Standalone和Yarn模式任选一种即可
1. 安装规划
- 每台服务器相互设置ssh无密码登录,注意authorized_keys权限为600
| 服务名 | 安装服务器 | 服务作用 | 安装教程 | 备注 |
|---|---|---|---|---|
| java8 | bigdata001/2/3 | |||
| zookeeper | bigdata001/2/3 | 基于Centos7分布式安装Zookeeper3.6.3 | ||
| hadoop | bigdata001/2/3 | Centos7上Hadoop 3.3.1的高可用HA安装过程 |
2. 下载解压(在bigdata001操作)
[root@bigdata001 opt]#
[root@bigdata001 opt]# wget https://mirror.novg.net/apache/flink/flink-1.13.2/flink-1.13.2-bin-scala_2.11.tgz
[root@bigdata001 opt]#
[root@bigdata001 opt]# tar -zxvf flink-1.13.2-bin-scala_2.11.tgz
[root@bigdata001 opt]#
[root@bigdata001 opt]# cd flink-1.13.2
[root@bigdata001 flink-1.13.2]#
3. Standalone模式
3.1 修改conf/flink-conf.yaml(在bigdata001操作)
新增目录
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# pwd
/opt/flink-1.13.2
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# mkdir web_upload_dir
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# mkdir io_tmp_dir
[root@bigdata001 flink-1.13.2]#
修改部分
rest.address: bigdata001
jobmanager.memory.process.size: 2g
taskmanager.memory.process.size: 6g
taskmanager.numberOfTaskSlots: 2
state.backend: rocksdb
state.checkpoints.dir: hdfs://nnha/flink/checkpoints/rocksdb
state.savepoints.dir: hdfs://nnha/flink/savepoints/rocksdb
io.tmp.dirs: /opt/flink-1.13.2/io_tmp_dir
high-availability: zookeeper
high-availability.zookeeper.quorum: bigdata001:2181,bigdata002:2181,bigdata003:2181
high-availability.storageDir: hdfs://nnha/flink/ha/recovery/
添加部分
env.java.home: /opt/jdk1.8.0_201
execution.checkpointing.interval: 300000
web.upload.dir: /opt/flink-1.13.2/web_upload_dir
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /ha_cluster
3.2 修改conf/masters和conf/workers(在bigdata001操作)
bigdata001:8081
bigdata002:8081
bigdata003:8081
bigdata001
bigdata002
bigdata003
3.3 依赖jar包的添加和环境变量的添加(在bigdata001操作)
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# pwd
/opt/flink-1.13.2
[root@bigdata001 flink-1.13.2]# mv lib/flink-shaded-zookeeper-3.4.14.jar opt/
[root@bigdata001 flink-1.13.2]# mv opt/flink-shaded-zookeeper-3.5.6.jar lib/
[root@bigdata001 flink-1.13.2]#
vi /root/.bashrc(在bigdata002/3也要操作)
export HADOOP_CLASSPATH=/opt/hadoop-3.3.1/share/hadoop/client/*:/opt/hadoop-3.3.1/share/hadoop/common/*:/opt/hadoop-3.3.1/share/hadoop/common/lib/*:/opt/hadoop-3.3.1/share/hadoop/hdfs/*:/opt/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.1/share/hadoop/mapreduce/*:/opt/hadoop-3.3.1/share/hadoop/tools/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/*:/opt/hadoop-3.3.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/csi/*:/opt/hadoop-3.3.1/share/hadoop/yarn/csi/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/timelineservice/*:/opt/hadoop-3.3.1/share/hadoop/yarn/timelineservice/lib/*
export HADOOP_CONF_DIR=/opt/hadoop-3.3.1/etc/hadoop
vi /root/.bashrc
export FLINK_HOME=/opt/flink-1.13.2
export PATH=$PATH:$FLINK_HOME/bin
3.4 启动和验证
- flink-1.13.2目录的分发(在bigdata001操作)
[root@bigdata001 opt]# scp -r flink-1.13.2 root@bigdata002:/opt
[root@bigdata001 opt]# scp -r flink-1.13.2 root@bigdata003:/opt
- 启动(在bigdata001操作)
[root@bigdata001 opt]#
[root@bigdata001 opt]# start-cluster.sh
Starting HA cluster with 3 masters.
Starting standalonesession daemon on host bigdata001.
Starting standalonesession daemon on host bigdata002.
Starting standalonesession daemon on host bigdata003.
