Ubuntu18.04下的Hadoop3.2.2详细安装与分布式集群搭建
一:jdk安装
我喜欢在root下使用命令,以下都是在root下操作的
-
使用
which Java命令查看是否有jdk,没显示说明没有,我用的是jdk1.8的版本

-
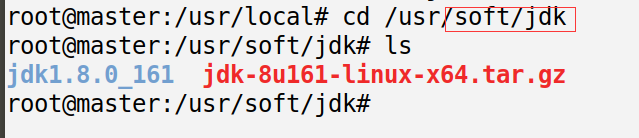
红框里是我自己创建的文件夹,把下载好的jdk放到这个文件夹下解压
解压命令tar -zxvf jdk1.8.0_161
-
编辑文件 使用命令
vim /etc/profile
在最下面加入这三行
export JAVA_HOM=E/usr/soft/jdk/jdk1.8.0_161 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:/usr/soft/jdk/jdk1.8.0_161/bin

:wq保存成功后,一定要在命令行敲source /etc/profile -
使用
Java -version命令就可以查看到java版本信息了

二:Hadoop安装
1.同上面一样,进入此文件夹/usr/soft/ ,创建一个hadoop文件夹,把压缩包和解压好的文件放入
解压命令tar -zxvf hadoop-3.2.2.tar.gz

三:集群环境搭建
1.先创建3台虚拟机,第一个为主机,其余为子机,我选择直接右键克隆出其余两台机器node1和node2。
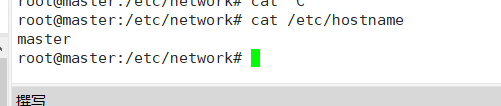
查看主机名,如果想改名字可用 vim /etc/hostname ,其余两台同样的操作
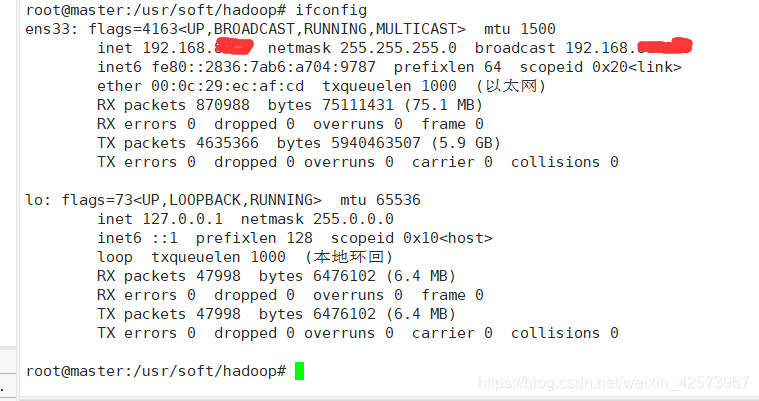
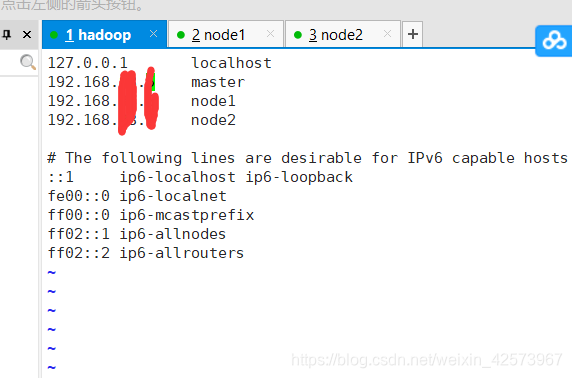
2. hosts映射3台机器,先查看IP地址,分别用ifconfig命令查看三台主机的IP地址
三台主机修改映射文件,使用vim /etc/hosts编辑文件,在第二行加入红框内自己的三台主机的IP地址和主机名,然后用cat /etc/hosts查看是否编辑成功
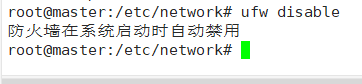
3.防火墙关闭,Ubuntu下防火墙关闭命令是ufw disable
4.进行三台主机SSH免密登录,防止以后上传文件和启动脚本,要不停的输入密码。只要打通主机(master)和其余两台子机。
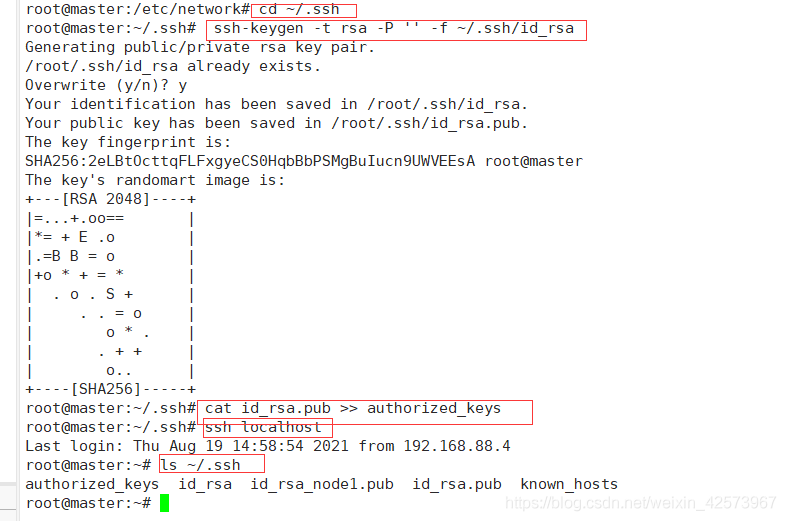
1.cd ~/.ssh 进入ssh目录下(这五步只在主机master操作)
2. ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa 产生公钥私钥,第一次生成不停的按回车就可以
3.cat id_rsa.pub >> authorized_keys 将产生的SSH Key放到许可证文件下
4.ssh localhost 验证是否成功(不用输入密码就是成功)
5.ls ~/.ssh查看文件
在node1和node2下分别执行下面操作
1.cd ~/.ssh 进入ssh目录下
3. ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa 产生公钥私钥
4. scp id_rsa.pub root@master:~/.ssh/id_rsa_node1.pub (node1下)
scp id_rsa.pub root@master:~/.ssh/id_rsa_node2.pub (node2下)
