?欢迎关注博客主页:https://blog.csdn.net/u013411339
欢迎点赞、收藏、留言 ,欢迎留言交流!
本文由【王知无】原创,首发于 CSDN博客!
本文首发CSDN论坛,未经过官方和本人允许,严禁转载!

本文是对《【硬刚大数据之学习路线篇】2021年从零到大数据专家的学习指南(全面升级版)》的面试部分补充。
?
硬刚大数据系列文章链接:
DorisDB是由Apache Doris核心研发团队打造的新一代企业级MPP数据库。它继承了Apache Doris项目十多年研发成果,累积了线上数千台服务器稳定运行经验,并在此基础上,对传统MPP数据库进行了开创性的革新。
DorisDB重新定义了MPP分布式架构,集群可扩展至数百节点,支持PB级数据规模,是当前唯一可以在大数据规模下进行在线弹性扩展的企业级分析型数据库。
DorisDB还打造了全新的向量化执行引擎,单节点每秒可处理多达100亿行数据,查询速度比其他产品快10-100倍!
Doris 简史
Doris 自第一版诞生以来,经过了 11 年的发展,中间做过无数改进。这?只罗列对 Doris 发展来说?比较重要的关键节点与事件。
2008
Doris1 ,「筑巢引凤」的重要基石
在 Doris1 诞生之前,百度使用 MySQL Sharding 方式来为广告主提供广告报表支持。随着百度本身流量的增加,广告流量也随之增加,已有的 MySQL Sharding 方案变得不再能够满足业务的需求。当时数据存储和计算成熟的开源产品很少,Hbase 的导入性能只有大约 2000 条/秒,不能满足业务每小时新增的要求。而业务还在不断增长,来自业务的压力越来越大。在这种情况下,Doris1 诞生了,并且在 2008 年 10 月份跟随百度凤巢系统一起正式上线。
2009
Doris2,解「百度统计」燃眉之急
2008 年的百度统计服务大约有 50-60 台 MySQL,但是业务每天有 3000 万+条增量数据,由于 MySQL 的存储和查询性能无法满足需求,对存量数据的支撑已经到了极限,问题频出,万般无奈之下百度统计甚至关闭了新增用户的功能,以减少数据量的增加。
Doris1 由于当时时间紧、任务重,所以设计、实现的时候只为了能够满足凤巢的业务需求,并没有兼顾其他的应用需求。2009 年 Doris2 研发完成后上线百度统计,并且成功支撑百度统计后续的快速增长,成功的助力百度统计成为当时国内规模最大,性能、功能最强的统计平台。
2010
Doris3 ,让查询再快一点
随着业务数据量的不断增长,Doris2 系统的问题也逐渐成为业务发展的瓶颈。首先体现在 Doris2 无法满足业务的查询性能需求,主要是对于长时间跨度的查询请求、以及大客户的查询请求。其次,Doris2 在日常运维方面基本上都需要停服后手动操作,比如 Schema Change、集群扩缩容等,一方面用户体验很差,一方面还会增加集群运维的成本。最后,Doris2 本身并不是高可用系统,机器故障等问题还是会影响服务的稳定性,并且需要人肉进行复杂的操作来恢复服务。为了解决 Doris2 的问题,团队开始了 Doris3 设计、研发。Doris3 的主要架构中,DT(Data Transfer)负责数据导入、DS(Data Seacher)模块负责数据查询、DM(Data Master)模块负责集群元数据管理,数据则存储在 Armor 分布式 Key-Value 引擎中。Doris3 依赖 ZooKeeper 存储元数据,从而其他模块依赖 ZooKeeper 做到了无状态,进而整个系统能够做到无故障单点。
在数据分布方面 Doris3 引入了分区的概念。
另外 Doris3 在日常运维 Schema Change,以及扩容、缩容等方面都做了针对性设计,使其能够自动化进行,不依赖线上人工操作。
Doris3 在 2011 年完成开发后逐渐替换 Doris2 所制成的业务,并且成功的解决了大客户查询的问题。而公司内部后续的新需求,也都由 Doris3 来承担支持。
2012
MySQL + Doris3 ,百度的第一个 OLAP 平台
2012 年随着 Doris3 逐步迁移 Doris2 的同时,大数据时代悄然到来。在公司内部,随着百度业务的发展,各个业务端需要更加灵活的方式来分析已有的数据。而此时的 Doris3 仍然只支持单表的统计分析查询,还不能够满足业务进行多维分析的需求。所以,为了能够支持业务的多维分析需求,Doris3 采用了 MySQL Storage Handler 的方式来扩展 Doris3。
2012
OLAP Engine,突破底层存储束缚
Doris3 支持报表分析场景时,底层通用 Key-Value 存储引擎的弊端也逐渐显露。
为了能够在底层存储引擎上有所突破,OLAP Engine 项目启动了。这个项目的发起者是当时从 Google 来的高 T,为百度带来了当时业界最领先的底层报表引擎技术。
2013
用 PALO,玩转 OLAP
底层技术的发展会激发上层业务的需求,而上层业务的需求同时会为底层的技术带来新的挑战。因此 Doris 亟需一款拥有分布式计算能力的查询引擎。新产品的名字命名为 PALO,意为玩转 OLAP。随着 PALO1 的正式上线,除了迁移所有 Doris3 已有的的业务外,也成功支持了当时百度内部大部分的 OLAP 分析场景。
2015
PALO 2,让架构再简单一点
如果说 PALO 1 是为了解决性能问题,那么 PALO 2 主要是为了在架构上进行优化。通过 PALO2 的工作,系统架构本身变得相当简洁,并且不需要任何依赖。
2017 and Future
Apache Doris (incubating) ,是更广阔的世界
Palo 于 2017 年正式在 GitHub 上开源,并且在 2018 年贡献给 Apache 社区,并将名字改为 Apache Doris(incubating)进行正式孵化。随着开源,Doris 已经在京东、美团、搜狐、小米等公司的生产环境中正式使用,也有越来越多的 Contributor 加入到 Doris 大家庭中。
整体架构 - MPP架构
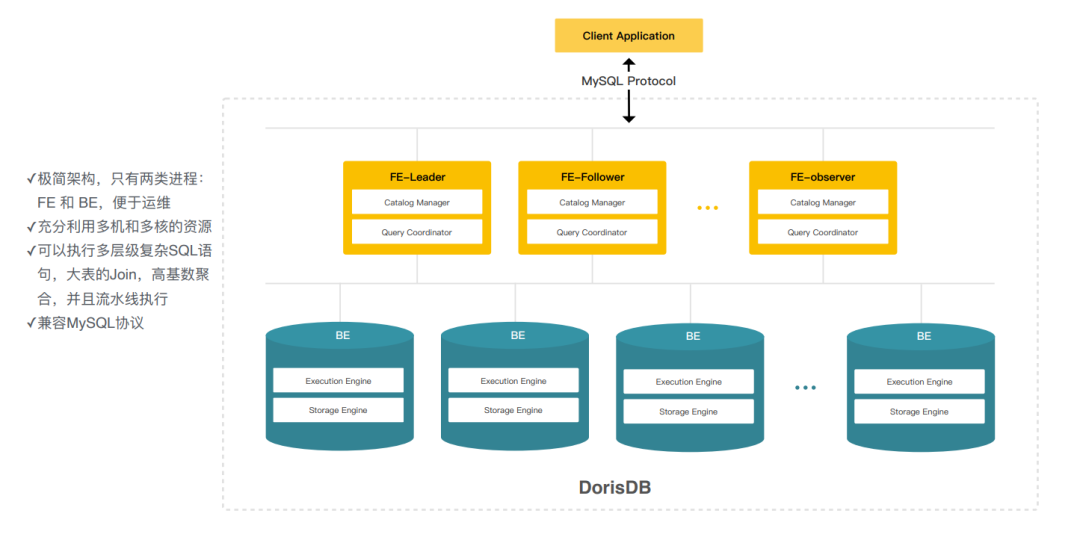
弹性MPP架构-极简架构
-
FE前端节点-主要负责元数据的管理、查询调度,解析sql的执行计划给BE,
-
BE-数据的存储和执行的引擎,这里存储和计算还是在一起的;
-
FE:leader 、follower(参与选举),水平扩容
-
对外提供了mysql兼容的协议;
-
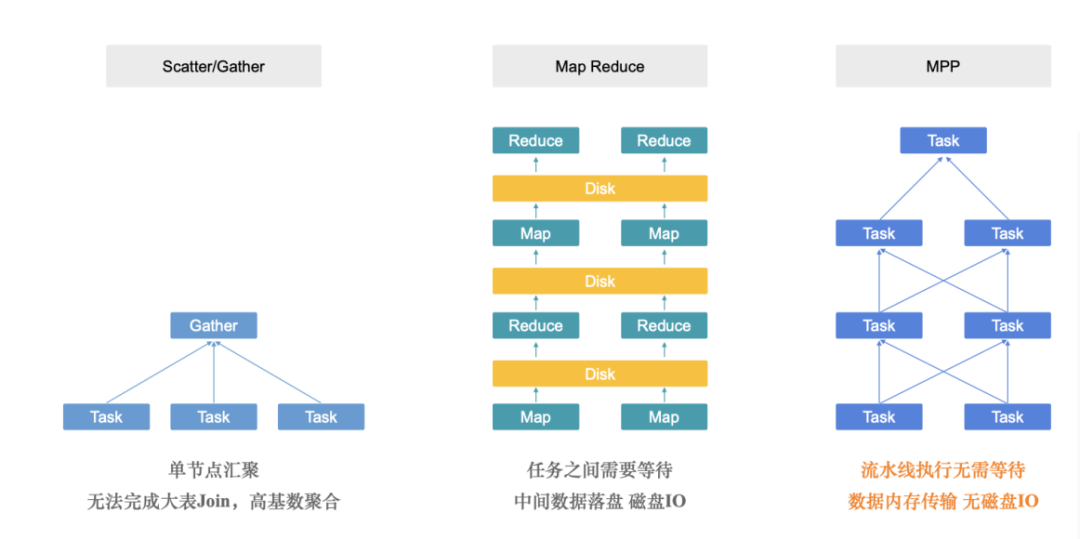
跟传统架构的区别:
-
通过分布式拆分成不同的task,再在中心节点汇聚;
-
druid、clickhouse都是类型;
-
MR是任务的拆分、落盘;
-
doris是MPP架构,任务之间分成task、全都在内存中执行和传输,所有任务都是流水线,没有磁盘IO,适用于低延迟亚秒级查询;
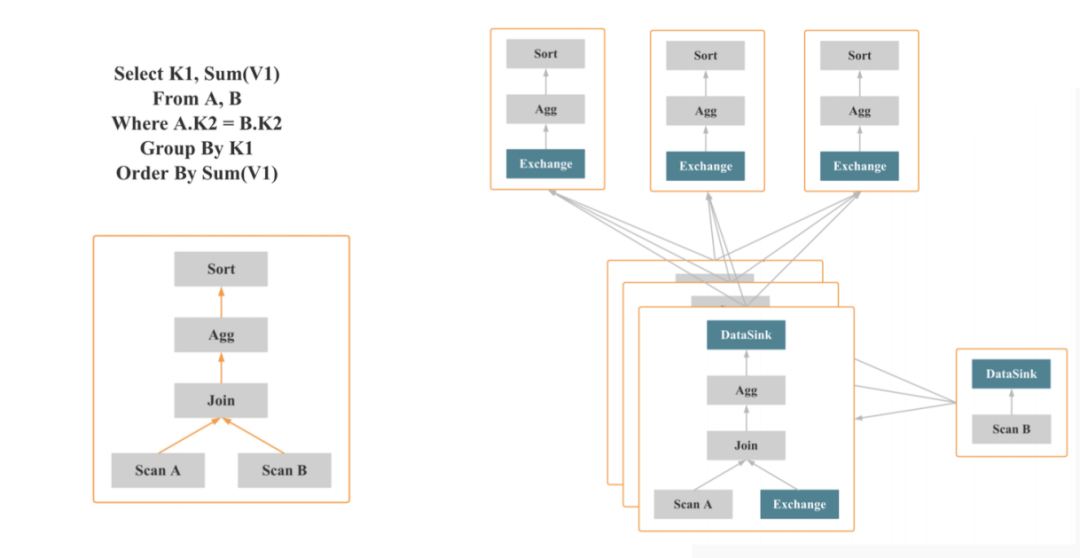
sql查询进入doris的过程:
-
解析成逻辑执行计划-A|B两个表的scan -> Join ->聚合(group by K1 sum(V1) ),聚合操作 -> 最后再sort by sum(V1)排序 ;
-
MPP架构就是可以把执行计划转换成物理层面的,
-
假设有3个节点,会把执行计划类似fregment(有节点的组合)
-
scanB扫描B表的数据,可能通过一个brokercust、dataSink和exchange这样的节点会把fregment串联起来,每个fregment中会有不同的计算节点;比如数据经过广播跟A表join,之后进行聚合操作;
-
一个MPP就是支持两层的聚合,每个节点做完聚合操作后最后汇总到一个节点再做一次;在doris中支持在中间做一次shuffle,shuffle完成之后在上层再做一次聚合,这样子就不会有大单点的计算瓶颈。再推给上层去做排序。
-
根据不同的机器每个fregment会拆成instent它执行的子单元,就可以充分发挥MPP的多基多合的能力,根据机器数量和设置的并行度,充分利用资源。
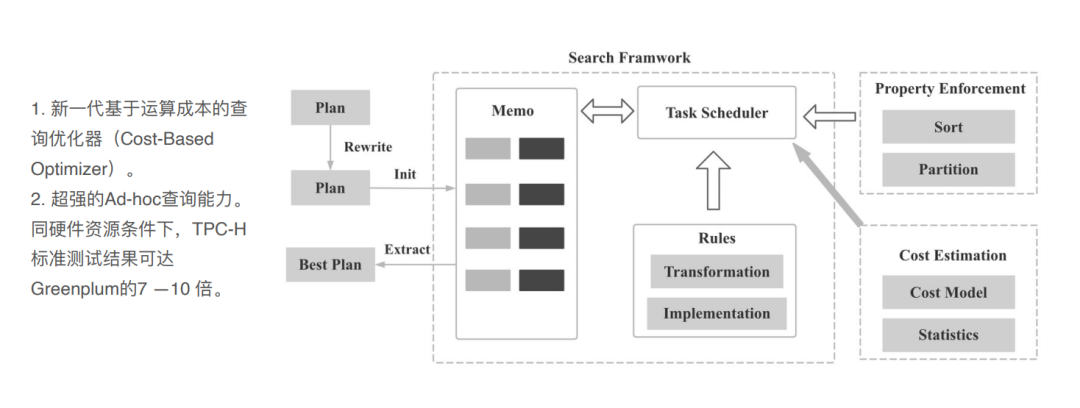
智能CBO查询优化器
-
dorisDB跟开源的apache doris有几个改造点:
-
在FE这边的改造:
-
plan会根据cpu的成本预估,加入更多的统计信息(列的基数、直方图等等),能够更准确的预估表的执行计划。
-
两个表join时,使用brokercast join还是shuffle join还是其他join的一些方式,左右表过滤出来应该有多少行数等,哪个表作为左右表等;聚合函数用1层还是2层等等
