��Ⱥ�ڲ�ԭ��
��Ⱥ��ڵ�
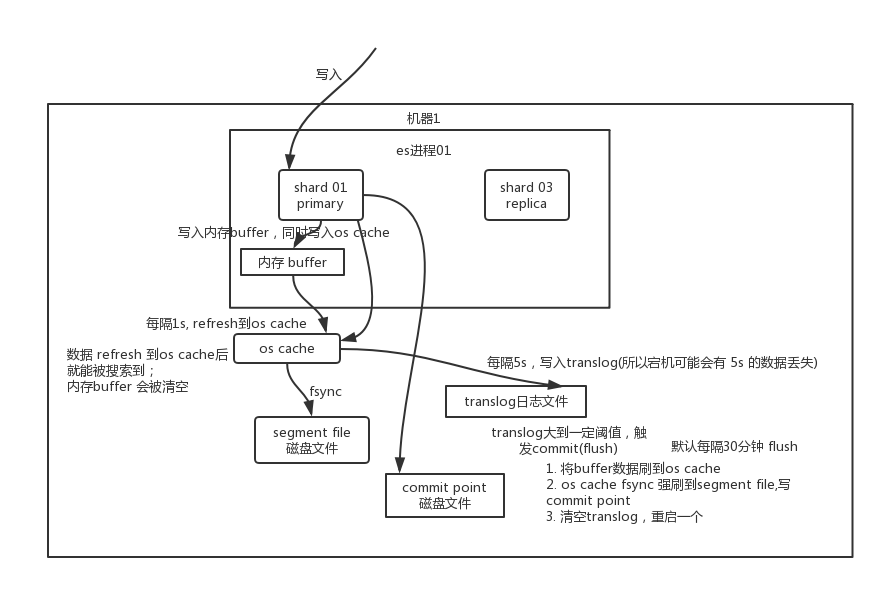
һ�������е�Elasticsearchʵ����Ϊһ���ڵ�,����Ⱥ����һ�����߶��ӵ����ͬ cluster.name ���õĽڵ����, ���ǹ�ͬ�е����ݺ��ص�ѹ�������нڵ���뼯Ⱥ�л��ߴӼ�Ⱥ���Ƴ��ڵ�ʱ,��Ⱥ��������ƽ���ֲ����е����ݡ�
����Elasticsearch����������ģʽ,���Ե�һ���ڵ㱻ѡ�ٳ�Ϊ���ڵ�ʱ, �������������Ⱥ��Χ�ڵ����б��,�������ӡ�ɾ������,�������ӡ�ɾ���ڵ�ȡ� ��Ϊ���ڵ㲢����Ҫ�漰���ĵ�����ı���������Ȳ���,���Ե���Ⱥֻӵ��һ�����ڵ�������,��ʹ������������Ҳ�����Ϊƿ���� �κνڵ㶼���Գ�Ϊ���ڵ㡣
��Ϊ�û�,���ǿ��Խ������͵���Ⱥ�е��κνڵ�(�����������Ľڵ�Ҳ����Э���ڵ�)�� ÿ���ڵ㶼֪�������ĵ�������λ��,�����ܹ������ǵ�����ֱ��ת�����洢���������ĵ��Ľڵ㡣 �������ǽ������͵��ĸ��ڵ�,�����ܸ���Ӹ����������������ĵ��Ľڵ��ռ�������,�������ս�����ؽo�ͻ��ˡ�
��Ƭ
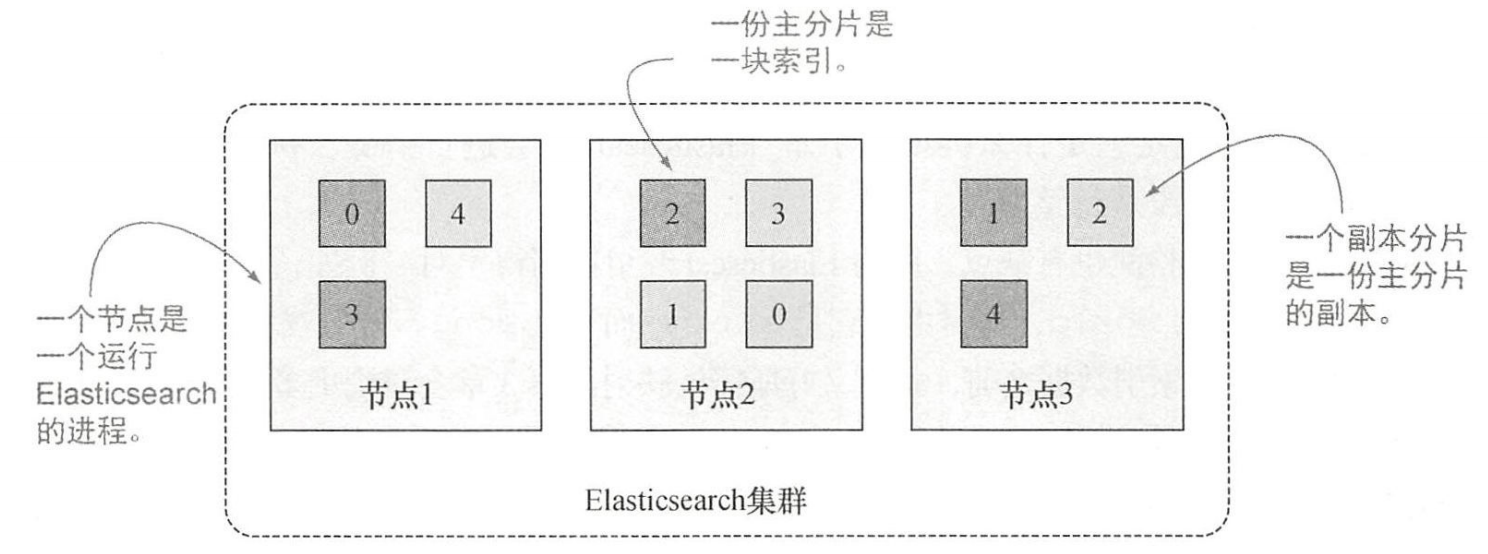
