OLTP和OLAP基础分析

OLTP
操作型处理,联机事务处理。简单来说指rdb、nosql(redis、mongo)
OLAP
分析型处理,联机分析处理。泛指数仓。
OLAP 是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的 OLAP 可以分为3类:多维OLAP ( Multi-dimensional OLAP )、关系型OLAP ( Relational OLAP ) 和混合OLAP ( Hybrid OLAP ) 三大类。
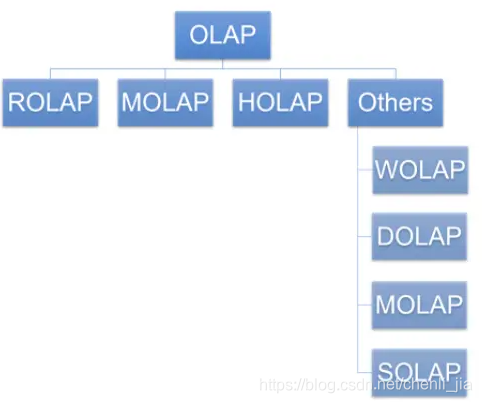
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)
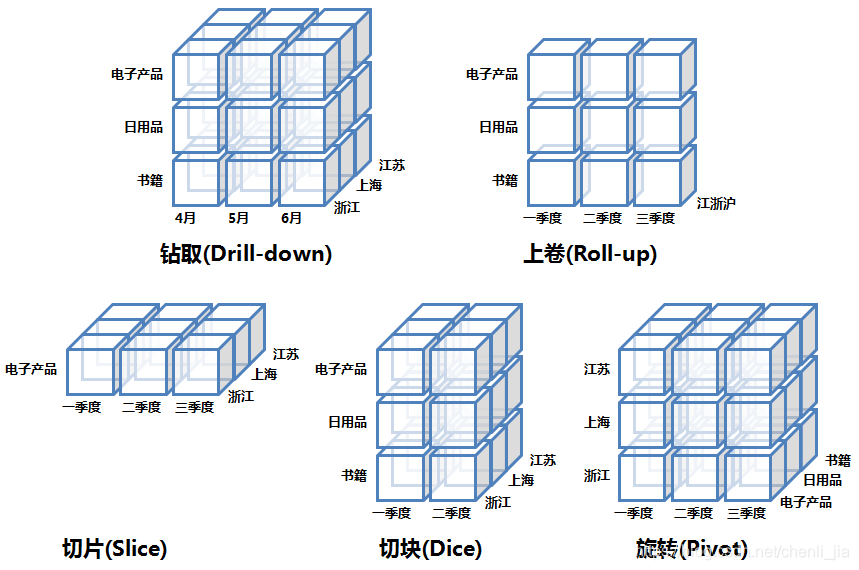
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2020年第二季度的总销售数据进行钻取来查看2020年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2020年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2020年第一季度到2020年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
