简介:?本文由社区志愿者陈政羽整理,内容来源自阿里巴巴高级开发工程师徐榜江 (雪尽) 7 月 10 日在北京站 Flink Meetup 分享的《详解 Flink-CDC》。深入讲解了最新发布的 Flink CDC 2.0.0 版本带来的核心特性,包括:全量数据的并发读取、checkpoint、无锁读取等重大改进。
一、CDC 概述
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛:
- 数据同步:用于备份,容灾;
- 数据分发:一个数据源分发给多个下游系统;
- 数据采集:面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
-
基于查询的 CDC:
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
-
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
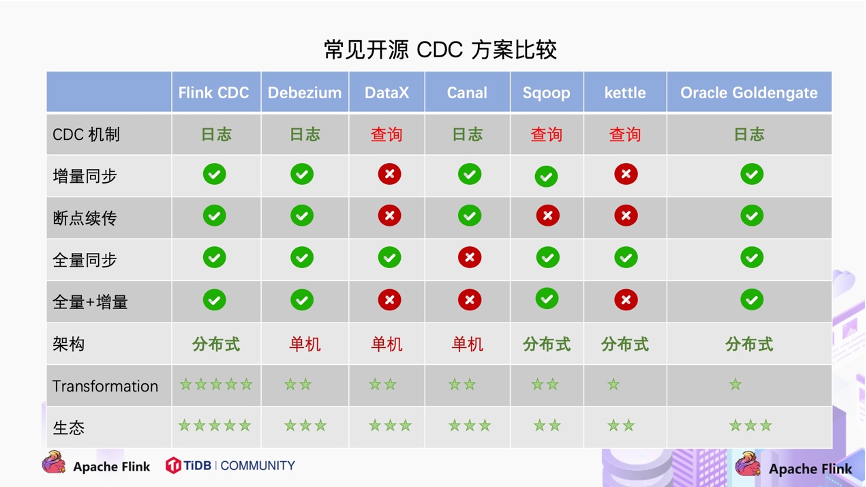
对比常见的开源 CDC 方案,我们可以发现:
-
对比增量同步能力,
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。
- 对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
- 而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
-
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
- 另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
二、Flink CDC 项目
讲到这里,先带大家回顾下开发 Flink CDC 项目的动机。
1. Dynamic Table & ChangeLog Stream