�ڷֲ�ʽϵͳ��,�������洢��ģ�������,Ҫ�������ģ��Ⱥ�����ʹ洢��Щ����,һ��ͨ�����ӻ������������ϵͳˮƽ��չ���������,��Ҫ�����ݷֳ�����С����䵽���������ϡ�Ȼ��ͨ��ij��·�ɲ����ҵ�ij�����ݿ����ڵ�λ�á�
��Ƭ(shard)�ǵײ�Ļ�����д��Ԫ,��Ƭ��Ŀ�����ָ������,�ö�д���Բ��в���,�ɶ�̨������ͬ�������д���������䵽ij����Ƭ��,��Ƭ���Զ���ִ�ж�д������Elasticsearch���÷�Ƭ�����ݷַ�����Ⱥ�ڸ�������Ƭ�����ݵ�����,�ĵ������ڷ�Ƭ��,������Ƭ�洢����Ƭ�ֱ����䵽��Ⱥ�ڵĸ����ڵ������Ⱥ��ģ�������Сʱ,Elasticsearch���Զ��ڸ��ڵ���Ǩ�Ʒ�Ƭ,ʹ������Ȼ���ȷֲ��ڼ�Ⱥ�
Ϊ��Ӧ�Բ�����������,Elasticsearch����Ƭ��Ϊ������,������Ƭ(primary shard)��������Ƭ(replica shard)����������ΪȨ������,д��������д����Ƭ,�ɹ�����д����Ƭ,�ָ���������ƬΪ��
һ��������Ƭֻ��һ������Ƭ�Ŀ�����������Ƭ��ΪӲ������ʱ�������ݲ���ʧ�����౸��,��Ϊ�����ͷ����ĵ��ȶ������ṩ����
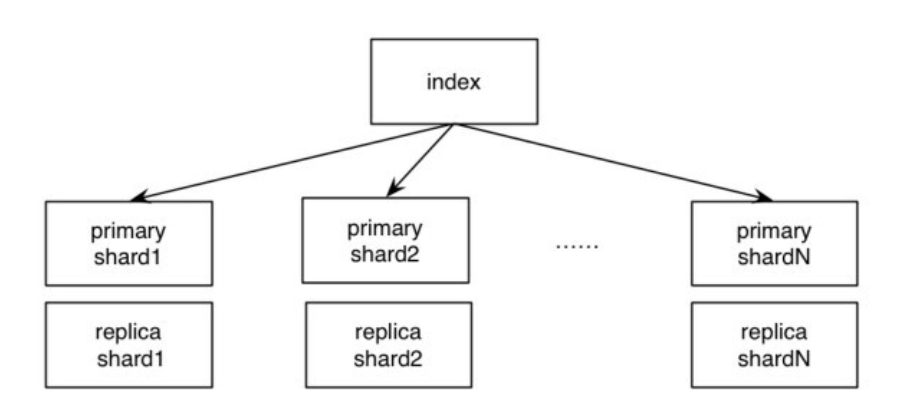
���������Ƭ֮������ʲô��ϵ��?
