1. 数据库和数据仓库的区别
- 数据库:
真正存储和管理数据的,对数据有直接的处置权
关心的事情是 在线事务过程(OLTP) - 数据仓库:
可以利用一个或多个数据库的数据,进行数据分析。
关心的事情是 在线分析过程(OLAP)
2. hive运行原理
写sql语句,hive内部自动转成MapReduce程序执行。
原数据在hdfs上,sql语句需要使用表。
表是以目录形式存在hdfs的某个指定位置(warehouse)
可以通过数据加载的形式,把hdfs或本地的原数据加载到表(目录)中
表里的数据实际上是存放在这个目录下的文件
3. hive数据存储
3.1. 真实数据
- hive-site.xml中设置的数据仓库的位置就是hive在hdfs的根目录
- 数据仓库的路径(warehouse)同时也是default默认数据库的位置
- 新建的数据库在warehouse的路径下以 xxx.db 目录形式存在
- 不管是默认数据库还是新建数据库,数据都是在相应的数据库的目录下
以文件形式存在
3.2. 元数据
- 初始化的时候会在mysql创建一个元数据库
- 在元数据下有很多表,包括数据库,表,字段,位置,格式化等信息
- hive是通过元数据找到真实数据,如果元数据被篡改或删除,
即使真实数据存在,也无法使用
3.3. 执行过程
hive的执行顺序,先去mysql中找元数据,通过元数据找hdfs的真实数据
4. 分区和分桶
4.1. 分区
4.1.1. 什么是分区?
- 在表中的数据以目录级别进行划分
有独立的与原表字段之外的单独字段,使用的时候与原表字段没有区别 - 分区表的优势
- 提高查找效率
- 减少字段的存储
4.1.2. 分区表的使用

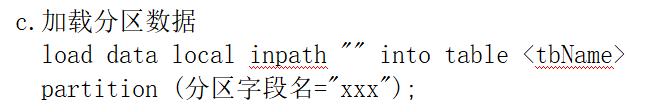
select * from xxx where 分区字段=xxx
- 单分区
只有一个分区字段,就是单分区。 - 多分区
如果有多个字段同时作为分区条件,就是多分区
多分区使用多层目录表示
4.2. 分桶
4.2.1. 分桶和分区的区别
分区:在hdfs上按照目录级别进行划分
分桶:在hdfs上按照文件级别进行划分
4.2.2. 分桶的使用
- 创建普通表,普通表里有数据
- 创建分桶表,定义分桶字段
- 将普通表的数据导入到分桶表中,可以进行分桶。
4.2.3. 分桶的原理
分桶本质上是MapReduce的分区,可以发现,在执行分桶操作的时候,reduce的数量就是等于桶的数量,默认以哈希值来分桶的。从某种意义上,可以把分桶就理解为MapReduce的分区。
4.2.4. 查询的时候分桶显示
与上面的分桶表已经没有关系了,任何表都可以使用以下语句查询
- a.按照某个字段分y桶,取第x桶数据
select * from tablesample (bucket x out of y on 字段) - b.完全随机抽取数据
select * from tablesample (bucket x out of y on rand())
5. 内部表和外部表
- 内部表和外部表
内部表:hive默认生成的表类型是管理表,也叫做内部表。
特点:删除表的时候,元数据和真实数据全部删除,比较危险。 - 外部表:create external table …
特点:删除表的时候,只删除表结构(元数据)
不删除表中的数据(hdfs上的真实数据)
再创建同名表的时候可以直接做数据的恢复
6. 排序(4个by)
- order by
select * from xxxx order by 字段 [desc]
reduceTask数量为1的全排序
与设定的reduce数量无关,不管设置多少,都按reduceTask=1执行
可以使用 order by field1 [desc],field2 [desc],… 进行二次排序 - sort by
只能针对把每个reduce中的数据进行排序,影响不了分组。
是MapReduce里的部分排序
每个文件有序,但是全局无序
结果写入文件,会生成与reduceTask数量一致个文件
结果直接输出到控制台,按照生成文件的数据顺序依次显示
可以使用 sort by field1 [desc],field2 [desc],… 进行二次排序 - distribute by
执行完查询操作之后的结果数据按某个字段的hashCode值分区,但是不排序
最终结果的分区数量要小于等于reduce的数量,或者为1
如果想排序,加 sort by 字段(可以为分区字段,也可以为非分区字段)
order by 以reduce数量为1执行,与distribute by分区相违背,不能使用 - cluster by
cluster by = distribute by + sort by
对同一个字段既分区又排序,可以直接使用cluster by,可以保证一个字段即分区,又全排序
7. 开窗函数
通过over函数 确定窗口数据。
区别:普通聚合函数最终只能返回一个数据,开窗聚合可以每条数据都返回。
8. 自定义函数
- UDF: 用户自定义普通函数
- UDAF: 用户自定义聚合函数(多进一出)
- UDTF: 用户自定义表生成函数(一进多出)
9. Hive优化
- 合理设置Map数量
- 合理设置reduce数量
- 尽量使用本地模式运行,本地模式运行的速度比分布式模式快很多
- 表连接的时候小表在左。