一.部署虚拟机
1. 过程略过
VMware安装Centos7
2. 部署3台
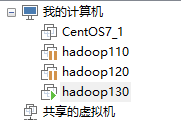
二.配置虚拟机
虚拟机网络
1.虚拟机网络采用仅主机模式。
安装时选择网络时选择,或者装好后重新设值。
2.设置主机VMware Virtual Ethernet Adapter for VMnet1

3.配置静态IP
- 编辑配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
- 机器一
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=bcb7a50e-bfdf-4255-b7fe-1c26e29d036d
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.40.110
NETMASK=255.255.255.0
GATEWAY=192.168.40.1
- 机器二
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=9c11cadc-1810-4181-bd1c-bc0dd18c424f
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.40.120
NETMASK=255.255.255.0
GATEWAY=192.168.40.1
- 机器二
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=9c11cadc-1810-4181-bd1c-bc0dd18c424f
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.40.130
NETMASK=255.255.255.0
GATEWAY=192.168.40.1
- 重启网络
service network restart
4.配置hosts
- 编辑hosts文件
vim /etc/hosts
- 机器一
192.168.40.110 hadoop110
192.168.40.120 hadoop120
192.168.40.130 hadoop130
- 机器二
192.168.40.110 hadoop110
192.168.40.120 hadoop120
192.168.40.130 hadoop130
- 机器三
192.168.40.110 hadoop110
192.168.40.120 hadoop120
192.168.40.130 hadoop130
5.关闭防火墙
- 查看防火墙状态
systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2021-08-08 11:53:17 CST; 2 days ago
Docs: man:firewalld(1)
Process: 670 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 670 (code=exited, status=0/SUCCESS)
- 如果防火墙为开启状态需要关闭防火墙
systemctl stop firewalld
6.设置网络共享
仅主机模式虚拟机不能连接外网多少还是不方便,有需要可以配置一下。
VMware虚拟机仅主机模式访问外网
7.Xshell连接虚拟机非常慢
如果有可以配置一下
Xshell连接虚拟机非常慢
创建hadoop用户
1.创建一个一般用户hadoop,配置密码
# 我的密码和用户名一样为了方便学习时好记,生产环境不能这样
useradd hadoop
passwd hadoop
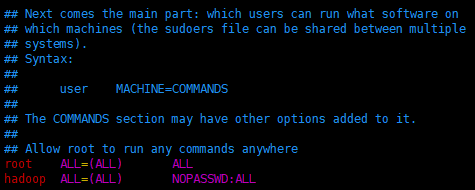
2.配置这个用户为sudoers(sudo时不用输入密码)
- 编辑sudoers
vim /etc/sudoers
- 加上
hadoop ALL=(ALL) NOPASSWD:ALL
- 最终结果
3.在/opt目录下创建两个文件夹module和software,并把所有权赋给hadoop
- 创建
mkdir /opt/module /opt/software
chown hadoop:hadoop /opt/module /opt/software
- 结果

安装Java
1.下载jdk8
- oracle官网去找,
2.将下载后的文件上传至虚拟机/opt/software
cd /opt/software
rz -b
- 选择下载的文件

3.安装rz命令
没有rz命令可以安装一下,或者使用其它方式上传
- 安装rz命令
yum install -y lrzsz
4.安装jdk
- 解压jdk到/opt/module
cd /opt/software/
tar -zxvf jdk-8u261-linux-x64.tar.gz -C /opt/module

5.配置Java环境变量
- 编辑profile
sudo vim /etc/profile
- 在尾部加上
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_261
export PATH=$PATH:$JAVA_HOME/bin
- 保存退出后执行
source /etc/profile
- 验证
# 查看java版本
java -version
# 出现下面结果就成功了
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
安装Hadoop
1.下载Hadoop
去Apache hadoop官网下载hadoop包,找到你需要的版本的包,我这里是2.7.2。
下载地址