һ��Elasticsearch���������˺ܶ����Ƭ,ÿ����Ƭ����һ��Lucene������,����������һ����������������,���Զ���ִ�н�����������������Lucene�������ɺܶ�ֶ����,ÿ���ֶζ���һ������������Elasticsearchÿ��refresh��������һ���µķֶ�,���а��������ĵ������ݡ���ÿ���ֶ��ڲ�,�ĵ��IJ�ͬ�ֶα���������������ÿ���ֶε�ֵ�����ɴ�(Term)���,Term��ԭ�ı����ݾ����ִ������������Դ���������ս����
ѡ��
�����ڵ�ѡ���㷨��ѡ����,����ԭ���Dz��ظ������ӡ����ʵ��һ��������֪���㷨,�����ĺô������е��ŵ��ȱ������֪�ġ�Elasticsearch��ѡ���㷨��ѡ������Ҫ�����������֡�
- Bully�㷨:Leaderѡ�ٵĻ����㷨֮һ�����ٶ����нڵ㶼��һ��Ψһ��ID,ʹ�ø�ID�Խڵ���������κ�ʱ��ĵ�ǰLeader���Dz��뼯Ⱥ�����ID�ڵ㡣���㷨���ŵ�������ʵ�֡�����,��ӵ�����ID�Ľڵ㴦�ڲ��ȶ�״̬�ij����»������⡣����,Master���ع��ض�����,��Ⱥӵ�еڶ���ID�Ľڵ㱻ѡΪ����,��ʱԭ����Master�ָ�,�ٴα�ѡΪ����,Ȼ���ּ�������
- Paxos�㷨:Paxos�dz�ǿ��,������ʲôʱ��,�Լ���ν���ѡ�ٷ��������Աȼ�Bully�㷨�кܴ������,��Ϊ����ʵ������,���ڱ����������쳣����Ĺ���ģʽ����Paxosʵ�������dz����ӡ�
Elasticsearch��ѡ���㷨�ǻ���Bully�㷨�ĸĽ�,��Ҫ˼·���Խڵ�ID����,ȡIDֵ���Ľڵ���ΪMaster,ÿ���ڵ㶼�������������ͬʱ,Ϊ�˽��Bully�㷨��ȱ��,��ͨ���Ƴ�ѡ��,ֱ����ǰ��MasterʧЧ�������������,ֻҪ��ǰ���ڵ㲻�ҵ�,�Ͳ�����ѡ�����������ײ�������(˫��),Ϊ��,��ͨ��������Ʊ������������������⡣
