1.���
�ӱ�̵ĽǶȶ���,�����߾��Ǹ�����Kafka������Ϣ��Ӧ�ó�����Kafka����ʷ��Ǩ��,һ����������汾�������߿ͻ���:��һ������Kafka��Դ֮��ʹ��Scala���Ա�д�Ŀͻ���,���ǿ��Գ�֮Ϊ�������߿ͻ���(Old Producer)��Scala�������߿ͻ���;�ڶ����Ǵ�Kafka0.9x �汾��ʼ�Ƴ���ʹ��Java���Ա�д�Ŀͻ���,���ǿ��Գ�֮Ϊ�������߿ͻ���(New Producer)��Java�������߿ͻ���,���ֲ��˾ɰ�ͻ����д��ڵ�������ȱ�ݡ���ȻKafka����Java/Scala���Ա�д��,���Ⲣ�����������ڶ����Ե�֧�֡�
2.�ͻ��˿���
һ����������������Ҫ�߱����¼�������:
- ���������߿ͻ��˲�����������Ӧ��������ʵ����
- ���������͵���Ϣ��
- ������Ϣ��
- �ر�������ʵ����
�����߿ͻ���ʾ������:
public class KafkaProducerAnalysis {
public static final String BROKER_LIST = "localhost:9092";
public static final String TOPIC_NAME = "topic-demo";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put("bootstrap.servers", BROKER_LIST);
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("client.id", "producer.client.id.demo");
return properties;
}
public static void main(String[] args){
Properties properties = initConfig();
//���������߿ͻ��˲���������KafkaProducerʵ��
KafkaProducer<String, String> producer = new KafkaProducer(properties);
//��������Ҫ���͵���Ϣ
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "hello,Kafka!");
//������Ϣ
try{
producer.send(record);
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
}
}
��������Ϣ����ProducerRecord,�������ǵ��������ϵ���Ϣ,�������˶������,ԭ����Ҫ���͵���ҵ����ص���Ϣ��ֻ�����е�һ��value����,���硰hello,Kafka!��ֻ��ProducerRecord�����е�һ�����ԡ�ProducerRecord��Ķ�������(ֻ��ȡ��Ա����):
public class ProducerRecord<K, V> {
private final String topic;//����
private final Integer partition;//������
private final Headers headers;//��Ϣͷ��
private final K key;//��
private final V value;//ֵ
private final Long timestamp;//��Ϣ��ʱ���
...
}
����topic��partition�ֶηֱ������ϢҪ��������ͷ����š�headers�ֶ�����Ϣ��ͷ��,Kafka 0.11.x�汾�������������,����������趨һЩ��Ӧ����ص���Ϣ,������ҪҲ���Բ������á�key������ָ����Ϣ�ļ�,����������Ϣ�ĸ�����Ϣ,������������������Ž�����������Ϣ�����ض��ķ�����ǰ���ἰ��Ϣ������Ϊ��λ���й���,�����key��������Ϣ�ٽ��ж��ι���,ͬһ��key����Ϣ�ᱻ���ֵ�ͬһ�������С���key����Ϣ����֧����־ѹ���Ĺ��ܡ�value��ָ��Ϣ��,һ�㲻Ϊ��,���Ϊ�����ʾ�ض�����Ϣ�CĹ����Ϣ��timestamp��ָ��Ϣ��ʱ���,����CreateTime��LogAppendTime��������,ǰ�߱�ʾ��Ϣ������ʱ��,���߱�ʾ��Ϣ�ӵ���־�ļ���ʱ�䡣
2.1.��Ҫ�IJ�������
�ڴ���������������ʵ��ǰ��Ҫ������Ӧ�IJ���,������Ҫ���ӵ�Kafka��Ⱥ��ַ����Kafka�����߿ͻ���KafkaProducer��3�������DZ���ġ�
- bootstrap.servers:�ò�������ָ�������߿ͻ�������Kafka��Ⱥ�����broker��ַ�嵥,��������ݸ�ʽΪhost1:port1,host2:port2,��������һ��������ַ,�м��Զ��Ÿ���,�˲�����Ĭ��ֵΪ������ע�����ﲢ����Ҫ���е�broker��ַ,��Ϊ������Ӹ�����broker����ҵ�����broker����Ϣ��������������Ҫ�����������ϵ�broker��ַ��Ϣ,����������һ��崻�ʱ,��������Ȼ�������ӵ�Kafka��Ⱥ�ϡ�
- key.serializer��value.serializer:broker�˽��յ���Ϣ�������ֽ�����(byte[])����ʽ���ڡ�������ʹ�õ�KafkaProducer<String, String>��ProducerRecord<String, String>�еķ���<String, String>��Ӧ�ľ�����Ϣ��key��value������,�����߿ͻ���ʹ�����ַ�ʽ�����ô���������õĿɶ���,�����ڷ���broker֮ǰ��Ҫ����Ϣ�ж�Ӧ��key��value����Ӧ�����л�������ת�����ֽ����顣key.serializer��value.serializer:broker�˽��յ���Ϣ�������ֽ�����(byte[])����ʽ���ڡ�������ʹ�õ�KafkaProducer<String, String>��ProducerRecord<String, String>�еķ���<String, String>��Ӧ�ľ�����Ϣ��key��value������,�����߿ͻ���ʹ�����ַ�ʽ�����ô���������õĿɶ���,�����ڷ���broker֮ǰ��Ҫ����Ϣ�ж�Ӧ��key��value����Ӧ�����л�������ת�����ֽ����顣key.serializer��value.serializer�����������ֱ�����ָ��key��value���л����������л���,������������Ĭ��ֵ��ע�����������д���л�����ȫ����,
initConfig()�����ﻹ������һ������client.id,������������趨KafkaProducer��Ӧ�Ŀͻ���id,Ĭ��ֵΪ����������ͻ��˲�����,��KafkaProducer���Զ�����һ���ǿ��ַ���,������ʽ�硰producer-1������producer-2��,���ַ�����producer-�������ֵ�ƴ�ӡ�
KafkaProducer�еIJ����ڶ�,Զ��ʾ����initConfig()�����е�����ֻ��4��,������Ա���Ը���ҵ��Ӧ�õ�ʵ������������Щ������Ĭ��ֵ,�Դﵽ�������Ŀ�ġ�һ�������,��ͨ������Ա����ס���еIJ�������,ֻ���и����µ�ӡ����ʵ��ʹ�ù�����,���硰key.serializer������max.request.size������interceptor.classes��֮����ַ�������������Ϊ���ض���д����Ϊ��,���ǿ���ֱ��ʹ�ÿͻ����е�org.apache.kafka.clients.producer.ProducerConfig������һ���̶��ϵ�Ԥ����ʩ,ÿ��������ProducerConfig���ж��ж�Ӧ������,��initConfig()����Ϊ��,����ProducerConfig����Ľ������:
public static Properties initConfig(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
BROKER_LIST);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,
"producer.client.id.demo");
return properties;
}
ע������Ĵ����е�key.serializer��value.serializer������Ӧ���ȫ�����Ƚϳ�,Ҳ�Ƚ�����д��,����ͨ��Java�еļ���������һ���ĸĽ�,��ش�������:
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
��˴������������,ͬʱ��һ����������Ϊ�����Ŀ����ԡ������������֮��,���ǾͿ�������������һ��������ʵ����ʾ������:
KafkaProducer<String, String> producer = new KafkaProducer(properties);
Kafka Producer���̰߳�ȫ��,�����ڶ���߳��й�������Kafka Producerʵ��,Ҳ���Խ�Kafka Producerʵ�����гػ��������̵߳��á�
Kafka Producer���ж�����췽��,�����ڴ���Kafka Producerʵ��ʱ��û���趨key.serializer��value.serializer���������ò���,��ô����Ҫ�ڹ��췽�������Ӷ�Ӧ�����л�����ʾ������:
KafkaProducer<String, String> producer =
new KafkaProducer(properties,
new StringSerializer(),
new StringSerializer());
���ڲ�ԭ���������л����Ĺ��췽��һ��,������ʵ��Ӧ�ö���,һ�㶼ѡ��public Kafka Producer(Properties properties)������췽��������Kafka Producerʵ����
2.2.��Ϣ�ķ���
�ڴ�����������ʵ��֮��,�������Ĺ������ǹ�����Ϣ,������ProducerRecord����,����topic���Ժ�value�����DZ�����,�����ѡ����,��Ӧ��ProducerRecord�Ĺ��췽��Ҳ�ܶ���,�ο�����:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
this(topic, partition, timestamp, key, value, (Iterable)null);
}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
this(topic, partition, (Long)null, key, value, headers);
}
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}
�������һ�ֹ��췽��,Ҳ�����һ��,���ַ�ʽ�൱�ڽ�ProducerRecord�г�topic��value�������ȫ��ֵ����Ϊnull����ʵ�ʵ�Ӧ����,�����õ��������췽��,����Ҫָ��key,��������headers�ȡ�
������������ʵ��������Ϣ֮��,�Ϳ��Կ�ʼ������Ϣ�ˡ�������Ϣ��Ҫ������ģʽ:������(fire-and-forget)��ͬ��(sync)���첽(async)��
������ķ��ͷ�ʽ���Ƿ�����,��ֻ����Kafka�з�����Ϣ������������Ϣ�Ƿ���ȷ����ڴ���������,���ַ��ͷ�ʽû��ʲô����,������ijЩʱ��(���緢�����������쳣ʱ)�������Ϣ�Ķ�ʧ�����ַ��ͷ�ʽ���������,�ɿ���Ҳ��
KafkaProducer��send()����������void����,����Future< RecordMetadata >����,send()�������������ط���,���嶨������:
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return this.send(record, (Callback)null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return this.doSend(interceptedRecord, callback);
}
Ҫʵ��ͬ���ķ��ͷ�ʽ,�������÷��ص�Future����ʵ��,ʾ������:
try{
producer.send(record).get();
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
ʵ����send()�������������첽��,send()�������ص�Future�������ʹ���÷��Ժ��÷��͵Ľ����ʾ����ִ��send()����֮��ֱ����ʽ������get()�����������ȴ�Kafka����Ӧ,֪����Ϣ���ͳɹ�,���߷����쳣,��������쳣,��ô����Ҫ�����쳣�����������������
Ҳ������ִ����send()����֮��ֱ�ӵ���get()����,���������һ��ͬ�����ͷ�ʽ��ʵ��:
try{
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get();
System.out.println(metadata.topic() + "-" + metadata.partition() + ":" + metadata.offset());
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
�������Ի�ȡһ��RecordMetadata����,��RecordMetadata�������������Ϣ��һЩԪ������Ϣ,���統ǰ��Ϣ�����⡢�����š������е�ƫ����(offset)��ʱ����ȡ������Ӧ�ô�������Ҫ��Щ��Ϣ,�����ʹ�������ʽ���������Ҫ,��ֱ�Ӳ���producer.send(record).get()�ķ�ʽ��ʡ�¡�
Future��ʾһ���������������,���ṩ����Ӧ�ķ������ж������Ƿ��Ѿ���ɻ�ȡ��,�Լ���ȡ����Ľ����ȡ������ȡ���ȻKafkaProducer.send()�����ķ���ֵ��һ��Future���͵Ķ���,��ô��ȫ������Java���Բ���ļ������ḻӦ�õ�ʵ��,����ʹ��Future�е�get(long timeout, TimeUnit unit)����ʵ�ֿɳ�ʱ��������
KafkaProducer��һ��ᷢ���������͵��쳣:�����Ե��쳣�Ͳ������Ե��쳣�������Ŀ����Ե��쳣��:NetworkException��LeaderNotAvailableException��UnkownTopicOrPartitionException��NotEnoughReplicasException��NotCoordinatorException�ȡ�����NetworkException��ʾ�����쳣,����п�������������˲ʱ���϶����µ��쳣,����ͨ�����Խ��;�ֱ���LeaderNotAviableException��ʾ������leader����������,����쳣ͨ��������leader�������߶��µ�leader����ѡ�����֮ǰ,����֮��������»ָ����������Ե��쳣,����RecordTooLargeException�쳣,��ʾ�������͵���Ϣ̫��,KafkaProducer�Դ˲�������κ�����,ֱ���׳��쳣��
