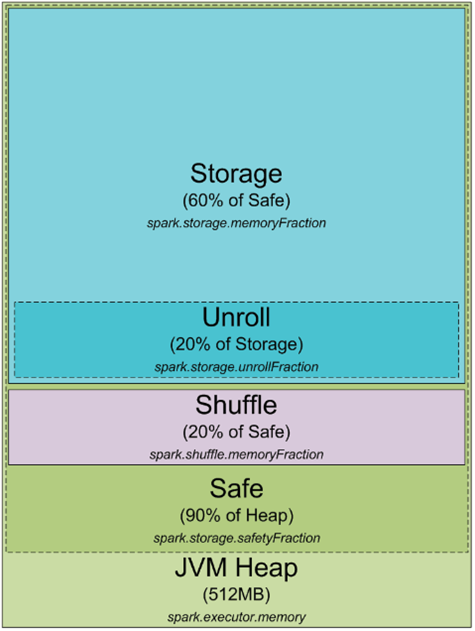
spark架构

底层可基于HDFS、Amason S3、Hbase等
Spark Core:包含Spark的基本功能,包含任务调度,内存管理,容错机制等,内部定义了RDDs(弹性分布式数据集),提供了很多APIs来创建和操作这些RDDs。为其他组件提供底层的服务。
http://spark.apache.org/docs/latest/cluster-overview.html

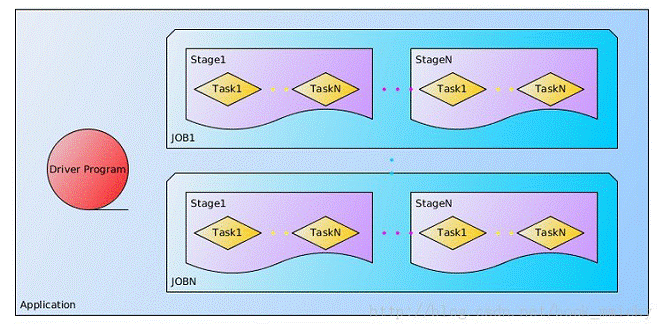
?
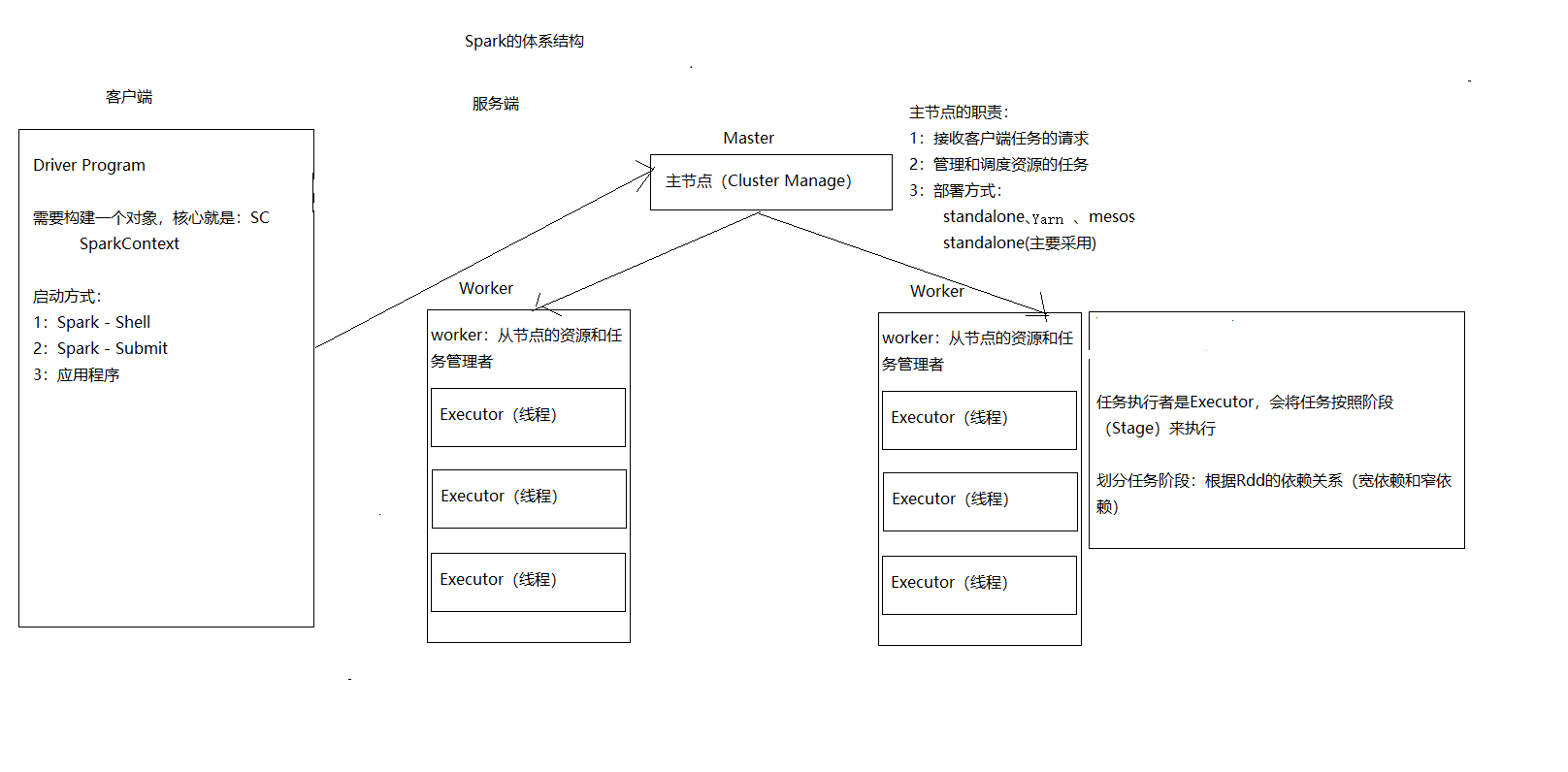
https://www.jianshu.com/p/eb2bc8d8ebc0
