1 RDD 定义
对于大量的数据,Spark 在内部保存计算的时候,都是用一种叫做弹性分布式数据集(ResilientDistributed Datasets,RDD)的数据结构来保存的,所有的运算以及操作都建立在 RDD 数据结构的基础之上。
在Spark开山之作Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-MemoryCluster Computing这篇paper中(以下简称 RDD Paper),Matei等人提出了RDD这种数据结构,文中开头对RDD的定义是:
也就是说RDD设计的核心点为:
RDD提供了一个抽象的数据模型,不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy等等)。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
拆分核心要点三个方面:
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract
Class和泛型Generic Type: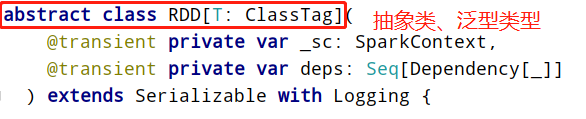
RDD弹性分布式数据集核心点示意图如下:
RDD将Spark的底层的细节都隐藏起来(自动容错、位置感知、任务调度执行,失败重试等),让开发者可以像操作本地集合一样以函数式编程的方式操作RDD这个分布式数据集,进行各种并行计算,RDD中很多处理数据函数与列表List中相同与类似。
2 RDD 特性
RDD 数据结构内部有五个特性(摘录RDD 源码)
前三个特征每个RDD都具备的,后两个特征可选的。
- 第一个:A list of partitions
- 一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位;
- 对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度;
- 用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值;

- 第二个:A function for computing each split
- 一个函数会被作用在每一个分区;
- Spark中RDD的计算是以分片为单位的,compute函数会被作用到每个分区上;
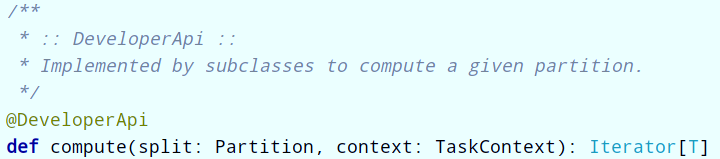
- 第三个:A list of dependencies on other RDDs
- 一个RDD会依赖于其他多个RDD;
- RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后
依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数
据,而不是对RDD的所有分区进行重新计算(Spark的容错机制);
- 第四个:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is
hash-partitioned)
- 可选项,对于KeyValue类型的RDD会有一个Partitioner,即RDD的分区函数;
- 当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个
是基于范围的RangePartitioner。 - 只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值
是None。 - Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的
分片数量。

- 第五个:Optionally, a list of preferred locations to compute each split on (e.g. block locations
for an HDFS file)
- 可选项,一个列表,存储存取每个Partition的优先位置(preferred location);
- 对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
- 按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些
存有数据的worker节点来进行任务计算。(数据本地性)

RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来、如何计算,主
要属性包括五个方面(必须牢记,通过编码加深理解,面试常问):
RDD 设计的一个重要优势是能够记录 RDD 间的依赖关系,即所谓血统(lineage)。
通过丰富的转移操作(Transformation),可以构建一个复杂的有向无环图,并通过这
个图来一步步进行计算。
3 WordCount中RDD
以词频统计WordCount程序为例,查看整个Job中各个RDD类型及依赖关系,WordCount程序
代码如下:
[\s]表示,只要出现空白就匹配
[\S]表示,非空白就匹配
\w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]"。
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]"。
运行程序结束后,查看WEB UI监控页面,此Job(RDD调用foreach触发)执行DAG图:

上图中相关说明如下:
- 第一点、黑色圆圈表示一个RDD
- 上图中有5个黑色圆圈,说明整个Job中有个5个RDD
- 【1号】RDD类型:HadoopRDD,从HDFS或LocalFS读取文件数据;
- 【2号、3号和4号】RDD类型:MapPartitionsRDD,从一个RDD转换而来,没有经过shuffle
操作; - 【5号】RDD类型:ShuffledRDD,从一个RDD转换而来,经过Shuffle重分区操作,Spark
Shuffle类似MapReduce流程中Map Phase和Reduce Phase中的Shuffle;
- 第二点、浅蓝色矩形框表示调用RDD函数
- 上图中【5号】RDD所在在蓝色矩形框上的函数【reduceByKey】,表明【5号】RDD是【4
号】RDD调用reduceByKey函数得到;
- 第三点、查看ShuffleRDD源码,实现RDD的5个特性

RDD 设计的一个重要优势是能够记录 RDD 间的依赖关系,即所谓血统(lineage)。
通过丰富的转移操作(Transformation),可以构建一个复杂的有向无环图,并通过这
个图来一步步进行计算。
4 RDD 创建
如何将数据封装到RDD集合中,主要有两种方式:并行化本地集合(Driver Program中)和引
用加载外部存储系统(如HDFS、Hive、HBase、Kafka、Elasticsearch等)数据集。

官方文档: http://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
4.1 并行化集合
由一个已经存在的 Scala 集合创建,集合并行化,集合必须时Seq本身或者子类对象。

