flink sql 连接kafka解析avro数据
flink sql 连接kafka解析avro数据
因为工作需要,需要写FlinkSqlClient解析avro数据,但是网上例子很少,最后在看到一位老哥用debug方式排查问题,我这里也用了相同方式,才找到问题所在 。
我用的flink 版本为 flink-1.12.2-bin-scala_2.12
查看avro的schema
{
"type" : "record",
"name" : "KafkaAvroMessage",
"namespace" : "xxx",
"fields" : [ {
"name" : "transactionId",
"type" : "string"
}, {
"name" : "opType",
"type" : "string"
}, {
"name" : "schemaName",
"type" : "string"
}, {
"name" : "tableName",
"type" : "string"
}, {
"name" : "columnInfos",
"type" : {
"type" : "map",
"values" : {
"type" : "record",
"name" : "ColumnInfo",
"fields" : [ {
"name" : "oldValue",
"type" : [ "null", "string" ],
"default" : null
}, {
"name" : "newValue",
"type" : [ "null", "string" ],
"default" : null
}, {
"name" : "name",
"type" : "string"
}, {
"name" : "isKeyColumn",
"type" : "boolean"
}, {
"name" : "type",
"type" : "string"
} ]
}
}
}, {
"name" : "timeStamp",
"type" : "string"
}, {
"name" : "numberOfColumns",
"type" : "int"
}, {
"name" : "processedTimeStamp",
"type" : "long"
}, {
"name" : "schemaVersion",
"type" : [ "null", "string" ],
"default" : null
}, {
"name" : "rba",
"type" : "long"
}, {
"name" : "seqNo",
"type" : "long"
},
{
"name" : "domainName",
"type" : "string",
"default" : ""
} ]
}
写flink sql 报错
拿到avro 按照flink sql 官网写sql(开始写的错误sql我就不贴出来了后面会写注意的点),会爆出如下错误
Exception in thread "main" java.lang.RuntimeException: Failed to fetch next result
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:109)
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.hasNext(CollectResultIterator.java:80)
at org.apache.flink.table.planner.sinks.SelectTableSinkBase$RowIteratorWrapper.hasNext(SelectTableSinkBase.java:117)
at org.apache.flink.table.api.internal.TableResultImpl$CloseableRowIteratorWrapper.hasNext(TableResultImpl.java:350)
at org.apache.flink.table.utils.PrintUtils.printAsTableauForm(PrintUtils.java:149)
at org.apache.flink.table.api.internal.TableResultImpl.print(TableResultImpl.java:154)
at com.stubhub.wyane.flink.avro.avroTest4.main(avroTest4.java:50)
Caused by: java.io.IOException: Failed to fetch job execution result
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.getAccumulatorResults(CollectResultFetcher.java:169)
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.next(CollectResultFetcher.java:118)
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:106)
... 6 more
Caused by: java.util.concurrent.ExecutionException: org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1928)
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.getAccumulatorResults(CollectResultFetcher.java:167)
... 8 more
Caused by: org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:144)
at org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:117)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
at java.util.concurrent.CompletableFuture.uniApplyStage(CompletableFuture.java:628)
at java.util.concurrent.CompletableFuture.thenApply(CompletableFuture.java:1996)
at org.apache.flink.runtime.minicluster.MiniClusterJobClient.getJobExecutionResult(MiniClusterJobClient.java:114)
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.getAccumulatorResults(CollectResultFetcher.java:166)
... 8 more
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:118)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:80)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:233)
at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:224)
at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:215)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:669)
at org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:89)
at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:447)
at sun.reflect.GeneratedMethodAccessor13.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:305)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:212)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction.applyOrElse(PartialFunction.scala:127)
at scala.PartialFunction.applyOrElse$(PartialFunction.scala:126)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:175)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176)
at akka.actor.Actor.aroundReceive(Actor.scala:517)
at akka.actor.Actor.aroundReceive$(Actor.scala:515)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: java.io.IOException: Failed to deserialize Avro record.