2.将下载后的文件上传至虚拟机/opt/software

3.解压至/opt/module
cd /opt/software/
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module
4.配置hadoop环境变量
- 编辑profile
sudo vim /etc/profile
- 在尾部加上
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 保存退出后执行
source /etc/profile
- 验证
# 查看hadoop版本
hadoop version
# 出现下面结果就成功了
Hadoop 2.7.2
Subversion Unknown -r Unknown
Compiled by root on 2017-05-22T10:49Z
Compiled with protoc 2.5.0
From source with checksum d0fda26633fa762bff87ec759ebe689c
This command was run using /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar
配置hadoop
1.hadoop目录结构
drwxr-xr-x. 2 hadoop hadoop 194 May 22 2017 bin
drwxr-xr-x. 3 hadoop hadoop 20 May 22 2017 etc
drwxr-xr-x. 2 hadoop hadoop 106 May 22 2017 include
drwxr-xr-x. 3 hadoop hadoop 20 May 22 2017 lib
drwxr-xr-x. 2 hadoop hadoop 239 May 22 2017 libexec
-rw-r--r--. 1 hadoop hadoop 15429 May 22 2017 LICENSE.txt
-rw-r--r--. 1 hadoop hadoop 101 May 22 2017 NOTICE.txt
-rw-r--r--. 1 hadoop hadoop 1366 May 22 2017 README.txt
drwxr-xr-x. 2 hadoop hadoop 4096 May 22 2017 sbin
drwxr-xr-x. 4 hadoop hadoop 31 May 22 2017 share
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本。
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件。
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)。
- sbin目录:存放启动或停止Hadoop相关服务的脚本。
- share目录:存放Hadoop的依赖jar包、文档、和官方案例。
2.本地模式
2.1官方Grep案例
1.在hadoop-2.7.2文件下面创建一个input文件夹
cd /opt/module/hadoop-2.7.2
mkdir input
2.将Hadoop的xml配置文件复制到input
cd /opt/module/hadoop-2.7.2
cp /etc/hadoop/*.xml input/
3.执行share目录下的MapReduce程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
4.查看输出结果
cat output/*

2.1官方WordCount案例
1.在hadoop-2.7.2文件下面创建一个wcinput文件夹
cd /opt/module/hadoop-2.7.2
mkdir wcinput
2.在wcinput文件下创建一个wc.input文件
vim wc.input
3.编辑wc.input文件
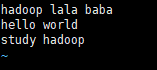
4.执行程序
cd /opt/module/hadoop-2.7.2
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
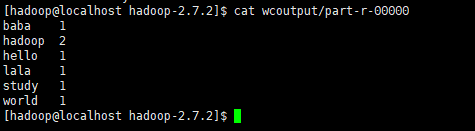
5.查看结果
cat wcoutput/part-r-00000
3.伪分布式运行模式
3.1启动HDFS并运行MapReduce程序
1.目标
- 配置集群
- 启动、测试集群增、删、查
- 执行WordCount案例
2.执行步骤
- 配置:hadoop-env.sh
# 修改JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_261

- 配置:core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop110:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>

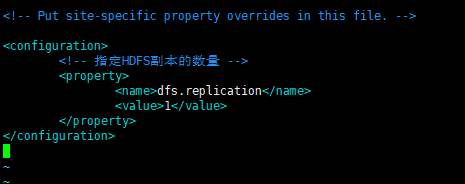
- 配置:hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 启动集群
(1)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode
hdfs namenode -format
(2)启动NameNode
hadoop-daemon.sh start namenode
(3)启动DataNode
hadoop-daemon.sh start datanode
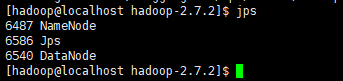
- 查看集群
(1)查看是否启动成功
jps
(1)web端查看HDFS文件系统
http://192.168.40.110:50070/dfshealth.html#tab-overview

(2)查看日志
cd /opt/module/hadoop-2.7.2/logs

可以查看对应的日志
- 操作集群
(1)在HDFS文件系统上创建一个input文件夹
hdfs dfs -mkdir -p /user/hadoop/input
(2)将测试文件内容上传到文件系统上
hdfs dfs -put wcinput/wc.input /user/hadoop/input/
(3)查看上传的文件是否正确
hdfs dfs -ls /user/hadoop/input/
hdfs dfs -cat /user/hadoop/input/wc.input

(4)运行 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input/ /user/hadoop/output
(5)查看输出结果
hdfs dfs -cat /user/hadoop/output/*