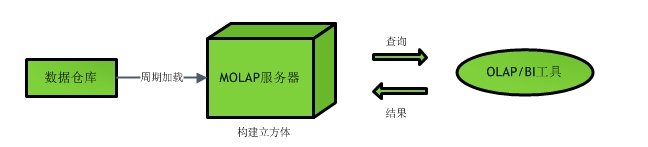
MOLAP
这是OLAP分析的传统方式。在MOLAP中,数据存储在一个多维数据集(cube)中,存储并不是在传统的关系型数据库中,而是自定义的格式。
核心思想是“空间换时间”,典型代表包括Druid和Kylin。
优势
卓越的性能:MOLAP cubes为了快速数据检索而构建,具有最佳的slicing dicing操作
可以执行复杂的计算:所有的计算都在创建多维数据表时预先生成。因此,可快速运行复杂的计算
劣势
数据有限:因为所有的计算都是执行在预选构建的多维数据集上,无超出范围的数据,例如明细数据的查询等
成本高:需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高
ROLAP
这种方法依赖于操作存储在关系型数据库中的数据,给传统的OLAP slicing 和 dicing功能。本质上,每个slicing或dicing功能和SQL语句中"WHERE"子句的功能是一样的。这种架构下的查询没有MOLAP快速。因为ROLAP中,所有的查询都是被转换为SQL语句执行的。而这些SQL语句的执行会涉及到多个表之间的JOIN操作,没有MOLAP速度快。
ROLAP的典型代表是:Presto,Doris,Impala,GreenPlum,Clickhouse,kudu,ES,Hive,Spark SQL,Flink SQL…