极速向量化引擎
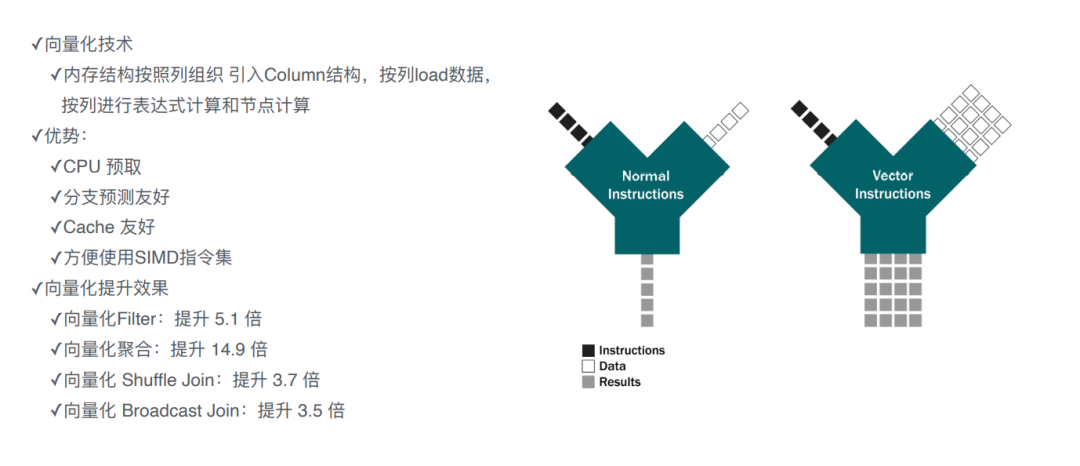
-
BE
-
计算+存储,
-
计算层: 向量化引擎,即把内存结构按照列的方式进行组织;跟之前按行来处理不一样的地方是可以充分利用全新的cpu指令(单、多数据流),一条指令可以处理很多的数据。
高效的列式存储

-
列式存储:
-
支持排序,选择排序键,二分查找等方式。
-
支持二级索引:bitmap、 bloom filter等
-
会把复杂查询推到存储层。
现代化物化视图加速
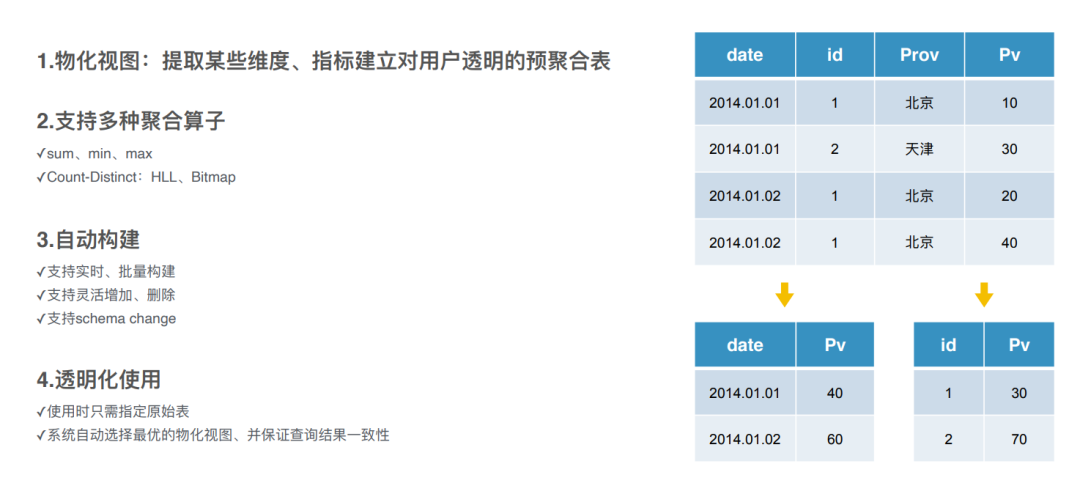
-
不同场景下预处理:
-
kylin的cube,doris中的物化视图;
-
doris的物化视图跟clickhouse的区别:clickhouse中是直接去查询它的物化视图,doris中会有一个路由,查询的时候还是原表它会路由到最好的一张物化视图中。
实时构建DWS数据
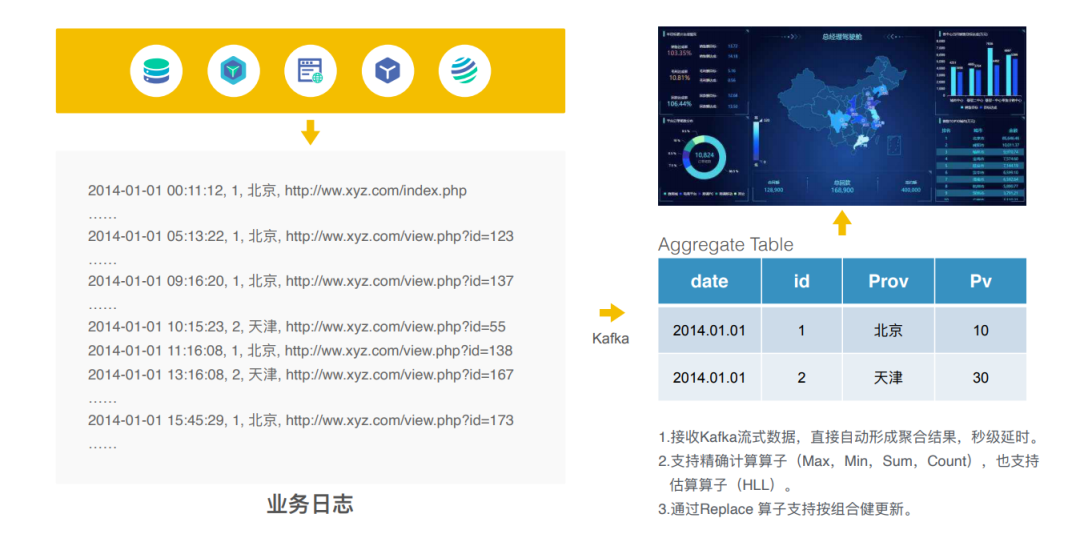
-
实时数据分析报表的场景:
-
flume-kafka-doris(进行实时数据的聚合)-BI工具的展示
-
Join优化 ― colocated Join
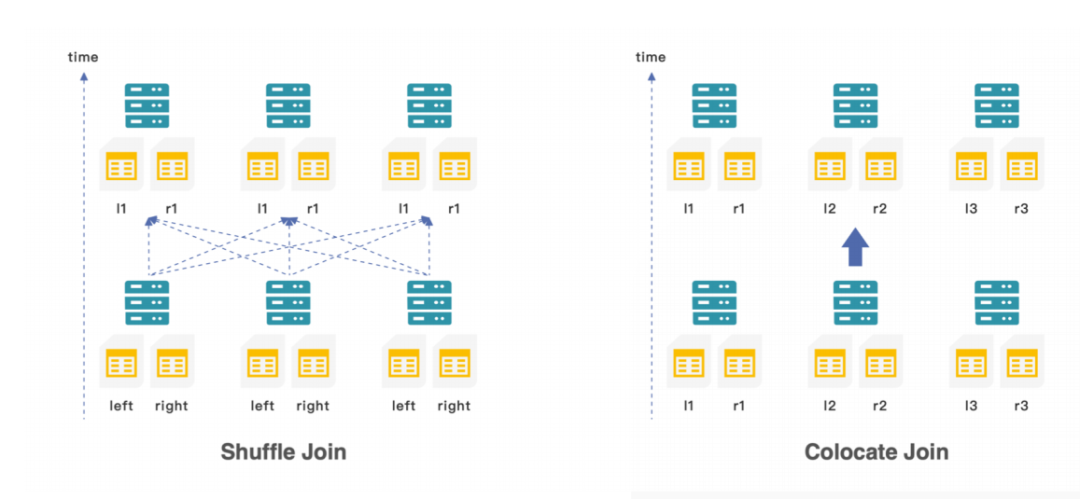
-
doris多表关联有一个明显的优势:
-
原来的建模倾向于宽表,一旦维度的变更就会导致数据的重新刷新,灵活性降低。
-
现场关联,秒级查询返回;
-
除了高效的shuffle join外还会有一个colocate join 降低特别大的两个表的数据传输量。
-
colocate join 在建表时就数据的分布方式,相同的数据可以哈希到一个桶中,所有的数据都可以在本地进行关联操作,最后再在上层做一次数据的聚合。
极简运维,弹性伸缩
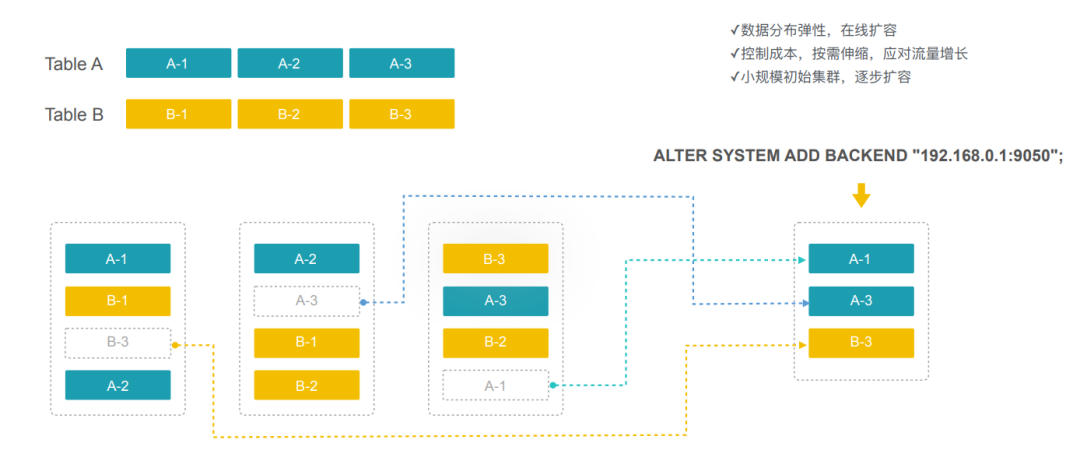
设计原理
海量分布式存储系统Doris原理概述
Doris是一个海量分布式 KV 存储系统,其设计目标是支持中等规模高可用可伸缩的 KV 存储集群。Doris可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。部署规模,建议部署4-100+台服务器。
逻辑架构
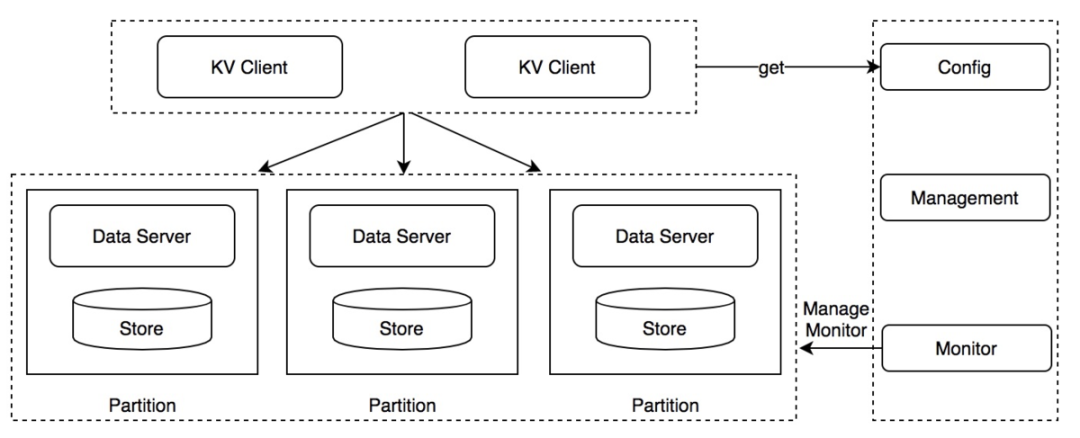
Doris采用两层架构,Client 和 DataServer+Store。
有四个核心组件,Client、DataServer、Store、Administration。
应用程序通过Client SDK进行Doris的访问,每台服务器上部署一个Data Sever做服务器的管理,每台服务器上有自己的存储Store,整个集群的数据存储,每台机器独立部署。数据通过路由选择写入到不同的机器中。
Administration为管理中心,提供配置、管理和监控。
config指应用程序启动一个Data Server,在启动时要配置管理中心的ip地址,通关管理中心。管理中心会修改配置项感知到集群中加了新机器,对新机器管理,扩容等。待机器处于可用状态,将该机器的配置项通知给KV Client。从而KV Client进行新的路由选择。扩容、下线机器等的控制台界面通过Management管理。Monitor监控机器是否正常。
KV Storage 概念模型
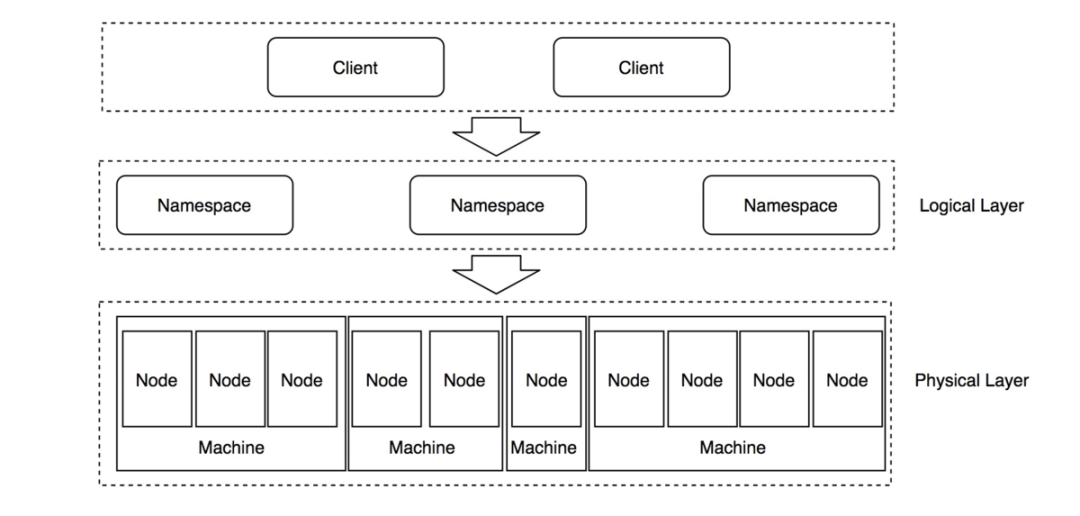
client写数据,绑定产品的namespace(逻辑隔离),构成新key,路由到具体机器上读写。
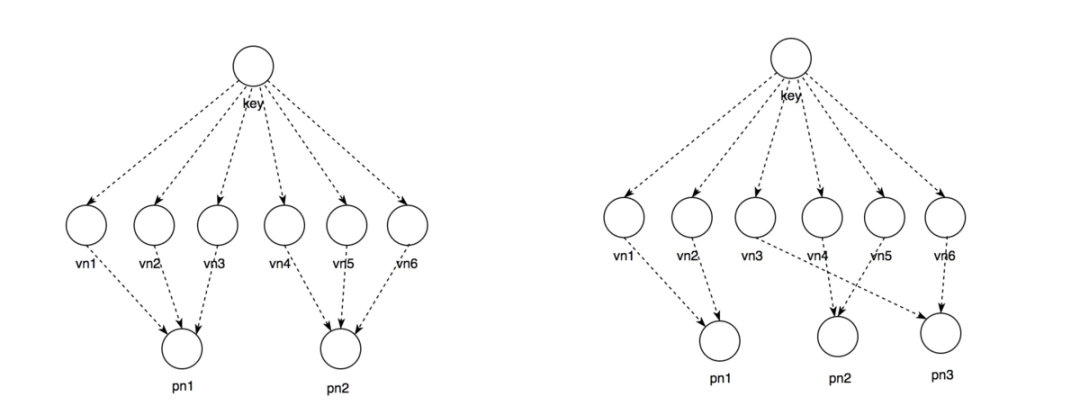
-
路由解析算法是设计的一个关键点,决定集群的管理方式,也决定了集群扩容的复杂性和难度。
-
Doris的算法类似redis,有桶的概念,key映射到1w个虚拟节点,虚拟节点在映射到物理节点。
-
由于Doris设计时,用于4-100+规模的集群。因此,Doris分了1w个虚拟节点,当服务器超过100会导致负载不均衡,1000会更差,相当于每一个集群上有10个虚拟节点,虚拟节点会有10%的影响。
-
扩容时,需要调节虚拟节点指向新的位置。具体过程为,暴利轮询新节点添加后,一个服务器上应该承载的虚拟节点个数,将超出的虚拟节点迁移到新机器即可。如上图左图有2个物理节点,扩容后,有3个物理节点,变为右图。
基本访问架构
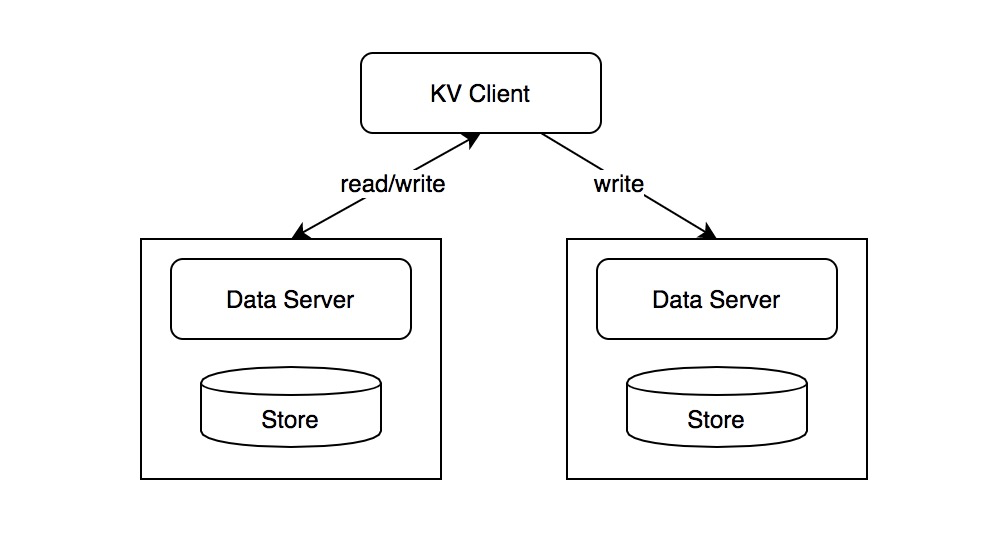
-
为了保证高可用。doris所有服务分成2个组,两组服务器对等。两个group是可以有不同数量的服务器。
-
写操作时,client的路由算法在两个group分别选2个服务器,分别(同时)写入,两个服务器全部返回后,再继续向下进行。读操作时,从两个服务器随机选一个读。这样,提高可用性,数据持久性,不会丢失。
监控检测
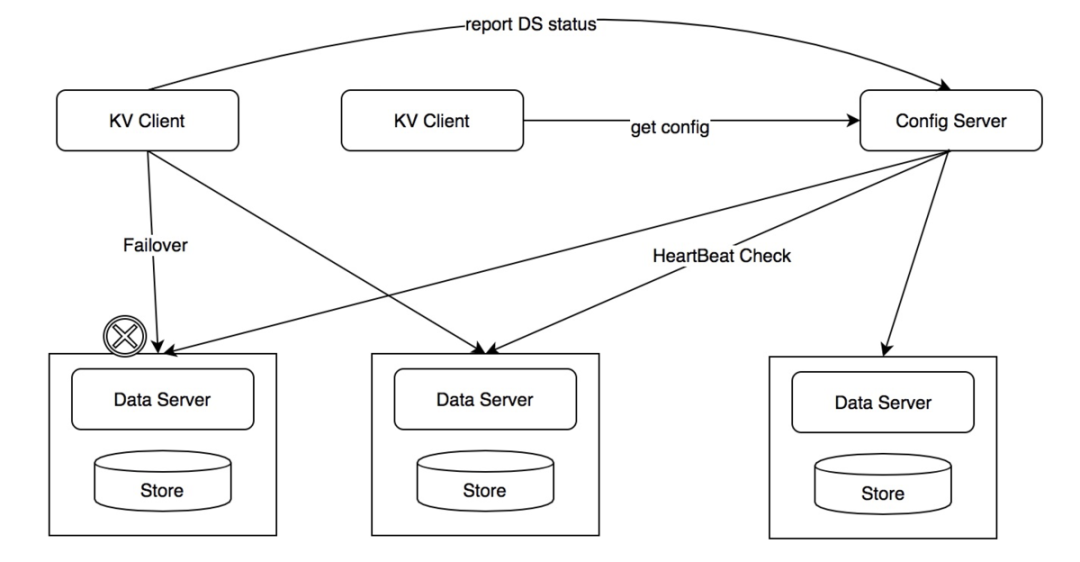
集群管理的重要角色Config Server,有一个功能是负责发现故障服务器。
发现故障的方式有2种:
-
ConfigServer对DataServer心跳检测
-
Client访问时Fail报告
通常心跳检测是慢的,几秒进行一次心跳检测。更多时候,是client Fail失败报告发现无效服务器,当写入失败时,Client会告诉Config Server。Config Server校验,也访问失败,则通知其他client。
基本原理
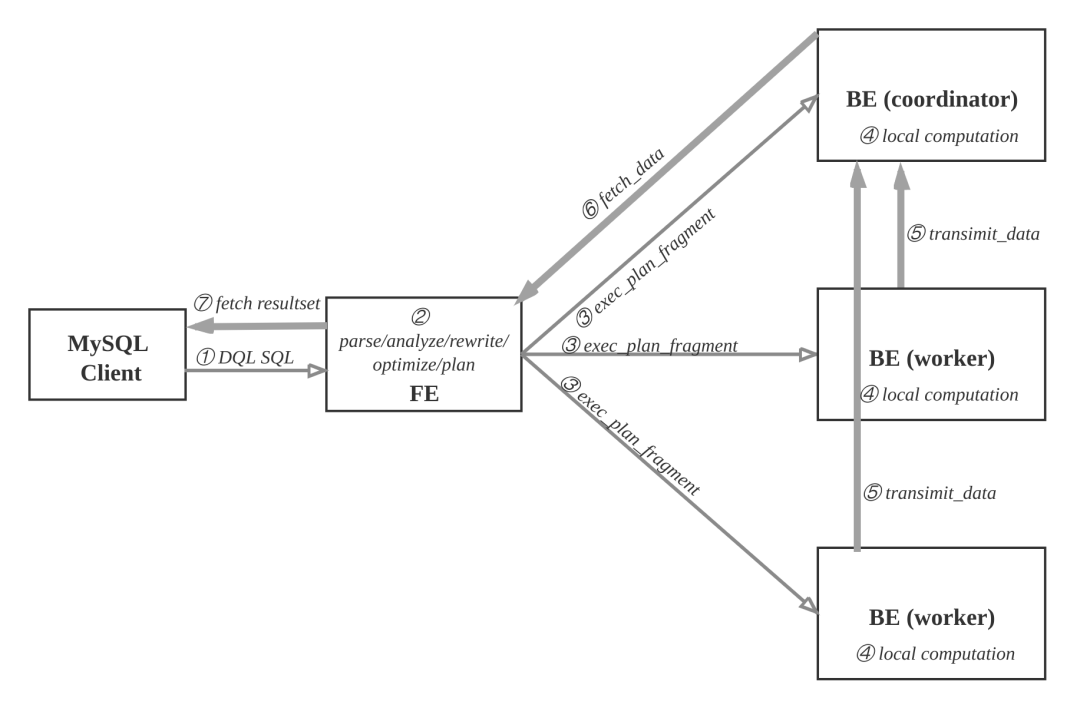
读取数据流程
用户可使用MySQL客户端连接FE,执行SQL查询, 获得结果。
查询流程如下:
① MySQL客户端执行DQL SQL命令。
② FE解析, 分析, 改写, 优化和规划, 生成分布式执行计划。
③ 分布式执行计划由 若干个可在单台be上执行的plan fragment构成, FE执行exec_plan_fragment, 将plan fragment分发给BE,指定其中一台BE为coordinator。
④ BE执行本地计算, 比如扫描数据。
⑤ 其他BE调用transimit_data将中间结果发送给BE coordinator节点汇总为最终结果。
⑥ FE调用fetch_data获取最终结果。
⑦ FE将最终结果发送给MySQL client。
执行计划在BE上的实际执行过程比较复杂, 采用向量化执行方式,比如一个算子产生4096个结果,输出到下一个算子参与计算,而非batch方式或者one-tuple-at-a-time。
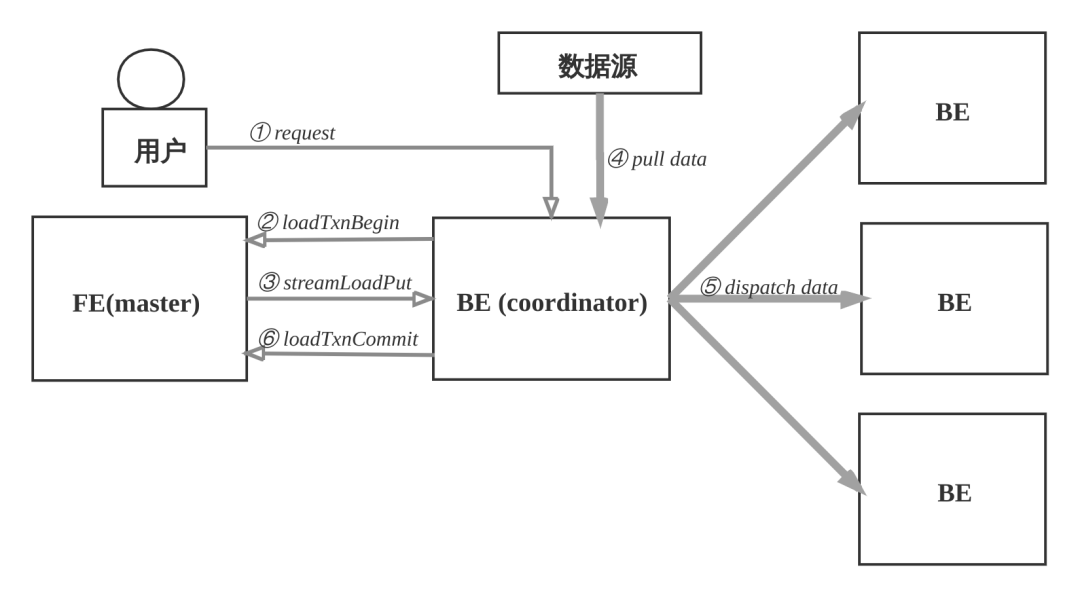
导入数据流程
用户创建表之后, 导入数据填充表.
-
支持导入数据源有: 本地文件, HDFS, Kafka和S3.
-
支持导入方式有: 批量导入, 流式导入, 实时导入.
-
支持的数据格式有: CSV, Parquet, ORC等.
-
导入发起方式有: 用RESTful接口, 执行SQL命令.
数据导入的流程如下:
① 用户选择一台BE作为协调者, 发起数据导入请求, 传入数据格式, 数据源和标识此次数据导入的label, label用于避免数据重复导入. 用户也可以向FE发起请求, FE会把请求重定向给BE.
② BE收到请求后, 向FE master节点上报, 执行loadTxnBegin, 创建全局事务。 因为导入过程中, 需要同时更新base表和物化索引的多个bucket, 为了保证数据导入的一致性, 用事务控制本次导入的原子性.
③ BE创建事务成功后, 执行streamLoadPut调用, 从FE获得本次数据导入的计划. 数据导入, 可以看成是将数据分发到所涉及的全部的tablet副本上, BE从FE获取的导入计划包含数据的schema信息和tablet副本信息.
④ BE从数据源拉取数据, 根据base表和物化索引表的schema信息, 构造内部数据格式.
⑤ BE根据分区分桶的规则和副本位置信息, 将发往同一个BE的数据, 批量打包, 发送给BE, BE收到数据后, 将数据写入到对应的tablet副本中.
⑥ 当BE coordinator节点完成此次数据导入, 向FE master节点执行loadTxnCommit, 提交全局事务, 发送本次数据导入的 执行情况, FE master确认所有涉及的tablet的多数副本都成功完成, 则发布本次数据导入使数据对外可见, 否则, 导入失败, 数据不可见, 后台负责清理掉不一致的数据.