Elasticsearch��Bully���ӵ�����Լ������
- ��ѡ������Ҫ���������ﵽ����ʱ��ѡ����ʱ���ڵ�,Ϊʲô����ʱ��?ÿ���ڵ���������ȡ���ֵ���㷨,�����һ����ͬ���ٸ�����,��Ⱥ��5̨����,�ڵ�ID�ֱ���1��2��3��4��5�����������������ڵ������ٶȲ���ϴ�ʱ,�ڵ�1�����Ľڵ��б���1��2��3��4,ѡ��4;�ڵ�2�����Ľڵ��б���2��3��4��5,ѡ��5������Ͳ�һ����,�ɴ˲�������ĵڶ������ơ�
- ��Ʊ����Ҫ������ij�ڵ㱻ѡΪ���ڵ�,�����жϼ������Ľڵ����ﵽ��������,��ȷ��Master����(�Ƴ�ѡ��)��
- ��̽��ڵ��뿪�¼�ʱ,�����жϵ�ǰ�ڵ����Ƿ���롣����ﲻ����������,�����Master����,���¼��뼯Ⱥ���������ô��,�������������:����5̨������ɵļ�Ⱥ�����������,2̨һ��,3̨һ��,��������ǰ,Masterλ��2̨�е�һ��,��ʱ3̨һ��Ľڵ�����²��ɹ�ѡȡMaster,����˫��,�׳�������(�ڵ�ʧЧ���)
��������ͼ

�ڵ�ʧЧ�����ؽڵ��Ƿ�����,Ȼ�������е��쳣��ʧЧ�����ѡ������֮�ɻ�ȱ�IJ���,��ִ��ʧЧ�����ܻ��������(˫�������)���ڴ�������Ҫ��������ʧЧ̽����:
- ��Master�ڵ�,����NodesFaultDetection,���NodesFD������̽����뼯Ⱥ�Ľڵ��Ƿ��Ծ��
- ��Master�ڵ�����MasterFaultDetection,���MasterFD������̽��Master�ڵ��Ƿ��Ծ��
��Ƭ�ڲ�ԭ��
����������
���ڵ�ȫ�ļ�����Ϊ�����ĵ����Ͻ���һ���ܴ�ĵ�������������д�뵽���̡� һ���µ���������,�ɵľͻᱻ���滻,��������ı仯����Ա���������
����������д����̺������ɸı��,�����IJ����Ծ������ºô�:
- ����Ҫ����������������������,��Ͳ���Ҫ���Ķ����ͬʱ�����ݵ����⡣
- һ�������������ں˵��ļ�ϵͳ����,������������������䲻����,ֻҪ�ļ�ϵͳ�����л����㹻�Ŀռ�,��ô�ֶ������ֱ�������ڴ�,���������д��̡����ṩ�˺ܴ������������
- ����(�����������)������������������ʼ����Ч�����Dz���Ҫ��ÿ�����ݸı�ʱ���ؽ�,��Ϊ���ݲ���仯��
- д�뵥����ĵ��������������ݱ�ѹ��,���ٴ��� I/O �� ��Ҫ�����浽�ڴ��������ʹ������
��Ȼ,һ�����������Ҳ�в��õĵط�������ȱ��������Dz��ɱ��,��������������ġ����������Ҫ��һ���µ��ĵ��ɱ�����,����Ҫ�ؽ������������ⲻ����һ���������ܰ���������������˾������,���Ҷ������ɱ����µ�Ƶ��ͬ�������Ӱ�졣
��̬��������
��ô����������ڱ��������Ե�ǰ����ʵ�ֵ��������Ķ�̬������?
�𰸾���ʹ�ø��������,���������ݲ�д��һ���µĵ���������,��ѯʱ,ÿ��������������������ѯ,��ѯ���ٶԽ�����кϲ���
Elasticsearch����Lucene����������д���ĸ����ÿ���ڴ滺������ݱ�д���ļ�ʱ,�����һ���µ�Lucene��,ÿ���ζ���һ������������ͬʱ,���ύ���������˵�ǰLucene������������Щ�ֶΡ�
��������������:
- ���ĵ����ռ����ڴ�������л���
- ������ѻ���һ����ģʱ,�ͻ�����ύ
- һ���µĶ�(��������)��д����̡�
- һ���µ��ύ�㱻д����̡�
- �������ļ�ϵͳ�����еȴ���д�붼ˢ�µ�����,��ȷ�����DZ�д�������ļ���
- �µĶα�����,�����������ĵ��ɼ��Ա�����
- �ڴ滺�汻���,�ȴ������µ��ĵ�
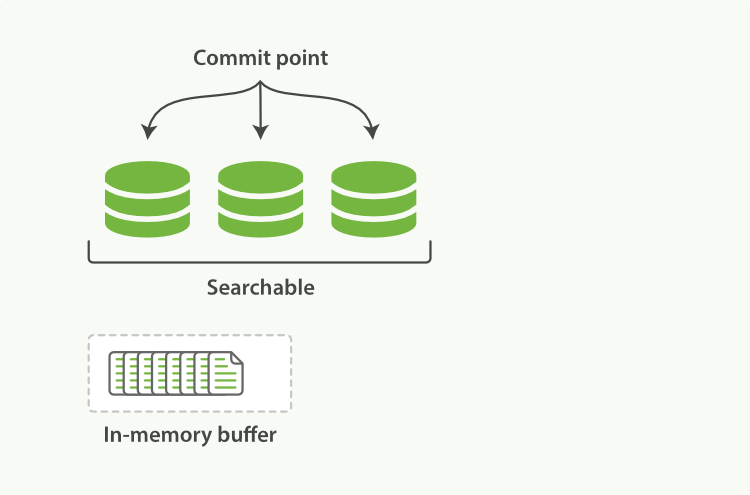
