文章目录
Hadoop 配置文件介绍
1 hadoop 目录结构
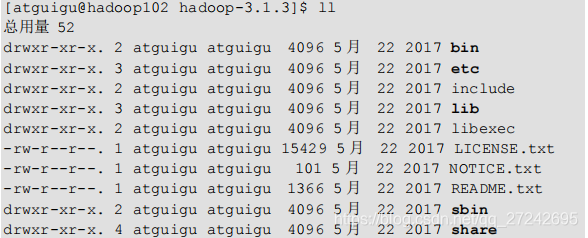
- bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
2 hadoop 核心配置
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认
配置值时,才需要修改自定义配置文件,更改相应属性值。
2.1 默认配置文件存储位置

2.2 自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在
$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
2.3 核心配置文件-core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nameNode:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2.4 HDFS 配置文件-hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
2.5 YARN 配置文件-yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
2.6 MapReduce 配置文件 mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.7 配置历史服务器-mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property
- mapred --daemon start historyserver
- 查看访问:http://hadoop102:19888/jobhistory
2.8 配置日志的聚集-yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property
- 关闭 NodeManager 、ResourceManager 和 HistoryServer: sbin/stop-yarn.sh
- mapred --daemon stop historyserver
- 启动 NodeManager 、ResourceManage 和 HistoryServer:start-yarn.sh
- mapred --daemon start historyserver
- 执行 WordCount 程序:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- 查看日志:http://hadoop102:19888/jobhistory
其他详细配置参考:https://blog.csdn.net/gyxinguan/article/details/73996208