大家都知道 Flink 有两个基础概念:Dynamic Table 和 Changelog Stream。
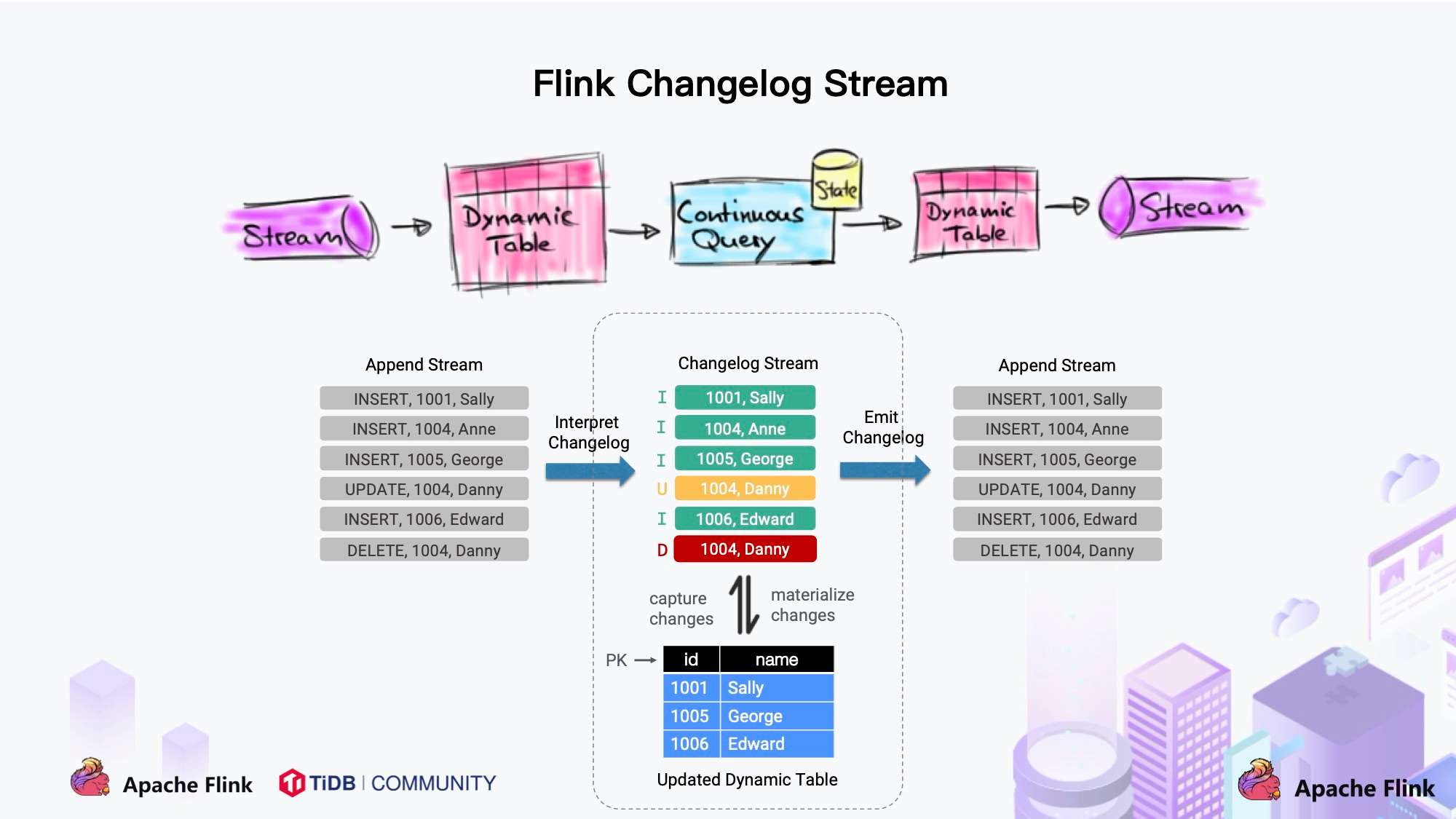
- Dynamic Table 就是 Flink SQL 定义的动态表,动态表和流的概念是对等的。参照上图,流可以转换成动态表,动态表也可以转换成流。
- 在 Flink SQL中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以翻译为一个表,也可以翻译为一个流。
联想下 MySQL 中的表和 binlog 日志,就会发现:MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。

在此基础上,我们调研了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能。
将 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构进行对比,可以发现两者是非常相似的。
- 每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致。
- 而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
通过分析两种数据结构,Flink 和 Debezium 两者的底层数据是可以非常方便地对接起来的,大家可以发现 Flink 做 CDC 从技术上是非常合适的。
2. 传统 CDC ETL 分析
我们来看下传统 CDC 的 ETL 分析链路,如下图所示:
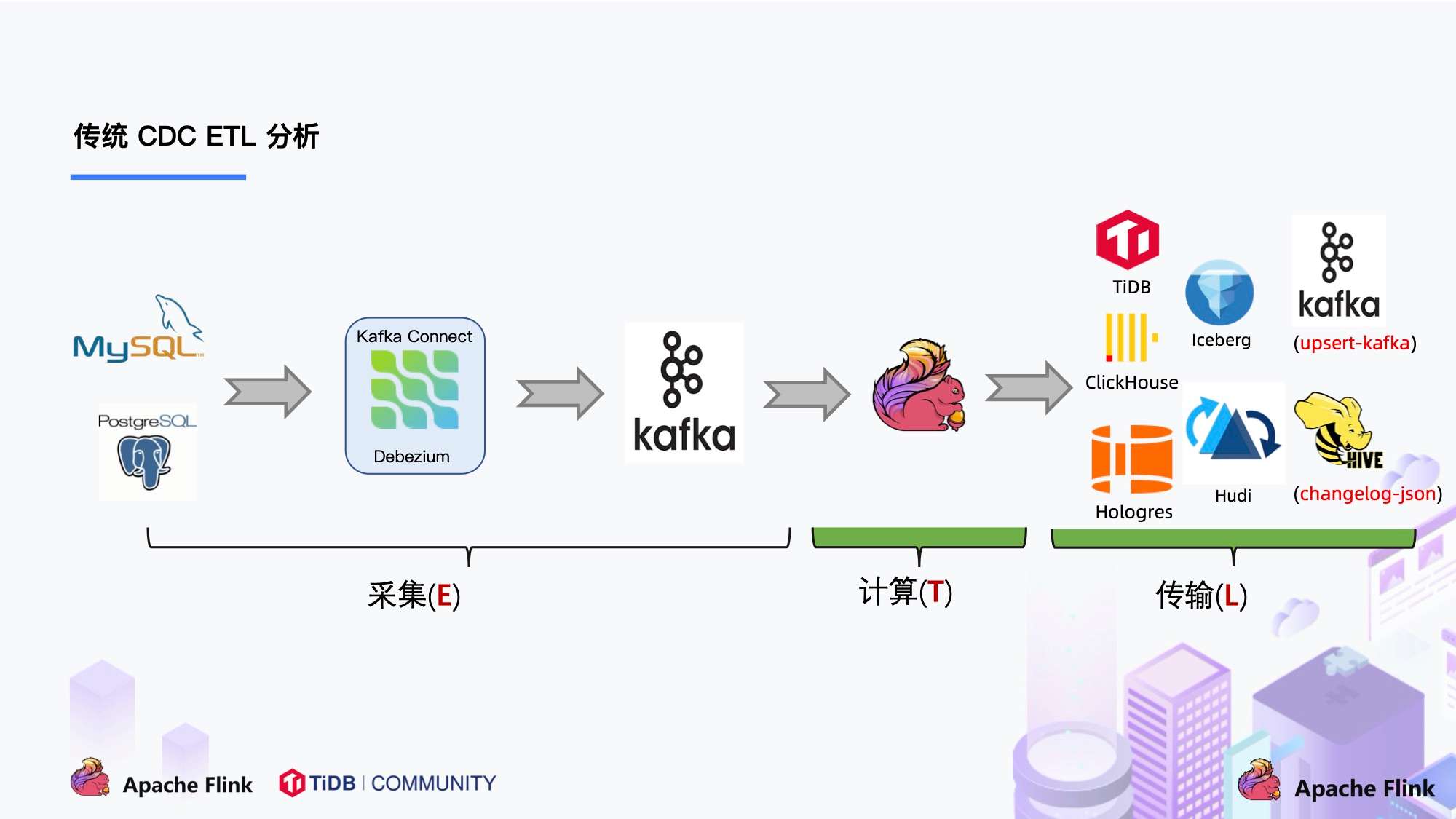
传统的基于 CDC 的 ETL 分析中,数据采集工具是必须的,国外用户常用 Debezium,国内用户常用阿里开源的 Canal,采集工具负责采集数据库的增量数据,一些采集工具也支持同步全量数据。采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这一部分数据写入到目的端,目的端可以是各种 DB,数据湖,实时数仓和离线数仓。
