вЛЁЂFlinkгІгУПЊЗЂ
FlinkзїЮЊСїХњвЛЬхЕФМЦЫув§Чц,ЦфУцЖдЕФЪЧвЕЮёГЁОА,УцЯђЕФЪЙгУепЪЧПЊЗЂШЫдБКЭдЫЮЌЙмРэШЫдБЁЃ
FlinkгІгУГЬађ,вВНаFlinkзївЕЁЂFlinkJob.FlinkзївЕАќКЌСЫСНИіЛљБОЕФПщ:Ъ§ОнСї(DataStream)КЭзЊЛЛ(Tranformation)ЁЃDataStreamЪЧТпМИХФю,ЮЊПЊЗЂепЬсЙЉСЫAPIНгПк,TransformationЪЧДІРэааЮЊЕФГщЯѓ,АќКЌСЫЪ§ОнЕФЖСШЁЁЂМЦЫуЁЂаДГіЁЃЫљвдFlinkЕФзївЕжаЕФDataStreamAPIЕїгУ,ЪЕМЪЩЯЙЙНЈСЫЖрИігЩTransformationзщГЩЕФЪ§ОнДІРэСїЫЎЯп(Pipline)ЁЃ
жДааЪБ,FlinkгІгУБЛгГЩфГЩDataFlow,гЩЪ§ОнСїКЭзЊЛЛВйзїзщГЩЁЃУПИіDataFlowДгвЛИіЛђЖрИіЪ§ОндДПЊЪМ,ВЂвдвЛИіЛђЖрИіSinkЪфГіНсЪјЁЃDataFlowБОжЪЩЯЪЧвЛИігаЯђЮоЛЗЭМ(DAG),ЕЋЪЧдЪаэЭЈЙ§ЕќДњЙЙдьЬиЪтаЮЪНЕФгаЯђЮоЛЗЭМЁЃ
FlinkгІгУгЩЯрЭЌЕФЛљБОВПЗжзщГЩ:
- ЛёШЁВЮЪ§(ПЩбЁ)
? ? ? ? ШчЙћгаХфжУВЮЪ§,дђЖСШЁХфжУВЮЪ§,ПЩвдЪЧУќСюЪфШыЕФВЮЪ§,вВПЩвдЪЧХфжУЮФМўЁЃ
- ГѕЪМЛЏStreamжДааЛЗОГ
? ? ? ? етЪЧБиаывЊзіЕФ,ЖСШЁЪ§ОнЕФAPIвРРЕгкИУжДааЛЗОГЁЃ
- ХфжУВЮЪ§
? ? ? ? ЖСШЁЕНЕФВЮЪ§ПЩвдЪЧжДааЛЗОГВЮЪ§ЛђепвЕЮёВЮЪ§ЁЃетаЉВЮЪ§ЛсИВИЧflink.confжаФЌШЯЕФХфжУВЮЪ§ЁЃ
- ЖСШЁЭтВПЪ§Он
? ? ? ? FlinkзїЮЊЗжВМЪНжДаав§Чц,БОЩэУЛгаЪ§ОнДцДЂФмСІ,ЫљвдЖЈвхСЫвЛЯЕСаНгПкЁЂСЌНгЦїгыЭтВПДцДЂНјааНЛЛЅ,ЖСаДЪ§ОнЁЃ
- Ъ§ОнДІРэСїГЬ
? ? ? ? ЕїгУDataStreamЕФAPIзщГЩЪ§ОнДІРэЕФСїГЬ,ШчЕїгУDataStream.map().filter()ЁЁзщГЩвЛИіЪ§ОнСїЫЎЯпЁЃ
- НЋДІРэНсЙћаДШыЭтВП
? ? ? ? дкFlinkжаНЋЪ§ОнаДШыЭтВПЕФЙ§ГЬНазіSink,FlinkжЇГжаДГіЪ§ОнЕНKafkaЁЂHDFSЁЂHbaseЕШЭтВПДцДЂЁЃ
- ДЅЗЂжДаа
? ? ? ? StreamExecutionEnvironment#executeЪЧFlinkгІгУжДааЕФДЅЗЂШыПк,ЮоТлЪЧвЛАуЕФDataStreamAPIПЊЗЂЛЙЪЧTable&SQLПЊЗЂЖМЪЧШчДЫЁЃ
ЖўЁЂAPIВуДЮ
APIВуДЮШчЭМ:
 ?
?
- КЫаФЕзВуAPI
? ? ? ? КЫаФЕзВуAPIЬсЙЉСЫFlinkЕФзюЕзВуЕФЗжВМЪНМЦЫуЙЙНЈПщЕФВйзїAPI,АќКЌСЫProcessFunctionЁЂзДЬЌЁЂЪБМфКЭДАПкЕШВйзїЕФAPIЁЃ
? ? ? ? ProcessFunctionЪЧFlinkЬсЙЉЕФзюОпБэЯжСІЕФЕзВуЙІФмНгПкЁЃFlinkЬсЙЉЕЅСїЪфШыЕФProcessFunctionКЭЫЋСїЪфШыЕФCoProcessFuntion,ФмЙЛЖдЕЅИіЪТМўНјааМЦЫу,вВФмЙЛАДееДАПкЖдЪБМфНјааМЦЫуЁЃ
