Hadoopѧϰ���
- ǰ��:�����ݵĸ���
- һ��Hadoop����
- ����HDFS
- ����MapReduce
- �ġ�Yarn��Դ������
- �塢Hadoop�ۺϵ�����Դ�����
- �澭
- end
ǰ��:�����ݵĸ���
4��V:
- Volume(����):����Ŀǰ,��������������ӡˢ���ϵ���������200PB,����ʷ��ȫ�����ܹ�˵���Ļ�����������Լ��5EB����ǰ,�����˼����Ӳ�̵�����ΪTB����,�� һЩ����ҵ���������Ѿ��ӽ�EB������

- Velocity(����):���Ǵ����������ڴ�ͳ�����ھ������������������IDC�ġ��������桱�ı���,Ԥ�Ƶ�2025��,ȫ������ʹ�������ﵽ163ZB������˺�����������ǰ,�� �����ݵ�Ч�ʾ�����ҵ��������
��è˫ʮһ:2017��3��01��,��è�����100�� 2020��96��,��è�����100�� - Variety(����):�������͵Ķ�����Ҳ�����ݱ���Ϊ�ṹ�����ݺͷǽṹ�����ݡ�������������ڴ洢�������ݿ�/�ı�Ϊ���Ľṹ������,�ǽṹ������Խ��Խ��,����������־����Ƶ����Ƶ��ͼƬ������λ����Ϣ��,��Щ�����͵����ݶ����ݵĴ�����������˸���Ҫ��
- Value(�ͼ�ֵ�ܶ�):��ֵ�ܶȵĸߵ������������Ĵ�С�ɷ��ȡ���ο��ٶ��м�ֵ���ݡ��ᴿ����ΪĿǰ�����ݱ����´���������⡣
�������漰������ؼ�д��������:
- NN,NameNode:�����ڵ�
- DN,DataNode:���ݽڵ�
- RM, ResourceManager:��Դ������
- NM,NodeManager:�ڵ������
- 2NN,Secondary NameNode:�ڶ����ƽڵ�
- QJM,Quorum Journal Manager:Ⱥ����־������
- FC,Failover Controller:����ת�ƿ�����
- ZKFC:,Zookeeper Failover Controller:Zookeeper����ת�ƿ�����
һ��Hadoop����
1.����
1.1 Hadoop��ʲô?
Hadoop��һ����Apache������������ķֲ�ʽϵͳ�����ܹ�����Ҫ���:�������ݵĴ洢�ͷ�����������⡣(�����ݼ����漰����������:�������ݵ��ռ����洢�ͼ��㡣)
������Hadoopͨ��ָһ�����㷺�ĸ����Hadoop��̬Ȧ��

1.2 Hadoop��չ��ʷ
1)Hadoop��ʼ��Doug Cutting,Ϊ��ʵ����Google���Ƶ�ȫ����������,����Lucene��ܻ����Ͻ����Ż�����,��ѯ������������档

2)2001�����Lucene��ΪApache������һ������Ŀ��
3)���ں������ݵij���,Lucene��������Googleͬ��������,�洢������������,���������ٶ�����
4)ѧϰ��ģ��Google�����Щ����İ취 :�Ͱ�Nutch��
5)����˵Google��Hadoop��˼��֮Դ(Google�ڴ����ݷ������ƪ����):
GFS ��>HDFS
Map-Reduce ��>MR
BigTable ��>HBase
6)2003-2004��,Google�����˲���GFS��MapReduce˼���ϸ��,�Դ�Ϊ����Doug Cutting������
��2��ҵ��ʱ��ʵ����DFS��MapReduce����,ʹNutch���������
7)2005 ��Hadoop ��Ϊ Lucene������Ŀ Nutch��һ������ʽ����Apache����ᡣ
8)2006 �� 3 �·�,Map-Reduce��Nutch Distributed File System (NDFS)�ֱ����뵽 Hadoop ��Ŀ
��,Hadoop�ʹ���ʽ����,��־�Ŵ�����ʱ�����١�
9)������Դ��Doug Cutting���ӵ���ߴ���

1.3 Hadoop�����а汾
Hadoop �����а汾:Apache��Cloudera��Hortonworks��
Apache �汾��ԭʼ(�����)�İ汾,��������ѧϰ��á�2006
Cloudera �ڲ������˺ܶ�����ݿ��,��Ӧ��Ʒ CDH,PaaS��2008
Hortonworks �ĵ��Ϻ�,��Ӧ��Ʒ HDP,PaaS��2011
Hortonworks �����Ѿ��� Cloudera ��˾�չ�,�Ƴ��µ�Ʒ�� CDP��
1.4Hadoop������
-
1)�߿ɿ���:Hadoop�ײ�ά��������ݸ���,���Լ�ʹHadoopij������Ԫ �ػ�洢���ֹ���,Ҳ���ᵼ�����ݵĶ�ʧ��
-
2)����չ��:�ڼ�Ⱥ�������������,�ɷ���Ķ�̬��չ����ǧ�ƵĽڵ㡣
-
3)��Ч��:��MapReduce��˼����,Hadoop�Dz��й�����,�Լӿ��������ٶȡ�
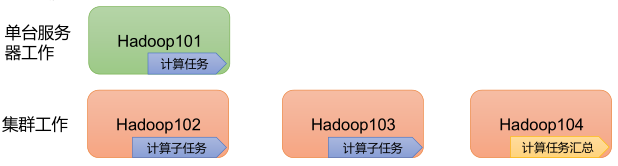
-
4)���ݴ���:�ܹ��Զ���ʧ�ܵ��������·��䡣

1.5Hadoop�����
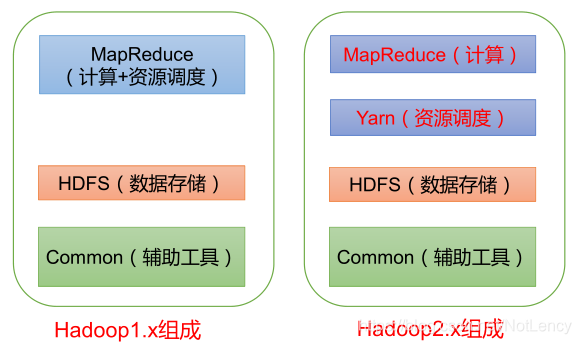
- �� Hadoop1.x ʱ �� ,Hadoop�е�MapReduceͬʱ����ҵ�����������Դ�ĵ���,����Խϴ�
- ��Hadoop2.xʱ��,������Yarn��Yarnֻ������Դ�ĵ��� ,MapReduceֻ�������㡣
- Hadoop3.x�������û�б仯
1.5.1 HDFS�ܹ�����
Hadoop Distributed File System,��� HDFS,��һ���ֲ�ʽ�ļ�ϵͳ��
- 1)NameNode(NN):�洢�ļ���Ԫ����,���ļ���,�ļ�Ŀ¼�ṹ,�ļ�����(����ʱ�䡢���������ļ�Ȩ��),�Լ�ÿ���ļ��Ŀ��б��Ϳ����ڵ�DataNode��(��һ������ʵ���ڼ�Ⱥ��������DataNode���л㱨����ȡ��,NameNode)��(ָ�����ݴ��ڵ�λ��)
- 2)DataNode(DN):�ڱ����ļ�ϵͳ�о���Ĵ洢�ļ�������,�Լ������ݵ�У��͡�(�������ݴ洢��λ��)
- 3)Secondary NameNode(2NN):ÿ��һ��ʱ���NameNodeԪ���ݽ��С����ݡ���(������NameNode�ġ����ݡ�)
1.5.2 YARN�ܹ�����
Yet Another Resource Negotiator ��� YARN ,��һ����ԴЭ����,�� Hadoop ����Դ��������
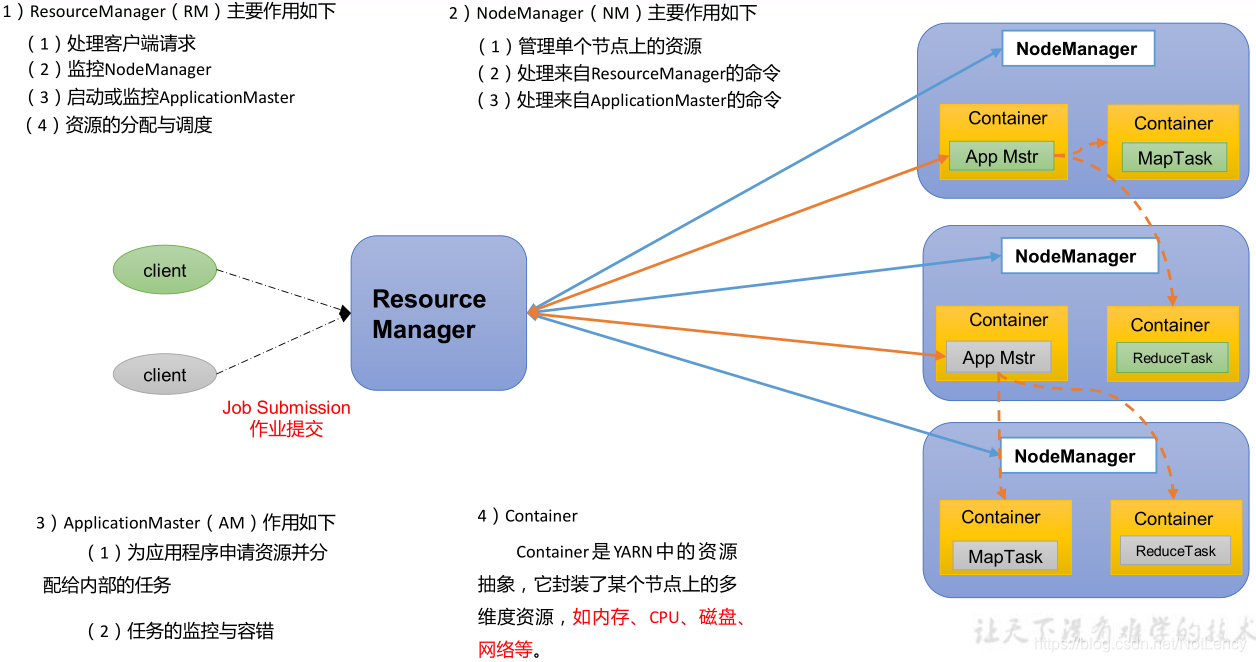
- 1)ResourceManager(RM):������Ⱥ��Դ(�ڴ桢CPU��)���ϴ�
- 2)NodeManager(NM):�����ڵ��������Դ�ϴ�
- 3)ApplicationMaster(AM):�����������е��ϴ�
- 4)Container:����,�൱һ̨�����ķ�����,�����װ��������������Ҫ����Դ,���ڴ桢CPU�����̡�����ȡ�
- ˵��1:�ͻ��˿����ж��
- ˵��2:��Ⱥ�Ͽ������ж��ApplicationMaster
- ˵��3:ÿ��NodeManager�Ͽ����ж��Container

1.5.3 MapReduce�ܹ�����
MapReduce ��������̷�Ϊ������:Map �� Reduce
- 1)Map �β��д������������
- 2)Reduce �ζ� Map ������л���
1.5.4 HDFS��YARN��MapRecduce����Ĺ�ϵ
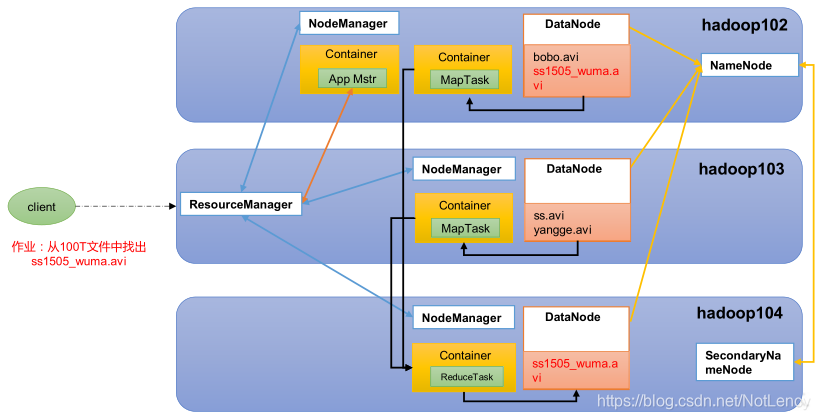
���ɿͻ���client�ύһ��Task��ResouceManager,RMѡ��һ̨�ڵ㽨��Container����Task��APP Mstr����,Ȼ��APP Mstrͨ������������RM���������Դ,RM����Ӧ�ļ�����Դ�����APP Mstr����MapTask�ļ���,����������½�һ��ReduceTask����Map Task�Ľ��,Ȼ������л��ܡ��洢������NameNode���м�¼,Ȼ��SecondaryNameNodeһ��ʱ���Ҳ�����NameNode�����ݽ��и��¡�
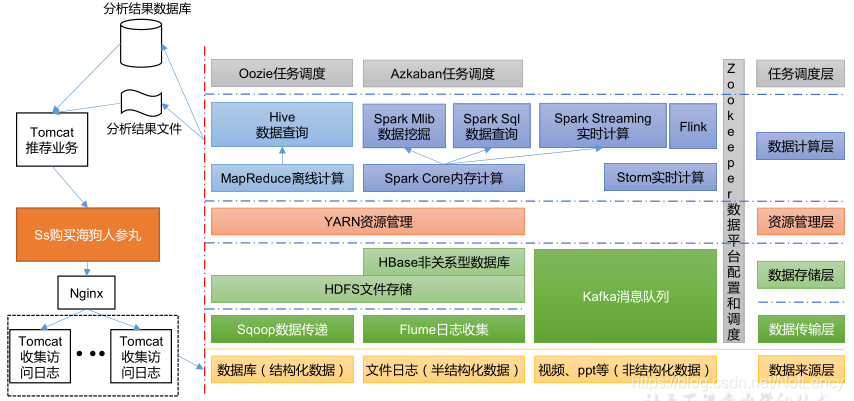
1.6�����ݼ�����̬��ϵ
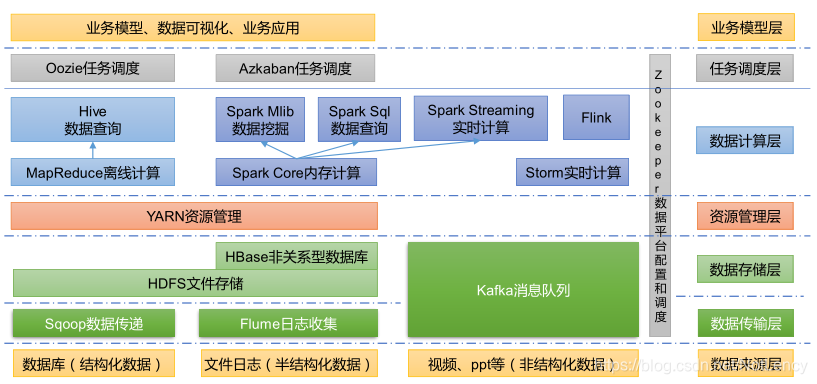
ͼ���漰�ļ������ʽ�������:
- 1)Sqoop:Sqoop ��һ�Դ�Ĺ���,��Ҫ������ Hadoop��Hive�봫ͳ�����ݿ�(MySQL)��������ݵĴ���,���Խ�һ����ϵ�����ݿ�(���� :MySQL,Oracle ��)�е����ݵ����� Hadoop�� HDFS ��,Ҳ���Խ� HDFS �����ݵ�������ϵ�����ݿ��С�
- 2)Flume:Flume ��һ���߿��õ�,�߿ɿ���,�ֲ�ʽ�ĺ�����־�ɼ����ۺϺʹ����ϵͳ,Flume ֧������־ϵͳ�ж��Ƹ������ݷ��ͷ�,�����ռ�����;
- 3)Kafka:Kafka ��һ�ָ��������ķֲ�ʽ����������Ϣϵͳ;
- 4)Spark:Spark �ǵ�ǰ�����еĿ�Դ�������ڴ�����ܡ����Ի��� Hadoop �ϴ洢�Ĵ����ݽ��м��㡣
- 5)Flink:Flink �ǵ�ǰ�����еĿ�Դ�������ڴ�����ܡ�����ʵʱ����ij����϶ࡣ
- 6)Oozie:Oozie ��һ������ Hadoop ��ҵ(job)�Ĺ������̵��ȹ���ϵͳ��
- 7)Hbase:HBase ��һ���ֲ�ʽ�ġ������еĿ�Դ���ݿ⡣HBase ��ͬ��һ��Ĺ�ϵ���ݿ�,����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ⡣
- 8)Hive:Hive �ǻ��� Hadoop ��һ�����ݲֿ��,���Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ�� SQL ��ѯ����,���Խ� SQL ���ת��Ϊ MapReduce ����������С����ŵ���ѧϰ�ɱ���,����ͨ���� SQL ������ʵ�ּ� MapReduce ͳ��,���ؿ���ר�ŵ� MapReduce Ӧ��,ʮ���ʺ����ݲֿ��ͳ�Ʒ�����
- 9)ZooKeeper:����һ����Դ��ͷֲ�ʽϵͳ�Ŀɿ�Э��ϵͳ,�ṩ�Ĺ��ܰ���:����ά�������ַ��ֲ�ʽͬ���������ȡ�
1.7�Ƽ�ϵͳ����
2. ������
(��һ�����PDF�Լ�˼ά��ͼ����ѧϰ��)
2.1ģ�����������
2.2��¡
2.3��װJDK�Լ�Hadoop
3.Hadoop������Ⱥ�
(��һ�����PDF�Լ�˼ά��ͼ����ѧϰ��)
3.1����ģʽ
3.2��ȫ�ֲ�ʽ��Ⱥ�(���������Ե��ص�)
4.��������Ľ������
(��һ�����PDF�Լ�˼ά��ͼ����ѧϰ��)
����HDFS
1.HDFS����
1.1HDFS�IJ��������Ͷ���
- ����:����������Խ��Խ��,��һ������ϵͳ�治�����е�����,��ô�ͷ��䵽����IJ���ϵͳ�����Ĵ�����,���Dz����������ά��,������Ҫһ��ϵͳ��������̨�����ϵ��ļ�,�� ���Ƿֲ�ʽ�ļ�����ϵͳ��HDFSֻ�Ƿֲ�ʽ�ļ�����ϵͳ�е�һ�֡�
- ����:HDFS(Hadoop Distributed File System),����һ���ļ�ϵͳ,���ڴ洢�ļ�,ͨ��Ŀ¼������λ�ļ�;���,���Ƿֲ�ʽ��,�ɺܶ��������������ʵ���书��,��Ⱥ�еķ��� ���и��ԵĽ�ɫ��
- HDFS ��ʹ�ó���:�ʺ�һ��д��,��ζ����ij�����һ���ļ�����������д��ر�֮��Ͳ���Ҫ�ı�
1.2��ȱ��
�ŵ�:
- 1)���ݴ��� �����Զ���������������ͨ�����Ӹ�������ʽ,����ݴ��ԡ�ijһ��������ʧ�Ժ�,�������Զ��ָ���
- 2)�ʺϴ��������� ���ݹ�ģ:�ܹ��������ݹ�ģ�ﵽGB��TB������PB���������; �ļ���ģ:�ܹ����������ģ���ϵ��ļ�����,�����൱֮��
- 3)�ɹ��������ۻ�����,ͨ���ั������,��߿ɿ��ԡ�
ȱ��:
- 1)���ʺϵ���ʱ���ݷ���,������뼶�Ĵ洢����,���������ġ�
- 2)����Ч�ĶԴ���С�ļ����д洢���洢����С�ļ��Ļ�,����ռ��NameNode�������ڴ����洢�ļ�Ŀ¼�Ϳ���Ϣ�������Dz���ȡ��,��ΪNameNode���ڴ���������;С�ļ��洢��Ѱַʱ��ᳬ����ȡʱ��,��Υ����HDFS�����Ŀ�ꡣ
- 3)��֧�ֲ���д�롢�ļ�����ġ�һ���ļ�ֻ����һ��д,����������߳�ͬʱд;��֧������append(��),��֧���ļ�������ġ�
1.3���
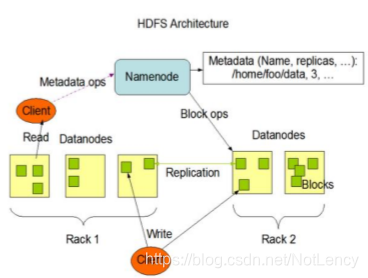
1)NameNode(NN):����Master,����һ�����ܡ�������,�洢��������Ⱥ�������ݵ������Ϣ��
(1)����HDFS�����ƿռ�;
(2)���ø�������;
(3)�������ݿ�(Block)ӳ����Ϣ;
(4)�����ͻ��˶�д����
2)DataNode:����Slave��NameNode�´�����,DataNodeִ��ʵ�ʵIJ�����
(1)�洢ʵ�ʵ����ݿ�;
(2)ִ�����ݿ�Ķ�/д����
3)Client:�ܹ���HDFS�ļ�ϵͳ���в����ĵط��͵ȼ��ڿͻ��ˡ�
(1)�ļ��з֡��ļ��ϴ�HDFS��ʱ��,Client���ļ��зֳ�һ��һ����Block,Ȼ������ϴ�;
(2)��NameNode����,��ȡ�ļ���λ����Ϣ;
(3)��DataNode����,��ȡ����д������;
(4)Client�ṩһЩ����������HDFS,����NameNode��ʽ��;
(5)Client����ͨ��һЩ����������HDFS,�����HDFS��ɾ��IJ���;
4)Secondary NameNode:����NameNode���ȱ�����NameNode�ҵ���ʱ��,�������������滻NameNode���ṩ����
(1)����NameNode,�ֵ��乤����,���綨�ںϲ�Fsimage�����ļ���Edits,������NameNode ;
(2)�ڽ��������,�ɸ����ָ�NameNode��
1.4�ļ����С(�����ص�)
HDFS�е��ļ����������Ƿֿ�洢(Block),��Ĵ�С����ͨ�����ò���( dfs.blocksize)���涨,Ĭ�ϴ�С��Hadoop2.x/3.x�汾����128M,1.x�汾����64M��
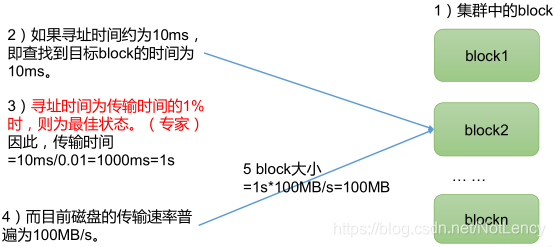
˼��:Ϊʲô��Ĵ�С��������̫С,Ҳ��������̫��?