(6)浏览文件夹

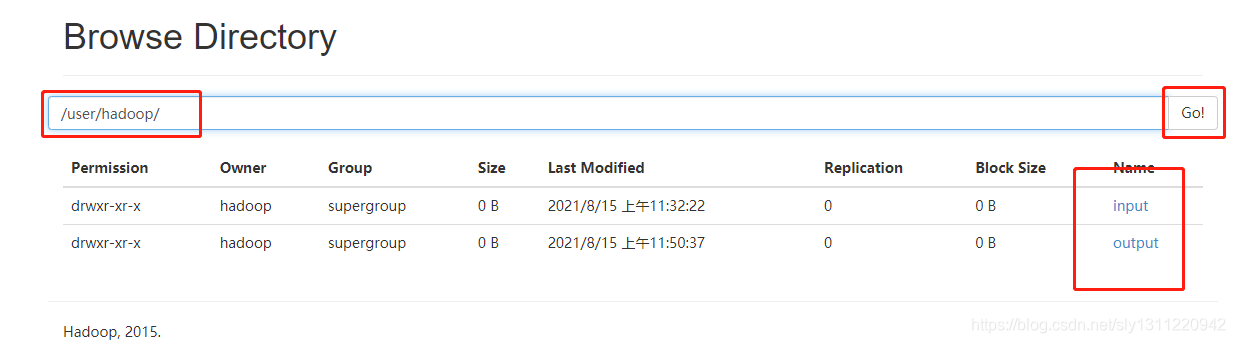
分别可以查看生成的文件和上传的文件。
3.2启动 YARN 并运行 MapReduce 程序
1.目标
- 配置集群在 YARN 上运行 MR
- 启动、 测试集群增、 删、 查
- 在 YARN 上执行 WordCount 案例
2.执行步骤
- 配置集群
(1)配置 yarn-env.sh
# 配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_261
(2)配置 yarn-site.xml
<!-- Reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop110</value>
</property>
<!--
下面的这几个配置开始没有配置导致执行wordcount卡在mapreduce.Job: Running job
加上后重启可以正常执行,但是后面我将其去掉重启后又可以正常执行wordcount,
而且这几个配置本来就有默认值,按道理是可以不加的,所以如果可以正常运行就可以不加下面的配置
真是充满玄学的一天
-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<!-- -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!-- -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>

(3)配置: mapred-env.sh
# 配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_261
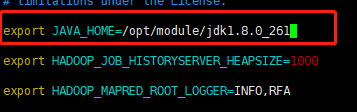
(4)配置:mapred-site.xml(对 mapred-site.xml.template 重新命名为:mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
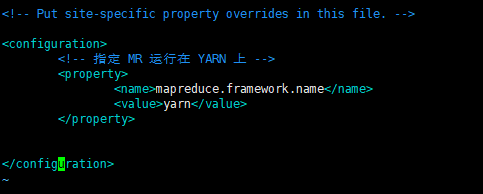
<!-- 指定 MR 运行在 YARN 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 启动集群
(1)启动前必须保证 NameNode 和 DataNode 已经启动
(2)启动 ResourceManager
yarn-daemon.sh start resourcemanager
(3)启动 NodeManager
yarn-daemon.sh start nodemanager
- 集群操作
(1)YARN 的浏览器页面查看
http://192.168.40.110:8088/cluster

(2)删除文件系统上的 output 文件
hdfs dfs -rm -R /user/hadoop/output

(3)执行 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input/ /user/hadoop/output
(4)查看运行结果
hdfs dfs -cat /user/hadoop/output/*
3.3 配置历史服务器
为了查看程序的历史运行情况, 需要配置一下历史服务器。
- 配置 mapred-site.xml
<!-- 在文件里面增加如下配置 -->
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop110:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop110:19888</value>
</property>
- 启动历史服务器
mr-jobhistory-daemon.sh start historyserver
- 查看历史服务器是否启动
jps
- 查看 JobHistory
http://192.168.40.110:19888/jobhistory

3.4配置日志的聚集
日志聚集概念: 应用运行完成以后, 将程序运行日志信息上传到 HDFS 系统上。
日志聚集功能好处: 可以方便的查看到程序运行详情, 方便开发调试。
注 意 : 开 启 日 志 聚 集 功 能 , 需 要 重 新 启 动 NodeManager 、 ResourceManager 和
HistoryManager。
- 配置 yarn-site.xml
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 关闭 NodeManager 、 ResourceManager 和 HistoryServer
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
- 启动 NodeManager 、 ResourceManager 和 HistoryServer
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
- 删除 HDFS 上已经存在的输出文件
hdfs dfs -rm -R /user/hadoop/output
- 执行 WordCount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input/ /user/hadoop/output
- 查看日志, 如图 所示
http://192.168.40.110:19888/jobhistory