at org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:101)
at org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:44)
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82)
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:113)
at org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.partitionConsumerRecordsHandler(KafkaFetcher.java:179)
at org.apache.flink.streaming.connectors.kafka.internals.KafkaFetcher.runFetchLoop(KafkaFetcher.java:142)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:826)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:263)
Caused by: java.lang.ArrayIndexOutOfBoundsException: 20
at org.apache.flink.avro.shaded.org.apache.avro.io.parsing.Symbol$Alternative.getSymbol(Symbol.java:460)
at org.apache.flink.avro.shaded.org.apache.avro.io.ResolvingDecoder.readIndex(ResolvingDecoder.java:283)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:187)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:259)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:247)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:179)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:160)
at org.apache.flink.avro.shaded.org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:153)
at org.apache.flink.formats.avro.AvroDeserializationSchema.deserialize(AvroDeserializationSchema.java:139)
at org.apache.flink.formats.avro.AvroRowDataDeserializationSchema.deserialize(AvroRowDataDeserializationSchema.java:98)
... 9 more
Process finished with exit code 1
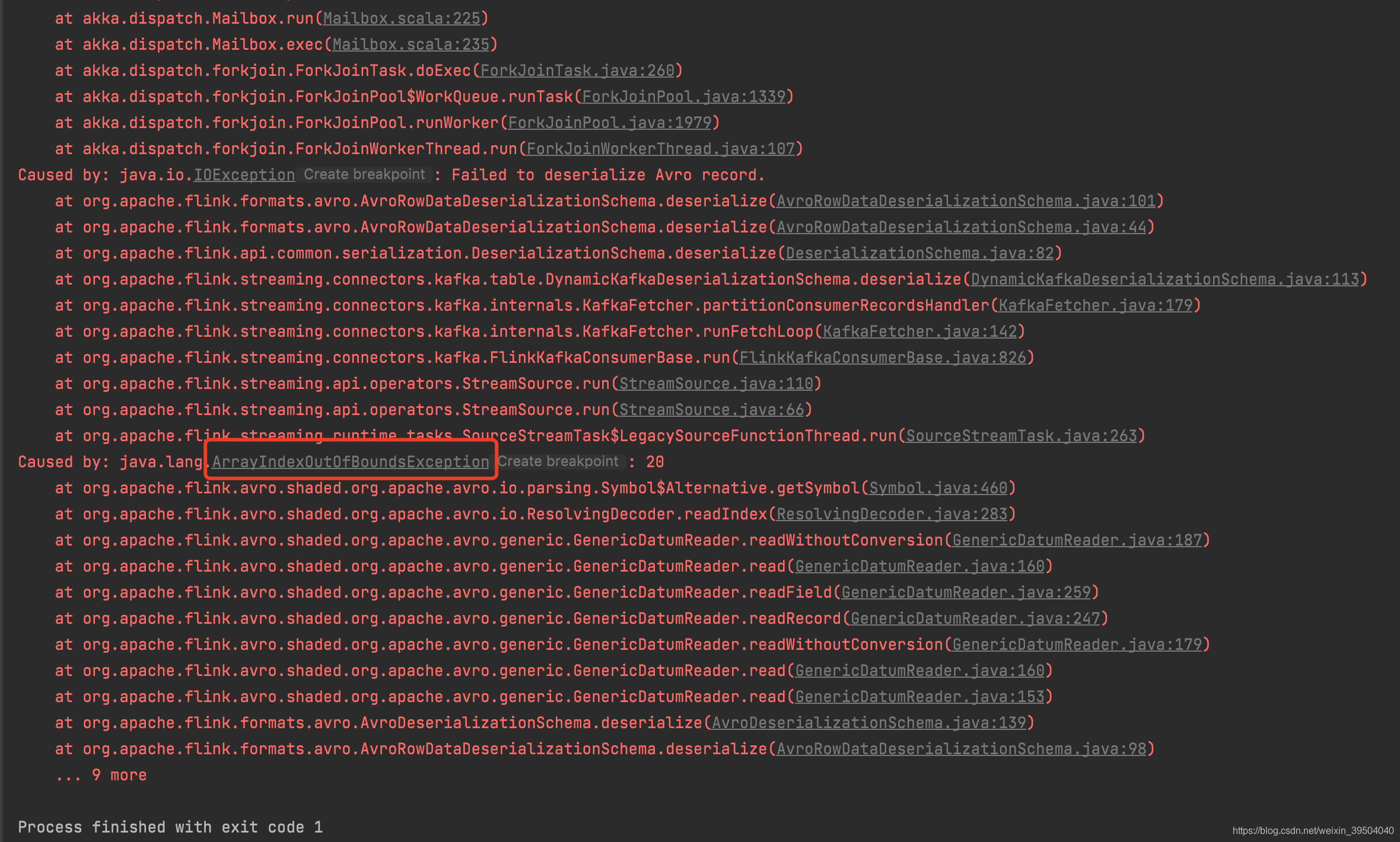
里面明显的说法就是索引越界,但是是因为sql写的有问题
正确的flink sql
CREATE TABLE xxxx (
`transactionId` STRING NOT NULL,
`opType` STRING NOT NULL,
`schemaName` STRING NOT NULL,
`tableName` STRING NOT NULL,