Starting taskexecutor daemon on host bigdata001.
Starting taskexecutor daemon on host bigdata002.
Starting taskexecutor daemon on host bigdata003.
[root@bigdata001 opt]#
- jps查看bigdata001/2/3,都会有下面2各进程
3125 StandaloneSessionClusterEntrypoint
3464 TaskManagerRunner
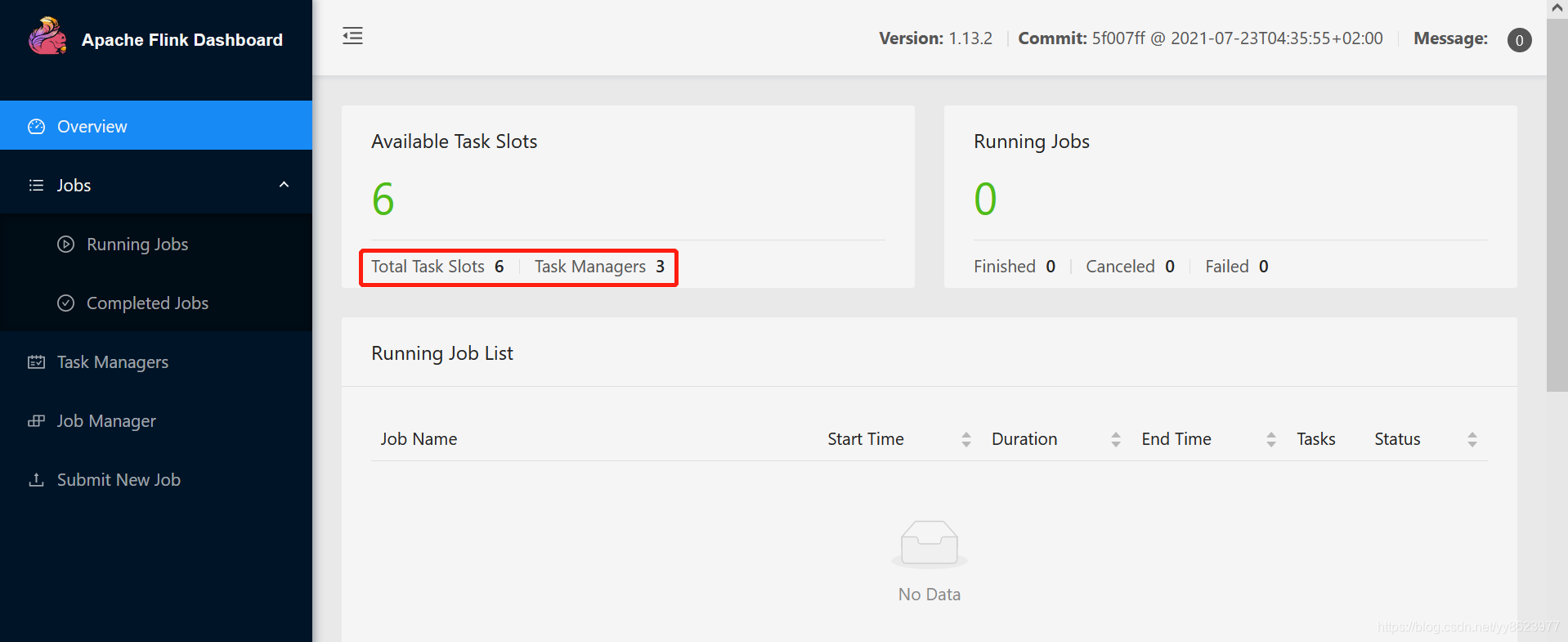
- 访问http://bigdata001:8081、http://bigdata002:8081、http://bigdata003:8081,如下图所示:
 5. 执行测试程序(在bigdata001操作)
5. 执行测试程序(在bigdata001操作)
[root@bigdata001 opt]#
[root@bigdata001 opt]# /opt/flink-1.13.2/bin/flink run /opt/flink-1.13.2/examples/streaming/WordCount.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.13.2/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.3.1/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 5e1d3795b04976513ea026b3a8b066ce
Program execution finished
Job with JobID 5e1d3795b04976513ea026b3a8b066ce has finished.
Job Runtime: 1125 ms
[root@bigdata001 opt]#
- stop集群(在bigdata001操作)
[root@bigdata001 opt]# stop-cluster.sh
Stopping taskexecutor daemon (pid: 32321) on host bigdata001.
