RabbitMQЪЧпу???
RabbitMQЪЧвЛИігЩerlangПЊЗЂЕФAMQP(Advanced Message Queue ИпМЖЯћЯЂЖгСаавщ )ЕФПЊдДЪЕЯж,
ФмЙЛЪЕЯжвьВНЯћЯЂДІРэ
бдМђвтърЕФНВ:RabbitMQЪЧвЛИіЯћЯЂДњРэ:ЫќНгЪмКЭзЊЗЂЯћЯЂ
rabbitmq гХЪЦ:
Лљгк erlang гябдПЊЗЂ, ОпгаИпВЂЗЂгХЕуЁЂ жЇГжЗжВМЪН
ОпгаЯћЯЂШЗШЯЛњжЦЁЂ ЯћЯЂГжОУЛЏЛњжЦ, ЯћЯЂПЩППадКЭМЏШКПЩППадИп
МђЕЅвзгУЁЂ дЫааЮШЖЈЁЂ ПчЦНЬЈЁЂ Жргябд
ПЊдД
Queue ЕФЬиад:
ЯћЯЂЛљгкЯШНјЯШГіЕФддђНјааЫГађЯћЗб
ЯћЯЂПЩвдГжОУЛЏЕНДХХЬНкЕуЗўЮёЦї
ЯћЯЂПЩвдЛКДцЕНФкДцНкЕуЗўЮёЦїЬсИпадФм
вЛ.RabbitMQ ЕЅЛњВПЪ№

ЙйЗНАцБО https://www.rabbitmq.com/
https://www.rabbitmq.com/download.html #ЙйЭјЯТдиЕижЗ
https://github.com/rabbitmq/rabbitmq-server/releases #github ЯТдиЕижЗ
ЗўЮёЦїЛЗОГ:
Ubuntu 1804 АВзАЕЅЛњАц RabbitMQ:
https://www.rabbitmq.com/install-debian.html#apt
ЕквЛжжЗНЪН:aptжБНгАВзА (АцБОВЛПЩбЁ,ФЌШЯАВзА)
1.ВщПДЕБЧАЯЕЭГФкШэМўЕФАцБО
apt-cache madison rabbitmq-server
2.ХфжУжїЛњУћНтЮі
[root@mq-sever1 ~]#cat /etc/hosts
10.0.0.101 mq-sever1 mq
3.жДааАВзА
apt -y install rabbitmq-server
4.RabbitMQ ВхМўЙмРэ
ЖЫПкЪЙгУЫЕУї
5672 #ПЭЛЇЖЫЪЙгУ,РрЫЦгкmysql 3306
15672 #webНчУц,ПЩвдЯдЪОrabbitmqЕФдЫаазДЬЌ
25672 #МЏШКЭЈаХЪЙгУ
ВщПДгаФФаЉВхМў
rabbitmq-plugins list
ПЊЦєwebНчУцЙмРэВхМў
rabbitmq-plugins enable rabbitmq_management
(3.8.4АцБОжЎЧАеЫКХУмТыФЌШЯЪЧguestЕЧТМЕФ)
ЕкЖўжжЗНЪН:(ПЩвдбЁдёАцБО)
https://www.rabbitmq.com/download.html
1.АВзАвРРЕ
apt-get install curl gnupg debian-keyring debian-archive-keyring apt-transport-https -y
2.ЕМШыЧЉУћЕФkey
apt-key adv --keyserver "hkps://keys.openpgp.org" --recv-keys "0x0A9AF2115F4687BD29803A206B73A36E6026DFCA"
3.ЬэМгвЛИіerlangВжПт
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/gpg.E495BB49CC4BBE5B.key | sudo apt-key add -
Cloudsmith:RabbitMQ ДцДЂПт
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/gpg.9F4587F226208342.key | sudo apt-key add -
4.ЬэМгaptдД
жБНгдкУќСюааЬэМг ЛиГЕМДПЩ
sudo tee /etc/apt/sources.list.d/rabbitmq.list <<EOF
## Provides modern Erlang/OTP releases
##
deb https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
deb-src https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
## Provides RabbitMQ
##
deb https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
deb-src https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
EOF
ВщПД

5.жДааИќаТ;
apt update
6.жДааАВзА
apt-cache madison rabbitmq-serverВщПД

7.ПЊЦєwebНчУцЙмРэВхМў
rabbitmq-plugins enable rabbitmq_management
8.ЩшжУЕЧТМеЫЛЇ
ЩшжУеЫКХУмТы rabbitmqctl add_user smart 12345678
ИјеЫЛЇЩшжУШЈЯо rabbitmqctl set_user_tags smart administrator
ЕЧТМwebНчУц
ВщПДЛљБОаХЯЂ