- КЫаФПЊЗЂAPI(DataStream/DataSet)
? ? ? ? ?DataStream/DataSetЪЙгУFluentЗчИёAPI,ЬсЙЉСЫГЃМћЪ§ОнДІРэЕФAPIНгПк,ШчгУЛЇжИЖЈЕФИїжжзЊЛЛаЮЪН,АќРЈСЌНг(Join)ЁЂОлКЯ(Aggregation)ЁЂДАПк(Window)ЁЂзДЬЌ(State)ЕШЁЃ
- ЩљУїЪНDSL API
? ? ? ? Table APIЪЧвдБэЮЊжааФЕФЩљУїЪНСьгђзЈгУгябд(Domain Specified Language,DSL)ЁЃБэЪЧЙиЯЕаЭЪ§ОнПтЕФИХФю,гУдкХњДІРэжаЁЃдкСїМЦЫужа,ЮЊСЫв§ШыЖЏЬЌБэЕФИХФю(Dynamic Table),гУРДБэДяЪ§ОнСїБэЁЃ
- НсЙЙЛЏAPI
? ? ? ? SQLЪЧFlinkЕФНсЙЙЛЏAPI,ЪЧзюИпВуДЮЕФМЦЫуAPI,гыTable APIЛљБОЕШМл,ЧјБ№дкгкЪЙгУЕФЗНЪНЁЃSQLгыTable APIПЩвдЛьКЯЪЙгУ,SQLПЩвдВйзїTable API ЖЈвхЕФБэ,Table APIвВФмВйзїSQLЖЈвхЕФБэКЭжаМфНсЙћЁЃ
Ш§ЁЂЪ§ОнСї
Ъ§ОнСїЪЧКЫаФЪ§ОнГщЯѓ,БэЪОвЛИіГжајВњЩњЕФЪ§ОнСїЁЃ
DataStreamЬхЯЕШчЭМ:
 ?
?
DataStreamSourceБОЩэОЭЪЧвЛИіDataStreamЁЃDataStreamSinkЁЂAsyncDataStreamЁЂBroadcastDataStreamЁЂBroadcastConnectedDataStreamЁЂQueryableDataStreamЖМЪЧЖдвЛАуDataStreamЖдЯѓЗтзАЁЃ
- DataStream
? ? ? ? DataStreamЪЧFlinkЪ§ОнСїЕФГщЯѓКЫаФ,ЦфЩЯЖЈвхСЫЖдЪ§ОнСїЕФвЛЯЕСаВйзї,ЭЌЪБвВЖЈвхСЫгыЦфЫћРраЭDataStreamЕФЯрЛЅзЊЛЛЙиЯЕЁЃУПИіDataStreamЖМгавЛИіTransformationЖдЯѓ,БэЪОИУDataStreamДгЩЯгЮЕФDataStreamЪЙгУИУTransformationЖјРДЁЃ
- DataStreamSource
? ? ? ? DataStreamSourceЪЧDataStreamЕФЦ№Еу,DataStreamSourceдкStreamExecutionEnvironmentжаДДНЈ,гЩStreamExecutionEnvrionment.addSource(SourceFunction)ДДНЈЖјРД,ЦфжаSourceFunctionжаАќКЌСЫDataStreamSourceДгЪ§ОндДЖСШЁЪ§ОнЕФОпЬхТпМЁЃ
- DataStreamSink
? ? ? ? Ъ§ОнДгDataSourceStreamжаЖСШЁ,ОЙ§жаМфЕФвЛЯЕСаДІРэВйзї,зюжеашвЊаДГіЕНЭтВПДцДЂ,ЭЈЙ§DataStream.addSink(SinkFunction)ДДНЈЖјРД,ЦфжаSinkFunctionЖЈвхСЫаДГіЪ§ОнЕНЭтВПДцДЂЕФТпМЁЃ
- KeyedStream
