�����
- https://www.bilibili.com/video/BV11A411L7CK?p=19
Spark���мܹ�
Spark��ܵĺ�����һ����������,������˵,�������˱�master-slave�Ľṹ����ͼչʾ��һ��Sparkִ��ʱ�Ļ����ṹ��ͼ���е�Driver��ʾmaster,�������������Ⱥ�е���ҵ������ȡ�ͼ���е�Executor����slave,����ʵ��ִ������
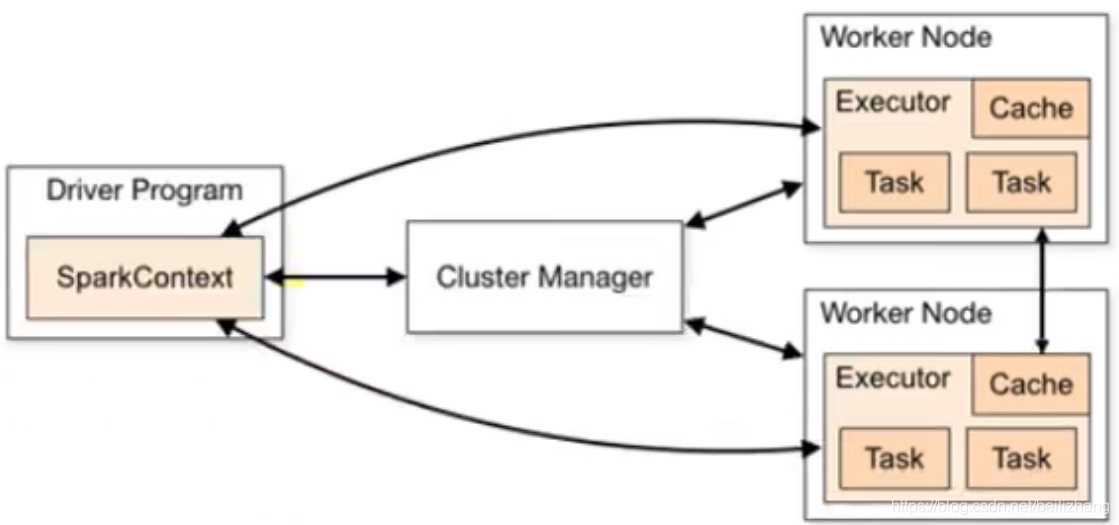
Driver
Spark�������ڵ�,����ִ��Spark�����е�main����,����ʵ�ʴ����ִ�й�����Driver��Spark��ҵִ��ʱ��Ҫ����:
-
���û�����ת��Ϊ��ҵ(job)
-
��Executor֮���������(task)
-
����Executor��ִ�����
-
ͨ��UIչʾ��ѯ�������
ʵ����,��ȷ������Driver�Ķ���,��Ϊ�������ı�̹�����û���κ��й�Driver�����ۡ����Լ�����,��ν��Driver������ʹ����Ӧ�����������ij���,Ҳ��֮ΪDriver��
Executor
Spark Executor�Ǽ�Ⱥ�й����ڵ�(Worker)�е�һ��JVM����,������Spark��ҵ�����о�������(Task),����˴�֮���������SparkӦ������ʱ,Executor�ڵ㱻ͬʱ����,����ʼ�հ���������SparkӦ�õ��������ڶ����ڡ������Executor�ڵ㷢���˹��ϻ����,SparkӦ��Ҳ���Լ���ִ��,�Ὣ�����ڵ��ϵ�������ȵ�����Executor�ڵ�������
Executor������������:
-
�����������SparkӦ�õ�����,����������ظ�����������
-
����ͨ�������Ŀ������(Block Manager)Ϊ�û�������Ҫ���RDD�ṩ�ڴ�ʽ�洢��RDD��ֱ�ӻ�����Executor�����ڵ�,����������������ʱ������û������ݼ�������
Master & Worker
