实验目的
(1)掌握Hadoop的伪分布式安装方法;
(2)理解HDFS在Hadoop体系结构中的角色;
(3)熟练使用HDFS操作常用的Shell命令;
(4)熟悉HDFS操作常用的Java API。
实验环境
操作系统:Linux(Ubuntu 18.04 LTS);
Hadoop版本:Hadoop 3.1.3;
JDK版本:1.8及11;
Java IDE:VSCode。
实验内容与完成情况
1、安装Linux系统(Ubuntu 18.04 LTS)

2、创建hadoop用户
执行
sudo useradd -m hadoop -s /bin/bash

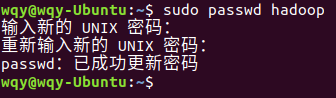
执行
sudo passwd hadoop
?执行
sudo adduser hadoop sudo
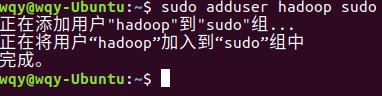
3、切换到hadoop用户
执行
sudo su - hadoop

4、更新APT
执行
sudo apt-get update

5、安装SSH,并配置SSH无密码登录
执行
sudo apt-get install openssh-server

显示openssh-server已经是最新版(1:7.6p1-4ubuntu0.4)
执行
ssh localhost

可以看到通过密码认证后,本地SSH登录成功,接下来开始配置SSH免密登录
执行
exit

执行
cd ~/.ssh/
![]()
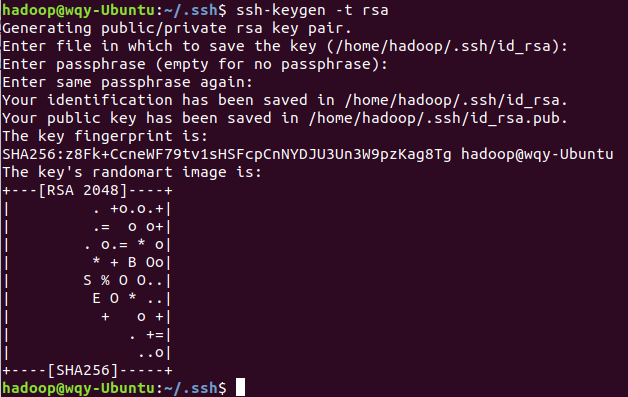
执行
ssh-keygen -t rsa
执行
cat ./id_rsa.pub >> ./authorized_keys
![]()
再次执行
ssh localhost
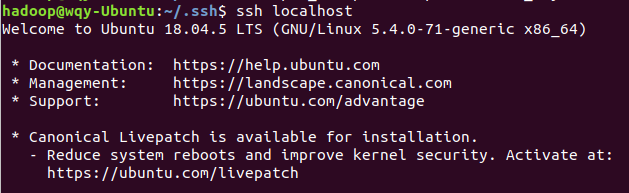
?可以看到,免密登录配置成功,没有出现输入密码的提示界面
6、安装Java环境
下载jdk-8u162-linux-x64.tar.gz
打开
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
选择文件并下载

?执行
sudo nautilus
以便以root权限打开文件浏览器

复制文件到/home/Downloads目录下
执行
cd /usr/lib
![]()
执行
sudo mkdir jvm

执行
cd ~/Downloads
![]()
执行
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm

执行
cd /usr/lib/jvm
![]()
执行
ls

可以看到,在/usr/lib/jvm目录下存在jdk1.8.0_162目录
执行
cd ~
![]()
执行
sudo gedit ~/.bashrc
在文件头添加了hadoop用户的环境变量并保存

执行
source ~/.bashrc
![]()
执行
java -version

查看到了安装的Java版本,说明Java已经安装成功
7、安装Hadoop,并检测是否安装成功
打开如下Hadoop官网链接下载Hadoop3.1.3安装文件
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
复制文件到/home/Downloads目录下
执行
sudo tar -zxf ~/Downloads/hadoop-3.1.3.tar.gz -C /usr/local

