Hadoop的架构和组成
*
Hadoop分布式系统基础框架具有创造性和极大的扩展性,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的高速运算和存储。
Hadoop的核心组成部分是HDFS,MapReduce以及Common,其中HDFS提供了海量数据的存储,MapReduce提供了对数据的计算,Common为其他模块提供了一系列文件系统和通用文件包。
*
部署前需要配置Java环境(已经配置可以跳过)
1.解压jdk
tar -zxvf jdk-8u121-linux-x64.tar.gz
2.配置环境变量
vim /etc/profile
然后添加:(根据自己的jdk版本进行调整)

使配置生效:
source /etc/profile
3.检查是否配置成功
java -version

Hadoop安装配置
我这里使用的版本是2.7.2
1.解压Hadoop

2.配置Hadoop
在 /etc/profile文件中添加:

配置使其生效
source /etc/profile
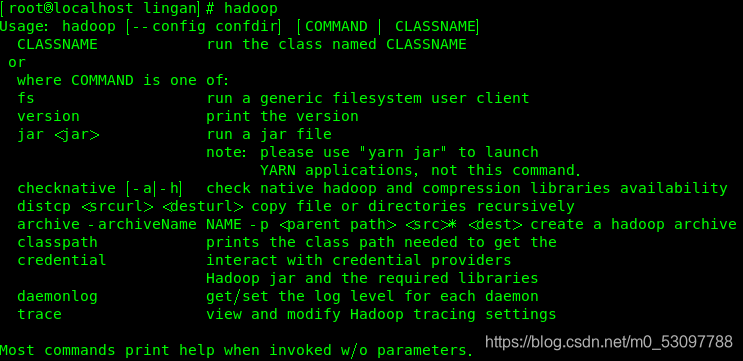
检验是否成功(在终端输入hadoop)
3.分别配置并修改以下文件:
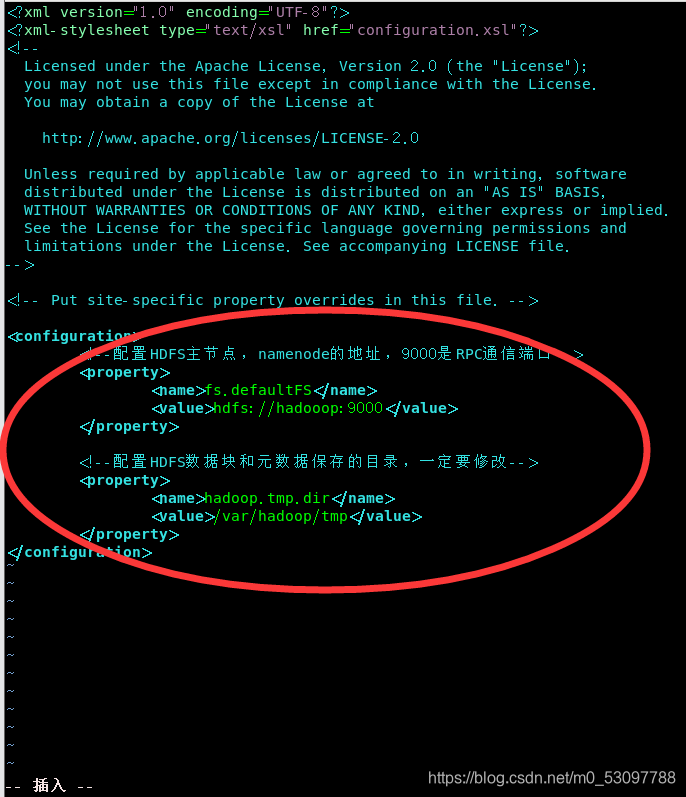
1)在第二十五行修改代码


2)

3)

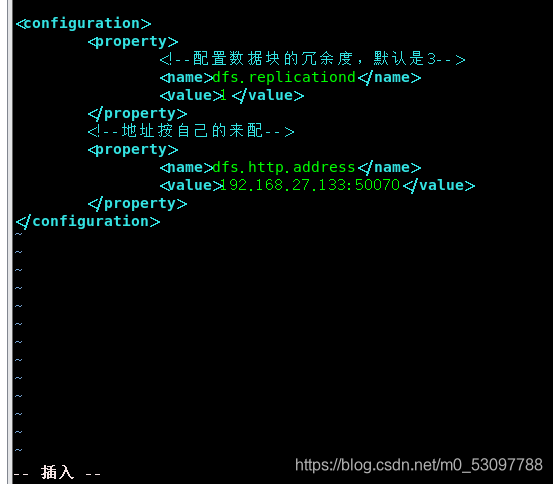
4)


修改完后将其重命名:

5)


4.生成秘钥,使得ssh服务免密连接localhost
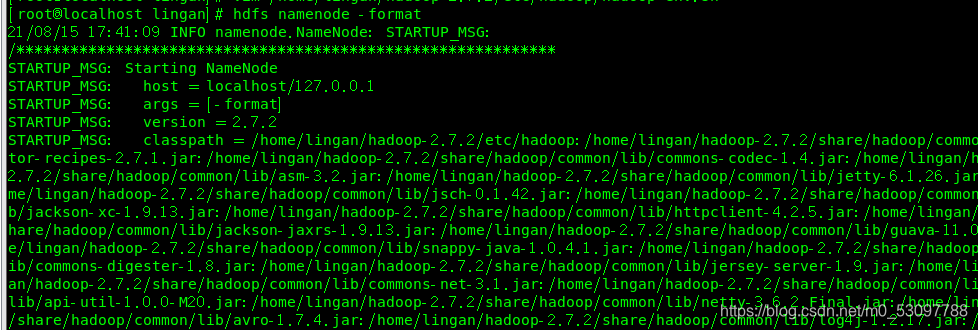
格式化,终端输入:
1| hdfs namenode -format
启动,终端输入(一路输入yes):
2| start-all.sh

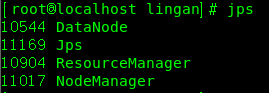
启动完成后,检查集群:
jps
Web控制台访问:http://192.168.27.133:50070、http://192.168.27.133:8088
上传HDFS
hdfs dfs -put in.txt /adir 上传本地路径下的in.txt文件到hdfs的/adir目录下
运行wordcount:
hadoop jar /home/lingan/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /data/wordcount /output/wordcount
然后在http://192.168.27.133:50070中查看/usr/root/output/part-r-00000文件里的词频统计结果。