? ? ? ? KeyedStreamгУРДБэЪОИљОнжИЖЈЕФkeyНјааЗжзщЕФЪ§ОнСїЁЃвЛИіKeyedStreamПЩвдЭЈЙ§ЕїгУDataStream.keyBy()РДЛёЕУЁЃЖјдкKeyedStreamЩЯНјааШЮКЮTransformationЖМНЋзЊБфЛиDataStreamЁЃдкЯжЪЕжа,KeyedStreamАбkeyЕФаХЯЂаДШыСЫTransformationжаЁЃУПЬѕМЧТМжЛФмЗУЮЪЫљЪєKeyЕФзДЬЌ,ЦфЩЯЕФОлКЯКЏЪ§ПЩвдЗНБуЕиВйзїКЭБЃДцЖдгІkeyЕФзДЬЌЁЃ
- WindowedStream & AllWindowedStream
? ? ? ? WindowedStreamДњБэСЫИљОнkeyЗжзщЧвЛљгкWindowAssignerЧаЗжДАПкЕФЪ§ОнСїЁЃЫљвдWindowedStreamЖМЪЧДгKeyedStreamбмЩњЖјРДЕФЁЃдкWindowedStreamЩЯНјааШЮКЮTransformationвВЖМНЋзЊБфЛиDataStreamЁЃ
- JoinedStreams & CoGroupedStreams
? ? ? ? JoinЪЧCoGroupЕФвЛжжЬиР§,JoinedStreamsЕзВу ЪЙгУCoGroupedStreamsРДЪЕЯжЁЃ
????????
? ? ? ? ?СНепЧјБ№ШчЯТ:
????????CoGroupedВржиЕФЪЧGroup,ЖдЪ§ОнНјааЗжзщ,ЪЧЖдЭЌвЛИіkeyЩЯЕФСНзщМЏКЯНјааВйзїЁЃ
? ? ? ? JoinВржиЕФЪЧЪ§ОнЖд,ЖдЭЌвЛИіkeyЕФУПвЛЖддЊЫиНјааВйзїЁЃ
- ConnectedStreams
? ? ? ? ConnectedStreamsБэЪОСНИіЪ§ОнСїЕФзщКЯ,СНИіЪ§ОнСїПЩвдРраЭвЛбљ,вВПЩвдРраЭВЛвЛбљЁЃConnectedStreamsЪЪгУгкСНИігаЙиЯЕЕФЪ§ОнСїЕФВйзї,ЙВЯэstateЁЃ
- BroadcastStream & BroadcastConnectedStream
????????BroadcastStream ЪЕМЪЩЯЪЧЖдвЛИіЦеЭЈDataStreamЕФЗтзА,ЬсЙЉСЫDataStreamЕФЙуВЅааЮЊЁЃ
????????BroadcastConnectedStream вЛАугЩDataStream/KeyedDataStreamгыBroadcastStream СЌНгЖјРД,РрЫЦгкConnectedStreamЁЃ
- IterativeStream
????????IterativeDataStream ЪЧЖдвЛИіDataStreamЕФЕќДњВйзї,ДгТпМЩЯРДЫЕ,АќКЌIterativeStreamЕФDataflowЪЧвЛИігаЯђгаЛЗЭМ,дкЕзВужДааВуУцЩЯ,FlinkЖдЦфНјааСЫЬиЪтДІРэЁЃ
- AsyncDataStream
? ? ? ? AysncDataStreamЪЧИіЙЄОп,ЬсЙЉдкDataStreamЩЯЪЙгУвьВНКЏЪ§ЕФФмСІЁЃ
ЫФЁЂЪ§ОнСїAPI
? ? ? ? DataStreamAPIЪЧFlinkСїМЦЫуЕФзюГЃгУЕФAPI,ЯрБШгкTable & SQL APIИќМгЕзВуЁЃ
4.1 Ъ§ОнЖСШЁ
? ? ? ? Ъ§ОнЖСШЁЕФAPIЖЈвхдкStreamExecutionEnvironmanet,етЪЧFlinkСїМЦЫугІгУЕФЦ№Еу,ЕквЛИіDataStreamОЭЪЧДгЪ§ОнЖСШЁAPIжаЙЙдьГіРДЕФЁЃ
- ДгФкДцжаЖСШЁ