注意,Flink 提供了 changelog-json format,可以将 changelog 数据写入离线数仓如 Hive / HDFS;对于实时数仓,Flink 支持将 changelog 通过 upsert-kafka connector 直接写入 Kafka。
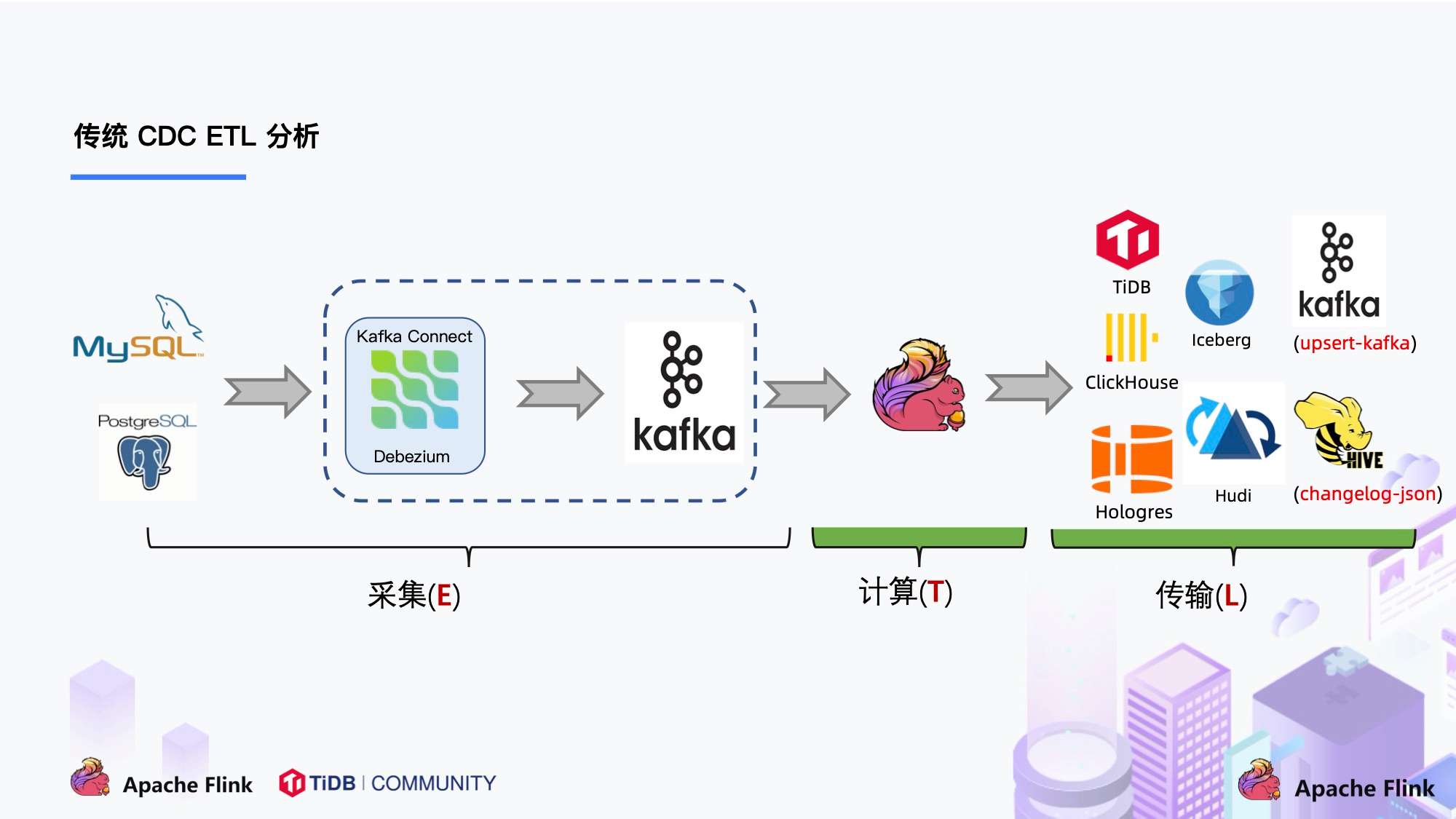
我们一直在思考是否可以使用 Flink CDC 去替换上图中虚线框内的采集组件和消息队列,从而简化分析链路,降低维护成本。同时更少的组件也意味着数据时效性能够进一步提高。答案是可以的,于是就有了我们基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
在使用了 Flink CDC 之后,除了组件更少,维护更方便外,另一个优势是通过 Flink SQL 极大地降低了用户使用门槛,可以看下面的例子:
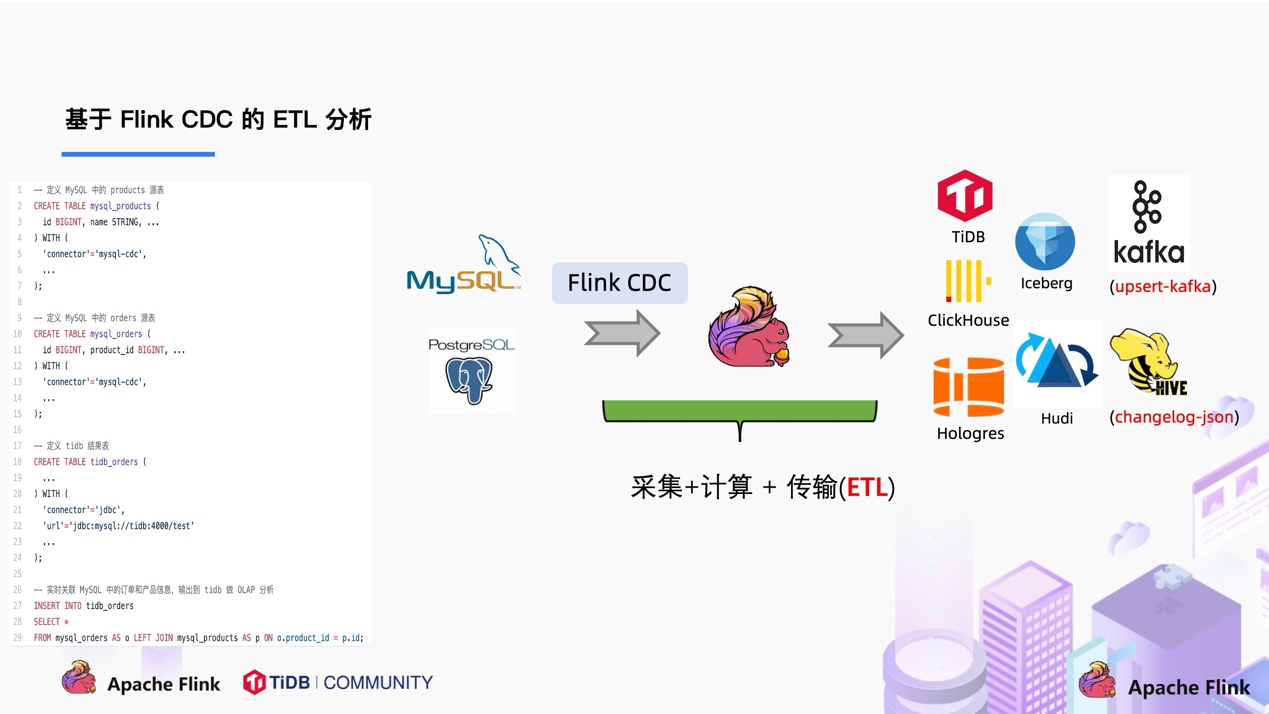
该例子是通过 Flink CDC 去同步数据库数据并写入到 TiDB,用户直接使用 Flink SQL 创建了产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
大家会发现这是一个纯 SQL 作业,这意味着只要会 SQL 的 BI,业务线同学都可以完成此类工作。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析、聚合。
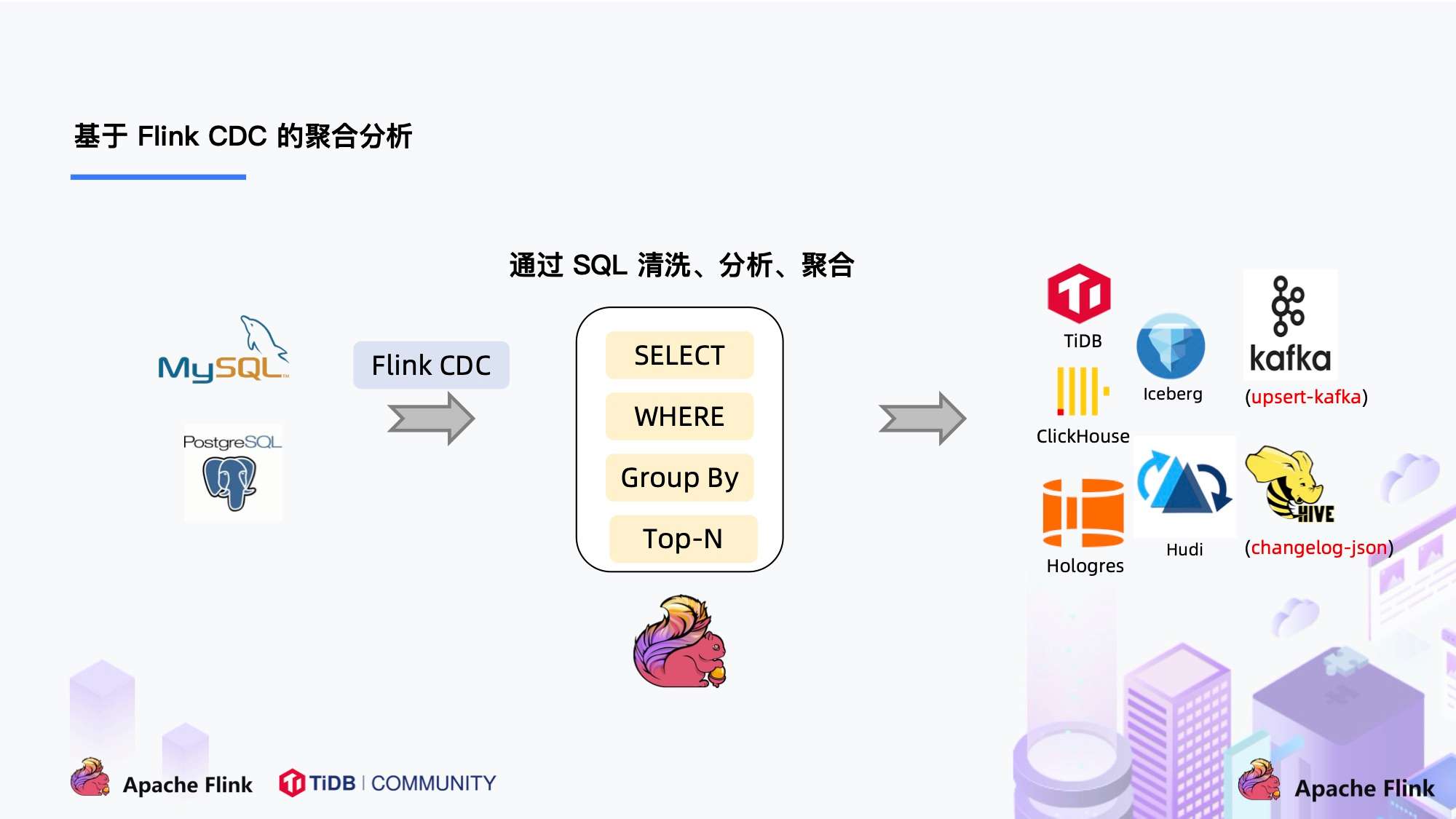
而这些能力,对于现有的 CDC 方案来说,进行数据的清洗,分析和聚合是非常困难的。
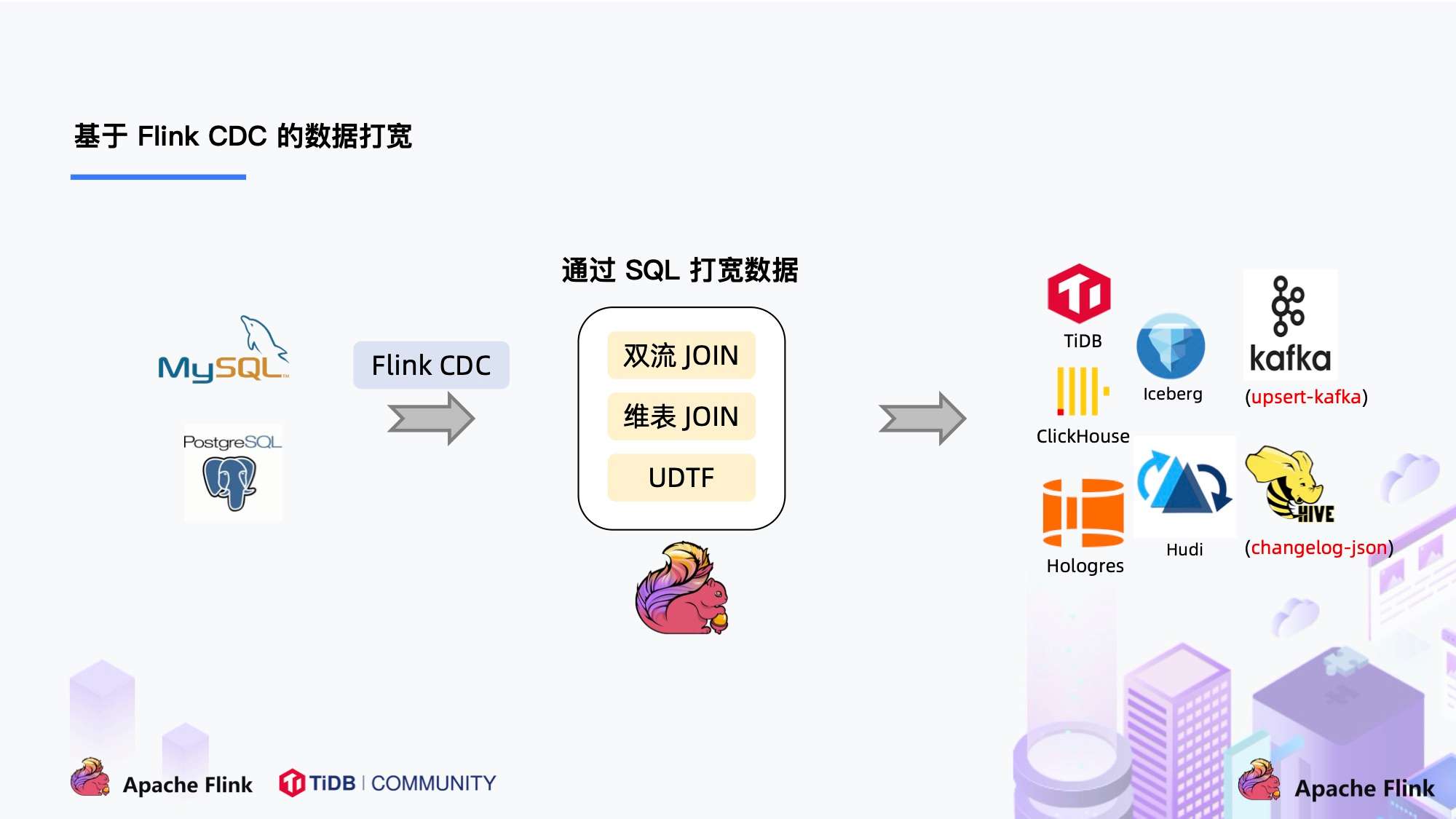
此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以非常容易地完成数据打宽,以及各种业务逻辑加工。
