一、实验环境
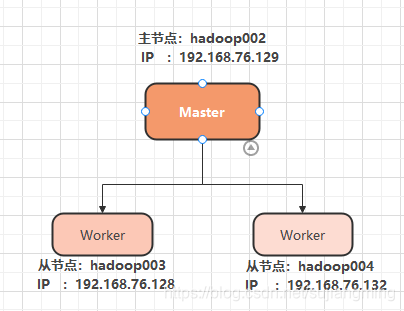
二、总体步骤
- 准备至少3台主机
- 修改主机名称及IP与主机名的映射关系(3台主机都需要操作)
- 做免密登录操作(3台主机都需操作),如已做过,则可删除重新生成
- 在作为master节点的主机上对spark进行配置
- 需要将master节点上配置好的spark环境拷贝到worker主机上
- 启动spark集群(在主机节点上执行start-all.sh)
- 检查是否部署成功,如下步骤:
- 检查进程:
主节点:Master
从节点:Worker - 访问SparkUI界面:http://ip|主机名:8080
- 注意事项:
如果需要主机名+端口号方式访问UI的话,需要做配置
即在windows上进行虚拟机主机名与虚拟机IP地址映射关系
C盘下:Window->System32->driver->etc/hosts
- 检查进程:
- 运行测试,演示wordcount
三、详细步骤
-
准备至少3台主机
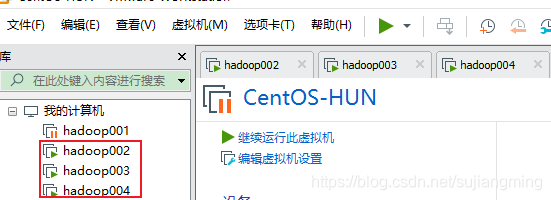
这里使用的是虚拟机,三台虚拟机主机,如下所示:
-
修改主机名称及IP与主机名的映射关系(
3台主机都需要操作)- 执行命令修改主机名称:
hostnamectl --static set-hostname hadoop004 - 编辑/etc/hosts文件,在文件末尾添加如下信息:
注意:192.168.76.129 hadoop002 192.168.76.128 hadoop003 192.168.76.132 hadoop004三台虚拟机主机配置的内容都一样
- 执行命令修改主机名称:
-
做免密登录操作(
3台主机都需操作),如已做过,则可删除重新生成ssh-keygen -t rsa (执行命令后,只需连续敲三次回车键即可) cd ~/.ssh/ ssh-copy-id -i id_rsa.pub root@hadoop002 ssh-copy-id -i id_rsa.pub root@hadoop003 ssh-copy-id -i id_rsa.pub root@hadoop004注意:
三台主机都需要操作 -
在Master节点的主机(
hadoop002)上配置,进入到Spark的安装目录下的conf目录下- 修改配置文件:spark-env.sh (事先不存在需要创建或者复制得到)
注意:export JAVA_HOME=/training/jdk1.8.0_171 export SPARK_MASTER_HOST=hadoop002 export SPARK_MASTER_PORT=7077 #history 配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=/training/spark-2.4.8-bin-hadoop2.7/history"history目录需要事先创建 - 修改slaves文件(事先不存在,需要创建或者复制模板文件得到),将localhost改成从节点的主机名,如下:
复制模板文件得到:cp slaves.template slaveshadoop003 hadoop004 - 复制spark-defaults.conf.template为spark-defaults.conf,并添加如下内容:
spark.eventLog.enabled true spark.eventLog.dir /training/spark-2.4.8-bin-hadoop2.7/logs
