如果我要建一个如下的hive表:
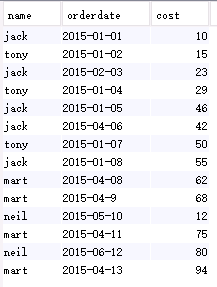
我可以使用下面的hive代码:
drop table if exists analyst.t_window;
create table analyst.t_window as select * from (
select 'jack' as name, '2015-01-01' as orderdate, 10 as cost
union all
select 'tony' as name, '2015-01-02' as orderdate, 15 as cost
union all
select 'jack' as name, '2015-02-03' as orderdate, 23 as cost
union all
select 'tony' as name, '2015-01-04' as orderdate, 29 as cost
union all
select 'jack' as name, '2015-01-05' as orderdate, 46 as cost
union all
select 'jack' as name, '2015-04-06' as orderdate, 42 as cost
union all
select 'tony' as name, '2015-01-07' as orderdate, 50 as cost
union all
select 'jack' as name, '2015-01-08' as orderdate, 55 as cost
union all
select 'mart' as name, '2015-04-08' as orderdate, 62 as cost
union all
select 'mart' as name, '2015-04-09' as orderdate, 68 as cost
union all
select 'neil' as name, '2015-05-10' as orderdate, 12 as cost
union all
select 'mart' as name, '2015-04-11' as orderdate, 75 as cost
union all
select 'neil' as name, '2015-06-12' as orderdate, 80 as cost
union all
select 'mart' as name, '2015-04-13' as orderdate, 94 as cost) t
现在只要传入一份含有hive表数据的excel,使用下面python源代码便可以快速生成以上hive代码,再将这份hive代码拷贝到hive平台就可以建hive表了。直接上python代码:
import pandas as pd
def dfToSql(df, table_name='tmp_table', t='d'):
'''
输入:
DataFrame
表名
t: c for create, o for overwrite, d for default
输出:用union all拼接的建表语句
select 'xx' as xx, 'xx' as xx
union all
select 'xx' as xx, 'xx' as xx
'''
def isStr(row):
res = 'select '
last_col = list(row.index)[-1]
print(row.index)
for i in row.index:
if isinstance(row[i], int) or isinstance(row[i], float):
if i != last_col:
res += "{} as {}, ".format(row[i], i)
else:
res += "{} as {}".format(row[i], i)
else:
if i != last_col:
res += "'{}' as {}, ".format(row[i], i)
else:
res += "'{}'as {}".format(row[i], i)
return res
duohang = df.apply(lambda row: isStr(row), axis=1) # 关键句
sql = "\n union all \n".join(duohang) #duohang的类型是 Series类型
sql = sql.replace('nan', '')
if t == 'c':
head = 'drop table if exists {};\ncreate table {} as select * from ( \n'.format(table_name, table_name)
elif t == 'o':
head = 'insert overwrite table {} select * from ( \n'.format(table_name)
elif t == 'd':
head = 'select * from ( \n'
tail = ') t'
res = head + sql + tail
return res
df = pd.read_excel('ceshi.xlsx') #将excel表名放在这里
sql = dfToSql(df, 'analyst.fiona_20210802_liupu', 'c') # 填写上你即将要建的hive表的表名
sql_2 = sql.replace('-1', 'null')
with open('res.txt', 'w+', encoding='utf-8') as f: # res.txt就是你要拷贝到hive里进行建表的hive代码
f.write(sql_2)
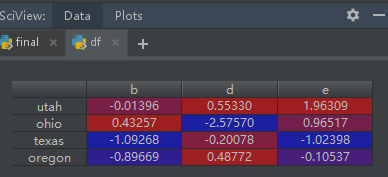
这个是Series类型的final:

下面我用一份更加简单的代码来解释上面的代码:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['utah', 'ohio', 'texas', 'oregon'])
def te(x):
print(x) # Name: oregon, dtype: float64
# '''
# b -0.878668
# d -0.213281
# e 0.946508
# '''
# print(x.index) # Index(['b', 'd', 'e'], dtype='object')
# print(x.index[1]) # d
# print(x['b']) # -0.8786
res = ''
for i in x.index:
if i != x.index[-1]:
res += 'select {} as {},'.format(x[i], i)
else:
res += 'select {} as {}'.format(x[i], i)
return res
final = df.apply(lambda x: te(x), axis=0)
'''
apply默认是一列列输入,这里用了axis=1就是变成一行行输入
如果没有加axis=1,那上面的x.index就是Index(['utah', 'ohio', 'texas', 'oregon'], dtype='object')
很简单的,就是一个索引
'''
print(type(final)) # final是series类型
'''
join的使用办法
li = ['a', 'b', 'r', 'we'] # list可以用join Series类型也可以用join
str = '-'
sql1 = str.join(li) 结果为:a-b-r-we
'''
str = '\n union all \n'
sql = str.join(final)
with open('D:/wow.txt', 'w') as f:
f.write('sql:')
f.write(sql)
这个是df: