����(��)��:�����
һ����¡��̨������
1����¡
����ǰ��Ҫ��¡�ķ������ر�
2����������
��ʱ��:hostname hadoop02(�ĺ��������
������:vim /etc/sysconfig/network
HOSTNAME=hadoop02
zookeeper��Ⱥ�������������Ⱥ
3���̶�ip

ȥ��ѡ�е���,�������һ�е�eth1��Ϊeth0
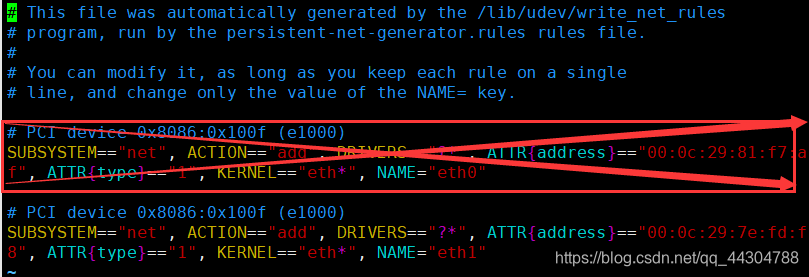

��ѡ�е������Ϊ�������һ���е�address,��ɾ��uuidһ��
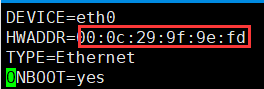
setup���õ�ַ
service network restart����
�����������ܵ�¼
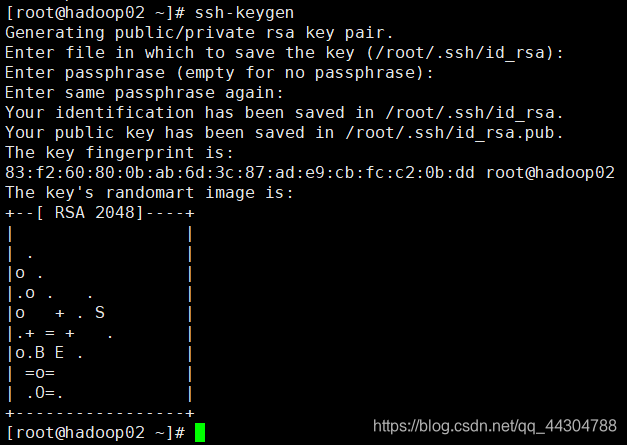
1����ÿ̨�����������ɹ�˽Կ:
ssh-keygen(Ȼ��һ·�س�����)
2������ԿԶ��ע��������ķ�����
ssh-copy-id ������������ip��ַ/������
��ÿһ̨�������²���
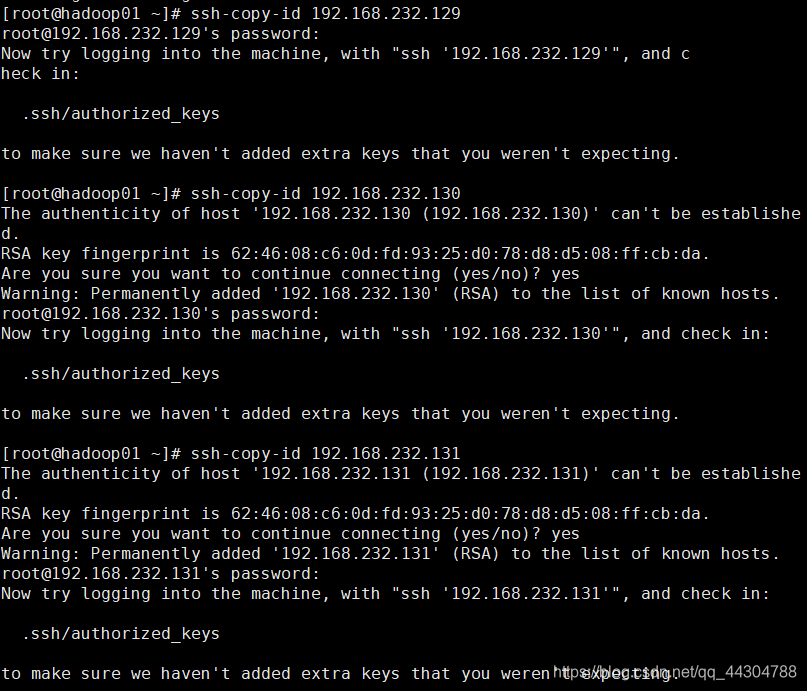
����֤:���ܵ�¼�ɹ�
������������:ssh + ������������ip��ַ/������
�˳�:exit
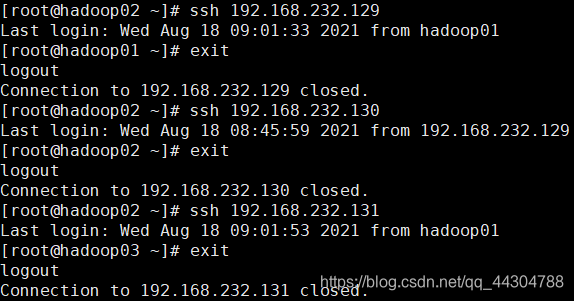
3��������������ip��ַ��ӳ��
��ÿһ�����������²���

�����رշ���ǽ
��ʱ�ر� service iptables stop
���ùر� chkconfig iptables off

�Դ���������һ��ִ�йرշ���ǽ�IJ���,��������xShell�����½��еı�ǩ,���·���������,����̨��������ִ��
�ġ�zookeeper��Ⱥ����
1��ɾ��֮ǰ���õ�α�ֲ�ʽ
����/home/softwareִ��rm -rf zookeeper-3.4.7

2�����½�ѹ
3������ģ���ļ�����Ϊzoo.cfg����zoo.cfg
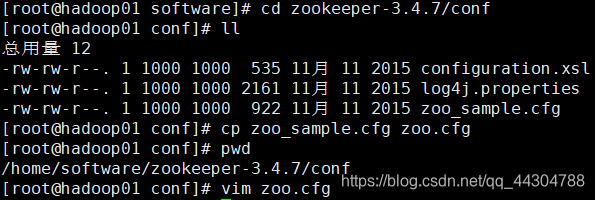
(1)��dataDir����

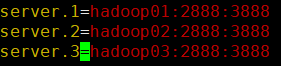
(2)�����ļ�ĩβ������������
2888:ԭ�ӹ㲥�Ķ˿�
3888:ѡ�ٵĶ˿�
ע��:�����ļ��ĵȺŵ��������˲����пո�
4������Ŀ¼���ļ�
��zookeeper�İ�װĿ¼����һ��tmpĿ¼,����tmpĿ¼����myid�ļ�

myid�ļ��е�����

5������
��hadoop01�����úõ�zookeeper���Ƶ�hadoop02��hadoop03��,�����ݷ�������service��,����myid���
(1)ɾ��ԭ�ȴ��ڵ�zookeeper