4.分布式运行模式(重要)
4.1准备
- 准备 3 台客户机(关闭防火墙、 静态 ip、 主机名称)
- 安装 JDK并配置环境变量
- 安装 Hadoop并配置环境变量
- 配置集群
- 单点启动
4.2集群配置
- 集群部署规划
| hadoop110 | hadoop120 | hadoop130 | |
| HDFS | NameNode DataNode | DateNode JobHistory | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
- 配置集群
(1)下载最新版的hadoop
- 我选择的是3.3.1
- 安装hadoop(不在重复)
- 重新配置hadoop环境变量(不在重复)
- 删除旧的hadoop(不在重复)
参考地址:https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-common/ClusterSetup.html
(1) 核心配置文件
- 配置hadoop-env.sh(每台都要配)
export JAVA_HOME=/opt/module/jdk1.8.0_261
- 配置core-site.xml(每台都要配)
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop110:9000</value>
</property>
<!-- 指定 顺序文件的缓冲区大小 可以减少IO次数 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.1/data/tmp</value>
</property>
- 配置 hdfs-site.xml(每台都要配)
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 Hadoop 辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop130:50090</value>
</property>
- 配置 yarn-site.xml(每台都要配)(3.0无需配置yarn-env.sh的java_home)
<!-- Reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop120</value>
</property>
<!-- 日志聚集功能使能 默认false -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 配置 mapred-site.xml(每台都要配)(3.0无需配置mapred-env.sh的java_home)
<!-- 指定 MR 运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop120:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop120:19888</value>
</property>
<!-- 这是3.2以上版本需要增加配置的,不配置运行mapreduce任务可能会有问题,记得使用自己的路径 -->
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/module/hadoop-3.3.1/etc/hadoop,
/opt/module/hadoop-3.3.1/share/hadoop/common/*,
/opt/module/hadoop-3.3.1/share/hadoop/common/lib/*,
/opt/module/hadoop-3.3.1/share/hadoop/hdfs/*,
/opt/module/hadoop-3.3.1/share/hadoop/hdfs/lib/*,
/opt/module/hadoop-3.3.1/share/hadoop/mapreduce/*,
/opt/module/hadoop-3.3.1/share/hadoop/mapreduce/lib/*,
/opt/module/hadoop-3.3.1/share/hadoop/yarn/*,
/opt/module/hadoop-3.3.1/share/hadoop/yarn/lib/*
</value>
</property>
- 配置works(每台都要配)(2.0是slaves文件)
hadoop110
hadoop120
hadoop130
- 配置ssh(每台都要配)
# hadoop110
# 生成公私钥,运动选择连续enter就行
ssh-keygen -t rsa
# 进入公私钥目录
cd /home/hadoop/.ssh/
# 将公钥安装到目标机器上,这样就可以免密SSH连接hadoop110、hadoop120和hadoop130
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop110
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop120
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop130
# hadoop120
# 生成公私钥,运动选择连续enter就行
ssh-keygen -t rsa
# 进入公私钥目录
cd /home/hadoop/.ssh/
# 将公钥安装到目标机器上,这样就可以免密SSH连接hadoop110、hadoop120和hadoop130
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop110
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop120
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop130
# hadoop130
# 生成公私钥,运动选择连续enter就行
ssh-keygen -t rsa
# 进入公私钥目录
cd /home/hadoop/.ssh/
# 将公钥安装到目标机器上,这样就可以免密SSH连接hadoop110、hadoop120和hadoop130
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop110
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop120
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop130
- 设置时间同步
(1)安装ntp(都安装)
# 安装ntp
yum install -y ntp
# 设置开机自启动
systemctl enable ntpd
(2)配置ntp(hadoop110)
vim /etc/ntp.conf
# 配置ntp时间同步的机器范围配置项(192.168.40的网段的机器都参与ntp的时间同步)
restrict 192.168.40.0 mask 255.255.255.0 nomodify notrap
# 阿里云时间服务器
server ntp1.aliyun.com
server ntp2.aliyun.com
server ntp3.aliyun.com
# 兜底时间服务器,当以上三个时间服务器不可用时
server 127.0.0.1
fudge 127.0.0.1 stratum 10