优势
可以处理大数据量:ROLAP技术的数据量大小就是底层关系数据库存储的大小。换句话说,ROLAP本身没有对数据量的限制。
可以利用关系型数据库所固有的功能:关系型数据库已经具备非常多的功能。ROLAP技术,由于它是建立在关系型数据库上的,因此可以使用这些功能。
劣势
性能可能会很慢:因为每个ROLAP包裹实际上是一个SQL查询(或多个SQL查询)关系数据库,可能会因为底层数据量很大,使得查询的时间很长。
受限于SQL的功能:因为ROLAP技术主要依赖于生成SQL语句查询关系数据库,SQL语句并不能满足所有的需求(举例来说,使用SQL很难执行复杂的计算),ROLAP技术因此受限于SQL所能做的事情。ROLAP厂商已经通过构建工具以减轻这种风险,而且允许用户自定义函数。
HOLAP
HOLAP技术试图将MOLAP和ROLAP技术的优势结合起来。总体来说,HOLAP利用了多维数据集的技术从而得到更快的性能。当需要详细信息时,HOLAP可以从多维数据集“穿过”到底层的关系数据库。
并发能力与查询延迟对比
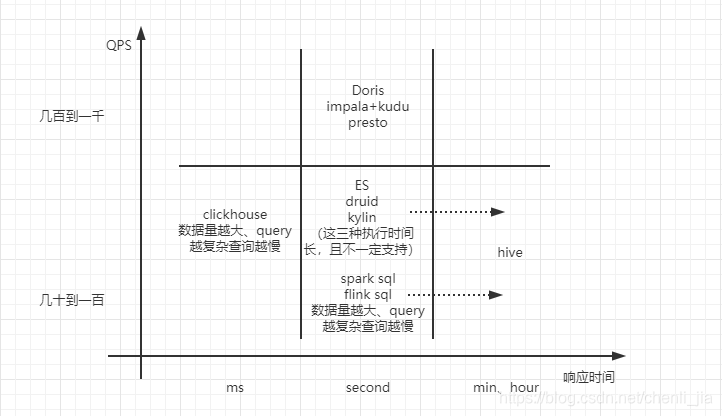
简单查询
简单查询指的是点查、简单聚合查询或者数据查询能够命中索引或物化视图(物化视图指的是物化的查询中间结果,如预聚合数据)。这样的查询经常出现在【在线数据服务】的企业应用中,如阿里生意参谋、腾讯的广点通、京东的广告业务等,它们共同的特点是对外服务、面向B端商业客户(通常是几十万的级别);并发查询量(QPS)大;对响应时间要求高,一般是ms级别;查询模式相对固定且简单。