前言
Hive是Facebook开源的,建立在Hadoop之上的的开源数据仓库系统,它关心与海量数据的离线分析,而不是去承担业务数据处理,注意这里Hive关心海量数据,在处理小数量数据,性能表现会非常糟糕。
Hive能将Hadoop文件转换为数据库表,并针对该表提供了类SQL的查询语言
Hive的核心是将HQL转换为MapReduce程序,再将MapReduce程序提交到Hadoop集群去执行,因此使用Hive,可以不用直接编写Hadoop的MapReduce程序,减少开发成本
数据仓库
数据库与数据仓库的区别
OLTP OLAP
OLTP联机事务处理,关注的是操作数据库的实时性,用于满足日常需求,在设计上,避免产生冗余数据,数据库是为了捕获数据
OLAP联机分析处理,描述的一般是数据库,一般保存的是历史数据,为决策者提供分析,有时候为了得到分析结果,数据冗余是有必要的,而数据仓库是为了分析数据。
数据仓库的分层架构

- 源数据(ODS):现有的一些数据,例如数据库数据
- 数据仓库(DW):由元数据通过ETL统一数据格式而来,E数据抽取,T数据转换,L数据加载
- 数据应用(DA或APP):对数据仓库中的数据,进行数据应用,前端能直接独去到的数据
数据模型
Hive的数据模型包括表、分区、分桶。
需要注意的是Hive表的数据是保存在HDFS上的,可通过hive-site.xml文件进行指定,而表结构相关的元数据是保存在RDBMS中的。
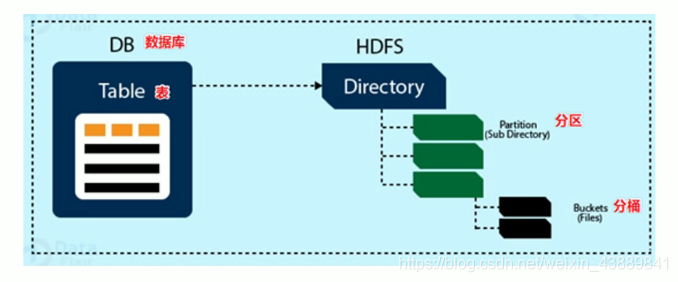
Hive也有默认数据库Default,其中有表A和表B,如果你自己也创建了数据库MYDB,那么其实在HDFS上的路径是这样的:
-
对于Default数据库,/{配置的路径}/A , /{配置的路径}/B
-
对于MYDB数据库的表,会是这样,/{配置的路径}/MYDB.db/表名
需要注意的是,Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大,鉴于以上原因,产生了分区表。
分区表
分区表怎么实现的呢? 事实上,分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。
这里说明一下分区表并 Hive 独有的概念,实际上这个概念非常常见。比如在我们常用的 Oracle 数据库中,当表中的数据量不断增大,查询数据的速度就会下降,这时也可以对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据存放到多个表空间(物理文件上),这样查询数据时,就不必要每次都扫描整张表,从而提升查询性能。
分桶表
分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。
同时 Hive 会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。
鉴于以上原因,Hive 还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。
分桶表会将指定列的值,例如根据编号ID进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中。
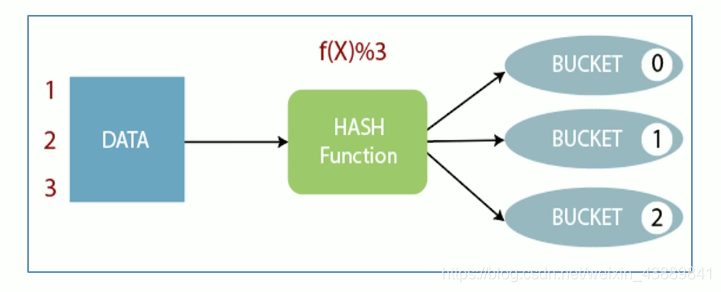
这样就实现了比根据字段细粒度更加小的分桶表。
元数据
元数据,即描述数据的数据,软件工程(张海藩)经典教材印象里应该也是这么定义的。
Hive元数据
在Hive中,对Hive中表、数据库等信息的描述,即Hive的元数据,是存在RDBMS中的,hive内置使用derby来存储元数据。
MetaStore
MetaStore是元数据服务,负责管理客户端对元数据的访问,由MetaStore与客户端交互,并由MetaStore去存取元数据。
Hive操作
Hive的语句写法与Mysql很像,区别在于Hive中的语句叫HQL。
?Hive插入数据方式底层是通过MapReduce程序执行的Job,所以插入一条数据相对于Mysql插入一条数据慢得多。
?Hive的核心是将结构化数据映射为表,可以把结构化的数据放入到表在HDFS存储目录,那么在查询表的时候就可以查到数据。但需要注意的是,在建表的时候需要类型指定尽可能与结构化数据类型一一对应,如果不对应,hive也会自动转换,但不一定保证成功。
除此之外,还需要指定结构化数据的分隔符,例如结构化数据中是以逗号来分割列的,那么建表的时候需要指定row format delimited fields terminated by ','。
总结
Hive与数据库还是有本质不同的,Hive是数据仓库,追求分析,而数据库则追求实时行。且Hive是存储在HDFS上的。
从粒度来从大到小,分别是表>分区>分桶