执行
cd /usr/local/
![]()
执行
sudo mv ./hadoop-3.1.3/ ./hadoop
![]()
执行
sudo chown -R hadoop ./hadoop
![]()
执行
cd hadoop
![]()
执行
./bin/hadoop version
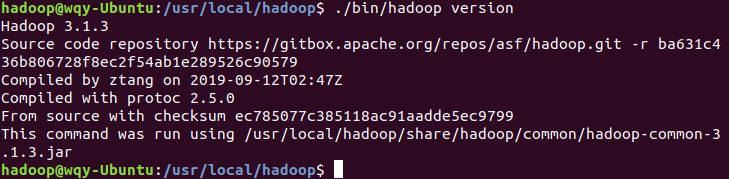
可以看到正确输出了安装的Hadoop版本信息,说明安装已经成功
8、搭建Hadoop伪分布式环境
编辑配置文件
执行
sudo gedit ./etc/hadoop/core-site.xml
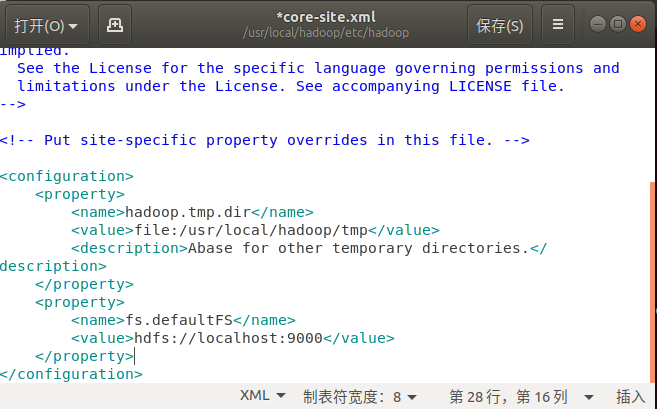
添加配置后保存
执行
sudo gedit ./etc/hadoop/hdfs-site.xml
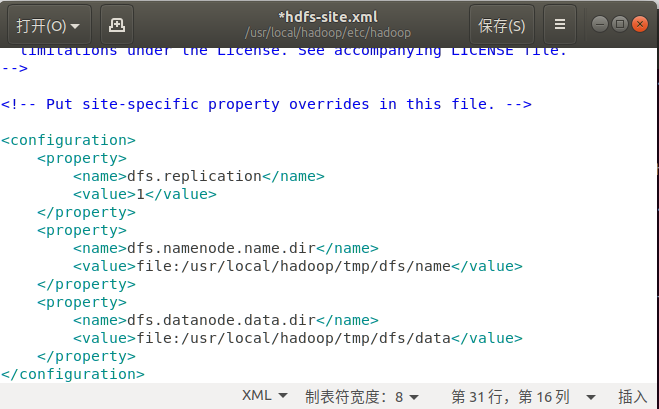
添加配置后保存
执行
cd /usr/local/hadoop
(由于已经处于该目录下,不重复执行了)
执行
./bin/hdfs namenode -format
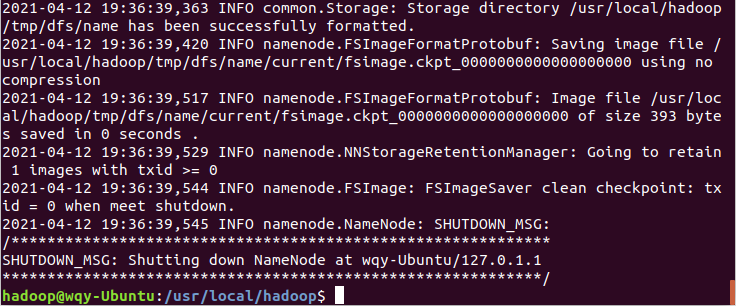
输出提示“Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted”可以看到NameNode 的格式化已经成功完成
9、使用hadoop用户登录Linux系统,启动Hadoop,并使用Web界面查看HDFS信息
执行
./sbin/start-dfs.sh

