Elasticsearch一个开源的搜索搜索和分析引擎,具有存储和分析一体的非sql的文档搜索引擎。
新型的索引方式
Elasticsearch用于文档型数据的搜索,用于文档型数据的查询和分析。如果将直接将文档id绑定到关键词的正排的索引结构的k-v结构,在互联网中海量数据的使用,会产生大量的索引,占用巨大内存空间空间,降低索引的性能。
Elasticsearch摒弃了传统的结构化的数据库或者兴起的k-v结构,而采用v-k倒排索引。
什么是倒排索引?
倒排索引是Elasticsearch将文档内具有关键字的一系列文档id,与关键字形成新的k-v结构,即一个关键字对应一系列的文档id,再将其作为索引保存起来。通过这个关键字查询时,可以迅速地查询到相关的文档。
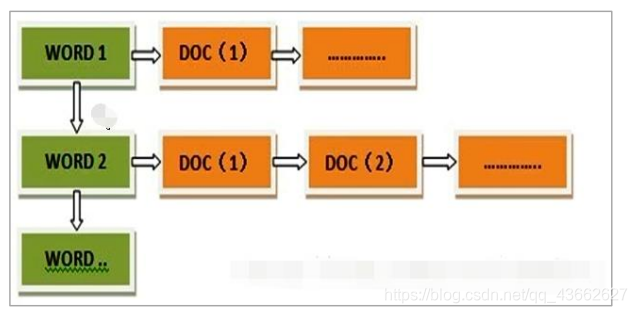
这种方式的好处兼顾了查询的性能和存储,大大减少了索引空间,提升性能。
索引的更新
比起数据库,动不动加锁的机制,Elasticsearch使用的索引采用的是不变的机制,好处在于:
不变的好处在于:
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够
的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
其它缓存(像 filter 缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为
数据不会变化。
写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
坏处在于
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如
果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的
数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
用更多的索引打败更新
Elasticsearch引入了版本的概念。Elasticsearch更新数据的方式,是建立新的索引作为补充。一个索引作为一个段,这是按段搜索更新的概念。Elasticsearch在查询合并后,根据版本号先后,自动过滤老版本的数据。即使删除了的数据,也只是在后缀加上.del,在查询匹配时可能被查询到,但返回结果就会被过滤掉。
当然,对于Es存在过多的段,es会在一段时间后进行将小段合并到大段,删除旧段。
近实时的搜索引擎
Elasticsearch的更新是不会立即提交到磁盘上的,相反Elasticsearch提供了一套缓存机制
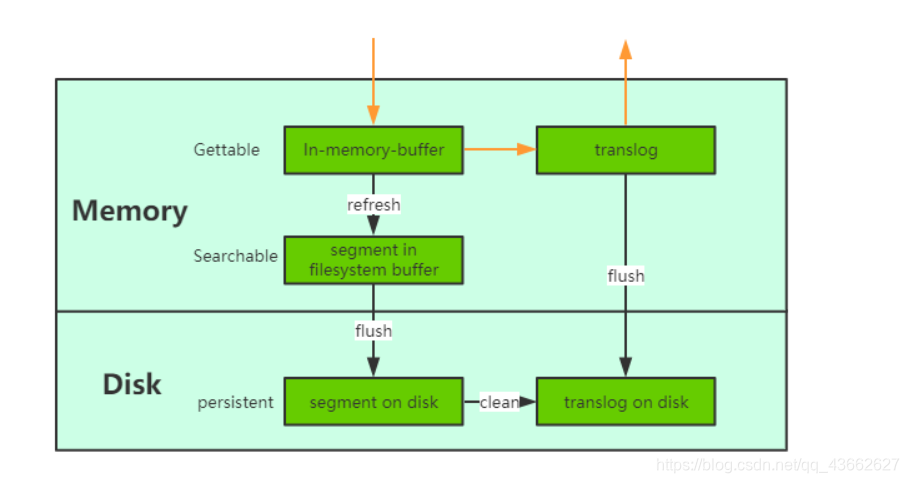
每次的更新如果都要写入磁盘的话,将耗费很多时间,也会极大的降低磁盘的性能,因此Elasticsearch采用多缓存的机制。新建立的段不会立即写入磁盘,而是先保存到文件系统缓存和translog中,保存到文件系统缓存行为被称为refresh,refresh的数据是可见的,可以被查询到。在此之前保存的数据不可以被索引到,因此这也是Elasticsearch被成为近实时的原因。
fresh是从缓存将数据刷写到磁盘中,为了避免提交失败Elasticsearch提供了translog的机制,translog记录了索引的变动行为。分片每30分钟实行fresh一次,或者在translog满了,也会进行一次fresh。
#设置refresh的机制
{
"settings": {
"refresh_interval": "30s"
} }
如果建立大的索引,可以先建立新的索引,关闭自动更新,节约系统资源
# 关闭自动刷新
PUT /users/_settings
{ "refresh_interval": -1 }
# 每一秒刷新
PUT /users/_settings
{ "refresh_interval": "1s" }