- ЮФМўжаЖСШЁ

- SockeНгШыЪ§Он

- здЖЈвхЖСШЁ


4.2 ДІРэЪ§Он
DataStreamAPI ЪЙгУFluentЗчИёДІРэЪ§Он,дкПЊЗЂЕФЪБКђЦфЪЕЪЧдкБраДвЛИіDataStreamзЊЛЛЙ§ГЬ,аЮГЩСЫDataStreamДІРэСДЁЃ

ДгЭМжаПЩвдПДЕН,ВЂВЛЪЧЫљгаЕФDataStreamЖМПЩвдЛЅЯрзЊЛЛЁЃ
- Map
? ? ? ? НгЪе1ИідЊЫи,ЪфГі1ИідЊЫиЁЃMapгІгУдкDataStreamЩЯ,ЪфГіНсЙћЮЊDataStreamЁЃ? DataStream#mapдЫЫуЖдгІЕФЪЧMapFunction,ЦфРрЗКаЭЮЊMapFunction<T,O>,TДњБэЪфШыЪ§ОнРраЭ,OДњБэВйзїНсЙћЪфГіРраЭЁЃ

- FlatMap
? ? ? ? НгЪе1ИідЊЫи,ЪфГі0ЁЂ1ЁЂ...ЁЂNИідЊЫиЁЃИУРрдЫЫугІгУдкDataStreamЩЯ,ЪфГіНсЙћЮЊDataStreamЁЃDataStream#flatMapЖдгІЕФНгПкЪЧFlatMapFuncion,ЦфРрЗКаЭЮЊFlatMapFunction<T,O>,TДњБэЪфШыЪ§ОнРраЭ,OДњБэВйзїНсЙћЪфГіРраЭЁЃ

- ?Filter
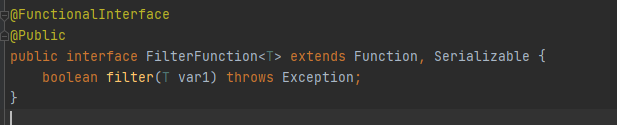
? ? ? ? Й§ТЫЪ§Он,ШчЙћЗЕЛиtrueдђИУдЊЫиМЬајЯђЯТДЋЕн,ШчЙћЮЊfalseдђНЋИУдЊЫиЙ§ТЫЕєЁЃИУРрдЫЫугІгУдкDataStreamЩЯ,ЪфГіНсЙћЮЊDataStreamЁЃDataStream#filterНгПкЖдгІЕФЪЧFilterFunction,ЦфРрЗКаЭЮЊFilterFunction<T>,TДњБэЪфГіКЭЪфГіЕФЪ§ОнРраЭЁЃ
- ?KeyBy
? ? ? ? НЋЪ§ОнСїдЊЫиНјааТпМЩЯЕФЗжзщ,ОпгаЯрЭЌKeyЕФМЧТМНЋБЛЛЎЗжЕНЭЌвЛзщЁЃKeyBy()ЪЙгУHash PartitionЪЕЯжЁЃИУдЫЫугІгУдкDataStreamЩЯ,ЪфГіНсЙћЮЊKeyedStreamЁЃЪфГіЕФЪ§ОнСїРраЭЮЊKeyedStream<T,KEY>,ЦфжаTДњБэKeyedStreamжадЊЫиЪ§ОнРраЭ,KEYДњБэТпМKeyЕФЪ§ОнРраЭЁЃ

?зЂвтвдЯТСНжжЪ§ОнВЛФмзїЮЊkeyЁЃ
- POJOРрЮДжиаДhashCode(),ЪЙгУСЫФЌШЯЕФObject.hashCode()ЁЃ
- Ъ§зщРраЭЁЃ
- Reduce
? ? ? ? АДееKeyedStreamжаЕФТпМЗжзщ,НЋЕБЧАЪ§ОнгызюКѓвЛДЮЕФReduceНсЙћНјааКЯВЂ,КЯВЂТпМгЩПЊЗЂепздМКЪЕЯжЁЃИУРрдЫЫугІгУдкKeyedStreamЩЯ,ЪфГіНсЙћЮЊDataStreamЁЃReduceFuntion<T>жаTДњБэKeyedStreamжадЊЫиЕФЪ§ОнРраЭЁЃ