修改元数据流程
更改元数据的操作有: 创建数据库, 创建表, 创建物化视图, 修改schema等等. 这样的操作需要:
-
持久化到永久存储的设备上;
-
保证高可用, 复制FE多实例上, 避免单点故障;
-
有的操作需要在BE上生效, 比如创建表时, 需要在BE上创建tablet副本.
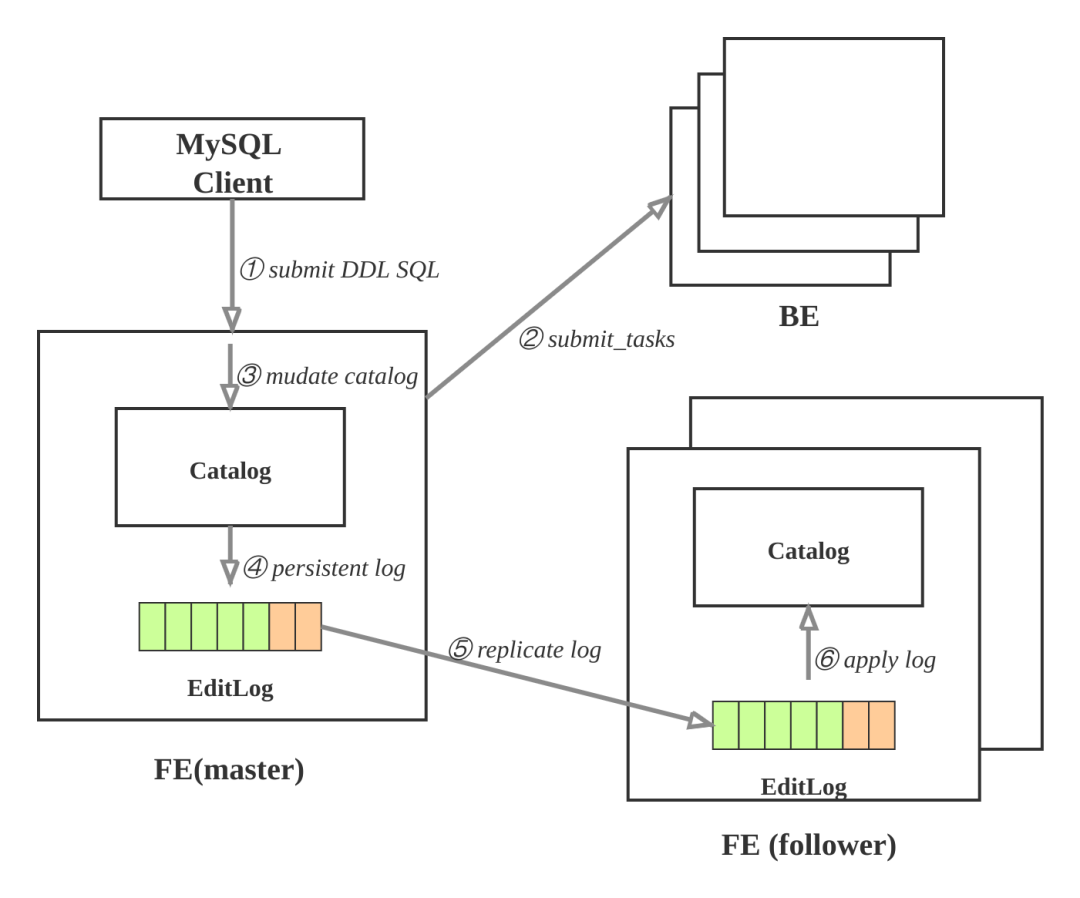
元数据的更新操作流程如下:
① 用户使用MySQL client执行SQL的DDL命令, 向FE的master节点发起请求; 比如: 创建表.
② FE检查请求合法性, 然后向BE发起同步命令, 使操作在BE上生效; 比如: FE确定表的列类型是否合法, 计算tablet的副本的放置位置, 向BE发起请求, 创建tablet副本.
③ BE执行成功, 则修改内存的Catalog. 比如: 将table, partition, index, tablet的副本信息保存在Catalog中.
④ FE追加本次操作到EditLog并且持久化.
⑤ FE通过复制协议将EditLog的新增操作项同步到FE的follower节点.
⑥ FE的follower节点收到新追加的操作项后, 在自己的Catalog上按顺序播放, 使得自己状态追上FE master节点.
上述执行环节出现失败, 则本次元数据修改失败.
表设计详解
数据存储基本原理
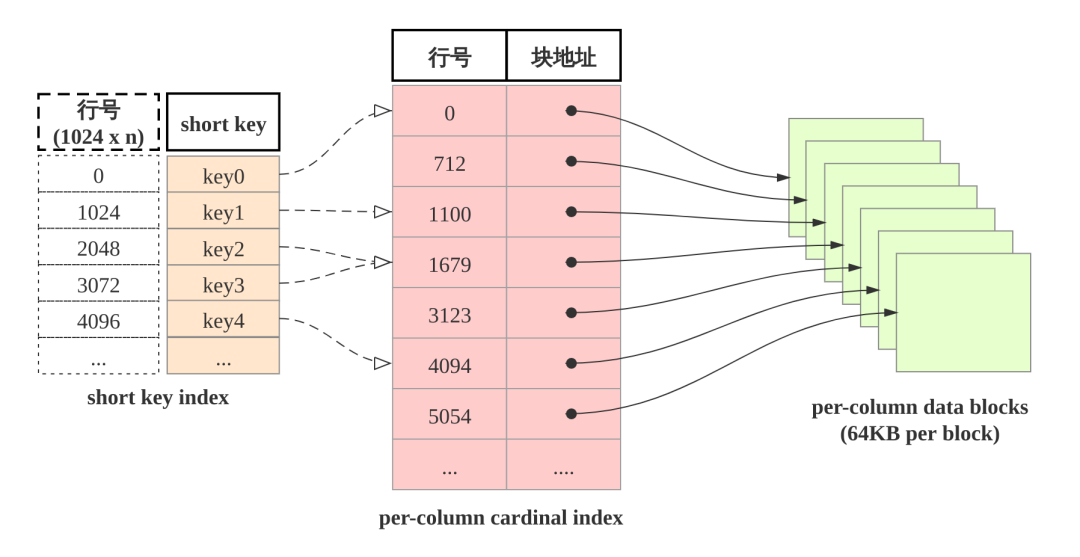
查找维度列的前缀的查找过程为: 先查找shortkey index, 获得逻辑块的起始行号, 查找维度列的行号索引, 获得目标列的数据块, 读取数据块, 然后解压解码, 从数据块中找到维度列前缀对应的数据项.
加速数据处理
-
列式存储
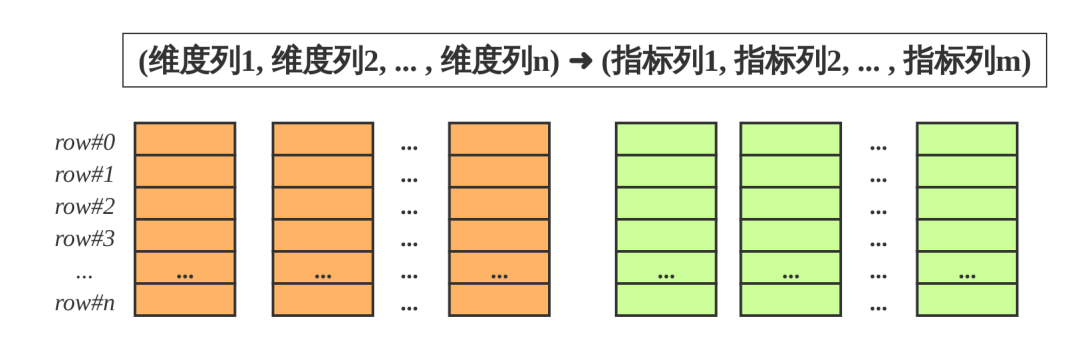
DorisDB的表和关系型数据相同, 由行和列构成. 每行数据对应用户一条记录, 每列数据有相同数据类型. 所有数据行的列数相同, 可以动态增删列. DorisDB中, 一张表的列可以分为维度列(也成为key列)和指标列(value列), 维度列用于分组和排序, 指标列可通过聚合函数SUM, COUNT, MIN, MAX, REPLACE, HLL_UNION, BITMAP_UNION等累加起来. 因此, DorisDB的表也可以认为是多维的key到多维指标的映射.
在DorisDB中, 表中数据按列存储, 物理上, 一列数据会经过分块编码压缩等操作, 然后持久化于非易失设备, 但在逻辑上, 一列数据可以看成由相同类型的元素构成的数组. 一行数据的所有列在各自的列数组中保持对齐, 即拥有相同的数组下标, 该下标称之为序号或者行号. 该序号是隐式, 不需要存储的, 表中的所有行按照维度列, 做多重排序, 排序后的位置就是该行的行号.
查询时, 如果指定了维度列的等值条件或者范围条件, 并且这些条件中维度列可构成表维度列的前缀, 则可以利用数据的有序性, 使用range-scan快速锁定目标行.
-
稀疏索引
当范围查找时, 如何快速地找到起始的目标行呢? 答案是shortkey index. 如下图所示: shortkey索引为稀疏索引,
表模型介绍
为了描述方便, 我们借鉴关系模式中的主键概念, 称DorisDB表的维度列的取值构成数据表的排序键, DorisDB的排序键对比传统的主键具有:
-
数据表所有维度列构成排序键, 所以后文中提及的排序列, key列本质上都是维度列.
-
排序键可重复, 不必满足唯一性约束.
-
数据表的每一列, 以排序键的顺序, 聚簇存储.
-
排序键使用稀疏索引.
对于摄入(ingest)的主键重复的多行数据, 填充于(populate)数据表中时, 按照三种处理方式划分:
-
明细模型: 表中存在主键重复的数据行, 和摄入数据行一一对应, 用户可以召回所摄入的全部历史数据.
-
聚合模型: 表中不存在主键重复的数据行, 摄入的主键重复的数据行合并为一行, 这些数据行的指标列通过聚合函数合并, 用户可以召回所摄入的全部历史数据的累积结果, 但无法召回全部历史数据.
-
更新模型: 聚合模型的特殊情形, 主键满足唯一性约束, 最近摄入的数据行, 替换掉其他主键重复的数据行. 相当于在聚合模型中, 为数据表的指标列指定的聚合函数为REPLACE, REPLACE函数返回一组数据中的最新数据.
需要注意:
-
建表语句, 排序列的定义必须出现在指标列定义之前.
-
排序列在建表语句中的出现次序为数据行的多重排序的次序.
-
排序键的稀疏索引(shortkey index)会选择排序键的若干前缀列.
明细模型
DorisDB建表的默认模型是明细模型。
一般用明细模型来处理的场景有如下特点:
-
需要保留原始的数据(例如原始日志,原始操作记录等)来进行分析;
-
查询方式灵活, 不局限于预先定义的分析方式, 传统的预聚合方式难以命中;
-
数据更新不频繁。导入数据的来源一般为日志数据或者是时序数据, 以追加写为主要特点, 数据产生后就不会发生太多变化。
聚合模型
在数据分析领域,有很多需要对数据进行统计和汇总操作的场景。比如:
-
分析网站或APP访问流量,统计用户的访问总时长、访问总次数;
-
广告厂商为广告主提供的广告点击总量、展示总量、消费统计等;
-
分析电商的全年的交易数据, 获得某指定季度或者月份的, 各人口分类(geographic)的爆款商品.
适合采用聚合模型来分析的场景具有如下特点:
-
业务方进行的查询为汇总类查询,比如sum、count、 max等类型的查询;
-
不需要召回原始的明细数据;
-
老数据不会被频繁更新,只会追加新数据。
更新模型
有些分析场景之下,数据会更新, DorisDB采用更新模型来满足这种需求。比如在电商场景中,定单的状态经常会发生变化,每天的订单更新量可突破上亿。在这种量级的更新场景下进行实时数据分析,如果在明细模型下通过delete+insert的方式,是无法满足频繁更新需求的; 因此, 用户需要使用更新模型来满足数据分析需求。
以下是一些适合更新模型的场景特点:
-
已经写入的数据有大量的更新需求;
-
需要进行实时数据分析。
数据分布
数据分布方式
-
数据分布:数据分布是将数据划分为子集, 按一定规则, 均衡地分布在不同节点上,以期最大限度地利用集群的并发性能。
-
短查询:short-scan query,指扫描数据量不大,单机就能完成扫描的查询。
-
长查询:long-scan query,指扫描数据量大,多机并行扫描能显著提升性能的查询。
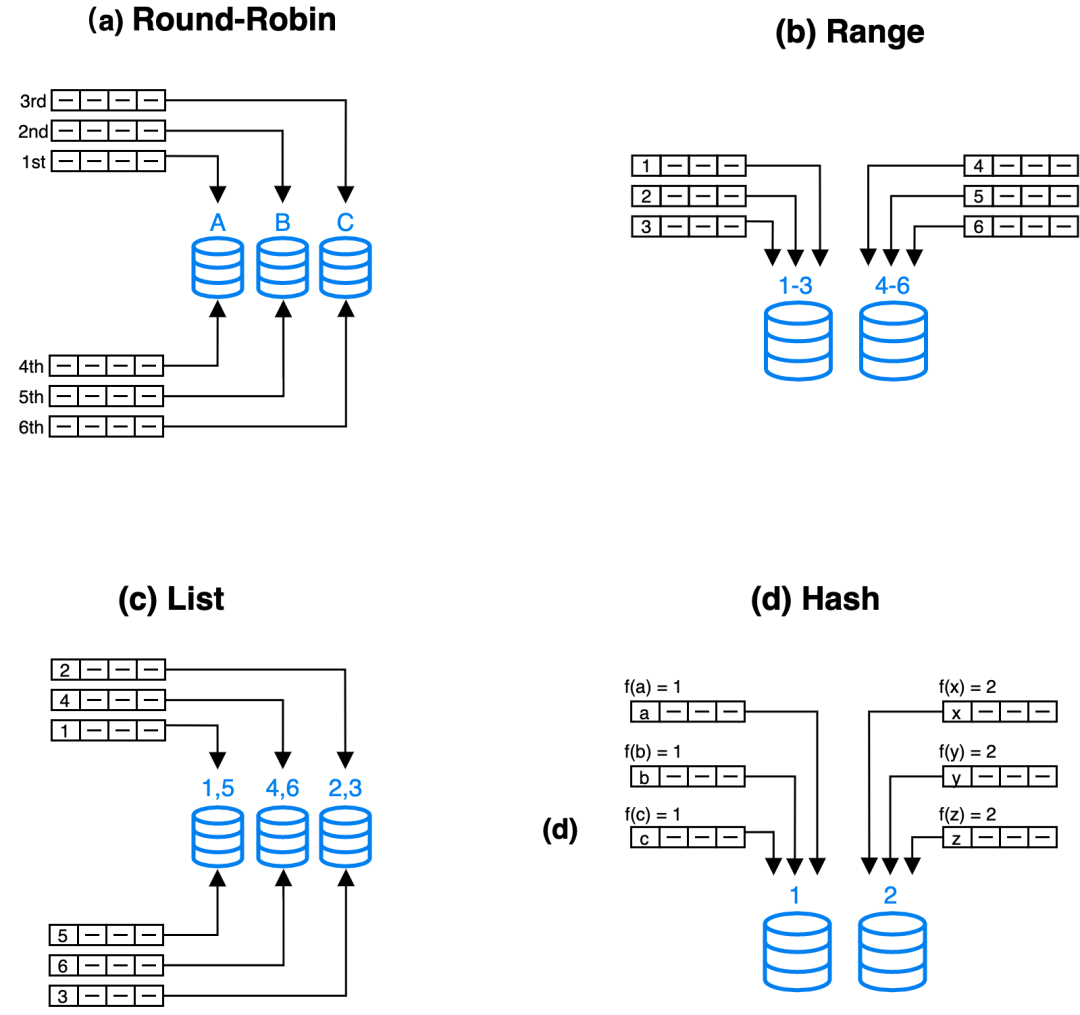
常见的四种数据分布方式有:(a) Round-Robin、(b) Range、(c) List和(d) Hash (DeWitt and Gray, 1992)。如下图所示:
-
Round-Robin : 以轮转的方式把数据逐个放置在相邻节点上。
-
Range : 按区间进行数据分布,图中区间[1-3],[4-6]分别对应不同Range。
-
List : 直接基于离散的各个取值做数据分布,性别、省份等数据就满足这种离散的特性。每个离散值会映射到一个节点上,不同的多个取值可能也会映射到相同节点上。
-
Hash : 按哈希函数把数据映射到不同节点上。
如何选择排序键
排序键基本原理
-
数据倾斜:业务方如果确定数据有很大程度的倾斜,那么建议采用多列组合的方式进行数据分桶,而不是只单独采用倾斜度大的列做分桶。
-
高并发:分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
-
高吞吐:尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
dynamic_partition.enable : 是否开启动态分区特性,可指定为 TRUE 或 FALSE。如果不填写,默认为 TRUE。
dynamic_partition.time_unit : 动态分区调度的粒度,可指定为 DAY/WEEK/MONTH。
-
指定为 DAY 时,分区名后缀需为yyyyMMdd,例如20200325。图1 就是一个按天分区的例子,分区名的后缀满足yyyyMMdd。 PARTITION p20200321 VALUES LESS THAN ("2020-03-22"), PARTITION p20200322 VALUES LESS THAN ("2020-03-23"), PARTITION p20200323 VALUES LESS THAN ("2020-03-24"), PARTITION p20200324 VALUES LESS THAN ("2020-03-25")
-
指定为 WEEK 时,分区名后缀需为yyyy_ww,例如2020_13代表2020年第13周。
-
指定为 MONTH 时,动态创建的分区名后缀格式为 yyyyMM,例如 202003。
dynamic_partition.start: 动态分区的开始时间。以当天为基准,超过该时间范围的分区将会被删除。如果不填写,则默认为Integer.MIN_VALUE 即 -2147483648。
dynamic_partition.end: 动态分区的结束时间。 以当天为基准,会提前创建N个单位的分区范围。
dynamic_partition.prefix : 动态创建的分区名前缀。
dynamic_partition.buckets : 动态创建的分区所对应的分桶数量。
-
指定为 DAY 时,分区名后缀需为yyyyMMdd,例如20200325。
-
指定为 WEEK 时,分区名后缀需为yyyy_ww,例如 2020_13, 代表2020年第13周。
-
指定为 MONTH 时,动态创建的分区名后缀格式为 yyyyMM,例如 202003。
DorisDB中为加速查询,在内部组织并存储数据时,会把表中数据按照指定的列进行排序,这部分用于排序的列(可以是一个或多个列),可以称之为Sort Key。明细模型中Sort Key就是指定的用于排序的列(即 DUPLICATE KEY 指定的列),聚合模型中Sort Key列就是用于聚合的列(即 AGGREGATE KEY 指定的列),更新模型中Sort Key就是指定的满足唯一性约束的列(即 UNIQUE KEY 指定的列)。
核心功能
存储结构设计解析
Doris是基于MPP架构的交互式SQL数据仓库,主要用于解决近实时的报表和多维分析。Doris高效的导入、查询离不开其存储结构精巧的设计。
设计目标
-
批量导入,少量更新
-
绝大多数的读请求
-
宽表场景,读取大量行,少量列
-
非事务场景
-
良好的扩展性
储存文件格式
1、存储目录结构
存储层对存储数据的管理通过storage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录下存放具体的tablet,按照tablet_id命名子目录。
Segment文件存放在tablet_id目录下按SchemaHash管理。Segment文件可以有多个,一般按照大小进行分割,默认为256MB。其中,Segment v2文件命名规则为:${rowset_id}_${segment_id}.dat。
2、Segment v2文件结构
Segment整体的文件格式分为数据区域,索引区域和footer三个部分
-
Data Region: 用于存储各个列的数据信息,这里的数据是按需分page加载的
-
Index Region: Doris中将各个列的index数据统一存储在Index Region,这里的数据会按照列粒度进行加载,所以跟列的数据信息分开存储
-
Footer信息
SegmentFooterPB: 定义文件的元数据信息
4个字节的FooterPB内容的checksum
4个字节的FileFooterPB消息长度,用于读取FileFooterPB
8个字节的MAGIC CODE,之所以在末位存储,是方便不同的场景进行文件类型的识别
Footer信息
Footer信息段在文件的尾部,存储了文件的整体结构,包括数据域的位置,索引域的位置等信息,其中有SegmentFooterPB,CheckSum,Length,MAGIC CODE 4个部分。
SegmentFooterPB数据结构如下:
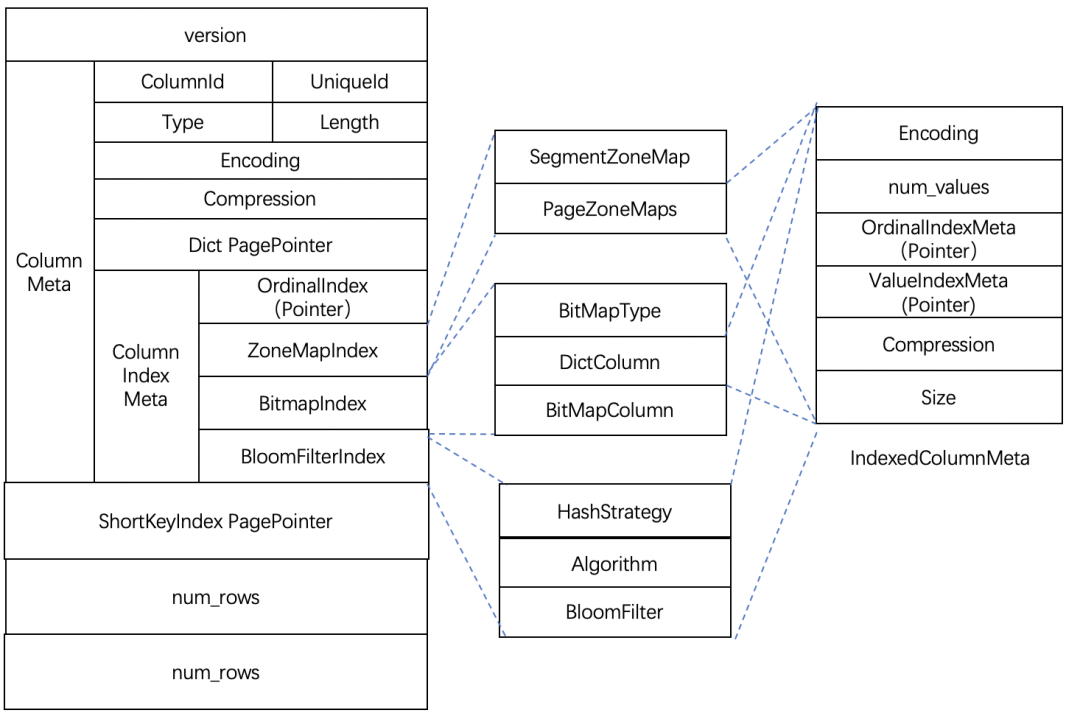
SegmentFooterPB采用了PB格式进行存储,主要包含了列的meta信息、索引的meta信息,Segment的short key索引信息、总行数。
1、列的meta信息
-
ColumnId:当前列在schema中的序号
-
UniqueId:全局唯一的id
-
