1.为什么不用关系型数据库做搜索
(1)要对表的每一行进行内容比对,效率很差。再加上实际开发中肯定不是单表查询,查询字段来源多个表,这种情况下效率就更差了。
(2)不能将搜索词拆开。比如搜索“农夫泉”,就搜索不出”农夫山泉“
类比一下 mysql 和 elasticsearch
| mysql | elasticsearch |
|---|---|
| 数据库 database | 索引 index |
| 表 table | 类型 type(注意:7.X版本 去掉了type) |
| 数据行 row | 文档 document |
| 数据列 column | 字段 field |
2.什么是全文检索
先建立倒排索引,再对索引进行搜索的过程叫做全文检索。
举例:有以下数据
| id | 值 |
|---|---|
| 1 | 小米手机 |
| 2 | 魅族手机 |
| 3 | 苹果手机 |
将以上数据拆成关键字就是“小米”“魅族”“苹果”“手机”四个关键字。然后组织倒排索引的数据结构。
倒排索引:将数据集合拆分成关键词,关键字做key,数据id集合做value,形成映射关系。
| 关键词 | ids |
|---|---|
| 小米 | 1 |
| 魅族 | 2 |
| 苹果 | 3 |
| 手机 | 1、2、3 |
这样搜索的时候,根据搜索条件直接搜索倒排索引。可能第一次扫描就拿到了你要的结果,效率非常高。
3.lucene?
可以看作是一个 jar 包,里面封装好了各种建立倒排索引,包含各种算法的搜索代码。我们进行 java 开发的时候,引入 lucene 依赖,基于它的 api 进行开发就行了。用了 lucene,我们就可以基于已有的数据建立倒排索引。
4.什么是elasticsearch
elasticsearch 是基于 lucene 开发的,采用 restful api标准的全文搜索工具。封装了多节点治理、数据备份,性能优化,以及提供了一些更加高级的功能。
接下来说一下 elasticsearch 的相关概念:
1.Node(节点)
安装了 Elasticsearch 服务的运行实例。在测试环境中可以在一台服务器上运行多个 es 实例,在生产环境中建议每台服务器单独运行一个 es 实例。
2.Cluster(集群)
一个集群就是由一个或多个 node 组织在一起,共同工作和分享整个数据,具有负载均衡功能的集群。elasticsearch 会自动的把集群名相同的节点组成一个集群,节点之间的通讯以及节点之间的数据分配和均衡,elasticsearch 都会自动进行管理。
3.Index(索引)
索引就是一个拥有几分相似特征的文档的集合。
4.Document(文档)
文档是一个可被索引的基础数据单元。
5.Type(类型)
一个索引中,你可以定义一种或多种类型。
6.Field(列)
Field是Elasticsearch的最小单位,相当于数据的某一列。
7.Shards(分片)
Elasticsearch会将一个索引分成若干个小的索引,每个小的索引就是一个 shard。
8.Replicas(副本)