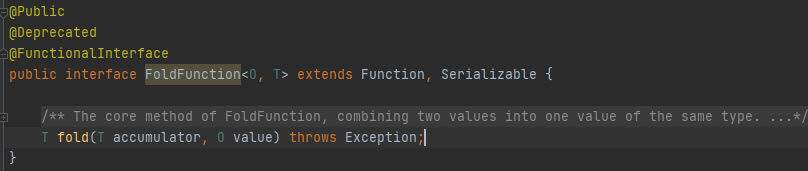
- ?Fold
? ? ? ? FoldгыReduceРрЫЦ,ЧјБ№дкгкFoldЪЧвЛИіЬсЙЉСЫГѕЪМжЕЕФReduce,гУГѕЪМжЕНјааКЯВЂдЫЫуЁЃИУРрдЫЫугІгУдкKeyedStreamЩЯ,ЪфГіНсЙћЮЊDataStreamЁЃFolderНгПкЖдгІЕФЪЧFoldFunction,ЦфРрЗКаЭЮЊFoldFunction<O,T>,OЮЊKeyStreamжаЕФЪ§ОнРраЭ,TЮЊГѕЪМжЕРраЭКЭFoldЗНЗЈЗЕЛижЕРраЭЁЃ

FoldFunction<O,T>вбОБЛБъМЧЮЊDeprecatedЗЯЦњ,ЬцДњНгПкЪЧAggregateFunction<IN,ACC,OUT>ЁЃ
?
- Aggregation
? ? ? ? НЅНјОлКЯОпгаЯрЭЌKeyЕФЪ§ОнСїдЊЫи,вдminКЭminByЮЊР§,minЗЕЛиЕФЪЧећИіKeyedStreamЕФзюаЁжЕ,АДееKeyНјааЗжзщ,ЗЕЛиУПИізщЕФзюаЁжЕЁЃОлКЯдЫЫуЪфГіНсЙћЮЊDataStreamЁЃ

- ?Window
? ? ? ? ЖдKeyedStreamЪ§Он,АДееKeyНјааЪБМфДАПкЧаЗжЁЃЪфГіНсЙћЮЊWindowedStreamЁЃЪфГіНсЙћЕФРрЗКаЭЮЊ<T,K,W extends Window>,TЮЊKeyedStreamжаЕФдЊЫиЪ§ОнРраЭ,KЮЊжИЖЈKeyЕФЪ§ОнРраЭ,WЮЊДАПкРраЭЁЃ

- WindowAll
? ? ? ? ЖдвЛАуЕФDataStreamНјааДАПкЧаЗж,МДШЋОжвЛИіДАПкЁЃЪфГіНсЙћЮЊAllWindowedStreamЁЃ

?зЂвт:дквЛАуЕФDataStreamЩЯНјааДАПкЧаЗж,ЭљЭљЛсЕМжТЮоЗЈВЂааМЦЫу,ЫљгаЕФЪ§ОнЖММЏжадкWindowAllЫузгЕФвЛИіTaskЩЯЁЃ
- Window Apply
? ? ? ? НЋWindowКЏЪ§гІгУЕНДАПкЩЯ,WindowКЏЪ§НЋвЛИіДАПкЕФЪ§ОнзїЮЊећЬхНјааДІРэЁЃWindow StreamгаСНжж:ЗжзщКѓЕФWindowedStreamКЭЮДЗжзщЕФAllWindowedStreamЁЃ
? ? ? ? 1ЁЂWindowedStream
? ??????????WindowedStreamЩЯгІгУЕФЪЧWindowFunction,ЪфГіНсЙћЮЊDataStreamЁЃWindowFunction<IN,OUT,KEY,W extends Window>жаINБэЪОЪфШыжЕЕФРраЭ,OUTБэЪОЪфГіжЕЕФРраЭ,KEYБэЪОKeyЕФРраЭ,WБэЪОДАПкЕФРраЭЁЃ