(3)测试是否可以同步(hadoop110)
ntpdate -u ntp2.aliyun.com

(4)启动ntp服务(hadoop110)
# 启动
systemctl start ntpd
# 查看状态
systemctl status ntpd
(5)客户机配置(hadoop120、hadoop130)
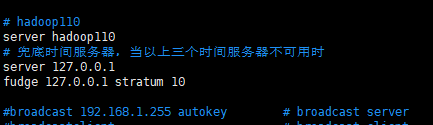
# 将时间服务器配置为hadoop110
# hadoop110
server hadoop110
# 兜底时间服务器,当以上三个时间服务器不可用时
server 127.0.0.1
fudge 127.0.0.1 stratum 10
# 测试是否可以同步
ntpdate -u ntp2.aliyun.com
# 启动
systemctl start ntpd
# 查看状态
systemctl status ntpd
4.3集群启动
- 如果集群是第一次启动, 需要格式化 NameNode
hdfs namenode -format
- 在 hadoop110 上启动 NameNode
# 启动NameNode
hadoop-daemon.sh start namenode
# 查看NameNode
jps
- 在 hadoop110 hadoop120 hadoop130上启动DataNode
# 启动DataNode
hadoop-daemon.sh start datanode
# 查看DataNode
jps
- 在hadoop120上启动ResourceManager
# 启动ResourceManager
yarn-daemon.sh start resourcemanager
# 查看ResourceManager
jps
- 在 hadoop110 hadoop120 hadoop130上启动NodeManager
# 启动NodeManager
yarn-daemon.sh start nodemanager
# 查看NodeManager
jps
- 在hadoop130上启动SecondaryNamenode
# 启动NodeManager
hadoop-daemon.sh start secondarynamenode
# 查看NodeManager
jps
- 在hadoop120上启动HistoryServer
# 启动HistoryServer
mr-jobhistory-daemon.sh start historyserver
# 查看HistoryServer
jps
- 检查集群情况
(1)Web 端查看 Yarn
http://192.168.40.120:8088/cluster