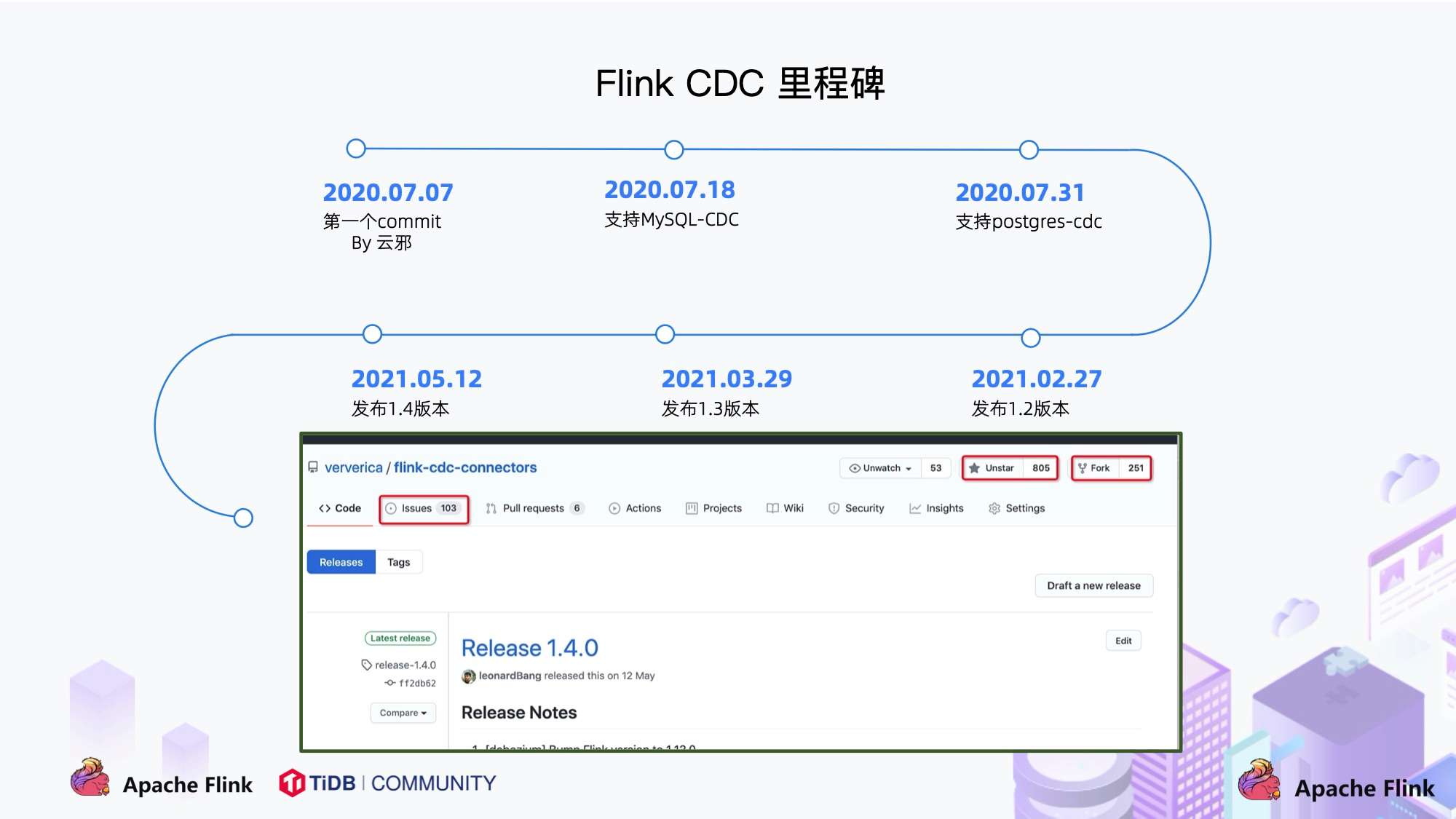
4. Flink CDC 项目发展
- 2020 年 7 月由云邪提交了第一个 commit,这是基于个人兴趣孵化的项目;
- 2020 年 7 中旬支持了 MySQL-CDC;
- 2020 年 7 月末支持了 Postgres-CDC;
- 一年的时间,该项目在 GitHub 上的 star 数已经超过 800。
三、Flink CDC 2.0 详解
1. Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多也是最重要的 Connector,本文下述章节描述 Flink CDC Connector 均为 MySQL CDC Connector。
随着 Flink CDC 项目的发展,得到了很多用户在社区的反馈,主要归纳为三个:

- 全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
- 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
- 全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
2. Debezium 锁分析
Flink CDC 底层封装了 Debezium, Debezium 同步一张表分为两个阶段:
- 全量阶段:查询当前表中所有记录;
- 增量阶段:从 binlog 消费变更数据。
大部分用户使用的场景都是全量 + 增量同步,加锁是发生在全量阶段,目的是为了确定全量阶段的初始位点,保证增量 + 全量实现一条不多,一条不少,从而保证数据一致性。从下图中我们可以分析全局锁和表锁的一些加锁流程,左边红色线条是锁的生命周期,右边是 MySQL 开启可重复读事务的生命周期。
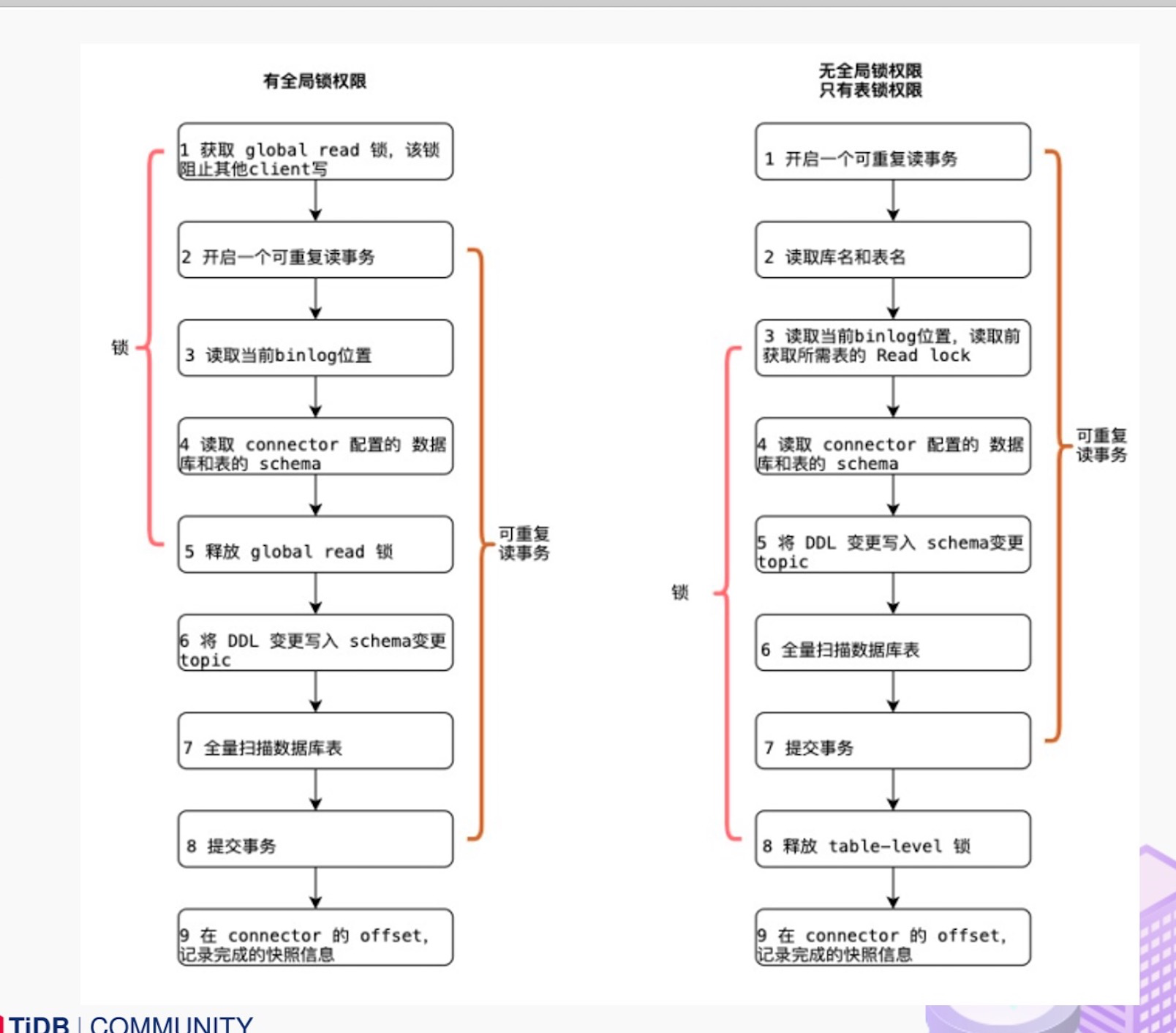