(1)HDFS�Ŀ�����̫С,������Ѱַʱ��,����һֱ���ҿ�Ŀ�ʼλ��;
(2)��������õ�̫��,�Ӵ��̴������ݵ�ʱ������Դ��ڶ�λ����鿪ʼλ�������ʱ�䡣���³����ڴ����������ʱ,��dz�����
�ܽ�:HDFS��Ĵ�С������Ҫȡ���ڴ��̴�������,��
2.HDFS��Shell��ز���(���������ص�)
2.1 �����
2.1.1 �ϴ�
hadoop fs + ���� === hadoop dfs + ����
1)-moveFromLocal:�ӱ��ؼ���ճ���� HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
����:
shuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
2)-copyFromLocal:�ӱ����ļ�ϵͳ�п����ļ��� HDFS ·��ȥ
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
����:
weiguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:��ͬ�� copyFromLocal,����������ϰ���� put
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
����:
wuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:��һ���ļ����Ѿ����ڵ��ļ�ĩβ
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
����:
liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2.1.2 ����
1)-copyToLocal:�� HDFS ����������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:��ͬ�� copyToLocal,����������ϰ���� get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
2.1.3 HDFSֱ�Ӳ���
1)-ls: ��ʾĿ¼��Ϣ
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:��ʾ�ļ�����
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp��-chmod��-chown:Linux �ļ�ϵͳ�е��÷�һ��,���ļ�����Ȩ��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4)-mkdir:����·��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:�� HDFS ��һ��·�������� HDFS ����һ��·��
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:�� HDFS Ŀ¼���ƶ��ļ�
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:��ʾһ���ļ���ĩβ 1kb ������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:ɾ���ļ����ļ���
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:�ݹ�ɾ��Ŀ¼��Ŀ¼��������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du ͳ���ļ��еĴ�С��Ϣ
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
˵��:27 ��ʾ�ļ���С;81 ��ʾ 27*3 ������;/jinguo ��ʾ�鿴��Ŀ¼
11)-setrep:���� HDFS ���ļ��ĸ�������
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
�������õĸ�����ֻ�Ǽ�¼�� NameNode ��Ԫ������,�Ƿ���Ļ�����ô�ั��,���ÿ� DataNode ����������ΪĿǰֻ�� 3 ̨�豸,���Ҳ�� 3 ������,ֻ�нڵ��������ӵ� 10̨ʱ,���������ܴﵽ 10��
3.HDFS�Ŀͻ���API
3.1���ݵ��ϴ�������
4.HDFS�Ķ�д����(�����ص�)
4.1 �������
4.1.1 �����ļ�д�������
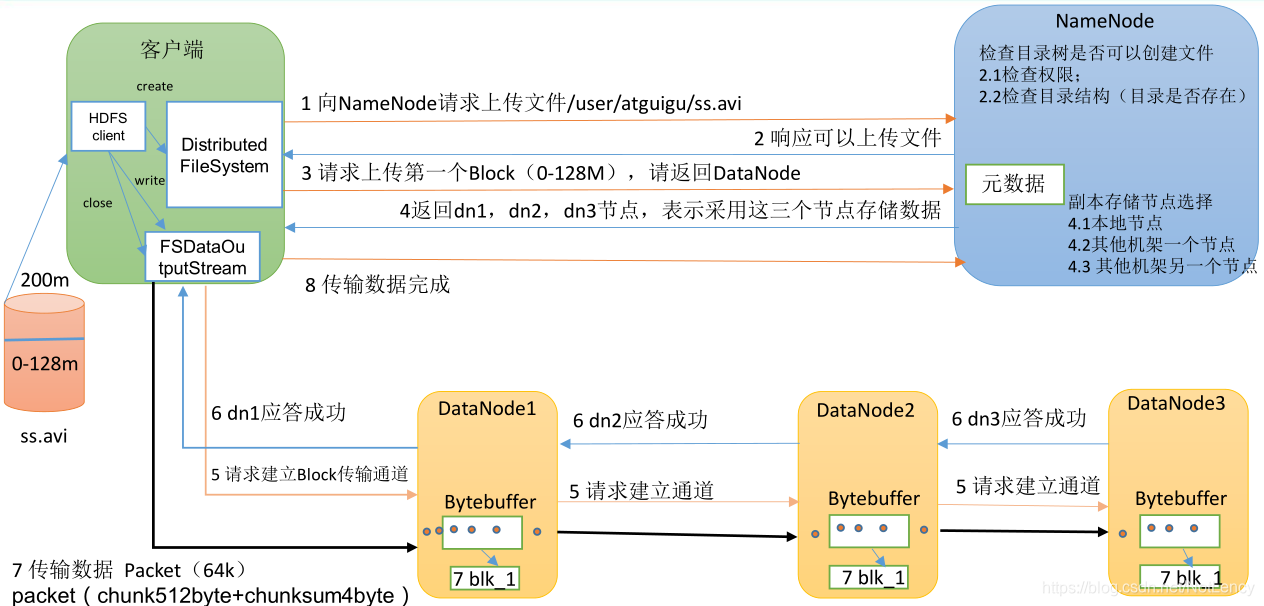
�����ļ���Ҫ�ϴ���HDFS��:
- 1)����Client�����ֲ�ʽ���ļ�ϵͳ����Distributed FileSystem,���ļ����зֲ�ʽ�ļ�ϵͳת��(���ﻹ��̫����,������ָ���ļ�Ԥ�����ɷ���HDFS�ļ�ϵͳ��Block�Ĵ�С��),����NameNode�����ϴ��ļ�����
- 2)NameNode���յ����������Ȩ���,���Ȼ�������ͻ�����û�н����ϴ�������Ȩ��,��������ϴ������ĺ�����,����˵:�ϴ���Ŀ��·���Ƿ���ڵ�,�Լ����������Ϣ�����һ�кϷ�,��ôNameNode������Client������Ӧ�����ϴ���
- 3)Client���յ������ϴ�����Ӧ��,�����ϴ���һ���ļ���,����NameNode����DataNode��λ�á�
- 4)NameNode���и����洢�ڵ�ѡ����Խ��д洢�ڵ��ѡ��,�����������ԭ���ǵ����ؾ�������ؽ���ѡ��洢�ڵ��ѡ��,���һᾡ���ܵ�ѡ��ͬһ���ܽ��д洢��
- 5)Client���յ�NameNode�Ĵ洢λ�õ���Ӧ��,���Ȼ����������DataNode����������ͨ���������ݴ���,Ȼ�����DataNode�������⼸�����ڴ洢��DataNodeͨ���ݹ�ķ�ʽ��˳�������ݴ���ͨ�������ݴ���Ĺ���Ϊ:����,Client�ڱ��ؽ������ݴ����������,���д洢����chunk��СΪ516B(���а���512B��chunk�Լ�4B����У���chunksum),Ȼ���ܹ�127��chunk,Ҳ����64KBʱ,������HDFS�������ݴ������С��λPacket��Ȼ����ŵ���һ����������еȴ�����,ͬʱ���ڱ����ڽ���һ���������,���ڱ��淢���˵�Packet,�Է���Ϊ����ԭ����ɵĶ���,ֻ�е�ȷ����DataNode���ص�ack��Ϣ��ŻὫ��Ӧ��Packetɾ����
- 6)��DataNode���յ�Client��������Packet��,һ�ǽ��䱣�浽����,����ͬʱ�������ݴ��佫�䴫����һ��DataNode������ÿ��Packet���ܳɹ������ϼ�����һ��ack��Ϣ,����DataNode�IJ�������ͬ��
- 7)������ݴ�������г��ֶ���������,��ʱClient���ڻ��������Ѱ�Ҷ�Ӧ��Packet���½��з��͡�
- 8)���ݴ������,�ͷ���Դ��
4.1.2 �������ˡ����ڵ�������
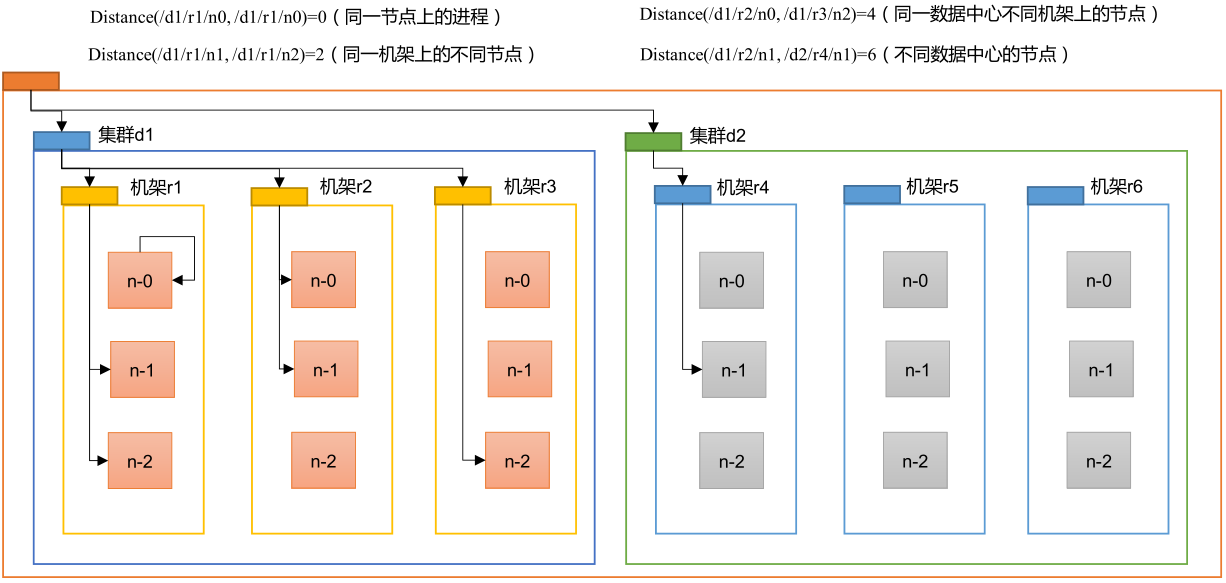
�� HDFS д���ݵĹ�����,NameNode ��ѡ�������ϴ������������� DataNode �������ݡ���ô������������ô������?
�ڵ����:�����ڵ㵽������Ĺ�ͬ���ȵľ����ܺ͡�
4.1.3 ���ܸ�֪(�����洢�ڵ�ѡ��)
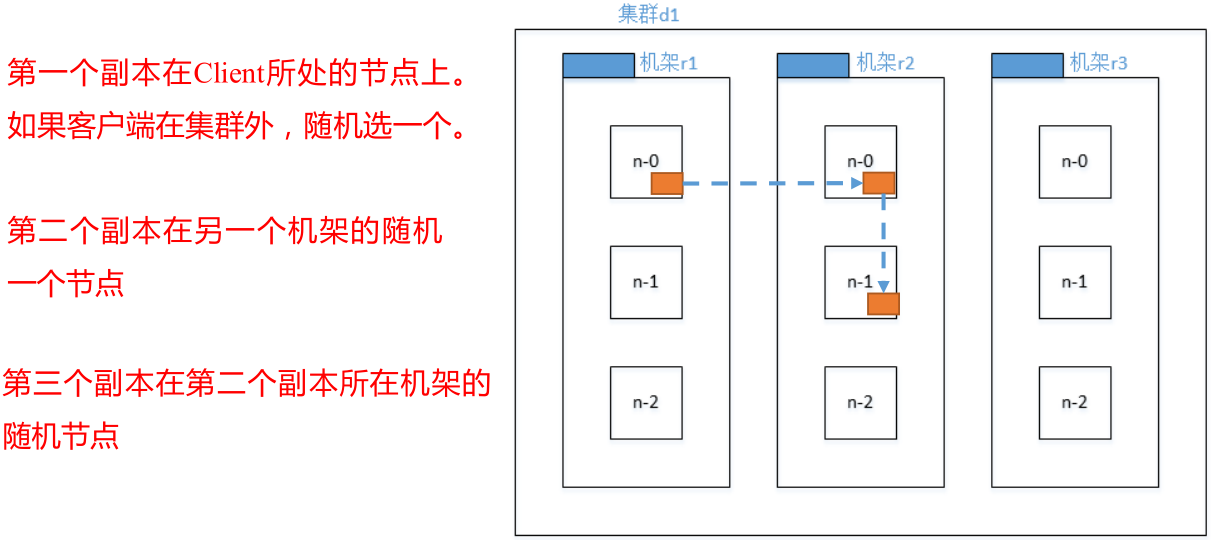
���ݵ�����Ϊ3��ʱ��:
- 1)��һ���ڵ�ѡ����������ԭ��,ѡ��ִ���ϴ��������һ̨Client������λ��,�ϴ��Ͽ�;����ϴ��������ڼ�Ⱥ��Ļ�����ִ�е�,��ô���ڼ�Ⱥ�����ѡһ̨����Ȼѡ��Ľ������Ҫ���ǽڵ��״̬(isGoodTarget()����),��������Ƿ��㹻���������������ýڵ����ڵĻ����д�ŵ�ǰ���ݵ�DN�Ƿ����;
- 2)�ڶ����ڵ������ܵ�ѡ�����һ���ڵ㲻ͬ�Ļ����ϵ����һ���ڵ���д洢,Ϊ�����ݵĿɿ��ԡ������,�����ܵ�ѡ��û�гɹ�,��ѡ�����һ���ڵ�ͬ�����ϵ�һ���ڵ㡣
- 3)�������ڵ�:���ǰ�����ڵ���ͬһ����������,��ô�����ܵ�ѡ�������Dz�ͬ�ĵĻ���,����ͬ�ڶ����ڵ��ѡ�����һ�����������newBlock(���������Ϊ������ʲô�������)Ϊtrue��ѡ����ڶ����ڵ�ͬ���ܵĽڵ㡣����ѡ�����һ���ڵ�ͬ�����ϵ�һ���ڵ㡣
- �Ǽ�Ȼ��Ϊ�˿ɿ�������,�ǵ������ڵ�Ϊʲô������ѡһ�����ܽ��д洢��?������Ϊ�˼�˴���Ч��,�Ͼ���ͬ�����ڲ����д����ٶȽϿ졣
- ��һ���ֵ�ʵ��ΪԴ��hadoop-hdfs:3.1.3��BlockPlacementPolicyDefault����chooseTargetInOrder()������
���������������3��������?��ôѡ��ڵ�?
