����(��)��:Hive
һ�����
(һ)Hadoop�������ڵ�����
1��ֻ����java���Կ���,�����c���Ի��������Եij���Ա��Hadoop,���������ż�
2����Ҫ��Hadoop�ײ�ԭ��,api�Ƚ��˽����������
3���������ԱȽ��鷳
(��)hive����
1��Hive�ǻ���Hadoop��һ�����ݲֿ�ߡ����Խ��ṹ���������ļ�ӳ��Ϊһ�ű�,���ṩ������sql��ѯ����
2���ײ��ǽ�sql���ת��ΪMapReduce�����������
3��Hive�ṩ��һϵ�еĹ���,������������������ȡ��ת��������(ETL Extract-Transform-Load ),����һ�ֿ��Դ洢����ѯ�ͷ����洢�� Hadoop �еĴ��ģ���ݵĻ���
4����������һ�ִ��������߷�������
(��)Hive��HQL
1�� HQL - Hiveͨ����SQL���,�����зֲ�ʽ�ļ���
2��HQL��������SQL�dz�������,Hive��ִ�еĹ����лὫHQLת��ΪMapReduceȥִ��,����Hive��ʵ�ǻ���Hadoop��һ�ֲַ�ʽ������,�ײ���Ȼ��MapReduce
(��)�ص�
1���ŵ�:
a. ѧϰ�ɱ���,ֻҪ��sql������hive
b. ����Ч�ʸ�,����Ҫ���,ֻ��Ҫдsql
c. ģ�ͼ�,��������
d. ��Ժ������ݵĸ����ܲ�ѯ�ͷ���
e. HiveQL ���Ŀ���չ��(Extendibility)
f. ����չ��(Scalability)���ݴ���
g. �� Hadoop ������Ʒ��ȫ����
2��ȱ��:
a. ��֧���м������ɾ��
b. ��֧������������������
c. ��������Ȼ��MR��ִ��,Ч�ʲ����
�塢���ó���
1. Hive �����ڻ��ھ�̬(����)��������Hadoop ֮��,Hadoop ͨ�����нϸߵ��ӳٲ�������ҵ�ύ�͵��ȵ�ʱ����Ҫ�����Ŀ��������,Hive �����ܹ��ڴ��ģ���ݼ���ʵ�ֵ��ӳٿ��ٵIJ�ѯ���,Hive �����ʺ���Щ��Ҫ���ӳٵ�Ӧ��
Hive �����ṩʵʱ�IJ�ѯ�ͻ����м������ݸ��²�����Hive �����ʹ�ó����Ǵ����ݼ���������������ҵ,����,������־����
������װ
1���ϴ�

2����ѹ�ļ���������
3������hdfs
[root@hadoop01 software]# mv apache-hive-1.2.1-bin hive
[root@hadoop01 software]# start-all.sh
4������ hive
[root@hadoop01 software]# cd /home/software/hive/bin/
[root@hadoop01 bin]# sh hive
�������������ɹ�
Logging initialized using configuration in jar:file:/home/software/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
��������ָ��
(һ)����
| ���� | ���� | ����˵�� |
|---|---|---|
| show | databases; | �鿴������Щ���ݿ� |
| create database park; | ����park���ݿ� | ���������ݿ�,ʵ������Hadoop��HDFS�ļ�ϵͳ�ﴴ��һ��Ŀ¼�ڵ�,ͳһ����:/user/hive/warehouse Ŀ¼�� |
| use park; | ����park���ݿ� | |
| show tables; | �鿴��ǰ���ݿ������б� | |
| create table stu | ����stu��,�Լ���ص������ֶ� | 1. hive��,��ʾ�ַ����õ���string,����char��varchar (id int,name string); 2. �������ı�,Ҳ��HDFS���һ��Ŀ¼�ڵ� |
| insert into stu values(1,��zhang��) | ��stu���������� | 1. HDFS��֧�����ݵ��ĺ�ɾ��,����Ѿ���������ݲ��ܹ��ٽ����κεĸĶ� ; 2�� ��Hadoop2.0�汾��֧���������ӡ�ʵ����,insert into ���ִ�е����Ӳ���; 3�� hive֧�ֲ�ѯ,�м���IJ��롣��֧���м����ɾ������; 4��hive�IJ���ʵ����ִ��һ��job����,���õ���Hadoop��MR; 5�� ����������֮��,����HDFS stuĿ¼�ڵ��¶���һ���ļ�,�ļ�����˲��������,���,hive�洢������,��ͨ��HDFS���ļ����洢�ġ� |
| select * from stu | �鿴������ | Ҳ���Ը����ֶ�����ѯ,����select id from stu |
| drop table stu | ɾ���� | |
| load data local inpath ��/home/software/1.txt�� into table stu; | ͨ�������ļ����ݵ�ָ���ı��� | 1�� ��ִ�������ָ��֮��,����hdfs stuĿ¼�¶���һ��1.txt�ļ����ɴ˿ɼ�,hive�Ĺ���ԭ��ʵ���Ͼ����ڹ���hdfs�ϵ��ļ�,���ļ������ݳ���ɶ�ά���ṹ,Ȼ���ṩhql��乩����Ա��ѯ�ļ����� ; 2�� ������������ʵ��:��ͨ��load ָ��,��ͨ�������stuĿ¼�����ϴ�һ���ļ�,����hive�Ƿ��ܽ����ݹ�����stu��� |
| create table stu1(id int,name string) row format delimited fields terminated by �� '; | ����stu1��,��ָ���ָ�� �ո� | |
| desc stu | �鿴 stu���ṹ | |
| create table stu2 like stu | ����һ��stu2��,���ṹ��stu���ṹ��ͬ | likeֻ���Ʊ��ṹ,���������� |
| insert overwrite table stu2 select * from stu | ��stu�����ݲ��뵽stu2���� | |
| insert overwrite local directory ��/home/stu�� row format delimited fields terminated by �� �� select * from stu; | ��stu���в�ѯ������д�����ص�/home/stuĿ¼�� | |