���ڿ������Ե��쳣,���������retries����,��ôֻҪ�ڹ涨�����Դ��������лָ���,�Ͳ����׳��쳣��retries������Ĭ��ֵΪ0,���÷�ʽ�ο�����:
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
ʾ����������10�����ԡ����������10��֮��û�лָ�,��ô�Ի��׳��쳣,�������͵��������Ҫ������Щ�쳣�ˡ�
ͬ�����͵ķ�ʽ�ɿ��Ը�,Ҫô��Ϣ�����ͳɹ�,Ҫô�����쳣����������쳣,����Բ�������Ӧ�Ĵ���,���������������ķ�ʽֱ�������Ϣ�Ķ�ʧ������ͬ�����͵ķ�ʽ�����ܻ��ܶ�,��Ҫ�����ȴ�һ����Ϣ������֮����ܷ�����һ����
�첽���͵ķ�ʽ,һ������send()������ָ��һ��Callback�Ļص�����,Kafka�ڷ�����Ӧʱ���øú�����ʵ���첽�ķ���ȷ�ϡ���Ȼsend()�����ķ���ֵ���;���Future,��Future�����Ϳ��������첽��������,����Future���get()�����ں�ʱ����,�Լ���ô���ö�����Ҫ��Ե�����,��Ϣ��ͣ�ط���,��ô�����Ϣ��Ӧ��Future����Ĵ��������������봦�����Ļ��ҡ�ʹ��Callback�ķ�ʽ�dz��������,Kafka����Ӧʱ�ͻ�ص�,Ҫô���ͳɹ�,Ҫô�׳��쳣���첽���ͷ�ʽ��ʾ������:
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e != null){
e.printStackTrace();
}else{
System.out.println(metadata.topic()
+ "-"
+ metadata.partition()
+ ":"
+ metadata.offset());
}
}
});
ʾ�������������쳣ʱ(e != null)ֻ�����˼Ĵ�ӡ����,��ʵ��Ӧ����Ӧ�����ø������ķ�ʽ������,������Խ��쳣��¼�Ա��պ����,Ҳ������һ���Ĵ�����������Ϣ�ط���onCompletion()���������������ǻ����,��Ϣ���ͳɹ�ʱ,metadata��Ϊnull��exceptionΪnull;��Ϣ�����쳣ʱ,metadataΪnull��exception��Ϊnull��
producer.send(record1, callback1);
producer.send(record2, callback2);
����ͬһ����������,�����Ϣrecord1��record2֮ǰ�ȷ���,��ôKafkaProducer�Ϳ��Ա�֤��Ӧ��callback1��callback2֮ǰ����,Ҳ����˵,�ص������ĵ���Ҳ���Ա�֤��������
ͨ��,һ��KafkaProducer����ֻ�����͵�����Ϣ,������Ƿ��Ͷ�����Ϣ,�ڷ�������Щ��Ϣ֮��,��Ҫ����KafkaProducer��close()������������Դ��
int i = 0;
while(i < 100){
ProducerRecord<String, String> record =
new ProducerRecord<>(TOPIC_NAME, "msg" + i++);
try {
producer.send(record).get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
close()�����������ȴ�֮ǰ���еķ����������֮���ٹر�KafkaProducer�����ͬʱ,KafkaProducer���ṩ��һ������ʱʱ���close()���������嶨������:
public void close(long timeout, TimeUnit timeUnit);
��������˴���ʱʱ��timeout��close()����,��ôֻ���ڵȴ�timeoutʱ���������������δ��ɵ�������,Ȼ��ǿ���˳�����ʵ��Ӧ����,һ��ʹ�õĶ����ε�close()������
2.3.���л�
��������Ҫ�����л���(Serializer)�Ѷ���ת�����ֽ��������ͨ�����緢��Kafka�����ڶԲ�,��������Ҫ�÷����л���(Deserializer)�Ѵ�Kafka���յ����ֽ�����ת������Ӧ�Ķ��ͻ����Դ���org.apache.kafka.common.serialization.StringSerializer,��������String���͵����л���,����ByteArray��ByteBuffer��Bytes��Double��Integer��Long�⼸������,���Ƕ�ʵ����org.apache.kafka.common.serialization.Serializer,�˽ӿ����ĸ�����:
default void configure(Map<String, ?> configs, boolean isKey) {}
byte[] serialize(String var1, T var2);
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {}
configure()�����������õ�ǰ��,serialize()��������ִ�����л�����,��close()���������رյ�ǰ�����л���,�����������close()������һ���շ���,���ʵ���˴η���,�����ȷ���˷������ݵ���,��Ϊ��������ܿ��ܻᱻKafkaProducer���ö�Ρ�
������ʹ�õ����л�����������ʹ�õķ����л�������Ҫһһ��Ӧ��,���������ʹ����ij�����л���,��StringSerializer,��������ʹ������һ�����л���,����IntegerSerializer,��ô������������Ҫ�����ݵġ�
StringSerializer��ľ���ʵ������:
public class StringSerializer implements Serializer<String> {
private String encoding = "UTF8";
public StringSerializer() {
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding";
Object encodingValue = configs.get(propertyName);
if (encodingValue == null) {
encodingValue = configs.get("serializer.encoding");
}
if (encodingValue instanceof String) {
this.encoding = (String)encodingValue;
}
}
@Override
public byte[] serialize(String topic, String data) {
try {
return data == null ? null : data.getBytes(this.encoding);
} catch (UnsupportedEncodingException var4) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + this.encoding);
}
}
@Override
public void close(){}