- ����ǰ�����ڵ�ѡ��ķ�ʽ��������ͬ,ʣ����Ŀ�ĸ���ѡ��������һ����Χ�ڽ������ѡ��,�����������chooseRandom(),Դ������λ����������ͬ,֮��������ݴ�����Ż����pipeline(��ʲô��˼?)��
- ��ʵǰ�����ڵ��ѡ����Ե�ʵ��,Ҳ�ǻ���chooseRandom()ʵ�ֵ�,ͨ���ı�һ�����������ƽڵ����ѡ��ķ�Χ��
- �ο�:https://www.cnblogs.com/gwgyk/p/4137060.html
4.2 HDFS����������

���ؿͻ�����Ҫ�Ӽ�Ⱥ����ȡ����:
- 1)�ͻ���Client�Ƚ���һ���ֲ�ʽ�ļ�ϵͳ����Distributed File System,���ںͼ�Ⱥ�е�NameNode�ͨ��,��NameNode�����������ļ�����Ϣ��
- 2)NameNode�жϴ˿ͻ����Ƿ���Ȩ������ز���,���Ҳ�ѯ��Ӧ�������ڵ�DataNode��λ����Ϣ,���ظ��ͻ���Client��Distributed File System����
- 3)�ͻ���Ҫ�������ݵĴ���,��Ҫ�Ƚ���һ���ļ�������FSDataInputStream�����ͻ���Client�����DataNode���ʹ������ݵ�����
- 4)DataNodeͨ�������Լ��ĸ�������������Ƿ����Client��������,��������������,��ͬ��������ݵĴ���;����,�ܾ�����ʱ�ͻ��˽�����һ���洢�������ļ���DataNode��������,����ͬ���IJ�����
- 5)�ڶ����ݵĹ�����,�������������һ��HDFS�洢Block,��ô�ڶ������ݿ�Ķ�ȡ����ͬ��4���е�һ������Ҫע�����,�ڴ��������ͬһ�ļ����������ݿ鴫���ϵ�Ǵ��е�,��ȡ����һ����,�ſ�ʼ��һ����Ĵ��䡣
- 6)����ͷ���Դ��
5.NN��2NN(�����ص�)
(����ʵ����ҵʵ�������Dz���2NN,���ǻ�����NameNode�ĸ߿���,����NameNode��)
��ͼ����NN�����洢����Ϣ:
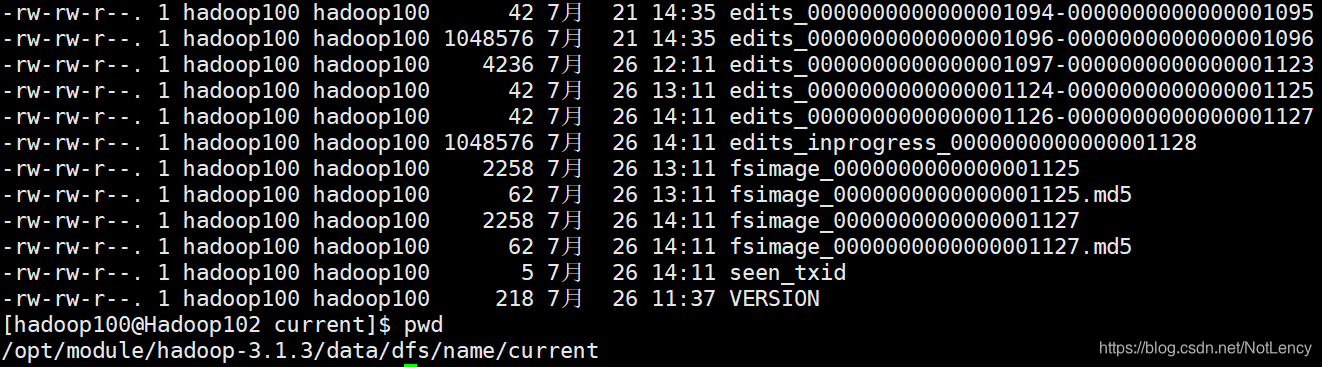
- edits����־�ļ�(��¼��DataNode���еIJ���,ֻ�����Ӳ���,Ч�ʺܸ�)
- edits_inprogress�ǵ�ǰ���ڸ����¼����־�ļ�
- fsimage��Ӧ�������ľ����ļ�
- seen_txid�д洢�˵�ǰ������־�ļ������
- VERSION���ǵ�ǰ��Ⱥ�İ汾��Ϣ
2NN�е���������ͼ:
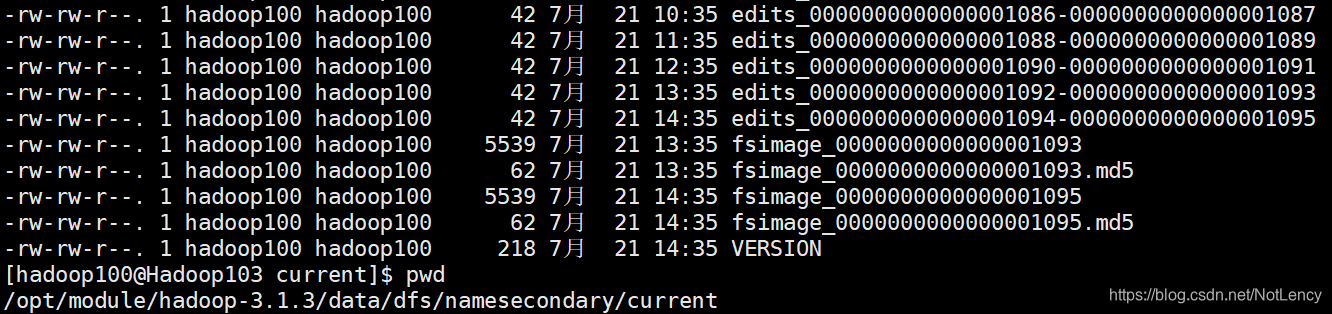
- edits��fsimage�Լ�VERSION������NN��һ��
˼��:NameNode �е�Ԫ�����Ǵ洢�������?
- ����,������������,����洢�� NameNode �ڵ�Ĵ�����,��Ϊ������Ҫ�����������,������Ӧ�ͻ�����,��Ȼ��Ч�ʹ��͡����,Ԫ������Ҫ������ڴ��С�
- �����ֻ�����ڴ���,һ���ϵ�,Ԫ���ݶ�ʧ,������Ⱥ���������ˡ���˲����ڴ����б���Ԫ���ݵ� FsImage �����ļ���
- ���������ֻ�����µ�����,���� NameNode �ڴ��е�Ԫ���ݸ���ʱ,���ͬʱ���� FsImage,�ͻᵼ��Ч�ʹ���,�����������,�ͻᷢ��һ��������,һ�� NameNode �ڵ�ϵ�,�ͻ�������ݶ�ʧ��
- ���,���� Edits ��־�ļ�(��¼��DataNode���еIJ���,ֻ�����Ӳ���,Ч�ʺܸ�)��ÿ��Ԫ�����и��»�������Ԫ����ʱ,���ڴ��е�Ԫ���ݲ��ӵ� Edits �С�����,һ�� NameNode �ڵ�ϵ�,����ͨ�� FsImage �� Edits �ĺϲ�,�ϳ�Ԫ���ݡ�(һ��������Hadoop��Ⱥʱ�ͻ�����������)
- ����,�����ʱ���������ݵ� Edits ��,�ᵼ�¸��ļ����ݹ���,Ч�ʽ���,����һ���ϵ�,�ָ�Ԫ������Ҫ��ʱ����������,��Ҫ���ڽ��� FsImage �� Edits �ĺϲ�,������������ NameNode �ڵ����,�ֻ�Ч�ʹ��͡����,����һ���µĽڵ� SecondaryNameNode,ר������ FsImage �� Edits �ĺϲ���
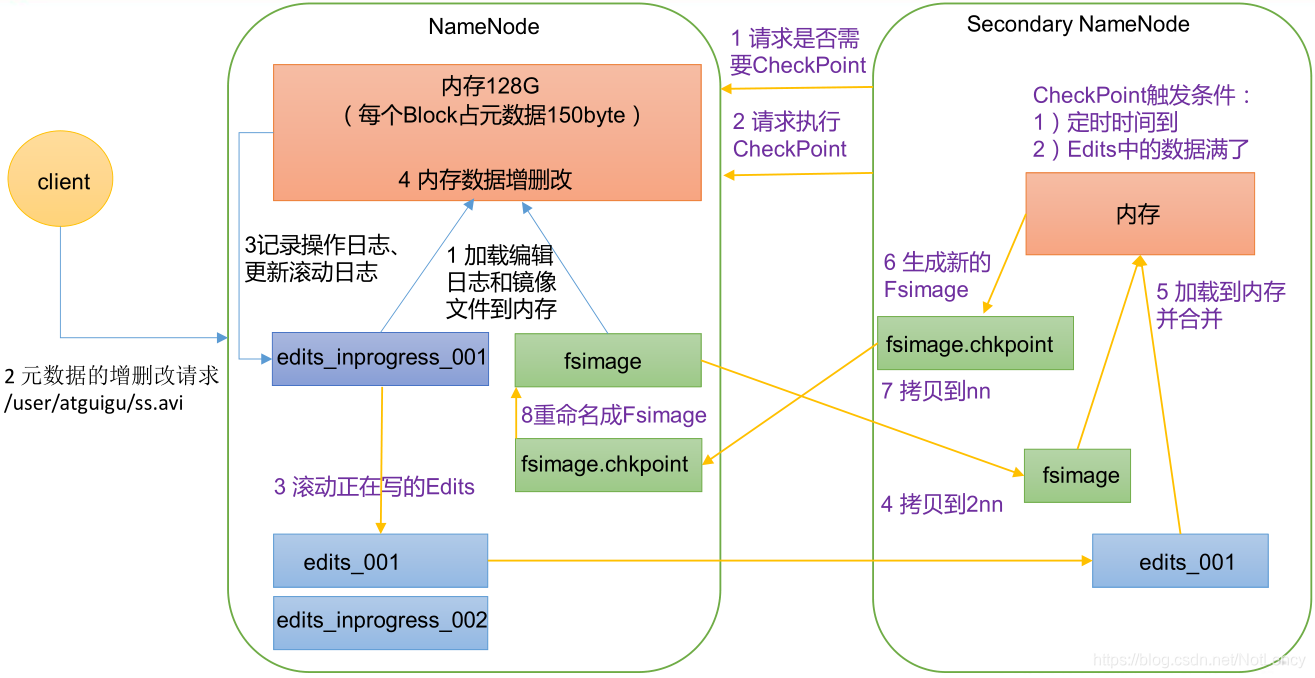
- 1)��Ⱥ����ʱ,������һ�ε�edits_inprogress_001������־�ļ��Լ�fsimageԪ���ݾ����ļ���
- 2)����Client�����IJ�������,����ʹ��edits_inprogress_001���м�¼,��ԭ�еIJ����Ͻ��к�����,Ȼ���ٻ���ж�Ԫ����ʵ�ʵ��ڴ������
����SecondaryNameNode:
- 1)�ڼ�Ⱥ���������ᶨʱ����NameNode��������鿴�Ƿ���Ҫִ��CheckPoint�ϲ���־����,�ֻ��ߴﵽ��CheckPoint�����Ĵ�������(��ʱʱ�䵽,Ĭ����1��Сʱ;��־�ļ��д洢��100��������,2NNÿ��1���Ӳ�ѯNNһ�������в�����������),2NN���ִ��CheckPoint������
- 2)����,��NameNode������һ��edits_inprogress_002�ļ����ڴ洢�ڽ��кϲ����������в�����Ԫ���ݲ�����־,ԭ����edits_inprogress_001����Ϊedits_001��NameNode�ϵ�fsimage�����ļ�һ����2NN�����ڽ��кϲ�������
- 3)��2NN�н�edits_001��fsimage���ڴ�����ɺϲ���,�����µ�fsimage.checkpointԪ���ݾ����ļ�,�����俽����NameNode,���������Ϊfsimage���ǵ��ɵ�fsimage�ļ���
6.DataNode
6.1 DataNode��������
DataNode�д洢���ļ�����ͼ:
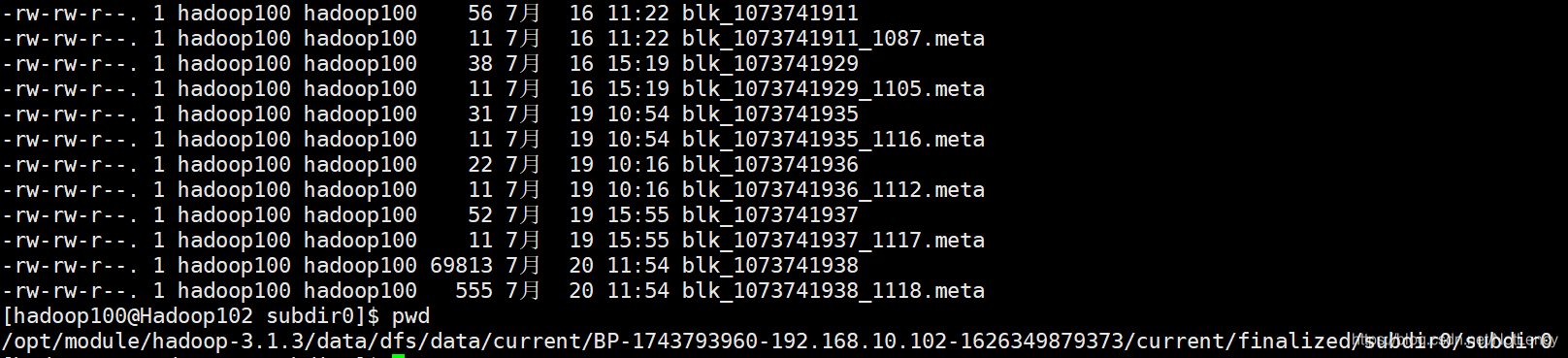
- blk.meta�Ƕ�Ӧblk�ļ��ļ����ļ�,����洢�˶�Ӧ���ݿ����ݳ��ȡ�У��͡�ʱ�������Ϣ��
- blk�Ǵ洢���ļ����ݵı�����
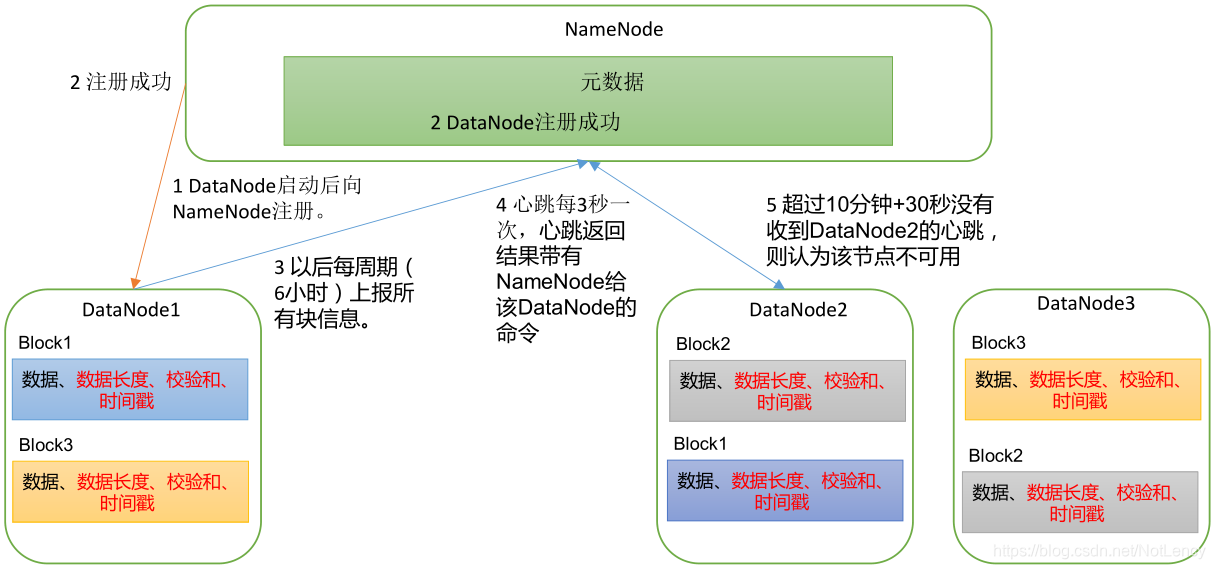
- 1)��Ⱥ������֮��,DataNode������NameNode������Ϣע��,���Լ���ǰ���������洢����Щ�ļ�����Щ��㱨��NameNode��
- 2)NameNode��ʱ�ͻὫ�㱨������Ϣ�洢���Լ����ڴ���,��������,���ҷ��ظ�DataNodeһ��ע��ɹ�����Ϣ��
- 3)DataNode�Ժ�Ĭ��ÿ��6��Сʱ(����㼯Ⱥ�����ܱȽϲ�,���ʱ���������)�ͻ������ϱ��Լ����洢�Ŀ��������Ϣ,���ڸ��¡�����֮��ÿ��DataNodeÿ��3������NN����������,֤���Լ�������������
- 4)���һ��DataNode����10���� + 30�뻹û����NN����������,NN����Ϊ���DN���������ˡ���������ز����ͻ�ܿ����DN��10�����ǿ��ǵ����DataNode��������æ�ڴ������MapReduce����,30�����Ǹ���10������ʱ�䡣
6.2 ����������
��DN���ػ�����ݽ���CRC-32У������У����,��Client��DN��������ʱ,�Ὣ����������Լ����ɵ�У����Ϣһͬ����Client,Ȼ��Client�ڱ�����ʹ��CRC-32ѭ��У�����ɼ�����,�鿴��DN���������Ƿ�һ��,������ж������Ƿ�����
6.3 ����ʱ��������
��DN���ػ�����ݽ���CRC-32У������У����,��Client��DN��������ʱ,�Ὣ����������Լ����ɵ�У����Ϣһͬ����Client,Ȼ��Client�ڱ�����ʹ��CRC-32ѭ��У�����ɼ�����,�鿴��DN���������Ƿ�һ��,������ж������Ƿ�����
7.HDFS���IJ�������
�����������Ƽ�����һ��ʼ���ü�Ⱥ��ʱ����в���,��Ϊ�漰����μ�Ⱥ������
��ϸ�����ò����鿴PDF06,�����������:
- 1)�ڵ���NameNode��DataNode������ռ���ڴ��С
- 2)����NameNode�����ڴ�����ͬ DataNode �IJ��������Լ��ͻ��˲�����Ԫ���ݲ������߳�����
- 3)��ʼ����վ����(��ҳ���ֶ�ɾ�������ݲ���ŵ�����վ��,������ɾ����Ҳ����ŵ�����վ,�ڳ�������Ҫ����moveToTrash()�����ŻὫ����ɾ��������վ)
- 4)��Ⱥѹ������(д���Ի�����������Ĵ����ٶ�,�����Ե��ٶȿ�������ύλ�ú����ݵĴ洢λ���Ƿ�ͬʱ������ͬһ���ڵ�,�����ֻ�����ڴ����ٶ�,��Ļ������������ٶ�)
- 5)HDFS��Ŀ¼����:
- NameNode��Ŀ¼����(��ֻ�ǰ�namenode�����ݸ�����һ��,���namenode���ڵĽڵ�崻�,��Ⱥһ�������)
- DataNode��Ŀ¼����,�����Ŀ¼ÿ��Ŀ¼�洢�����ݶ���ͬ,������չDataNode�����Ĺ��ܡ����Խ��д�����չ�ʹ��̾��������
- 6)HDFS��Ⱥ�����ݺ�����
- ���úڰ�����
- ��̬�����·�����
- �ڵ�����ݾ���
- ����������
- 7)HDFS�洢�Ż�
- ʹ�þ�ɾ�뽵�ʹ洢�������õĿռ�,���Ǵ����ǻ�����CPU�ļ�������
- �칹�洢(�������ݴ���),����ʹ�õġ�����ʹ�õġ�������ʹ�õġ����ñ��������,Ӧ�÷ֱ�洢�ڲ�ͬ�Ľ����С���������������һ��ʼ�Ͷ�HDFS��Ŀ¼���÷���,ÿ��Ŀ¼�д洢��ͬ�����͵�����,���������ü�Ⱥʱ,ҲҪ���ú�ÿ���ڵ��Ǹ�·����ʹ�õ�ʲô���Ĵ洢����,���ִ洢�����ʺ����������
- 8)HDFS�����ų�
- NameNode����ҵ���ô����,��SecondaryNameNode�����ݸ��Ƶ�NameNode,���Ի�ԭһ���̶��ϵ����ݡ�
- ��ȫģʽ
- �����̼��
- С�ļ��鵵
- 9)HDFS��ȺǨ��
����MapReduce
1.MapReduce����
1.1 ���塢����������
MapReduce ��һ���ֲ�ʽ�������ı�̿��,���û����������� Hadoop �����ݷ���Ӧ�á��ĺ��Ŀ�ܡ�
MapReduce ���Ĺ����ǽ��û���д��ҵ����������Դ�Ĭ��������ϳ�һ�������ķֲ�ʽ�������,����������һ�� Hadoop ��Ⱥ�ϡ�
�ŵ�:
- 1)���ڱ��,�û�ֻ�����Լ���Ҫ��ҵ����,Ȼ��ʵ�ֿ�ܵĽӿ�,�Ϳ�����ɷֲ�ʽ����
- 2)���õ���չ��,���Զ�̬�����ӷ�������
- 3)���ݴ���,MapReduce ��Ƶij��Ծ���ʹ�����ܹ����������۵� PC ������,���Ҫ�������кܸߵ��ݴ��ԡ���������һ̨��������,����������ļ�������ת�Ƶ�����һ���ڵ�������,�����������������ʧ��,����������̲���Ҫ�˹�����,����ȫ����Hadoop�ڲ���ɵġ�
- 4)�ʺϺ������ݵļ���(TB/PB),��ǧ̨��������ͬ���㡣
ȱ��:
- 1)���ó�ʵʱ����
- 2)���ó���ʽ����(SparkStreaming��flink�ʺ�)
- 3)���ó�DAG������ͼ����(�����Dz���),Ҳ���Ǵ���ʽ����ʽ��������,ǰ�����������֮��,�������������չ����(spark�ó�,��Ϊspark�ǻ����ڴ�ļ����ٶȿ�,��MapReduce�ǻ���Ӳ�̵ļ����ٶ�����)
1.2 MapReduce����˼��
WordCount����

1.3 MapReduce��������(�����ص�)
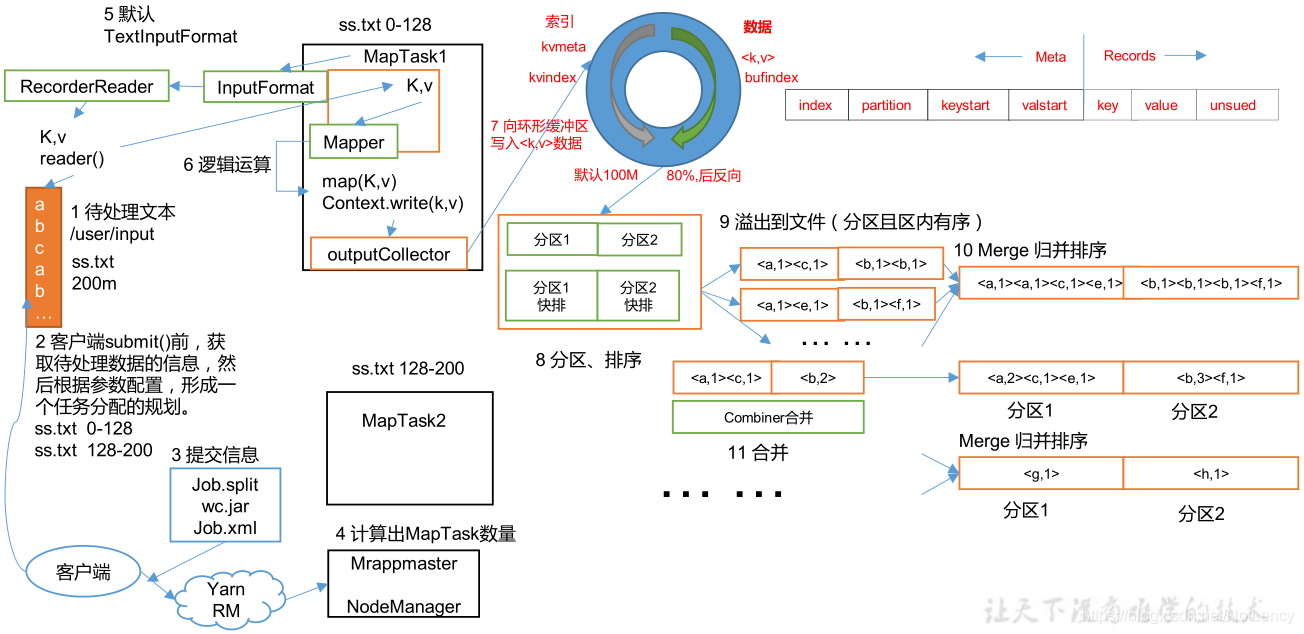
- ���ô��������ݡ�
- �ͻ����ڽ���job��submit()ǰ,��ȡ���������ݵ���Ϣ,���ݲ�������,�γ�һ���������Ĺ滮������Ƭ���á���Ⱥ�������á��Լ������jar����
- �ύ��Ϣ,�����YARN��Ⱥģʽ��������Ļ�,������Ҫ������jar����job.split������Ƭ���á��Լ���Ⱥ������������job���ύClient�ͻ����ϴ�����Ⱥ�С�(����DZ���ģʽ�Ļ�,Jar�������ϴ���)
- ����ύ��,YARN�Ὺ��һ���ܹ�job��MrAppMaster���ڹܿ�����job��������������ȶ�ȡClient�ϴ���������Ϣ,������Ӧ������MapTask,����NodeManager�����в���,��ִ������
- MapTask������֮��ʼʹ��InputFormat����ȡ����,Ĭ����ʹ��TextInputFormat����ȡ��,��������������,RecorderReader()��isSplitedable()�����������ݵĶ�ȡ��ʽ���ж������Ƿ�����з֡�TextInputFormat�е�RecorderReaderʵ�ֵ���LineRecorderReader,Ҳ���ǰ��ж�ȡ��Ϣ,��������Ϣ��ƫ������ΪK,�Լ�����Ϣ��������ΪV,����<K, V>�Է��ظ�jar����(������������)��Mapper��
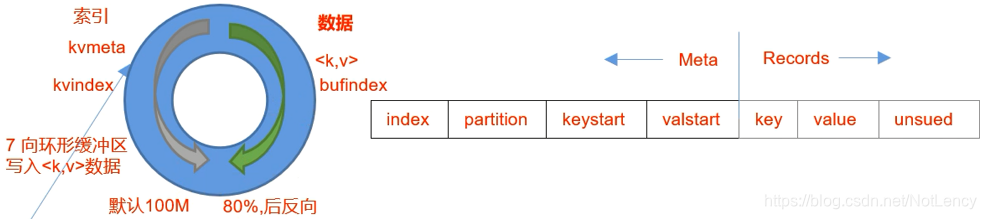
- ��Mapper�ж�<K, V>���ݶ�����û��Զ�������ݲ���֮��(�����Ƶ��������������������),���Context���ݽ���outputCollector�ռ����ڴ��еĻ��λ�������
- �ڻ��λ�������,һ��洦���õ�<K, V>���ݶ�,��һ�ߴ��Ӧ���ݵ��������߽��������ݵ�Ԫ����,Ԫ�����д洢�����ݵ�����index,�������������� partition = (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks (��������ʲô?��:��������ֵ��е�һ��,����˵�����ֽ�������0��4����Ϊһ������,5��9����һ������������),<K,V>���ݶ�Kֵ�Ŀ�ʼλ��keystart,<K,V>���ݶ�Vֵ�Ŀ�ʼλ��valstart��(���λ�����Ĭ�ϴ�СΪ100m,�����д洢����Ϣռ��������80%ʱ,���ݻᷴ����д洢,�����Ѿ�д�����80%�����ݾͿ��Կ�ʼ�������д�롣����������λ������Ϳ���һֱ��ͣ�Ĺ���,������ͣ�����ȴ������������д�롣)
- ��д�뵽�����е�ʱ��֮ǰ,��ʹ�������Է����ڵ����ݽ�������,��������ʱ�ı��������д�����ѭ��(����,keystart��valstart��ʼλ��),������ʵ�ʵ����ݴ洢λ�á�
- д�뵽���̺�,ÿһ���ļ������ж������������������ġ���ͬ�ķ����ں����Ĵ����л�������ͬ��Reducer��
- Ȼ����ʹ�ù鲢�����㷨(���Ѿ������˵����ݽ�������ʹ�ù鲢�����ȽϿ�),������ļ��ϲ���һ�������������γɵ��ļ�����������,��������ġ�
- ��ʱ��������ǰʹ��Combiner��һЩͬKeyֵ�����ݶԺϲ�,���Ż������á�
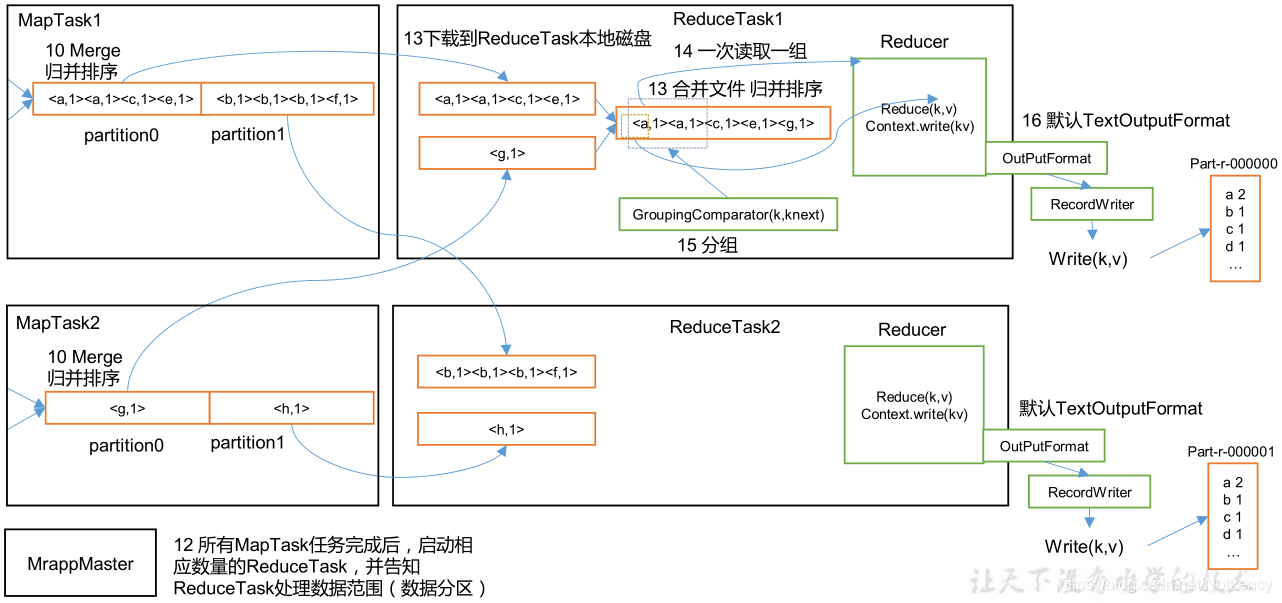
- �����л��߲��ֵ�MapTask������ɺ�,������Ӧ������ReduceTask,����֪ReduceTask�������ݵķ�Χ(���ݷ���)��
- ReduceTask����������MapTask���Լ�����ķ����е�������ȡ����,��ʱ���ͳһ���������ݶ������������,�������ǻ���Ҫ����һ���鲢����,�����DZ����������ġ�
- �������ǵ������Ѿ������ͬһ�����������������,�����ں��洫�䵽Reduce�����н�����ͬKֵ�����ݵ���Ŀͳ��ʱ,�������ж�ǰ�������������Dz��Ǿ�����ͬ��Kֵ��,��ΪKֵ��ͬ�����ݿ϶���������һ��
- ���ﻹ���Լ��Ϸ�����������ݡ�
- ����ͳ����ɺ����ǾͿ���ʹ��outputFormat�е�RecordWriter��������ˡ�
1.4 MapReduce����
һ�������� MapReduce �����ڷֲ�ʽ����ʱ������ʵ������:
(1)MrAppMaster:������������Ĺ��̵��ȼ�״̬Э����
(2)MapTask:���� Map �ε��������ݴ������̡�
(3)ReduceTask:���� Reduce �ε��������ݴ������̡�
1.5 MapReduce��̹淶
1.6 WordCount����ʵ��
2.MapReduce���л�
2.1 �������
ʲô�����л�?
- ���л����ǰ��ڴ��еĶ���,ת�����ֽ�����(���������ݴ���Э��)�Ա��ڴ洢������(�־û�)�����紫�䡣
- �����л����ǽ��յ��ֽ�����(���������ݴ���Э��)�����Ǵ��̵ij־û�����,ת�����ڴ��еĶ���
ΪʲôҪ���л�?
- һ����˵,����ġ�����ֻ�������ڴ���,�ػ��ϵ��û���ˡ����ҡ���ġ�����ֻ���ɱ��صĽ���ʹ��,���ܱ����͵������ϵ�����һ̨�������
- Ȼ�����л����Դ洢����ġ�����,���Խ�����ġ������͵�Զ�̼���������Ե�������Ҫ��һ�������е������Ϣ�Լ�����������������֮��Ĺ�ϵ���͵���һ̨������ʱ,������Ҫ���ȶ���������л���
Ϊʲô����java�Լ���Serializable���,��ʹ��Writable?
- Java �����л���һ�����������л����(Serializable),����Hadoop��˵һ���������л���,�ḽ��̫��������Ϣ(����У����Ϣ,Header,�̳���ϵ��),�������������и�Ч���䡣����,Hadoop �Լ�������һ�����л�����(Writable)��
- Writable���ص���:���л����������С,��д�ٶȿ�,֧�ֶ������ԵĻ�������
2.2�Զ�bean����ʵ�����л��ӿ�
����ҵ�������������õĻ������л����Ͳ���������������,������ Hadoop ����ڲ�����һ�� bean ����,��ô�ö������Ҫʵ�����л��ӿڡ�
����ʵ�� bean �������л��������� 7 ����
(1)����ʵ�� Writable �ӿ�
(2)�����л�ʱ,��Ҫ������ÿղι��캯��,���Ա����пղι���
public FlowBean() {
super();
}
(3)��������
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)����������
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5)ע�ⷴ���л���˳������л���˳����ȫһ��
(6)Ҫ��ѽ����ʾ���ļ���,��Ҫ��д toString(),����"\t"�ֿ�,��������á�
(7)�����Ҫ���Զ���� bean ���� key �д���,����Ҫʵ�� Comparable �ӿ�,��Ϊ
MapReduce ���е� Shuffle ����Ҫ��� key �������������������������
@Override
public int compareTo(FlowBean o) {
// ��������,�Ӵ�С
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
2.3 bean�������л�����ʵ��
3.���Ŀ��ԭ��(�ص�)
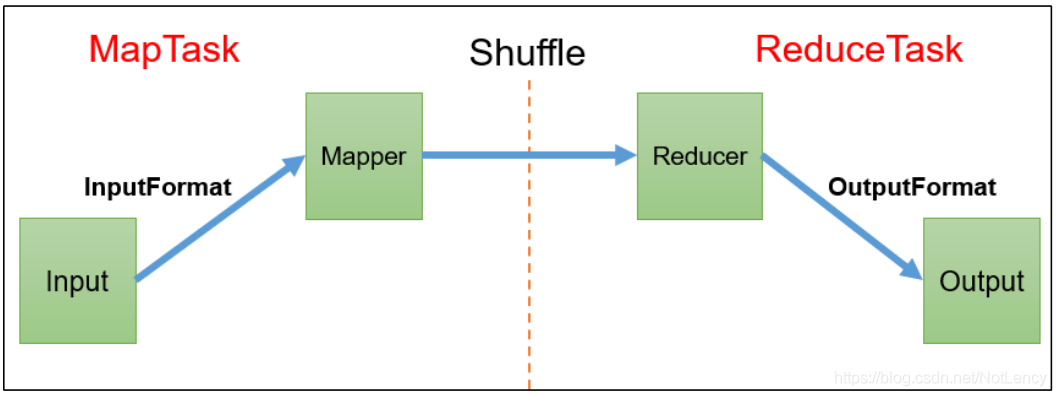
- MapReduce��Ҫ��Ϊ�����ε�����:MapTask��ReduceTask,�м���Shuffle�������ӡ�
- ��MapTask����Ҫ������ݵ�Input����,����ͨ������InputFormat������,���ǿ��Կ����������ݵĸ�ʽ,�������������İ����������ʽ����ʹ�õ�Ĭ�ϸ�ʽ:һ��һ�еĶ���,key��ʾ���ݿ�ʼ�ֽڵ�ƫ����,value��ʾ��ʽ���ݡ����Է������key��û�ж���ô���
Ȼ����Mapper���н�����ص����ݷ�װ����,���������Shuffle��Reduce������ - ͨ��Shuffle���ǿ�����ɶ��������ݵ�����ѹ��������Ȳ���,Ȼ��Reducer��
- ��ReduceTask��������ݵ����ҵ�������Ȼ��ͨ��OutputFormat�������ݵ������ʽ,����İ������Ƕ��ǽ����������ļ���,ͨ��OutputFormat���ǿ�����ɽ�����ֱ�����뵽MySQL���ݿ��HBase�е���ز�����
3.1 InputFormat�������ݵĴ���
3.1.1 ��Ƭ��MapTask���жȾ�������
Job�ύ����Դ�����
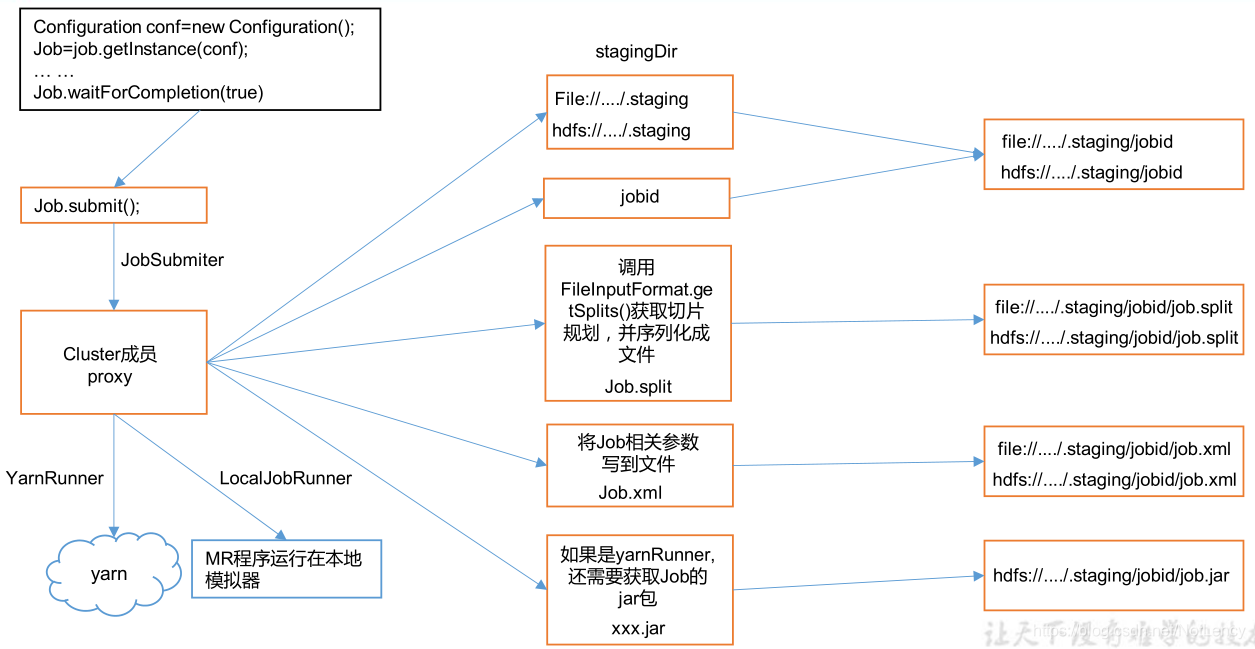
- 1)�����Job��Map��Reduce�εı�д,���Ǿͽ���job���ύ,����Job.waitForCompletion(true);
- 2)Ȼ��job����submit(),��cluster����������job���д���,һ���DZ���Localģʽ,һ����Yarn��Ⱥģʽ,�����Ե�ǰ������ģʽ�����жϾ�����Localģʽ����Yarn��Ⱥģʽ��
- 3)Ȼ�����job������������������Ϣ����jar������Ƭ���á�job����ʱ�ļ�Ⱥ��������,���Ȼᴴ��һ��stage��dir���ڴ����Щ��Ϣ�����ں����ϴ�,�漯Ⱥģʽ�ͱ���ģʽ������·�����в�ͬ��
- 4)������漯Ⱥģʽ,���ȻὫ�������е�jar���ϴ�����Ⱥ�ж�Ӧ��·��,����DZ���ģʽ����Ҫjar��ֱ��ʹ��java�������С�
- 5)����FileInputFormat.getSplits()��ȡ��Ƭ�滮,��������д�뵽stagingDir/jobid�е�job.split�ļ��С�
- 6)job����ʱ��Ⱥ��xml������ϢҲ��д�뵽���·����,Ȼ��5���е���Ƭ�滮��xml����һ���ϴ�����Ⱥ��
- 7)����,���job���ύ,job����RUNNINGģʽ��
���Ǿ����ڼ�Ⱥ����������ʱ,�������������(MapTask)������,��������job������?�϶�������Ĺ�ģ���,��һ����������Ƿ���϶�Ļ���������������IJ��ж�;Сһ������Ƿ���Ļ���Ҳ��Сһ�㡣
��ô�������ʲô��?����ô������?