这种场景最合适的是Elasticsearch、Doris、Druid、Kylin这些。
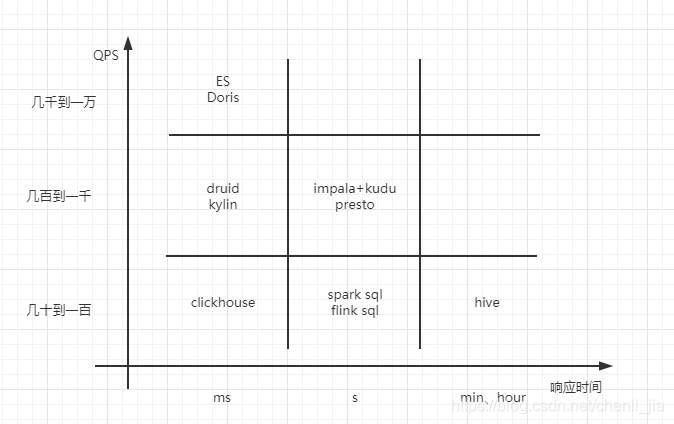
复杂查询
复杂查询指的是复杂聚合查询、大批量数据SCAN、复杂的查询(如JOIN)。在ad-hoc场景中,经常会有这样的查询,往往用户不能预先知道要查询什么,更多的是探索式的。这里也根据QPS和查询耗时分几种情况,如下图所示。有一点要提的是FlinkSQL和SparkSQL虽然也能完成类似需求,但是它们目前还不是开箱即用,需要做周边生态建设,这两种技术目前更多的应用场景还是在通过操作灵活的编程API来完成流式或离线的计算上。
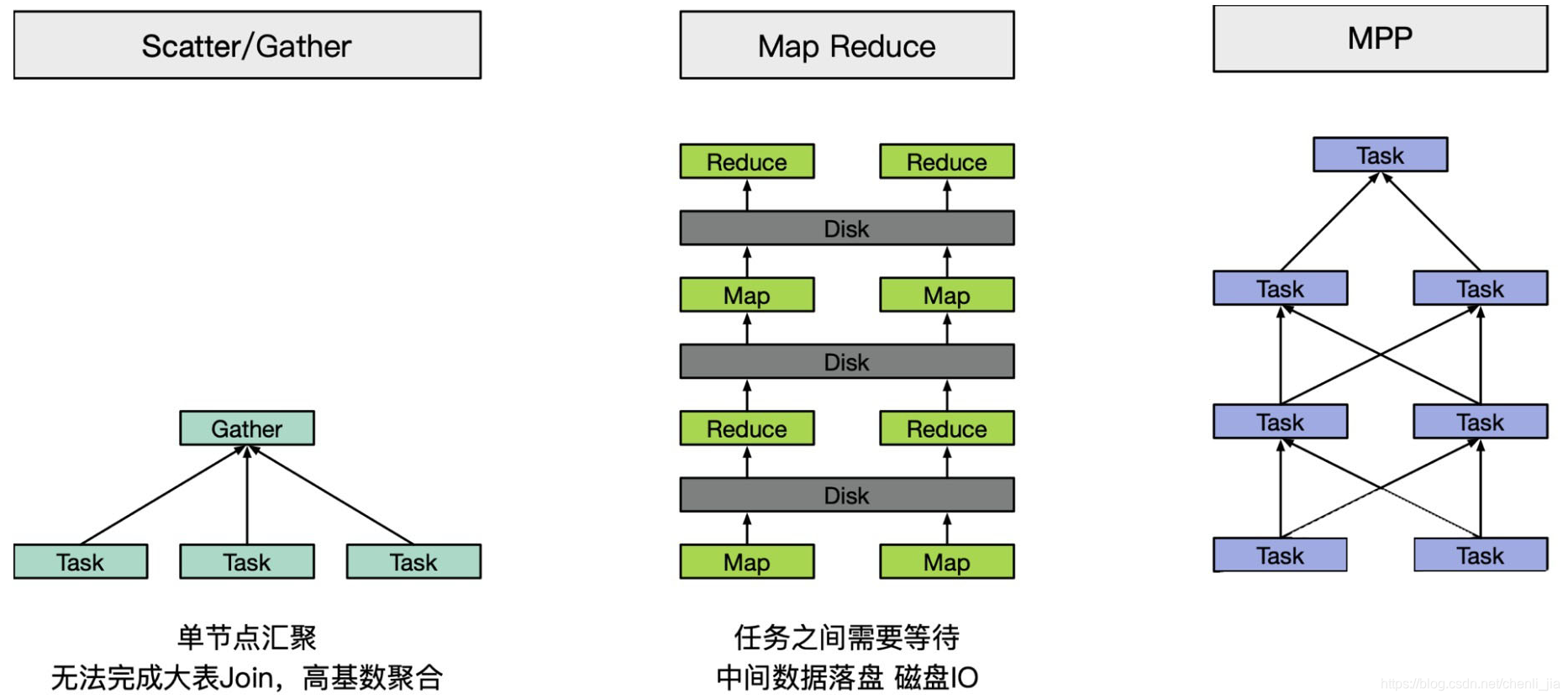
执行模型对比
Scatter-Gather执行模型:相当于MapReduce中的一趟Map和Reduce,没有多轮的迭代,而且中间计算结果往往存储在内存中,通过网络直接交换。Elasticsearch、Druid、Kylin都是此模型。
MapReduce:Hive是此模型
MPP:MPP学名是大规模并行计算,其实很难给它一个准确的定义。如果说的宽泛一点,Presto、Impala、Doris、Clickhouse、Spark SQL、Flink SQL这些都算。(Spark SQL和Flink SQL属于DAG模型,DAG并不算一种单独的模型,它只是生成执行计划的一种方式)