}
������configure()����,�����ʽ���ڴ���KafkaProducerʵ����ʱ����õ�,��Ҫ����ȷ����������,����һ��ͻ��˶���key.serializer.encoding��value.serializer.encoding��serializer.encoding�⼸�ֲ�������������,��Kafkaproducer�IJ�������(ProducerConfig)��Ҳû���⼸������(���ǿ��Կ����û��Զ���IJ���),����һ�������encoding��ֵ��Ĭ��Ϊ��UTF-8����serialize()�����dz�ֱ��,���ǽ�String����ת��Ϊbyte[]���͡�
���Kafka�ͻ����ṩ�ļ������л�����������Ӧ������,�����ѡ��ʹ����Avro��JSON��Thrift��ProtoBuf��ProtostuFF��ͨ�õ����л�������ʵ��,����ʹ���Զ������͵����л�����ʵ�֡�
�������һ���������������Զ������͵�ʹ�÷�����
��������Ҫ���͵���Ϣ����Company����,���Company�Ķ���ܼ��, ֻ��name��address�ֶ�,ʾ����������:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Company {
private String name;
private String address;
}
Company��Ӧ�����л���CompanySerializerʾ����������:
public class CompanySerializer implements Serializer<Company> {
@Override
public void configure(Map configs, boolean isKey){}
@Override
public byte[] serialize(String s, Company company) {
if(company == null){
return null;
}
byte[] name, address;
try{
if(company.getName() != null){
name = company.getName().getBytes("UTF-8");
}else {
name = new byte[0];
}
if(company.getAddress() != null){
address = company.getAddress().getBytes("UTF-8");
}else{
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close(){}
}
ֻ��Ҫ��KafkaProducer��value.serializer��������ΪCompanySerializer���ȫ�������ɡ�������Ҫ����һ��Company����Kafka,������������:
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
CompanySerializer.class.getName());
properties.put("bootstrap.servers", BROKER_LIST);
KafkaProducer<String, Company> producer =
new KafkaProducer<String, Company>(properties);
Company company = Company.builder()
.name("hiddenkafka")
.address("china")
.build();
ProducerRecord<String, Company> record =
new ProducerRecord<>(TOPIC_NAME, company);
try {
producer.send(record).get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}finally {
producer.close();
}
2.4.������
��Ϣ��ͨ��send()��������broker�Ĺ�����,�п�����Ҫ����������(Interceptor)�����л���(Serializer)�ͷ�����(Partitioner)��һϵ������֮����������ط���broker��������һ�㲻�DZ����,�����л�ʱ����ġ���Ϣ�������л�֮�����Ҫȷ���������ķ���,�����ϢProducerRecord��ָ����partition�ֶ�,��ô�Ͳ���Ҫ������������,��Ϊpartition�����ľ�����Ҫ�����ķ����š�
�����ϢProducerRecord��û��ָ��partition�ֶ�,��ô����Ҫ����������,����key����ֶ�������partition��ֵ�������������þ���Ϊ��Ϣ���������
Kafka���ṩ��Ĭ�Ϸ�������org.apache.kafka.clients.producer.internals.DefaultPartitioner,��ʵ����org.apache.kafka.clients.producer.Partitioner�ӿ�,����ӿڶ�������������:
int partition(String var1, Object var2, byte[] var3, Object var4, byte[] var5, Cluster var6);
void close();
����partition()�����������������,����ֵΪint���͡�partition()�����еIJ����ֱ��ʾ���⡢�������л���ļ���ֵ�����л����ֵ,�Լ���Ⱥ��Ԫ������Ϣ,ͨ����Щ��Ϣ����ʵ�ֹ��ܷḻ�ķ�������close()�����ڹؼ���������ʱ����������һЩ��Դ��
Partitioner�ӿڻ���һ�����ӿ� org.apache.kafka.common.Configurable,����ӿ���ֻ��һ������:
void configure(Map<String, ?>) configs);
Configurable�е�configure()������Ҫ������ȡ������Ϣ����ʼ�����ݡ�
��Ĭ�Ϸ�����DefaultPartitioner��ʵ����,close�ǿշ���,����partition()�����ж�������Ҫ�ķ��������������key��Ϊnull,��ôĬ�ϵķ��������key���й�ϣ(����MurmurHash2�㷨,�߱����������ܼ�����ײ��),���ո��ݵõ��Ĺ�ϣֵ�����������,ӵ����ͬ��key����Ϣ�ᱻд��ͬһ�����������keyΪnull,��ô��Ϣ��������ѯ�ķ�ʽ���������ڵĸ������÷�����
ע��:���key��Ϊnull,��ô����õ��ķ����Ż������з����е�����һ��;���keyΪnull,��ô����õ��ķ����Ž�Ϊ���÷����е�����һ��,����֮�����в��ġ�
�ڲ��ı�������������������,key�����֮���ӳ����Ա��ֲ��䡣����,һ�������������˷���,��ô�����Ա�֤key�����֮���ӳ���ϵ�ˡ�
����ʹ��Kafka�ṩ��Ĭ�Ϸ��������з�������,������ʹ���Զ���ķ�����,ֻ��ͬDefaultPartitionerһ��ʵ��Partitioner�ӿڼ��ɡ�Ĭ�ϵķ�������keyΪnullʱ����ѡ��ǿ��õķ���,���ǿ���ͨ���Զ���ķ�����DefaultPartitioner��������һ����,�����ʵ�ִ�������:
public class DemoPartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if(null == keyBytes){