- ���ݿ�:Block �� HDFS �����ϰ����ݷֳ�һ��һ�顣���ݿ��� HDFS �洢���ݵ�λ��
- ������Ƭ:������Ƭֻ�������϶�������з�Ƭ,�������ڴ����Ͻ����зֳ�Ƭ���д洢��������Ƭ��MapReduce��������������ݵĵ�λ,һ����Ƭ���Ӧ����һ��MapTask��
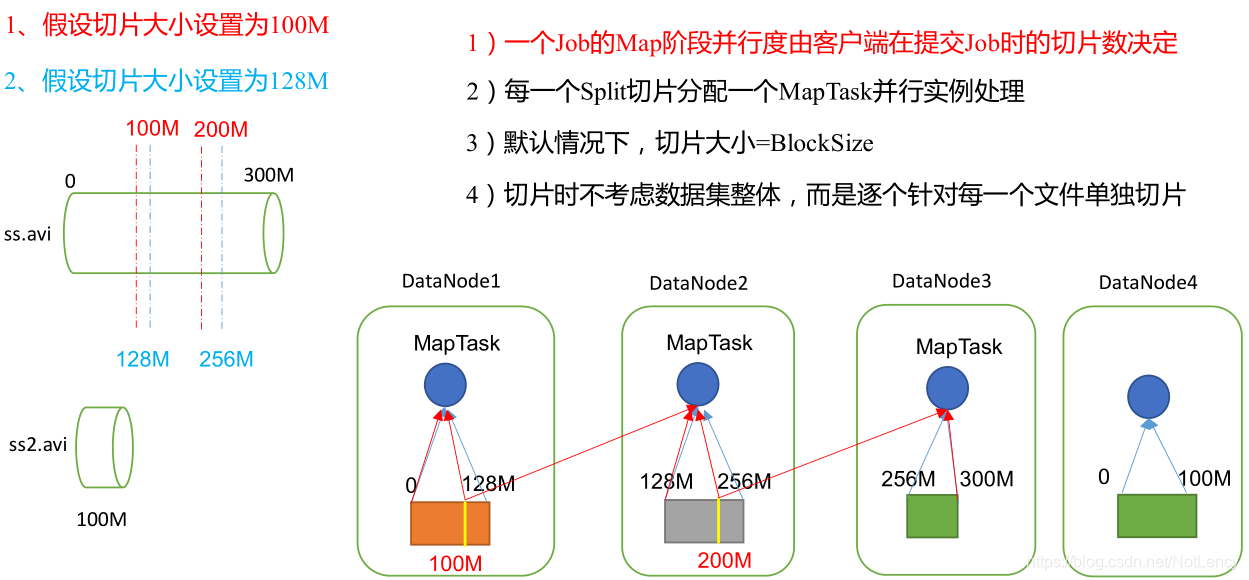
��ƬԴ������:
- �������ҵ����ݴ洢��Ŀ¼��
- ��ʼ��������Ŀ¼�µ�ÿһ���ļ����й滮��Ƭ��
- ÿһ�����������ļ��Ĵ�����ʽ���Ȼ�ȡ�ļ���С length = file.getLen()��
- ���㵱ǰ�������Ƭ��С:
Math.max(minSize, Math.min(maxSize, blockSize));
maxSize(��Ƭ���ֵ):����������ñ�blockSizeС,�������Ƭ��С,���Ҿ͵������õ����������ֵ��
minSize(��Ƭ��Сֵ):�������ı�blockSize��,���������Ƭ��ñ�blockSize����
splitSize = computeSplitSize(
blockSize,
Math.max(1, ("mapreduce.input.fileinputformat.split.minsize"�е��趨ֵ)),
(("mapreduce.input.fileinputformat.split.maxsize"), Long.MAX_VALUE); // ���ǰ����趨ֵ����,��ȡ�趨ֵ,����ȡLong.MAX_VALUE��ֵ
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize)); // Ĭ��ÿһ����Ƭ�Ĵ�С�������ݷֿ�Ĵ�С
}
- ��ʼ�������ݵ���Ƭ�滮:0 �C splitSizeΪ��һ����Ƭ,splitSize �C 2 * splitSizeΪ�ڶ�����Ƭ����(ÿ�ο�ʼ��Ƭʱ,��Ҫ�ж�ʣ�µIJ����Ƿ����splitSize��1.1��,��������ڵĻ����ֳ�һƬ,�����г���Ƭ��)
// ʹ�� ������ļ����ݵĴ�С/��Ƭ�Ĵ�С �������SPLIT_SLOP(��ֵ1.1)�Ż���к�����Ƭ��
// ����˵��һ��split�����Ĵ�СΪsplit�趨ֵ��1.1����
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
- ����Ƭ��Ϣд����Ƭ�滮�ļ���(������Ƭ�Ĺ�����getSplit()���������,InputSplitֻ��¼����Ƭ��Ԫ������Ϣ)

- �����Ƭ��Ϣ�ͺ�����ɵ�job����������Ϣ�ύ�����ط���������Yarn��Ⱥ��,�������ϵ�MRAppMaster�Ϳ��Ը�����Ƭ�Ĺ滮�ļ�������Ӧ������MapTask��
3.1.2 FileInputFormat
�����ڱ�дMapReduce����ʱ,�����ļ��ĸ�ʽ�кܶ�:��������е���־�ļ��������Ƹ�ʽ�ļ������ݿ�ı��ȡ����������İ�������ʹ�õ�Ĭ�ϵ�TextInputFormat��ʽ�����л�ȡ��������,���������������е������������������������ݵ������ʽ֮��,���ǻ���KeyValueTextInputFormat��NLineInputFormat��CombineTextInputFormat ���Զ��� InputFormat �ȸ�ʽ��
TextInputFormat ��Ĭ�ϵ� FileInputFormat ʵ���ࡣ���ж�ȡÿ����¼�����Ǵ洢�����������ļ��е���ʼ�ֽ�ƫ����, LongWritable ���͡�ֵ�����е�����,�������κ�����ֹ��(���з��ͻس���),Text ���͡�
-
������һ��ʾ��,����,һ����Ƭ���������� 4 ���ı���¼��
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise -
ÿ����¼��ʾΪ���¼�/ֵ��:
(0,Rich learning form)
(20,Intelligent learning engine)
(49,Learning more convenient)
(74,From the real demand for more close to the enterprise)
3.1.3 CombineTextInputFormat��Ƭ����(���С�ļ����ⷽ��֮һ)
Ĭ�ϵ� TextInputFormat ��Ƭ�����Ƕ������ļ��滮��Ƭ,�����ļ���С,������һ����������Ƭ,���ύ��һ�� MapTask,��������д���С�ļ�,�ͻ����������MapTask,����Ч�ʼ�����¡�

3.2 Shuffle(�����ص�)
Shuffleָ����Map����֮��,Reduce����֮ǰ���ݵĴ������̡�
Shuffle���̵�ͼʾ:

- ��Map�δ����õ�����,��д�뻷�λ�����,Ȼ���λ��������������ﵽ80%ʱ,��ʼ������д洢,ͬʱ����80%������ʹ�ÿ��Ž�����������ʱ,ʹ�õ��㷨������,��<K, V>����Ԫ���ݵ�������������,�������ֵ����������,�����ݰ����źõ�˳��д�뵽�����ϡ�
- �������,������д�����̡���ʱ������д�ļ���ȫ�������,�����д�ļ��ŵ�һ���ֻ�����������ˡ��ڴ����ж�ͬһ��MapTask�Ķ����д����ļ�ʹ���鲢������������,�γ�һ����д����ļ���
- Ȼ����ԶԴ�ʱ�����ݽ���Combiner����,��������ͬKֵ��<K, V>��ֵ����ϵ�һ��,����<a, 1>, <a, 1>��ϱ��<a, 2>�������Խ���ѹ����Reducer����ȡ����ʱЧ���ܹ���һ�㡣
- Reduce�ν�����MapTask���ɵ�ͬһ��������������ȡ����,�����ݽ��й鲢����,Ȼ������ͬ��Keyֵ���з���,����Reduce��������ͳ�ơ�
3.2.1 Partition��������
Ĭ�ϵ�Partition�����Ļ��ַ����Ǹ������ݶ���key��hashCodeֵ��ReduceTasks����ȡģ��õ�,�û����ܿ����ĸ�keyֵ���ֵ�ij��������
�������ǿ�����дPartitioner����,��ʵ����Ҫ�ķ������ַ�ʽ����
ReduceTask��������getPartition���������ù�ϵ:
-
1)�����ű�����㿪ʼ����,��һ�ۼӡ� �����Ϻ�������ź��������㻮��,ֻҪ����Ŀ�ܶ��������յ���Ҫ�������,����ӳ������ķ�����ŵ���ֵ�ϱ����0��ʼ��һ����,��Ϊ�����ֵ�Ǻ�ReduceTaskһһ��Ӧ��,����ֻ����ֵ�ϵ���ȡ�(��Դ������һ�����ж����:partition < 0 || partition >= partitions,����������ʽΪ����ᱨ�쳣����partition������ǰ���������ķ�����,partitions��������������뼸��ReduceTask�����д���,�����ReduceTask��װ��˷���Դ��)
-
2)���ReduceTask������ > getPartition�Ľ����,������������յ�����ļ�part-r-000xx;
-
3)���1 < ReduceTask������ < getPartition�Ľ����,����һ���ַ�������������,��Exception;
-
4)���ReduceTask������ = 1,��MapTask��������ٸ������ļ�,���ս����������һ��
ReduceTask,����Ҳ��ֻ�����һ������ļ� part-r-00000; -
����:�����Զ��������Ϊ5,��
(1)job.setNumReduceTasks(1); // ����������,ֻ���������һ������ļ�,ʧȥ�˷���Ϊ5����Ч��
(2)job.setNumReduceTasks(2); // �ᱨ��
(3)job.setNumReduceTasks(6); // ����5,�������������,�������Ż�������ļ�
3.2.2 WritableComparable����(�����ص�)
��Hadoop��Key����һ����Ҫ�ܹ����������,�������ʹ��Hadoop�Ŀ��,������Ϊ��Hadoop��ҵ����MapReduce�����һ��Reduce����Ҫ������Key��ͬ�����ݽ��оۺ�,��������������ÿ���ھۺ���ͬ��Keyֵʱ,��Ҫ�������ݲ����ˡ�
����MapTask,���Ὣ�����Ľ����ʱ�ŵ����λ�������,�����λ�����ʹ���ʴﵽһ����ֵ��,�ٶԻ������е����ݽ���һ�ο�������,������Щ����������д��������,�������ݴ�����Ϻ�,����Դ����������ļ����й鲢����
����ReduceTask,����ÿ��MapTask��Զ�̿�����Ӧ�������ļ�,����ļ���С����һ����ֵ,����д������,����洢���ڴ��С�����������ļ���Ŀ�ﵽһ����ֵ,�����һ�ι鲢����������һ�������ļ�;����ڴ����ļ���С������Ŀ����һ����ֵ,�����һ�κϲ���������д�������ϡ����������ݿ�����Ϻ�,ReduceTaskͳһ���ڴ�ʹ����ϵ��������ݽ���һ�ι鲢����
�����ķ���:
- 1)��������:MapReduce���������¼�ļ������ݼ�����֤�����ÿ���ļ��ڲ�����
- 2)ȫ����:����������ֻ��һ���ļ�,���ļ��ڲ�����ʵ�ַ�ʽ��ֻ����һ��ReduceTask�����÷����ڴ��������ļ�ʱЧ�ʼ���,��Ϊһ̨�������������ļ�,��ȫɥʧ��MapReduce���ṩ�IJ��мܹ���
- 3)��������:(GroupingComparator����)��Reduce�˶�key���з��顣Ӧ����:�ڽ��յ�keyΪbean����ʱ,����һ�����ֶ���ͬ(ȫ���ֶαȽϲ���ͬ)��key���뵽ͬһ��reduce����ʱ,���Բ��÷�������
- 4)��������:���Զ������������,���compareTo�е��ж�����Ϊ������Ϊ��������
3.2.3 Combiner �ϲ�
- 1)Combiner��MR������Mapper��Reducer֮���һ�������
- 2)Combiner����ĸ������Reducer��Reducer�������ǽ���Ⱥ������Map����Ľ�����л���,Combiner��������Reducer������,������������MapTask���ڵĽڵ�,��ֻ�����Լ����ڽڵ��Map����Ľ�����л��ܡ�
- 3)Combiner��Reducer�������������е�λ��:Combiner����ÿһ��MapTask���ڵĽڵ�����;Reducer�ǽ���ȫ������Mapper��������;�������߽��еIJ���������������һ�µ�,ֻҪ���յĽ����������
- 4)Combiner��������Ƕ�ÿһ��MapTask��������оֲ�����,�Լ�С���紫������
- 5)Combiner�ܹ�Ӧ�õ�ǰ���Dz���Ӱ�����յ�ҵ����,����,Combiner�����<K, V>Ӧ�ø�Reducer������<K, V>����Ҫ��Ӧ������
���������������,�����ÿ��Map����֮�����Combiner��������Combiner����������Ҳ��Reducer��ͬ�Ļ�,���յĵ��Ľ���ͳ����˴���
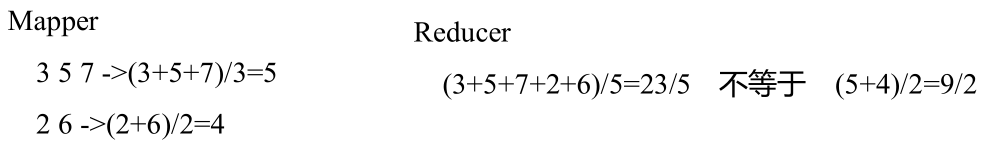
�����Map�ε�Combinerֻ�����˼ӺͲ���,3 + 5 + 7 = 15,2 + 6 = 8,Ȼ������Reducer��ȡ���ݽ������Ĵ���,15 + 8 = 23,23 / 2 = 11.5�ð�����Ҳ���С�
����֪����ʹ��Combiner���֮��,Ψһ��������ĵ�ҵ��������ǡ���͡���
3 + 5 + 7 = 15,2 + 6 = 8 => 15 + 8 = 23;