执行
jps
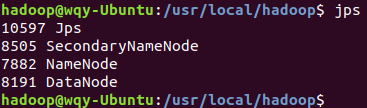
可以看到,列出了“NameNode”、”DataNode” 和 “SecondaryNameNode”进程,说明Hadoop已经成功启动
在Ubuntu虚拟机中的Chromium浏览器中输入http://127.0.0.1:9870/查看WEB界面
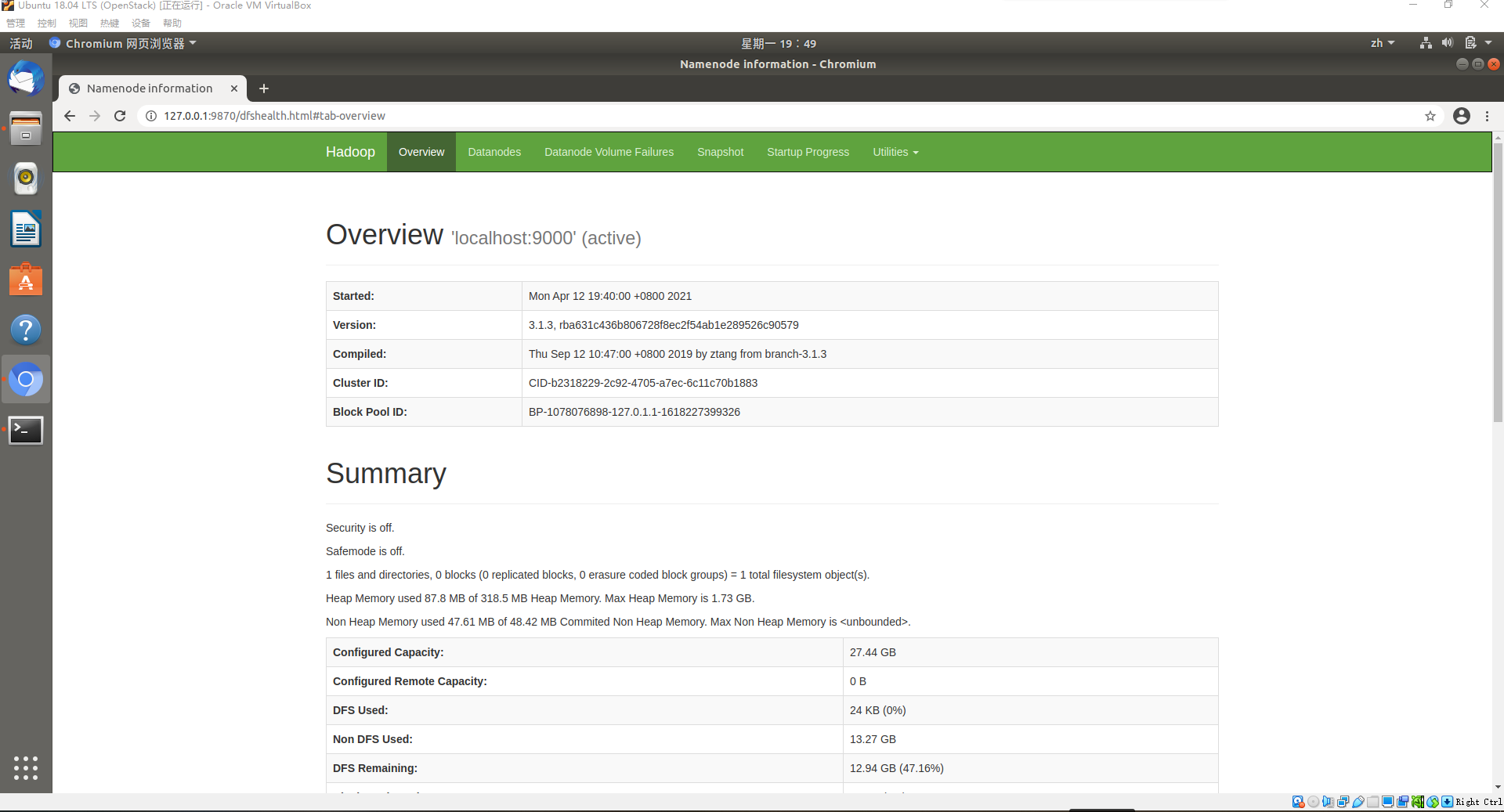
可以看到WEB界面正常显示,Hadoop的安装配置到此结束
10、运行Hadoop伪分布式实例
创建用户目录
执行
./bin/hdfs dfs -mkdir -p /user/hadoop
![]()
本地新建myLocalFile.txt文件
执行
sudo gedit /home/hadoop/myLocalFile.txt

粘贴相关内容并保存
11、利用Java API与HDFS进行交互
为方便起见,本次实验不使用Eclipse,转而使用VSCode的Remote SSH插件进行远程Java调用和编程
首先,下载并解压JDK11,即
OpenJDK11U-jdk_x64_linux_hotspot_11.0.10_9.tar.gz文件

执行
sudo tar -zxvf OpenJDK11U-jdk_x64_linux_hotspot_11.0.10_9.tar.gz -C /usr/local
?在VirtualBox中设置网络端口转发,将虚拟机的SSH(端口:22)转发到宿主计算机(端口:222)