return counter.getAndIncrement() % numPartitions;
}
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> map) {}
}
ʵ���Զ����DemoPartitioner��֮��,��Ҫͨ�����ò���partitioner.class����ʽָ�������������ʾ������:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoPartitioner.class.getName());
����Զ����������ʵ�ֱȽϼ�, һ����͵��̶��ж���ֿ�,���Խ��ֿ�����ƻ�ID��Ϊkey�����ؼ�¼��Ʒ��Ϣ��
2.5.������������
������(Interceptor)������Kafka 0.10.0.0�о��Ѿ������һ������,Kafkaһ��������������:����������������������������
�������������ȿ�����������Ϣ����Ǯ��һЩ������,���簴��ij��������˲�����Ҫ�����Ϣ������Ϣ�����ݵ�,Ҳ���������ڷ��ͻص���Ǯ��һЩ���ƻ�������,����ͳ�������
��������������ʹ��Ҳ�ܷ���,��Ҫ���Զ���ʵ�� org.apache.kafka.clients.producer.ProducerInterceptor�ӿڡ�ProducerInterceptor�ӿ��а�����������:
ProducerRecord<K, V> onSend(ProducerRecord<K, V> var1);
void onAcknowledgement(RecordMetadata var1, Exception var2);
void close();
KafkaProducer�ڽ���Ϣ���л��ͼ������֮ǰ�������������������onSend()����������Ϣ������Ӧ�Ķ��ƻ�������һ����˵��ò�Ҫ����ϢProducerRecord��topic��key��partition����Ϣ,���Ҫ��,����Ҫȷ��������ȷ���ж�,�������Ԥ���Ч������ƫ�������key������Ӱ������ļ���,ͬ����Ӱ��broker����־ѹ��(Log Compaction)�Ĺ��ܡ�
KafkaProducer������Ϣ��Ӧ��(Acknowledgement)֮ǰ����Ϣ����ʧ��ʱ������������������onAcknowledgement()����,�������û��趨��Callback֮ǰִ�С��������������Producer��I/O�߳���,�������������ʵ�ֵĴ�����Խ��Խ��,�����Ӱ����Ϣ�ķ����ٶȡ�
close()������Ҫ�����ڹر�������ʱִ��һЩ��Դ����������������������������׳����쳣���ᱻ����¼����־��,�����������ϴ��ݡ�
����ͨ��һ��ʾ������ʾ�������������ľ����÷�,ProducerInterceptorPrefix��ͨ��onSend()������Ϊÿ����Ϣ����һ��ǰ��prefix-1��,��ͨ��onAcknowledgement()���������㷢����Ϣ�ijɹ��ʡ�
�����������:
public class ProducerInterceptorPrefix implements ProducerInterceptor<String, String> {
private volatile long sendSuccess = 0;
private volatile long sendFailure = 0;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String modifiedValue = "prefix1-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(),
record.timestamp(),
record.key(),
modifiedValue,
record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if(e == null){
sendSuccess++;
}else{
sendFailure++;
}
}
@Override
public void close() {
double successRatio = (double)sendSuccess / (sendFailure + sendSuccess);
System.out.println("[INFO] ���ͳɹ���="
+ String.format("%f", successRatio * 100)
+ "%");
}
@Override
public void configure(Map<String, ?> map) {}
}
ʵ���Զ����ProducerInterceptorPrefix֮��,��Ҫ��KafkaProducer�����ò���interceptor.classes��ָ�����������,�˲�����Ĭ��ֵΪ������ʾ������:
properties.put(ProducerConfig.INTERCEPTOR_CLASS_CONFIG, ProducerInterceptorPrefix.class.getName());
Ȼ��ʹ��ָ����ProducerInterceptorPrefix����������������10������Ϊ��kafka������Ϣ�������������10����Ϣ,�ᷢ�������˵���Ϣ������ˡ�prefix1-kafka��,������ԭ���ġ�kafka����
KafkaProducer�в�������ָ��һ��������,������ָ��������������γ����������������ᰴ��interceptor.classes�������õ���������˳����һһִ��(���õ�ʱ��,����������֮��ʹ�ö��Ÿ���)���������Զ���һ��������ProducerInterceptorPrefixPlus,��ֻʵ����Interceptor�ӿ��е�onSend()����,��Ҫ����Ϊÿ����Ϣ������һ��ǰ��prefix2-��,����ʵ������:
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String modifiedValue = "prefix2-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(),
record.timestamp(),
record.key(),
modifiedValue,
record.headers());
}
�����������ߵ�interceptor.classes����,����ʵ������:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptorPrefix.class.getName()
+ ","
+ ProducerInterceptorPrefixPlus.class.getName());
��ʱ����������������10������Ϊ��kafka������Ϣ,��ô�������������ѵ�����10������Ϊ��prefix2-prefix-kafka������Ϣ�������interceptor.classes�����е�������������λ�û���:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptorPrefixPlus.class.getName()
+ ","
+ ProducerInterceptorPrefix.class.getName());
��ô�������������ѵ�����ϢΪ��prefix1-prefix2-kafka����
����������е�ij����������ִ����Ҫ������ǰһ�������������,��ô�Ϳ��ܲ����������á�������һ��,���ǰһ�������������쳣��ִ��ʧ��,��ô���������Ҳ����������ִ�С�����������,���ij��������ִ��ʧ��,��ô��һ������������Ŵ���һ��ִ�гɹ�������������ִ�С�
3.ԭ������
3.1.����ܹ�
ǰ���������Ϣ����������Kafka֮ǰ,�п�����Ҫ����������(Interceptor)�����л���(Serializer)�ͷ�����(Partitioner)��һϵ�е����á���ͼ�������߿ͻ��˵�����ܹ�:
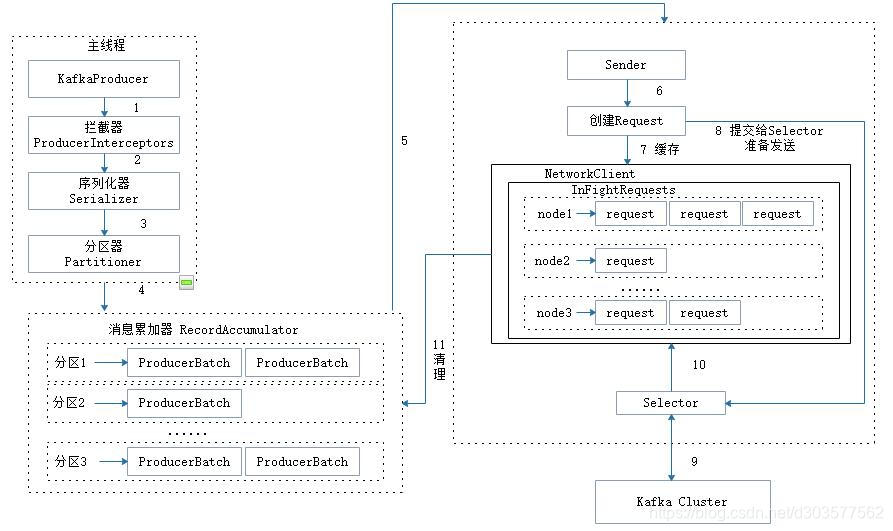
���������߿ͻ����������߳�Э������,�������̷ֱ߳�Ϊ���̺߳�Sender�߳�(�����߳�)�������߳�����KafkaProducer�����߳�,Ȼ��ͨ�����ܵ������������л����ͷ�����������֮�浽��Ϣ�ۼ���(RecordAccumulator,Ҳ��Ϊ��Ϣ�ռ���)�С�Sender�̸߳����RecordAccumulator�л�ȡ��Ϣ�����䷢�͵�Kafka�С�
RecordAccumulator��Ҫ����������Ϣ�Ա�Sender�߳̿�����������,�����������紫�����Դ�������������ܡ�RecordAccumulator����Ĵ�Сͨ�������߿ͻ��˲���buffer.memory����,Ĭ��ֵΪ33554432B,��32MB����������߷�����Ϣ���ٶȳ������͵����������ٶ�,��ᵼ�������߿ռ䲻��,���ʱ��KafkaProducer��send()��������Ҫô������,Ҫô�׳��쳣,���ȡ���ڲ���max.block.ms������,�˲�����Ĭ��ֵΪ60000,��60�롣
���߳��з���������Ϣ���ᱻ�ӵ�RecordAccumulator��ij��˫�˶���(Deque)��,��RecordAccumulator���ڲ�Ϊÿ��������ά����һ��˫�˶���,�����е����ݾ���ProducerBatch,��Depue<ProducerBatch>����Ϣд�뻺��ʱ,�ӵ�˫�˶��е�β��:Sender��ȡ��Ϣʱ,��˫�˶��е�ͷ����ȡ��ע��ProducerBatch����ProducerRecord,ProducerBatch�п�����һ�����ProducerRecord��ͨ��˵,ProducerRecord���������д�������Ϣ,��ProducerBatch��һ����Ϣ����,ProducerRecord�ᱻ������ProducerBatch��,��������ʹ�ֽڵ�ʹ�ø��ӽ��ա����ͬʱ,����С��ProducerRecordƴ�ճ�һ���ϴ��ProducerBatch,Ҳ���Լ�����������ĴȺ��������������������ProducerBatch����Ϣ�ľ����ʽ�йء���������߿ͻ�����Ҫ��ܶ����������Ϣ,����Խ�buffer.memory�����ʵ������������������������
��Ϣ�������϶������ֽ�(Byte)����ʽ�����,�ڷ���֮ǰ��Ҫ����һ���ڴ������������Ӧ����Ϣ����Kafka�����߿ͻ�����,ͨ��java.io.ByteBufferʵ����Ϣ�ڴ�Ĵ������ͷš�����Ƶ���ش������ͷ��DZȽϺķ���Դ��,��RecordAccumulator���ڲ�����һ��BufferPool,����Ҫ����ʵ��ByteBuffer�ĸ���,��ʵ�ֻ���ĸ�Ч���á�����BufferPoolֻ����ض���С��ByteBuffer���й���,��������С��ByteBuffer���Ỻ���BufferPool��,����ض��Ĵ�С��batch.size������ָ��,Ĭ��ֵΪ16384B,��16KB�����ǿ����ʵ��ص���batch.size�����Ա���һЩ��Ϣ��
ProducerBatch�Ĵ�С��batch.size����Ҳ�����еĹ�ϵ����һ����Ϣ(ProducerRecord)����RecordAccumulatorʱ,����Ѱ������Ϣ��������Ӧ��˫�˶���(���û�����½�),�ٴ����˫�˶��е�β����ȡһ��ProducerBatch(���û�����½�),�鿴ProducerBatch���Ƿ���д�����ProducerRecord,���������д��,�������������Ҫ����һ���µ�ProducerBatch�����½�ProducerBatchʱ����������Ϣ�Ĵ�С�Ƿ�batch.size�����Ĵ�С,���������,��ô����batch.size�����Ĵ�С������ProducerBatch,������ʹ��������ڴ�����֮��,����ͨ��BufferPool�Ĺ��������и���;�������,��ô���������Ĵ�С������ProducerBatch,����ڴ����ᱻ���á�
Sender��RecordAccumulator�л�ȡ�������Ϣ֮��,���һ����ԭ��<����, Deque<ProducerBatch>>�ı�����ʽת��Ϊ<Node, List<ProducerBatch>>����ʽ,����Node��ʾKafka��Ⱥ��broker�ڵ㡣��������������˵,�����߿ͻ�����������broker�ڵ㽨��������,Ҳ����������broker�ڵ㷢����Ϣ,������������Ϣ������һ������;������KafkaProducer������������,����ֻ��ע���Ǹ������з�����Щ��Ϣ,������������Ҫ��һ��Ӧ�������浽����I/O�����ת����
��ת����<Node, List<ProducerBatch>>����ʽ֮��,Sender�����һ����װ��<Node, Request>����ʽ,�����Ϳ��Խ�Request����������Node��,�����Request��ָKafka�ĸ���Э������,������Ϣ���Ͷ��Ծ���ָ�����ProduceRequest��
�����ڴ�Sender�̷߳���Kafka֮ǰ���ᱣ�浽InFlightRequests��,InFlightRequests�������ľ�����ʽΪMap<NodeId, Deque<Request>>,������Ҫ�����ǻ������Ѿ�����ȥ����û���յ���Ӧ������(NodeId��һ��String����,��ʾ�ڵ��id���)�����ͬʱ,InFlightRequests���ṩ�����������ķ���,����ͨ�����ò�������������ÿ������(Ҳ���ǿͻ�����Node֮�������)�������������������ò���Ϊmax.in.flight.requests.per.connection,Ĭ��ֵΪ5,��ÿ���������ֻ�ܻ���5��δ��Ӧ������,��������ֵ֮��Ͳ�������������ӷ������������,�����л���������յ�����Ӧ(Response)��ͨ���Ƚ�Deque<Request>��size����������Ĵ�С���ж϶�Ӧ��Node���Ƿ��Ѿ��ѻ��˺ܶ�δ��Ӧ����Ϣ,����������,��ô˵�����Node�ڵ㸺�ؽϴ����������������,�ټ������䷢���������������ʱ�Ŀ��ܡ�
3.2.Ԫ���ݵĸ���
InFlightRequests�����Ի��leastLoadedNode,������Node�и�����С����һ��������ĸ�����С��ͨ��ÿ��Node��InFlightRequests�л�δȷ�ϵ����������,δȷ�ϵ�����Խ������Ϊ����Խ��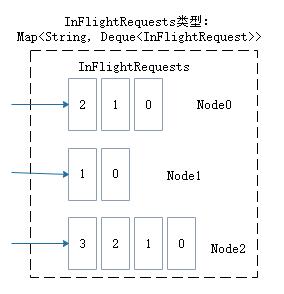
