先前准备工作
安装好jdk1.8版本并加入环境变量,配置好免密,处理好ip和节点名称的映射(所有节点都需要)
一、系统配置
Node1:ResourceManager和Namenode配置节点,并且也是DataNode
Node2:DataNode和SecondaryNamenode
Node3:DataNode
二、基础概念
hadoop主要包含了3个组件:存储组件hdfs、资源调度引擎yarn、计算引擎MapReduce
1、hdfs集群
NameNode: 资源存储目录,负责维护整个HDFS文件系统的目录树以及每一个路径(文件)对应的block块信息
DataNode: 资源实际存储位置
2、yarn集群
ResourceManage: 负责资源的分配与调度
NodeManager: 负责接收 ResourceManager的资源分配请求,分配具体的资源给应用
三、hadoop集群搭建
1.在Node1上下载Hadoop3.2.1安装包并解压到指定目录
tar zxvf hadoop-3.2.1.tar.gz -C /opt/software
2.添加hadoop环境变量
vim /etc/profile.d/myenv.sh
配置如下
export HADOOP_HOME=/opt/software/hadoop321
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
激活使其生效
source /etc/profile
3、修改配置文件
(1)core-site.xml
<configuration>
<!--配置node1为namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9820</value>
</property>
<!--配置数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop321/data</value>
</property>
<!--配置HDFS网页登录使用的静态用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--配置root(超级用户)允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--配置root(超级用户)允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--配置root(超级用户)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.user</name>
<value>*</value>
</property>
</configuration>
(2)hdfs-site.xml
<configuration>
<!--配置node1的namenode web访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>node1:9870</value>
</property>
<!--配置node2为secondary namenode web访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
<!--配置hdfs副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(3)yarn-site.xml
<configuration>
<!--配置mr的执行方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置node1为ResouManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!--配置环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--配置yarn的容器允许分配的最小内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!--配置yarn的容器允许分配的最大内存-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!--配置yarn容器允许管理的物理内存大小-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--是否开启日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--自动跳转到的聚合日志的网页地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://${yarn.timeline-service.webapp.address}/applicationhistory/logs</value>
</property>
<!--聚合日志保存时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--通用方式存储和检索应用程序的当前和历史信息-->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<!--通用方式存储和检索应用程序的当前和历史信息的网页地址-->
<property>
<name>yarn.timeline-service.hostname</name>
<value>${yarn.resourcemanager.hostname}</value>
</property>
<!--存储和检索应用程序的当前和历史信息是否跨平台-->
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<!--发送测量数据-->
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
</configuration>
(4)mapred-site.xml
<configuration>
<!--配置mapreduce运行与yarn上:默认为local,也可以指定spark阶段了解的mesos-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--配置历史服务器地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!--配置历史服务器web段地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
(5)workers文件

(6)配置hadoop-env.sh
vim mapred-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/jdk180
-------------------------------------------
(7)配置mapred-env.sh
vim mapred-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/jdk180
-------------------------------------------
(8)配置yarn-env.sh
vim yarn-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/jdk180
-------------------------------------------
(9)添加变量
vim opt/software/hadoop321/sbin/start-dfs.sh
vim opt/software/hadoop321/sbin/stop-dfs.sh
------------------------------------------------
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
------------------------------------------------
vim opt/software/hadoop321/sbin/start-yarn.sh
vim opt/software/hadoop321/sbin/stop-yarn.sh
------------------------------------------------
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
------------------------------------------------
(10)设置服务器时间同步
【node1】
yum -y install ntp
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp /etc/ntp.conf /etc/ntp.conf.bak
cp /etc/sysconfig/ntpd /etc/sysconfig/ntpd.bak
echo "restrict node1 mask 255.255.0.0 nomodify notrap" >> /etc/ntp.conf
echo "SYNC_HWCLOCK=yes" >> /etc/sysconfig/ntpd
systemctl restart ntpd
【node2、node3】
yum -y install ntpdate crontabs
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate node1 #稍等几分钟,同步node1的时间会有3~5分钟延迟
echo "*/30 * * * * /usr/sbin/ntpdate hadoop1.bigdata" >> /var/spool/cron/root
(11)将配置好的hadoop文件整个发送到node2、node3节点
scp -r /opt/software/hadoop321/ root@node2:/opt/software/
scp -r /opt/software/hadoop321/ root@node3:/opt/software/
(12)HDFS格式化
hdfs namenode -format
(13)node1节点启动Hadoop服务
cd /opt/software/sbin
./start-dfs.sh
./start-yarn.sh
(14)9870web端和jps查看
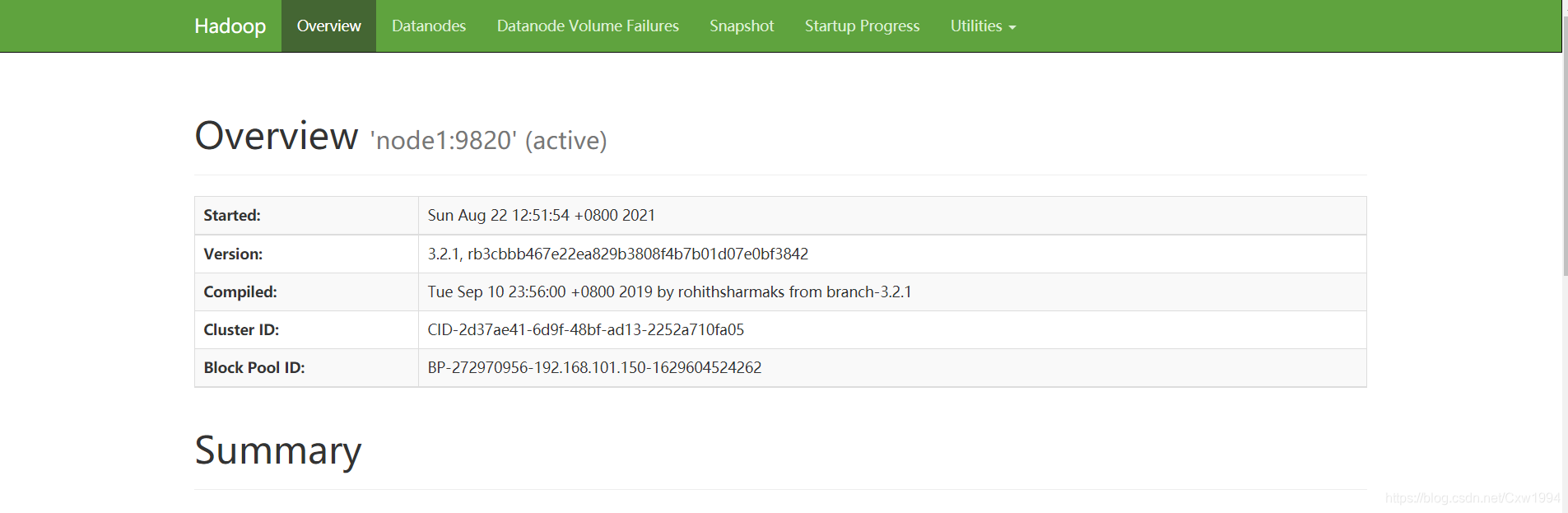
node1进程
node2进程

node3进程

(15)hadoop自带的workcount测试集群
在hdfs根目录建一个output/test.txt文件,里面放了11个hello word
cd /opt/software/hadoop321/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.2.1.jar wordcount /input/test.txt /output/
最终结果