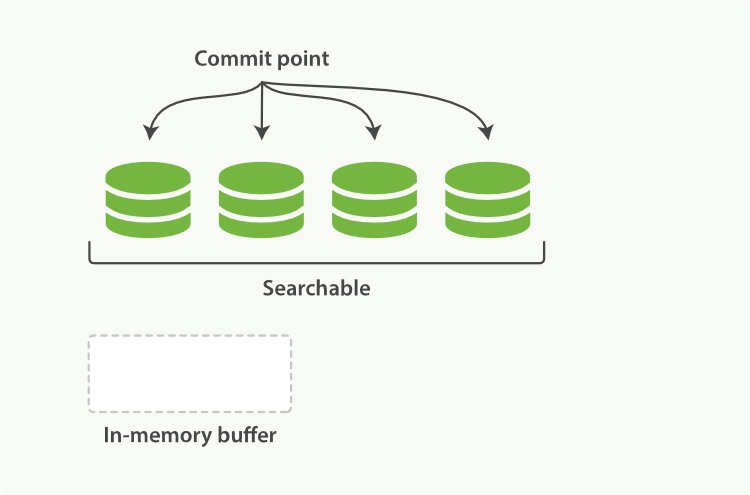
��һ����ѯ������,������֪�Ķΰ�˳��ѯ������ͳ�ƻ�����жεĽ�����оۺ�,�Ա�֤ÿ���ʺ�ÿ���ĵ��Ĺ�������ȷ���㡣 ���ַ�ʽ��������Խϵ͵ijɱ������ĵ����ӵ�������
�Dz�����������ʵ����?
���Dz��ɸı��,���ԼȲ��ܴӰ��ĵ��ӾɵĶ����Ƴ�,Ҳ�����ľɵĶ������з�ӳ�ĵ��ĸ��¡� ȡ����֮����,ÿ���ύ������һ�� .del �ļ�,�ļ��л��г���Щ��ɾ���ĵ��Ķ���Ϣ��
- ��һ���ĵ���ɾ��ʱ,��ʵ����ֻ����
.del�ļ��б����ɾ����һ�������ɾ�����ĵ���Ȼ���Ա���ѯƥ�䵽, �����������ս��������ǰ�ӽ�������Ƴ��� - ��һ���ĵ�������ʱ,�ɰ汾�ĵ������ɾ��,�ĵ����°汾��������һ���µĶ��С� ���������汾���ĵ����ᱻһ����ѯƥ�䵽,����ɾ�����Ǹ��ɰ汾�ĵ��ڽ��������ǰ���Ѿ����Ƴ���
��ʵʱ����
Elasticsearch�ʹ���֮�����ļ�ϵͳ����,��ִ��д����ʱ,Ϊ�˽��ʹ��������ɱ��������ӳ�,һ���¶λᱻ��д�뵽�ļ�ϵͳ����,�ٽ���Щ����д��Ӳ��(����I/O������ƿ��)��
��д������,һ��������ڴ��л���һ������,�ٽ���Щ����д��Ӳ��,ÿ��д��Ӳ�̵��������ݳ�Ϊһ���ֶΡ���ͬ�κ�д����һ��,ͨ������ϵͳ��write�ӿ�д�����̵����ݻ��ȵ���ϵͳ����(�ڴ�)��write�������سɹ�ʱ,����δ�ر�ˢ�����̡�ͨ���ֹ�����flush,���߲���ϵͳͨ��һ�����Խ��ļ�ϵͳ����ˢ�����̡�
���ֲ��Դ��������д��Ч�ʡ���write�������سɹ���ʼ,����������û�б�ˢ������,ֻҪ�ļ��Ѿ��ڻ�����, �Ϳ����������ļ�һ�����Ͷ�ȡ�ˡ�
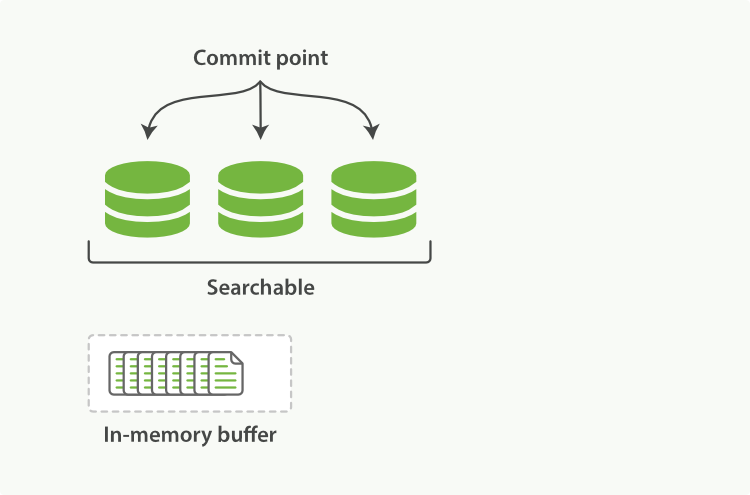