3 5 7 2 6 => 3 + 5 + 7 + 2 + 6 = 23
3.3 ������ݵĴ���OutputFormat
OutputFormat��MapReduce����Ļ���,����ʵ��MapReduce�����ʵ����OutputFormat
�ӿڡ��������ǽ��ܼ��ֳ�����OutputFormatʵ���ࡣ
Ĭ�ϵ������ʽ��TextOutputFormat�����ǻ����Ը����Լ��������Զ������ݵ������ʽ,���������ǵ�ʵ������,������������ݿ�����ݴ洢�ֿ��С�
3.3.1 �Զ���OutputFormat
����:
1.�Զ���һ��Output��̳�FileOutputFormat��
2.��дRecordWriter�е�write()����ʹ���������ǵ�����
3.4 MapReduce�ں�Դ�����
3.4.1 MapTask��������
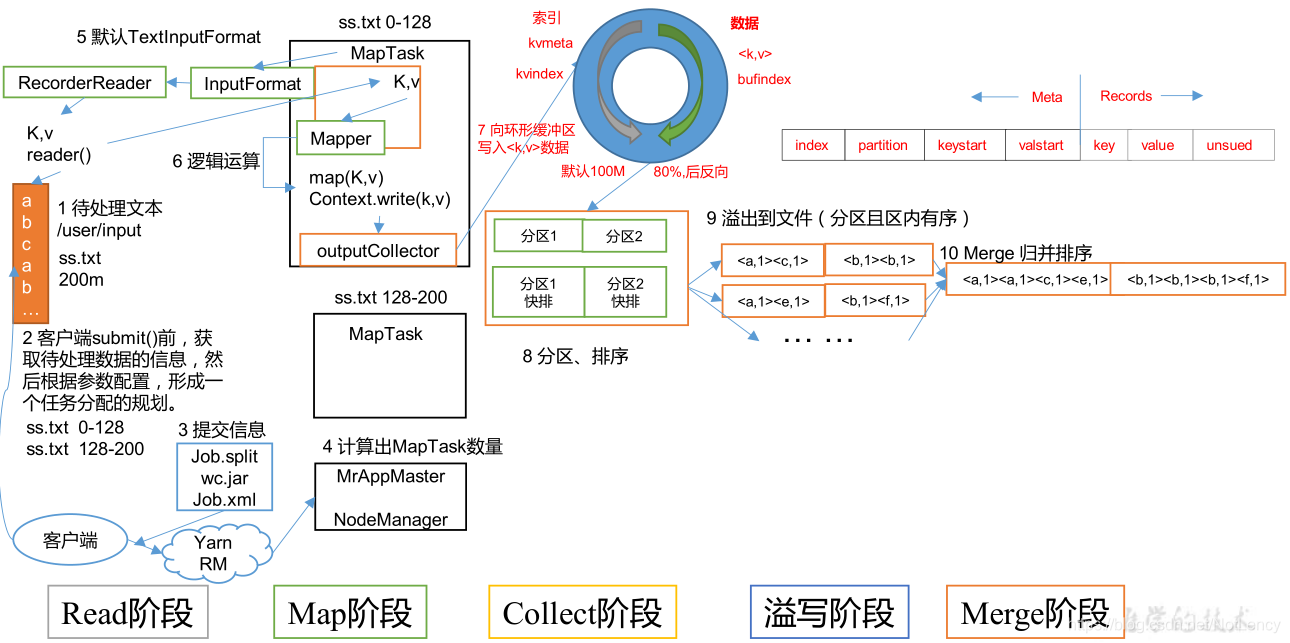
MapTask�����ݴ�������:
- 1)Read ��:MapTask ͨ�� InputFormat ��õ� RecordReader,������ InputSplit �н�����һ���� key/value��
- 2)Map ��:�ý���Ҫ�ǽ��������� key/value �����û���д map()��������,������һϵ���µ� key/value��
- 3)Collect �ռ���:���û���д map()������,�����ݴ�����ɺ�,һ������OutputCollector.collect()���������ڸú����ڲ�,���Ὣ���ɵ� key/value ���з���(����Partitioner,Ĭ���Ǹ��� key/value �е�key���з���),��д��һ�������ڴ滺�����С�
- 4)Spill ��:������д��,�����λ���������,MapReduce �Ὣ����д�����ش�����,����һ����ʱ�ļ�����Ҫע�����,������д�뱾�ش���֮ǰ,��Ҫ�����ݽ���һ������,���ڱ�Ҫʱ�����ݽ��кϲ���ѹ���Ȳ�����
�������:
���� 1:���ÿ��������㷨�Ի������ڵ����ݽ�������,����ʽ��,�Ȱ��շ������Partition ��������,Ȼ���� key ��������(�������������ݴ���������key���Լ��������,������Ҫ���������ʵ��WritableComparable�ӿ��е�compareTo()����)������,���������,�����Է���Ϊ��λ�ۼ���һ��,��ͬһ�������������ݰ��� key ����
���� 2:���շ��������С�������ν�ÿ�������е�����д��������Ŀ¼�µ���ʱ�ļ�output/spillN.out(N ��ʾ��ǰ��д����)�С�����û������� Combiner,��д���ļ�֮ǰ,��ÿ�������е����ݽ���һ�ξۼ�������
���� 3:���������ݵ�Ԫ��Ϣд���ڴ��������ݽṹ SpillRecord ��,����ÿ��������Ԫ��Ϣ��������ʱ�ļ��е�ƫ������ѹ��ǰ���ݴ�С��ѹ�������ݴ�С�������ǰ�ڴ�������С���� 1MB,���ڴ�����д���ļ� output/spillN.out.index �С� - 5)Merge ��:���������ݴ�����ɺ�,MapTask ��������ʱ�ļ�����һ�κϲ�,��ȷ������ֻ������һ�������ļ������������ݴ������,MapTask �Ὣ������ʱ�ļ��ϲ���һ�����ļ�,�����浽�ļ�output/file.out ��,ͬʱ������Ӧ�������ļ� output/file.out.index���ڽ����ļ��ϲ�������,MapTask �Է���Ϊ��λ���кϲ�������ij������,�������ö��ֵݹ�ϲ��ķ�ʽ��ÿ�ֺϲ� mapreduce.task.io.sort.factor(Ĭ�� 10)���ļ�,�����������ļ����¼�����ϲ��б���,���ļ������,�ظ����Ϲ���,ֱ�����յõ�һ�����ļ�����ÿ�� MapTask ����ֻ����һ�������ļ�,�ɱ���ͬʱ�����ļ���ͬʱ��ȡ����С�ļ������������ȡ�����Ŀ�����
3.4.2 ReduceTask��������
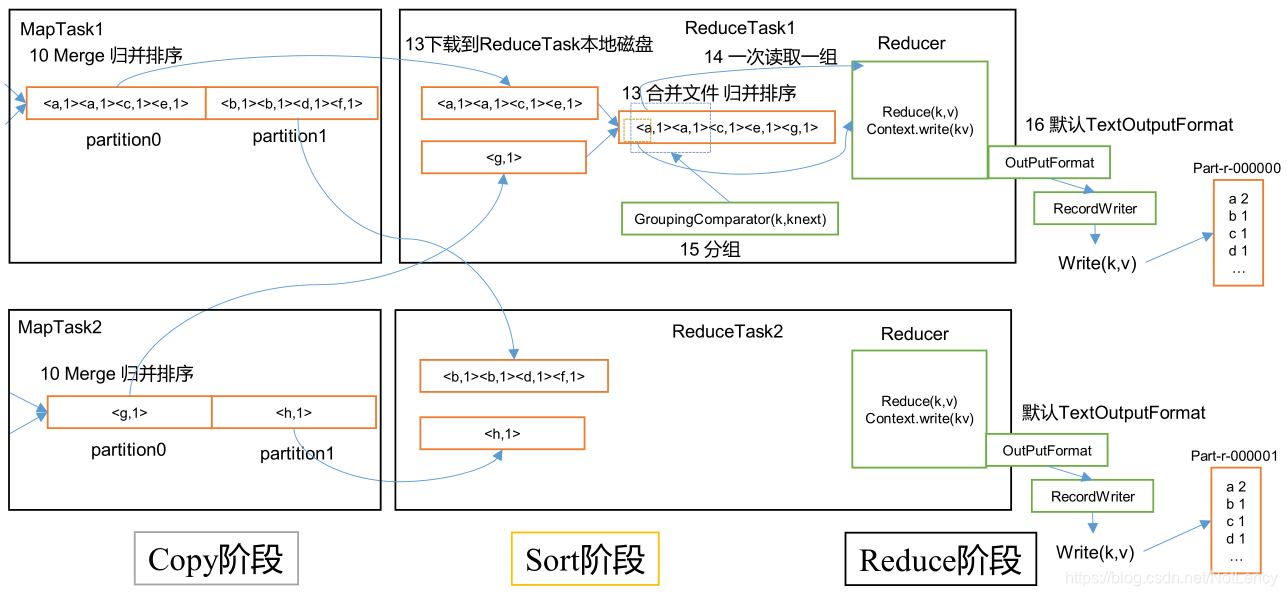
- 1)Copy ��:ReduceTask �Ӹ��� MapTask ��Զ�̿���һƬ����,�����ijһƬ����,������С����һ����ֵ,��д��������,����ֱ�ӷŵ��ڴ��С�
- 2)Sort ��:��Զ�̿������ݵ�ͬʱ,ReduceTask ������������̨�̶߳��ڴ�ʹ����ϵ��ļ����кϲ�,�Է�ֹ�ڴ�ʹ�ù����������ļ����ࡣ���� MapReduce ����,�û���д reduce()�������������ǰ� key ���оۼ���һ�����ݡ�Ϊ�˽� key ��ͬ�����ݾ���һ��,Hadoop �����˻�������IJ��ԡ����ڸ��� MapTask �Ѿ�ʵ�ֶ��Լ��Ĵ�����������˾ֲ�����,���,ReduceTask ֻ����������ݽ���һ�ι鲢���ɡ�
- 3)Reduce ��:reduce()������������д�� HDFS �ϡ�
3.4.3 ReduceTask���жȾ�������
�ع�:MapTask ���ж�����Ƭ��������,��Ƭ�����������ļ��ĸ���(����ͨ�������������ݵ�����ΪCombineTextInputFormat����С�ļ����оۺ�)����Ƭ�������(max(1, min(Long.MAX_VALUE, blockSize)),Ĭ��ΪblockSIze)��
˼��:ReduceTask ���ж���˭����?
1 ) ���� ReduceTask ���ж�(����)
ReduceTask �IJ��ж�ͬ��Ӱ������ Job ��ִ�в����Ⱥ�ִ��Ч��,���� MapTask �IJ���������Ƭ��������ͬ,ReduceTask �����ľ����ǿ���ֱ���ֶ�����:
// Ĭ��ֵ�� 1,�ֶ�����Ϊ 4
job.setNumReduceTasks(4);
ע������:
- 1)ReduceTask=0,��ʾû��Reduce��,����ļ�������MapTask����һ�¡�
- 2)ReduceTaskĬ��ֵ����1,��������ļ�����Ϊһ����
- 3)������ݷֲ�������,���п�����Reduce�β���������б
- 4)ReduceTask������������������,��Ҫ����ҵ��������,��Щ�����,��Ҫ����ȫ�ֻ��ܽ��,��ֻ����1��ReduceTask��
- 5)������ٸ�ReduceTask,��Ҫ���ݼ�Ⱥ���ܶ�����
- 6)�������������1,����ReduceTaskΪ1,�Ƿ�ִ�з������̡�����:��ִ�з������̡���Ϊ��MapTask��Դ����,ִ�з�����ǰ�������ж�ReduceNum�����Ƿ����1,������1�϶���ִ�С�
3.4.4 MapTask & ReduceTask Դ�����
3.5 JoinӦ��
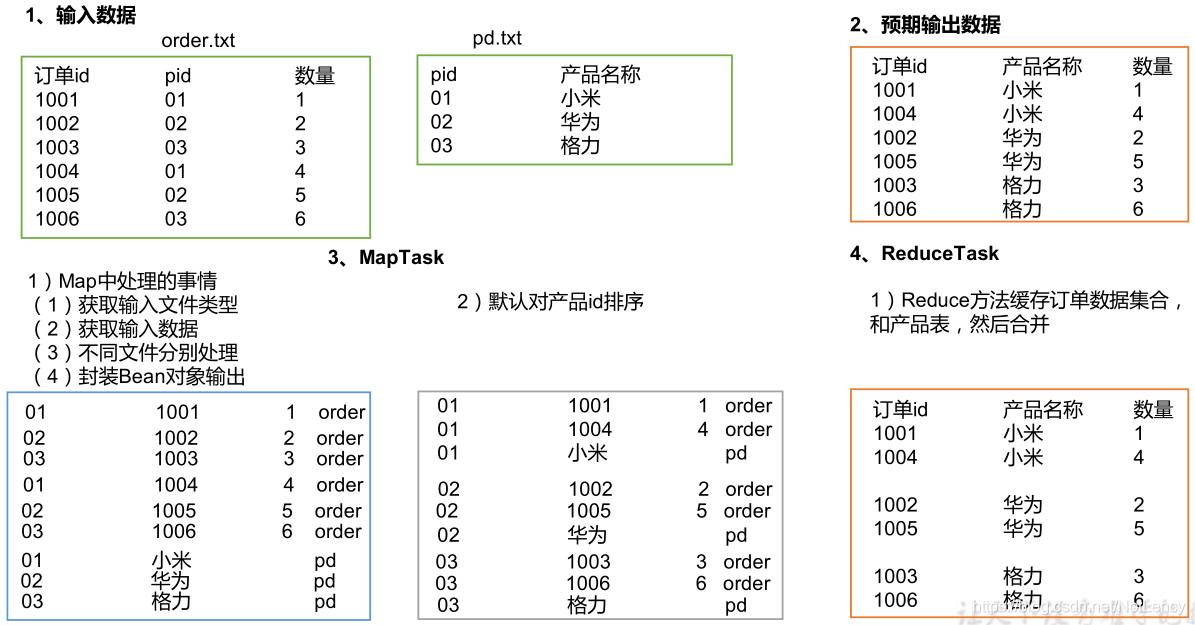
����������map�ν����ݴ�����TableBean����,Ȼ��ʹ��Pid��ΪKey,������з����������Լ�������Reduce�ε�������ȡ����������Reduce�ξ�����ͬKeyֵҲ����Pidֵ�����ݾͻ�ͬʱ�����д���,Ȼ�����ǴӴ洢����Ʒ���Ƶĵ�TableBean������ȡ����Ʒ����,Ȼ��ֵ���洢�˶�����Ϣ��TableBean����,��������������ű���join������
- ȱ��:���ַ�ʽ�н���ReduceJoin:�ϲ��IJ������� Reduce �����,Reduce�˵Ĵ���ѹ��̫��,Map�ڵ�����㸺����ܵ�,��Դ�����ʲ���,���� Reduce �μ��ײ���������б��
- �������:ʹ��MapJoin,������Ҫjoin���������һ�㶼���漰���ű�,һ���������϶����dz�֮Ϊ���,һ���������������dz�֮ΪС��������zaimap���Ƚ�С�������ݴ洦���ڴ���,Ȼ���ȡ���������,������map�ξͽ�join�Ĺ�����ɡ������ͱ����˴���������reduce�μ�Ҫjoin��Ҫreduce�����⡣
3.6 ������ϴExtract Transform Load
������ϴETL,���������������ݴ���Դ�˾�����ȡExtract��ת��Transform������Load��Ŀ�Ķ˵Ĺ��̡�ETLһ�ʽϳ��������ݲֿ�,�������������ݲֿ⡣
�����к���ҵ�� MapReduce ����֮ǰ,����Ҫ�ȶ����ݽ�����ϴ,�������������û�Ҫ������ݡ������Ĺ�������ֻ��Ҫ���� Mapper ����,����Ҫ���� Reduce����(job.setNumReduceTask(0))��
3.7 �ܽ�
MapReduce��������:
1 ) �������ݽӿ�:InputFormat��
- Ĭ��ʹ�õ�ʵ������:TextInputFormat,�书������:һ�ζ�һ���ı�,Ȼ���е���ʼƫ������Ϊkey,��������Ϊ value ���ء�
- CombineTextInputFormat ���Ѷ��С�ļ��ϲ���һ����Ƭ����,��ߴ���Ч�ʡ�
2 ) �������ӿ�:Mapper,�û�����ҵ������ʵ��������������:
- setup() ���ڳ�ʼ��һЩ��Ϣ,����˵����joinʱ���ȼ�¼��С������Ϣ
- map() �û��Լ���д�����ݴ�����
- cleanup()�ͷ���Դ�IJ���
3 )Partitioner ����
- ��Ĭ��ʵ�� HashPartitioner,���Ǹ��� key �Ĺ�ϣֵ�� numReduces(Ĭ��Ϊ1)������һ��������;key.hashCode()&Integer.MAXVALUE % numReduces
- ���ҵ�������ر������,�����Զ������,�Զ����������Ҫ��job��numReducerTask����Ϊ��Ӧ����Ŀ��
4 )Comparable ����
- ���������Զ���Ķ�����Ϊ key �����ʱ,�ͱ���Ҫʵ�� WritableComparable �� ��,��д���е�compareTo()������
- ��������:�����������ÿһ���ļ������ڲ��������ֻ����map��,����ÿһ����Ƭ�ļ��ڵĶ�������ڲ��ֲ�����,ÿ���ļ�ȫ���������;����reduce�κ�,���ݱ��һ�������շ����ֱ�洢���ļ�,���ļ�������
- ȫ����:���������ݽ�������,ͨ��ֻ��һ�� Reduce������������û��������,���ջ���ֻ��һ������ļ�,���ڲ�ȫ������
- ��������:������������������Ȱ���ij��ָ������,�����ָ����ͬʱ�ٰ��յڶ���ָ������
5 )Combiner �ϲ�
- Combiner �ϲ�������߳���ִ��Ч��,��ǰԤ�ۺ�����,���� IO ����,����һ���̶��Ͻ��������б�����⡣
- ����ʹ��ʱ���벻��Ӱ��ԭ�е�ҵ�������������˵���ǵ�ҵ�����������������ݵĺ�����Ԥ�ۺ�û������,�������ƽ��ֵ�Ͳ����ԡ�
6 ) �������ӿ�:Reducer�û�����ҵ������ʵ��������������:
- setup()
- reduce()
- cleanup ()
7 ) ������ݽӿ�:OutputFormat
- Ĭ��ʵ������ TextOutputFormat,��������:��ÿһ�� KV ��,��Ŀ���ı��ļ����һ�С�
- �û��������Զ��� OutputFormat��
4.ѹ��
ѹ�����ŵ�:���ٴ���IO(��������,�㴫�����ݵ�ʱ��Ҳ�Ͷ�ȡ������)������ռ�õĴ��̿ռ� ?(������,Ϊʲô?�洢��ʱ��ȷʵ��ʡ�ռ���,�����õ�ʱ���ý�ѹ��?)