Type:列的类型信息
-
Length:列的长度信息
-
Encoding:编码格式
-
Compression:压缩格式
-
Dict PagePointer:字典信息
2、列索引的meta信息
-
OrdinalIndex:存放列的稀疏索引meta信息。
-
ZoneMapIndex:存放ZoneMap索引的meta信息,内容包括了最大值、最小值、是否有空值、是否没有非空值。SegmentZoneMap存放了全局的ZoneMap信息,PageZoneMaps则存放了每个页面的统计信息。
-
BitMapIndex:存放BitMap索引的meta信息,内容包括了BitMap类型,字典数据BitMap数据。
-
BloomFilterIndex:存放了BloomFilter索引信息。
Ordinal Index (一级索引)
Ordinal Index索引提供了通过行号来查找Column Data Page数据页的物理地址。Ordinal Index能够将按列存储数据按行对齐,可以理解为一级索引。其他索引查找数据时,都要通过Ordinal Index查找数据Page的位置。因此,这里先介绍Ordinal Index索引。
在一个segment中,数据始终按照key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序顺序进行存储,即key的排序决定了数据存储的物理结构。确定了列数据的物理结构顺序,在写入数据时,Column Data Page是由Ordinal index进行管理,Ordinal index记录了每个Column Data Page的位置offset、大小size和第一个数据项行号信息,即Ordinal。这样每个列具有按行信息进行快速扫描的能力。
列数据存储
Column的data数据按照Page为单位分块存储,每个Page大小一般为64*1024个字节。
Page在存储的位置和大小由ordinal index管理。
1、data page存储结构
DataPage主要为Data部分、Page Footer两个部分。
Data部分存放了当前Page的列的数据。当允许存在Null值时,对空值单独存放了Null值的Bitmap,由RLE格式编码通过bool类型记录Null值的行号。
Page Footer包含了Page类型Type、UncompressedSize未压缩时的数据大小、FirstOrdinal当前Page第一行的RowId、NumValues为当前Page的行数、NullMapSize对应了NullBitmap的大小。
2、数据压缩
针对不同的字段类型采用了不同的编码。默认情况下,针对不同类型采用的对应关系如下:
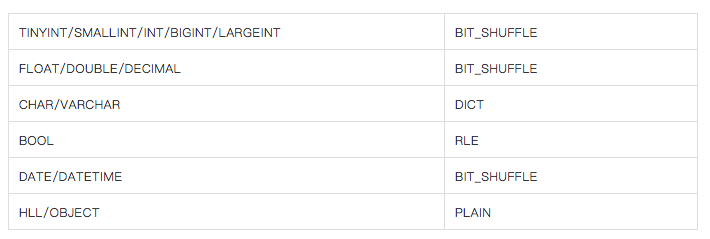
默认采用LZ4F格式对数据进行压缩。
存储结构
1、存储结构
Short Key Index前缀索引,是在key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。这里Short Key Index索引也采用了稀疏索引结构,在数据写入过程中,每隔一定行数,会生成一个索引项。这个行数为索引粒度默认为1024行,可配置。
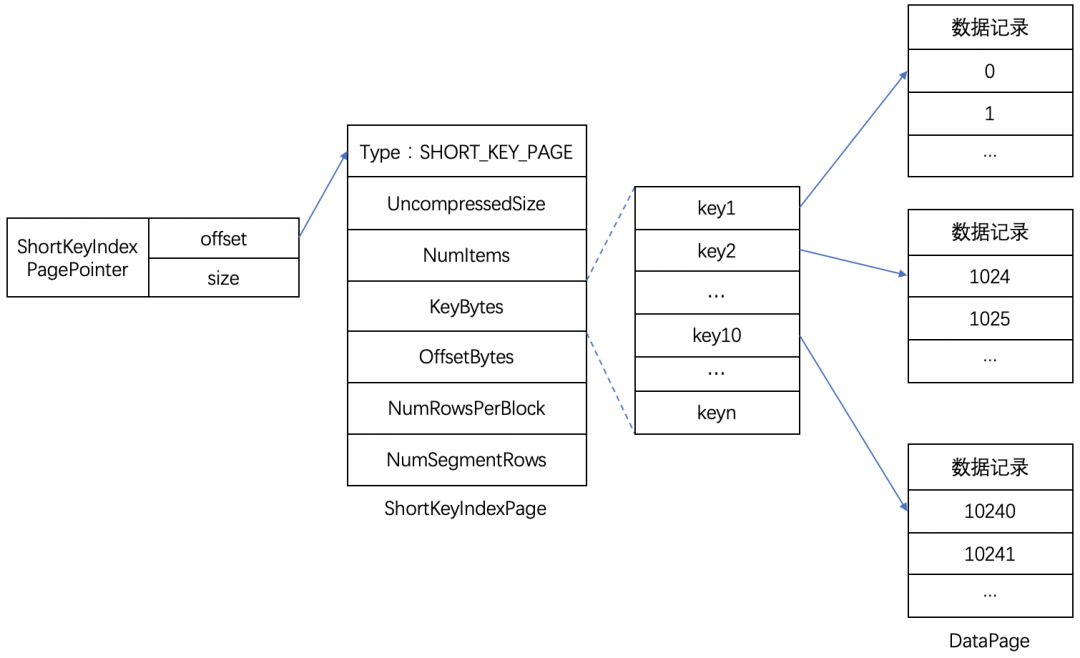
其中,KeyBytes中存放了索引项数据,OffsetBytes存放了索引项在KeyBytes中的偏移。
2、索引生成规则
Short Key Index采用了前36 个字节,作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。
ZoneMap Index索引
ZoneMap索引存储了Segment和每个列对应每个Page的统计信息。这些统计信息可以帮助在查询时提速,减少扫描数据量,统计信息包括了Min最大值、Max最小值、HashNull空值、HasNotNull不全为空的信息。
BloomFilter
当一些字段不能利用Short Key Index并且字段存在区分度比较大时,Doris提供了BloomFilter索引。
Bitmap Index索引
Doris还提供了BitmapIndex用来加速数据的查询。
写入流程、删除流程分析
Doris 针对不同场景支持了多种形式的数据写入方式,其中包括了从其他存储源导入 Broker Load、http 同步数据导入 Stream Load、例行的 Routine Load 导入和 Insert Into 写入等。同时导入流程会涉及 FE 模块(主要负责导入规划生成和导入任务的调度工作)、BE 模块(主要负责数据的 ETL 和存储)、Broker 模块(提供 Doris 读取远端存储系统中文件的能力)。其中 Broker 模块仅在 Broker Load 类型的导入中应用。
下面以 Stream Load 写入为例子,描述了 Doris 的整体的数据写入流程如下图所示:
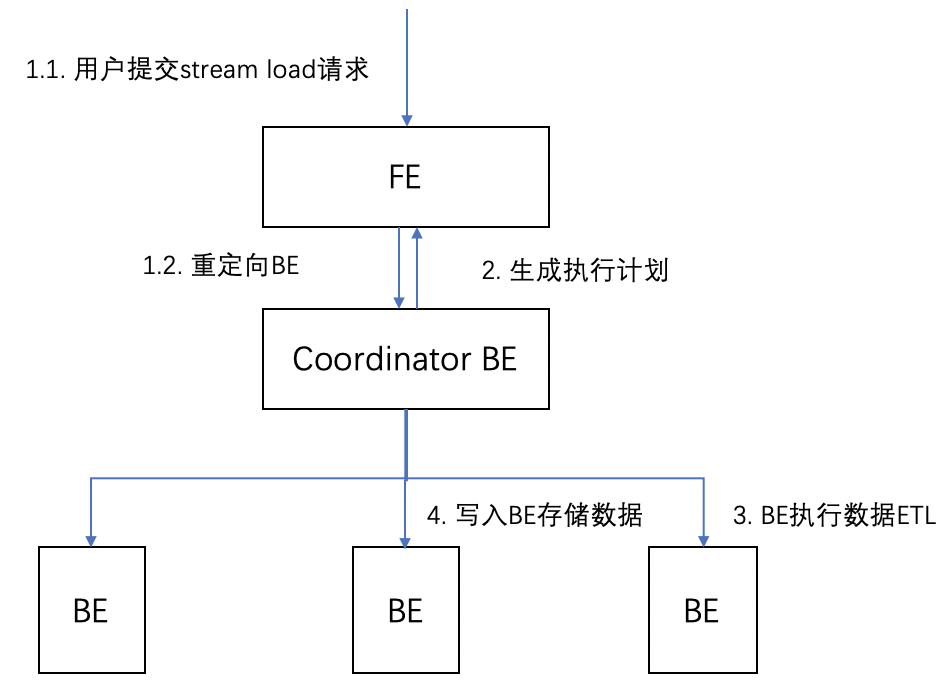
流程描述如下:
1、FE 接收用户的写入请求,并随机选出 BE 作为 Coordinator BE。将用户的请求重定向到这个 BE 上。
2、Coordinator BE 负责接收用户的数据写入请求,同时请求 FE 生成执行计划并对调度、管理导入任务 LoadJob 和导入事务。
3、Coordinator BE 调度执行导入计划,执行对数据校验、清理之后。
4、数据写入到 BE 的存储层中。在这个过程中会先写入到内存中,写满一定数据后按照存储层的数据格式写入到物理磁盘上。
数据分发流程
数据在经过清洗过滤后,会通过 Open/AddBatch 请求分批量的将数据发送给存储层的 BE 节点上。在一个 BE 上支持多个 LoadJob 任务同时并发写入执行。LoadChannelMgr 负责管理了这些任务,并对数据进行分发。
数据分发和写入过程如下图所示:
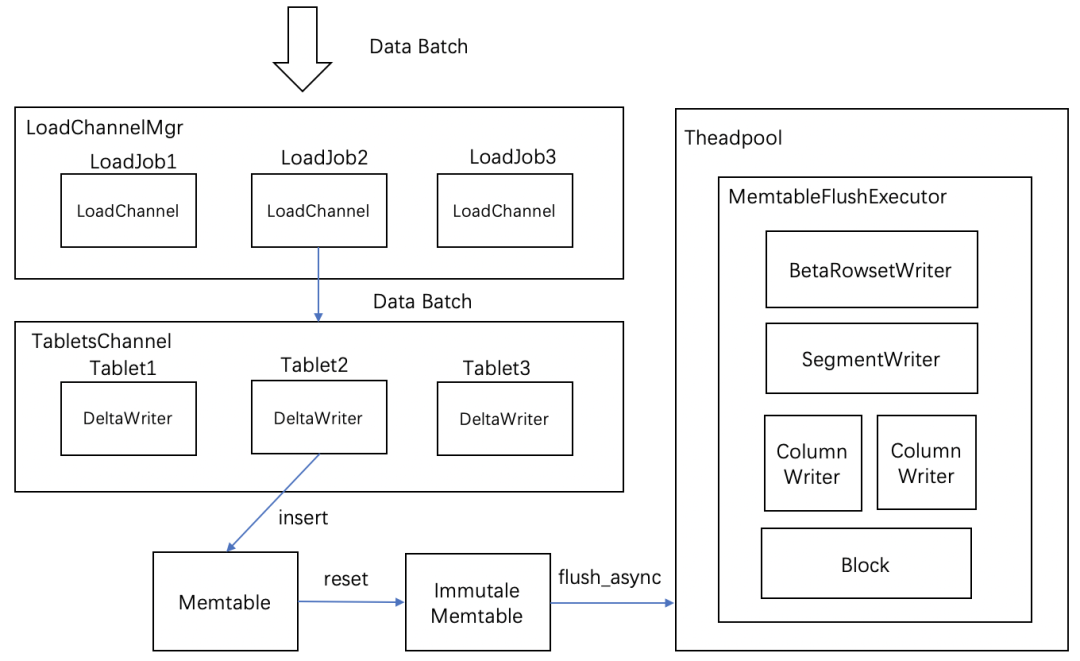
-
每次导入任务 LoadJob 会建立一个 LoadChannel 来执行,LoadChannel 维护了一次导入的通道,LoadChannel 可以将数据分批量写入操作直到导入完成。
-
LoadChannel 会创建一个 TabletsChannel 执行具体的导入操作。一个 TabletsChannel 对应多个 Tablet。一次数据批量写入操作中,TabletsChannel 将数据分发给对应 Tablet,由 DeltaWriter 将数据写入到 Tablet,便开始了真正的写入操作。
DeltaWriter 与 Memtable
DeltaWriter 主要负责不断接收新写入的批量数据,完成单个 Tablet 的数据写入。由于新增的数据可以是增量 Delta 部分,因此叫做 DeltaWriter。
DeltaWriter 数据写入采用了类 LSM 树的结构,将数据先写到 Memtable 中,当 Memtable 数据写满后,会异步 flush 生成一个 Segment 进行持久化,同时生成一个新的 Memtable 继续接收新增数据导入,这个 flush 操作由 MemtableFlushExecutor 执行器完成。
Memtable 中采用了跳表的结构对数据进行排序,排序规则使用了按照 schema 的 key 的顺序依次对字段进行比较。这样保证了写入的每一个写入 Segment 中的数据是有序的。如果当前模型为非 DUP 模型(AGG 模型和 UNIQUE 模型)时,还会对相同 key 的数据进行聚合。
物理写入
1、RowsetWriter 各个模块设计
在物理存储层面的写入,由 RowsetWriter 完成。RowsetWriter 中又分为 SegmentWriter、ColumnWriter、PageBuilder、IndexBuilder 等子模块。
-
其中 RowsetWriter 从整体上完成一次导入 LoadJob 任务的写入,一次导入 LoadJob 任务会生成一个 Rowset,一个 Rowset 表示一次导入成功生效的数据版本。实现上由 RowsetWriter 负责完成 Rowset 的写入。
-
SegmentWriter 负责实现 Segment 的写入。一个 Rowset 可以由多个 Segment 文件组成。
-
ColumnWriter 被包含在 SegmentWriter 中,Segment 的文件是完全的列存储结构,Segment 中包含了各个列和相关的索引数据,每个列的写入由 ColumnWriter 负责写入。
-
在文件存储格式中,数据和索引都是按 Page 进行组织,ColumnWriter 中又包含了生成数据 Page 的 PageBuilder 和生成索引 Page 的 IndexBuilder 来完成 Page 的写入。
-
最后,FileWritableBlock 来负责具体的文件的读写。
2、RowsetWriter 写入流程
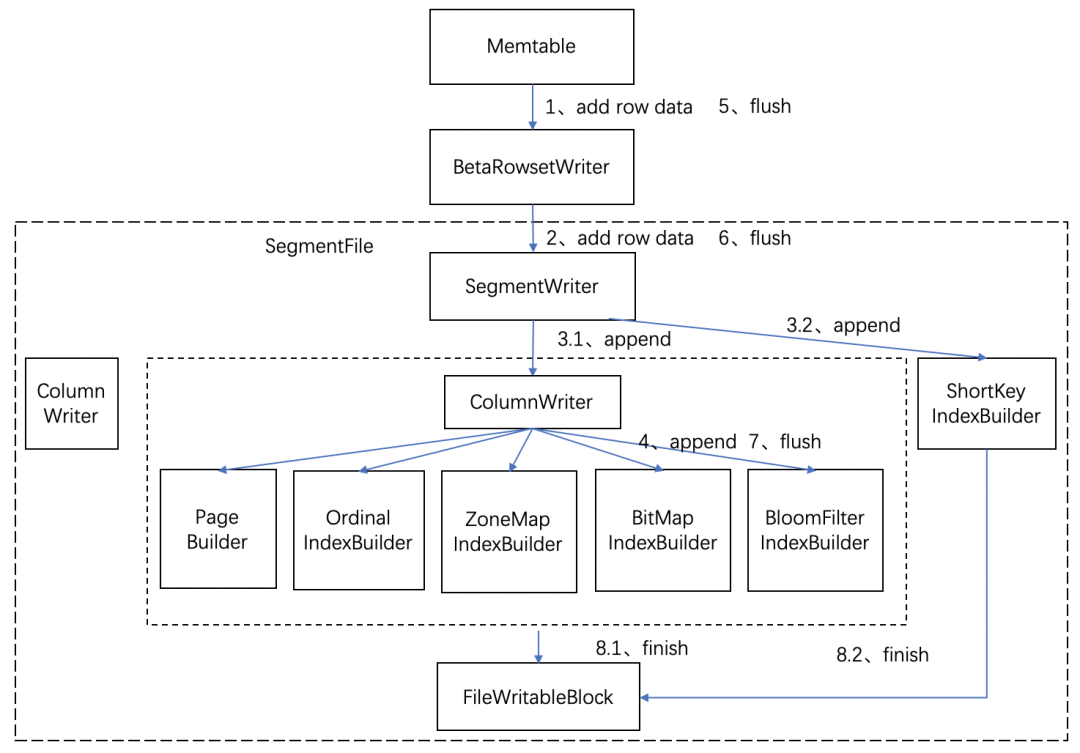
物理写入流程的详细描述:
1.当一个 Memtable 写满时(默认为 100M),将 Memtable 的数据会 flush 到磁盘上,这时 Memtable 内的数据是按 key 有序的。然后逐行写入到 RowsetWriter 中。
2.RowsetWriter 将数据同样逐行写入到 SegmentWriter 中,RowsetWriter 会维护当前正在写入的 SegmentWriter 以及要写入的文件块列表。每完成写入一个 Segment 会增加一个文件块对应。
3.SegmentWriter 将数据按行写入到各个 ColumnWriter 的中,同时写入 ShortKeyIndexBuilder。ShortKeyIndexBuilder 主要负责生成 ShortKeyIndex 的索引 Page 页。具体的 ShortKeyIndex 索引格式可以参见《Doris 存储层设计介绍 1――存储结构设计解析》文档。
4.ColumnWriter 将数据分别写入 PageBuilder 和各个 IndexBuilder,PageBuilder 用来生成 ColumnData 数据的 PageBuilder,各个 IndexBuilder 包括了(OrdinalIndexBuilder 生成 OrdinalIndex 行号稀疏索引的 Page 格式、ZoneMapIndexBuilder 生成 ZoneMapIndex 索引的 Page 格式、BitMapIndexBuilder 生成 BitMapIndex 索引的 Page 格式、BloomFilterIndexBuilder 生成 BloomFilterIndex 索引的 Page 格式)。具体参考 Doris 存储文件格式解析。
5.添加完数据后,RowsetWriter 执行 flush 操作。
6.SegmentWriter 的 flush 操作,将数据和索引写入到磁盘。其中对磁盘的读写由 FileWritableBlock 完成。
7.ColumnWriter 将各自数据、索引生成的 Page 顺序写入到文件中。
8.SegmentWriter 生成 SegmentFooter 信息,SegmentFooter 记录了 Segment 文件的原数据信息。完成写入操作后,RowsetWriter 会再开启新的 SegmentWriter,将下一个 Memtable 写入新的 Segment,直到导入完成。
Rowset 发布
整个发布过程如下:
1.DeltaWriter 统计当前 RowsetMeta 元数据信息,包括行数、字节数、时间、Segment 数量。
2.保存到 RowsetMeta 中,向 FE 提交导入事务。当前导入事务由 FE 开启,用来保证一次导入在各个 BE 节点的数据的同时生效。
3.在 FE 协调好之后,由 FE 统一下发 Publish 任务使导入的 Rowset 版本生效。任务中指定了发布的生效 version 版本信息。之后 BE 存储层才会将这个版本的 Rowset 设置为可见。
4.Rowset 加入到 BE 存储层的 Tablet 进行管理。
删除流程
目前 Delete 有两种实现,一种普通的删除类型为 DELETE,一种为 LOAD_DELETE。
DELETE 执行流程
DELETE 的支持一般的删除操作,实现较为简单,DELETE 模式下没有对数据进行实际删除操作,而是对数据删除条件进行了记录。存储在 Meta 信息中。当执行 Base Compaction 时删除条件会一起被合入到 Base 版本中。Base 版本为 Tablet 从[0-x]的第一个 Rowset 数据版本。具体流程如下:
1.删除时由 FE 直接下发删除命令和删除条件。
2.BE 在本地启动一个 EngineBatchLoadTask 任务,生成新版本的 Rowset,并记录删除条件信息。这个删除记录的 Rowset 与写入过程的略有不同,该 Rowset 仅记录了删除条件信息,没有实际的数据。
3.FE 同样发布生效版本。其中会将 Rowset 加入到 Tablet 中,保存 TabletMeta 信息。
LOAD_DELETE 执行流程
LOAD_DELETE 支持了在 UNIQUE KEY 模型下,实现了通过批量导入要删除的 key 对数据进行删除,能够支持大量数据删除能力。整体思路是在数据记录中加入删除状态标识,在 Compaction 流程中会对删除的 key 进行压缩。
数据模型和物化视图
聚合模型
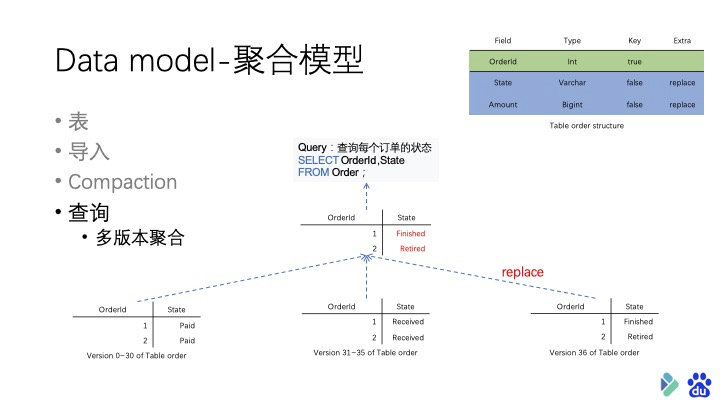
聚合模型的特点就是将表中的列分为了 Key 和 Value 两种。 Key 就是数据的维度列,比如时间,地区等等。Value 则是数据的指标列,比如点击量,花费等。每个指标列还会有自己的聚合函数,包括 sum、min、max 和 bitmap_union 等。数据会根据维度列进行分组,并对指标列进行聚合。

首先是导入数据 ,原始数据在导入过程中,会根据表结构中的 Key 进行分组,相同 Key 的 Value 会根据表中定义的 Aggregation Function 进行聚合。
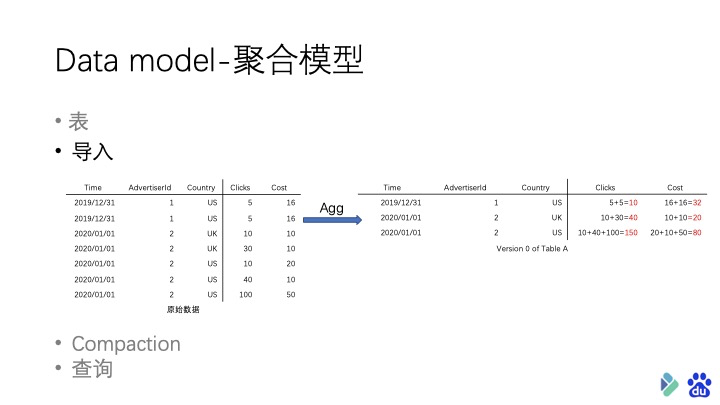
由于 Doris 采用的是 MVCC 机制进行的并发控制,所以每一次新的导入都是一个新的版本。我们把这种版本称为 Singleton 。
不断的导入新的数据后,尽管同一批次的数据在导入过程中已经发生了聚合,但不同版本之间的数据依旧存在维度列相同但是指标列并没有被聚合的情况。这时候就需要通过 Compaction 机制进行二次聚合。
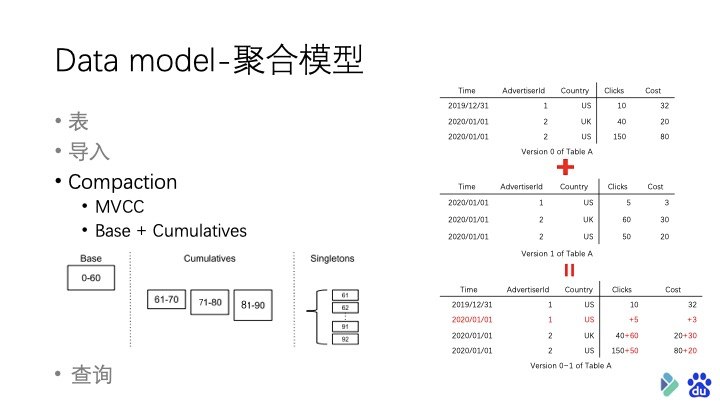
Compaction?的意思其实就是将不同版本的数据进行合并。它 分为两个阶段,第一个阶段是: 当 Singleton 的数据版本个数到达 Doris 设置的阈值时,就会触发 Cumulative 级别的 Compaction。 这个级别的 Compaction 会将一个区间段内的版本数据根据定义好的聚合函数进行再聚合。
说完聚合模型,再介绍一种聚合模型上的 提升查询效率 的方式―― 构建 Rollup

Rollup 也就是上卷,是一种在多维分析中比较常用的操作――也就是从细粒度的数据向高层的聚合。
在 Doris 中,我们提供了在聚合模型上的构建 Rollup 功能,将数据根据更少的维度进行预聚合。将本身在用户查询时才会进行聚合计算的数据预先计算好,并存储在 Doris 中,从而达到提升用户粗粒度上的查询效率。
Rollup 还有一点好处在于,由于 Doris 具有在原始数据上实时计算的能力,因此不需要对所有维度的每个组合都创建 Rollup。尤其是在维度很多的情况下,可以取得一个存储空间和查询效率之间的平衡。
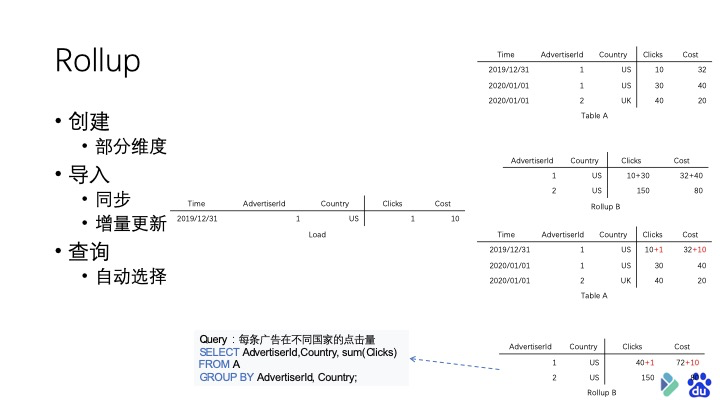
在创建 Rollup 的时候首先你需要有一个聚合模型的 Base 表,然后就可以取部分维度创建一个 Rollup 表。
聚合模型的优点就在于:划分维护和指标列后,数据本身已经进行过预聚合,对于分析型查询效率提升明显。
-
但是聚合模型在某些用户场景下并不适用:
-
很多业务并没有聚合的需求,就是要存储原始的用户行为日志。
-
一些业务在初期还不能确认哪些是维度列,哪些是指标列
-
聚合模型本身更难理解,对新用户体验不好,比如一些查询结果和用户预期的不一致。
基于以上问题,我们增加了对明细数据模型的支持。
明细模型
![]()
明细数据模型刚好和聚合模型相反,不区分维护和指标列,并不对导入的数据做任何聚合,每条原始数据都会保留在表中。
明细模型就像 Mysql 中的表一样,优势就在于你可以详细追溯每个用户行为或订单详情。但劣势也很明显,分析型的查询效率不高。
Doris 的物化视图
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询的需求。
首先,什么是物化视图?

从定义上来说,就是包含了查询结果的数据库对象,可能是对远程数据的本地 Copy;也可能是一个表或多表 Join 后结果的行或列的子集;也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
在 Doris 中的物化视图,就是查询结果预先存储起来的特殊的表。
它的优势在于:
1.对于那些经常重复的使用相同的子查询结果的查询性能大幅提升
2.Doris 自动更新物化视图的数据,保证 Base 表和物化视图表的数据一致性。无需额外的维护成本
3.查询的时候也可以自动匹配最优的物化视图
物化视图
目前支持的聚合函数包括常用的 sum、min、max、count 以及 pv、uv, 留存率等计算时常用的去重算法 hll_union,和用于精确去重计算 count(distinct) 的算法 bitmap_union。

使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML 类型操作会有一些限制。
使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML 类型操作会有一些限制。
对于物化视图和 Rollup 来说,他们的共同点都是 通过预聚合 的方式来提升查询效率。 实际上物化视图是 Rollup 的一个超集,在覆盖 Rollup 的工作同时,还支持更灵活的聚合方式。
因此,如果对数据的分析需求既 覆盖了明细查询也存在分析类查询 ,则可以先创建一个明细模型的表,并构建物化视图。
Doris SQL 原理解析
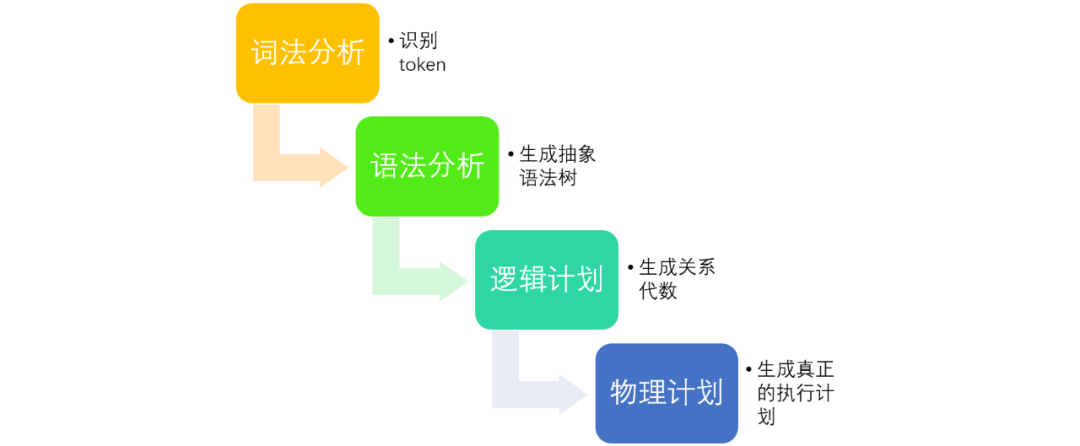
SQL解析在下文中指的是将一条sql语句经过一系列的解析最后生成一个完整的物理执行计划的过程。
这个过程包括以下四个步骤:词法分析,语法分析,生成逻辑计划,生成物理计划。
设计目标
Doris SQL解析架构的设计有以下目标:
-
最大化计算的并行性
-
最小化数据的网络传输
-
最大化减少需要扫描的数据
总体架构
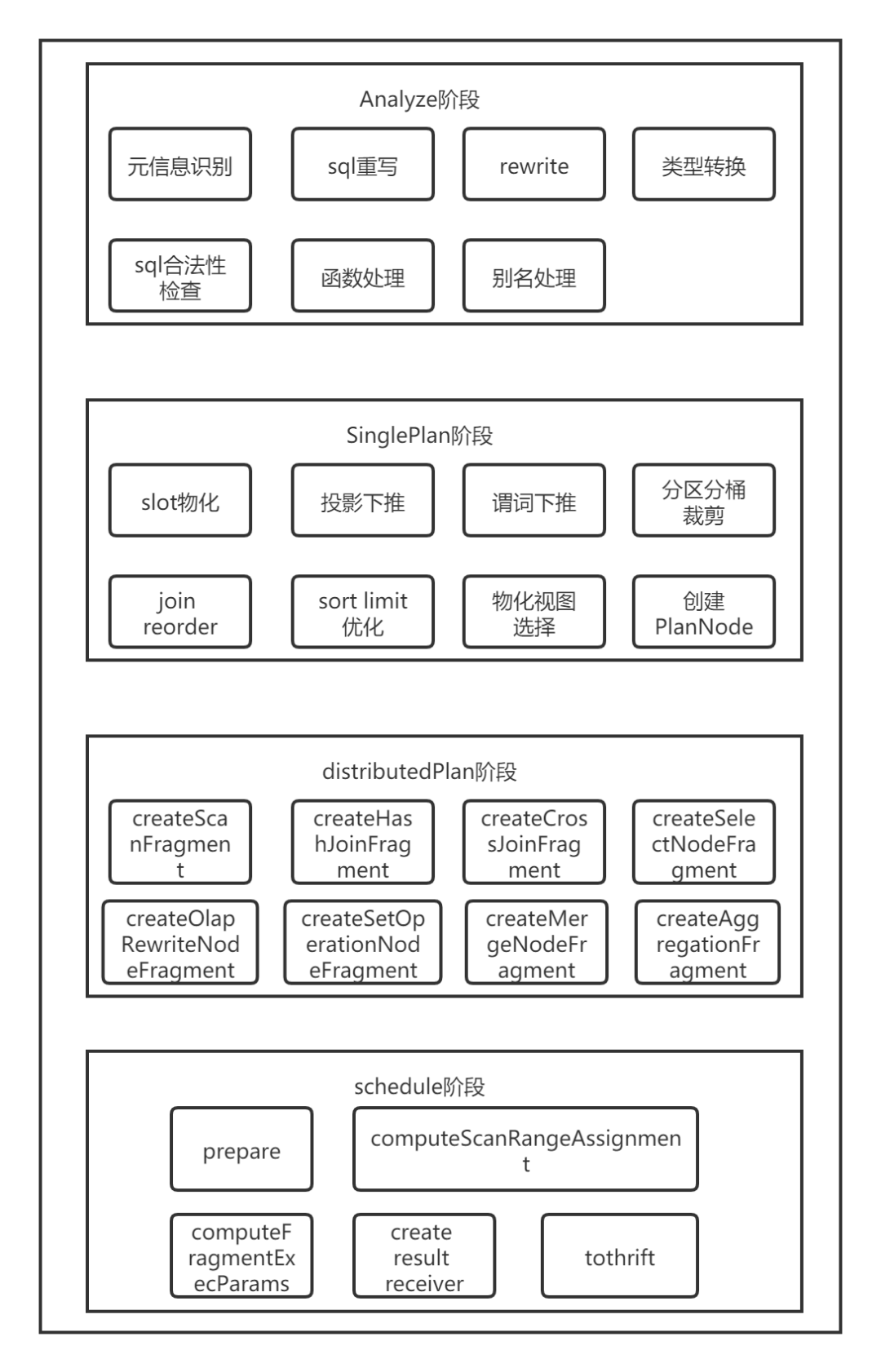
Doris SQL解析具体包括了五个步骤:词法分析,语法分析,生成单机逻辑计划,生成分布式逻辑计划,生成物理执行计划。
具体代码实现上包含以下五个步骤:Parse, Analyze, SinglePlan, DistributedPlan, Schedule。
下文侧重介绍查询SQL的解析。
下图展示了一个简单的查询SQL在Doris的解析实现。
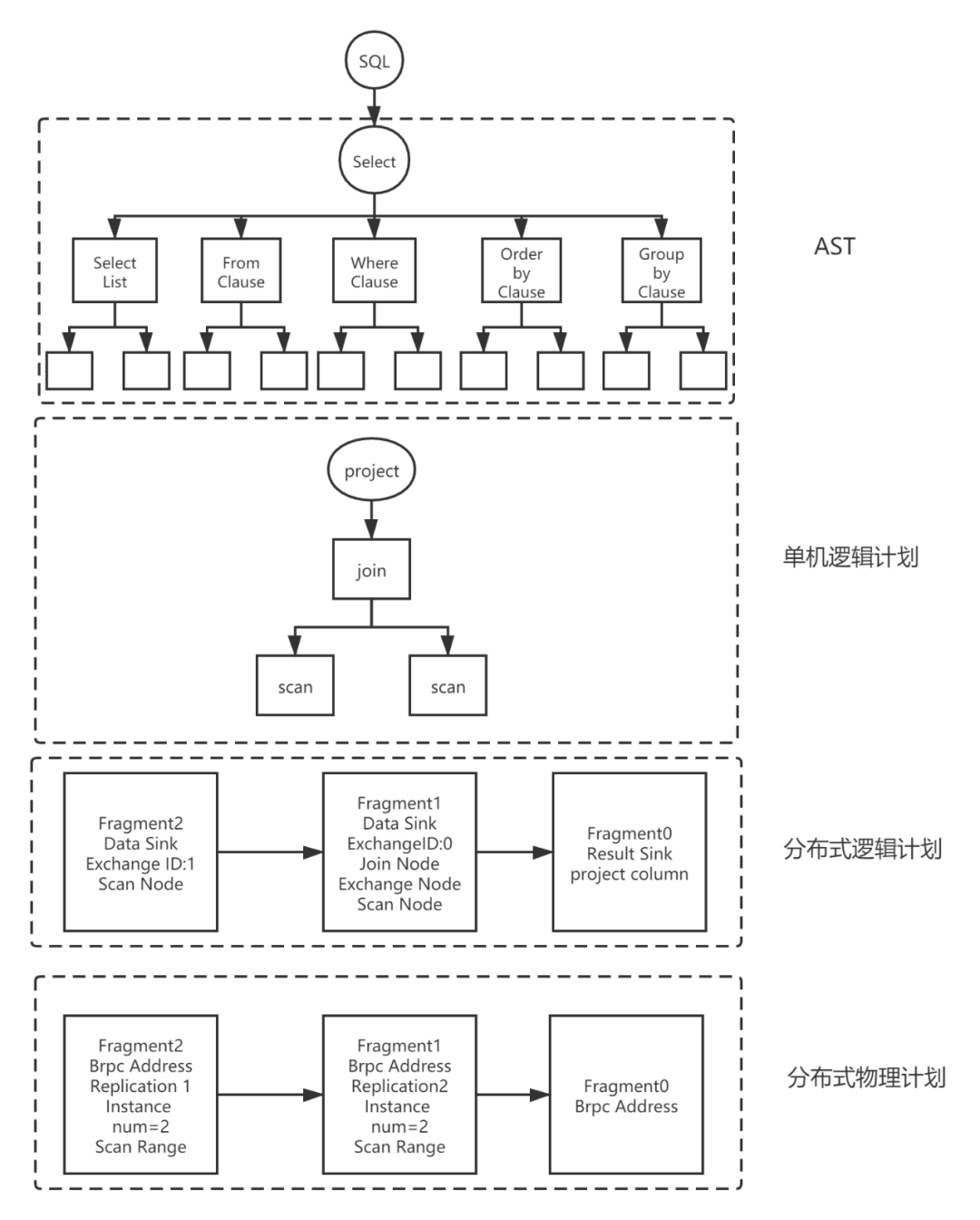
Parse阶段
词法分析采用jflex技术,语法分析采用java cup parser技术,最后生成抽象语法树(Abstract Syntax Tree)AST,这些都是现有的、成熟的技术,在这里不进行详细介绍。
AST是一种树状结构,代表着一条SQL。不同类型的查询select, insert, show, set, alter table, create table等经过Parse阶段后生成不同的数据结构(SelectStmt, InsertStmt, ShowStmt, SetStmt, AlterStmt, AlterTableStmt, CreateTableStmt等),但他们都继承自Statement,并根据自己的语法规则进行一些特定的处理。例如:对于select类型的sql, Parse之后生成了SelectStmt结构。
SelectStmt结构包含了SelectList,FromClause,WhereClause,GroupByClause,SortInfo等结构。这些结构又包含了更基础的一些数据结构,如WhereClause包含了BetweenPredicate(between表达式), BinaryPredicate(二元表达式), CompoundPredicate(and or组合表达式), InPredicate(in表达式)等。
Analyze阶段
抽象语法树是由StatementBase这个抽象类表示。这个抽象类包含一个最重要的成员函数analyze(),用来执行Analyze阶段要做的事。
不同类型的查询select, insert, show, set, alter table, create table等经过Parse阶段后生成不同的数据结构(SelectStmt, InsertStmt, ShowStmt, SetStmt, AlterStmt, AlterTableStmt, CreateTableStmt等),这些数据结构继承自StatementBase,并实现analyze()函数,对特定类型的SQL进行特定的Analyze。
例如:select类型的查询,会转成对select sql的子语句SelectList, FromClause, GroupByClause, HavingClause, WhereClause, SortInfo等的analyze()。然后这些子语句再各自对自己的子结构进行进一步的analyze(),通过层层迭代,把各种类型的sql的各种情景都分析完毕。例如:WhereClause进一步分析其包含的BetweenPredicate(between表达式), BinaryPredicate(二元表达式), CompoundPredicate(and or组合表达式), InPredicate(in表达式)等。
生成单机逻辑Plan阶段
这部分工作主要是根据AST抽象语法树生成代数关系,也就是俗称的算子数。树上的每个节点都是一个算子,代表着一种操作。
ScanNode代表着对一个表的扫描操作,将一个表的数据读出来。HashJoinNode代表着join操作,小表在内存中构建哈希表,遍历大表找到连接键相同的值。Project表示投影操作,代表着最后需要输出的列,图片表示只用输出citycode这一列。
![]()
生成分布式Plan阶段
有了单机的PlanNode树之后,就需要进一步根据分布式环境,拆成分布式PlanFragment树(PlanFragment用来表示独立的执行单元),毕竟一个表的数据分散地存储在多台主机上,完全可以让一些计算并行起来。
这个步骤的主要目标是最大化并行度和数据本地化。主要方法是将能够并行执行的节点拆分出去单独建立一个PlanFragment,用ExchangeNode代替被拆分出去的节点,用来接收数据。拆分出去的节点增加一个DataSinkNode,用来将计算之后的数据传送到ExchangeNode中,做进一步的处理。
这一步采用递归的方法,自底向上,遍历整个PlanNode树,然后给树上的每个叶子节点创建一个PlanFragment,如果碰到父节点,则考虑将其中能够并行执行的子节点拆分出去,父节点和保留下来的子节点组成一个parent PlanFragment。拆分出去的子节点增加一个父节点DataSinkNode组成一个child PlanFragment,child PlanFragment指向parent PlanFragment。这样就确定了数据的流动方向。
Schedule阶段
这一步是根据分布式逻辑计划,创建分布式物理计划。主要解决以下问题:
-
哪个 BE 执行哪个 PlanFragment
-
每个 Tablet 选择哪个副本去查询
-
如何进行多实例并发
实践
Apache Doris 基于 Bitmap 的精确去重和用户行为分析
How Doris Count Distinct without Bitmap
Doris 除了支持 HLL 近似去重,也是支持 Runtime 现场精确去重的。实现方法和 Spark,MR 类似。
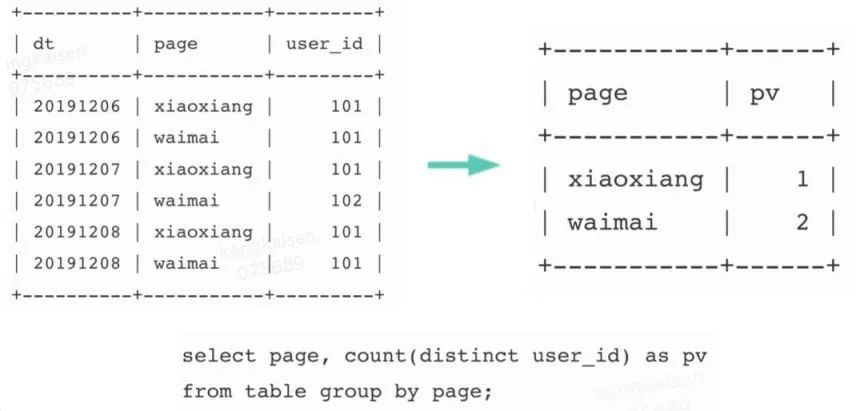
对于上图计算 PV 的 SQL,Doris 在计算时,会按照下图进行计算,先根据 page 列和 user_id 列 group by,最后再 count。
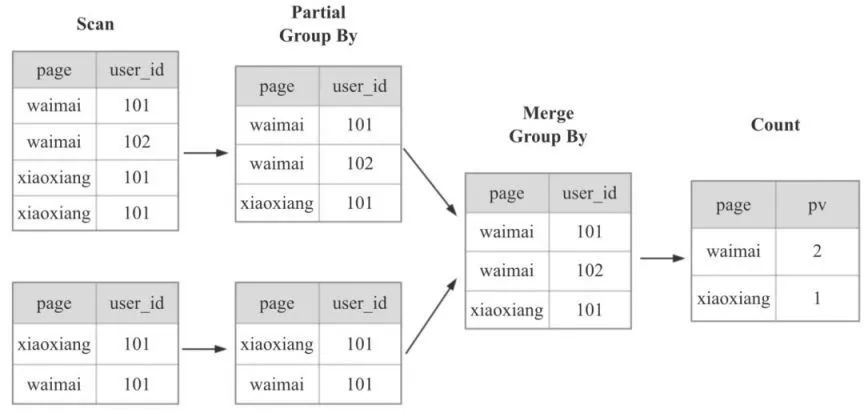
显然,上面的计算方式,当数据量越来越大,到几十亿,几百亿时,使用的 IO 资源,CPU 资源,内存资源,网络资源就会越来越多,查询也会越来越慢。
那么,下面一个自然而然的问题就是,应该如何让 Doris 的精确去重查询性能更快呢?