Lucene�����¶α�д��ʹ���ʹ��������ĵ���δ����һ�������ύʱ��������ɼ��� ���ַ�ʽ�Ƚ���һ���ύ����ҪС�ö�,�����ڲ�Ӱ�����ܵ�ǰ���¿��Ա�Ƶ����ִ�С�
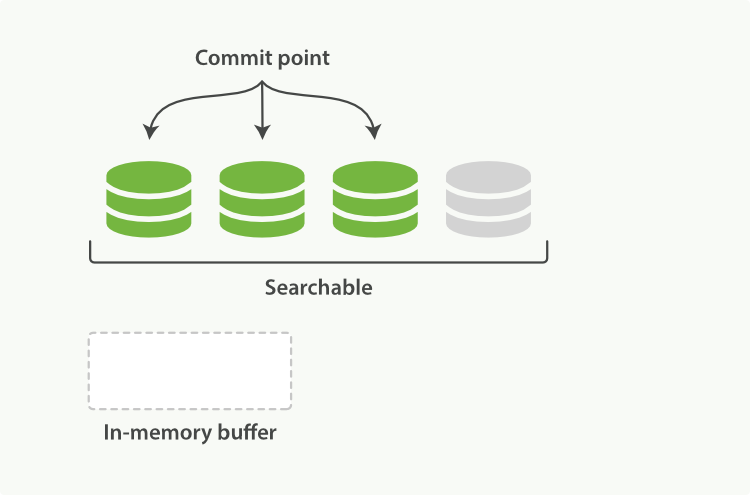
Elasticsearch�н�д��ʹ�һ���¶εĹ��̽���refresh(ˢ��) �� Ĭ�������ÿ����Ƭ��ÿ���Զ�ˢ��һ�Ρ������Ϊʲô����˵Elasticsearch����ʵʱ���������ĵ��ı仯�����������������ɼ�,������һ��֮�ڱ�Ϊ�ɼ���
������־
����ϵͳ�Ȼ���һ�����ݲ�д,���¶β�������ˢ�����,�������������������ijЩ�������(�������ϵ�),�����ڶ�ʧ���ݵķ��ա�
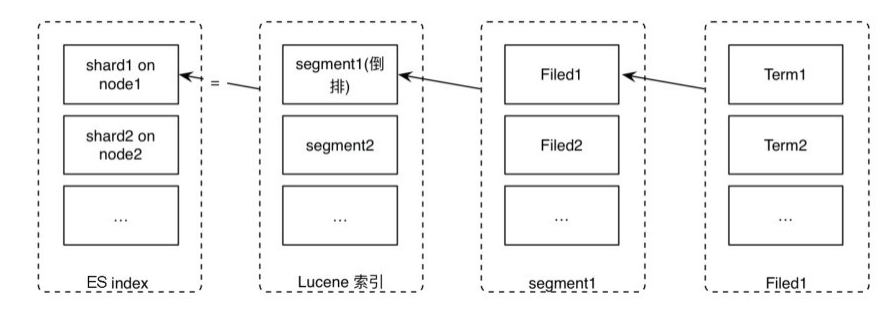
Ϊ�˽���������,Elasticsearch������һ��translog(������־),��ÿһ�ζ�Elasticsearch���в���ʱ����������־��¼,��Elasticsearch������ʱ��,�ط�translog�����������һ���ύ�����ı��������
��ִ����������:
- һ���ĵ�������֮��,�ͻᱻ���ӵ��ڴ滺����,�����ӵ���translog
- �µ��ĵ������ӵ��ڴ滺�������ұ��ӵ���������־,����ͼ

- �µ��ĵ������ӵ��ڴ滺�������ұ��ӵ���������־,����ͼ
- ��Ƭ��ÿ���Զ�ִ��һ��ˢ��,��Щ�ڴ滺�������ĵ���д���µĶ��в����Ա�����,ͬʱ����ڴ滺������
- ˢ����ɺ�, ���汻��յ���������־����,ͬʱ�¶�д���ļ�ϵͳ������
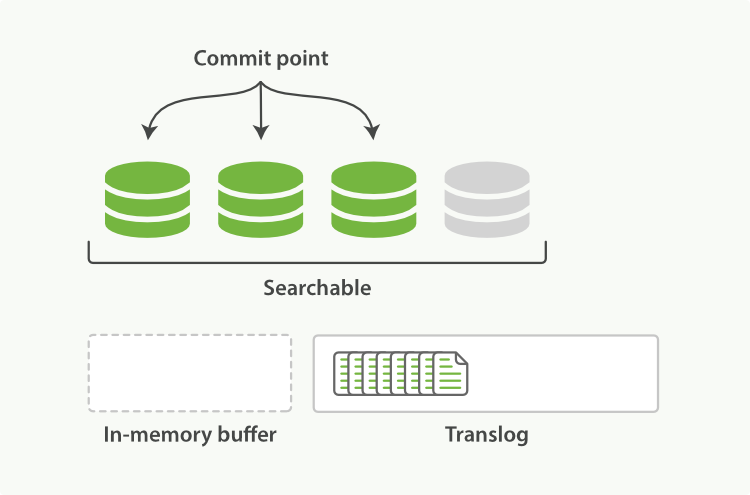
- ˢ����ɺ�, ���汻��յ���������־����,ͬʱ�¶�д���ļ�ϵͳ������
- ������̼�������,������ĵ������ӵ��ڴ滺�������ӵ�translog
- ������־���ϻ����ĵ�
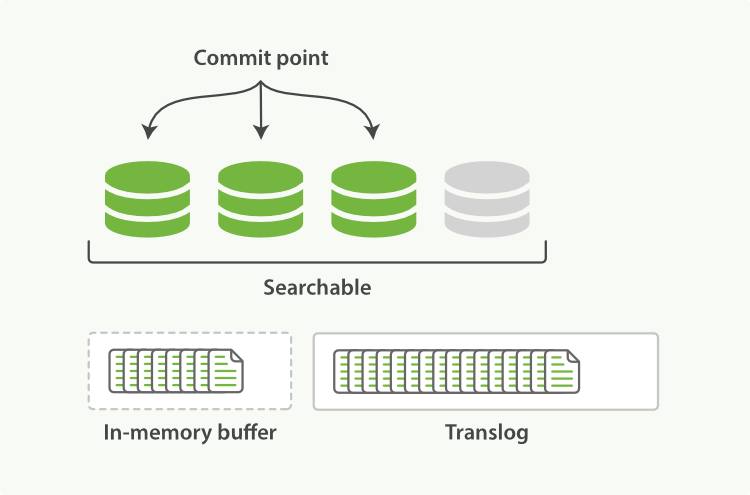
