目录
一、HBase 架构
-
HLOG里面有 master、regionserver、wal(预写日志)
-
当有数据来了之后先查询HMaster 来获取向哪个HRegionserver中插入数据
-
数据来了之后先向HLog中写,然后写到Mem Store,达到默认64MB之后写入HFile

?
二、Hbase 读写流程
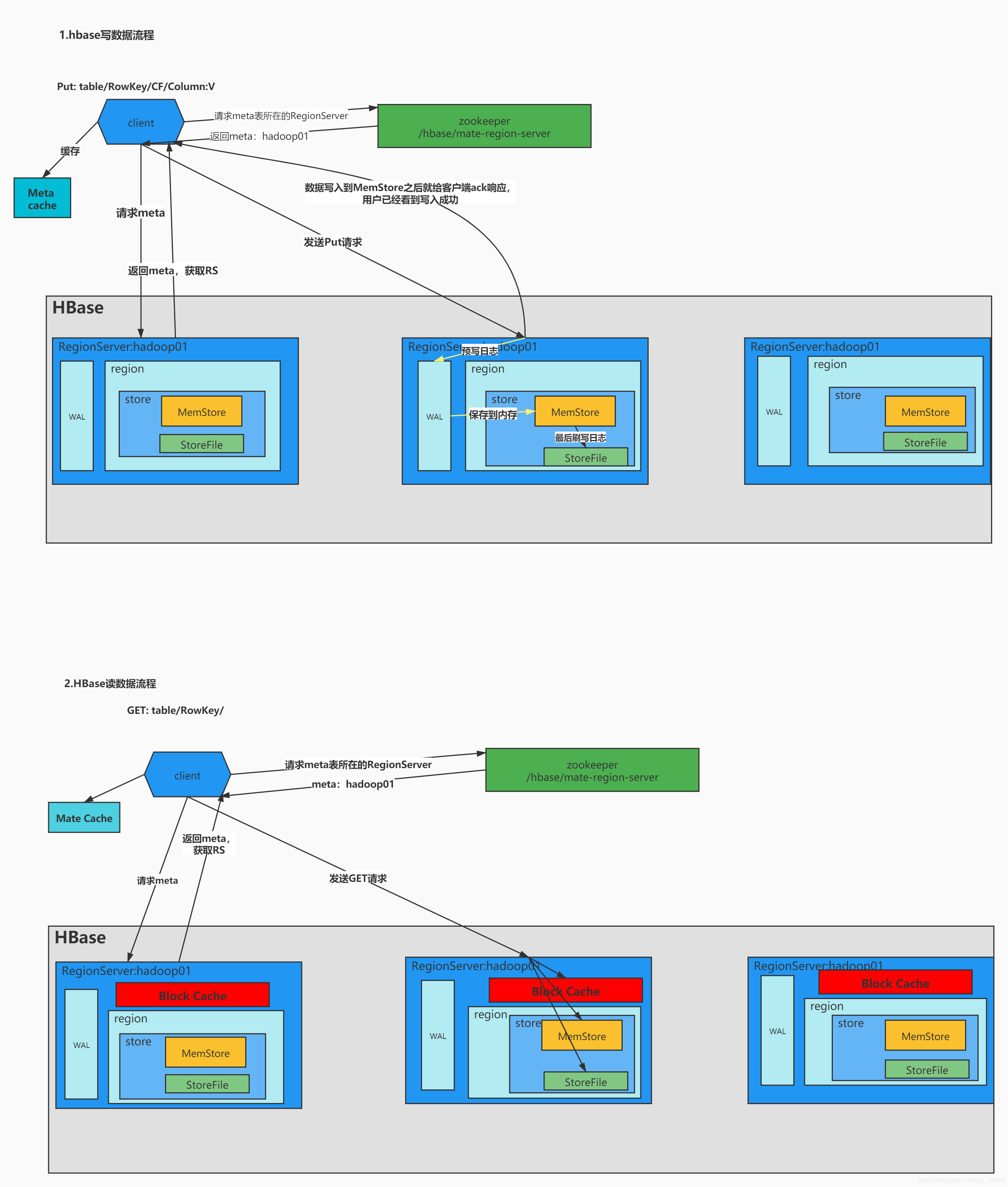
?
三、StoreFile Compaction

?
Compaction 分为两种,分别是Minor Compaction和 Major Compaction 。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile。但不会清理 过期和删除 的数据。Major Compaction 会将一个Store 下的所有的HFile合并成一个大HFile,并且会 清理掉过期和删除 的数据
四、Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split 时机 配置在 hbase-site.xml
? 1. 当1个region中的某个Store下所有StoreFile的总大小超过 ==hbase.hregion.max.filesize== 该Region就会进行拆分 (0.94版本前) ? 2. 当1个region中的某个Store下所有StoreFile的总大小超过 ==Min(R^3 * 2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize)== ,该Region就会进行拆分,其中R为当前Region Server中属于该Table的个数 (0.94版本后) ? 3. HBase2.0引入了新的Split策略:如果当前RegionServer上改表只有一个Region按照 ==2 * hbase.hregion.memstore.flush.size== 分裂,否则按照==hbase.hregion.max.filesize== 分裂

?
五、预分区
每一个region维护着StartRow与EndRow,如果加入的数据符合某个Region维护的RowKey范围,则该数据交给这个Region维护。那么依照这个原则,我们可以将数据索要投放的分区提前大致的规划好,以提高HBase性能。
? 1. 手动预分区 ? 2. 生成16进制序列预分区 ? 3. 按照文件设置的规则预分区
六、ROWKey设计
一条数据的唯一标识就是RowKey,那么这条数据存储与哪个分区,取决于RowKey处于哪一个预分区的区间内,设计RowKey的主要目的就是让数据均匀的分布于所有的region中,在一定的程度上防止数据倾斜。
-
生成随机数、hash、散列值 (加盐)
-
字符串反转
-
字符串拼接