Admin-Add a user ПЩвдДДНЈеЫКХ
ЕуЛїгУЛЇУћПЩвдзіаоИФШЈЯо;
ЕквЛжжЗНЗЈ
ЕуЛїДДНЈЕФгУЛЇУћsmart

ЕуЛїset permission

ЕкЖўжжЗНЗЈ
жДааrabbitmqctl set_permissions smart ".*" ".*" ".*"
бщжЄНсЙћ;

ДДНЈгУЛЇУћУмТывдМАЪкШЈзмНсШ§ИіУќСю:
rabbitmqctl add_user smart 12345678
rabbitmqctl set_user_tags smart administrator
rabbitmqctl set_permissions smart ".*" ".*" ".*"
Жў.rabbitmqЕФМЏШКВПЪ№
ЦеЭЈФЃЪН:
ДДНЈКУ RabbitMQ МЏШКжЎКѓЕФФЌШЯФЃЪНЁЃ(жЛЭЌВНдДЪ§Он)
queueДДНЈКѓ,ЯћЯЂжЛДцдквЛИіНкЕу,ЦфЫћНкЕуНігаЯрЭЌЕФдЊЪ§Он,МДЖгСаНсЙЙ,ЖгСаЪ§ОнБЃДцвЛВПЗж,ИУФЃЪНДцдквЛИіЮЪЬтОЭЪЧЕБ A НкЕуЙЪеЯКѓ,B НкЕуЮоЗЈШЁЕН A НкЕужаЛЙЮДЯћЗбЕФЯћЯЂЪЕЬх
ОЕЯёФЃЪН:
АбашвЊЕФЖгСазіГЩОЕЯёЖгСаЁЃ(Ъ§ОнЛсЭЌВН)
АбашвЊЕФЖгСазіГЩОЕЯёЖгСа, ДцдкгкЖрИіНкЕу, Ъєгк RabbitMQ ЕФ HA ЗНАИ(ОЕЯёФЃЪНЪЧдкЦеЭЈФЃЪНЕФЛљДЁЩЯ, діМгвЛаЉОЕЯёВпТд)ИУФЃЪННтОіСЫЦеЭЈФЃЪНжаЕФЪ§ОнЖЊЪЇЮЪЬт,
ЯћЯЂЪЕЬхЛсжїЖЏдкОЕЯёНкЕуМфЭЌВН, ЖјВЛЪЧдк consumer ШЁЪ§ОнЪБСйЪБРШЁ
ШБЕуЪЧ:НЕЕЭЯЕЭГадФм,вЊЯШЩшжУpolicy
МЏШКжагаСНжжНкЕуРраЭ:
ФкДцНкЕу: жЛНЋЪ§ОнБЃДцЕНФкДц;
ДХХЬНкЕу: БЃДцЪ§ОнЕНФкДцКЭДХХЬЁЃ
ФкДцНкЕуЫфШЛВЛаДШыДХХЬ, ЕЋЪЧЫќжДааБШДХХЬНкЕувЊКУ, МЏШКжа, жЛашвЊвЛИіДХ
ХЬНкЕуРДБЃДцЪ§ОнОЭзуЙЛСЫШчЙћМЏШКжажЛгаФкДцНкЕу, ФЧУДВЛФмШЋВПЭЃжЙЫќУЧ,
ЗёдђЫљгаЪ§ОнЯћЯЂдкЗўЮёЦїШЋВПЭЃЛњжЎКѓЖМЛсЖЊЪЇЁЃ
ЭЦМіЩшМЦМмЙЙ:
дквЛИі rabbitmq МЏШКРя, га 3 ЬЈЛђвдЩЯЛњЦї, Цфжа 1 ЬЈЪЙгУДХХЬФЃЪН, ЦфЫќНк
ЕуЪЙгУФкДцФЃЪН, ФкДцНкЕуЮоЗУЮЪЫйЖШИќПь, гЩгкДХХЬ IO ЯрЖдНЯТ§, вђДЫПЩзї
ЮЊЪ§ОнБИЗнЪЙгУЁЃ
ЛЗОГзМБИ:
3ЬЈАВзАrabbitmqЕФЛњЦї;АВзАВНжшВЮПМЩЯУцЕЅЛњВПЪ№Й§ГЬ;
mq1: 10.0.0.101
mq2: 10.0.0.102
mq3:10.0.0.103
1.жїЛњУћНтЮіХфжУ
vim /etc/hosts
10.0.0.101 mq-server1 mq1
10.0.0.102 mq-server2 mq2
10.0.0.103 mq-server3 mq3
ИФЭъКѓжиЦє;systemctl restart rabbitmq-server.service
ЯШжЊ:
Rabbitmq ЕФМЏШКЪЧвРРЕгк erlang ЕФМЏШКРДЙЄзїЕФ, ЫљвдБиаыЯШЙЙНЈЦ№ erlang ЕФМЏШКЛЗОГ,Жј Erlang ЕФМЏШКжаИїНкЕуЪЧЭЈЙ§вЛИі magic cookie РДЪЕЯжЕФ, етИіcookie ДцЗХдк /var/lib/rabbitmq/.erlang.cookie жа, ЮФМўЪЧ 400 ЕФШЈЯо,ЫљвдБиаыБЃжЄИїНкЕу cookie БЃГжвЛжТ, ЗёдђНкЕужЎМфОЭЮоЗЈЭЈаХ
МЏШКдРэЪОвтЭМ:
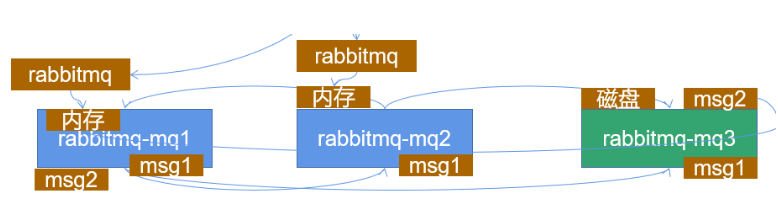
1.Ш§ЬЈcookieВЛвЛбљ ЮЊСЫвЊБЃжЄcookieБЃГжвЛжТ,НЋЦфжавЛЬЈЕФcookie ЭЌВНЕНСэЭтСНЬЈ
[root@mq-server1 ~]#cat /var/lib/rabbitmq/.erlang.cookie
CHMPABUQTTUBQKOOREBF
scp /var/lib/rabbitmq/.erlang.cookie 10.0.0.102:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie 10.0.0.103:/var/lib/rabbitmq/.erlang.cookie
#ПНБДЭъГЩКѓУПЬЈЗўЮёЦїжиЦєЗўЮё
systemctl restart rabbitmq-server.service
2.ВщПДЕБЧАМЏШКзДЬЌ
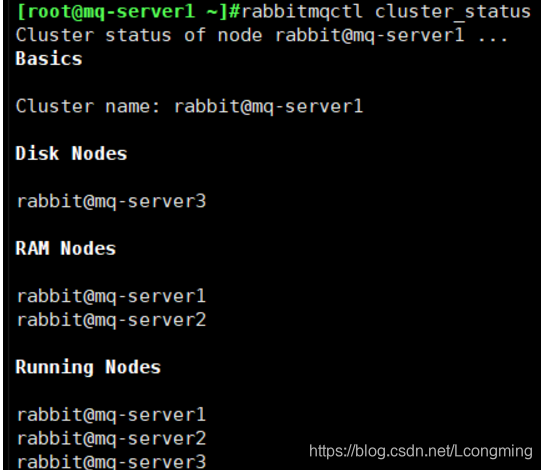
rabbitmqctl cluster_status
вдmq3ЮЊФПБъ,НЋСНИіСНИіЗўЮёЦїЬэМг
3.ДДНЈ RabbitMQ МЏШК:
mq1КЭmq2ЩЯВйзї
rabbitmqctl stop_app #ЭЃжЙmq1КЭmq2ЕФаДШыЗўЮё
rabbitmqctl reset #ЧхПедЊЪ§Он
#НЋrabbitmq-server1 ЬэМгЕНМЏШКЕБжа,ВЂГЩЮЊФкДцНкЕу,ВЛМг--ram ФЌШЯЪЧДХХЬНкЕу
rabbitmqctl join_cluster rabbit@mq-server3 --ram
#ЬэМгЭъГЩКѓПЊЦєapp
rabbitmqctl start_app

дкШЮКЮвЛЬЈжїЛњВщПД НсЙћвЛбљrabbitmqctl cluster_status
4.НЋМЏШКЩшжУЮЊОЕЯёФЃЪН :жЛвЊдкЦфжавЛЬЈНкЕужДаавдЯТУќСюМДПЩ:
rabbitmqctl set_policy ha-all "#" '{"ha-mode":"all"}'
5.бщжЄЕБЧАМЏШКзДЬЌ
rabbitmqctl cluster_status
6.вГУцбщжЄ;
гЩгкИеИежДааСЫrabbitmqctl reset #ЧхПедЊЪ§Он Вйзї,УЛгаеЫЛЇУмТыСЫЁЃжиаТЩшжУ
rabbitmqctl add_user smart 12345678
rabbitmqctl set_user_tags smart administrator
rabbitmqctl set_permissions smart ".*" ".*" ".*"
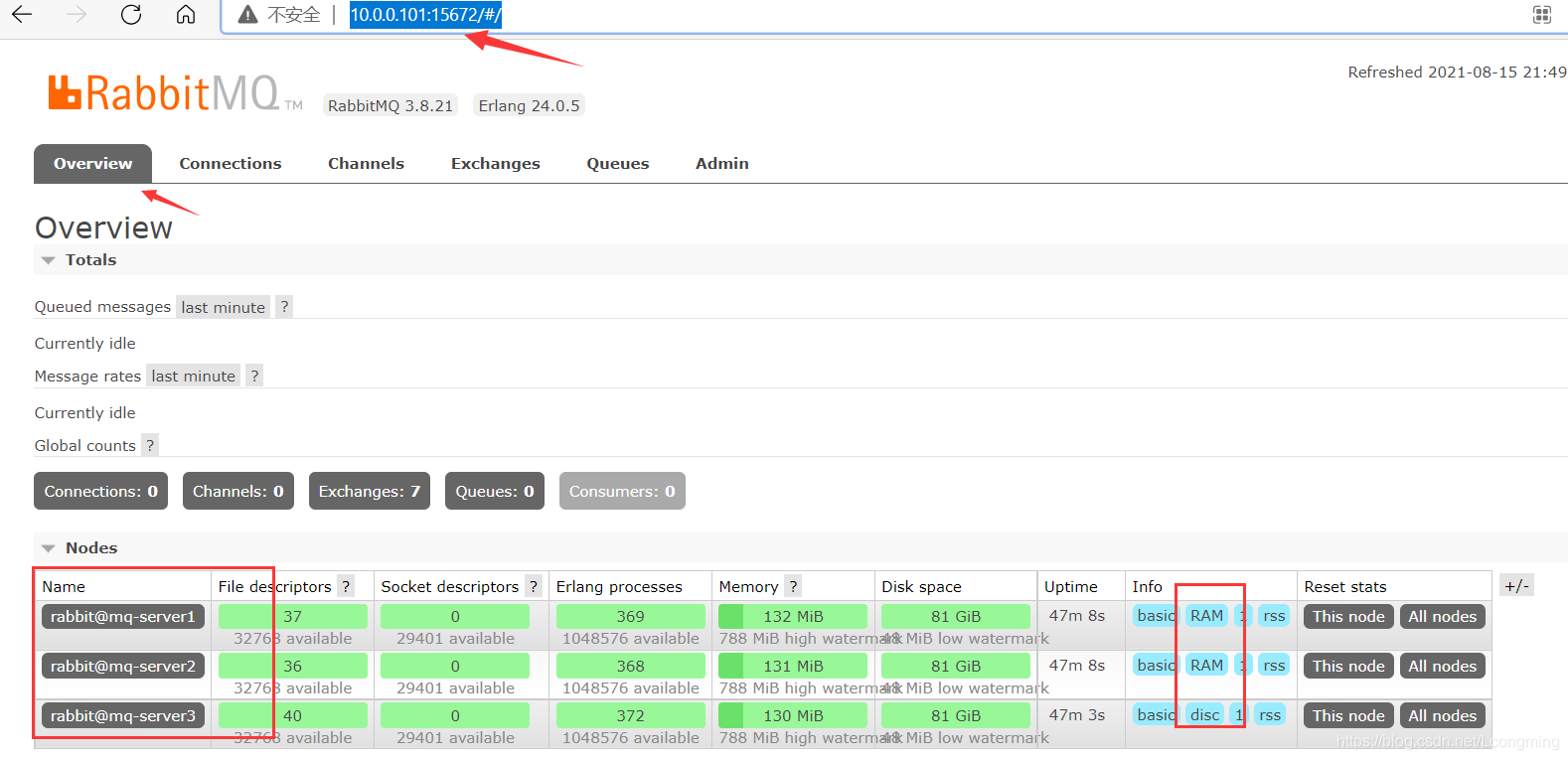
7.web НчУцбщжЄМЏШКзДЬЌГіДэЧщПі:
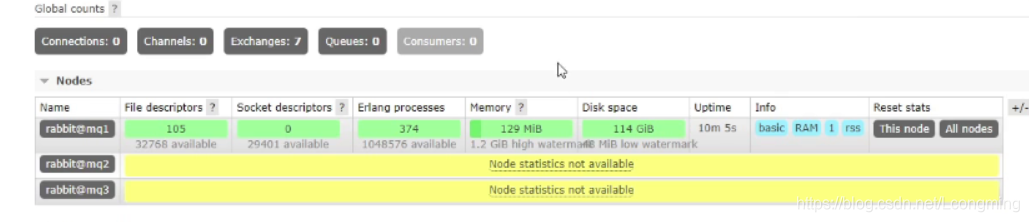
ВЛЦєгУ web ВхМўЕФ rabbitmq ЗўЮёЦї, Лсдк web НкЕуЬсЪОНкЕуЭГМЦаХЯЂВЛПЩгУ
rabbitmq-plugins enable rabbitmq_management #жДааКѓМДПЩНтОі
ЩшжУЭъГЩ,аЛаЛЙлЩЭ