- ������־���ϻ����ĵ�
- ��translog�㹻��ʱ,�ͻ�ִ��ȫ���ύ,���ļ�ϵͳ����ִ��
flush,��������ȫ��д��Ӳ����,�����������־��- ��ˢ��(flush)֮��,�α�ȫ���ύ,����������־�����

- ��ˢ��(flush)֮��,�α�ȫ���ύ,����������־�����
����֮��,translog����������Щ����
- translog�ṩ���л�û�б�ˢ�����̵IJ�����һ���־û���¼����Elasticsearch������ʱ��, ����Ӵ�����ʹ�����һ���ύ��ȥ�ָ���֪�Ķ�,���һ��ط�translog�����������һ���ύ�����ı��������
- translogҲ�������ṩʵʱCRUD ����������ͨ��ID��ѯ�����¡�ɾ��һ���ĵ�,�ڴ���Ӧ�Ķ��м���֮ǰ, ���ȼ��translog�κ�����ı��������ζ���������ܹ�ʵʱ�ػ�ȡ���ĵ������°汾��
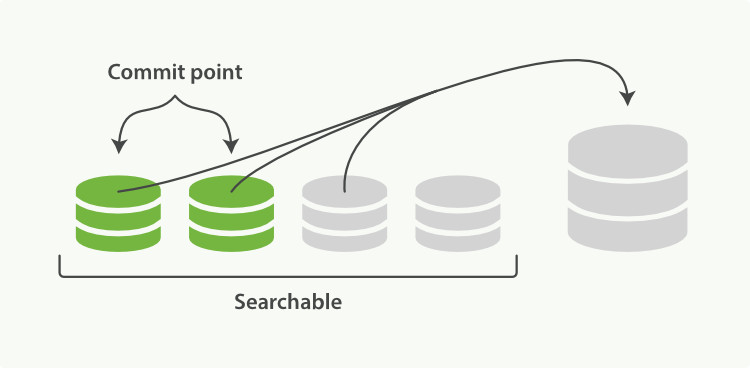
�κϲ�
�����Զ�ˢ������ÿ��ᴴ��һ���µĶ� ,�����ᵼ�¶�ʱ���ڵĶ�����������������Ŀ̫�������ϴ���鷳�� ÿһ���ζ��������ļ�������ڴ��cpu�������ڡ�����Ҫ����,ÿ�������������������ÿ����,���Զ�Խ��,����Ҳ��Խ����
Elasticsearchͨ���ں�̨�����κϲ�������������,���ѡ���С���Ƶķֶν��кϲ����ںϲ�������,���Ϊɾ��(����)�����ݲ���д���·ֶ�,���ϲ����̽���,�ɵķֶ����ݱ�ɾ��,���ɾ�������ݲŴӴ���ɾ����
��������ͼ
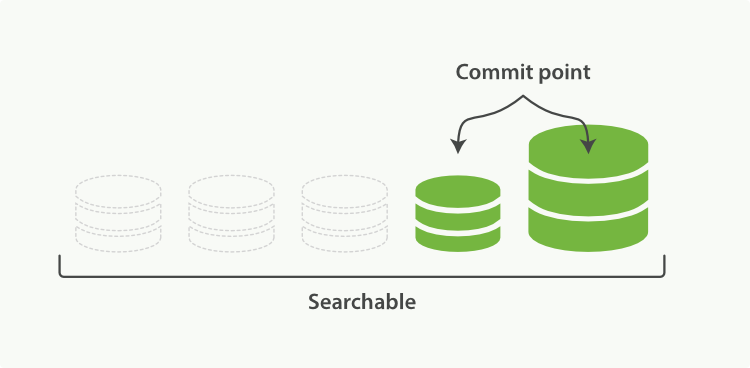
�ϲ���Ķ���Ҫ���Ĵ�����I/O��CPU��Դ,������䷢չ��Ӱ���������ܡ�Elasticsearch��Ĭ������»�Ժϲ����̽�����Դ����,����������Ȼ���㹻����Դ�ܺõ�ִ�С�
����д����������ͼ