? ? ? ? 2ЁЂAllWindowedStream
????????????AllWindowedStreamЩЯгІгУЕФЪЧAllWindowFunction,ЪфГіНсЙћЮЊDataStreamЁЃAllWindowFunction<IN,OUT,KEY,W extends Window>жаINБэЪОЪфШыжЕЕФРраЭ,OUTБэЪОЪфГіжЕЕФРраЭ,KEYБэЪОKeyЕФРраЭ,WБэЪОДАПкЕФРраЭЁЃ

- Window Reduce
? ? ? ? дкWindowedStreamЩЯгІгУReduceFunction,НсЙћЪфГіЮЊDataStreamЁЃ

- Window Fold
? ? ? ? дкWindowedStreamЩЯгІгУFoldFunction,НсЙћЪфГіЮЊDataStreamЁЃ
- Window Aggregation
? ? ? ? ЭГМЦОлКЯдЫЫу,дкWindowedStreamгІгУИУдЫЫу,гІгУAggregationFunction,ЪфГіНсЙћЮЊDataStreamЁЃ
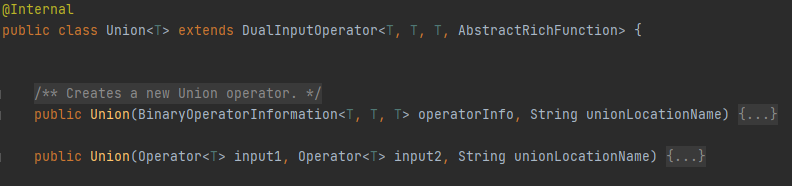
- Union
? ? ? ? АбСНИіЛђЖрИіDataStreamКЯВЂ,ЫљгаDataStreamжаЕФдЊЫиЖМЛсзщКЯГЩвЛИіаТЕФDataStream,ЕЋЪЧВЛШЅжи,ШчЙћдкздЩэЩЯгІгУUnionдЫЫу,дђУПИідЊЫидкаТЕФDataStramГіЯжСНДЮЁЃ
- Window Join
? ? ? ? дкЯрЭЌЪБМфЗЖЮЇЕФДАПкЩЯJoinСНИіDataStreamЪ§ОнСї,ЪфГіНсЙћЮЊDataStreamЁЃJoinКЫаФТпМдкJoinFunction<IN1,IN2,OUT>жаЪЕЯж,IN1ЮЊЕквЛИіDataStreamжаЕФЪ§ОнРраЭ,IN2ЮЊЕкЖўИіDataStreamжаЕФЪ§ОнРраЭ,OUTЮЊJoinНсЙћЕФЪ§ОнРраЭЁЃ

- Interval Join
? ? ? ? ЖдСНДЮKeyedStreamНјааJoin,ашвЊжИЖЈЪБМфЗЖЮЇКЭJoinЪБЪЙгУЕФKey,ЪфГіНсЙћЮЊDataStreamЁЃJoinЕФКЫаФТпМдкProcessJoinFunction<IN1,IN2,OUT>жаЪЕЯж,IN1ЮЊЕквЛИіDataStreamжаЕФдЊЫиЪ§ОнРраЭ,IN2ЮЊЕк2ИіDataStreamжаЕФдЊЫиЪ§ОнРраЭ,OUTЮЊНсЙћЪфГіРраЭЁЃ

- WindowCoGroup
? ? ? ? СНИіDataStreamдкЯрЭЌЪБМфДАПкЩЯгІгУCoGroupдЫЫу,ЪфГіНсЙћЮЊDataStream,CoGroupКЭJoinЙІФмРрЫЦ,CoGroupНгПкЖдгІЕФЪЧCoGroupFunction,ЦфРрЗКаЭЮЊCoGroupFunction<IN1,IN2,O>,IN1ДњБэЕквЛИіDataStreamжаЪЧдЊЫиРраЭ,IN2ДњБэЕкЖўИіDataStreamжаЪЧдЊЫиРраЭ,OЮЊЪфГіНсЙћРраЭЁЃ

