�����
- https://www.bilibili.com/video/BV11A411L7CK?p=11
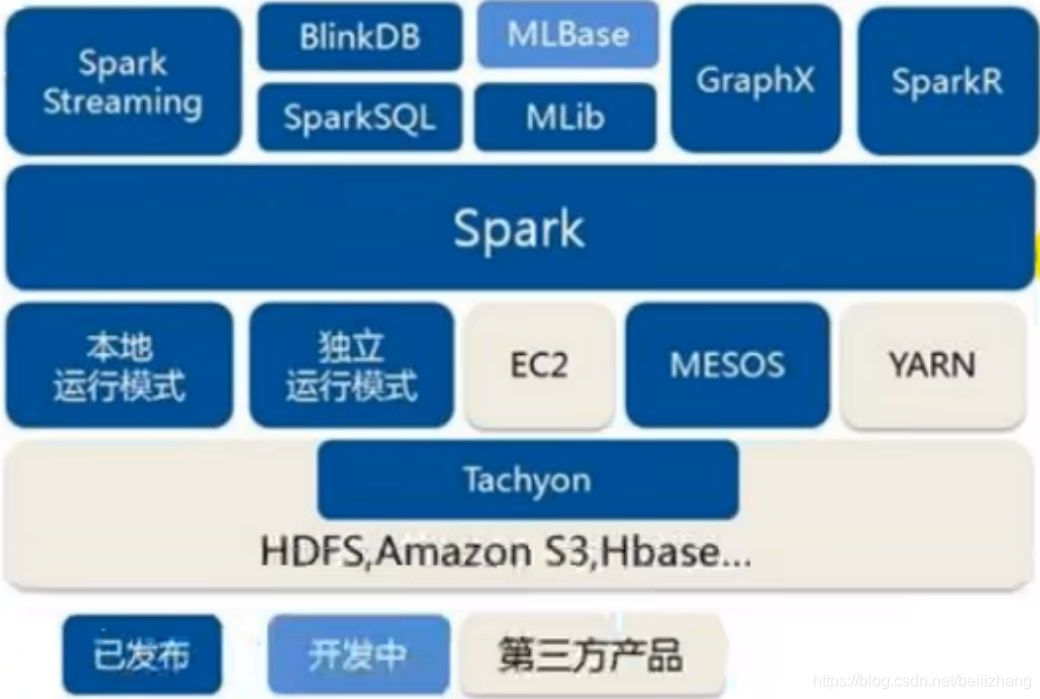
Spark�����
Spark��Ϊһ�����ݴ�����ܺͼ�������,����������г����ļ�Ⱥ����������,�ڹ��ڹ����������Ļ���ΪYarn,����������ʽ����Ҳ������������
Localģʽ
��ν��Localģʽ,���Dz���Ҫ�����κνڵ���Դ�Ϳ����ڱ���ִ��Spark����Ļ���,һ�����ڽ�ѧ,����,��ʾ�ȡ���IDEA�����д���Ļ�����Ϊ��������,��һ��
-
������������������spark-shell����
-
�����ɹ���,����������ַ����Web UI���ҳ�����
-
��Ctrl+C������Scalaָ��:quit�˳�����ģʽ
�ύӦ��
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- �Cclass��ʾҪִ�г��������,�˴����Ը���Ϊ�Լ�д��Ӧ�ó���
- �Cmaster local[2]����ģʽ,Ĭ��Ϊ����ģʽ,���ֱ�ʾ���������CPU������
- spark-examples_2.12-3.0.0.jar���е�Ӧ�������ڵ�jar��,ʵ��ʹ��ʱ,�����趨Ϊ�Լ����jar��
- ����10��ʾ�������ڲ���,�����趨��ǰӦ�õ���������
Standaloneģʽ
local����ģʽֻ������������ϰ��ʾ��,��ʵ�����л���Ҫ��Ӧ���ύ����Ӧ�ļ�Ⱥ��ȥִ�С�ֻʹ��Spark�����ڵ����еļ�Ⱥģʽ,������ν�Ķ�������(Standalone)ģʽ��Spark��Standaloneģʽ�����˾����master-slaveģʽ
��Ⱥ�滮:

�������ļ�
-
�����ѹ�����confĿ¼,��slavers.template�ļ���Ϊslaves
-
��slaves�ļ�,����work�ڵ�
linux1
linux2
linux3
-
��spark-env.sh.template�ļ���Ϊspark-env.sh
-
��spark-env.sh,����JAVA_HOME���������ͼ�Ⱥ��Ӧ��master�ڵ�
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1
SPARK_MASTER_PORT=7077
ע��:7077�˿�,�൱��hadoop3�ڲ�ͨ�ŵ�8020�˿�,�˴��Ķ˿���Ҫȷ���Լ���Hadoop����
- �ַ�spark-standaloneĿ¼
xsync spark-standalone
������Ⱥ
- ִ�нű�����
sbin/start-all.sh
-
�鿴�������������н���
-
�鿴Master��Դ���Web UI����:http://linux1:8080
�ύӦ��
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- �Cclass��ʾҪִ�г��������
- �Cmaster spark://linux1:7077��������ģʽ,���ӵ�Spark��Ⱥ
- spark-examples_2.12-3.0.0.jar���������ڵ�jar��
- ����10��ʾ�������ڲ���,�����趨��ǰӦ�õ���������
������ʷ����
����spark-shellֹͣ����,��Ⱥ���linux1:4040ҳ��Ϳ�������ʷ������������,���Կ���ʱ��������ʷ��������¼�����������
-
��spark-defaults.conf.template�ļ���Ϊspark-defaults.conf
-
��spark-default.conf�ļ�,������־�洢·��
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
ע��:��Ҫ����hadoop��Ⱥ,HDFS�ϵ�directoryĿ¼��Ҫ��ǰ����
sbin/start-dfs.sh
hadoop fs -mkdir /directory
- ��spark-env.sh�ļ�,������־����
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"
����1����:WEB UI���ʵĶ˿ں�Ϊ18080
����2����:ָ����ʷ��������־�洢·��
����3����:ָ������Application��ʷ��¼�ĸ���,����������ֵ,�ɵ�Ӧ�ó������Ϣ����ɾ��,�����ڴ��е�Ӧ����,������ҳ������ʾ��Ӧ����
- �ַ������ļ�
xsync conf
- ����������Ⱥ����ʷ����
sbin/start-all.sh
sbin/start-history-server.sh
- ����ִ������
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
���ø߿���(HA)
�߿�������Ϊ��ǰ��Ⱥ�е�Master�ڵ�ֻ��һ��,���Ի���ڵ���������⡣Ϊ��,��Ҫ�ڼ�Ⱥ�����ö��Master�ڵ�,һ�����ڻ״̬��Master��������ʱ,�ɱ���Master�߶�����,��֤��ҵ���Լ���ִ�С�����ĸ߿���һ�����Zookeeper����
��Ⱥ�滮:

- ֹͣ��Ⱥ
sbin/stop-all.sh
- ����Zookeeper
xstart zk
- ��spark-env.sh�ļ�������������
ע����������:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
������������:
#Master���ҳ��Ĭ�Ϸ��ʶ˿�Ϊ8080,���ǿ��ܻ��Zookeeper��ͻ,����,�ij�8989,Ҳ�����Զ���,����UI���ҳ��ʱ��ע��
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark"
- �ַ������ļ�
xsync conf/
- ������Ⱥ
sbin/start-all.sh
- ����linux2�ĵ���Master�ڵ�,��ʱlinux2�ڵ�Master״̬���ڱ���״̬
sbin/start-master.sh
- �ύӦ�õ��߿��ü�Ⱥ
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077,linux2:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- ֹͣlinux1��Master��Դ��ؽ���
Yarnģʽ
��������(Standalone)ģʽ��Spark�����ṩ������Դ,������������ṩ��Դ�����ַ�ʽ�����˺�������������Դ��ܵ������,�����Էdz�ǿ������Spark��Ҫ�Ǽ�����,��������Դ���ȿ��,���Ա����ṩ����Դ���Ȳ���������ǿ��,���Ի��Ǻ�����רҵ����Դ���ȿ�ܼ��ɻ������һЩ
�������ļ�
- ��hadoop�����ļ�/opt/module/hadoop/etc/hadoop/yarn-site.xml,���ַ�
<!--�Ƿ�����һ���̼߳��ÿ��������ʹ�õ������ڴ���,�����������ֵ,��ֱ�ӽ���ɱ��,Ĭ����true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--�Ƿ�����һ���̼߳��ÿ��������ʹ�õ������ڴ���,�����������ֵ,��ֱ�ӽ���ɱ��,Ĭ����true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- ��conf/spark-env.sh,����JAVA_HOME��YARN_CONF_DIR����
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
-
����HDFS�Լ�YARN��Ⱥ
-
�ύӦ��
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
�鿴http://linux2:8088ҳ��,���History,�鿴��ʷҳ��
-
������ʷ������
-
��spark-defaults.conf.template�ļ���Ϊspark-defaults.conf
-
��spark-default.conf�ļ�,������־�洢·��
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory
ע��:��Ҫ����hadoop��Ⱥ,HDFS�ϵ�directoryĿ¼��Ҫ��ǰ����
sbin/start-dfs.sh
hadoop fs -mkdir /directory
- ��spark-env.sh�ļ�,������־����
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"
����1����:WEB UI���ʵĶ˿ں�Ϊ18080
����2����:ָ����ʷ��������־�洢·��
����3����:ָ������Application��ʷ��¼�ĸ���,����������ֵ,�ɵ�Ӧ�ó������Ϣ����ɾ��,�����ڴ��е�Ӧ����,������ҳ������ʾ��Ӧ����
- ��spark-defaults.conf
spark.yarn.historyServer.address=linux1:18080
spark.history.ui.port=18080
- ������ʷ����
sbin/start-history-server.sh
- �����ύӦ��
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- Webҳ��鿴��־:http://linux2:8088
K8S & Mesosģʽ
Mesos��Apache�µĿ�Դ�ֲ�ʽ��Դ�������,������Ϊ�Ƿֲ�ʽϵͳ���ں�,��Twitter�õ��㷺ʹ��,������Twitter����30,0000̨�������ϵ�Ӧ�ò���,�����ڹ���,��Ȼʹ�ô�ͳHadoop�����ݿ��,���Թ���ʹ��Mesos��ܵIJ�����,����ԭ�������
������������Ŀǰҵ������е�һ���,����Docker���������ܹ����û����ӷ���ض�Ӧ�ý��й�������ά������������������Ϊ���еľ���Kubernetes(k8s),��SparkҲ������İ汾��֧����k8s����ģʽ
Windowsģʽ
��ѧϰʱ,ÿ�ζ���Ҫ���������,������Ⱥ,����һ���ȽϷ����Ĺ���,���һ�ռ�ô�����ϵͳ��Դ,����ϵͳִ�б�����Spark�ṩ�˿�����windowsϵͳ���������ؼ�Ⱥ�ķ�ʽ,����,�ڲ�ʹ��������������,Ҳ��ѧϰSpark�Ļ���ʹ��
-
��ѹ���ļ�
���ļ�spark-3.0.0-bin-hadoop3.2.tgz��ѹ�����������ո��·���� -
�������ػ���
i) ִ�н�ѹ���ļ�·����binĿ¼�е�spark-shell.cmd�ļ�,����Spark���ػ���
ii) ��binĿ¼�д���inputĿ¼,������word.txt�ļ�,��������������ű�����
- �������ύӦ��
��DOS�����д�����ִ���ύָ��
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10