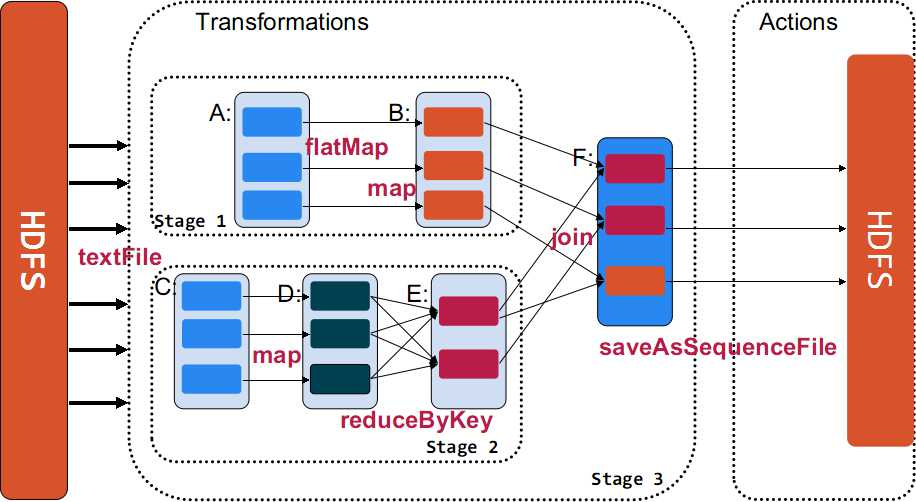
三大数据结构分别是:
- RDD : 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
基本运行流程:https://blog.csdn.net/dsdaasaaa/article/details/94181815
https://www.cnblogs.com/shishanyuan/p/4721326.html
https://blog.csdn.net/zxc123e/article/details/79912343
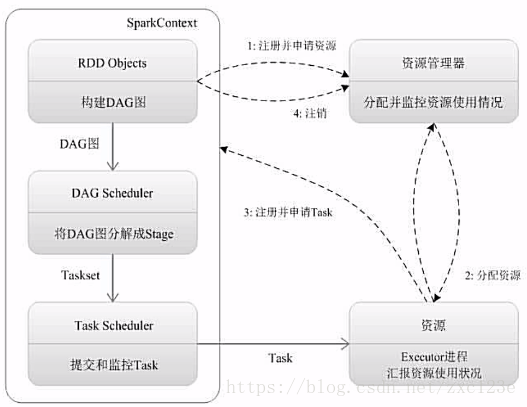
?