转换算子: mapValues
注意: 只针对PariedRDD,也就是说RDD描述的数据是若干个键值对
(其实,这里可以操作的数据,可以可以是RDD(Tuple2))
逻辑: 对键值对的值做映射,不对键做任何处理
转换算子: map
逻辑: 对RDD中的每一个元素进行映射,映射为指定的值
对每一个分区中的每一个数据进行映射
案例对比:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object anli1 extends App{
val sc=new SparkContext(new SparkConf().setMaster("local").setAppName("alnli1"))
val book=sc.parallelize(List(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
val book1 : RDD[((String, Int), Int)]=book.map(x=>(x,1))
book1.foreach(println)
val book2 : RDD[(String, (Int, Int))]=book.mapValues(x=>(x,1))
book2 .foreach(println)
}结果:
map:???????????????????????????????????????????????????????????????????? mapValues:
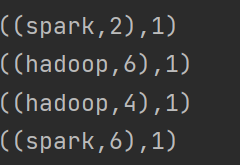 ??????????????????????????????????
?????????????????????????????????? 
val RDD :RDD[(String, Int)]= sc.parallelize(List(("e",5),("c",3),("d",4),("c",2),("a",1)))
//filterByRange:对RDD中的元素进?过滤,返回指定范围内的数据
//filterByRange:该函数作用于键值对RDD,对RDD中的元素进行过滤,返回键在指定范围中的元素。
val rdd3:RDD[(String, Int)]=RDD.filterByRange("a","c")
rdd3.foreach(println) //(c,3) (a,1) (c,2)
//filter使用一个布尔函数为RDD的每个数据项计算,并将函数返回true的项放入生成的RDD中
val rdd4:RDD[(String, Int)]=RDD.filter(x=>(x._1 <= "c" && x._1 >= "a"))
rdd4.foreach(println) //(c,3) (a,1) (c,2)
//flatMapValues对参数进?扁平化操作,是value的值
val RdD:RDD[(String, String)]= sc.parallelize(List(("e","6,5"),("c","3"),("d","10,11"),("c","2,7"),("a","2")))
val rdd5:RDD[(String, String)]=RdD.flatMapValues(x=>(x.split(",")))
rdd5.foreach(println)//(a,2)(d,10)(e,6)(c,2)(c,3)(c,7)(e,5)(d,11)
println(rdd5.collect().toList)//List((e,6), (e,5), (c,3), (d,10), (d,11), (c,2), (c,7), (a,2))
//flatMap是map的一种扩展。在flatMap中,我们会传入一个函数,该函数对每个输入都会返回一个集合(而不是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个集合。
val rdd6:RDD[String]=RdD.flatMap(x=>(x._2.split(",")))
println(rdd6.collect().toList)//List(6, 5, 3, 10, 11, 2, 7, 2)
//map操作是针对集合的典型变换操作,它将某个函数应用到集合中的每个元素,并产生一个结果集合
val rdd7:RDD[String]=RdD.map(x=>(x._2.split(",")).mkString(","))
val rdd8:RDD[Array[String]] =RdD.map(x=>(x._2.split(",")))
rdd7.foreach(println)//3 10,11 6,5 2 2,7