如果出现了lost connection情况,换成ip地址 scp id_rsa.pub root@192.168.x.x(主机):~/.ssh/id_rsa_node1.pub
回到主机master,依次执行下面命令,先进入目录cd ~/.ssh
cat id_rsa_node1.pub >> authorized_keyscat id_rsa_node2.pub >> authorized_keysrm -rf id_rsa_node1.pubrm -rf id_rsa_node2.pubscp authorized_keys root@node1:~/.ssh/authorized_keys这两步和上面一样,报错换成IP地址(node1和node2)scp authorized_keys root@node2:~/.ssh/authorized_keys
开始在主机master下分别输入ssh node1ssh node2验证是否成功,不用输入密码就是成功
5.接下来要开始配置五个文件了
1.进入自己安装Hadoop文件下,cd /usr/soft/hadoop/hadoop-3.2.2/etc/hadoop,配置文件都是在此目录下
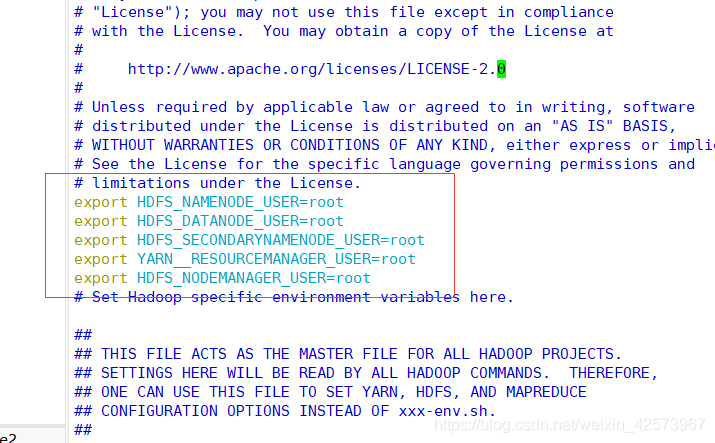
2.编辑文件vim hadoop-env.sh,在此文件下加入以下
export JAVA_HOME=/usr/soft/jdk/jdk1.8.0_161
export HADOOP_HOME=/usr/soft/hadoop/hadoop-3.2.2
最下面加入这些
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN__RESOURCEMANAGER_USER=root
export HDFS_NODEMANAGER_USER=root