Stopping taskexecutor daemon (pid: 16596) on host bigdata002.
Stopping taskexecutor daemon (pid: 2990) on host bigdata003.
Stopping standalonesession daemon (pid: 31982) on host bigdata001.
Stopping standalonesession daemon (pid: 16274) on host bigdata002.
Stopping standalonesession daemon (pid: 2675) on host bigdata003.
[root@bigdata001 opt]#
4. Yarn模式
4.1 修改conf/flink-conf.yaml(在bigdata001操作)
新增目录
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# pwd
/opt/flink-1.13.2
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# mkdir web_upload_dir
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# mkdir io_tmp_dir
[root@bigdata001 flink-1.13.2]#
修改部分
jobmanager.memory.process.size: 2g
taskmanager.memory.process.size: 6g
taskmanager.numberOfTaskSlots: 2
state.backend: rocksdb
state.checkpoints.dir: hdfs://nnha/flink/checkpoints/rocksdb
state.savepoints.dir: hdfs://nnha/flink/savepoints/rocksdb
io.tmp.dirs: /opt/flink-1.13.2/io_tmp_dir
high-availability: zookeeper
high-availability.zookeeper.quorum: bigdata001:2181,bigdata002:2181,bigdata003:2181
high-availability.storageDir: hdfs://nnha/flink/ha/recovery/
添加部分
env.java.home: /opt/jdk1.8.0_201
execution.checkpointing.interval: 300000
web.upload.dir: /opt/flink-1.13.2/web_upload_dir
high-availability.zookeeper.path.root: /flink
4.2 修改conf/masters和conf/workers(在bigdata001操作)
bigdata001:8081
bigdata002:8081
bigdata003:8081
bigdata001
bigdata002
bigdata003
4.3 依赖jar包的添加和环境变量的添加(在bigdata001操作)
[root@bigdata001 flink-1.13.2]#
[root@bigdata001 flink-1.13.2]# pwd
/opt/flink-1.13.2
[root@bigdata001 flink-1.13.2]# mv lib/flink-shaded-zookeeper-3.4.14.jar opt/
[root@bigdata001 flink-1.13.2]# mv opt/flink-shaded-zookeeper-3.5.6.jar lib/
[root@bigdata001 flink-1.13.2]#
vi /root/.bashrc(在bigdata002/3也要操作)
export HADOOP_CLASSPATH=/opt/hadoop-3.3.1/share/hadoop/client/*:/opt/hadoop-3.3.1/share/hadoop/common/*:/opt/hadoop-3.3.1/share/hadoop/common/lib/*:/opt/hadoop-3.3.1/share/hadoop/hdfs/*:/opt/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.1/share/hadoop/mapreduce/*:/opt/hadoop-3.3.1/share/hadoop/tools/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/*:/opt/hadoop-3.3.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/csi/*:/opt/hadoop-3.3.1/share/hadoop/yarn/csi/lib/*:/opt/hadoop-3.3.1/share/hadoop/yarn/timelineservice/*:/opt/hadoop-3.3.1/share/hadoop/yarn/timelineservice/lib/*
export HADOOP_CONF_DIR=/opt/hadoop-3.3.1/etc/hadoop
vi /root/.bashrc
export FLINK_HOME=/opt/flink-1.13.2
export PATH=$PATH:$FLINK_HOME/bin
4.4 Application Mode启动和验证
- 每一个application启动一个集群,application的main()方法在JobManager执行,减轻了client的压力,application失败或运行完就会关闭集群
- 因每一次都需要启动集群,适用于时效要求不高、长时间运行、资源隔离要求高的application
- 准备测试jar包
[root@bigdata001 opt]#
[root@bigdata001 opt]# hadoop fs -mkdir /flink
[root@bigdata001 opt]# hadoop fs -mkdir /flink/run-jars
[root@bigdata001 opt]# hadoop fs -put flink-1.13.2/examples/streaming/WordCount.jar /flink
/run-jars
[root@bigdata001 opt]#
- 启动application
[root@bigdata001 opt]#
[root@bigdata001 opt]# flink run-application -t yarn-application hdfs://nnha/flink/run-jars/WordCount.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.13.2/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.3.1/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2021-08-13 11:36:19,441 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/flink-1.13.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-08-13 11:36:19,659 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-08-13 11:36:19,766 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2021-08-13 11:36:19,863 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2021-08-13 11:36:19,863 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2021-08-13 11:36:19,974 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=2048, taskManagerMemoryMB=6144, slotsPerTaskManager=2}
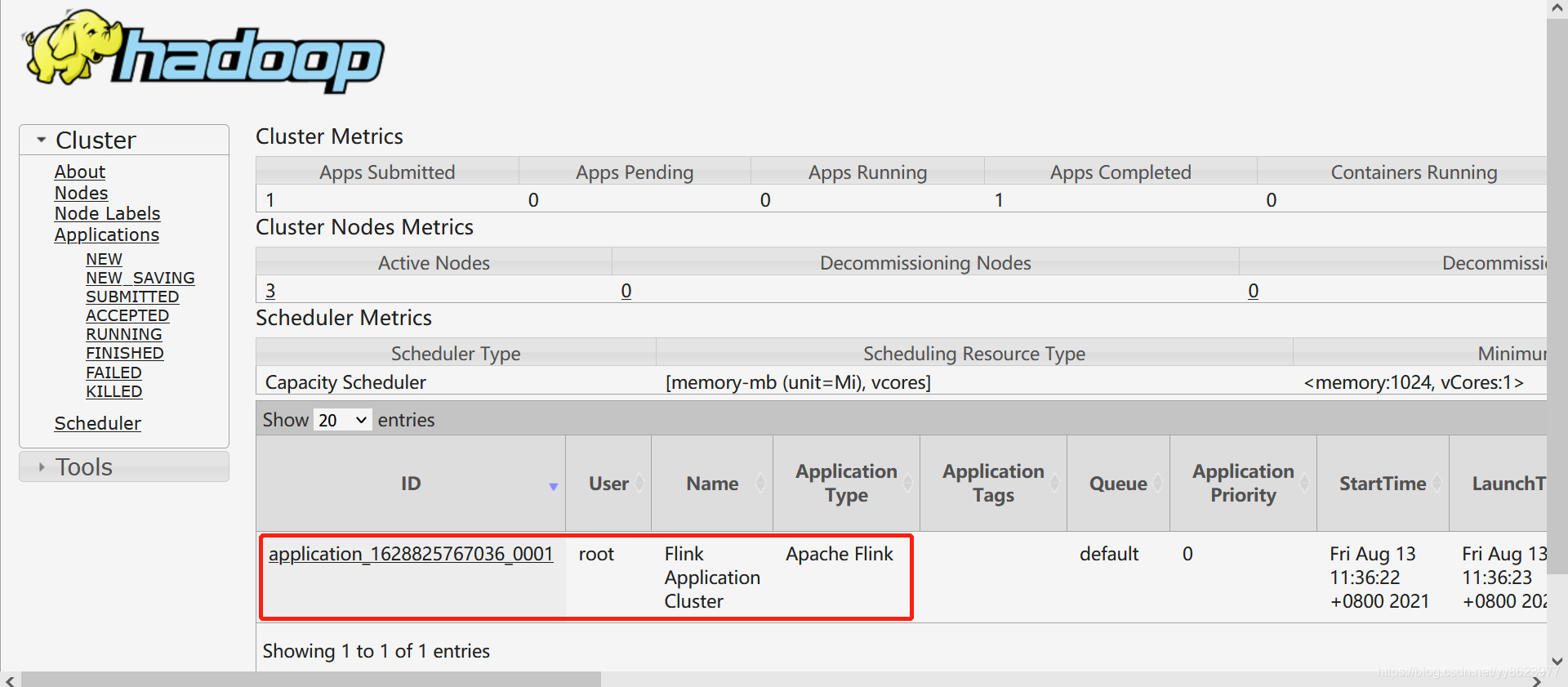
2021-08-13 11:36:22,837 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1628825767036_0001
2021-08-13 11:36:23,245 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1628825767036_0001
2021-08-13 11:36:23,246 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2021-08-13 11:36:23,252 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2021-08-13 11:36:29,935 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2021-08-13 11:36:29,936 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata001:41218 of application 'application_1628825767036_0001'.
[root@bigdata001 opt]#
- 可以看到Flink的Web访问链接是:bigdata001:41218,这个Ip和Port每次都是不固定的
- 当需要添加依赖的jar包,添加方式如:
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" - 可以通过命令列出application正在运行的job:
flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY - 可以通过命令停掉application正在运行的job:
flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
- 查看yarn的Web界面
4.5 Session Mode启动和验证
- 启动
[root@bigdata001 opt]#
[root@bigdata001 log]# yarn-session.sh --detached > /opt/flink-1.13.2/yarn-session_start.log
[root@bigdata001 log]#
[root@bigdata001 log]# cat /opt/flink-1.13.2/yarn-session_start.log
......省略部分......