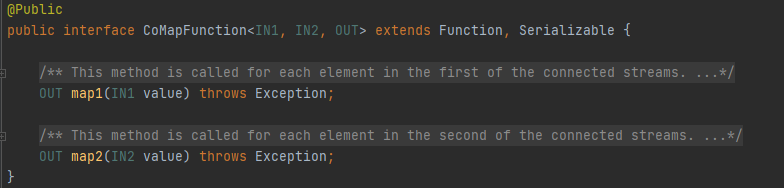
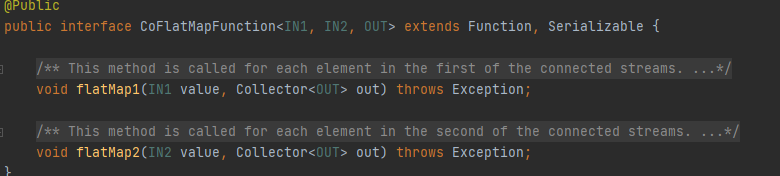
- CoMapКЭCoFlatMap
? ? ? ? дкConnectedStreamЩЯгІгУMapКЭFlatMapдЫЫу,ЪфГіСїЮЊDataStreamЁЃЦфЛљБОТпМРрЫЦгкдквЛАуDataStreamЩЯЕФMapКЭFlatMapдЫЫу,ЧјБ№дкгкCoMapзЊЛЛга2ИіЪфШы,MapзЊЛЛга1ИіЪфШы,CoFlatMapЭЌРэЁЃ
- Split
? ? ? ? НЋDataStreamАДееЬѕМўЧаЗжЖрИіDataStream,ЪфГіСїЮЊSplitDataStreamЁЃИУЗНЗЈвбОБъМЧЮЊЗЯЦњ,ЭЦМіЪЙгУSideOutputЁЃ

- Select?
? ? ? ? SelectгыSplitдЫЫуХфКЯЪЙгУ,дкSplitдЫЫужаЧаЗжЕФЖрИіDataStreamжа,SelectгУРДбЁдёЦфжаФГвЛИіОпЬхЕФDataStreamЁЃ

- Iterate
? ? ? ? дкAPIВуУцЩЯ,ЖдDataStreamгІгУЕќДњЛсЩњГЩ1ИіIteractiveStream,ШЛКѓдкIteractiveSteramгІгУвЕЮёДІРэТпМ,зюжеЩњГЩвЛИіаТЕФDataStream,дкЪ§ОнСїжаДДНЈвЛИіЕќДњбЛЗ,НЋЯТгЮЕФЪфГіЗЂЫЭИјЩЯгЮжиаТДІРэЁЃ

- Extract Timestamps
? ? ? ? ДгМЧТМжаЬсШЁЪБМфДС,ВЂЩњГЩWaterMarkЁЃИУРрдЫЫуВЛЛсИФБфDataStramЁЃ

- Project
? ? ? ? ИУРрдЫЫужЛЪЪгУгкTupleРраЭЕФDataStream,ЪЙгУProjectбЁШЁзгTuple,ПЩвдбЁдёTupleЕФВПЗждЊЫи,ПЩвдИФБфдЊЫиЫГађ,РрЫЦгкSQLгяОфжаЕФSelectзгОф,ЪфГіСїШдШЛЪЧDataStreamЁЃ

4.3 ХдТЗЪфГі
? ? ? ? ХдТЗЪфГідкFlinkжаНазіSideOutput,РрЫЦгкDataStream#split,БОжЪЩЯЪЧвЛИіЪ§ОнСїЕФЧаЗжааЮЊ,АДееЬѕМўНЋDataStreamЧаЗжЮЊЖрИізгЪ§ОнСї,згЪ§ОнСїНазіХдТЗЪфГіЪ§ОнСїЁЃУПИіХдТЗЪфГіЪ§ОнСїПЩвдгаздМКЕФЯТгЮДІРэТпМЁЃ

ХдТЗЪфГіЪ§ОнСїЕФЪ§ОнРраЭПЩвдгыЩЯгЮЪ§ОнСїВЛЭЌ,ЖрИіХдТЗЪфГіЪ§ОнСїЕФЪ§ОнРраЭвВВЛБиЯрЭЌЁЃ
ШчКЮЪЙгУХдТЗЪфГі:
1ЁЂЖЈвхOutputTag,OutpuTagЪЧУПвЛИіЯТгЮЗжжЇЕФБъЪЖЁЃ
![]()

2ЁЂЛёШЁХдТЗЪфГі

?
НгЯТРДFlinkКЫаФЦЊ,ШчЙћЖдFlinkИааЫШЄЛђепе§дкЪЙгУЕФаЁЛяАщ,ПЩвдМгЮвШыШКвЛЦ№ЬНЬжбЇЯАЁЃ
ВЮПМЪщМЎЁЖFlink ФкКЫдРэгыЪЕЯжЁЗ