- 修改配置文件:spark-env.sh (事先不存在需要创建或者复制得到)
-
需要将master节点上配置好的spark环境拷贝到worker主机上,执行如下命令:
scp -r /training/spark-2.4.8-bin-hadoop2.7/ root@hadoop003:/training/ scp -r /training/spark-2.4.8-bin-hadoop2.7/ root@hadoop004:/training/ -
启动spark集群,在主机节点上进入到spark的安装目录的sbin,执行:
./start-all.sh -
检查是否部署成功,如下步骤:
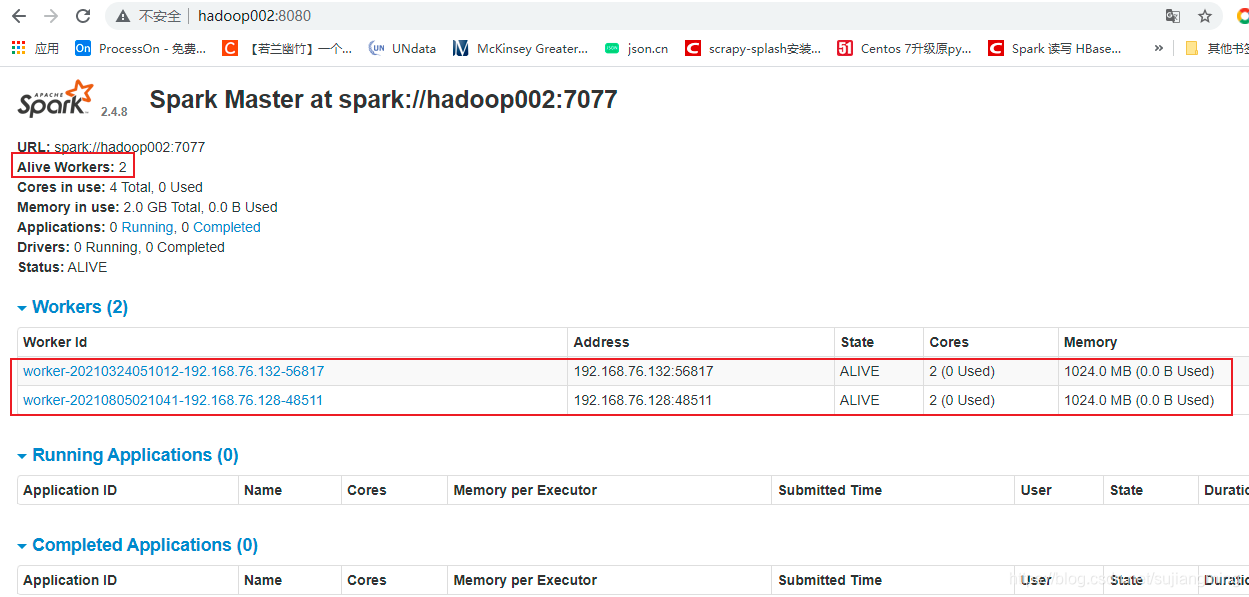
- 检查进程,存在以下进程说明配置成功:
主节点:Master
从节点:Worker - 访问SparkUI界面:http://ip|主机名:8080
注意事项:
如果需要主机名+端口号方式访问UI的话,需要做配置
即在windows上进行虚拟机主机名与虚拟机IP地址映射关系
C盘下:Window->System32->driver->etc/hosts
- 检查进程,存在以下进程说明配置成功:
-
运行测试,演示wordcount
- 准备测试数据:
在主节点(hadoop002)上的在/tools目录下新建文件word.txt,添加如下内容:I love Guizhou I love Guiyang Guiyang is the capital of Guizhou - 将word.txt文件发送到从节点(hadoop003和hadoop004)对应的目录下,执行:
scp -r word.txt root@hadoop003:/tools/ scp -r word.txt root@hadoop004:/tools/ - 启动spark-shell,进入到spark安装目录的bin目录下,执行:
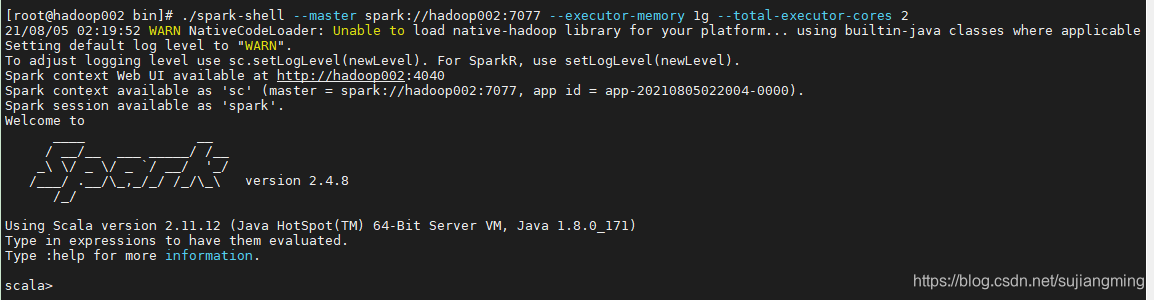
./spark-shell --master spark://hadoop002:7077 --executor-memory 1g --total-executor-cores 2
启动成功后,看到如下界面:
- 编写并运行如下代码,回车运行
或者执行:sc.textFile("file:///tools/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("file:///tools/results/spark/wc")sc.textFile("/tools/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/tools/results/spark/wc") - 查看结果文件:进入到从节点hadoop003下的/tools/results/spark/wc目录下,看到如下文件:

进入到_temporary目录下,看到只有一个目录名称为0的目录,进入目录0下,看到如下:

进入上图红色框下的目录下,看到如下问文件:

其中part-00000就是结果文件,查看文件内容:

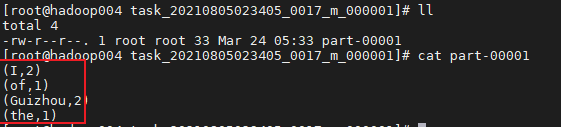
在从节点hadoop004下执行上述相同操作,会看到结果文件为part-00001,内容如下所示:
至此,全部过程已完结!!!!收工了!!!
- 准备测试数据:
