顺序保证难点
本文主要分析 CDC 业务场景中任务级顺序保证,技术选型为:debezium、kafka、flink,其构成了顺序保证中至关重要的每一环,应该充分考虑、分析各组件的对于顺序的支持。
首先 debezium 作为采集组件,其分别为 schema topic 和 data topic 提供了不同的时间字段,如下图 schema topic 中提供了事件时间,data topic 中提供了事件时间和采集时间,为后续数据处理提供了依据。


Kafka 作为一款性能优秀的消息队列,在分布式事务中有着广泛地应用,其为了做到水平扩展,达到提高并发的目的,将一个 topic 分布到多个 broker(服务器)上,即一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。Kafka 在发送消息时,producer 可以知道相关 topic 的集群信息,从而将消息按照不同的策略发送到不同的分区。常见的分区策略有很多种(常用包括轮询、随机、按分区权重、就近原则、按消息键分区等策略)。各个分区中的消息比较独立,很难有一种高效的方法来判断不同分区的顺序。
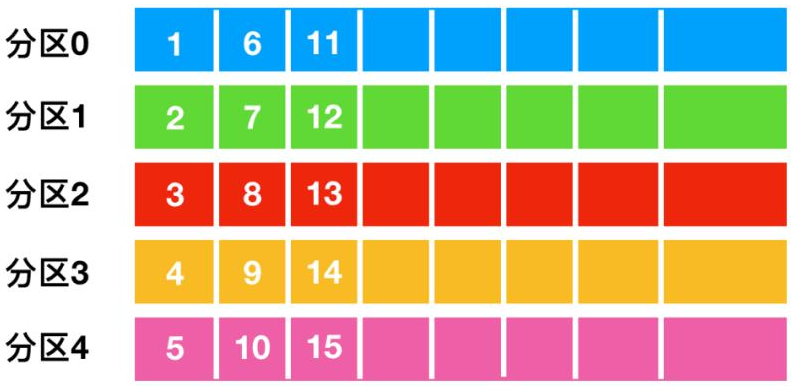
Flink 程序本质上是分布式并行程序。在程序执行期间,一个流有一个或多个流分区(Stream Partition),每个算子有一个或多个算子子任务(Operator Subtask),每个子任务彼此独立,并在不同的线程、节点或容器中运行。
Flink 算子之间可以通过一对一(直传)模式或重新分发模式传输数据:
一对一模式(例如上图 condensed view 中的 Source 和 map() 算子之间)可以保留元素的分区和顺序信息。这意味着 map() 算子的输入的数据以及其顺序与 Source 算子的输出的数据和顺序完全相同,即同一分区的数据只会进入到下游算子的同一分区。
重新分发模式(例如上图 parallelized view 中的 map() 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间)会更改数据所在的流分区。当你在程序中选择使用:keyBy()(通过散列键重新分区)、broadcast()(广播)或 rebalance()(随机重新分发)会把数据发送到不同的目标子任务。如上图所示的 keyBy/window 和 Sink 算子之间数据的重新分发时,不同键(key)的聚合结果到达 Sink 的顺序是不确定的。
综上,顺序保证中有两大难点:kafka 多分区、flink 多并行度。
方案设计
用 flink 处理来自 kafka 的数据时,将为每一个 topic(schema topic、data topic)创建一个 consumer,对应转换为一条流(schema stream、data stream),每一个流单独处理,互不影响。但流内数据依然存在上述的 kafka 多分区、flink 多并行度导致的乱序问题。
单分区顺序
解决乱序问题,首先想到的是排序,但是对于一个无界数据数据流无法进行排序,由此引入窗口的概念,将有界数据流切分为一个个有界的窗口,在窗口内便于执行排序操作。
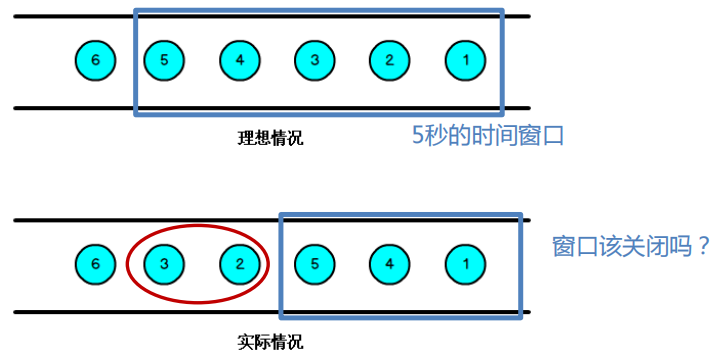
当一个窗口到了关闭时间,不应该立刻触发窗口计算,而是等待一段时间,而是等迟到的数据来了再关闭窗口。数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据都已经到达了,并在该窗口内按照事件时间处理该窗口内的数据即可保证数据处理顺序。watermark 本质上是带有特殊标记的时间戳,必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退。
注意:watermark 的设置是开发者在实时性与准确性之间的权衡
-
如果 watermark 设置的延迟太大,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果(增量聚合)。
-
如果 watermark 到达得太小,则可能收到错误结果,不过 Flink 可以通过侧输出流、允许的延迟(allowed lateness)来解决这个问题。
流级顺序
上面提到对于对于流处理并行任务来说顺序保证中的两大难点:kafka 多分区、流处理多并行度。flink 中给出了一个同时解决这两个问题的解决方案,watermark 是一个流层面全局的概念,即一个流中维护一个全局的 watermark,保证流中多并行任务之间的顺序,以下图为例:
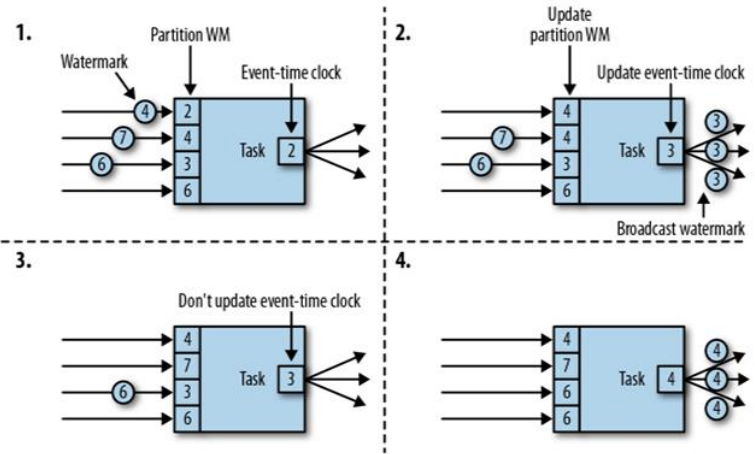
流中并行度为 4,partition WM 代表单个并行子任务的 watermark,Event-Time clock 代表该流中全局 watermark。
- 该时刻并行子任务的 watermark 分别为:2、4、3、6,全局 watermark 为并行子任务 watermark 的最小值 2;
- 第一个子任务中 watermark 变为 4,此时并行子任务的 watermark 分别为:4、4、3、6,最小值变为 3,因此全局 watermark 值为 3;
- 第二个子任务中 watermark 变为 7,此时并行子任务的 watermark 分别为:4、7、3、6,最小值仍为 3,全局 watermark 值不变;
- 第三个子任务中 watermark 变为 6,此时并行子任务的 watermark 分别为:4、7、6、6,最小值变为 4,全局 watermark 值变为 4;
由此可见全局 watermark 的值取决于并行子任务 watermark 的最小值,因此为减小各分区之间的 watermark 差值,建议 kafka 分区策略使用轮询策略。
另外 flink 会根据 kafka 分区数取模 flink 并行度的方式(kafka partitions % flink parallelism)调整各子任务具体处理哪一分区的数据。有三种可能的情况:
-
kafka partitions = flink parallelism:这种情况是最理想的,因为每个消费者负责一个分区。如果消息在分区之间是平衡的,那么工作将均匀分布在 flink 并行任务之间;
-
kafka partitions < flink parallelism:一些 flink 并行任务处于空闲状态,不会收到任何消息(flink 中提供了定期空闲状态检查机制);
-
kafka partitions > flink parallelism:在这种情况下,某些任务将处理多个分区,造成分区数据实际上以串行执行。
建议使用第一种 kafka 分区与 flink 并行度分配方式,将 flink 并行度设置为 kafka 分区相同。
任务级顺序
上述流内乱序引入 window+watermark 之后即可解决,但是数据处理为达到任务级别的顺序要求,不能只解决流内乱序,因为 schema stream 和 data stream 并非完全相互独立,如下:
假设某表的原始结构为:CREATE TABLE tab1(uid bigint(20), name varchar(50))),下图中 alter 代表:ALTER TABLE tab1 CHANGE COLUMN name uname varchar(50)。
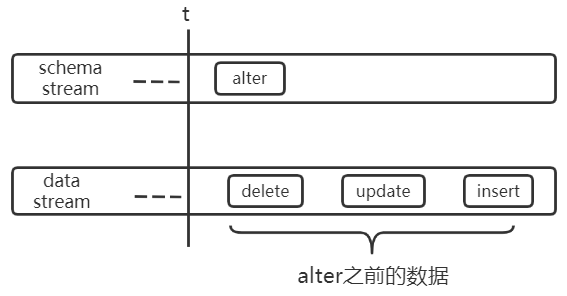
unknow column name
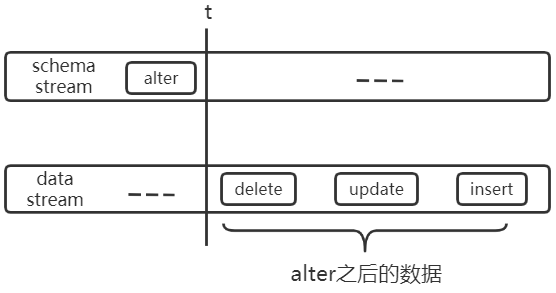
unknow column uname
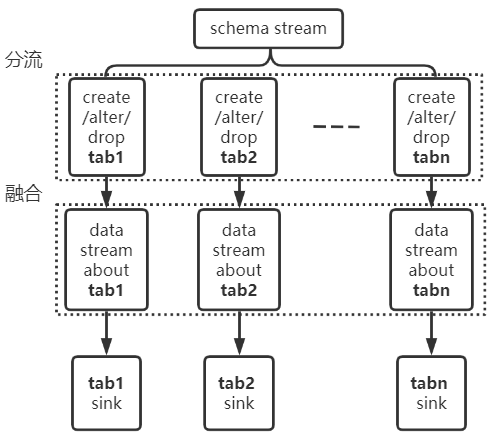
以上两个实例说明了多流之间可能出现乱序的情况,为了保证任务级顺序,需要在多流之间进行分流与融合的操作,如下:将关于 tab1 的 schema 流切分出来,将其与 tab1 的 data 流进行融合。保证其流内顺序,即可解决上述问题。
关注公众号 HEY DATA,添加作者微信,一起讨论更多。