`columnInfos` MAP<STRING NOT NULL,ROW<oldValue STRING NULL ,newValue STRING ,name STRING NOT NULL ,isKeyColumn BOOLEAN NOT NULL,type STRING NOT NULL > NOT NULL> NOT NULL,
`timeStamp` STRING NOT NULL,
`numberOfColumns` INT NOT NULL ,
`processedTimeStamp` BIGINT NOT NULL,
`schemaVersion` STRING ,
`rba` BIGINT NOT NULL ,
`seqNo` BIGINT NOT NULL ,
`domainName` STRING NOT NULL
) WITH (
'connector' = 'kafka',
'topic' = 'xxxx',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'xxxx',
'properties.group.id' = 'xxxx',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username="xxxx" password="xxxx";',
'properties.sasl.mechanism' = 'PLAIN',
'format' = 'avro'
)
注意的点
1.schema 如果字段后面没有 “type” : [ “null”, “string” ] 这个指定,则需要 加上NOT NULL 例如transactionId 字段
2.如果有 “type” : [ “null”, “string” ] 则可以不加 例如 oldValue字段或者newValue 这种写法
3.如果有 domainName 这种写法 也需要加上NOT NULL
4.map 后面没有 “type” : [ “null”, “string” ] 所以需要加上 NOT NULL
5.row 后面没有 “type” : [ “null”, “string” ] 所以需要加上 NOT NULL
如何确定flink sql是用map array row
可以看到里面有个type 指的是map 毫无疑问,直接用map,但是map里面有个record 类型 ,实际上record 类型对应的是flink sql的row类型,其他的类型可以参照下表
| Flink SQL 类型 | Avro 类型 | Avro 逻辑类型 |
|---|---|---|
| CHAR / VARCHAR / STRING | string | |
| BOOLEAN | boolean | |
| BINARY / VARBINARY | bytes | |
| DECIMAL | fixed | decimal |
| TINYINT | int | |
| SMALLINT | int | |
| INT | int | |
| BIGINT | long | |
| FLOAT | float | |
| DOUBLE | double | |
| DATE | int | date |
| TIME | int | time-millis |
| TIMESTAMP | long | timestamp-millis |
| ARRAY | array | |
| MAP (key 必须是 string/char/varchar 类型) | map | |
| MULTISET (元素必须是 string/char/varchar 类型) | map | |
| ROW | record |
其中row类型字段定义类似于scala中的 case class,类似于以下定义
ROW<myField INT, myOtherField BOOLEAN>