关于flume的简介不再过多赘述,小伙伴们可参考官方文档及谷歌翻译进行了解~
一、使用架构
apache-flume-1.9.0
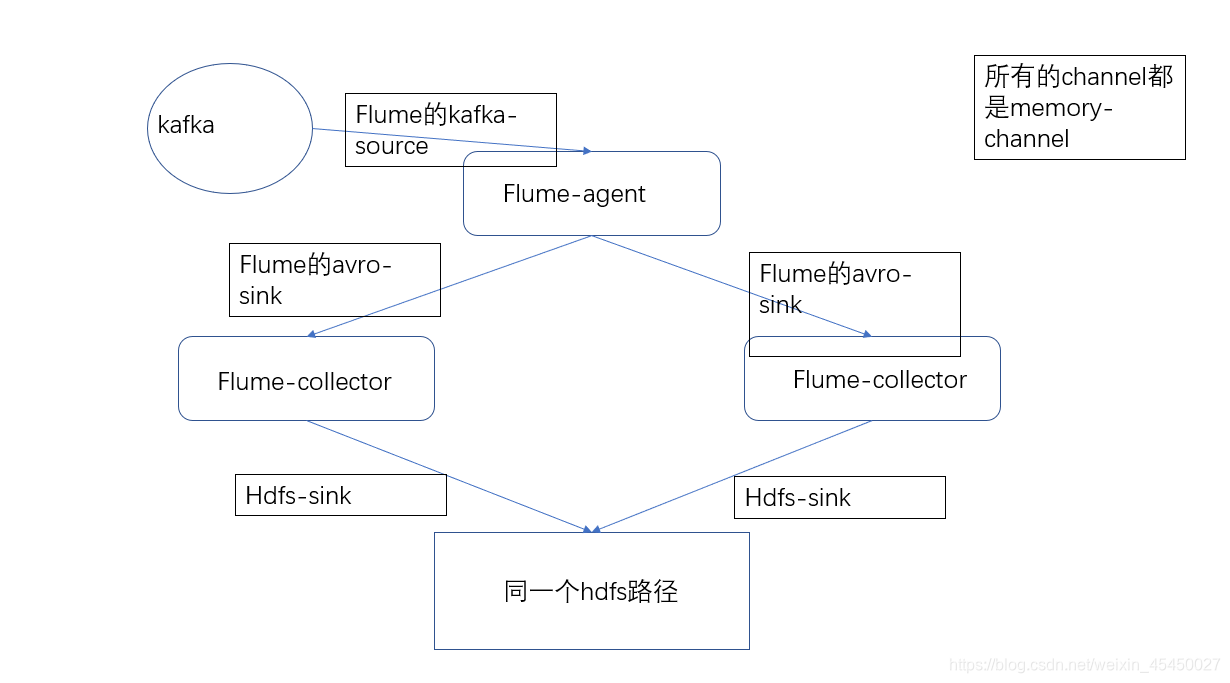
目前我在实际生产使用的方案是在网上参照大神们的一套高可用方案:agent-collector。
一个节点作为agent从kafka消费获取数据,然后通过avro-sink,传输到2个collector(当然同样用avro-source进行接收了),然后2个collector绑定为一个group,并配置为failover,写入hdfs-sink。
注:这里的agent和collector,是角色,两部分都用的flume-agent启动的。
整个过程的channel,都用的是memory,因为这样效率比较高,如果用filechannel,那么可能就不考虑这样的3节点了,大家酌情使用。
?
二、重点参数
? ? ? ? agent:
#this flume is an agent of kafka-flumeagent-flumecollector?
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2?
# set threads limit
agent1.sinks.k1.maxIoWorkers = 3
agent1.sinks.k2.maxIoWorkers = 3
#set channels c1
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 100000
agent1.channels.c1.transactionCapacity = 1000(少量多次)
agent1.channels.c1.keep-alive = 120(防止被kafka认为死掉踢出消费者组)
#set sources r1
agent1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent1.sources.r1.channels = c1
agent1.sources.r1.batchSize = 200
agent1.sources.r1.batchDurationMillis = 10(少量多次)
agent1.sources.r1.kafka.bootstrap.servers = xxx:x
agent1.sources.r1.kafka.topics = xxx
agent1.sources.r1.kafka.consumer.group.id = xxx
agent1.sources.r1.kafka.consumer.session.timeout.ms = 120000(防止被踢)
agent1.sources.r1.kafka.consumer.max.poll.interval.ms = 60000000(防止被踢)
# set sink1?
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = xx1
agent1.sinks.k1.port = x
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro?
agent1.sinks.k2.hostname = xx2
agent1.sinks.k2.port = x
#set group1
agent1.sinkgroups = g1
#set sink group1
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
#64.3 is more prior
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10(大则优先)
agent1.sinkgroups.g1.processor.priority.k2 = 5
#failover waiting time
agent1.sinkgroups.g1.processor.maxpenalty = 1000? ? ? ? collector:
# more prior than xx2
a1.sources = r1
a1.channels = c1
a1.sinks = hdfs_k1
#
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.keep-alive = 120
#properties of avro-AppSrv-source
a1.sources.r1.type = avro
a1.sources.r1.bind = xx1
a1.sources.r1.port = x
a1.sources.r1.channels=c1
#
#set sink to hdfs
a1.sinks.hdfs_k1.type=hdfs
a1.sinks.hdfs_k1.channel=c1
a1.sinks.hdfs_k1.hdfs.path=xxx
a1.sinks.hdfs_k1.hdfs.fileType=DataStream
a1.sinks.hdfs_k1.hdfs.writeFormat=TEXT
a1.sinks.hdfs_k1.hdfs.minBlockReplicas=1
a1.sinks.hdfs_k1.hdfs.rollInterval=0
a1.sinks.hdfs_k1.hdfs.rollCount=0
a1.sinks.hdfs_k1.hdfs.rollSize=134217728(这里设置为128M,减少小文件,同时基本等于hdfs的块大小,其实126、127兆更好,因为总会多写一点)
a1.sinks.hdfs_k1.hdfs.idleTimeout=120
a1.sinks.hdfs_k1.hdfs.batchSize=200
a1.sinks.hdfs_k1.hdfs.threadsPoolSize=3
a1.sinks.hdfs_k1.hdfs.maxOpenFiles=1(比较关键,一个是防止打开多个文件,未关闭的文件无法被hive识别到;同时为了保证隔天能及时关闭前一天的文件。)
#
a1.sinks.hdfs_k1.hdfs.filePrefix=%Y-%m-%d-xx1(其实配置了前缀就不必配置拦截器了,防止两个collector的文件重名)
a1.sinks.hdfs_k1.hdfs.fileSuffix=.txt
a1.sinks.hdfs_k1.hdfs.useLocalTimeStamp = false
#################################################################################################