ɽ��չʾ�������ڵ�Node0��Node1��Node2,������Node1�ĸ�����С��Ҳ����˵,Node1Ϊ��ǰ��leastLoadedNode��ѡ��leastLoadedNode�����������ʹ���ܹ����췢��,����������ӵ�����쳣��Ӱ������Ľ��ȡ�leastLoadedNode�ĸ���������ڶ��Ӧ�ó���,����Ԫ���������������鲥Э��Ľ�����
ʹ�����·�ʽ����һ����ϢProducerRecord:
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello,Kakfa!");
����ֻ�����������,��������һЩ��Ҫ����Ϣ��û�С�KafkaProducerҪ������Ϣ�ӵ�ָ�������ij����������Ӧ��leader����֮ǰ,������Ҫ֪������ķ�������,Ȼ������ó�(����ֱ��ָ��)Ŀ�����,֮��KafkaProducerҪ������Ϣ�ӵ�ָ�������ij����������Ӧ��leader����֮ǰ,������Ҫ֪������ķ�������,Ȼ������ó�(����ֱ��ָ��)Ŀ�����,֮��KafkaProducer��Ҫ֪��Ŀ�������leader�������ڵ�broker�ڵ�ĵ�ַ���˿ڵ���Ϣ���ܽ�������,���ղ��ܽ���Ϣ���͵�Kafka,����һ����������Ҫ����Ϣ������Ԫ������Ϣ��
bootstrap.servers����ֻ��Ҫ���ò���broker�ڵ�ĵ�ַ����,����Ҫ�������е�broker�ڵ�ĵ�ַ,��Ϊ�ͻ��˿����Լ���������broker�ڵ�ĵ�ַ,��һ����Ҳ����Ԫ������صĸ��²��������ͬʱ,����������leader�����ķֲ����ᶯ̬�ر仯,�ͻ���Ҳ��Ҫ��̬�ز���Щ�仯��
Ԫ������ָKafka��Ⱥ��Ԫ����,��ЩԪ���ݾ����¼�˼�Ⱥ������Щ����,��Щ��������Щ����,ÿ��������leader�����������ĸ��ڵ���,follower������������Щ�ڵ���,��Щ������AR��ISR�ȼ�����,��Ⱥ������Щ�ڵ�,�������ڵ�������һ������Ϣ��
���ͻ�����û����Ҫʹ�õ�Ԫ������Ϣʱ,����û��ָ����������Ϣ,���߳���metadata.max.age.msʱ��û�и���Ԫ���ݶ�������Ԫ���ݵĸ��²������ͻ��˲���metadata.max.age.ms��Ĭ��ֵΪ3000000,��5���ӡ�Ԫ���ݵĸ��²������ڿͻ����ڲ����е�,�Կͻ��˵��ⲿʹ�����Dz��ɼ�������Ҫ����Ԫ����ʱ,������ѡ��leastLoadedNode,Ȼ�������Node����MetadataRequest��������ȡ�����Ԫ������Ϣ��������²�������Sender�̷߳����,�ڴ�����MetadataRequest֮��ͬ�������InFlightRequests,�ܵIJ���ͷ�����Ϣʱ���ơ�Ԫ������Ȼ��Sender�̸߳������,�������߳�Ҳ��Ҫ��ȡ��Щ��Ϣ,���������ͬ��ͨ��synchronized��final�ؼ��������ϡ�
4.��Ҫ�������߲���
��KafkaProducer��,���������ἰ������Ĭ�ϵĿͻ��˲���,�ֵIJ������к�����Ĭ��ֵ,һ�㲻��Ҫ�����ǡ������˽���Щ�������Ը�������ʹ�������߿ͻ���,���л���һЩ��Ҫ�IJ����漰����Ŀ����Ժ�����,����ܹ�������������,Ҳ�����������ڱ�д��صij���ʱ�ܹ����õؽ������ܵ���������ų���
4.1.acks
�����������ָ�������б���Ҫ�ж��ٸ������յ�������Ϣ,֮�������߲Ż���Ϊ������Ϣ�dzɹ�д��ġ�acks�������߿ͻ����е�һ���dz���Ҫ�IJ���,���漰��Ϣ�Ŀɿ��Ժ�������֮���Ȩ�⡣acks�������������͵�ֵ(�����ַ�������)��
- acks = 1��Ĭ��ֵ��Ϊ1�������߷�����Ϣ֮��,ֻҪ������leader�����ɹ�д����Ϣ,��ô���ͻ��յ����Է���˵ijɹ���Ӧ�������Ϣ��д��leader����,������leader��������������ѡ���µ�leader�����Ĺ�����,��ô�����߾ͻ��յ�һ���������Ӧ,Ϊ�˱�����Ϣ��ʧ,�����߿���ѡ���ط���Ϣ�������Ϣд��leader���������سɹ���Ӧ��������,���ڱ�����follower������ȡ֮ǰleader��������,��ô��ʱ��Ϣ���ǻᶪʧ,��Ϊ��ѡ�ٵ�leader�����в�û��������Ӧ����Ϣ��acks����Ϊ1,����Ϣ�ɿ��Ժ�������֮������з�����
- acks = 0�������߷�����Ϣ֮����Ҫ�ȴ��κη������˵���Ӧ���������Ϣ�ӷ��͵�д��Kafka�Ĺ����г�����ijЩ�쳣,����Kafka��û���յ�������Ϣ,��ô������Ҳ�ӵ�֪,��ϢҲ�Ͷ�ʧ�ˡ����������û�����ͬ�������,acks����Ϊ0���Դﵽ������������
- acks = -1 �� acks = all������������Ϣ����֮��,��Ҫ�ȴ�ISR�е����и������ɹ�д����Ϣ֮����ܹ��յ����Է���˵ijɹ���Ӧ�����������û�����ͬ�������,acks����Ϊ-1(all)���Դﵽ��ǿ�Ŀɿ��ԡ����Ⲣ����ζ����Ϣ��һ���ɿ�,��ΪISR�п���ֻ��leader����,�������˻�����acks = 1�������Ҫ��ø��ߵ���Ϣ�ɿ�����Ҫ���min.insync.replicas�Ȳ�����������
ע��:acks�������õ�ֵ��һ���ַ�������,�������������͡��ٸ�����,��acks��������Ϊ0,��Ҫ����������������ʽ:
properties.put("acks", "0");
//����
properties.put("ProducerConfig.ACKS_CONFIG, "0");
���������ó�����������ʽ:
properties.put("acks", 0);
//����
properties.put(ProducerConfig.ACKS_CONFIG, 0);
�����ᱨ�����µ��쳣:
org.apache.kafka.common.config.ConfigException: Invalid value 0 for configuration acks: Expected value to be a string, but it was a java.lang.Integer
4.2.max.request.size
����������������߿ͻ����ܷ��͵�С�ӵ����ֵ,Ĭ��ֵΪ1048576B,��1MB��һ�������,���Ĭ��ֵ�Ϳ�������������Ӧ�ó����ˡ����ﲻ����äĿ�������������������ֵ,�������ڶ�Kafka��������û��û���㹻�ѿص�ʱ����Ϊ����������漰һЩ��������������,����broker�˵�message.max.bytes����,������ô�����ܻ�����һЩ����Ҫ���쳣������broker�˵�message.max.bytes��������Ϊ10,��max.request.size��������Ϊ20,��ô�����Ƿ���һ����СΪ15B����Ϣʱ,�����߿ͻ��˾ͻᱨ�����µ��쳣:
org.apache.kafka.commom.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.
4.3.retries��retry.backoff.ms
retries���������������������ԵĴ���,Ĭ��ֵΪ0,���ڷ����쳣��ʱ�����κ����Զ�������Ϣ�ڴ������߷������ɹ�д�������֮ǰ���ܷ���һЩ��ʱ�Ե��쳣,�������綶����leader������ѡ�ٵ�,�����쳣�����ǿ������лָ���,�����߿���ͨ������retries����0��ֵ,�Դ�ͨ���ڲ��������ָ�������һζ�ؽ��쳣�������ߵ�Ӧ�ó���������Դ����ﵽ�趨�Ĵ���,��ô�����߾ͻ�������Բ������쳣���������������е��쳣���ǿ���ͨ�������������,������Ϣ̫��,����max.request.size�������õ�ֵʱ,���ַ�ʽ�Ͳ������ˡ�
���Ի�����һ������retry.backoff.ms�й�,���������Ĭ��ֵΪ100,�������趨��������֮���ʱ����,������Ч��Ƶ�����ԡ�������retries��retry.backoff.ms֮ǰ,����ȹ���һ�¿��ܵ��쳣�ָ�ʱ��,���������趨�ܵ�����ʱ���������쳣�ָ�ʱ��,�Դ������������߹���ط������ԡ�
Kafka���Ա�֤ͬһ�������е���Ϣ������ġ���������߰���һ����˳������Ϣ,��ô��Щ��ϢҲ��˳���д�����,����������Ҳ������ͬ����˳���������ǡ�����ijЩӦ����˵,˳���Էdz���Ҫ,����MySQL��binlog����,������ִ���ͻ���ɷdz����صĺ���������acks��������Ϊ����ֵ,����max.in.flight.requests.per.connection��������Ϊ����1��ֵ,��ô�ͻ���ִ��������:�����һ������Ϣд��ʧ��,���ڶ�������Ϣд��ɹ�,��ô�����߾ͻ����Է��͵�һ���ε���Ϣ,��ʱ�����һ���ε���Ϣд��ɹ�,��ô���������ε���Ϣ�ͳ����˴���һ�����,����Ҫ��֤��Ϣ˳��ij��Ͻ���Ѳ���max.in.flight.requests.per.connection����Ϊ1,�����ǰ�acks����Ϊ0,��������Ҳ��Ӱ����������¡�
4.4.compression.type
�����������ָ����Ϣ��ѹ����ʽ,Ĭ��ֵΪ��none��,��Ĭ�������,��Ϣ���ᱻѹ�����ò������������á�gzip������snappy���͡�lz4��������Ϣ����ѹ�����Լ���ؼ������紫��������������I/O,�Ӷ������������ܡ���Ϣѹ����һ��ʹ��ʱ�任�ռ���Ż���ʽ,�����ʱ����һ����Ҫ��,���Ƽ�����Ϣ����ѹ����
4.5.connections.max.idle.ms
�����������ָ���ڶ��֮��ر����Ƶ�����,Ĭ��ֵΪ540000(ms),��9���ӡ�
4.6.linger.mx
�����������ָ�������߷���producerBatch֮ǰ�ȴ�������Ϣ(ProducerRecord)����ProducerBatch��ʱ��,Ĭ��ֵΪ0.�����߿ͻ��˻���ProducerBatch��������ȴ�ʱ�䳬��linger.msֵʱ���ͳ�ȥ���������������ֵ��������Ϣ���ӳ�,����ͬʱ������һ���������������linger.ms������TCPЭ���е�Nagle�㷨������ͬ��֮�
4.7.receive.buffer.bytes
���������������Socket������Ϣ������(SO_RECBUF)�Ĵ�С,Ĭ��ֵΪ32768(B),��32KB���������Ϊ-1,��ʹ�ò���ϵͳ��Ĭ��ֵ�����Producer��Kafka���ڲ�ͬ�Ļ���,������ʵ������������ֵ��
4.8.send.buffer.bytes
���������������Socket������Ϣ������Ϣ������(SO_SNDBUF)�Ĵ�С,Ĭ��ֵΪ131072(B),��128KB����receive.buffer.bytes����һ��,�������Ϊ-1,��ʹ�ò���ϵͳ��Ĭ��ֵ��
4.9.request.timeout.ms
���������������Producer�ȴ�������Ӧ���ʱ��,Ĭ��ֵΪ30000(ms)������ʱ֮�����ѡ��������ԡ�ע�����������Ҫ��broker�˲���replica.lag.time.max.ms��ֵҪ��,�������Լ�����ͻ������Զ��������Ϣ�ظ��ĸ��ʡ�
4.10.�����ܽ�
| �������� | Ĭ��ֵ | �������� |
|---|---|---|
| bootstrap.servers | ���� | ָ������Kafka��Ⱥ�����broker��ַ�嵥�� |
| key.serializer | ���� | ��Ϣ��key��Ӧ�����л���,��Ҫʵ�֡�org.apache.kafka.common.serialization.Serializer�ӿڡ� |
| value.serializer | ���� | ��Ϣ��value��Ӧ�����л���,��Ҫʵ��org.apache.kafka.common.serialization.Serializer�ӿڡ� |
| buffer.memory | 33554432(32MB) | �����߿ͻ��������ڻ�����Ϣ�Ļ�������С�� |
| batch.size | 16384(16KB) | ����ָ��ProducerBatch���Ը����ڴ�����Ĵ�С�� |
| client.id | ���� | �����趨KafkaProducer��Ӧ�Ŀͻ���id�� |
| max.block.ms | 60000 | ��������KafkaProducer��send()������partitionsFor()����������ʱ�䡣�������ߵķ��ͻ���������,����û�п��õ�Ԫ����ʱ,��Щ�����ͻ������� |
| partitioner.class | org.apache.kafka.clients.producer.internals.DefaultPartitioner | ����ָ��������,��Ҫʵ��org.apache.kakfa.clients.producer.Partitioner�ӿڡ� |
| enable.idempotence | false | �Ƿ����ݵ��Թ��� |
| interceptor.class | ���� | �����趨������������,��Ҫʵ��org.apache.kafka.clients.producer.ProducerInterceptor�ӿڡ� |
| max.in.flight.requests.per.connection | 5 | ����ÿ������(Ҳ���ǿͻ�����Node֮�������)������������� |
| metadata.max.age.ms | 300000(5����) | ��������ʱ����Ԫ����û�и��µĻ��ᱻǿ�Ƹ��¡� |
| transactional.id | null | ��������id,����Ψһ |