Spark��Ⱥ�Ķ���������,����Ҫ������������Դ���ȿ��,������ʵ������Դ���ȹ���,���Ի����к������������������:Master��Worker,�����Master��һ������,��Ҫ������Դ�ĵ��Ⱥͷ���,�����м�Ⱥ�ļ�ص�ְ��,������Yarn�����е�RM;��WorkerҲ�ǽ���,һ��Worker�����ڼ�Ⱥ��һ̨��������,��Master������Դ�����ݽ��в��еĴ����ͼ���,������Yarn�����е�NM
Driver��Executor�Ǽ�����ص����;Master��Worker����Դ��ص����
ApplicationMaster
Hadoop�û���YARN��Ⱥ�ύӦ�ó���ʱ,�ύ������Ӧ�ð���ApplicationMaster,��������Դ����������ִ���������Դ����Container,�����û��Լ��ij�������job,������������ִ��,�������������״̬,��������ʧ�ܵ��쳣���
��,ResourceManager(��Դ)��Driver(����)֮��Ľ���Ͽ��ľ���ApplicationMaster
���ĸ���
Executor��Core
Spark Executor�Ǽ�Ⱥ�������ڹ����ڵ�(Worker)�е�һ��JVM����,��������Ⱥ�е�ר�����ڼ���Ľڵ㡣���ύӦ����,�����ṩ����ָ������ڵ�ĸ���,�Լ���Ӧ����Դ���������Դһ��ָ���ǹ����ڵ�Executor���ڴ��С��ʹ�õ�����CPU��(Core)����
Ӧ�ó������������������:
-
�Cnum-executors:����Executor������
-
�Cexecutor-memory:����ÿ��Executor���ڴ��С
-
�Cexecutor-cores:����ÿ��Executor������CPU core����
���ж�(Parallelism)
�ڷֲ�ʽ��������һ�㶼�Ƕ������ͬʱִ��,��������ֲ��ڲ�ͬ�ļ���ڵ���м���,�����ܹ�������ʵ�ֶ�������ִ�С�������Ⱥ����ִ�������������֮Ϊ���жȡ�һ����ҵ�IJ��ж�ȡ���ڿ�ܵ�Ĭ�����á�Ӧ�ó���Ҳ���������й����ж�̬��
������ͼ(DAG)
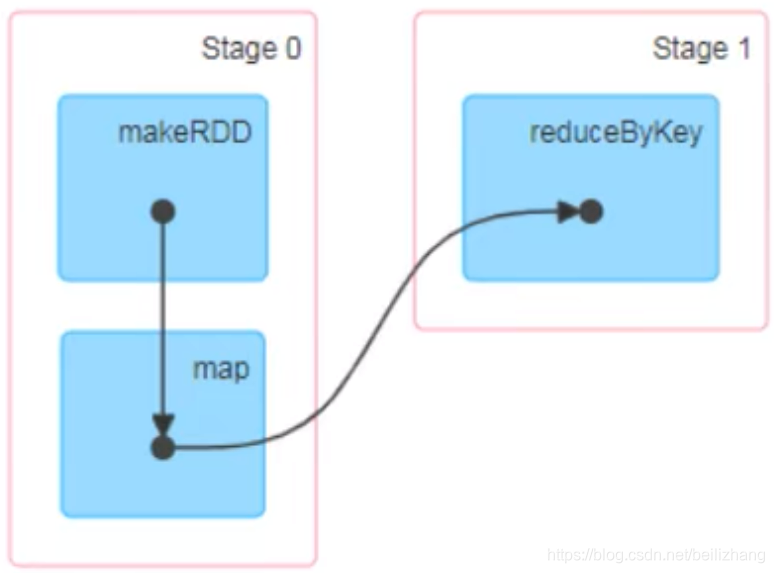