(2)����

(3)�ı��

6������
hadoop01

hadoop02

hadoop03
�������Ų�:�Ȱѽ���ͣ��,��������,����ǽ,�����ļ�,myid
������־:binĿ¼�µ�zookeeper.out
�塢zookeeperѡ�ٻ���
(һ)����
1����һ��zookeeper��Ⱥ��������ʱ��,�����ѡ��״̬,��ʱ���еĽڵ�(������)�����Ƽ��Լ���leader�����һ���Լ���ѡ����Ϣ���������ڵ�
2�����ڵ��յ������ڵ㷢������ѡ����Ϣ֮��,���������бȽ�,���ʤ���Ľڵ㵱leader
(��)ϸ��
1��ѡ����Ϣ����:
a. ��ǰ�ڵ���������id
b. ѡ�ٱ��,��myid
c. ��ʼ��ֵ-��֤ѡ�ٵ�����
2���Ƚ�ԭ��
a. �ȱȽ��������id,˭��˭Ӯ
b. �������idһ���Ļ�,�Ƚ�myid,˭��˭Ӯ
c. ���һ���ڵ�ʤ����һ�����ϵĽڵ�,��ô����ڵ����leader�C������
3����zookeeper��,�����ڵ�����ϵ�˵��,���leader崻�,��ô������Ⱥ��ѡ��һ���µ�leader���������ṩ����
4�����leader崻�֮����������,���ʱ��ῴ��һ���µĽڵ���뼯Ⱥ,��ʱ����ڵ�һ����follower
5�����һ����Ⱥ�Ѿ�ѡ�ٳ���leader,Ϊ��ά�ּ�Ⱥ���ȶ���,���������ӵĽڵ������id��myid�Ƕ���,�����ᴥ��leader������ѡ��,�¼ӵĽڵ�ֻ����follower
6�����һ����Ⱥ���ֶ��leader,���������������
7��zookeeper�������ѵ�������:
a. ��Ⱥ��������
b. ���Ѻ������ѡ��
8����zookeeper��������Ľڵ�(�����ͨ�ŵķ�����)����һ��,����Щ�ڵ㲻�ᷢ��ѡ�١���ʱ��Щ�ڵ�Ҳ��������ṩ����C������������
9��zookeeper���ÿһ��ѡ�ٳ�����leader����һ��ȫ�ֵĵ����ı��,��֮Ϊepochid,��zookeeper���ִ��ڶ��leaderʱ,���Զ���epochid��С�Ľڵ��״̬�л���follower,�������ַ������Ա�֤������Ⱥֻ����Ψһ��leader
