����Yarn-Clientģʽ,�����ѡ��YarnClientClusterScheduler��YarnClientSchedulerBackend;
- ResourceManager�յ������,�ڼ�Ⱥ��ѡ��һ��NodeManager,Ϊ��Ӧ�ó�������һ��Container,Ҫ���������Container������Ӧ�ó����ApplicationMaster,��YARN-Cluster��������ڸ�ApplicationMaster������SparkContext,ֻ��SparkContext������ϵ������Դ�ķ���;
- Client�е�SparkContext��ʼ����Ϻ�,��ApplicationMaster����ͨѶ,��ResourceManagerע��,����������Ϣ��ResourceManager������Դ(Container);
- һ��ApplicationMaster���뵽��Դ(Ҳ����Container)��,�����Ӧ��NodeManagerͨ��,Ҫ�����ڻ�õ�Container������CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend���������Client�е�SparkContextע�Ტ����Task;
- Client�е�SparkContext����Task��CoarseGrainedExecutorBackendִ��,CoarseGrainedExecutorBackend����Task����Driver�㱨���е�״̬�ͽ���,����Client��ʱ���ո������������״̬,�Ӷ�����������ʧ��ʱ������������;
- Ӧ�ó���������ɺ�,Client��SparkContext��ResourceManager����ע�����ر��Լ�;
��Ⱥ�ύ��������:
# ʹ��spark-submit�ύһ�����߿��õ�YARN��Ⱥ,ʹ��clientģʽ:
./bin/spark-submit
�Cclass org.apache.spark.examples.mainTest
�Cmaster yarn
�Cdeploy-mode client
�Cexecutor-memory 512m
�Ctotal-executor-cores 1
~/jars/spark-examples.jar
Yarn-Clusterģʽ��Yarn-Clientģʽ����
��YARN��,ÿ��Applicationʵ������һ��ApplicationMaster����,����Application�����ĵ�һ���������������ResourceManager����������Դ,��ȡ��Դ֮�����NodeManagerΪ������Container��
| �Ƚ��� | YARN-Clientģʽ | YARN-Clusterģʽ |
|---|---|---|
| Application Master | Application Master������YARN����Executor,Client��������Containerͨ�����������ǹ��� | Driver������AM(Application Master)��,��������YARN������Դ,���ල��ҵ������״�������û��ύ����ҵ֮��,�Ϳ��Թص�Client,��ҵ�������YARN������ |
| Driver | ������Client�� | ������AM(Application Master)�� |
| client�ر� | �ر�client,�����ֱ�ӽ��� | �ύ��������ֱ�ӹر�client,��Ӱ�켯Ⱥ��������� |
| ʹ�ó��� | �ʺϽ����͵��Ի��� | �ʺ��������� |
| �����־ | ֱ�Ӳ鿴 | yarn logs -applicationId xxxxxx |
| �ŵ� | ���ڵ��ԺͲ鿴�����־ | ����ֱ�ӹر�client,��Ӱ�켯Ⱥ��������� |
| ȱ�� | 1.���ڴ��ڴ���������Driver�ͼ�Ⱥ�н��н���,�������й����в����������������ݴ���,���翪���Ӵ�;2.client����,������� | �����ڽ����Ͳ鿴�����־ |
����:
https://www.cnblogs.com/yy3b2007com/p/10934090.html
https://blog.csdn.net/github_28583061/article/details/106385707
https://blog.csdn.net/qq_37332702/article/details/87944361
https://blog.csdn.net/u012137473/article/details/84965567
https://blog.csdn.net/weixin_35602748/article/details/78724195