ѹ����ȱ��:������CPU�Ŀ���(����һ����ѹ�ͽ�ѹ�Ĺ���,����Ҫʹ��CPU���в���
4.1 ѹ���㷨
| ѹ���㷨 | Hadoop�Ƿ��Դ� | �㷨 | �ļ���չ�� | �Ƿ������Ƭ | ����ѹ����,ԭʼ�����Ƿ���Ҫ������ | �ŵ� | ȱ�� |
|---|---|---|---|---|---|---|---|
| DEFLATE | ��,ֱ��ʹ�� | DEFLATE | .deflate | �� | ���ı�����һ��,����Ҫ�� | - | - |
| Gzip | ��,ֱ��ʹ�� | DEFLATE | .gz | �� | ���ı�����һ��,����Ҫ�� | ѹ���ʽϸ� | ��֧����Ƭ;ѹ���ͽ�ѹ���ٶ�һ�� |
| bzip2 | ��,ֱ��ʹ�� | bzip2 | .bz2 | �� | ���ı�����һ��,����Ҫ�� | ѹ���ʸ�,֧����Ƭ | ѹ���ͽ�ѹ���ٶ��� |
| LZO | ��,��Ҫ��װ������ | LZO | .lzo | �� | ��Ҫ��������,����Ҫָ�������ʽ | ѹ���ͽ�ѹ���ٶȿ�;֧����Ƭ | ѹ����һ��;��Ҫ��Ƭ�Ļ���Ҫ���ⴴ������ |
| Snappy | ��,ֱ��ʹ�� | Snappy | .snappy | �� | ���ı�����һ��,����Ҫ�� | ѹ���ͽ�ѹ���ٶȼ��� | ��֧����Ƭ;ѹ����һ�� |
ѹ�����ܶԱ�:
| ѹ���㷨 | ԭʼ�ļ���С | ѹ�����ļ���С | ѹ���ٶ� | ��ѹ�ٶ� |
|---|---|---|---|---|
| gzip | 8.3g | 1.8g | 17.5MB/s | 58MB/s |
| bzp2 | 8.3g | 1.1g | 2.4MB/s | 9.5MB/s |
| LZO | 8.3g | 2.9g | 49.3MB/s | 74.6MB/s |
4.2 ѹ���㷨��ʹ��
4.2.1 ѹ��λ�õ�ѡ��

- ���뵽mapǰ��Ҫ�����������ݵĴ�С������:�����������ݲ�������Ƭ�Ĵ�С,��ô��ôֻ��Ҫ����ѹ���ʸ�,����ѹ���ͽ�ѹ���ٶȿ���㷨(Snappy);�����������ݴ�����Ƭ�Ĵ�С,������Ҫ���Dz�ȡ�ܹ�������Ƭ���㷨(LZO)��
- �������뵽reduceʱ,��Ϊ����Ҫ������Ƭ������ֻ��Ҫ����MapTask��ReduceTask֮�������IO,���������ص㿼��ѹ���ͽ�ѹ���ٶȿ��(Snappy)��
- ���ݴ�reduce�����ʱ,��ô��Ҫ�������������,���������Ҫ���ڱ���,��ô��ѡ��ѹ���ʽϸߵ��㷨(Bzip2����Gzip);���������ǰ��ҵ������û����,����Ҫ�����reduce�Ľ���ٴ����뵽��һ��map��ʱ,���ǵĵ�ͺ�������һ����ͬ�ˡ�
4.3 ����������ô��
�鿴����
5.����������������
�鿴PDF
- 1)MapReduce��������
- ������б:���ȼ���Ƿ��ֵ������ɵ�������б����������,����ֱ�ӹ��˵���ֵ;����뱣����ֵ,���Զ������,����ֵ���������ɢ,����ٶ��ξۺ�;���� map ����ǰ����,������� Map �δ�������:Combiner�� ��MapJoin�����ö�� reduceTask
�ġ�Yarn��Դ������
1.����
Yarn ��һ����Դ����ƽ̨,����Ϊ��������ṩ������������Դ,�൱��һ���ֲ�ʽ�IJ���ϵͳƽ̨,�� MapReduce ������������൱�������ڲ���ϵͳ֮�ϵ�Ӧ�ó���
1.1 Yarn�����ܹ�
YARN ��Ҫ�� ResourceManager��NodeManager��ApplicationMaster �� Container ��������ɡ�
1.2 Yarn�Ĺ�������(�����ص�)
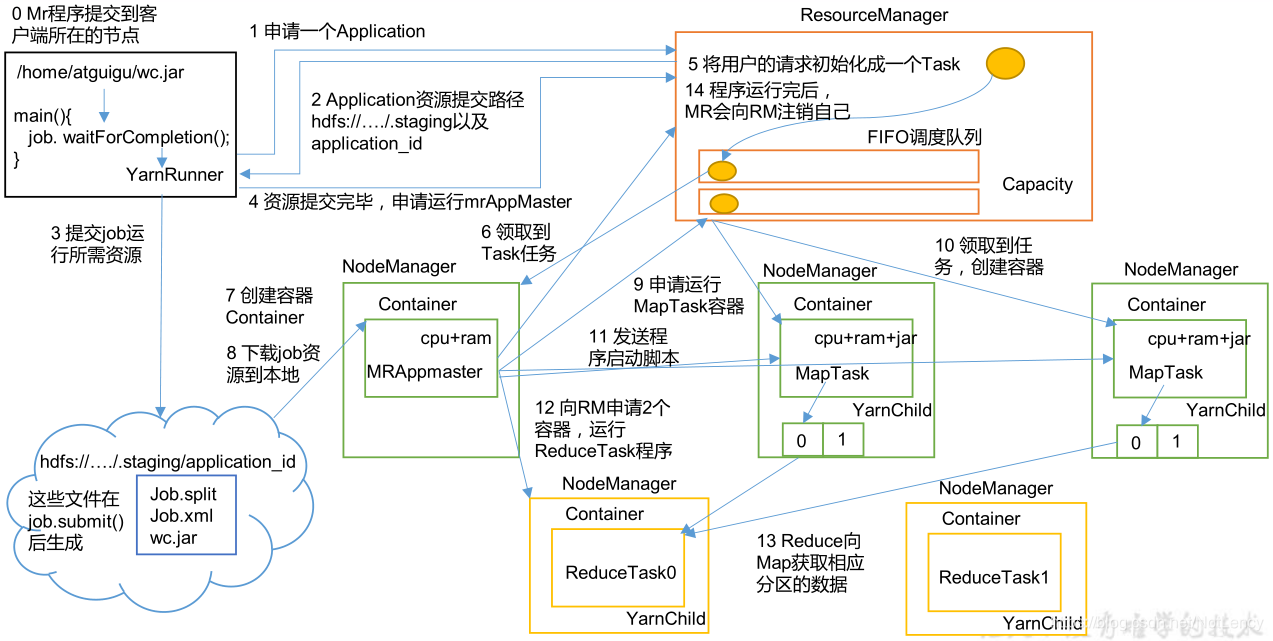
- 1)һ��Mr�����ύ���ͻ������ڵĽڵ�,��ʼ�������С����ڳ��������е�job.waitForCompletion()ʱ,�Ϳ�ʼ��YarnRunner���н�����
- 2)����,�ͻ�����Ⱥ��ResourceManager����һ��Application(Ҳ����˵���Լ���һ��������Ҫ����)������������е�ǰ�ù���,Ȼ��ResourceManager�᷵�ظ�һ��Application����Դ�ύ·��,���ͻ��˽����������������������ϴ���
- 3)�ͻ��˻Ὣ����Application������ļ��������ϴ���ָ����·��,�����ϴ����ļ�������ִ��job.submit()�����ɵ�job.split(���������������Ƭ��Ϣ)��job.xml(������������в�������)�Լ�wc.jar(������������г�����)��
- 4)��Դ�ύ��Ϻ�,�ͻ��˻��ٴ���ResourceManager��������,����һ��MrAppMaster(����ǵ�ǰ�����������еĹ�����,Ҳ������Ҫ���е�Application��Master)��
- 5)ResourceManager�ڽ��ܵ��û�����MrAppMaster�������,�Ὣ��������ʼ����һ��Task,���ҷŵ��Լ��ĵ��ȶ�����,�ȴ������ȡ�
- 6)�ȵ�ResourceManager���ȵ����Task��,���������п��е�NodeManager��Դ,
- 7)��ô��������NodeManager�ϴ���һ��Container����,��������������еı���MrAppMaster,������ص�ǰ��������������
- 8)����MrAppMaster���ȡ��3)�����ϴ�������,
- 9)Ȼ��������е��������Ƭ��Ϣ��ResourceManager������Ӧ������MapTask����Ȼ���������ResourceManager����һ���ᱻ�ŵ����ȶ����еȴ����ȡ�
- 10)����Դ����ʱ,ӵ����Ӧ��Դ��NodeManager�ͻᱻ��������,������MapTask������ͬ��Container��������ʵ�ʵ�job����(MapTask����Ŀһ���Ǻ�Container����Ŀ���Ӧ��,��NodeManagerû��ֱ�ӹ�ϵ,һ��NodeManager�����Դ�㹻�Ļ�,���Ͽ���ͬʱ���ڶ��Container����������ͬ���߲�ͬjob��MapTask,����Container֮���Լ������е�MapTask֮��û���Ӱ�졣)������������,���Ƚ�job�������������job.xml�ļ���job���е�jar���ļ���ȡ����,������������
- 11)��������MrAppMaster�����������ű�,��ʽ��ʼjob�����MapTask���С���ʱ�ͻ���Container�п���YarnChild����,���д��롣�ȵ�MapTask�������н���,������Map�εĽ���ļ���,��֪ͨMrAppMaster�����к�������������
- 12)MrAppMaster���յ�ȫ�����߲��ֵ�MapTask�����������Ϣ��,���ٴ���ResourceManager������Դ���ڽ��к�����Reduce����(���������ReduceTask��Ŀ����������úͷ�������Ŀ�й�,��Ȼ���û��Reduce��,��ֱ��ת������14)),ͬ���������Ҳ�ᱻ�ŵ����ȶ����еȴ����ȡ������ɹ����ȵ�ʱ,��MapTask��һ�����Ȼ������Ӧ������Container,Ȼ������Container�д���ReduceTask����,���Ӧ�Ľ���ͬ����YarnChild��
- 13)ReduceTask��ȡ��Ӧ��MapTask�����ݲ����д�����
- 14)��ReduceTaskҲִ����Ϻ�,MrAppMaster����ResourceManagerע���Լ�,�ͷ��Լ��������Դ��
1.3 MapReduce/HDFS/Yarn֮��ĺ���
������Ի�һ��˼ά��ͼ,�����ߵĺ�����ϵ��������
1.4 �������͵����㷨(�����ص�)
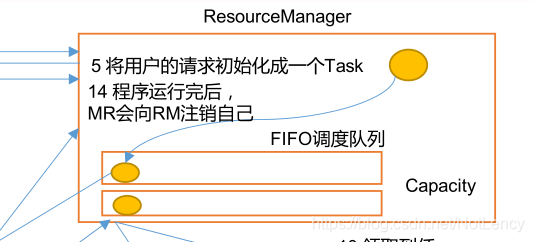
Hadoop��Yarn����ҵ�������㷨������:FIFO�����ȷ�������Capacity Scheduler��ƽFair Scheduler�㷨��ApacheHadoopĬ�ϵ���Դ��������Capacity Scheduler��CDH��HadoopĬ����Fair Scheduler�㷨��
�����������:yarn-default.xml �ļ�
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
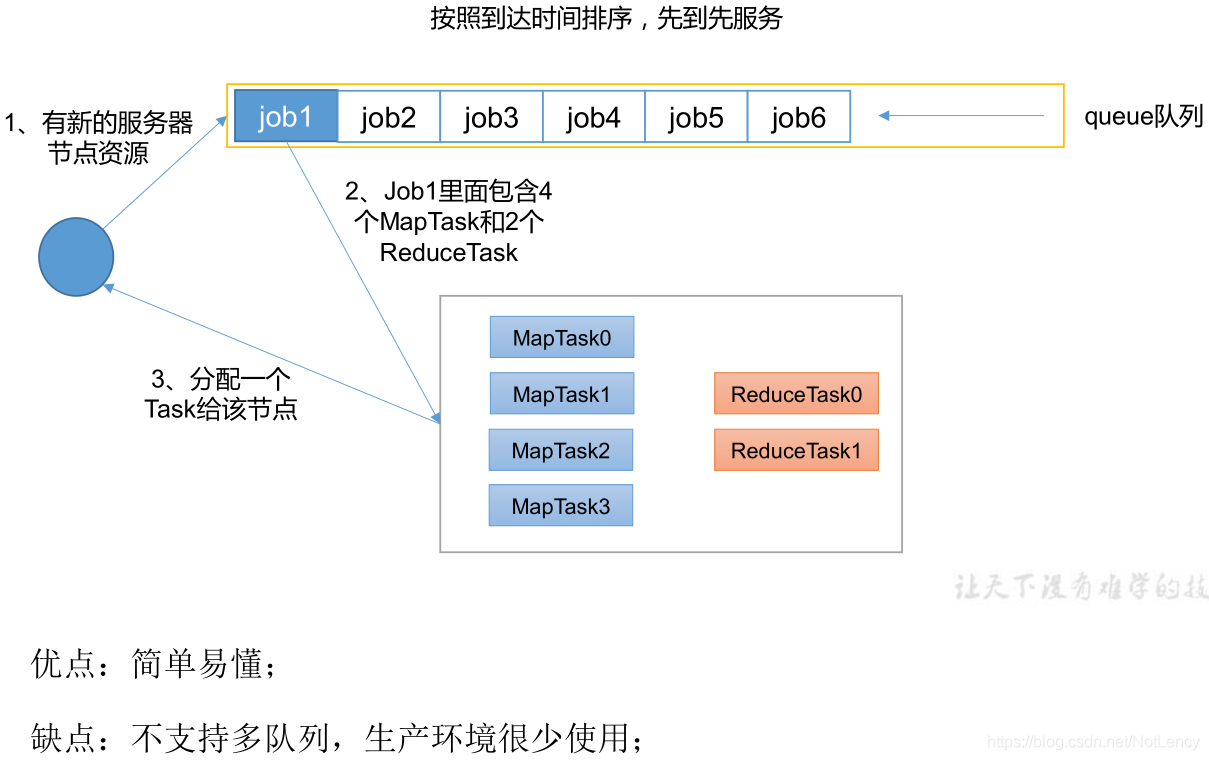
1.4.1 �Ƚ��ȳ�FIFO
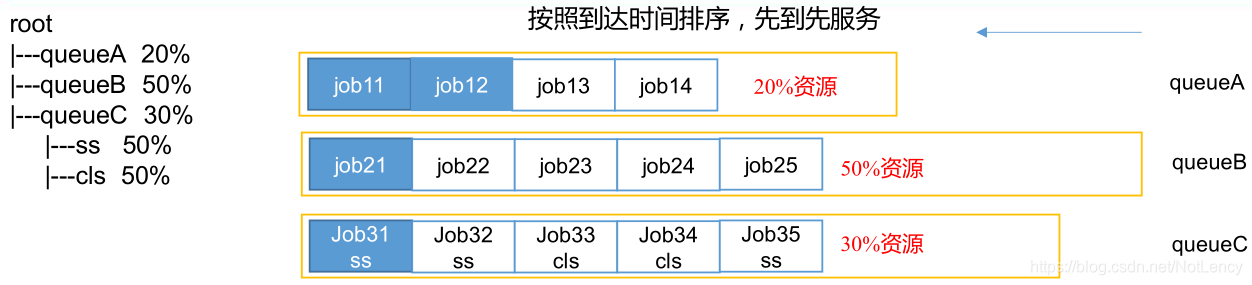
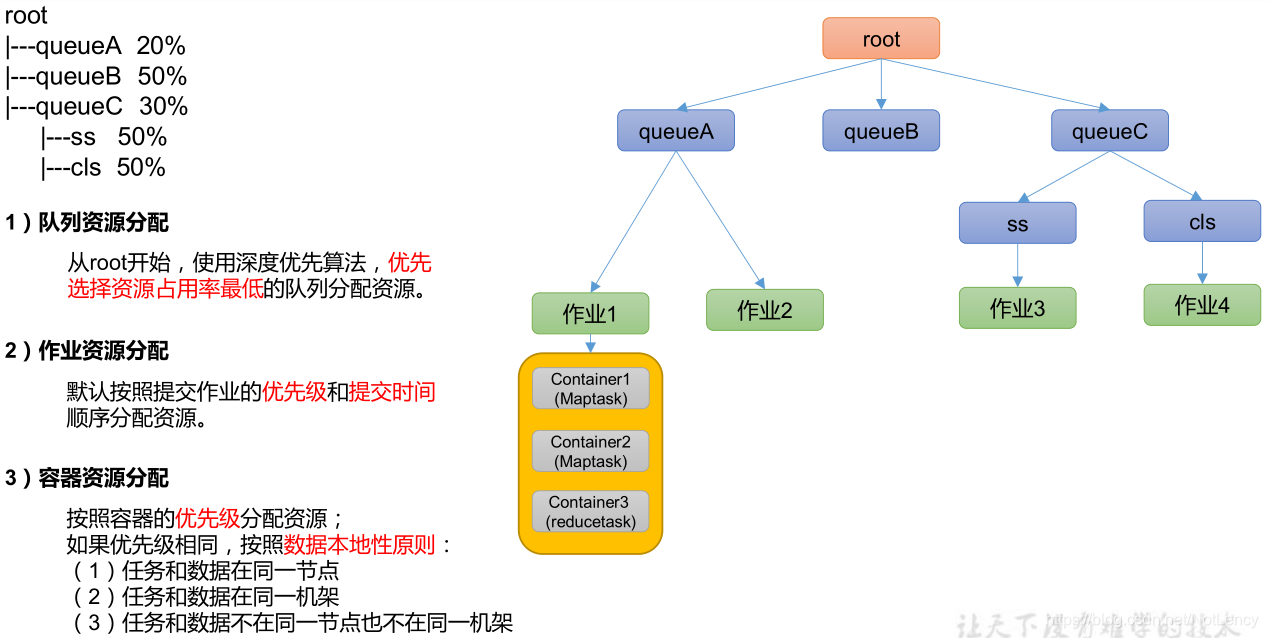
1.4.2 ����������Capacity Scheduler
Capacity Scheduler �� Yahoo �����Ķ��û���������

1.4.3 ��ƽ������Fair Scheduler
Fair Schedulere �� Facebook �����Ķ��û���������

ʲô��ȱ��?ijʱ��һ����ҵӦ�û�ȡ����Դ��ʵ�ʻ�ȡ��Դ�IJ��С�ȱ���
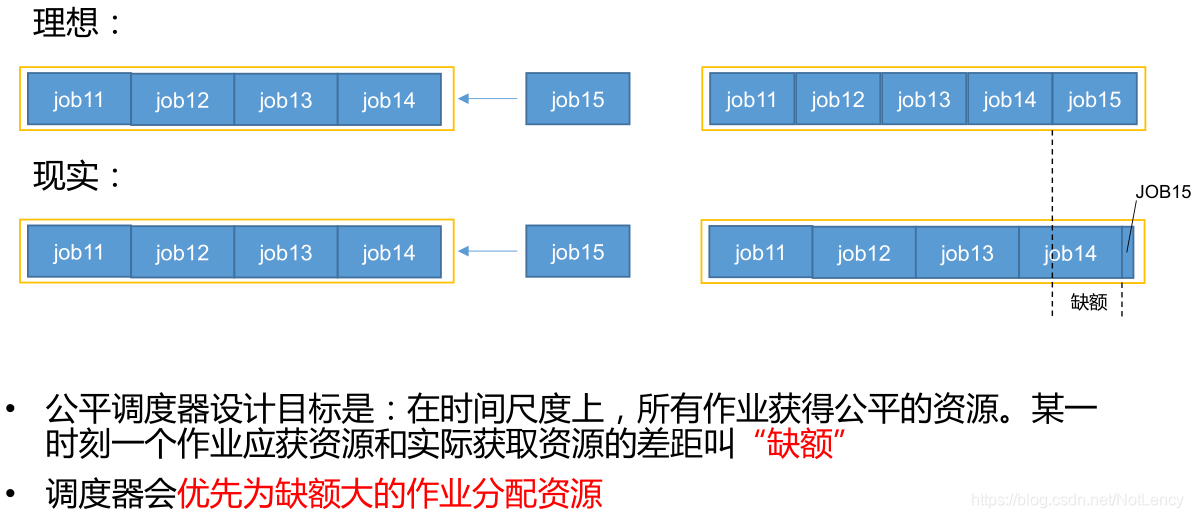
��ƽ�������ж�����Դ�ķ��䷽ʽ:
- 1)FIFO����:��ƽ������ÿ��������Դ����������ѡ�����FIFO�Ļ�,��ʱ��ƽ�������൱�����潲����������������
- 2)Fair����:һ�ֻ��������С��ƽ�㷨ʵ�ֵ���Դ��·���÷�ʽ,Ĭ�������,ÿ�������ڲ����ø÷�ʽ������Դ������ζ��,���һ��������������Ӧ�ó���ͬʱ����,��ÿ��Ӧ�ó���ɵõ��˶���1/2����Դ;�����ʱ����һ��Ӧ��,���ԭ�е�����Ӧ���зֳ�һ����,ʹ��ÿ��Ӧ�ó���ɵõ�����1/3����Դ��
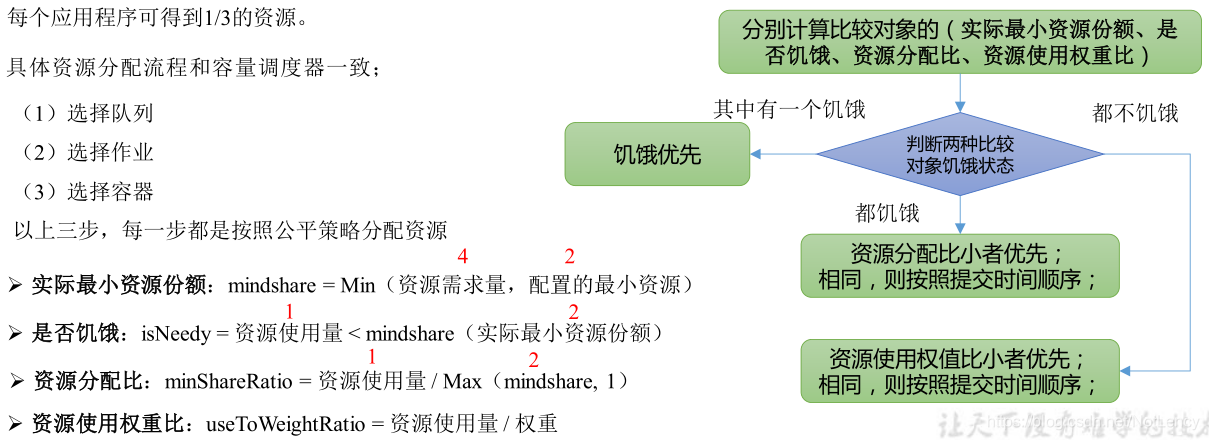
- 3 )DRF ����
DRF(Dominant Resource Fairness),����֮ǰ˵����Դ,���ǵ�һ��,����ֻ�����ڴ�(Ҳ��YarnĬ�ϵ����)�����Ǻܶ�ʱ��������Դ�кܶ���,�����ڴ�,CPU,���������,�������Ǻ��Ѻ�������Ӧ��Ӧ�÷������Դ������
��ô��YARN��,������DRF��������ε���:
���輯Ⱥһ����100 CPU��10T �ڴ�,��Ӧ��A��Ҫ(2 CPU, 300GB),Ӧ��B��Ҫ(6 CPU,100GB)��������Ӧ�÷ֱ���ҪA(2%CPU, 3%�ڴ�)��B(6%CPU, 1%�ڴ�)����Դ,�����ζ��A���ڴ�������, B��CPU������,����������,���ǿ���ѡ��DRF���ԶԲ�ͬӦ�ý��в�ͬ��Դ(CPU���ڴ�)��һ����ͬ���������ơ�
1.5 �������Yarn
1.5.1 yarn application �鿴����
- ����� Application:
yarn application -list
- ���� Application ״̬����:yarn application -list -appStates + ����״̬:ALL��NEW��NEW_SAVING��SUBMITTED��ACCEPTED��RUNNING��FINISHED��FAILED��KILLED
yarn application -list -appStates FINISHED
- Kill �� Application:
yarn application -kill application_1612577921195_0001
1.5.2 yarn logs �鿴��־
- ��ѯ Application ��־:yarn logs -applicationId
yarn logs -applicationId application_1612577921195_0001
- ��ѯ Container ��־: yarn logs -applicationId -containerId