2021-08-13 12:49:12,218 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
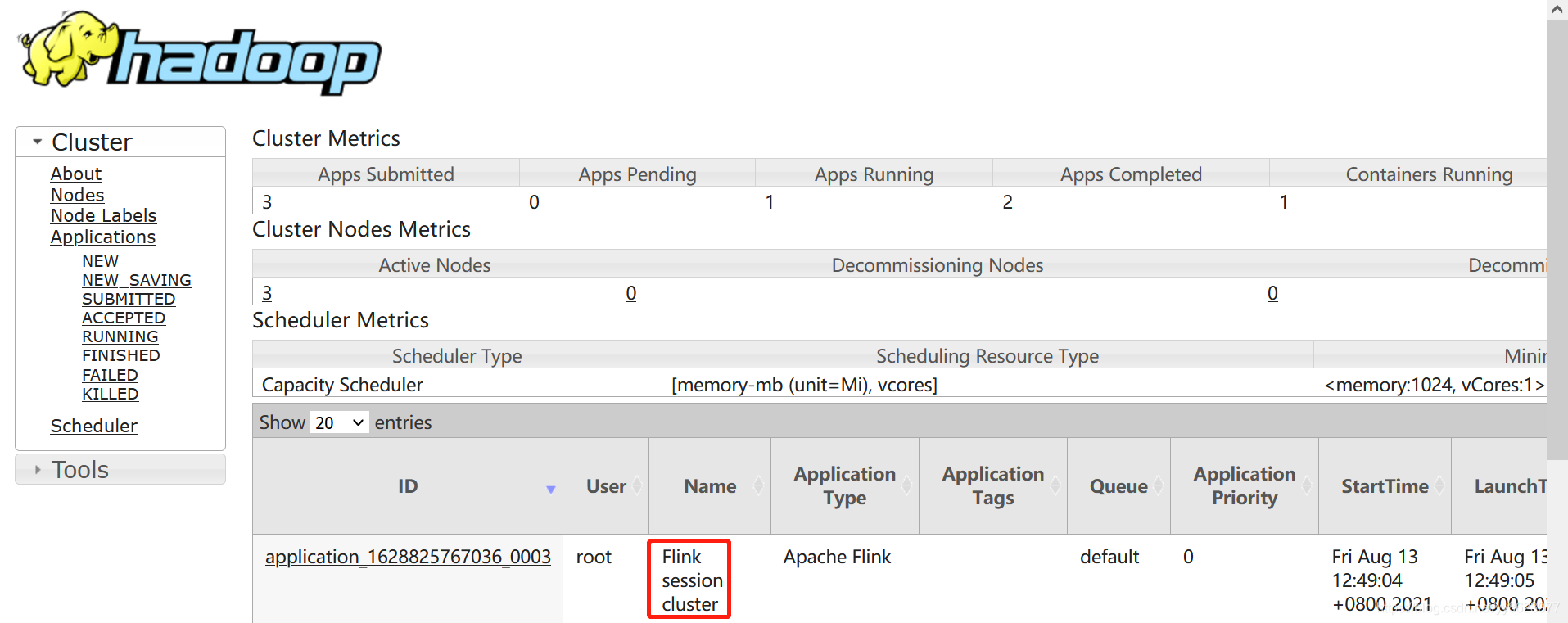
2021-08-13 12:49:12,219 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata002:39955 of application 'application_1628825767036_0003'.
2021-08-13 12:49:12,319 INFO org.apache.flink.shaded.curator4.org.apache.curator.utils.Compatibility [] - Using emulated InjectSessionExpiration
......省略部分......
- 可以看到随机的Flink Web链接是: bigdata002:39955, 此Ip和Port每次都是不固定的
- 用jps查看,只有bigdata002上有一个进程:
31346 YarnSessionClusterEntrypoint - 可以通过命令列出session正在运行的job:
flink list -t yarn-session -Dyarn.application.id=application_XXXX_YY - 可以通过命令停掉session正在运行的job:
flink cancel -t yarn-session -Dyarn.application.id=application_XXXX_YY <jobId>
查看Flink的Web界面,如下所示:
 查看Yarn的Web界面,如下所示:
查看Yarn的Web界面,如下所示:
2. 运行测试jar包
[root@bigdata001 opt]#
[root@bigdata001 opt]# /opt/flink-1.13.2/bin/flink run /opt/flink-1.13.2/examples/streaming/WordCount.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.13.2/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.3.1/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2021-08-13 12:56:46,180 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2021-08-13 12:56:46,180 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
2021-08-13 12:56:46,642 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/flink-1.13.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-08-13 12:56:46,811 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-08-13 12:56:46,877 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm2
2021-08-13 12:56:46,917 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata002:39955 of application 'application_1628825767036_0003'.