3.vim core-site.xml,加入以下配置
<configuration>
<!-- 指定集群的文件系统类型:分布式文件系统 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定临时文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/soft/hadoop/hadoop-3.2.2/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<!-- 在web UI访问hdfs使用的用户名 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
4.vim hdfs-site.xml,加入以下配置
<configuration>
<!-- 文件切片的副本个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定namenode的访问地址和端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<!-- 指定namenode元数据的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/soft/hadoop/tmp/dfs/name1,file:///usr/soft/hadoop/tmp/dfs/name2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>/usr/soft/hadoop/tmp/dfs/name
<value>file:///usr/soft/hadoop/tmp/dfs/data1,file:///usr/soft/hadoop/tmp/dfs/data2</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
5.vim mapred-site.xml,加入以下配置
<configuration>
<!-- 指定分布式计算使用的框架是yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MR Map Task 环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<!--MR ReduceTask环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<!--MR App Master环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
6.vim yarn-site.xml,加入以下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--每个容器请求最大内存资源(MB)-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!--每个容器请求最小内存资源(MB)-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!--虚拟内存与物理内存之间的比率-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
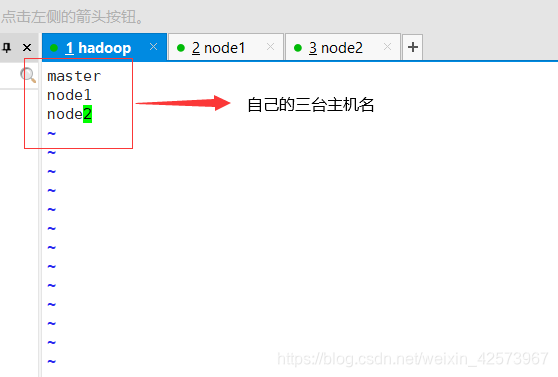
7.vim workers 一键启动时需要,要一行一个