yarn logs -applicationId application_1612577921195_0001 -containerId container_1612577921195_0001_01_000001
1.5.3 yarn applicationattempt �鿴�������е�����
- �г����� Application ���Ե��б�:yarn applicationattempt -list
yarn applicationattempt -list application_1612577921195_0001
- ��ӡ ApplicationAttemp ״̬:yarn applicationattempt -status
yarn applicationattempt -status appattempt_1612577921195_0001_000001
1.5.4 yarn container �鿴����
- ����� Container:yarn container -list
yarn container -list appattempt_1612577921195_0001_000001
- ��ӡ Container ״̬: yarn container -status
yarn container -status container_1612577921195_0001_01_000001
ע:ֻ�����������е��ڼ���ܿ��� container ��״̬,��Ϊһ���������н���container�����ͻᱻ�ͷš�
1.5.5 yarn node �鿴�ڵ�״̬
- �г����нڵ�:yarn node -list -all
yarn node -list -all
1.5.6 yarn rmadmin ��������
- ���¼��ض�������:yarn rmadmin -refreshQueues,����ҶԶ��еĵ��Ȼ��ƽ����˸���,����ͨ��ִ�������������������á�
yarn rmadmin -refreshQueues
1.5.7 yarn queue �鿴����
- ��ӡ������Ϣ:yarn queue -status
yarn queue -status default
1.6 Yarn�����������µ����ò���
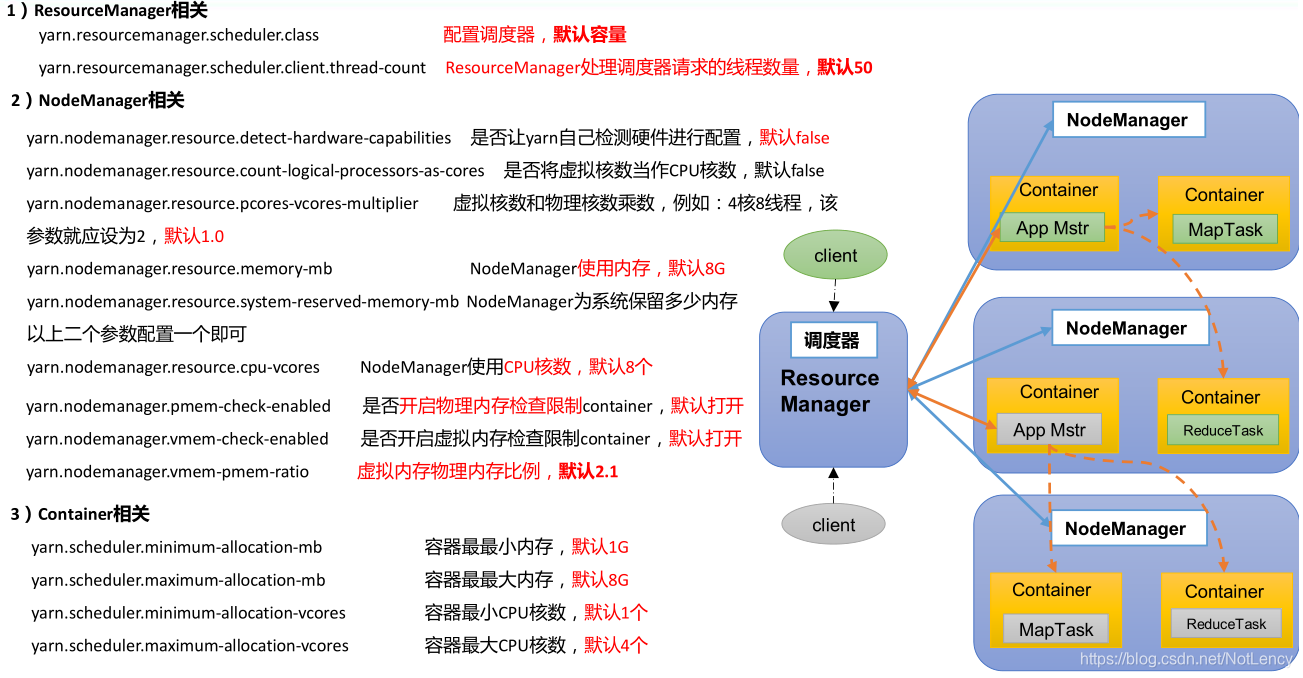
- 1)ResourceManager����������������Ⱥ�Ĺ��������������õ�,���е�������߳�����,�����ʾ��ͬʱ�ж��ٸ��߳��ڵȴ���Ϊ����������������м�Ⱥ��Դ�ķ���,���Ҫ����Ҫ����ʵ���������������������,������ϰ������н��⡣
- 2)NodeManager����������ÿһ̨�����Ļ������������õ�,����˵���е�һ�����Ƿ���Yarn�Լ����Ӳ���������á�������Yarnϵͳ���н��д˽ڵ��������á��ڶ����͵��������á��Ƿ������������CPU����������������������������ij�����,��ͬһʱ�̵ļ�Ⱥ���е�CPU���ܽ�ǿ,�еĿ��ܽ���,�еĽڵ��CPU����һ�˶����Ͻ���CPU�Ķ��,����������ֵ�����þ���Ϊ��ƽ�ⲻͬ�ڵ��CPU���ܵIJ��졣
(�������NodeManager�������������,NodeManager�Լ�Ҳ�������ڽڵ��ϵ�һ������������,����������Task��Container�����������NodeManager����֮�еġ��й�NodeManager���������һ��Ϊ���ܹ�ʹNodeManager�е�Container�ܹ�������õ�ǰ�ڵ����Դ,��һ������Ϊ�˲���NodeManagerռ�õ�ǰ�ڵ����е�Linuxϵͳ����Դ,һ��Linuxϵͳ����������NodeManager������������ֵҪС�ڵ�ǰ�ڵ��ʵ��ֵ,ΪLinuxϵͳ������������Դ��) - 3)Container��ص�����,һ��Ϊ���ܹ������Task���õ�����,�������NodeManager����Դ;ͬʱ����Ϊ�˲��ܳ���NodeManager��������ռ�õ���Դ,����ͬ����ռ�õ�ǰ�ڵ������е�Linuxϵͳ����Դ,���ܻ�����ϵͳ�ı���������Container������������ֵͬ��ҪС��NodeManager���������ֵ��
2.Yarn��ôʹ��
2.1 ���������µIJ�������
��������������,�������ü�PDF
2.2 ����������������
��Ĭ�������,Hadoop��ResourceManager��������ֻ��һ��Default����,ʵ�����е���FIFO����,���ܹ�����ʵ�ʵ�����Ҫ��
����ʵ������������,һ���ǰ���ҵ����ģ���������������,���ǵ�¼ע�����,���ﳵ����,�µ�,ҵ����1,ҵ����2�ȡ�
����������еĺô���:
- 1)���õ���Ա����С��,д������Ĵ��뽫��Ⱥ��Դһ����ȫ������
- 2)ʵ��ҵ��Ľ���,������ʱ���ܹ�ֱ�ӽ�����ij��ҵ�����Ķ�����Դȫ���ó����ȹ��Ƚ���Ҫ������ʹ��,����˵˫11ʱ,Ӧ��û��������ע��,���Ը����¼ע��Ķ����е���Դ�Ϳ������ó�������Ϊ��Ҫ��ҵ������ʹ�á�
2.2.1 ���ö��������������
2.2.2 �����������ȼ�
����������,֧���������ȼ�������,����Դ����ʱ,���ȼ��ߵ��������Ȼ�ȡ��Դ��Ĭ�����,Yarn ��������������ȼ�����Ϊ 0,����ʹ����������ȼ�����,�뿪�Ÿ����ơ�
2.3 ��ƽ������������
2.3.1 ����
������������,�ֱ��� test �� atguigu(���û�����������)������ʵ������Ч��:���û��ύ����ʱָ������,�������ύ��ָ����������;��δָ������,test �û��ύ������ root.group.test ��������,atguigu �ύ������ root.group.atguigu ��������(ע:group Ϊ�û�������)��
��ƽ�������������漰�������ļ�,һ���� yarn-site.xml,��һ���ǹ�ƽ���������з����ļ� fair-scheduler.xml(�ļ������Զ���)��
2.4 Yarn��tool�ӿ�
��ʹ��tool�ӿں�,���Ǿ��ܹ�ʹ��һ��jar��ִ�ж��hadoop����,�����Ͳ�����hadoop���ṩ��example��ͬ,����������ָ����������Ķ��С������yarndemo
�塢Hadoop�ۺϵ�����Դ�����
1.�ۺϵ���
- 1)С�ļ��Ż�
- ��Դͷ�ϴ���,��С�ļ��ϲ��ɴ��ļ�
- HDFS�洢����,�����С�ļ������HAR�ļ�
- CombineTextInputFormat�����С�ļ�����Ƭ����������һ����Ƭ,������ÿ��С�ļ���Ӧһ��MapTask
- ����uberģʽ,ʵ��JVM����
ʵ�ʹ����еIJ������Ű���PDF06�ĵ���10.3��������һ�顣
2.Դ�����
2.1 RPCͨ��ԭ������
171
2.2 NameNode����Դ�����
2.3 DataNode����Դ�����
2.4 HDFS�ϴ�Դ�����
2.5 YarnԴ�����
2.6 MapReduceԴ�����
2.7 HadoopԴ�����
�澭
1.HDFS���ݿ����
HDFS���ݿ�:
��һ���ļ�ϵͳһ��,HDFSҲ�п�(block)�ĸ���,HDFS�ϵ��ļ�Ҳ������Ϊ���С�Ķ���ֿ���Ϊ�����Ĵ洢��Ԫ��
HDFS��С��һ�����С���ļ�����ռ��������Ŀռ�(��һ��1MB���ļ��洢��һ��128MB�Ŀ���ʱ,�ļ�ֻʹ��1MB�Ĵ��̿ռ�,������128MB)
1.1 �������ݿ�ĺô�?
- 1)һ���ļ��Ĵ�С���Դ��ڼ�Ⱥ����ڵ���̵�����
- 2)�������ݽ��б���,����ݴ�����
- 3)ʹ�ó���������������ļ���Ϊ�洢��Ԫ,���洢��ϵͳ�����
1.2 HDFS����Ϊʲôһ�����ÿ��СΪ64MB��128MB?
- �����Ҫ��Ӳ�̵������йء�һ��Ҫ����һ����ϵ:Ѱַʱ���Ǵ���ʱ���1%,���������HDFS�ֲ�ʽ�ļ�ϵͳ��Ч�������ŵġ�HDFS�ļ�ϵͳ��,Ѱַʱ��ƽ������10ms����,����һ�㶼������ͨ�Ļ�еӲ����HDFS�洢,��ô��һ��10ms / 0.01 = 1s,���ڻ�еӲ�̵Ĵ�������һ����100MB/s,���Կ��СӦ������Ϊ100MB����,ȡ������128MB��
Ϊʲô����̫С?
- 1)����һЩ������ԭ��,�洢��Ĵ�С��Ӱ���ȡ����ʱ��Ӳ��Ѱ��ʱ��,HDFS������Ϊ�˴�����������������,����ļ������õ�̫С,��ôһ�����ݾͻᱻ���ֳ�̫��Ŀ�,��Ӳ���ϴ洢��ʱ����ܱȽϷ�ɢ,����������Ӳ�̵�Ѱ��ʱ�䡣
- 2)��Ĵ�СС��,ͬһ���ļ��洢����Ŀ����Ŀ�ͻ���,NameNode����Ҫ�洢�Ķ�ӦԪ���ݵ���ϢҲ�ͱ����,������NameNode�ڴ档ÿ���ļ�/Ŀ¼��Ԫ����(�����ļ����ֳ�����Щblocks,ÿ��block�洢����Щ���������ĸ�block����),���Ǵ洢��NameNode�ϵġ�ÿһ��Ԫ����ռ��150B,���300M�ڴ������,ֻ�ܴ洢������300M/150=2M��Ԫ���ݡ�
Ϊʲô����̫��?
- �����Hadoop��MapReduce�������й�
- (1)Map��������:����ڽ���������������,Map���������,ϵͳ������֮����Ҫ���¼������ݿ�,���ݿ�Խ��,���ݼ���ʱ���Խ��,ϵͳ�ָ�ʱ��Ҳ��Խ����
- 2)���ʱ������:ÿ���ڵ�������Ե���NameNode�ڵ���л㱨ͨ��,˵���Լ��Ĺ���״̬������ijһ���ڵ㱣�ֳ�Ĭ��ʱ�䳬��һ��Ԥ���ʱ����,NameNode�ڵ���¼����ڵ�״̬Ϊ����,�����ýڵ�����ݽ������±���,ת������Ľڵ㡣�������Ԥ��ʱ�������Ǵ����ݿ��С�ĽǶȴ��¹���ġ�(����64MB�����ݿ�,�ҿ��Լ�����10����֮���������Ҳ�ܽ�����˰�,����10���ӻ�û��Ӧ,���Ҿ���Ϊ������ϻ��Ѿ����ˡ�)64MB��С�����ݿ�,��ʱ���пɽ�Ϊ���ع���,����ҽ����ݿ��С��Ϊ640MB������G,�������Ԥ���ʱ�������㲻�ù���,�������̶�ϵͳ������ɲ���Ҫ����ʧ����Դ�˷ѡ�
- 3)����ֽ�����:�������Ĵ�С���������ĸ��Ӷȳ�һ�����Թ�ϵ������ͬһ���㷨,������������Խ��,ʱ�临�ӶȾ�Խ��,ͬʱҲ�����������IJ����Ե��½���
- 4)Լ��Map���:��MapReduce�����,Map֮���������Ҫ���������ִ��Reduce�����ġ���ͨ���漰���鲢����,���鲢������㷨˼����ǡ���С�ļ���������,Ȼ��С�ļ��鲢�ɴ��ļ���,��ˡ�С�ļ������˹���
�ο�
- 1)https://blog.csdn.net/qq_40407889/article/details/107711094?utm_term=hdfs%E7%9A%84%E5%AF%BB%E5%9D%80%E6%97%B6%E9%97%B4&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allsobaiduweb~default-0-107711094&spm=3001.4430
- 2)https://blog.csdn.net/a934079371/article/details/103826093?utm_term=hdfs%E7%9A%84%E5%AF%BB%E5%9D%80%E6%97%B6%E9%97%B4&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allsobaiduweb~default-1-103826093&spm=3001.4430
- 3)https://blog.csdn.net/m0_37367424/article/details/84897246
- 4)https://www.cnblogs.com/parent-absent-son/p/9878668.html