�����ݼ��������ܸ���ʹ�÷�ʽ�IJ�ͬһ����Ϊ����,���е�һ����Hadoop�����ص�MapReduce,���������Ϊ������,�ֱ�ΪMap�κ�Reduce�Ρ������ϲ�Ӧ����˵,�Ͳ��ò��뷽�跨ȥ����㷨,�����ڲ��ò����ϲ�Ӧ��ʵ�ֶ��Job�Ĵ���,�����һ���������㷨,����������㡣
���������ı�,������֧��DAG��ܵIJ��������֧��DAG�Ŀ�ܱ�����Ϊ�ڶ����������档��Tez�Լ����ϲ��Oozie������Tez��Oozie��˵,����������������
������������SparkΪ�����ĵ������ļ������档����������������ص���Ҫ��Job�ڲ���DAG֧��(����ԽJob),�Լ�ʵʱ����
�����DAG,����Spark����ֱ��ӳ��ɵ��������ĸ�����ģ�͡���������ǽ�������������ִ�й�����ͼ�α�ʾ����
DAG���ɵ������ɵ�����ͼ��,��ͼ�ξ��з���,����ջ�
�ύ����
�ύ����,���ǿ�����Ա��������д��Ӧ�ó���ͨ��Spark�ͻ����ύ��Spark���л���ִ�м�������̡��ڲ�ͬ�IJ�����,����ύ���̻�����ͬ,��������ϸ������
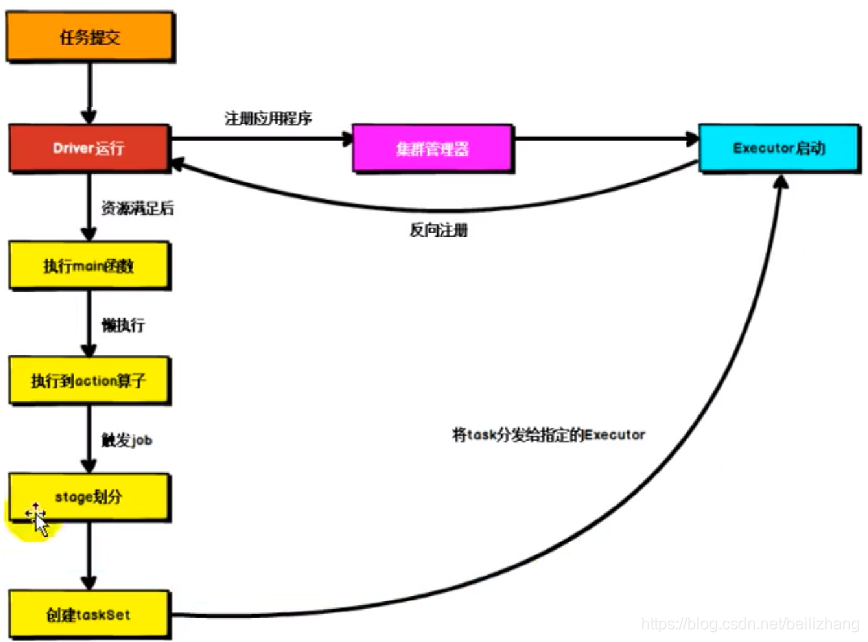
Yarn���ֲ���ģʽ
SparkӦ�ó����ύ��Yarn������ִ�е�ʱ��,һ��������ֲ���ִ�еķ�ʽ:Client��Cluster������ģʽ��Ҫ��������:Driver��������нڵ�λ��
Yarn Clientģʽ
Clientģʽ�����ڼ�غ͵��ȵ�Driverģ���ڿͻ���ִ��,��������Yarn��,����һ�����ڲ���
-
Driver�������ύ�ı��ػ���������
-
Driver��������ResourceManagerͨѶ��������ApplicationMaster
-
ResourceManager����container,�ں��ʵ�NodeManager������ApplicationMaster,������ResourceManager����Executor�ڴ�
-
ResourceManager�ӵ�ApplicationMaster����Դ���������container,Ȼ��ApplicationMaster����Դ����ָ����NodeManager������Executor����