以全局锁为例,首先是获取一个锁,然后再去开启可重复读的事务。这里锁住操作是读取 binlog 的起始位置和当前表的 schema。这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 是可以对应上的,因为表的 schema 是会改变的,比如如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动 BinlogReader 从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户只有表锁。表锁锁的时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。
经过上面分析,接下来看看这些锁到底会造成怎样严重的后果:

Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述 hang 住数据的风险。
3. Flink CDC 2.0 设计 ( 以 MySQL 为例)
通过上面的分析,可以知道 2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展、checkpoint。

DBlog 这篇论文里描述的无锁算法如下图所示:
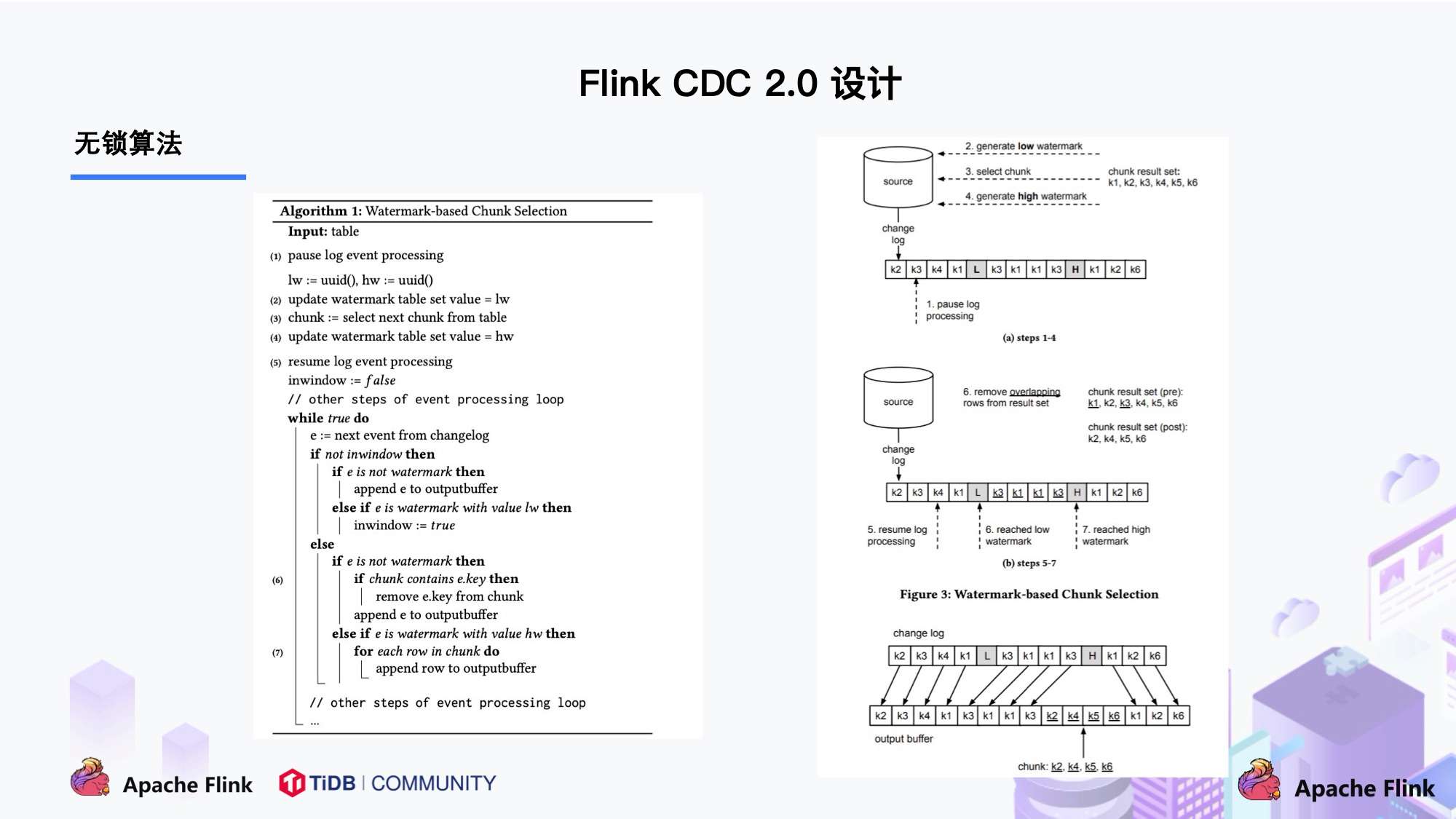
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。Chunk 的切分如下图所示:
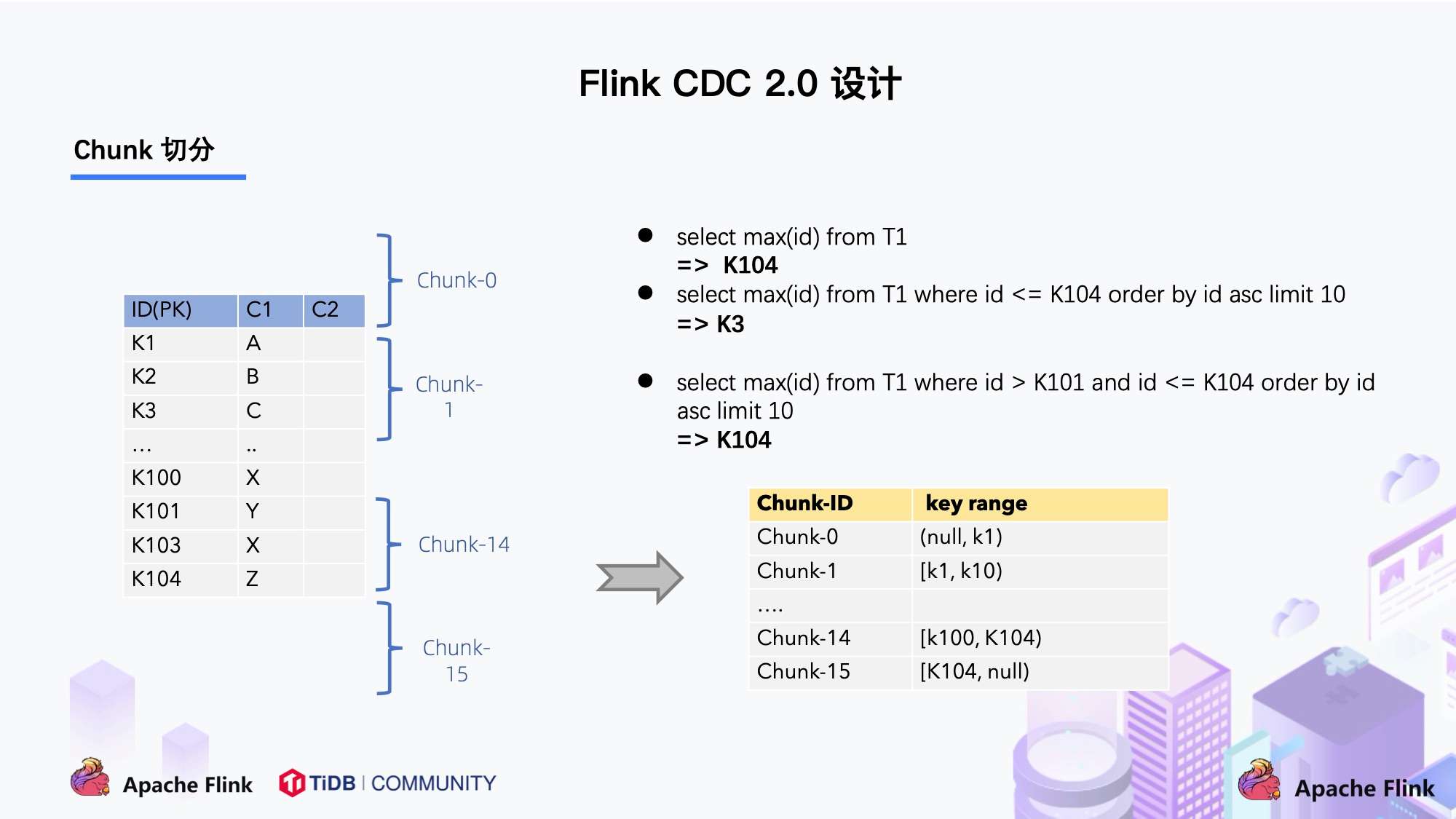
因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
Netflix 的 DBLog 论文中 Chunk 读取算法是通过在 DB 维护一张信号表,再通过信号表在 binlog 文件中打点,记录每个 chunk 读取前的 Low Position (低位点) 和读取结束之后 High Position (高位点) ,在低位点和高位点之间去查询该 Chunk 的全量数据。在读取出这一部分 Chunk 的数据之后,再将这 2 个位点之间的 binlog 增量数据合并到 chunk 所属的全量数据,从而得到高位点时刻,该 chunk 对应的全量数据。