演示范例代码,从List列表构建RDD集合:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark 采用并行化的方式构建Scala集合Seq中的数据为RDD
* - 将Scala集合转换为RDD
* sc.parallelize(seq)
* - 将RDD转换为Scala中集合
* rdd.collect()
* rdd.collectAsMap()
*/
object SparkParallelizeTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: 1、Scala中集合Seq序列存储数据
val linesSeq: Seq[String] = Seq(
"hadoop scala hive spark scala sql sql", //
"hadoop scala spark hdfs hive spark", //
"spark hdfs spark hdfs scala hive spark" //
)
// TODO: 2、并行化集合创建RDD数据集
/*
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism
): RDD[T]
*/
val inputRDD: RDD[String] = sc.parallelize(linesSeq, numSlices = 2)
//val inputRDD: RDD[String] = sc.makeRDD(linesSeq, numSlices = 2)
// TODO: 3、调用集合RDD中函数处理分析数据
val resultRDD: RDD[(String, Int)] = inputRDD
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
// TODO: 4、保存结果RDD到外部存储系统(HDFS、MySQL、HBase。。。。)
resultRDD.foreach(println)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
SparkContext中存在makeRDD方法并行化集合为RDD,API说明:
4.2 外部存储系统
由外部存储系统的数据集创建,包括本地的文件系统,还有所有 Hadoop支持的数据集,比如
HDFS、Cassandra、HBase 等。实际使用最多的方法:textFile,读取HDFS或LocalFS上文本文件,
指定文件路径和RDD分区数目。

范例演示:从文件系统读取数据,设置分区数目为2,代码如下。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从HDFS/LocalFS文件系统加载文件数据,封装为RDD集合, 可以设置分区数目
* - 从文件系统加载
* sc.textFile("")
* - 保存文件系统
* rdd.saveAsTextFile("")
*/
object SparkFileSystemTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: 2、从文件系统加载数据,创建RDD数据集
/*
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions
): RDD[String]
*/
val inputRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data", minPartitions = 2)
println(s"Partitions Number : ${inputRDD.getNumPartitions}")
// TODO: 2、调用集合RDD中函数处理分析数据
val resultRDD: RDD[(String, Int)] = inputRDD
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
// TODO: 3、保存结果RDD到外部存储系统(HDFS、MySQL、HBase。。。。)
resultRDD.foreach(println)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
其中文件路径:最好是全路径,可以指定文件名称,可以指定文件目录,可以使用通配符指定。
实际项目中如果从HDFS读取海量数据,应用运行在YARN上,默认情况下,RDD分区数目等于HDFS上Block块数目。
4.3 小文件读取
在实际项目中,有时往往处理的数据文件属于小文件(每个文件数据数据量很小,比如KB,
几十MB等),文件数量又很大,如果一个个文件读取为RDD的一个个分区,计算数据时很耗时性
能低下,使用SparkContext中提供:wholeTextFiles类,专门读取小文件数据。
范例演示:读取100个小文件数据,每个文件大小小于1MB,设置RDD分区数目为2。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 采用SparkContext#wholeTextFiles()方法读取小文件
*/
object SparkWholeTextFileTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: wholeTextFiles()
val inputRDD: RDD[String] = sc
.wholeTextFiles("datas/ratings100/", minPartitions = 2)
.flatMap(tuple => tuple._2.split("\\n"))
println(s"Partitions Number = ${inputRDD.getNumPartitions}")
println(s"Count = ${inputRDD.count()}")
// 应用程序运行结束,关闭资源
Thread.sleep(1000000)
sc.stop()
}
}
实际项目中,可以先使用wholeTextFiles方法读取数据,设置适当RDD分区,再将数据保存到
文件系统,以便后续应用读取处理,大大提升性能。
4.4 RDD 分区数目
在讲解 RDD 属性时,多次提到了分区(partition)的概念。分区是一个偏物理层的概念,也
是 RDD 并行计算的核心。数据在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个
分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,
所以分区数越多,整个应用的并行度也会越高。
获取RDD分区数目两种方式:

RDD分区的数据取决于哪些因素?
- 第一点:RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充
分利用CPU的计算资源; - 第二点:在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍;
- 第三点:RDD分区数和启动时指定的核数、调用方法时指定的分区数、如文件本身分区数有关
系,具体如下说明:
1)、启动的时候指定的CPU核数确定了一个参数值:
-
spark.default.parallelism=指定的CPU核数(集群模式最小2)
2)、对于Scala集合调用parallelize(集合,分区数)方法 -
如果没有指定分区数,就使用spark.default.parallelism
-
如果指定了就使用指定的分区数(不要指定大于spark.default.parallelism)
3)、对于textFile(文件, 分区数) -
defaultMinPartitions
如果没有指定分区数sc.defaultMinPartitions=min(defaultParallelism,2)
如果指定了就使用指定的分区数sc.defaultMinPartitions=指定的分区数rdd的分区数 -
rdd的分区数对于本地文件
rdd的分区数 = max(本地file的分片数, sc.defaultMinPartitions) -
rdd的分区数对于HDFS文件
rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions)
所以如果分配的核数为多个,且从文件中读取数据创建RDD,即使hdfs文件只有1个切片,最后的Spark的RDD的partition数也有可能是2