(2)Web 端查看 SecondaryNameNode
http://192.168.40.130:50090/status.html

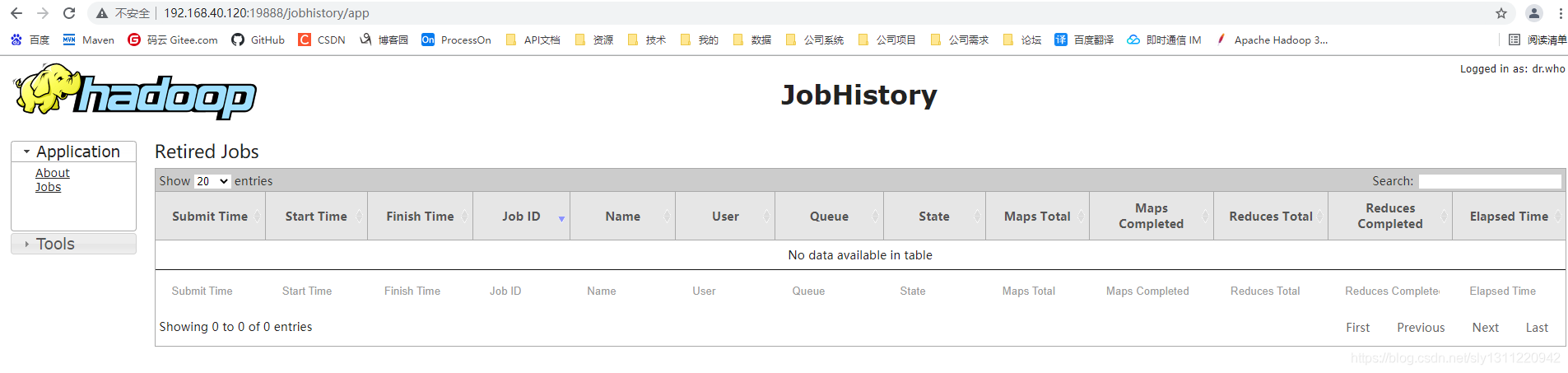
(3)Web查看HistoryServer
http://192.168.40.120:19888/jobhistory/app
(4)Web查看NameNode(2.x端口是50070,3.x端口是9870)
http://192.168.40.110:9870/dfshealth.html#tab-overview
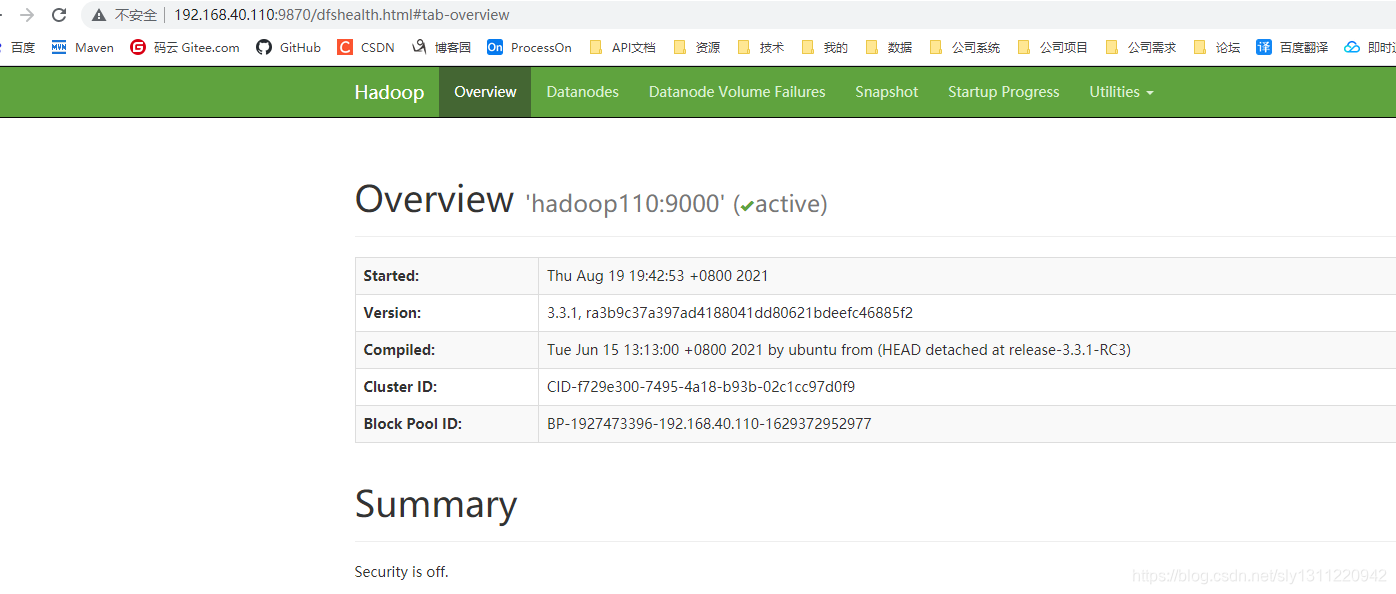
- 验证集群
(1)在 HDFS 文件系统上创建一个 input 文件夹
hdfs dfs -mkdir -p /user/hadoop/input
(2)测试文件上传到文件系统
# 上传小文件
hdfs dfs -put wcinput/wc.input /user/hadoop/input
# 上传大文件
hdfs dfs -put /opt/software/jdk-8u261-linux-x64.tar.gz /user/hadoop/input
(3)查看上传是否正确

(4)查看文件上传是否正确(每个节点都能看的文件)
cd /opt/module/hadoop-3.3.1/data/tmp/dfs/data/current/BP-1927473396-192.168.40.110-1629372952977/current/finalized/subdir0/subdir0
从文件大小上我们可以看到1002和1003是我上传的jdk包,拼接起来就是完整的包了。
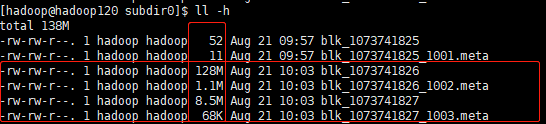
(5)下载
# 网页或者命令都行
hadoop fs -get /user/hadoop/input/jdk-8u261-linux-x64.tar.gz ./