How To Make Count Distinct More Faster
-
堆机器
-
Cache
-
优化 CPU 执行引擎 (向量化,SIMD,查询编译等)
-
支持 GPU 执行引擎
-
预计算
How Doris Count Distinct With Bitmap
要在 Doris 中预计算,自然要用到 Doris 的聚合模型,下面简单看下 Doris 中的聚合模型:
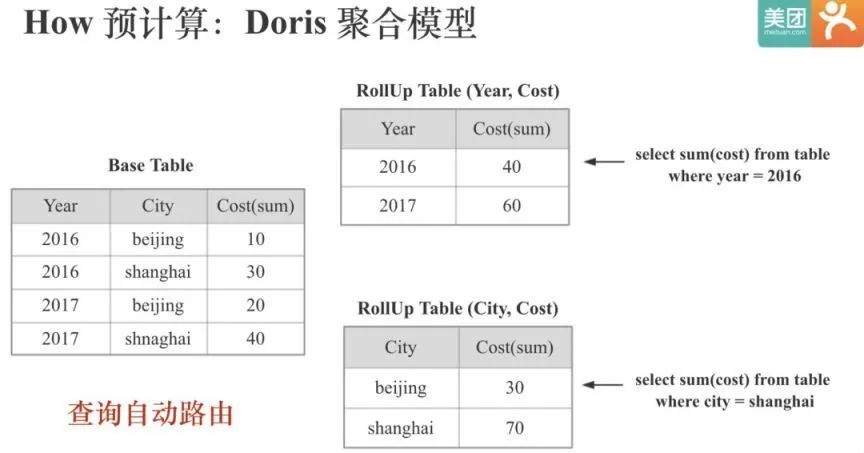
Doris 的聚合模型分为 Key 列和 Value 列,Key 列就是维度列,Value 列是指标列,Key 列全局有序,每个 Value 列会有对应的聚合函数,相同 Key 列的 Value 会根据对应的聚合函数进行聚合。上图中,Year,City 是 Key 列,Cost 是 Value 列,Cost 对应的聚合函数式 Sum。Doris 支持根据不同维度组合建立不同的 Rollup 表,并能在查询时自动路由。
所以要在 Doris 中实现 Count Distinct 的预计算,就是实现一种 Count Distinct 的聚合指标。那么可以像 Sum,Min,Max 聚合指标一样直接实现一种 Count Distinct 聚合指标吗?

Doris 中聚合指标必须支持上卷。 但如果只保留每个 City 的 User 的去重值,就没办法上卷聚合出只有 Year 为维度的时候 User 的去重值,因为去重值不能直接相加,已经把明细丢失了,不知道在 2016 或 2017 年,北京和上海不重合的 User 有多少。
所以去重指标要支持上卷聚合,就必须保留明细,不能只保留一个最终的去重值。而计算机保留信息的最小单位是一个 bit,所以很自然的想到用 Bitmap 来保留去重指标的明细数据。
![]()
Roaring Bitmap 的核心思路很简单,就是根据数据的不同特征采用不同的存储或压缩方式。 为了实现这一点,Roaring Bitmap 首先进行了分桶,将整个 int 域拆成了 2 的 16 次方 65536 个桶,每个桶最多包含 65536 个元素。
所以一个 int 的高 16 位决定了,它位于哪个桶,桶里只存储低 16 位。以图中的例子来说,62 的前 1000 个倍数,高 16 位都是 0,所以都在第一个桶里。
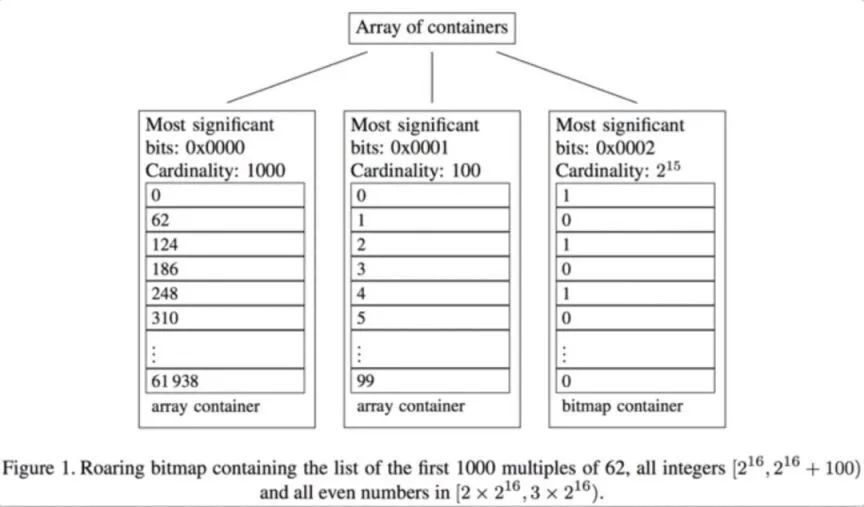
然后在桶粒度针对不同的数据特点,采用不同的存储或压缩方式:
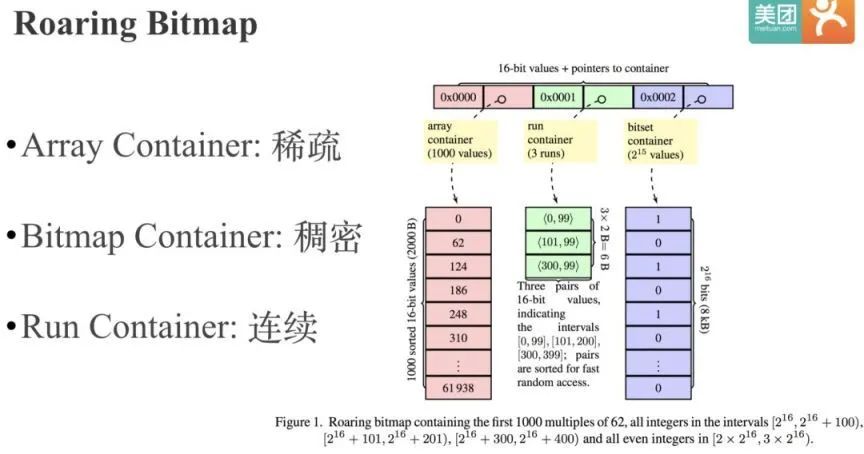
默认会采用 16 位的 Short 数组来存储低 16 位数据,当元素个数超过 4096 时,会采用 Bitmap 来存储数据。
第 3 类 Run Container 是优化连续的数据, Run 指的是 Run Length Encoding(RLE)
在做字典映射时,使用比较广泛的数据结构是 Trie 树。
Trie 树的问题是字典对应的编码值是基于节点位置决定的,所以 Trie 树是不可变的。这样没办法用来实现全局字典,因为要做全局字典必然要支持追加。
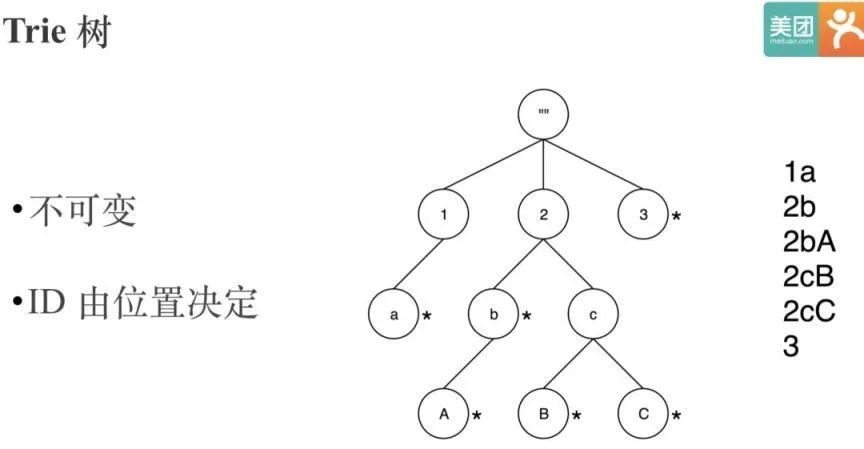
如何让同一个 String 永远映射到同一个 ID。一个简单的思路是把 String 对应的 ID 直接序列化下来,因为全局字典只需要支持 String 到 ID 的单向查找,不需要支持 ID 到 String 的反向查找。
当全局字典越来越大的时候,就会面临内存不足的问题。一个自然的想法就是 Split。当全局字典拆成多个子树之后,必然会涉及到每个子树的按需加载和删除,这个功能是使用 Guava 的 LoadingCache 实现的。
为了解决读写冲突的问题,实现了 MVCC,使得读写可以同时进行。全局字典目前是存储在 HDFS 上的,一个全局字典目录下会有多个 Version,读的时候永远读取最新 Version 的数据,写的时候会先写到临时目录,完成后再拷贝到最新的 Version 目录。同时为了保证全局字典的串行更新,引入分布式锁。
目前基于 Trie 树的全局字典存在的一个问题是,全局字典的编码过程是串行的,没有分布式化,所以当全局字典的基数到几十亿规模时,编码过程就会很慢。一个可行的思路是,类似 Roaring Bitmap,可以将整个 Int 域进行分桶,每个桶对应固定范围的 ID 编码值,每个 String 通过 Hash 决定它会落到哪个桶内,这样全局字典的编码过程就可以并发。
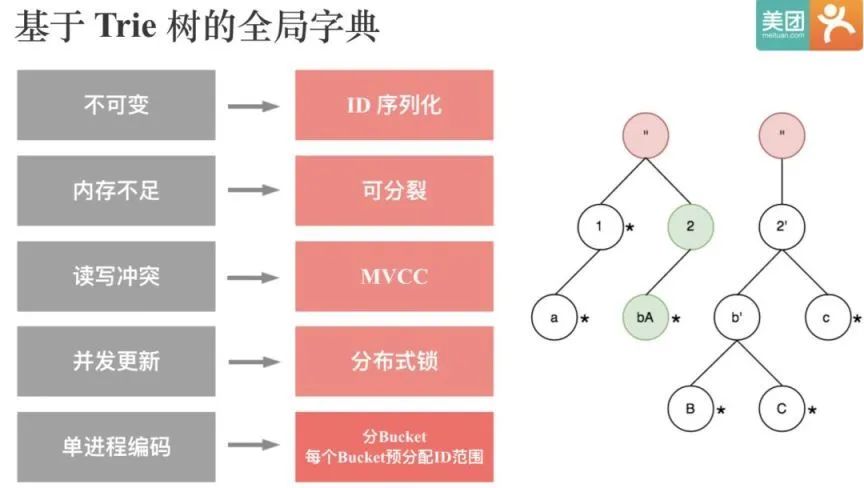
正是由于目前基于 Trie 树的全局字典 无法分布式构建,滴滴的同学引入了基于 Hive 表的全局字典。
![]()
这种方案中全局字典本身是一张 Hive 表,Hive 表有两个列,一个是原始值,一个是编码的 Int 值,然后通过上面的 4 步就可以通过 Spark 或者 MR 实现全局字典的更新,和对事实表中 Value 列的替换。
基于 Hive 表的全局字典相比基于 Trie 树的全局字典的优点除了可以分布式化,还可以实现全局字典的复用。但是缺点也是显而易见,相比基于 Trie 树的全局字典,会使用多几倍的资源,因为原始事实表会被读取多次,而且还有两次 Join。
How to Use Doris Bitmap
Create Table (为了有更好的加速效果,最好建下 ROLLUP)
CREATE TABLE `pv_bitmap` (
`dt` int,
`page` varchar(10),
`user_id` bitmap bitmap_union
)
AGGREGATE KEY(`dt`, page)
DISTRIBUTED BY HASH(`dt`) BUCKETS 2;
ALTER TABLE pv_bitmap ADD ROLLUP pv (page, user_id);Load Data
cat data | curl --location-trusted -u user:passwd -T -
-H "columns: dt,page,user_id, user_id=$BITMAP_LOAD_FUNCTION(user_id)"
http://host:8410/api/test/pv_bitmap/_stream_load
TO_BITMAP(expr) : 将 0 ~ 4294967295 的 unsigned int 转为 bitmap
BITMAP_HASH(expr): 将任意类型的列通过 Hash 的方式转为 bitmap
BITMAP_EMPTY(): 生成空 bitmap,用于 insert 或导入的时填充默认值Query
select bitmap_count(bitmap_union(user_id)) from pv_bitmap; select bitmap_union_count(user_id) from pv_bitmap; select bitmap_union_int(id) from pv_bitmap;
BITMAP_UNION(expr) : 计算两个 Bitmap 的并集,返回值是序列化后的 Bitmap 值
BITMAP_COUNT(expr) : 计算 Bitmap 的基数值
BITMAP_UNION_COUNT(expr): 和 BITMAP_COUNT(BITMAP_UNION(expr)) 等价
BITMAP_UNION_INT(expr) : 和 COUNT(DISTINCT expr) 等价(仅支持TINYINT,SMALLINT 和 INT)Insert Into ( 可以加速无需上卷的精确去重查询场景 )
insert into bitmaptable1 (id, id2) VALUES (1001, tobitmap(1000)), (1001, to_bitmap(2000));
insert into bitmaptable1 select id, bitmapunion(id2) from bitmap_table2 group by id;
insert into bitmaptable1 select id, bitmaphash(id_string) from table;基于 Bitmap 的用户行为分析
用户行为分析从字面意思上讲,就是分析用户的行为。分析用户的哪些行为呢?可以简单用 5W2H 来总结。即 Who(谁)、What(做了什么行为)、When(什么时间)、Where(在哪里)、Why(目的是什么)、How(通过什么方式),How much (用了多长时间、花了多少钱)。
其终极目的就是为了不断优化产品,提升用户体验,让用户花更多的时间,花更多的钱在自己的产品上。
目前用户行为分析的解法大概有这么几种:
第一种就数据库的 Join 解法,一般效率是比较低的。我们在 Doris 中是可以用这种思路实现的。
第二种是基于明细数据的,UDAF 实现。Doris 也是支持的。
第三种是基于 Bitmap 的 UDAF 实现的,也就是今天要分享的。
第四种是用专用的系统来做用户行为分析,专用系统的好处是可以针对特定场景,做更多的优化。
Doris Intersect_count
现在已经在 Doris 的聚合模型中支持了 Bitmap,所以可以基于 Bitmap 实现各类 UDF, UDAF,来实现大多数用户行为分析。
Intersect_count 计算留存
select intersect_count(user_id, dt, '20191111') as first_day,
intersect_count(user_id, dt, '20191112') as second_day,
intersect_count(user_id, dt, '20191111', '20191112') as retention,
from table
where dt in ('20191111', '20191112')假如有 user_id 和 page 的信息,我们希望知道在访问美团页面之后,又有多少用户访问了外卖页面,也可以用 intersect_count 来进行计算。
Intersect_count 筛选特定用户
select
intersect_count(user_id, tag_value, '男', '90后', '10-20万')
from user_profile
where (tag_type='性别' and tag_value='男')
or (tag_type='年龄' and tag_value='90后')
or (tag_type='收入' and tag_value='10-20万')最后也可以通过 intersect_count 来进行一些特定用户的筛选。例如原始表里有 user_id,tag_value,tag_type 这些信息,我们想计算年收入 10-20 万的 90 后男性有多少,就可以用这个简单的 SQL 来实现。
Doris Bitmap ToDo
-
全局字典进行开源,支持任意类型的精确去重
-
支持 Int64,支持 Int64 后一方面支持更高基数的 bitmap 精确去重,另一方面如果原始数据中有 bigint 类型的数据便不需要全局字典进行编码。
-
支持 Array 类型。很多用户行为分析的场景下的 UDAF 或 UDF,用 Array 表达更加方便和规范。
-
更方便更智能的批量创建 Rollup。当用户基数到达十多亿时,Bitmap 本身会比较大,而且对几十万个 Bitmap 求交的开销也会很大,因此还是需要建立 Rollup 来进行加速查询。更进一步,我们期望可以做到根据用户的查询特点去自动建立 Rollup。
-
希望支持更多、更复杂的用户行为分析。
Summary
如果应用基数在百万、千万量级,并拥有几十台机器,那么直接选择 count distinct 即可;
如果希望进行用户行为分析,可以考虑 IntersectCount 或者自定义 UDAF。
Reference
Apache Doris 在美团外卖数仓中的应用实践
外卖运营业务特点
外卖业务为大家提供送餐服务,连接商家与用户,这是一个劳动密集型的业务,外卖业务有上万人的运营团队来服务全国几百万的商家,并以“商圈”为单元,服务于“商圈”内的商家。“商圈”及其上层组织机构是一个变化维度,当“商圈”边界发生变化时,就导致在往常日增量的业务生产方式中,历史数据的回溯失去了参考意义。在所有展现组织机构数据的业务场景中,组织机构的变化是一个绕不开的技术问题。此外,商家品类、类型等其它维度也存在变化维的问题。如下图所示:

数据生产面临的挑战
数据爆炸,每日使用最新维度对历史数据进行回溯计算。在 Kylin 的 MOLAP 模式下存在如下问题:
-
历史数据每日刷新,失去了增量的意义。
-
每日回溯历史数据量大,10 亿+的历史数据回溯。
-
数据计算耗时 3 小时+,存储 1TB+,消耗大量计算存储资源,同时严重影响 SLA 的稳定性。
-
预计算的大量历史数据实际使用率低下,实际工作中对历史的回溯 80%集中在近 1 个月左右,但为了应对所有需求场景,业务要求计算近半年以上的历史。
-
不支持明细数据的查询。
解决方案:引入 MPP 引擎,数据现用现算
既然变化维的历史数据预计算成本巨大,最好的办法就是现用现算,但现用现算需要强大的并行计算能力。OLAP 的实现有 MOLAP、ROLAP、HOLAP 三种形式。长期以来,由于传统关系型 DBMS 的数据处理能力有限,所以 ROLAP 模式受到很大的局限性。随着分布式、并行化技术成熟应用,MPP 引擎逐渐表现出强大的高吞吐、低时延计算能力,号称“亿级秒开”的引擎不在少数,ROLAP 模式可以得到更好的延伸。例如:日数据量的 ROLAP 现场计算,周、月趋势的计算,以及明细数据的浏览都可以较好的应对。
下图是 MOLAP 模式与 ROLAP 模式下应用方案的比较:

MOLAP 模式的劣势
-
应用层模型复杂,根据业务需要以及 Kylin 生产需要,还要做较多模型预处理。这样在不同的业务场景中,模型的利用率也比较低。
-
Kylin 配置过程繁琐,需要配置模型设计,并配合适当的“剪枝”策略,以实现计算成本与查询效率的平衡。
-
由于 MOLAP 不支持明细数据的查询,在“汇总+明细”的应用场景中,明细数据需要同步到 DBMS 引擎来响应交互,增加了生产的运维成本。
-
较多的预处理伴随着较高的生产成本。
ROLAP 模式的优势
-
应用层模型设计简化,将数据固定在一个稳定的数据粒度即可。比如商家粒度的星形模型,同时复用率也比较高。
-
App 层的业务表达可以通过视图进行封装,减少了数据冗余,同时提高了应用的灵活性,降低了运维成本。
-
同时支持“汇总+明细”。
-
模型轻量标准化,极大的降低了生产成本。
综上所述,在变化维、非预设维、细粒度统计的应用场景下,使用 MPP 引擎驱动的 ROLAP 模式,可以简化模型设计,减少预计算的代价,并通过强大的实时计算能力,可以支撑良好的实时交互体验。
Doris 引擎在美团的重要改进
Join 谓词下推的传递性优化
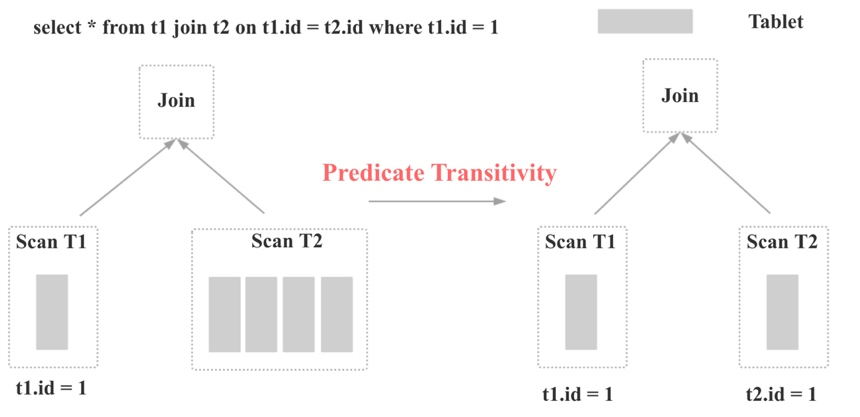
如上图所示,对于下面的 SQL:
select * from t1 join t2 on t1.id = t2.id where t1.id = 1Doris 开源版本默认会对 t2 表进行全表 Scan,这样会导致上面的查询超时,进而导致外卖业务在 Doris 上的第一批应用无法上线。
于是在 Doris 中实现了第一个优化:Join 谓词下推的传递性优化(MySQL 和 TiDB 中称之为 Constant Propagation)。Join 谓词下推的传递性优化是指:基于谓词 t1.id = t2.id 和 t1.id = 1, 可以推断出新的谓词 t2.id = 1,并将谓词 t2.id = 1 下推到 t2 的 Scan 节点。这样假如 t2 表有数百个分区的话,查询性能就会有数十倍甚至上百倍的提升,因为 t2 表参与 Scan 和 Join 的数据量会显著减少。
查询执行多实例并发优化
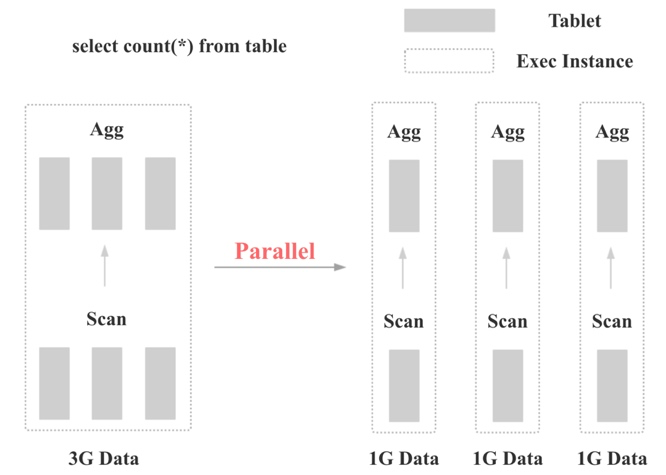
如上图所示,Doris 默认在每个节点上为每个算子只会生成 1 个执行实例。这样的话,如果数据量很大,每个执行实例的算子就需要处理大量的数据,而且无法充分利用集群的 CPU、IO、内存等资源。
一个比较容易想到的优化手段是,可以在每个节点上为每个算子生成多个执行实例。这样每个算子只需要处理少量数据,而且多个执行实例可以并行执行。
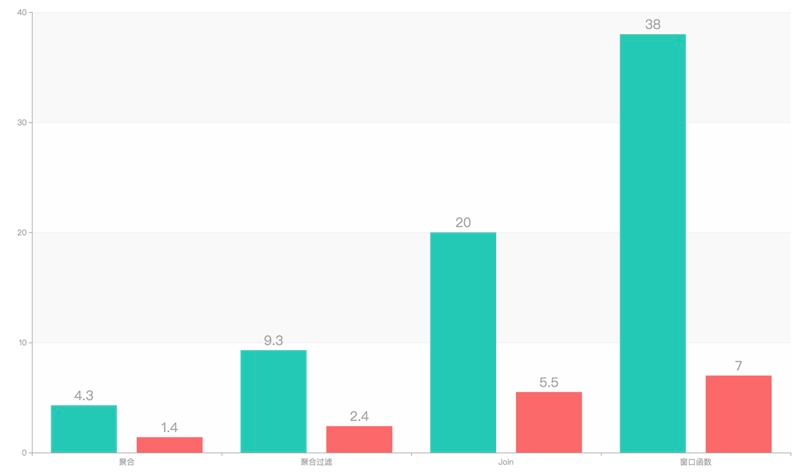
下图是并发度设置为 5 的优化效果,可以看到对于多种类型的查询,会有 3 到 5 倍的查询性能提升:
Colocate Join
Colocate Join(Local Join)是和 Shuffle Join、Broadcast Join 相对的概念,即将两表的数据提前按照 Join Key Shard,这样在 Join 执行时就没有数据网络传输的开销,两表可以直接在本地进行 Join。
整个 Colocate Join 在 Doris 中实现的关键点如下:
-
数据导入时保证数据本地性。
-
查询调度时保证数据本地性。
-
数据 Balance 后保证数据本地性。
-
查询 Plan 的修改。
-
Colocate Table 元数据的持久化和一致性。
-
Hash Join 的粒度从 Server 粒度变为 Bucket 粒度。
-
Colocate Join 的条件判定。
对于下面的 SQL,Doris Colocate Join 和 Shuffle Join 在不同数据量下的性能对比如下:
select count(*) FROM A t1 INNER JOIN [shuffle] B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN [shuffle] C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days);![]()
Bitmap 精确去重
Doris 之前实现精确去重的方式是现场计算的,实现方法和 Spark、MapReduce 类似:

对于上图计算 PV 的 SQL,Doris 在计算时,会按照下图的方式进行计算,先根据 page 列和 user_id 列 group by,最后再 Count:
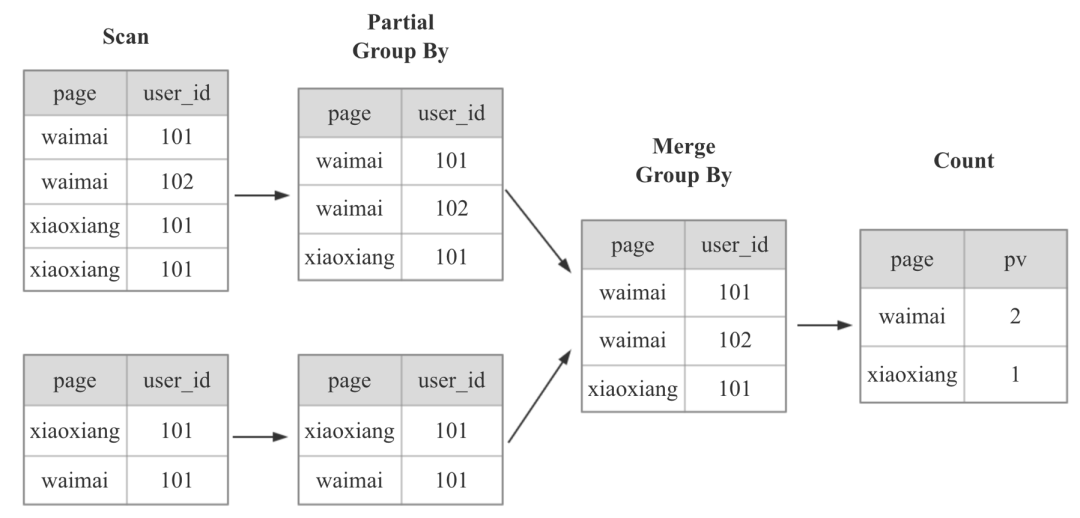
显然,上面的计算方式,当数据量越来越大,到几十亿几百亿时,使用的 IO 资源、CPU 资源、内存资源、网络资源会变得越来越多,查询也会变得越来越慢。
于是在 Doris 中新增了一种 Bitmap 聚合指标,数据导入时,相同维度列的数据会使用 Bitmap 聚合。有了 Bitmap 后,Doris 中计算精确去重的方式如下:
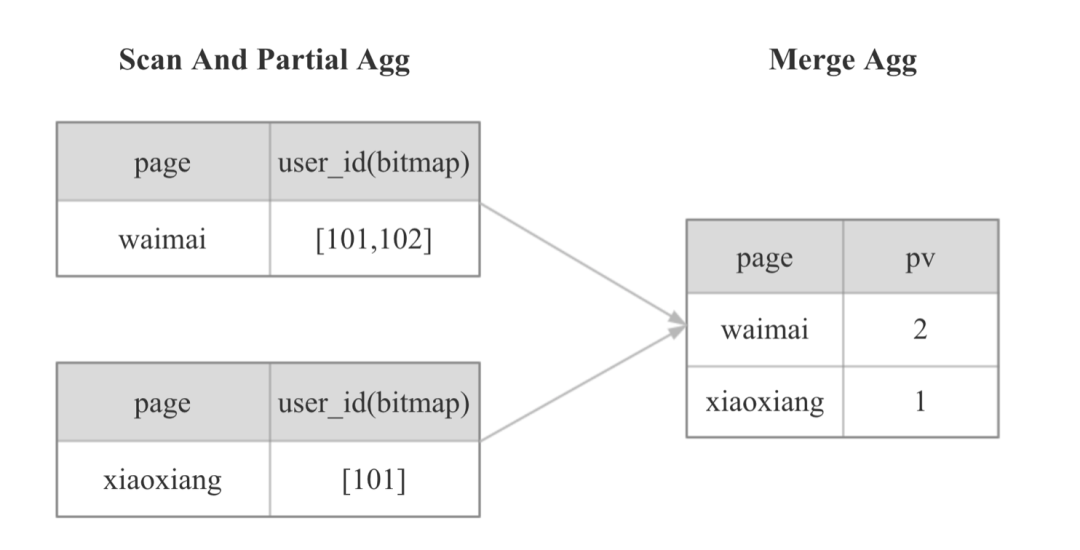
可以看到,当使用 Bitmap 之后,之前的 PV 计算过程会大幅简化,现场查询时的 IO、CPU、内存,网络资源也会显著减少,并且不再会随着数据规模而线性增加。
总结与思考
实践证明,以 Doris 引擎为驱动的 ROLAP 模式可以较好地处理汇总与明细、变化维的历史回溯、非预设维的灵活应用、准实时的批处理等场景。而以 Kylin 为基础的 MOLAP 模式在处理增量业务分析,固化维度场景,通过预计算以空间换时间方面依然重要。
业务方面,通过外卖数仓 Doris 的成功实践以及跨事业群的交流,美团已经有更多的团队了解并尝试使用了 Doris 方案。而且在平台同学的共同努力下,引擎性能还有较大提升空间,相信以 Doris 引擎为驱动的 ROLAP 模式会为美团的业务团队带来更大的收益。从目前实践效果看,其完全有替代 Kylin、Druid、ES 等引擎的趋势。
目前,数据库技术进步飞速,近期柏睿数据发布全内存分布式数据库 RapidsDB v4.0 支持 TB 级毫秒响应(处理千亿数据可实现毫秒级响应)。可以预见,数据库技术的进步将大大改善数仓的分层管理与应用支撑效率,业务将变得“定义即可见”,也将极大地提升数据的价值。
Apache Doris 在京东广告的应用实践
原有系统存在的问题
主要表现以下几个方面:
-
原有系统已经逐渐无法满足我们日常业务的性能需求。
-
日常业务所需的 Schema Change,Rollup 等操作,在原有系统上有极高的人力成本。
-
原有系统的数据无法迁移,扩容需要重刷全部历史数据,运维成本极高。
-
在“618”和“双 11”的时候,原有系统会成为我们对外服务的一个隐患。
因此需要一个合适的数据查询引擎来替代原有系统,考虑到团队的人力和研发能力,选择使用开源的 OLAP 引擎来替换原有系统。
技术选型
-
查询
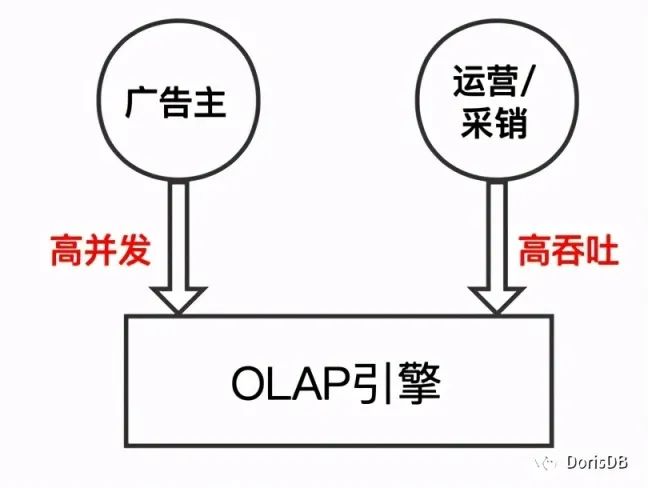
为广告主提供在线报表数据查询服务,因此该 OLAP 查询引擎必须满足:可以支持高并发查询,可以毫秒级返回数据,且可以随着业务的发展水平扩展。此外也承接了越来越多运营和采销同事的多维数据分析的需求,因此希望该 OLAP 引擎也可以支持高吞吐的 Ad-hoc 查询。
-
数据导入
需要同时支持离线(T+1)大规模数据和实时(分钟级间隔)数据的导入,数据导入后即可查询,保证数据导入的实时性和原子性。离线数据(几十 G)的导入任务需要在 1 小时内完成,实时数据(百 M 到几 G)的导入任务需要在 10 分钟内完成。
-
扩容
在“618”这类大促前通常会进行扩容,因此需要新系统扩容方便,无需重刷历史数据来重新分布数据,且扩容后原有机器的数据最好可以很方便地迁移到新机器上,避免造成数据倾斜。
根据日常业务的需要,经常会进行 Schema Change 操作。由于原有系统对这方面的支持很差,希望新系统可以进行 Online Schema Change,且对线上查询无影响。
-
数据修复
由于业务的日常变更会对一些表进行数据修复,因此新系统需要支持错误数据的删除,从而无需重刷全部历史数据,避免人力和计算资源的浪费。
目前开源的 OLAP 引擎很多,但由于面临大促的压力,需要尽快完成选型并进行数据迁移,因此只考察比较出名的几个 OLAP 系统:ClickHouse,Druid 和 Doris。
最终选择 Doris 来替换原有系统,主要基于以下几方面的考虑:
-
Doris 的查询速度是亚秒级的,并且相对 ClickHouse 来说,Doris 对高并发的支持要优秀得多。
-
Doris 扩容方便,数据可以自动进行负载均衡,解决了原有系统的痛点。ClickHouse 在扩容时需要进行数据重分布,工作量比较大。
-
Doris 支持 Rollup 和 Online Schema Change,这对日常业务需求十分友好。而且由于支持 MySQL 协议,Doris 可以很好地和之前已有的系统进行融合。而 Druid 对标准 SQL 的支持有限,并且不支持 MySQL 协议,改造成本很高。
广告场景应用
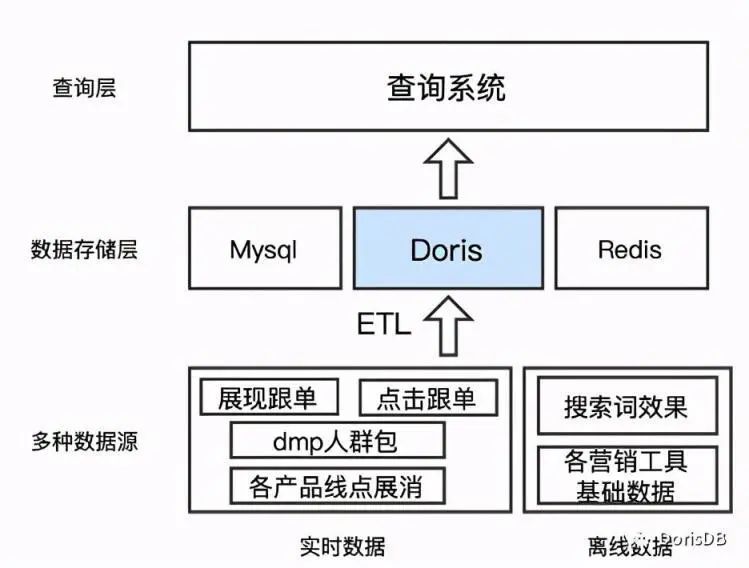
经过对系统的改造,目前使用 Doris 作为系统中的一个数据存储层,汇总了离线和实时数据,也为上层查询系统提供统一的效果数据查询接口。如下图所示:
-
数据导入
日常实时数据主要包含展现/点击跟单数据,DMP 人群包的效果数据以及十几条产品线的点击,展现和消耗数据,导入时间间隔从 1 分钟到 1 小时不等,数据量在百 M 左右的可以秒级导入,数据量在 1G 左右的可以在 1 分钟内完成。离线数据主要包含搜索词的效果数据和各种营销工具的基础数据,大多数都是 T+1 数据,每日新增数据量在 20G-30G,导入耗时在 10-20 分钟。
-
预计算
大多数效果数据报表,广告主的查询维度相对固定且可控,但要求能在毫秒级返回数据,所以必须保证这些查询场景下的性能。Doris 支持的聚合模型可以进行数据的预聚合,将点击,展现,消耗等数据汇总到建表时指定的维度。
此外,Doris 支持建立 Rollup 表(即物化视图)也可以在不同维度上进行预聚合,这种自定义的方式相比 Kylin 的自动构建 cube,有效避免了数据的膨胀,在满足查询时延的要求下,降低了磁盘占用。Doris 还可以通过 Rollup 表对维度列的顺序进行调整,避免了 Kylin 中因过滤维度列在 HBase RowKey 后部而造成的查询性能低下。
-
现场计算
对于一些为广告主提供的营销工具,维度和指标通常会有 30~60 列之多,而且大部分查询要求按照所有维度列进行聚合,由于维度列较多,这种查询只能依赖于现场计算能力。目前对于这种类型的查询请求,会将其数据尽量均匀分布到多台 BE 上,利用 Doris MPP 架构的特性,并行计算,并通过控制查询时间范围(一个月),可以使 TP99 达到 3s 左右。
-
业务举例
正是由于 Doris 具有自定义的预计算能力和不俗的现场计算能力,简化了日常工作。以为广告主提供的营销工具“行业大盘”为例,如图所示,这种业务场景下,不仅要计算广告主自身的指标数据,还需计算广告主所在类目的指标数据,从而进行对比。
原有系统数据分片只能按照指定列进行散列,没有分布式查询计划,就不能汇总类目维度数据。原先为了解决这种业务场景,虽然底层是同一数据源,但需要建两个表,一个是广告主维度表,一个是类目维度表,维护了两个数据流,增大了工作负担。
使用了 Doris 之后,广告主维度表可以 Rollup 出类目维度表。查询广告主维度数据时可以根据分区分桶(按照时间分区,按照广告主 ID 分桶)确定一个 Tablet,缩小数据查询范围,查询效率很高。查询类目维度时,数据已经按照广告主 ID 进行分片 ,可以充分利用 Doris 现场计算的能力,多个 BE 并行计算,实时计算类目维度数据,在我们的线上环境也能实现秒级查询。这种方案下数据查询更加灵活,无需为了查询性能而维护多个预计算数据,也可以避免多张表之间出现数据不一致的问题。
实际使用效果
-
日常需求
Doris 支持聚合模型,可以提前聚合好数据,对计算广告效果数据点击,展现和消耗十分适合。对一些数据量较大的高基数表,可以对查询进行分析,建立不同维度或者顺序的的 Rollup 表来满足查询性能的需求。
Doris 支持 Online Schema Change,相比原有系统 Schema Change 需要多个模块联动,耗费多个人力数天才能进行的操作,Doris 只需一条 SQL 且在较短时间内就可以完成。对于日常需求来说,最常见的 Schema Change 操作就是加列,Doris 对于加列操作使用的是 Linked Schema Change 方式,该方式可以无需转换数据,直接完成,新导入的数据按照新的 Schema 进行导入,旧数据可以按照新加列的默认值进行查询,无需重刷历史数据。
Doris 通过 HLL 列和 BITMAP 列支持了近似/精确去重的功能,解决了之前无法计算 UV 的问题。
日常数据修复,相较于以前有了更多的方式可以选择。对于一些不是很敏感的数据,我们可以删除错误数据并进行重新导入;对于一些比较重要的线上数据,我们可以使用 Spark on Doris 计算正确数据和错误数据之间的差值,并导入增量进行修复。这样的好处是,不会暴露一个中间状态给广告主。还有一些业务会对一个或多个月的数据进行重刷。目前在测试使用 Doris 0.12 版本提供的 Temp Partition 功能,该功能可以先将正确数据导入到 Temp Partition 中,完成后可以将要删除的 Partition 和 Temp Partition 进行交换,交换操作是原子性的,对于上层用户无感知。
-
大促备战