Flink CDC 结合自身的情况,在 Chunk 读取算法上做了去信号表的改进,不需要额外维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能,整体的 chunk 读算法描述如下图所示:
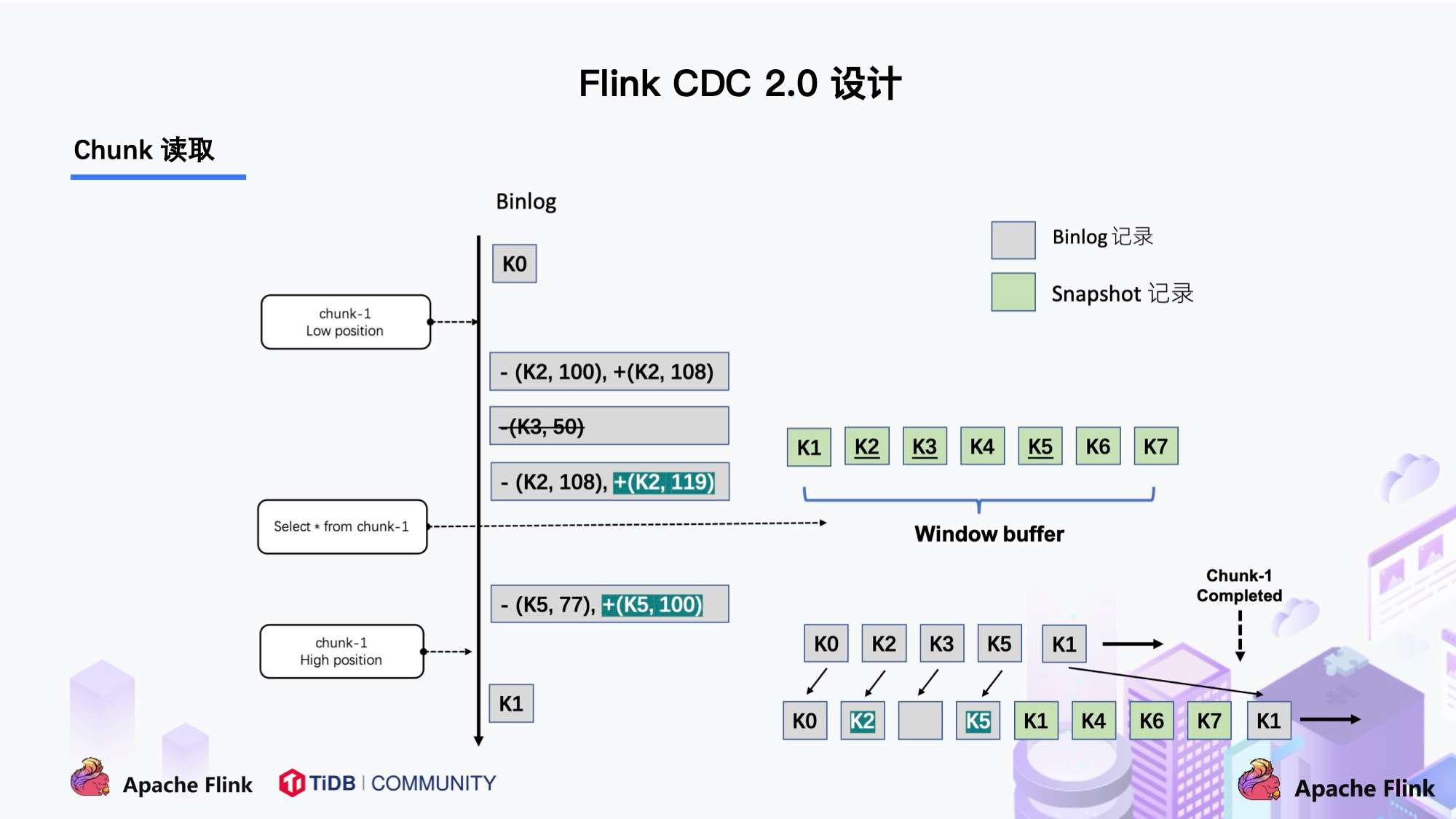
比如正在读取 Chunk-1,Chunk 的区间是 [K1, K10],首先直接将该区间内的数据 select 出来并把它存在 buffer 中,在 select 之前记录 binlog 的一个位点 (低位点),select 完成后记录 binlog 的一个位点 (高位点)。然后开始增量部分,消费从低位点到高位点的 binlog。
- 图中的 - ( k2,100 ) + ( k2,108 ) 记录表示这条数据的值从 100 更新到 108;
- 第二条记录是删除 k3;
- 第三条记录是更新 k2 为 119;
- 第四条记录是 k5 的数据由原来的 77 变更为 100。
观察图片中右下角最终的输出,会发现在消费该 chunk 的 binlog 时,出现的 key 是k2、k3、k5,我们前往 buffer 将这些 key 做标记。
- 对于 k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
- 对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是 119 ,那么只需要输出 +(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是在高位点是 chunk 中最新的数据。
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?