OLAP引擎的主要特点
Hive
Hive是一个分布式SQL on Hadoop方案,底层依赖MapReduce计算模型执行分布式计算。Hive擅长执行长时间运行的离线批处理,数据量越大,优势越明显。Hive在数据量大、数据驱动需求强烈的互联网大厂比较流行。近2年,随着clickhouse的逐渐流行,对于一些总数据量不超过百PB级别的互联网数据仓库需求,已经有多家公司改为了clickhouse的方案。clickhouse的优势是单个查询执行速度更快,不依赖hadoop,架构和运维更简单。
Spark SQL、Flink SQL
在大部分场景下,Hive计算还是太慢了,别说不能满足那些要求高QPS、低查询延迟的的对外在线服务的需求,就连企业内部的产品、运营、数据分析师也会经常抱怨Hive执行ad-hoc查询太慢。这些痛点,推动了MPP内存迭代和DAG计算模型的诞生和发展,诸如Spark SQL、Flink SQL、Presto这些技术,目前在企业中也非常流行。Spark SQL、Flink SQL的执行速度更快,编程API丰富,同时支持流式计算与批处理,并且有流批统一的趋势,使大数据应用更简单。
注:上面说的在线服务,指的是如阿里对几百万淘宝店主开放的数据应用生意参谋,腾讯对几十万广告主开发的广点通广告投放分析等。
Clickhouse