8.在主机master下将Hadoop安装包同步到其他两台主机上
1.cd /usr/soft/hadoop
2.scp -r hadoop-3.2.2 root@node1:/usr/soft/hadoop
3.scp -r hadoop-3.2.2 root@node2:/usr/soft/hadoop (根据自己的目录)
9.编辑文件 使用命令vim /etc/profile
依旧在最下面加入三行
export HADOOP_HOME=/usr/soft/hadoop/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export $HADOOP_COMMON_HOME=$HADOOP_HOME
修改后的环境变量同步到其他两台机器
1.scp /etc/profile root@node1:/etc/
2.scp /etc/profile root@node2:/etc/
:wq保存成功后,一定要在命令行敲 source /etc/profile
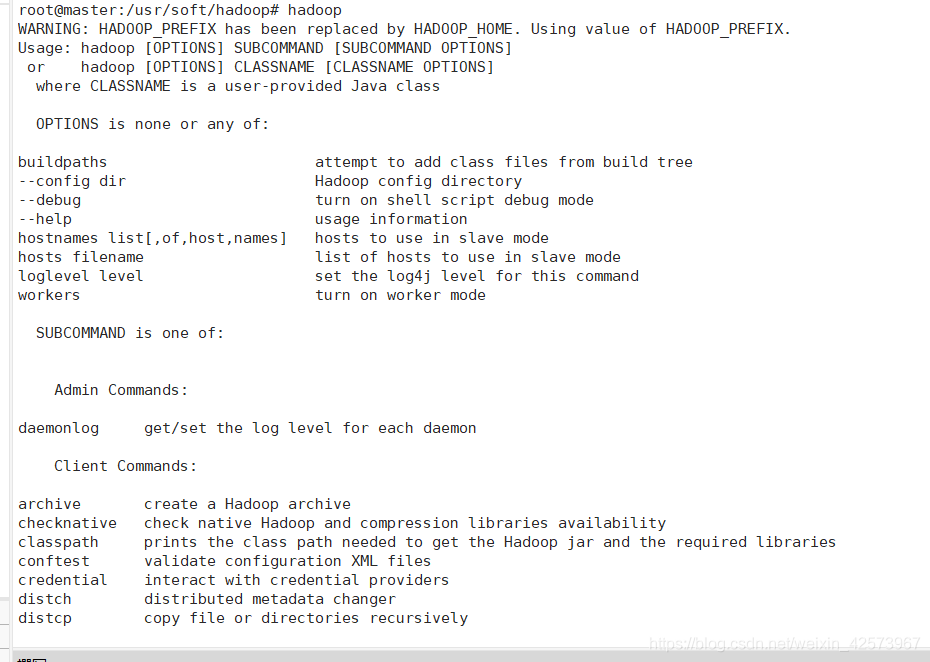
在三台机器分别敲hadoop,看看有没有成功,出现下面页面是成功
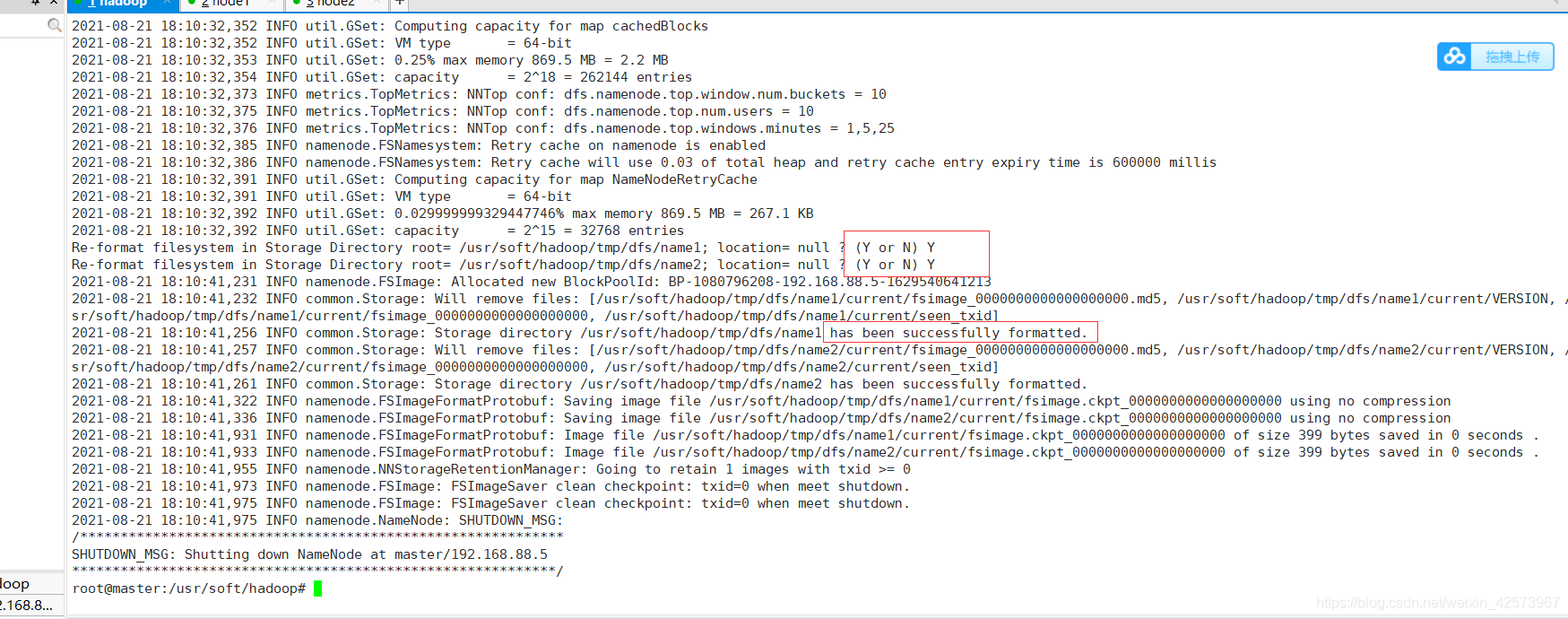
10.hafs首次启动必须必须进行格式化操作,使用命令hdfs namenode -format进行格式化,要输入大写的Y,有下面那个红框就代表格式化成功。只需要初始化一次,后续不再需要。
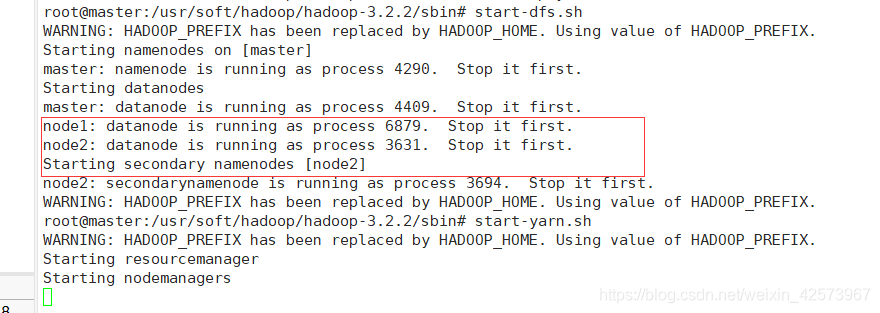
11.在三台机器分别使用start-all.sh命令启动集群,也可依次输入start-dfs.sh和start-yarn.sh,下面是启动成功