Doris 添加新的 BE 节点后可以自动迁移 Tablet 到新节点上,达到数据负载均衡。通过添加 FE 节点,则可以支撑更高的查询峰值,满足大促高并发的要求。
大促期间数据导入量会暴增,而且在备战期间,也会有憋单演练,在短时间内会产生大量数据导入任务。通过导入模块限制 Load 的并发,可以避免大量数据的同时导入,保证了 Doris 的导入性能。
Doris 在团队已经经历了数次大促,在所有大促期间无事故发生,查询峰值 4500+qps,日查询总量 8 千万+,TP99 毫秒级,数据日增量近 300 亿行,且实时导入数据秒级延迟。
-
使用实践
Doris 支持低延时的高并发查询和高吞吐的 Ad-hoc 查询,但是这两类查询会相互影响,迁移到 Doris 的初期日常线上的主要问题就是高吞吐的查询占用资源过多,导致大量低延时的查询超时。后来使用两个集群来对两类查询进行物理隔离,解决了该问题。
Doris 在 0.11 版本时 FE 的 MySQL 服务 IO 线程模型较为简单,使用一个 Acceptor+ThreadPool 来完成 MySQL 协议的通信过程,单个 FE 节点在并发较高(2000+qps 左右)的时候会出现连接不上的问题,但此时 CPU 占用并不高。在 0.12 版本的时候,Doris 支持了 NIO,解决了这个问题,可以支撑更高的并发。也可以使用长连接解决这个问题,但需要注意 Doris 默认对连接数有限制,连接占满了就无法建立新的连接了。
基于 Doris 的小程序用户增长实践
首先为什么要做思域精细化运营呢,这起源于两个痛点:
-
私域用户的价值不突出
-
比如:有 100 万个用户,想给高收入人群去推荐奢侈品的包包,但是不知道在这 100 万人里面有多少人是这种高收入人群
-
缺乏主动触达的能力
然后针对这两个问题,产品上面提出了一个解决方案 -- 就是分层运营,它主要分为两部分:一个是运营触达,还有一个是精细化的人群。
这套解决方案的收益和价值:
对于开发者来说:
-
合理地利用私域流量提升价值
-
促进用户活跃和转化
对于整个生态来讲:
-
提高了私欲利用率和活跃度
-
激活了开发者主动经营的意愿
-
促进了生态的良性循环
用户分层技术难点
首先给大家简单介绍遇到的四个难点:
1.TB 级数据。数据量特别大,前面讲到是基于画像和行为去做的一个用户分层,数据量是特别大的,每天的数据量规模是 1T +
2.查询的频响要求极高,毫秒级到秒级的一个要求。前面介绍 B 端视角功能时大家有看到,有一个预估人数的功能,用户只要点击 ”预估人数“ 按钮,需要从 TB 级的数据量级里面计算出筛选出的人群人数是多少,这种要在秒级时间计算 TB 级的数量的一个结果的难度其实可想而知
3.计算复杂,需要动静组合。怎么理解?就是现在很多维度是没办法去做预聚合的,必须去存明细数据,然后去实时的计算,这个后面也会细讲
4.产出用户包的时效性要求高。这个比较好理解,如果产出特别慢的话,肯定会影响用户体验
针对上面的四个难点,解法是:
针对第一个难点 --> 压缩存储,降低查询的数量级。
具体选型就是使用 Bitmap 存储,这解法其实很好理解,不管现在主流的 OLAP 引 擎有多么厉害,数据量越大,查询肯定会越慢,不可能说数据量越大,我查询还是一直不变的,这种其实不存在的,所以我们就需要降低存储。
针对第二和第三个难点 --> 选择合适计算引擎
在调研了当前开源的包括 ClickHouse, Doris, Druid 等多种引擎后,最终选择了基于 MPP 架构的 OLAP 引擎 Doris。
这里可以简单跟大家介绍一下选择 Doris 的原因,从性能来说其实都差不多,但是都 Doris 有几个优点:
第一:它是兼容 Mysql 协议,也就是说你的学习成本非常低,基本上大家只要了解 mysql, 就会用 Doris, 不需要很大的学习成本。
第二:Doris 运维成本很低,基本上就是自动化运维。
针对第四个难点 --> 选择合适的引擎
通过对比 Spark 和 Doris,我们选择了 Doris ,后面会详细讲为什么会用 Doris。
用户分层的架构和解决方案
分层运营架构:
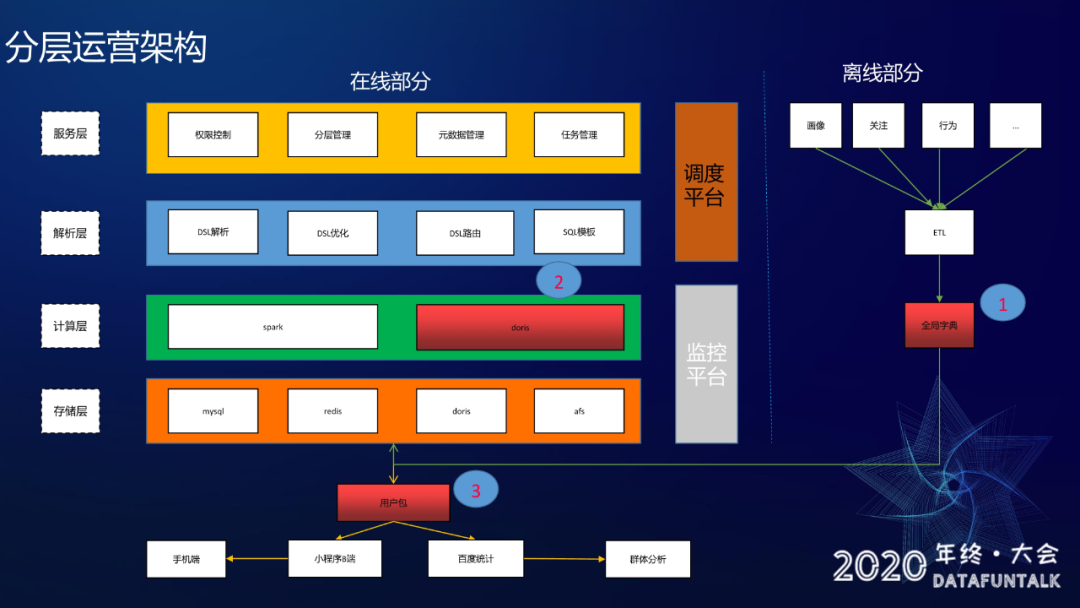
架构的话分为两部分,就是在线部分跟离线部分。
在线部分:
分为了四层:服务层、解析层、计算层跟存储层,然后还有调度平台和监控平台。
服务层,主要功能包含:
-
权限控制:主要是户权限、接口权限的控制
-
分层管理:主要是是对用户筛选的增删改查
-
元数据管理:主要是对页面元素、ID-Mapping 这类数据的管理
-
任务管理:主要是支持调度平台任务的增删改查
解析层,是对 DSL 的一个解析、优化、路由以及 Sql 模板:
比如要查在线预估人数,首先会在解析层做一个 DSL 的解析,之后根据不同情景做 DSL 的优化,比如选择了近七天活跃且近七天不活跃的用户,这种要七天活跃和七天不活跃的交集显然就是零了,对不对?像这样情况在优化层直接将结果 0 返回给用户就不会再往下走计算引擎,类似还有很多其他优化场景。然后优化完之后会使用 DSL 路由功能,根据不同查询路由到不同的 Sql 模板进行模板的拼接。
计算层,计算引擎使用 Spark 和 Doris:
-
Spark:离线任务
-
Doris:实时任务
存储层:
-
Mysql:主要用来存用户分层的一些用户信息
-
Redis:主要用作缓存
-
Doris:主要存储画像数据和行为数据
-
AFS:主要是存储产出的用户包的一些信息
调度平台:
-
主要是离线任务的调度
-
监控平台:
-
整个服务稳定性的监控
离线部分:
离线部分的话主要是对需要的数据源(比如说画像、关注、行为等数据源)做 ETL 清洗,清洗完之后会做一个全局字典并写入 Doris。任务最终会产出用户包,并会分发给小程序 B 端跟百度统计:
-
小程序 B 端:推送给手机端用户
-
百度统计:拿这些用户包做一次群体分析
以上就是一个整体的架构。
图中大家可以看到有几个标红的地方,同时也用数字 1、2、3 做了标记,这几个标红是重点模块,就是针对于上面提到的四个难点做的重点模块改造,接下来会针对这三个重点模块一一展开进行讲解。
1、全局字典
首先讲解全局字典这个模块,全局字典的目的主要是为了解决难点一:数据量大,需要压缩存储同时压缩存储之后还要保证查询性能。
为啥要用全局字典:
这里大家可能会有一个疑问,就是说用 BitMap 存储为啥还要做全局字典?这个主要是因为 Doris 的 BitMap 功能是基于 RoaringBitmap 实现的,因此假如说用户 ID 过于离散的时候,RoaringBitmap 底层存储结构用的是 Array Container 而不是 BitMap Container,Array Container 性能远远差于 BitMap Container。因此我们要使用全局字典将用户 ID 映射成连续递增的 ID,这就是使用全局字典的目的。
全局字典的更新逻辑概况:
这里是使用 Spark 程序来实现的,首先加载经过 ETL 清洗之后各个数据源(画像、关注、行为这些数据源)和全局字典历史表(用来维护维护用户 ID 跟自增 ID 映射关系),加载完之后会判断 ETL 里面的用户 ID 是否已经存在字典表里面,如果有的话,就直接把 ETL 的数据写回 Doris 就行了,如果没有就说明这是一个新用户,然后会用 row_number 方法生成一个自增 ID ,跟这个新用户做一次映射,映射完之后更新到全局字典并写入 Doris。
2、Doris
接下来介绍第二个重点模块 Doris。
2.1 Doris 分桶策略
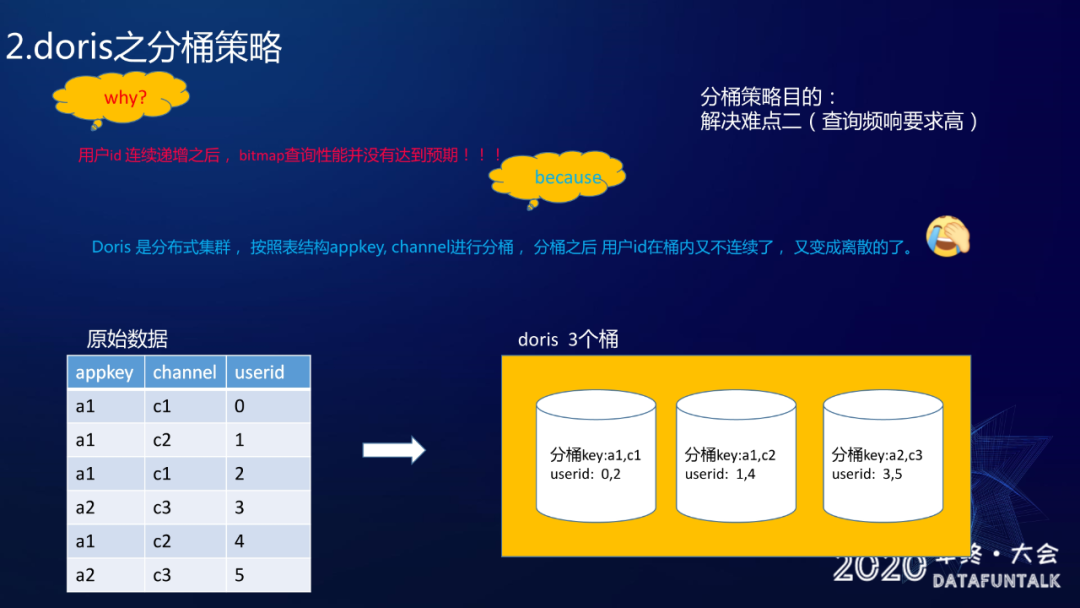
分桶策略的目的是为了解决难点二:查询频响要求高。
为啥要做分桶策略:
之前使用了全局字典保证用户的连续递增,但是发现用了全局字典之后,BitMap 的查询性能其实并没有达到预期。 Doris 其实是分布式的一个集群,它会按照某些 Key 进行分桶,也就是分桶之后用户 ID 在桶内就不连续,又变成零散的了。
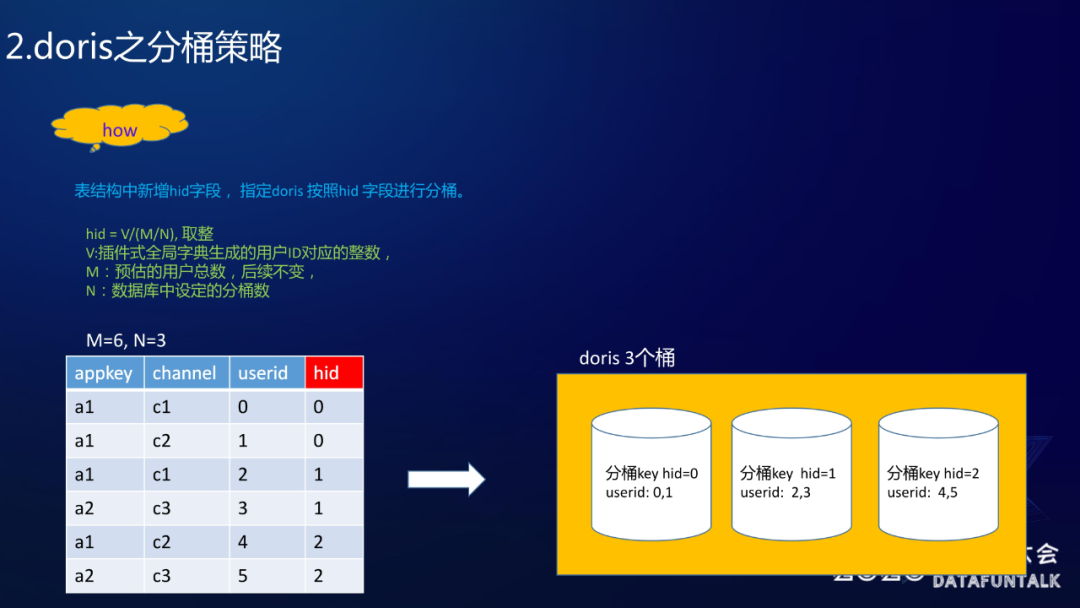
方案其实就是在表里面增加了一个 hid 的字段,然后让 Doris 按照 hid 字段进行分桶,这里 hid 生成算法是:
hid = V/(M/N) 然后取整
其中:
-
V:全局字典的用户 ID 对应的整数
-
M:预估的用户总数
-
N:分层数
大家可以看一下:userid 是六个即 0~5,所以 M= 6;分为三个桶,N = 3;因此 M 除以 N 就等于二。这样的话我就要用 userid 去除以二,然后取整作为 hid。可以看一下,比如说 userid 是零,0÷2 取整为 0 ,userid 是一的话,hid 还是这样,因为 1÷2 的整数部分是零;同理 2÷2 、3÷2 是一,4÷2、5÷2 是二,这样的话就把 userid 跟 hid 做对应,然后再根据 hid 做分层。大家可以看到分层结果,hid = 0 时 userid 是 0、1,hid = 1 时 userid 是 2、3,hid = 2 时 userid 是 4、5,这样就保证了桶内连续。
2.2 doris 之用户画像标签优化
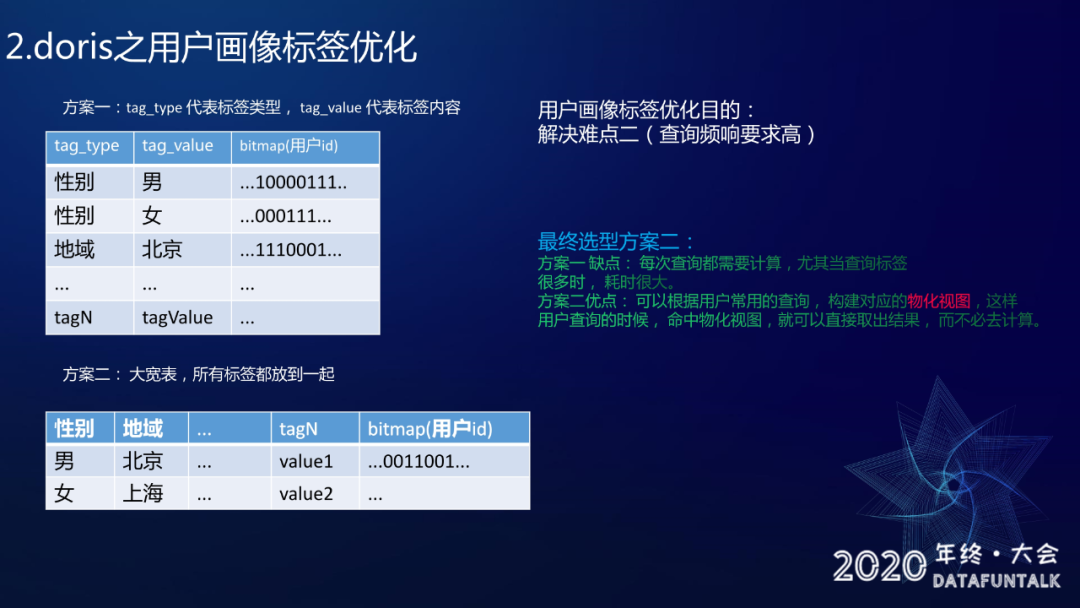
画像标签优化解决的难点也是难点二:查询频响要求高。
方案一:
tag_type, tag_value 。tag_type 是用来记录标签的类型,tag_value 是用来记录标签的内容。
如图所示:比如说 tag_type 是性别,tag_value 可能是男或女,bitmap 这里就是存储所有性别是男的用户 id 列表。
同样对于 tag_type 是地域、tag_value 是北京,bitmap 存储的是所有地域在北京的用户 id 列表。
方案二:
大宽表,使用大宽表在一行记录了所有的标签,然后使用 bitmap 记录这个标签的用户 id 列表。
最终选择方案二,为什么没有选方案一呢 ?因为方案一它是一个标签对应一个用户 bitmap,当想查一个联合的结果就比较耗时,比如想查询性别是男且区域是北京的所有用户,这样的话需要取出 “男” 的用户和 “北京“ 的用户,两者之间做一个交集。肯定会有计算量会有更多的时间消耗,但是如果用大宽表去做存储的话,就可以根据用户常用的查询去构建一个物化视图,当用户的查询(比如在北京的男性)命中了物化视图,就可以直接去取结果,而不用再去做计算,从而降低耗时。
这里还有一个知识点跟大家分享一下:在使用 Doris 的时候,一定要尽量去命中它的前缀索引跟物化视图,这样会大大的提升查询效率。
2.3 doris 之动静组合查询

动静组合查询,对应的难点是难点三:计算复杂。
首先介绍一下什么叫动静组合查询:
-
静态查询:定义为用户维度是固定的,就是可以进行预聚合的查询为静态查询。比如说男性用户,男性用户个就是一个固定的群体,不管怎么查用户肯定不会变,就可以提前进行预聚合的。
-
动态查询:主要偏向于一些行为,就是那种查询跟着用户的不同而不同。比如说查近 30 天收藏超过三次的用户,或者还有可能是近 30 天收藏超过四次的用户,这种的话就很随意,用户可能会查询的维度会特别的多,而且也没法没办法进行一个预聚合,所以称之为动态的一个查询。
然后小程序用户分层,相比于同类型的用户分层功能增加了用户行为筛选,这也是小程序产品的特点之一。比如说可以查近 30 天用户支付订单超过 30 元的男性, 这种 ”近 30 天用户支付订单超过 30 元“ 的查询是没办法用 bitmap 做记录的,也没办法说提前计算好,只能在线去算。这种就是一个难点,就是说怎么用非 bitmap 表和 bitmap 做交并补集的运算,为了解决这个问题,结合上面的例子把查询拆分为四步:查近 30 天用户支付订单超过 30 元的男性,且年龄在 20 ~30 岁的用户(具体查询语句参考 PPT 图片)
第一步先查 20~30 岁的男性用户。因为是比较固定,这里可以直接查 bitmap 表。
第二步要查近 30 天用户支付订单超过 30 元的用户。这种的话就没办法去查 bitmap 表了,因为 bitmap 没有办法做这种聚合,只能去查行为表。
第三步就是要做用户 ID 跟在 线 bitmap 的一个转化。Doris 其实已经提供了这样的功能函数:to_bitmap,可以在线将用户 id 转换成 bitmap。
第四步是求交集。就是第一步和第四步的结果求交集。
然后,整篇的核心其实是在第三步:Doris 提供了 to_bitmap 的功能,它帮我们解决了非 bitmap 表和 bitmap 联合查询的问题。
以上是基于 Doris 用户分层方案的一个讲解,基于上述方案整体的性能收益是:
-
95 分位耗时小于一秒
-
存储耗降低了 9.67 倍
-
行数优化了八倍
如何快速产出用户包

现在讲一下第三部分:用户包。这部分主要是用来解决难点四:产出用户包要求时效性高。这个其实也有两个方案:
方案一:调度平台 + spark。
这个其实比较容易理解,因为要跑离线任务很容易就想到了 spark。在这个调度平台里面用了 DAG 图,分三步:先产出用户的 cuid,然后再产出用户的 uid,最后是回调一下做一次更新。
方案二:调度平台 + solo。
-
执行的 DAG 图的话就是:solo 去产出 cuid,uid,还有回调。
-
solo:是百度云提供的 Pingo 单机执行引擎,可以理解为是一个类似于虚拟机的产品。
最终的方案选型选用了Doris。
方案一使用的是 Spark ,它存在几个问题:比如 Yarn 调度比较耗时,有时候也会因为队列的资源紧张而会有延迟,所以有时候会出现一个很极端的情况就是:产出零个用户,也要 30 分钟才能跑完,这种对用户的体验度非常不好。
方案二的话就是利用了 Doris 的 SELECT INTO OUTFILE 产出结果导出功能,就是查出的结果可以直接导出到 AFS,这样的效果就是最快不到三分钟就可以产出百万级用户,所以 Doris 性能在某些场景下比 Spark 要好很多。