| insert overwrite directory ��/stu�� row format delimited fields terminated by �� �� select * from stu; | ��stu���в�ѯ������д��HDFS��stuĿ¼�� | |
| alter table stu rename to stu2 | Ϊ��stu������Ϊstu2 | |
| alter table stu add columns (age int); | Ϊ��stu����һ�����ֶ�age,����Ϊint | |
| exit | �˳�hive |
��hive�IJ��������ϲ����Ļ���hdfs
(��)��������������Ľ��(����ֱ������)
hive> show dataBases;
OK
default
Time taken: 0.75 seconds, Fetched: 1 row(s)
hive> create database student;
OK
Time taken: 0.23 seconds
hive> show dataBases;
hive> use student;
OK
Time taken: 0.019 seconds
hive> show tables;
hive> create table stu (id int,name string);
hive> insert into stu values(1,'list');
hive> select * from stu;
OK
1 list
Time taken: 0.11 seconds, Fetched: 1 row(s)
�ڴ���2��
[root@hadoop01 ~]# cd /home/
[root@hadoop01 home]# vim student
3 mayun
4 hafl
5 agkh
6 agkh
�ڴ�����
hive> load data local inpath '/home/student' into table stu;
Loading data to table student.stu
Table student.stu stats: [numFiles=1, totalSize=29]
OK
Time taken: 0.259 seconds
hive> select * from stu;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
����NUll����Ϊ��˵������,���ָ�����һ��,Ĭ���� /t ���ļ����ǿո�
���ķ���
hive> drop table stu;
Moved: 'hdfs://hadoop01:9000/user/hive/warehouse/student.db/stu' to trash at: hdfs://hadoop01:9000/user/root/.Trash/Current
OK
Time taken: 0.176 seconds
hive> show tables;
OK
values__tmp__table__1
Time taken: 0.028 seconds, Fetched: 1 row(s)
hive> create table stu (id int,name string)row format delimited fields terminated by ' ';
hive> load data local inpath '/home/student' into table stu;
hive> select * from stu;
OK
3 mayun
4 hafl
5 agkh
6 agkh
Time taken: 0.052 seconds, Fetched: 4 row(s)
hive> desc stu;
OK
id int
name string
Time taken: 0.059 seconds, Fetched: 2 row(s)
hive> create table stu2 like stu;
hive> insert overwrite table stu2 select * from stu;
hive> insert overwrite local directory '/home/stu' row format delimited fields terminated by ' ' select * from stu;
ִ�н������һ����2��ִ��
[root@hadoop01 home]# cat stu
cat: stu: ��һ��Ŀ¼
[root@hadoop01 home]# cd stu
[root@hadoop01 stu]# ll
������ 4
-rw-r--r--. 1 root root 29 8�� 23 08:45 000000_0
[root@hadoop01 stu]# cat 000000_0
3 mayun
4 hafl
5 agkh
6 agkh
[root@hadoop01 stu]#
�ġ���װMySqL
1�����ϵͳ�й���MySQL�İ���ɾ��
�Cnodeps ��������ǿ��ж��
[root@hadoop01 ~]# rpm -qa|grep mysql
mysql-libs-5.1.71-1.el6.x86_64
[root@hadoop01 ~]# rpm -e mysql-libs-5.1.71-1.el6.x86_64
error: Failed dependencies:
libmysqlclient.so.16()(64bit) is needed by (installed) postfix-2:2.6.6-2.2.el6_1.x86_64
libmysqlclient.so.16(libmysqlclient_16)(64bit) is needed by (installed) postfix-2:2.6.6-2.2.el6_1.x86_64
mysql-libs is needed by (installed) postfix-2:2.6.6-2.2.el6_1.x86_64
[root@hadoop01 ~]# rpm -e -nodeps mysql-libs-5.1.71-1.el6.x86_64
-nodeps: δ֪��ѡ��
[root@hadoop01 ~]# rpm -e --nodeps mysql-libs-5.1.71-1.el6.x86_64
[root@hadoop01 ~]# rpm -qa|grep mysql
2���������û���
[root@hadoop01 ~]# cd /home/software/
[root@hadoop01 software]# groupadd mysql
[root@hadoop01 software]# useradd -r -g mysql mysql
[root@hadoop01 software]# id mysql
uid=496(mysql) gid=500(mysql) ��=500(mysql)
3���Ȱ�װ����ˡ��ٰ�װ�ͻ���
[root@hadoop01 software]# rpm -ivh MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm
warning: MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY
Preparing... ########################################### [100%]
1:MySQL-server ########################################### [100%]
......