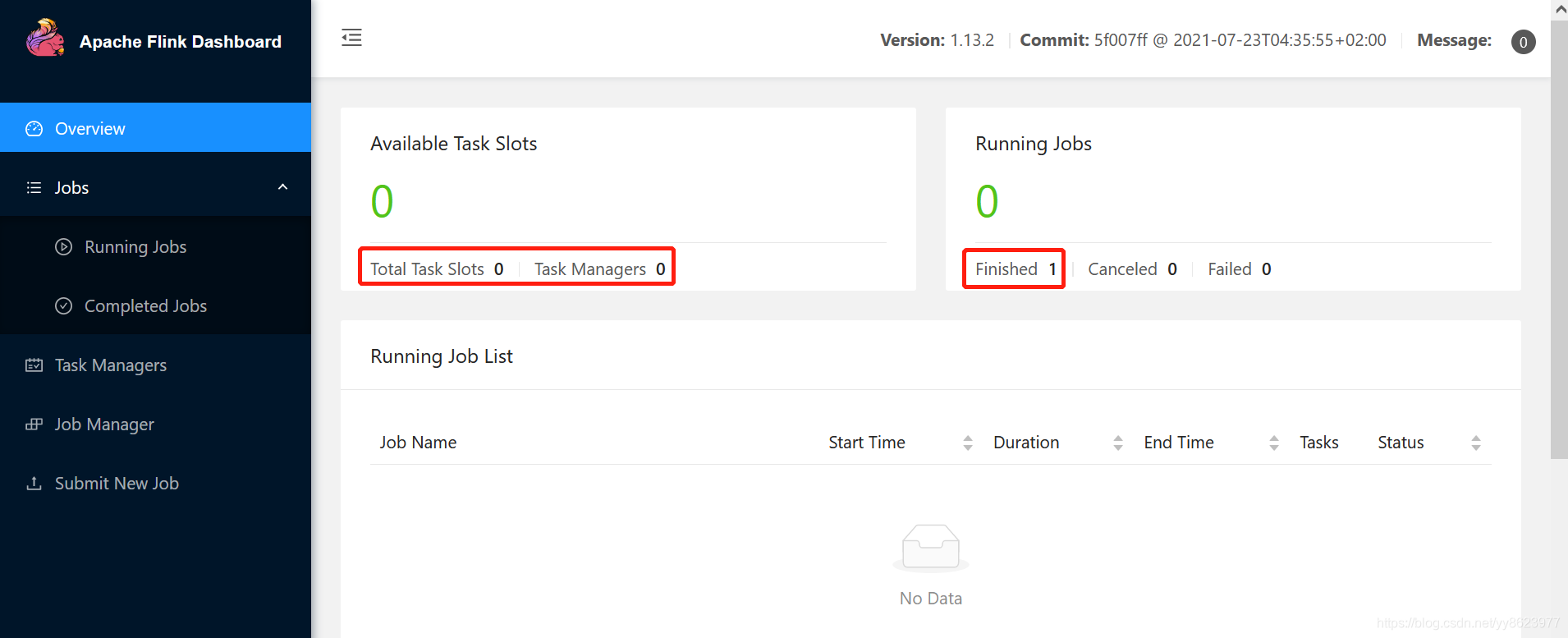
Job has been submitted with JobID a6c736ff784fb4e73702f7ef6597d4cf
Program execution finished
Job with JobID a6c736ff784fb4e73702f7ef6597d4cf has finished.
Job Runtime: 11389 ms
[root@bigdata001 opt]#
再次查看Flink的Web界面
3. 停止session
[root@bigdata001 opt]#
[root@bigdata001 opt]# echo "stop" | yarn-session.sh -id application_1628825767036_0003
[root@bigdata001 opt]#
或者
[root@bigdata001 opt]#
[root@bigdata001 opt]# yarn application -kill application_1628825767036_0004
[root@bigdata001 opt]#