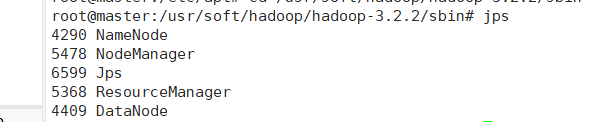
12.在三台机器使用jps命令查看是否启动成功,
主机(master)会出现这五个进程
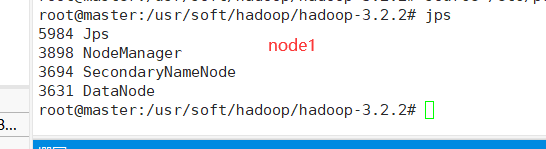
node1出现下面四个进程
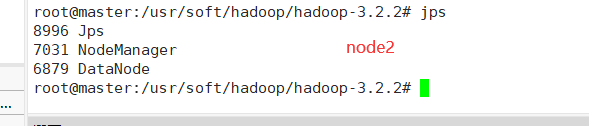
node2出现下面四个进程
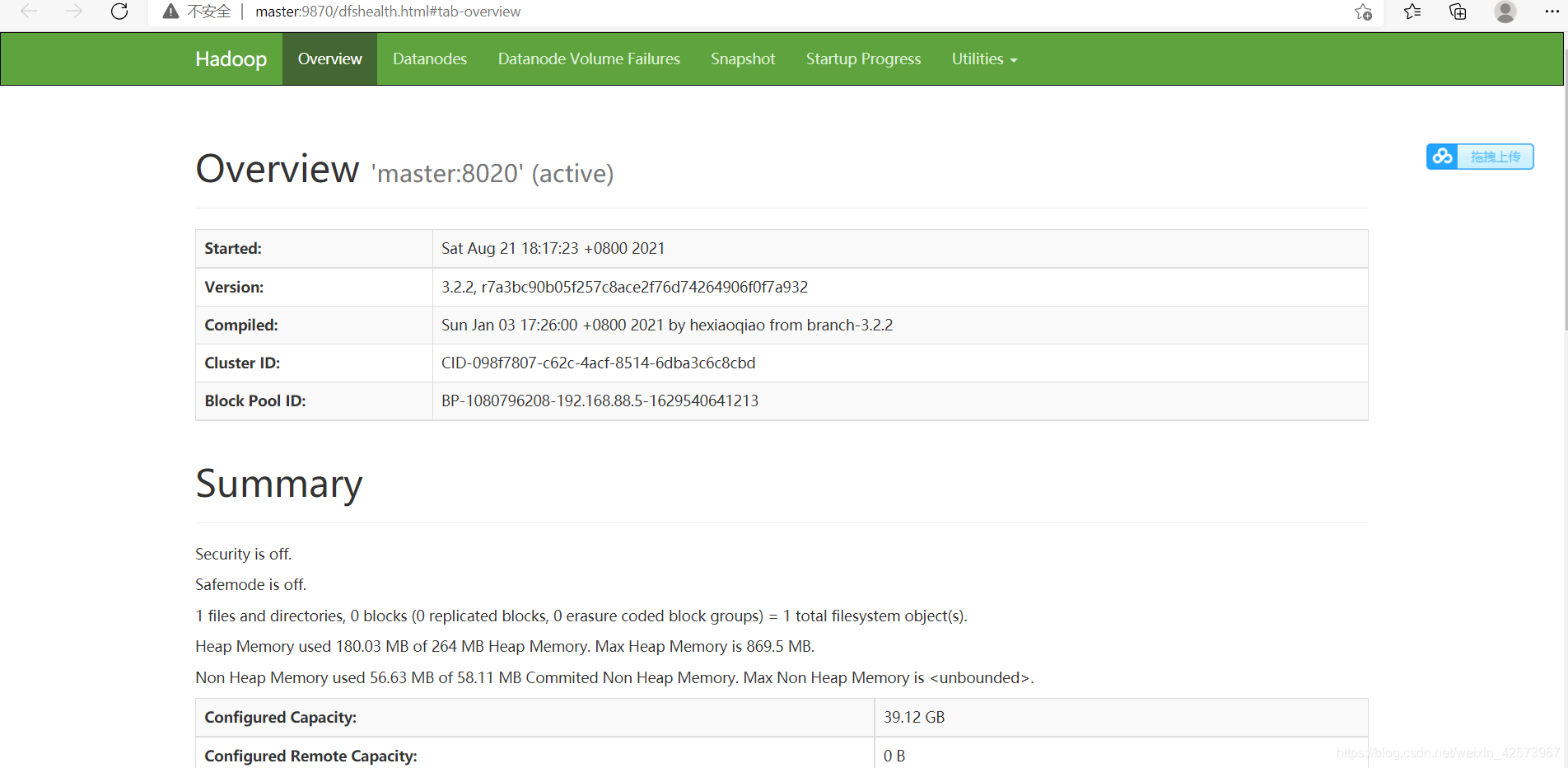
四:网页验证
转到此页面 http://master:9870/,出现下面情况,代表成功
转到http://master:8088/出现下面界面
以上就是全部成功了,下面是自己的报错点
五:报错点
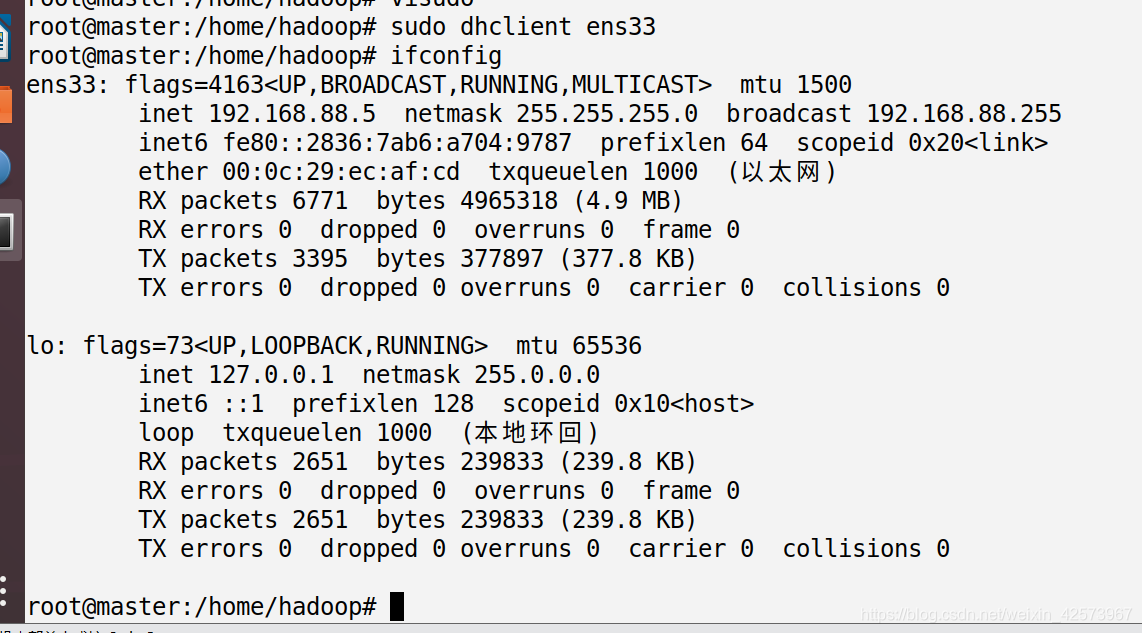
- 有网卡没IP地址,使用
sudo dhclient ens33命令,然后再查看
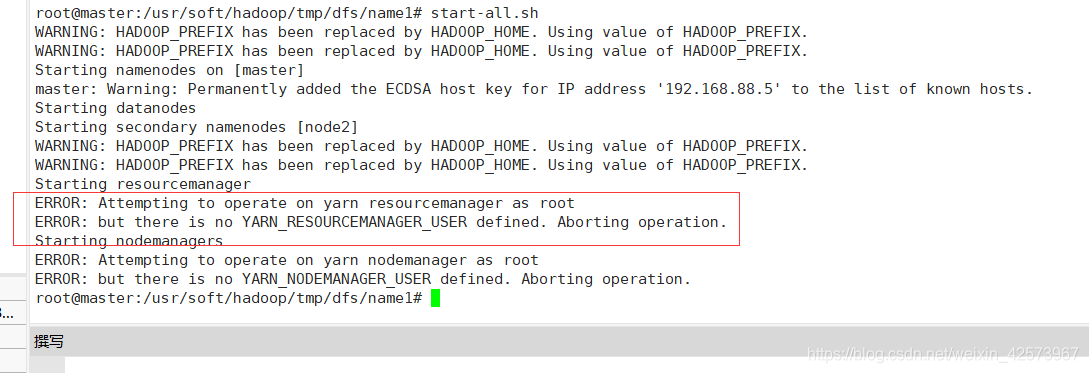
- 启动集群时出现ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
一般resourcemanager和nodemanager报错,就是yarn文件有问题
解决方法
1.进入下面文件cd /usr/soft/hadoop/hadoop-3.2.2/sbin
2.在vim start-yarn.sh和vim start-yarn.sh开头第二行下加入下面几行代码后,再重新启动集群
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.如果jps出现command jps not found,使用一次命令source /etc/profile,在进行jps操作。
.