这个就是基于 FLIP-27 来优雅地实现的,通过下图可以看到有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。
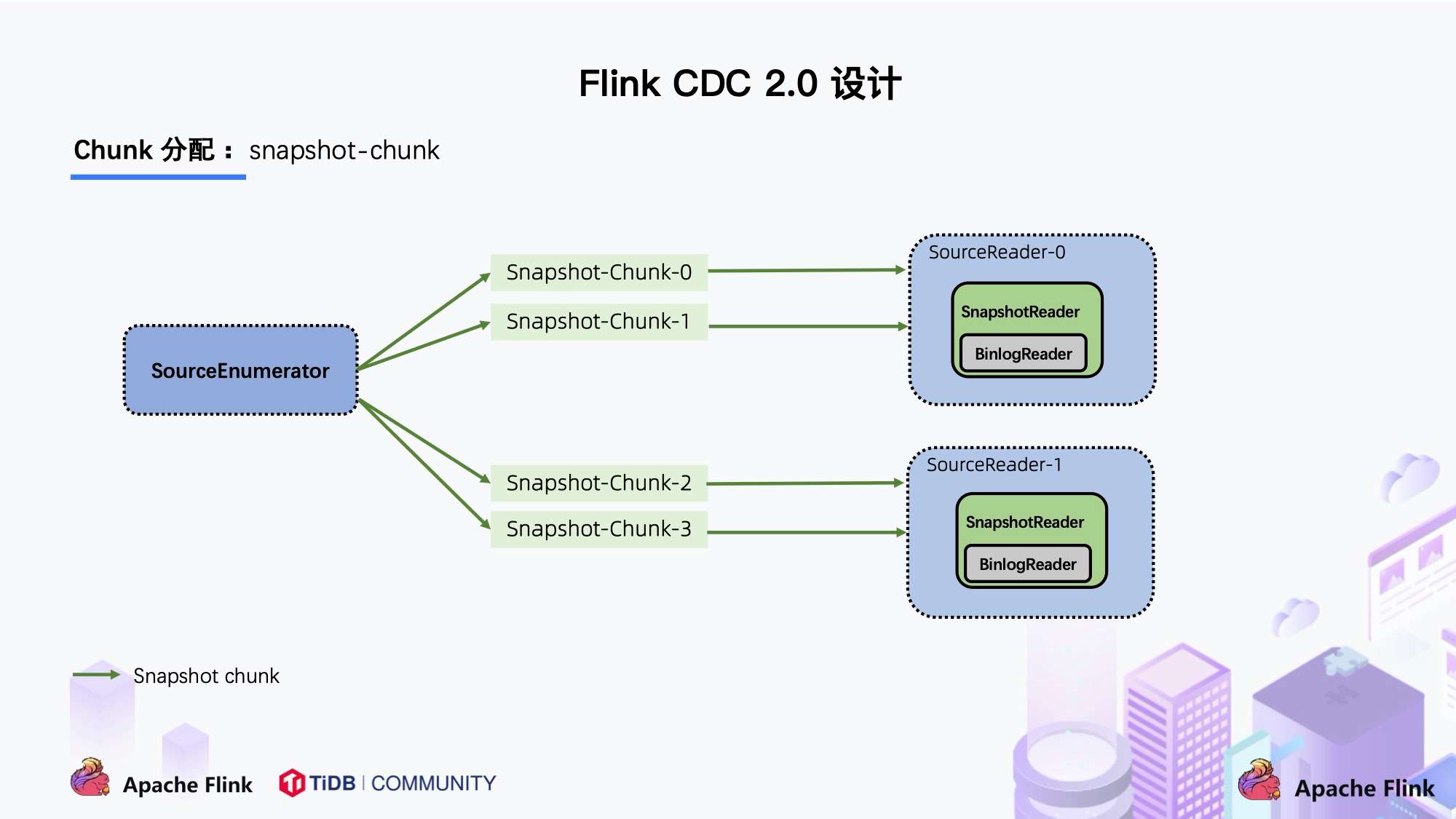
当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。
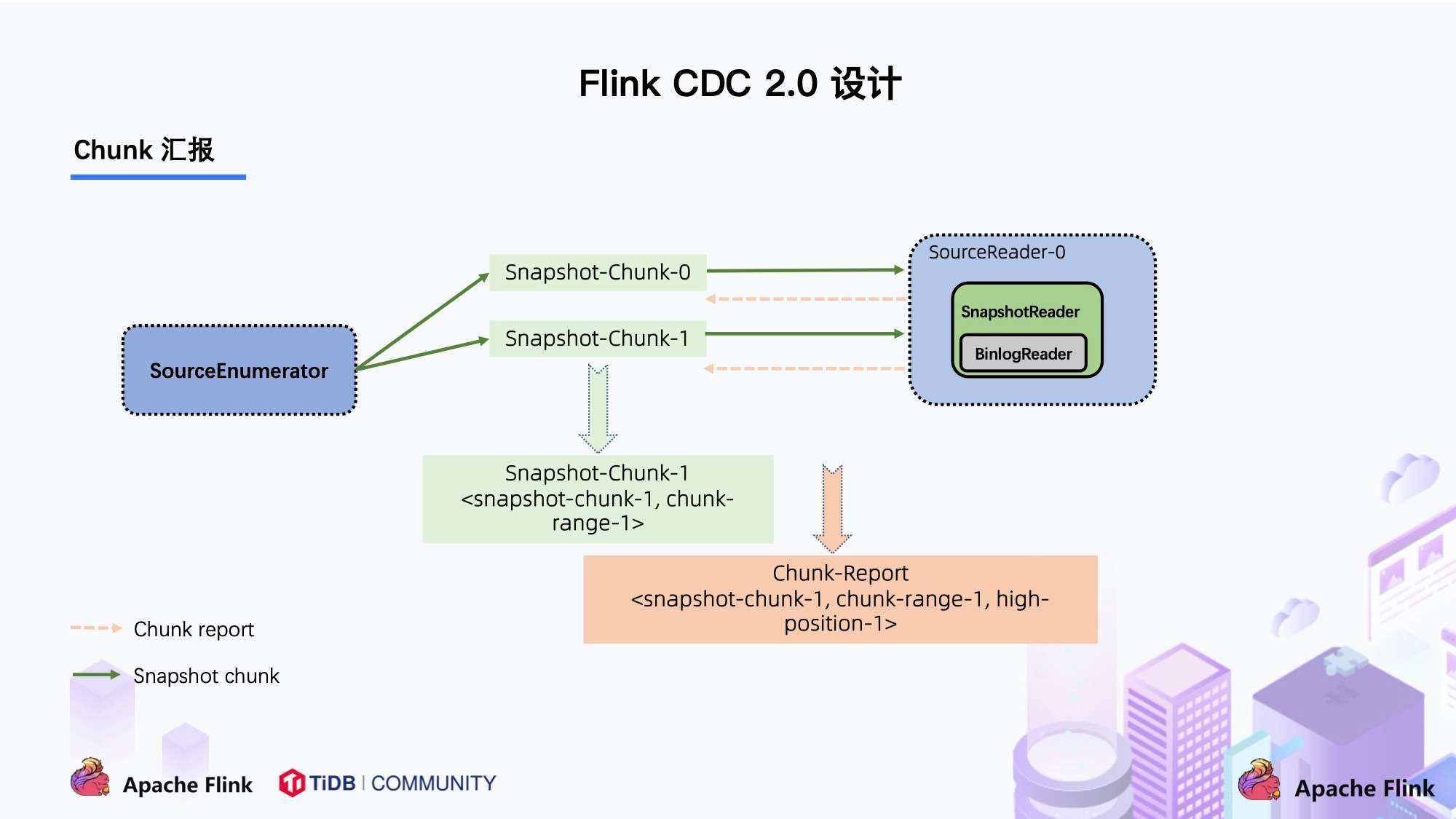
汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。
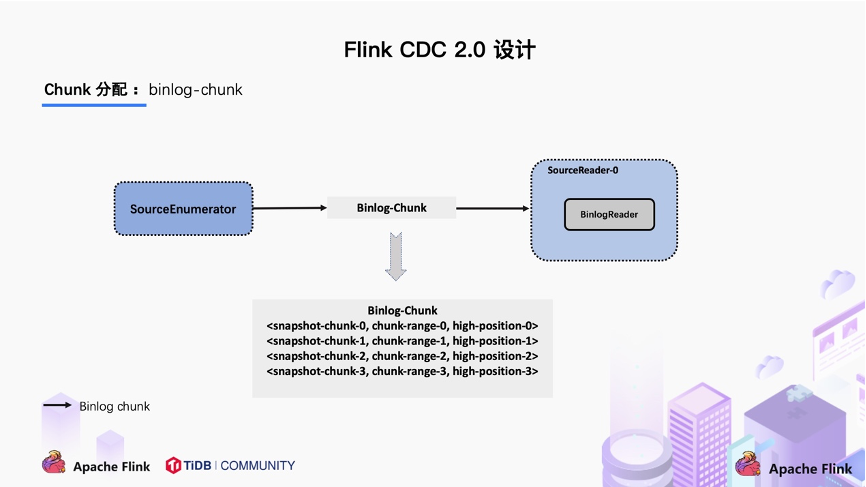
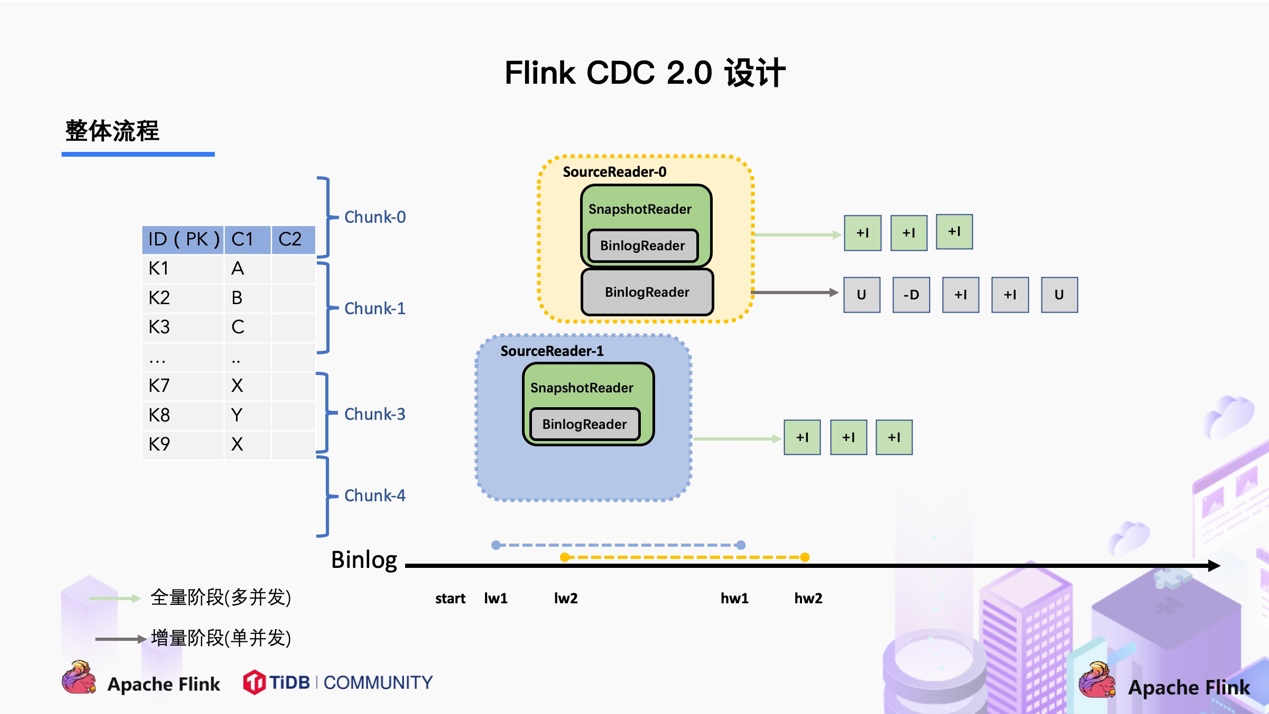
对于大部分用户来讲,其实无需过于关注如何无锁算法和分片的细节,了解整体的流程就好。
整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:
Flink CDC 是一个完全开源的项目,项目所有设计和源码目前都已贡献到开源社区,Flink CDC 2.0?也已经正式发布,此次的核心改进和提升包括:
-
提供 MySQL CDC 2.0,核心feature 包括
- 并发读取,全量数据的读取性能可以水平扩展;
- 全程无锁,不对线上业务产生锁的风险;
- 断点续传,支持全量阶段的 checkpoint。
- 搭建文档网站,提供多版本文档支持,文档支持关键词搜索
笔者用 TPC-DS 数据集中的 customer 表进行了测试,Flink 版本是 1.13.1,customer 表的数据量是 6500 万条,Source 并发为 8,全量读取阶段:
- MySQL CDC 2.0 用时?13?分钟;
- MySQL CDC 1.4 用时?89?分钟;
- 读取性能提升?6.8?倍。
为了提供更好的文档支持,Flink CDC 社区搭建了文档网站,网站支持对文档的版本管理:
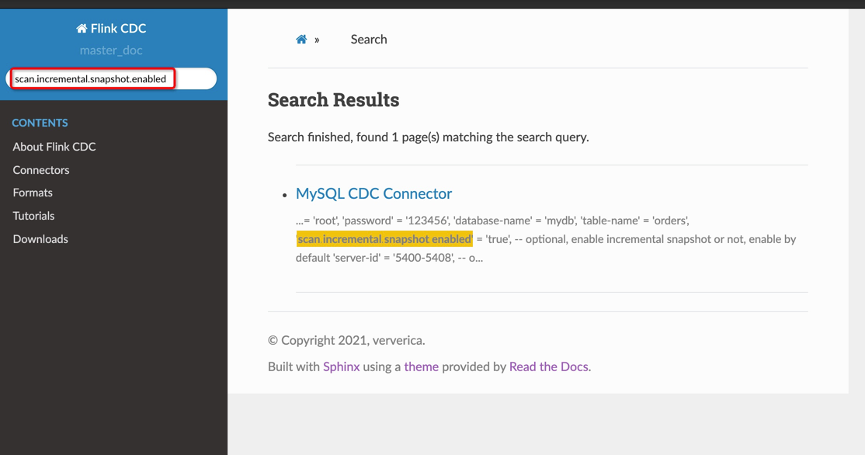
文档网站支持关键字搜索功能,非常实用:
四、未来规划
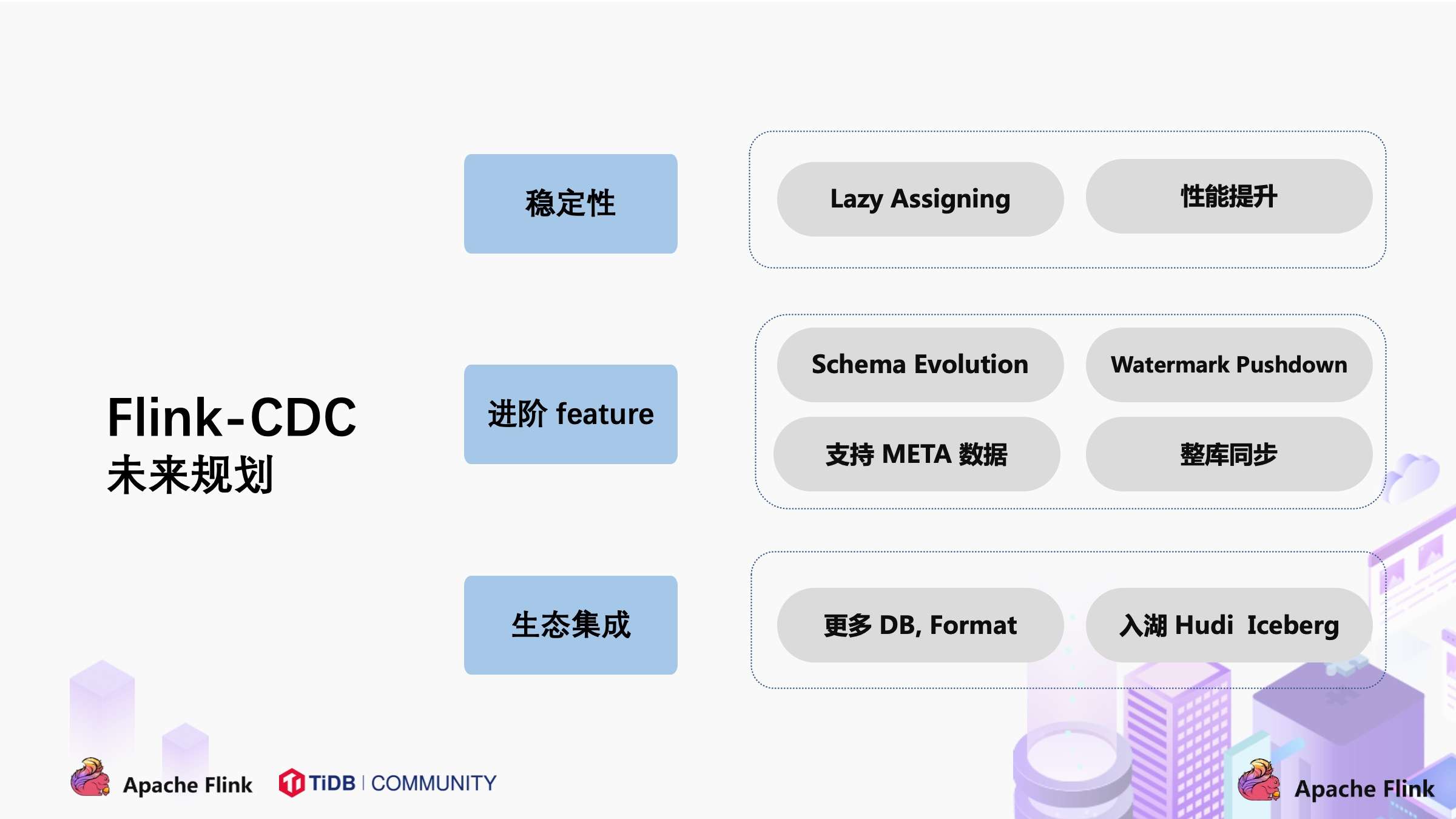
关于 CDC 项目的未来规划,我们希望围绕稳定性,进阶 feature 和生态集成三个方面展开。
-
稳定性
- 通过社区的方式吸引更多的开发者,公司的开源力量提升 Flink CDC 的成熟度;
- 支持 Lazy Assigning。Lazy Assigning 的思路是将 chunk 先划分一批,而不是一次性进行全部划分。当前 Source Reader 对数据读取进行分片是一次性全部划分好所有 chunk,例如有 1 万个 chunk,可以先划分 1 千个 chunk,而不是一次性全部划分,在 SourceReader 读取完 1 千 chunk 后再继续划分,节约划分 chunk 的时间。
-
进阶 Feature
- 支持 Schema Evolution。这个场景是:当同步数据库的过程中,突然在表中添加了一个字段,并且希望后续同步下游系统的时候能够自动加入这个字段;
- 支持 Watermark Pushdown 通过 CDC 的 binlog 获取到一些心跳信息,这些心跳的信息可以作为一个 Watermark,通过这个心跳信息可以知道到这个流当前消费的一些进度;
- 支持 META 数据,分库分表的场景下,有可能需要元数据知道这条数据来源哪个库哪个表,在下游系统入湖入仓可以有更多的灵活操作;
- 整库同步:用户要同步整个数据库只需一行 SQL 语法即可完成,而不用每张表定义一个 DDL 和 query。
-
生态集成
- 集成更多上游数据库,如 Oracle,MS SqlServer。Cloudera 目前正在积极贡献 oracle-cdc connector;
- 在入湖层面,Hudi 和 Iceberg 写入上有一定的优化空间,例如在高 QPS 入湖的时候,数据分布有比较大的性能影响,这一点可以通过与生态打通和集成继续优化。
原文链接
本文为阿里云原创内容,未经允许不得转载。?