在Windows系统中的PowerShell下进行测试
PowerShell中执行
ssh hadoop@127.0.0.1 -p 222
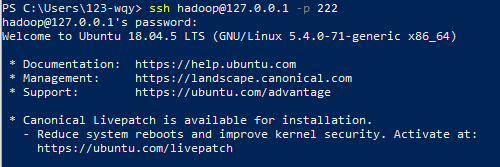
可以看到,连接成功,输入hadoop用户的密码后顺利连接到了虚拟机
为使连接过程更加顺畅,在Windows上配置对Linux虚拟机的SSH免密登录
首先,使用已有的公钥,将其添加到/home/Hadoop/.ssh/authorized_keys
保存后使用WinScp进行登录测试

可以看到,登录成功
在VSCode中安装remote SSH插件
添加主机
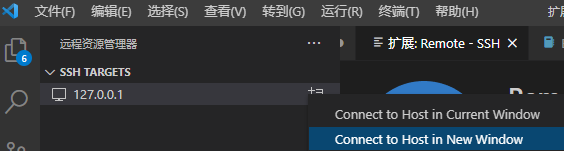
点击侧边栏,再点击“+”号,输入“ssh hadoop@127.0.0.1 -p 222”并回车确认

随后,选择第一个配置文件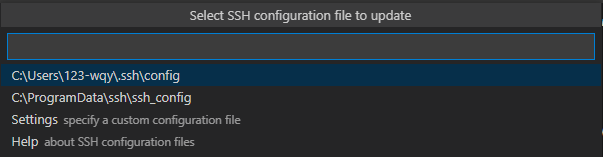
?点击“在新窗口中打开”

出现错误,查看日志中出现提示“Bad owner or permissions”,猜测是如Linux下的.ssh文件夹权限问题,以管理员身份启动VSCode,问题依旧存在,没有得到解决
尝试对Windows用户目录下的.ssh文件夹执行“管理员取得所有权”
随后点击“Retry”
进入界面如下

点击“打开文件夹”,默认选择/home/hadoop,确认即可
随后弹出界面如下

点击“新建文件夹”,输入文件夹名称,此处设置为“HDFS”
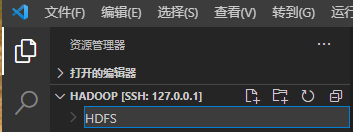
随后点击右侧“Welcome”窗口,选择“create a New Project”

在弹出窗口中选择“No build tools”

选择刚刚创建的文件夹“HDFS”

输入项目名称,此处设置为“Hadoop”

弹出窗口如下
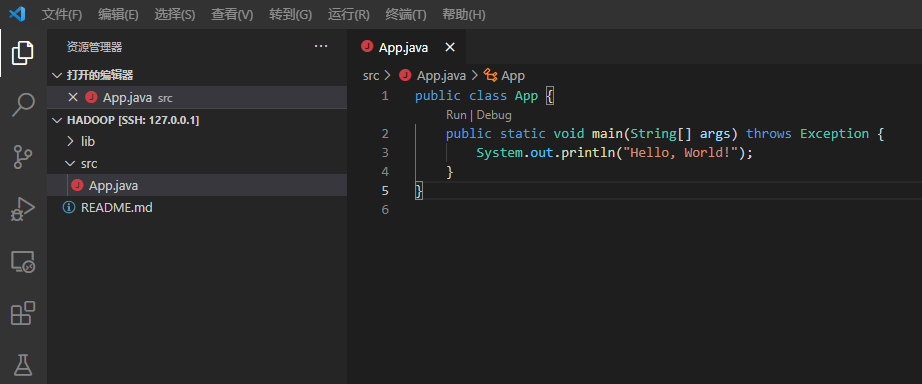 点击“Run”
点击“Run”
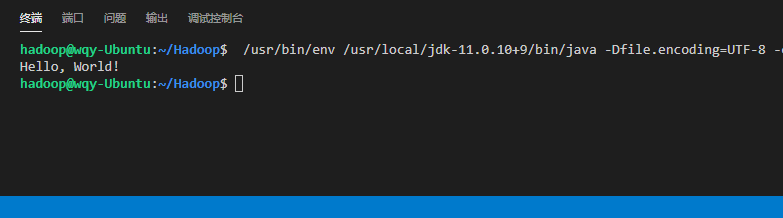
可以看到下方的终端中显示了程序运行的结果,使用VSCode的Java远程开发环境配置完成
随后,改写App.java的内容为实验内容,如下
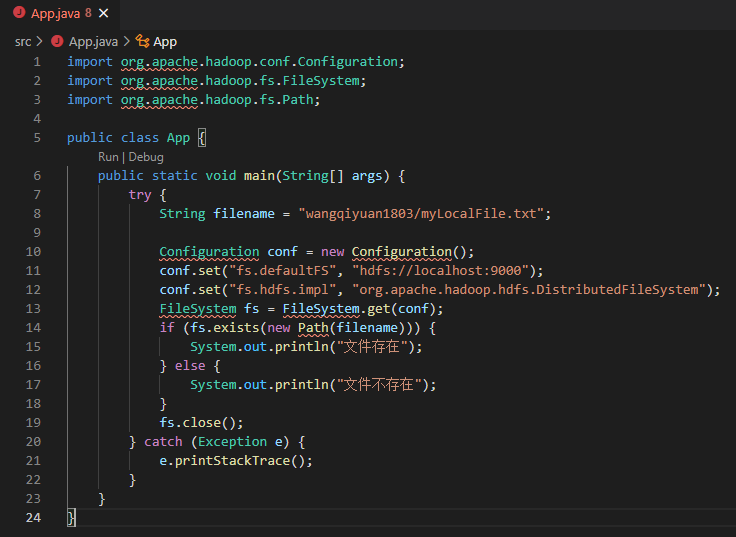
可以看到,文件中出现大量红色波浪线,点击“Run”后提示错误如下

原因为没有导入项目需要使用的JAR包
点击侧边栏,新建“.vscode”文件夹
在“.vscode”文件夹下继续新建文件“settings.json”?
?
写入如下配置并保存
 ?
?
随后,回到App.java文件,再次点击“Run”

可以看到,程序输出了“文件存在”的提示
若修改App.js的“filename”变量的值,如改为
String filename = "wangqiyuan1803/myLocalFile1.txt";
再次点击“Run”,则运行结果如下

说明成功实现了Java API与HDFS的交互,实验内容到此结束
出现的问题与解决方案
1、打开Ubuntu的SSH免密登录后仍需要输入密码
解决方案:为确保连接成功,需要给hadoop用户授予/.ssh文件夹及公钥文件权限,定位到~/.ssh文件夹下,执行chmod 600 authorized_keys和chmod 700 ~/.ssh即可。
2、双击打开的文件浏览器对/home目录没有修改的权限
解决方案:执行sudo nautilus即可以root权限打开文件浏览器,此时操作不再受限,但文件浏览器关闭后需要手动在终端结束进程。
3、Windows系统通过SSH连接Ubuntu时遇到“无法打开连接问题”
解决方案:查看C:\Users\“用户名”\.ssh文件夹的权限,对该文件夹执行“管理员取得所有权”的指令即可。
4、编译Java文件时遇到无法导入包的错误
解决方案:使用的IDE没有默认导入Hadoop的Java API接口所使用的jar包,需要手动在工程的设置中添加(本实验中通过在.vscode文件夹下新建settings.json文件来进行配置)。
5、VSCode编译时报错,找不到Java环境
解决方案:由于VSCode是通过远程连接的方式进行开发,因此需要手动指定Java环境,由于其已不再支持默认的JDK1.8,因此需要手动安装更高版本的JDK,实验中以JDK11为例,解压后再设置相应目录即可。
6、将虚拟机关机后再打开时HDFS不能使用
解决方案:由于HDFS不像OpenStack一样开机自启,因此开机后要手动执行./sbin/start-dfs.sh启动Hadoop。
实验总结
通过本次Hadoop的安装与HDFS基础实验,我进一步熟悉了Ubuntu的基本使用以及Linux系统的各种文件操作指令,对于分布式存储中的重要工具――Hadoop的使用及HDFS的基本操作有了更多的了解。
尽管我先前没有选修大数据课程,但通过详细的安装教程及同学之间的相互交流,我顺利地完成了Hadoop的安装和使用,并通过执行指令从HDFS上增删改查文件,实验达到了预期的效果。
实验中还对Hadoop的Java API进行了基础的操作,这也让我对于Linux的Java开发环境配置、借助Remote SSH的VSCode远程开发及SSH登录验证的相关配置和使用更加熟悉。