10����Ⱥ�нڵ��״̬
a. Looking/voting:ѡ��״̬
b. Follower:����
c. leader:�쵼��
d. observer:�۲���
����ZAB��
(һ)����
1��ZAB(zookeeper Atomic Broadcast)Э��ר��Ϊzookeeper��Ƶ����ڽ���ԭ�ӹ㲥�������ָ���һ��Э��
2��ZABЭ���ǻ���2PC�㷨���ʵ�ֵġ������˹�����+PAXOS�����˸���
(��)ԭ�ӹ㲥
1������:��֤��Ⱥ�и����ڵ�֮���������һ�µ�,����������һ���ڵ�,��ȡ�������ݶ�����ͬ��
2������2PC�㷨���ʵ�ֵ�
3��2PC-two Phase Commi-�����ύ�㷨,����˼��,��һ�������ֳ�������
a. �����
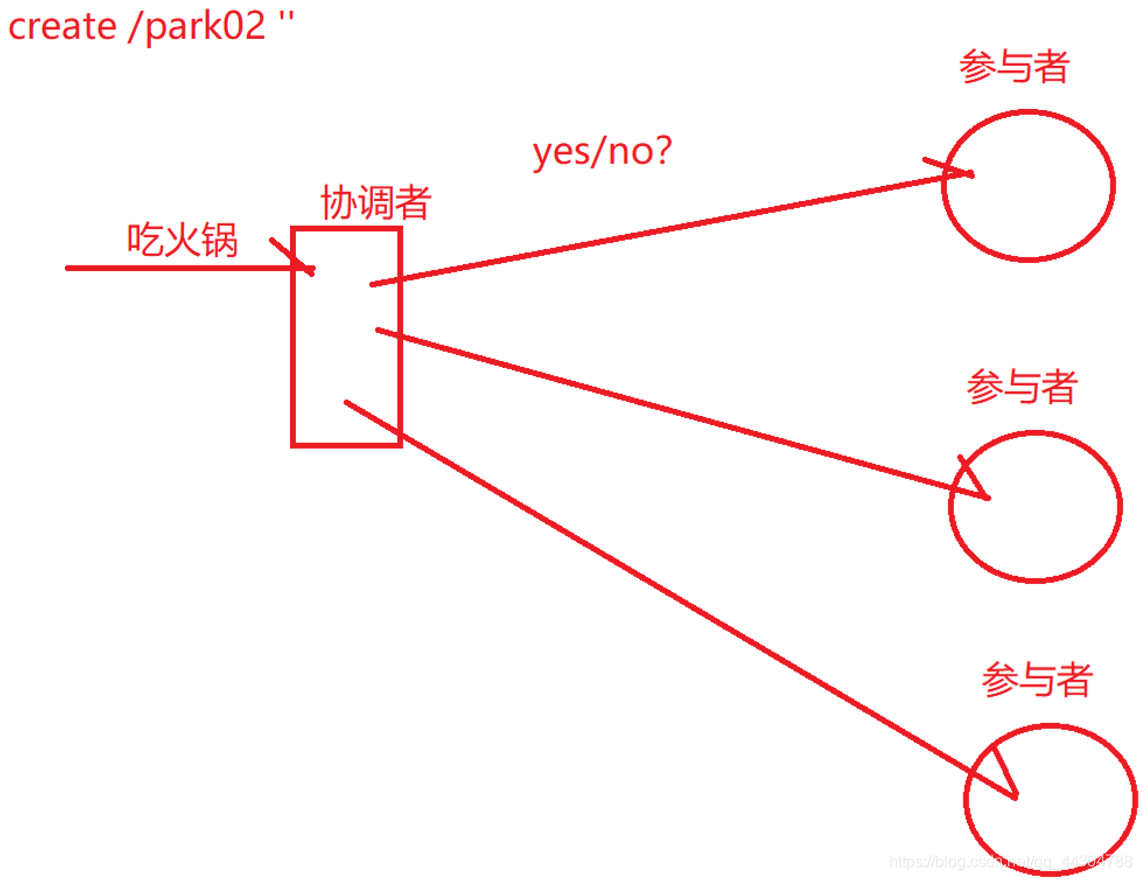 b. �ύ��:���Э�����յ����в����߷��ص�yes,��ô��Ϊ����������ִ��,��ô�ͻ��������еIJ�����ִ���������
b. �ύ��:���Э�����յ����в����߷��ص�yes,��ô��Ϊ����������ִ��,��ô�ͻ��������еIJ�����ִ���������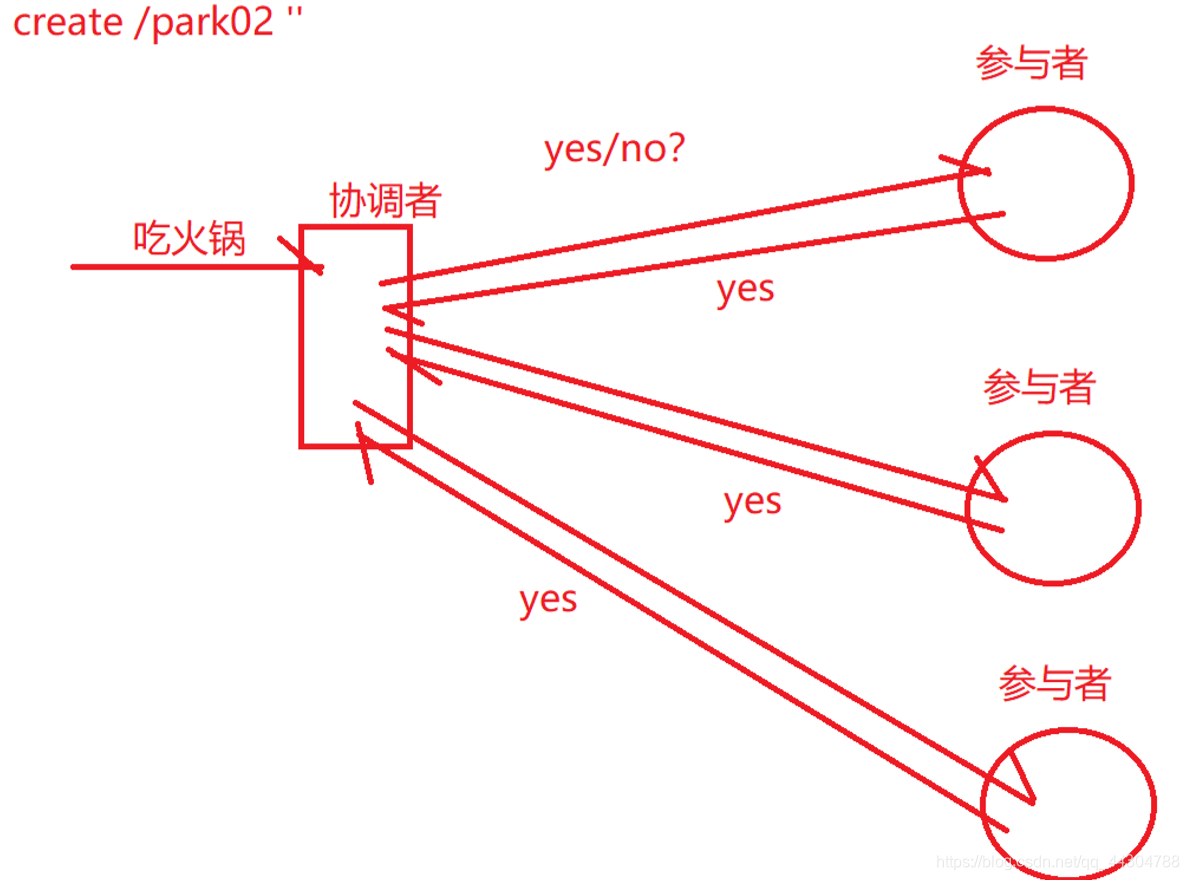
c. ��ֹ��,ֻҪЭ����û���յ����в����߷��ص�yes,��ô�ͻ���Ϊ���������ִ��,Ҳ��Ҫ�����еIJ����߷����ղŵ�����
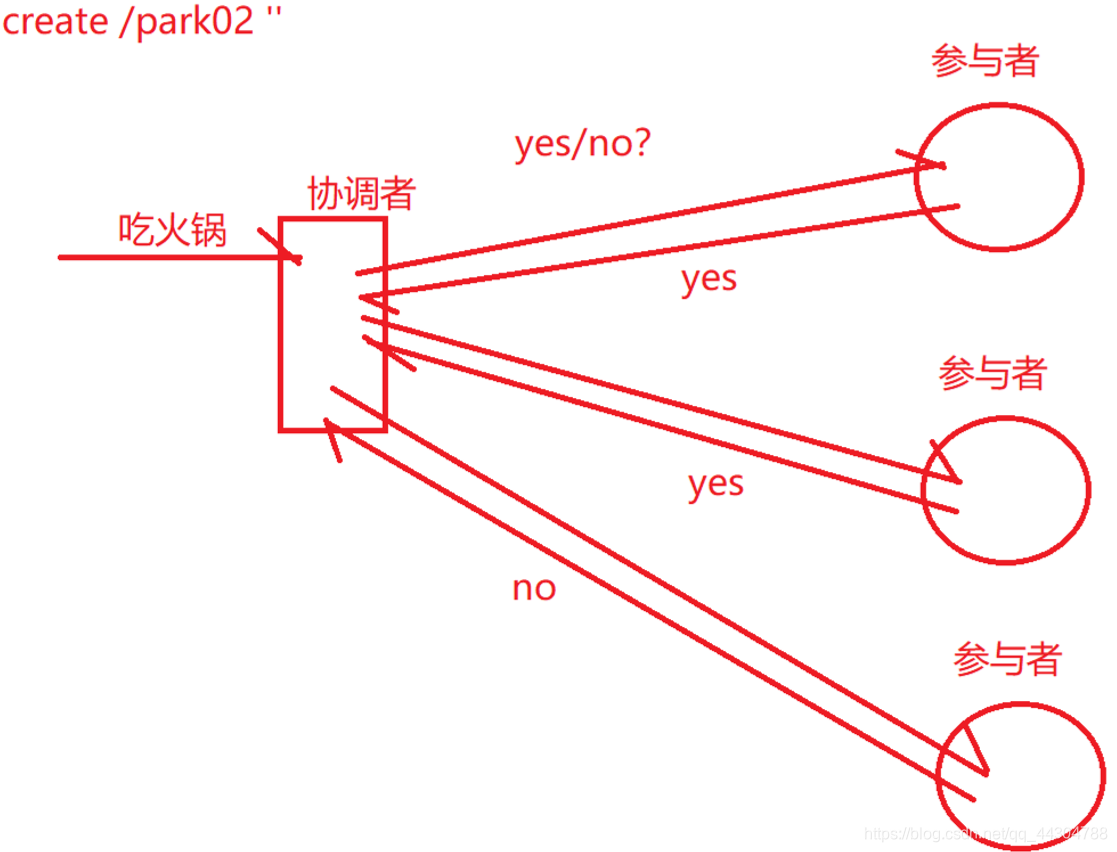
4����2PC�㷨��,Ҫô��������ִ��,Ҫô����������ֹ
5��2PC�㷨��˼�����"һƱ���"
6��2PC�㷨����������,����ʵ��Ҳ������,���ڷֲ�ʽ������,2PC�㷨�ijɹ��ʺܵ͡�Ч��Ҳ�ܵ�,��2PC�㷨��������PAXOS�㷨(������)��ԭ�����иĽ�
7��ԭ�ӹ㲥�Ĺ���
follower����������,���ǽ���������ת����leader���д�������>��leader���յ������,�Ὣ�����¼�����ص���־��(log.xxx),�����¼�ɹ�,leader�ͻὫ����ŵ������з���follower����>follower�յ����к�,�Ὣ����Ӷ�����ȡ��,Ȼ����ͼ��¼�����ص���־�С�����>�����¼�ɹ�,��follower�ͻ���Ϊ����ִ���������,���ҷ��ظ�leaderһ��yes;�����¼ʧ��,��followerr����Ϊ���������ִ��,���ҷ��ظ�leaderһ��no����>���leader�յ��������ϵĽڵ㷵�ص�yes,�����Ϊ����������ִ��,�ͻ�������Щfollowerִ���������;�������ϵ�no,����������������ִ��,֪ͨ���е�followerɾ���ղŵļ�¼
8��follower���ڼ�¼��־ʧ�ܵĿ���,����,�ļ���ռ�á����������������������ܵ�����־�ļ���¼ʧ��,�����������zookeeper��ԭ��,zookeeper�����
9��
(��)�����ָ�
1����leader崻�֮��,������Ⱥ������ʹ�ֹͣ����,���ǻ�ѡ�ٳ���һ���µ�leader,���������ṩ����
2����zookeeper��Ⱥ��,���ÿһ��ѡ�ٳ�����leader����һ��ȫ�ֵ�����Ψһ�ı��,��֮Ϊepochid,��leader��ѡ�ٳ���֮��,���leader�ͻὫepochid�ַ���ÿһ��follower��follower�յ����id֮��,�ͻὫ���id�洢��acceptedEpoch�ļ���
3������:���ⵥ�����
4�����follower��¼ʧ��,��ô��follower���ɹ�֮��,���leader��������,��������Ĺ����лὫ����������id����leader,leader�յ�����֮��,�������idһ��,˵����follower���������ʱ��,leaderû�������κε����������leader������id����follower������id,���ʱ��leader�Ὣ�����������ŵ������з���follower��Ҫ��follower����������followerû�в�������֮ǰ�������ṩ����
(��)�۲���
����
1��observer��zookeeper��Ⱥ�мȲ��μ�ѡ��Ҳ���μ�ͶƱ,���ǻ����ͶƱ�Ľ����ѡ�ٵĽ��,
2��observer���¿�������Ϊû��ѡ��Ȩ��ͶƱȨ��follower���Cֻ�иɻ������û��ѡ�ٵ�Ȩ��
3����ʵ�ʿ���������,����Ⱥ��ģ�ϴ�(�ڵ�Ƚ϶�)��ʱ��,�������绷���Ƚϲ��ʱ�����ǽ�һ����Ⱥ��90%-97%�Ľڵ�����Ϊobserver
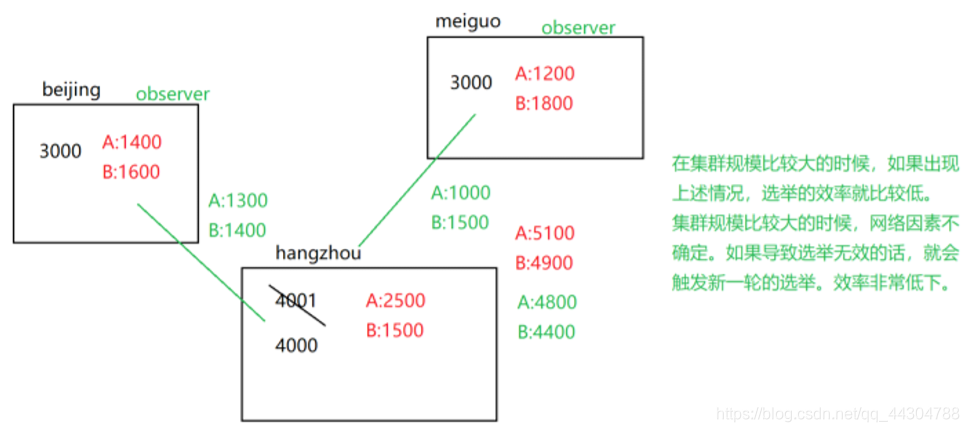
�ڼ�Ⱥ��ģ�ϴ��ʱ��,�����źŶ�ʧ�����ѡ����Ч(������(���õ�����)),��������������,ѡ�ٵ�Ч�ʾͱȽϵ�;��Ⱥ��ģ�ϴ��ʱ��,�������ز�ȷ�����������ѡ����Ч�Ļ�,�ͻᴥ����һ�ֵ�ѡ�١�Ч�ʷdz�����
����Ϊobserver
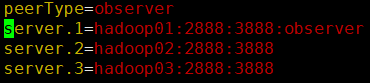
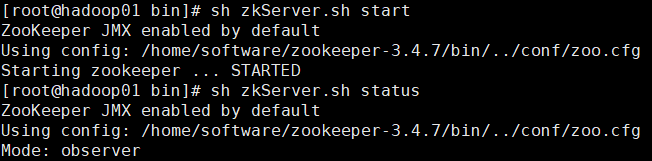
4������observer
a. ��zoo.cfg
i ����peerType=observer
ii ��Ҫ����Ϊobserver��������������:observer
(��)����
1��������:����ѡ�١����������������
2������һ����:������ڵ��ȡ����,�õ������ݶ���һ����
3��ԭ����:һ������Ҫô���еĽڵ���ɹ�,Ҫô��ʧ��
4��˳����:���нڵ��ȡ��������˳����һ�µĨC����
5���ɿ���:�����ָ�
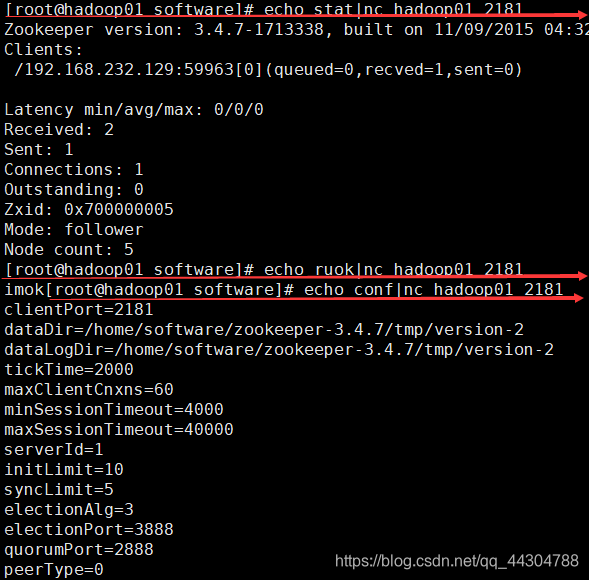
����:(���Ȱ�װnc)
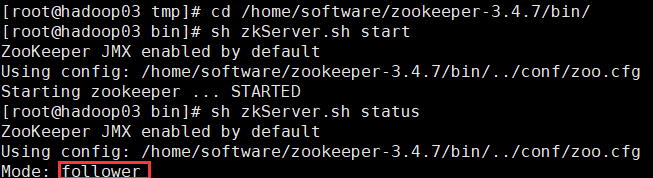
1���鿴�ڵ��Ƿ�崻�:echo ruok|nc hadoop01 2181
2���鿴�ڵ�״̬:echo stat|nc hadoop01 2181
3���鿴�ڵ��������Ϣ:echo conf|nc hadoop01 2181
��װnc-1.84��
���Ƚ�nc����/home/software��
ִ�а�װ����

�������
�ߡ��ֲ�ʽһ�����㷨-Paxos
û�о���Ĺ�ʽ,ֻ��һ��˼��,��ppt
�ˡ��鿴��־(��������״̬)
������������/tmp/version-2��
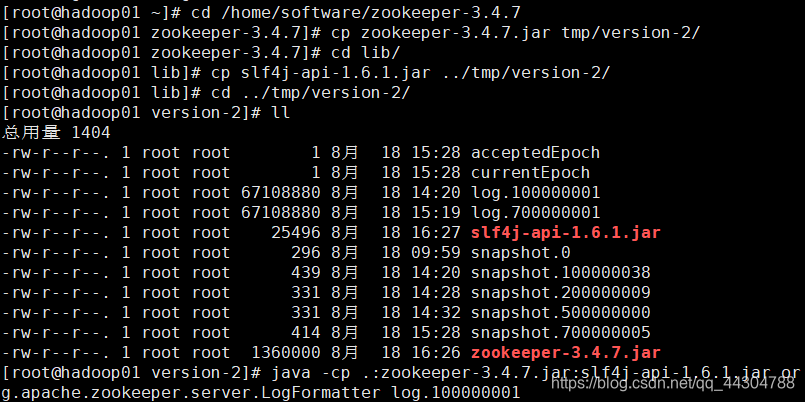
ʹ����������鿴