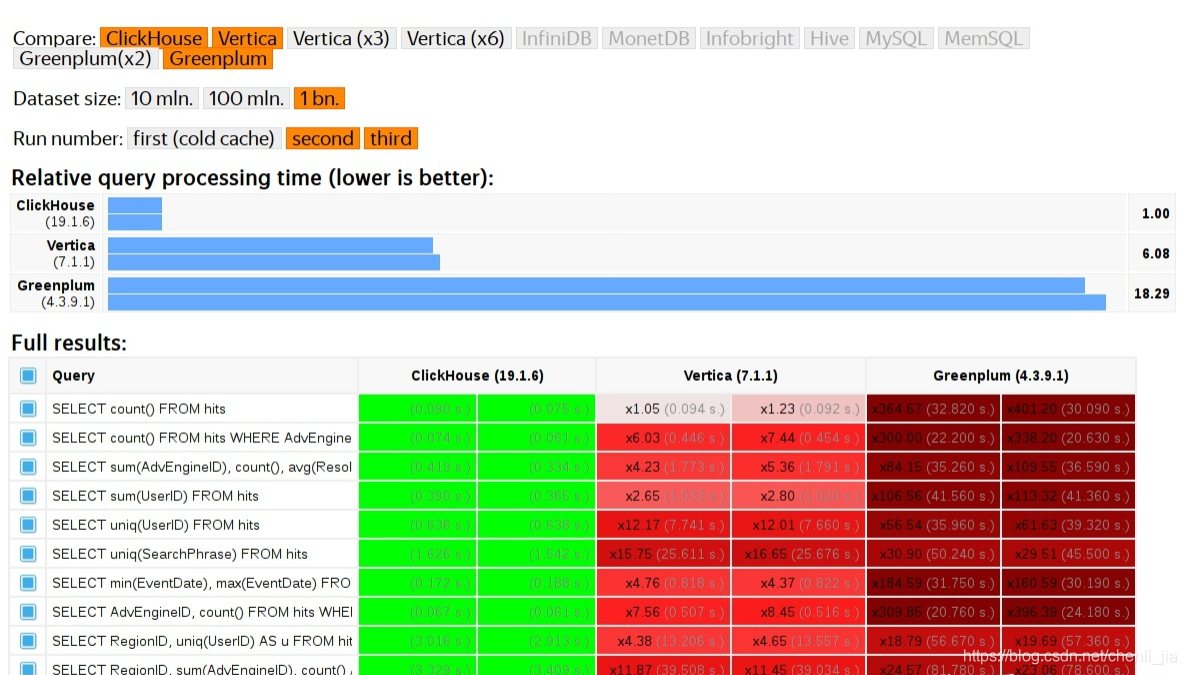
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
- 今日头条 内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
ES
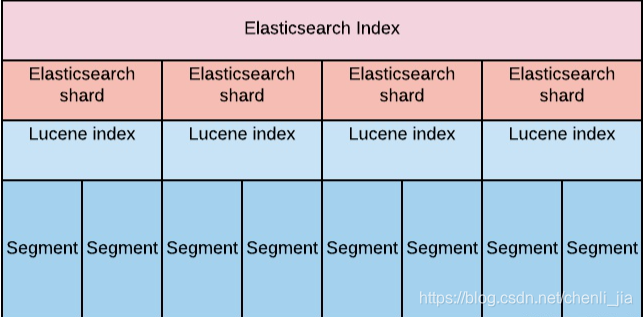
优势:(1)擅长高QPS(QPS > 1K)、低延迟、过滤条件多、查询模式简单(如点查、简单聚合)的查询场景。(2)集群自动化管理能力(shard allocation,recovery)能力非常强。集群、索引管理和查看的API非常丰富。
劣势:多维度分组排序、分页。不支持Join。在做aggregation后,由于返回的数据嵌套层次太多,数据量会过于膨胀。
Presto
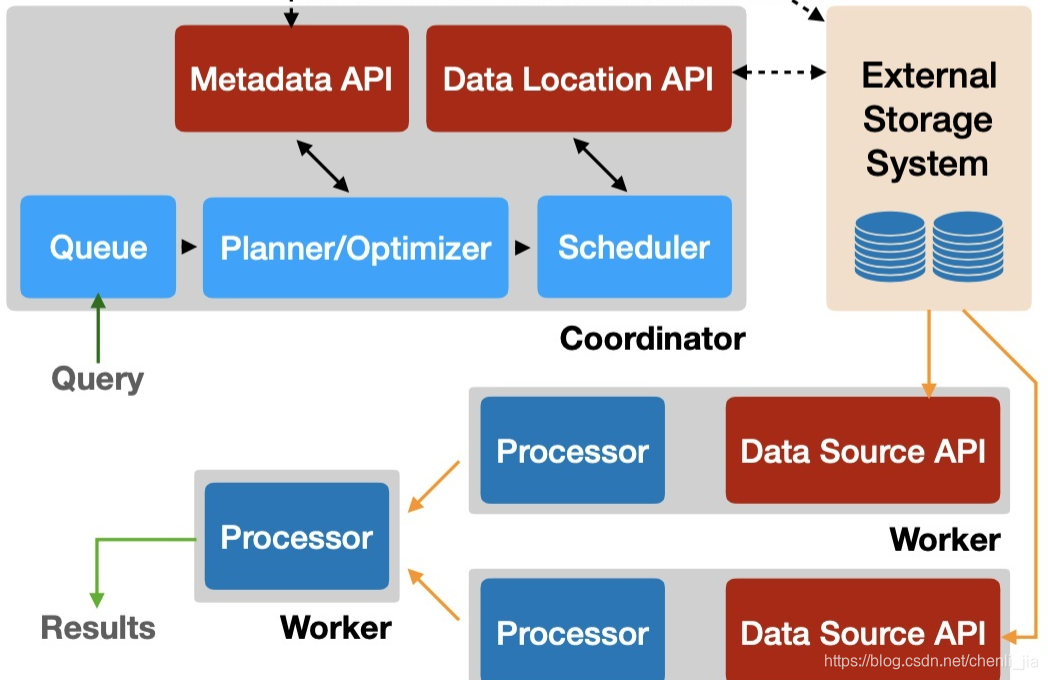
Presto、Impala、GreenPlum均基于MPP架构,相比Elasticsearch、Druid、Kylin这样的简单Scatter-Gather模型,在支持的SQL计算上更加通用,更适合ad-hoc查询场景,然而这些通用系统往往比专用系统更难做性能优化,所以不太适合做对查询QPS(参考值QPS > 1000)、延迟要求比较高(参考值search latency < 500ms)的在线服务,更适合做公司内部的查询服务和加速Hive查询的服务。Presto还有一个优秀的特性是使用了ANSI标准SQL,并且支持超过30+的数据源Connector。
