解耦利器:MQ
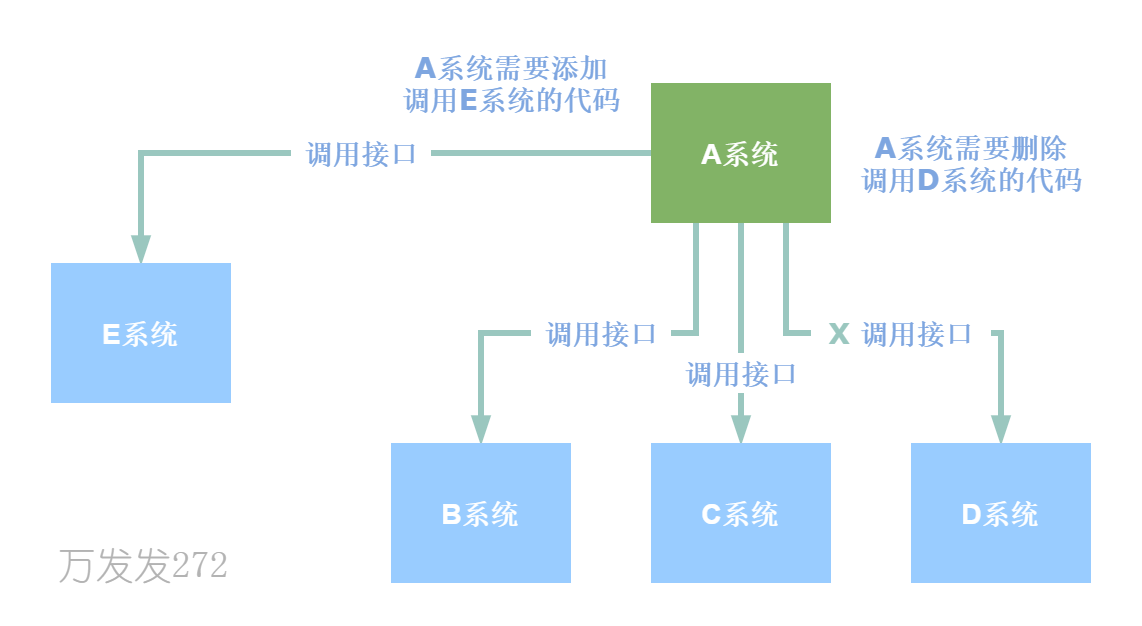
A系统发送数据到BCD系统,明明需要数据的是BCD,更改代码却需要在A系统实现,架构中出现了反向依赖
使用MQ,A系统产生数据发送到MQ里,哪个系统需要数据则去MQ消费,如果不需要就取消订阅。A不需要考虑给谁发消息
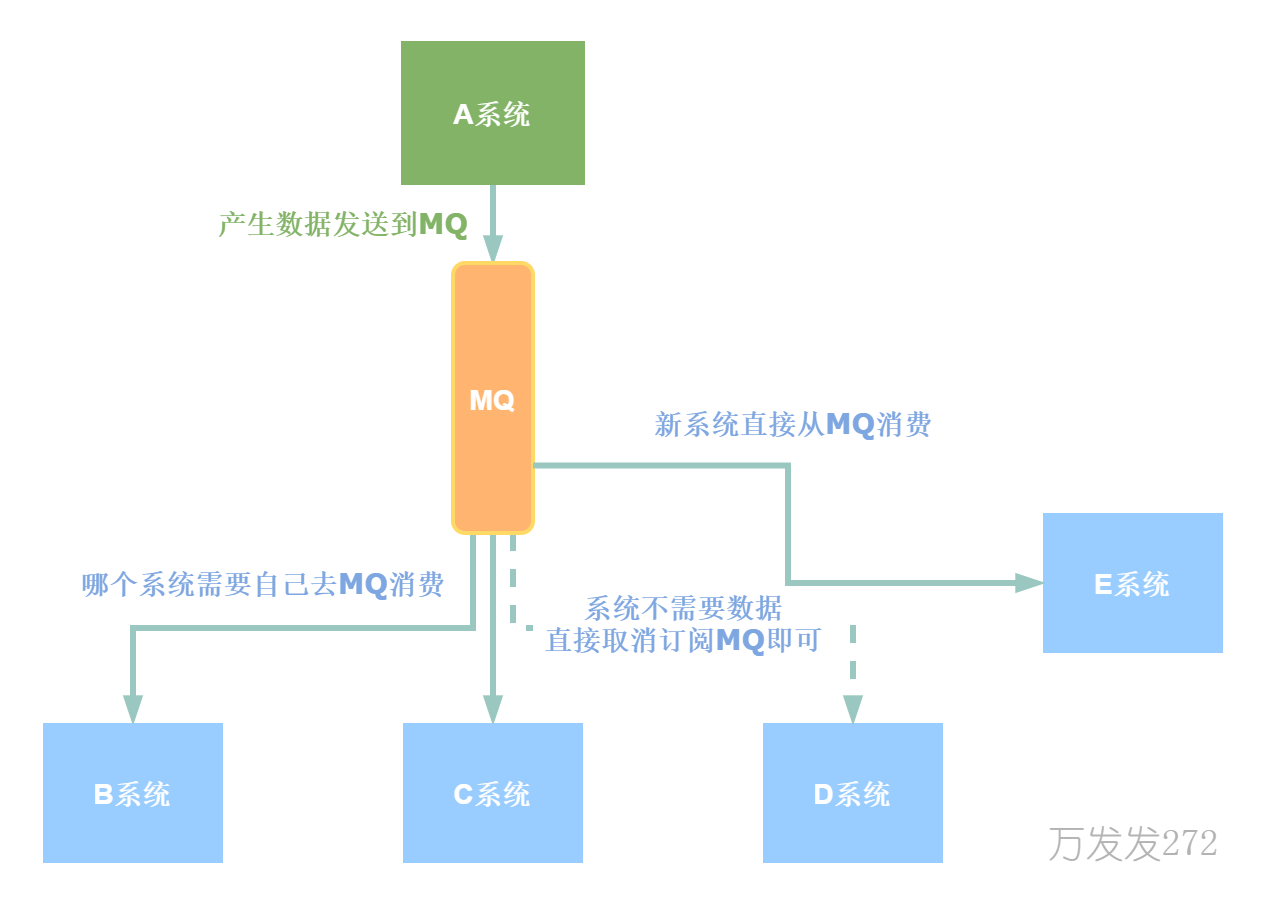
通过MQ,A 系统就跟其它系统解耦了
异步通信
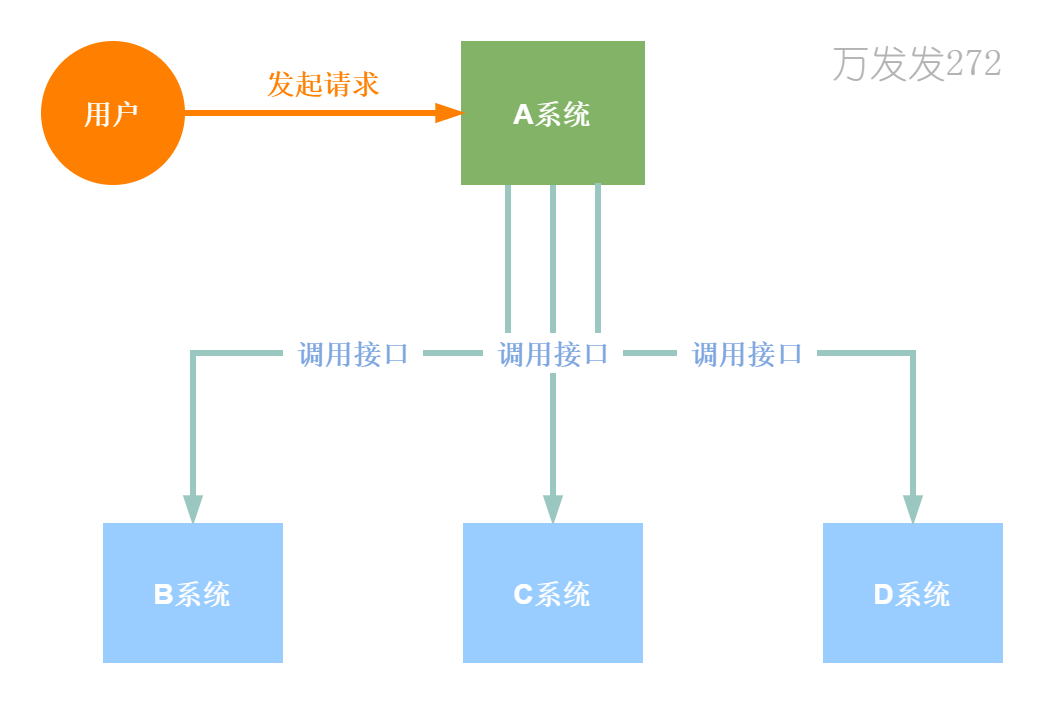
上游不关心下游执行结果,用户请求发送消息到MQ直接返回。
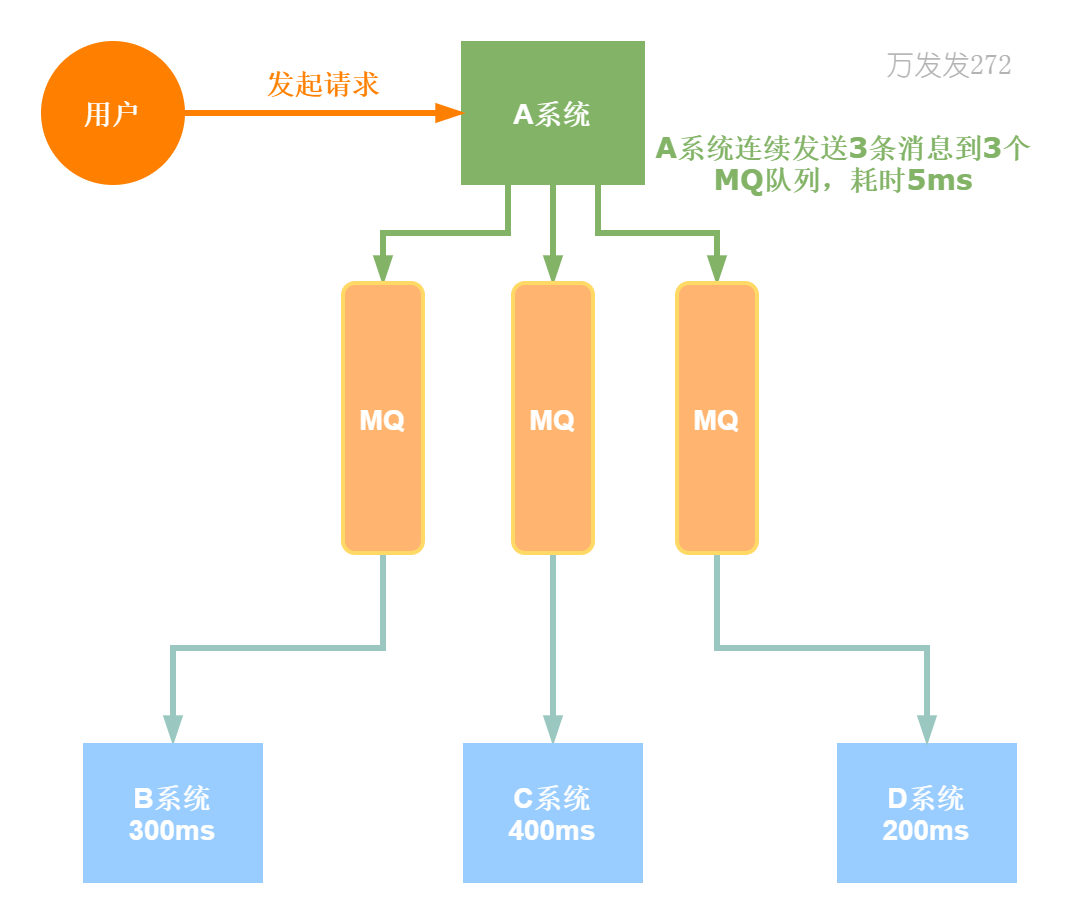
削峰
高峰期不论发送多少请求系统只处理MQ放行请求,减轻底层DB压力
MQ的高可用
RabbitMQ的镜像集群模式
元数据和队列(queque)都在多个实例上,每个RabbitMQ节点都有queque的完整镜像
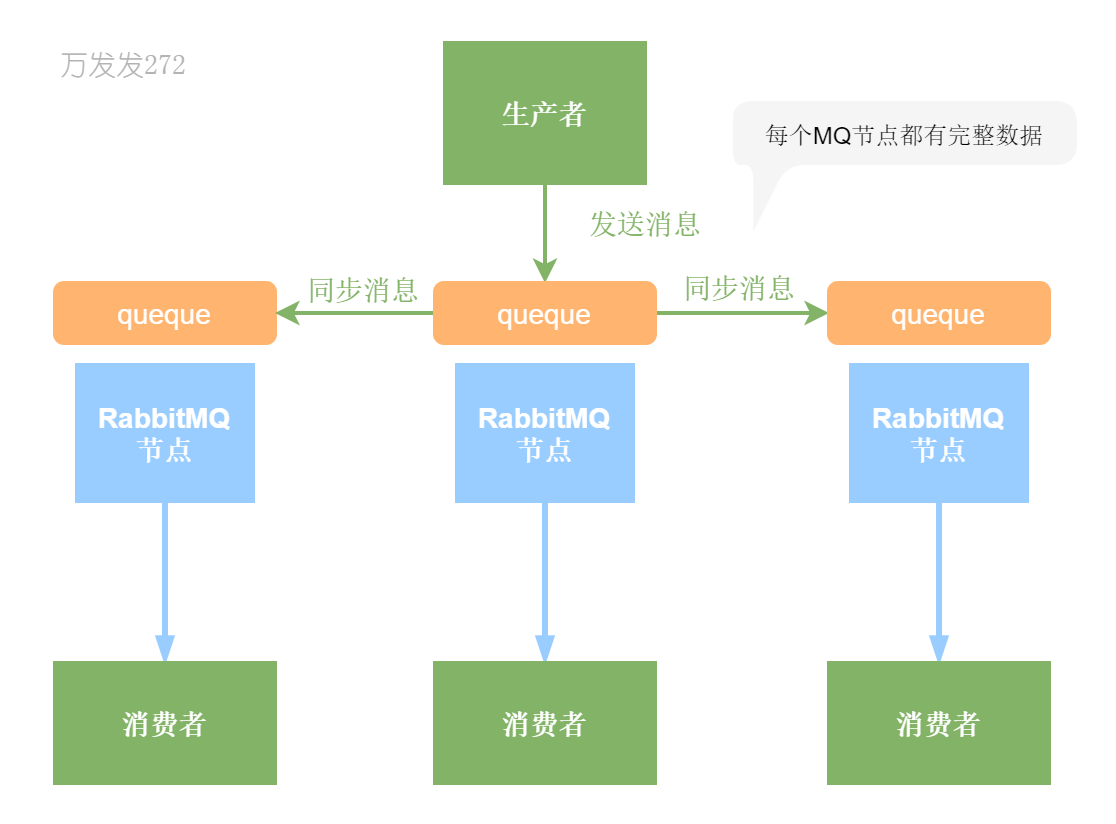
优点:高可用,不怕宕机
缺点:性能开销大,非分布式,没有扩展性
Kafka的高可用
Kafka由多个节点(broker)组成,topic由partition组成,存在于不同节点上,topic分散在多个机器上,Kafka是一个天然的分布式消息队列
RabbitMQ一个queque都是放在一个节点里的,不是分布式
Kafka在0.8以前没有副本,一个broker宕机=所有partition消失
Kafka 0.8以后提供了高可用机制(High Availability),就是副本机制(replica),每个partition的数据都同步到其他机器上,形成多个副本,所有副本选举一个领袖(leader),消费与生产者只和leader副本交互,leader会把数据同步到其他副本上(保证了数据的一致性,系统简单高效)
如果一个broker宕机,副本就重新选举leader,保证高可用
写数据时,生产者只写入leader副本,其他副本自动从leader中拉取数据,一旦所有数据同步完成,就返回确认字符(ack)给leader,leader再返回成功消息给生产者
消费时,只从leader读取数据,但是只有所有副本同步成功,并且返回确认字符,消费者才能读取到
保证消息必达
-
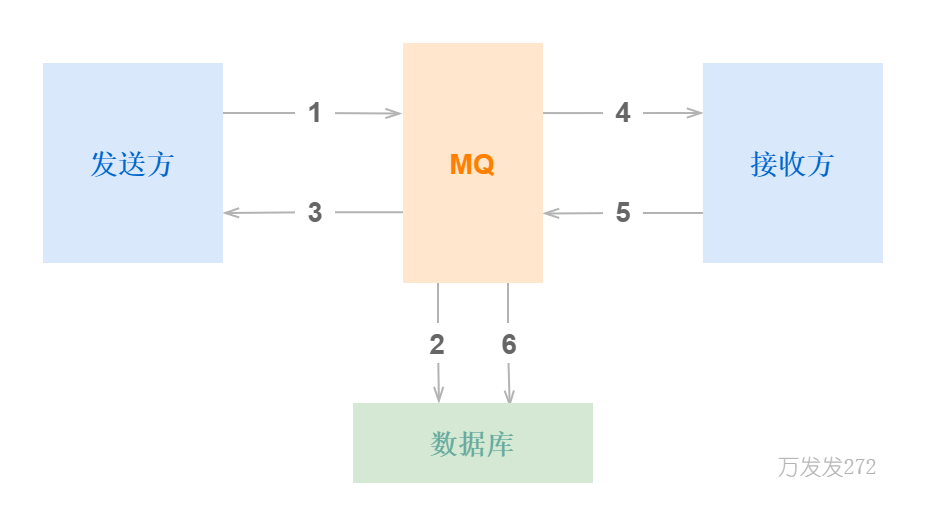
发送方调用SendMsg接口,把消息发送给消息队列
-
消息队列让消息落地,写入数据库,落地=成功
-
消息队列调用SendCallback接口,把确认字符返回给发送方
-
MQ调用RecvCallback接口,把消息发送给接收方
-
接收方调用SendAck,回复MQ
-
MQ接收到确认字符ACK,将已经落地的消息删除
设置一个timer,当消息超时或者丢失时,timer会重发消息,直到收到消息落地的消息,如果重传N次还没收到,就返回发送失败
为了保证消息必达:
- 收到消息先落地
- 通过超时,重传,确认保证消息必达
对于RabbitMQ,生产者需要开启confirm模式,每次写消息生产者都会分配一个唯一id,发送到RabbitMQ中,RabbitMQ开启消息持久化,将消息持久化到磁盘中,消费者关闭自动ack机制,手动回传确认消息
MQ的幂等性
为了保证消息必达,可能导致接收方或发送方收到重复消息
所以必须保证消息总线的幂等性
如果消息队列返回确认字符时消息丢失,发送端会重发消息
为了避免数据重复落地,MQ需要生成内部消息ID
- 全局唯一
- MQ生成,业务无关
- MQ保证幂等
如果接收方返回确认字符时消息丢失,消息队列会重发消息
为了保证业务幂等性,业务消息中必须有业务ID
- 同一个业务,全局唯一
- 发送方生成,业务相关
- 消费方判重,保证幂等
生产者发送每条数据时先生成一个全局唯一的订单ID,到达消费者之前先去Redis中查一下之前是不是消费过,没消费就写入Redis,消费了就不处理了