每一个副本都是分片的的完整拷贝,es的每一个分片都可以有零个或者多个副本。提高查询速度的同时也提高了系统的容错性。
总结下来就是:elasticsearch 可以让我们快速地开发传说中的三高架构系统:高性能,高可用,搞扩展。并且开箱即用。
5.分析一下Elasticsearch写数据的底层原理
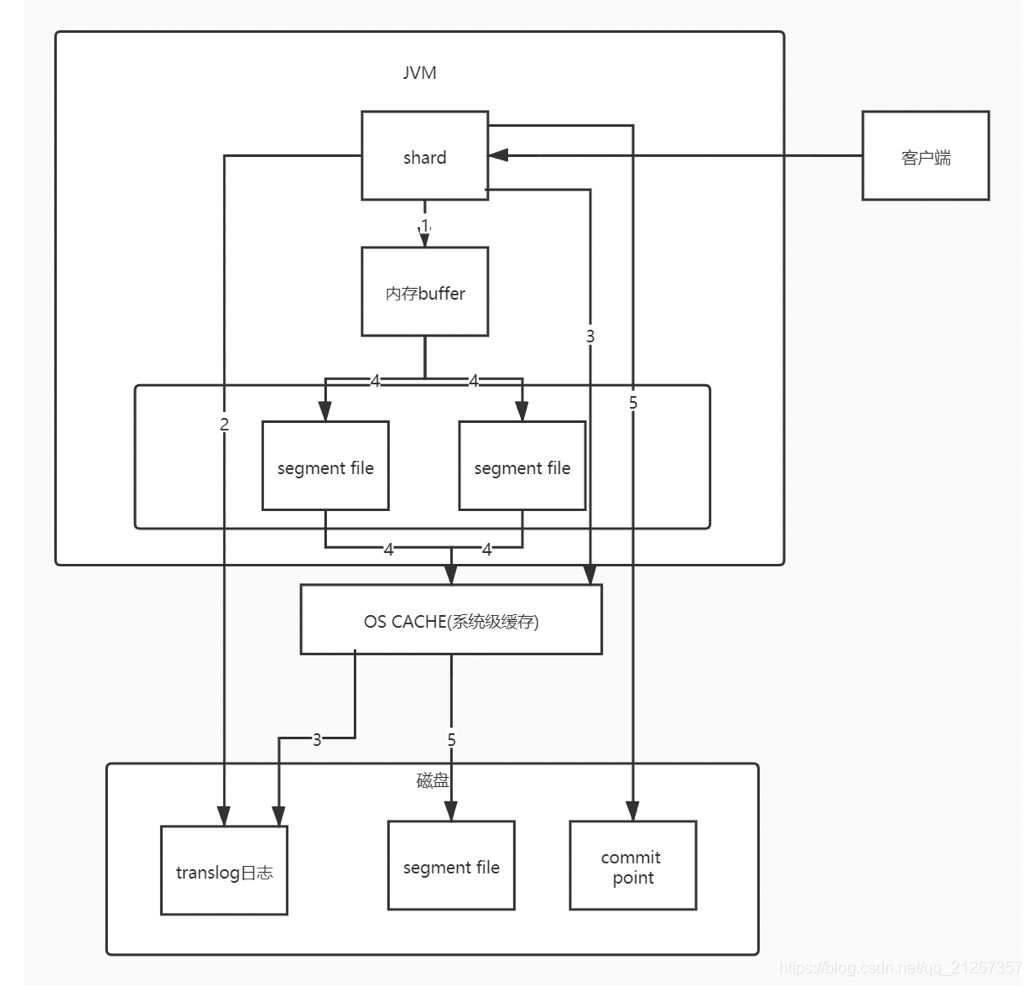
概念
了解它的写入原理之前我们先来了解一些概念
1.内存buffer
JVM内存缓冲区简单来说就是byte数组
2.os cache
简单来说就是操作系统直接分配的一个内存空间,又称为磁盘缓存、文件系统缓存、操作系统缓存。
3.segment file
存储倒排索引的文件,每个segment本质上就是一个倒排索引
4.translog日志文件
记录数据操作的日志文件
5.commit point
记录所有segment file的提交点,记录哪些 segment file 属于哪些分片
写入流程
1.数据写入内存 buffer 缓冲同时写入 translog 日志,这里解释一下为啥要同时写入 translog 日志,因为一旦 elasticsearch 宕机,在内存 buffer 中的数据就会丢失,有了 translog 日志就能找回 elasticsearch 宕机时丢失的数据。这里需要注意一下:在 buffer 里的数据是搜索不到的。
2.translog 其实有两种写入策略一种是上面说的在写入 buffer 的同时写入磁盘中的 translog,即同步刷盘,这种方式不会丢数据,但磁盘IO高,有性能损耗。
3.另一种是写入 buffer 的同时直接写入 os cache,然后 os cache 异步刷入磁盘,这种方式性能好,但如果服务出现异常,可能丢失一点数据(最多5秒的数据丢失)
4.每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file(可以理解为存放数据的容器),
这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。并立刻进入 os cache,此时 buffer 的数据也会被清空
5.随着以上步骤不断发生,新的数据不断进入 buffer 和 translog,不断将 buffer 数据写入一个又一个新的segment file中去,每次 refresh 完 buffer 清空, translog 保留。
随着这个过程推进,translog 会变得越来越大,当 translog 达到一定大小的时候,就会触发 commit 操作。
commit 操作发生的第一步,就是将 buffer 中现有数据 refresh 到 os cache 中去,清空 buffer。
然后将一个 commit point 写入磁盘文件,里面标识着这个 commit point 对应的所有 segment file。
接着将 os cache 数据 fsync 强刷到磁盘上去,
最后将现有的 translog 清空,然后再次重新启用这个 translog,此时 commit 操作完成。