Impala
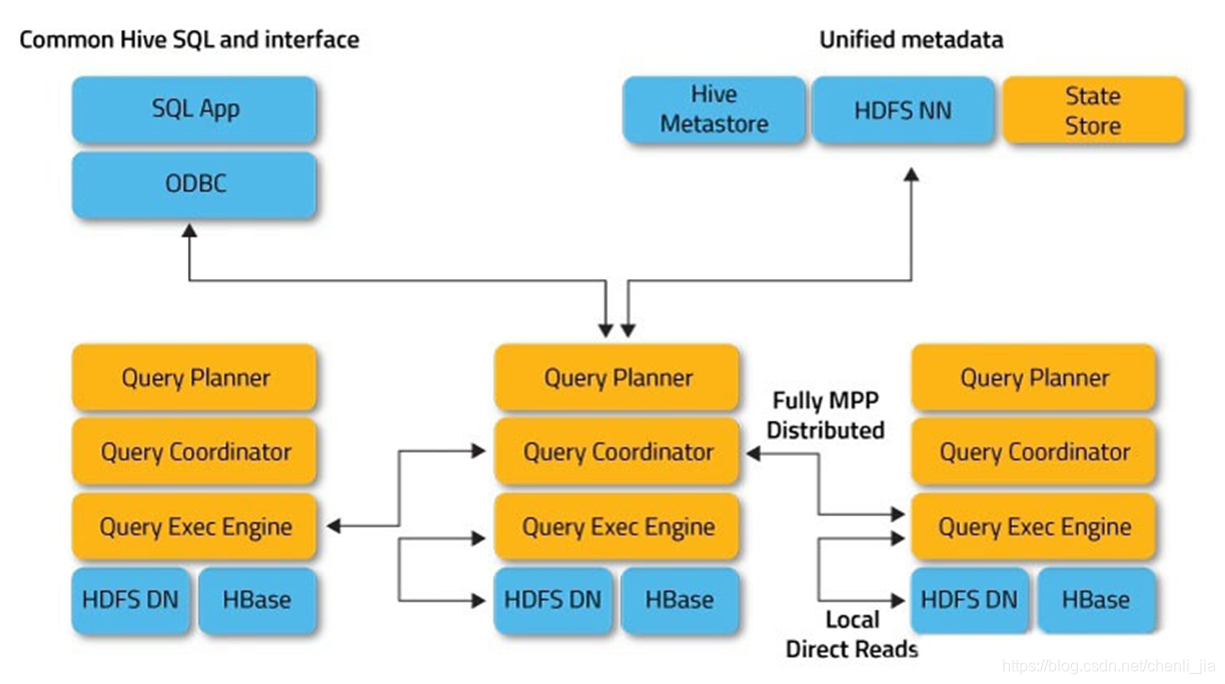
Doris
Doris是百度主导的,根据Google Mesa论文和Impala项目改写的一个大数据分析引擎,在百度、美团团、京东的广告分析等业务有广泛的应用
Druid
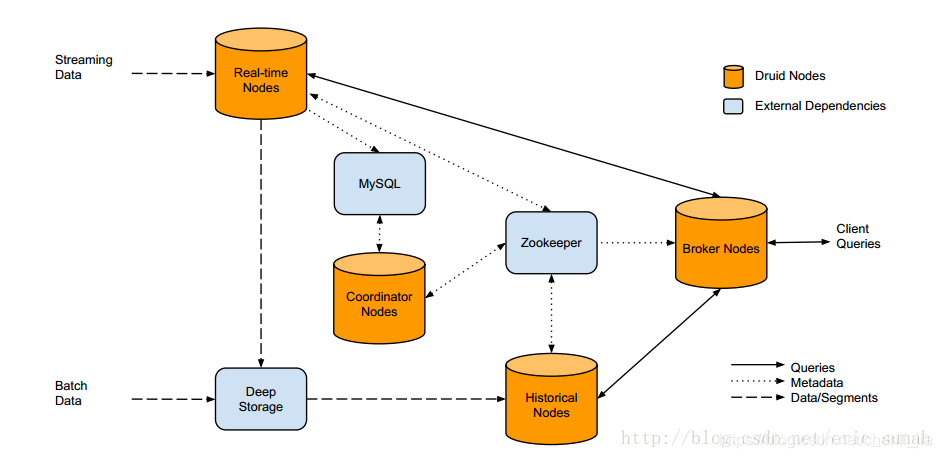
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。Druid支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用;
Kylin
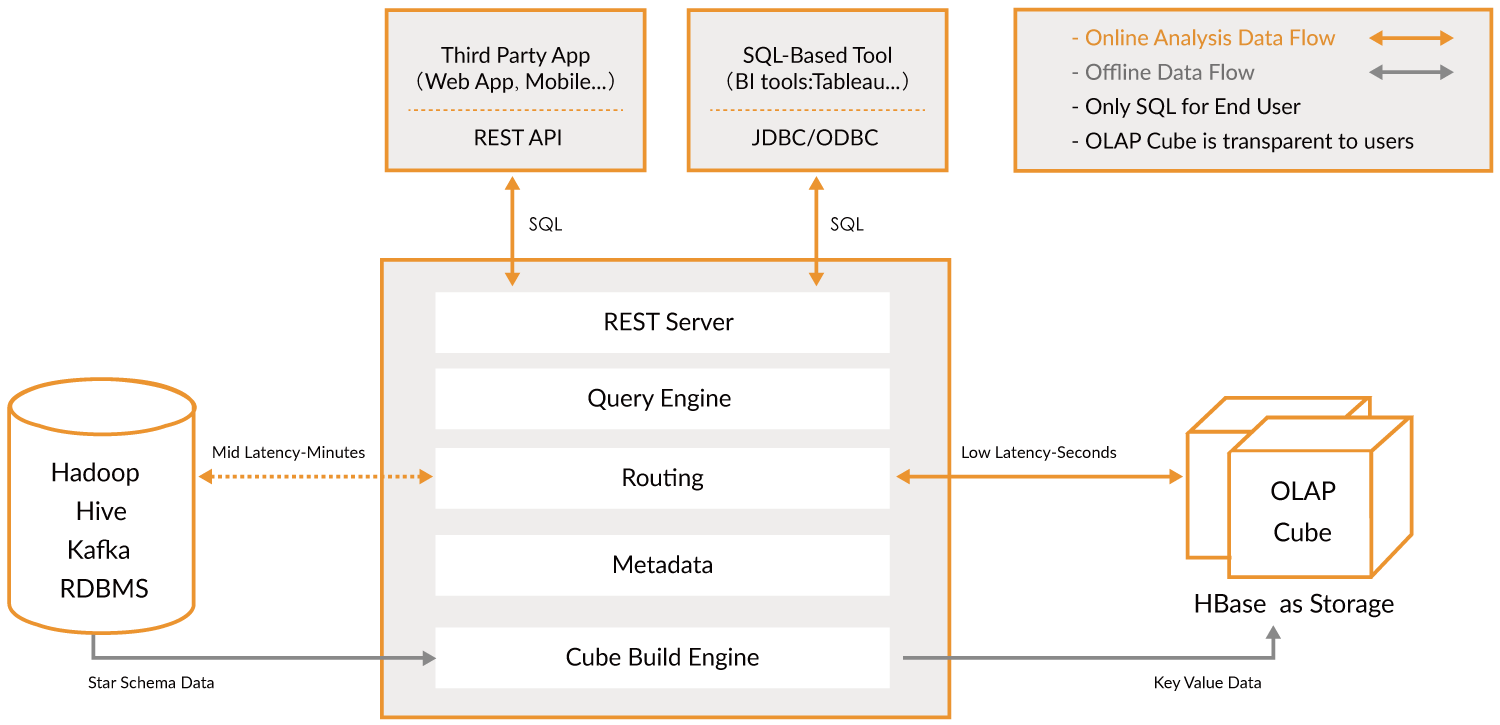
Kylin自身就是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。
适合Kylin的场景包括:
用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
每天有数G甚至数十G的数据增量导入
有10个以内较为固定的分析维度
简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。