[root@hadoop01 software]# rpm -ivh MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm
warning: MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY
Preparing... ########################################### [100%]
1:MySQL-client ########################################### [100%]
[root@hadoop01 software]#
4���������ļ�
[root@hadoop01 software]# cd /usr
[root@hadoop01 usr]# vim my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.6/en/server-configuration-defaults.html
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf8
5���ŵ�����Ŀ¼
[root@hadoop01 usr]# cp /usr/share/mysql/mysql.server /etc/init.d/mysqld
6������
[root@hadoop01 usr]# cp /usr/share/mysql/mysql.server /etc/init.d/mysqld
[root@hadoop01 usr]# cd /etc/init.d
[root@hadoop01 init.d]# service mysqld start
Starting MySQL. [ȷ��]
[root@hadoop01 init.d]# service mysqld status
MySQL running (6062) [ȷ��]
7����¼MySql
(���������)
[root@hadoop01 init.d]# vim /root/.mysql_secret
�������е�SdBlnGZt7EoDIvwy(ʮ��λ�ַ�)
[root@hadoop01 init.d]# mysqladmin -u root -p password root
Enter password: (���ƵĶ���)
Warning: Using a password on the command line interface can be insecure.
[root@hadoop01 init.d]# mysql -u root -p
Enter password: (root)
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.29 MySQL Community Server (GPL)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
8��ʹ��
(1)�������ݿ�hive
mysql> create database hive character set latin1;
Query OK, 1 row affected (0.00 sec)
(2)Ȩ����
mysql> grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
Query OK, 0 rows affected (0.00 sec)
(3)ˢ����Ч
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
)�˳�(
mysql> exit;
Bye
9������hive-site.xml
[root@hadoop01 init.d]# cd /home/software/hive/conf/
[root@hadoop01 conf]# cp hive-default.xml.template hive-site.xml
[root@hadoop01 conf]# vim hive-site.xml
�ѹ���ƶ���configuration����һ��,����3890dd,��Ҫ������u
--><configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value></property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value></property>
</configuration>
10�������ļ�������
[root@hadoop01 software]# cp mysql-connector-java-5.1.38-bin.jar hive/lib
[root@hadoop01 software]# cd /home/software/hive/bin/
[root@hadoop01 bin]# sh hive
Logging initialized using configuration in jar:file:/home/software/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
Ԫ����:���ݿ���hdfs·���Ķ�Ӧ��ַ
11��һЩ����
hive> create database park;
OK
Time taken: 0.763 seconds
hive> use park;
OK
Time taken: 0.039 seconds
hive> create table student(id int,name string);
OK
Time taken: 0.417 seconds
hive> insert into student values(1,'zhangsan');
�塢hive
(һ)�ڲ������ⲿ��(��ҵ���ⲿ���õĽ϶�)
(��)�ڲ����ĸ���
����hive�ィһ�ű�,Ȼ�����������������(��insert���Բ�������,Ҳ����ͨ�������ⲿ�ļ���ʽ����������),�����ı���֮Ϊhive���ڲ���
(��)�ⲿ���ĸ���
1��HDFS���Ѿ���������,Ȼ��,ͨ��hive����һ�ű�����������ļ����ݡ�����������֮Ϊ�ⲿ��
2��ע��,hive�ⲿ����������HDFS���ijһ��Ŀ¼�µ��ļ�����
(��)�ⲿ����������:
����hive,ִ��:create external table stu (id int,name string) row format delimited fields terminated by �� �� location ��/Ŀ¼·����
(��)�ڲ������ⲿ�������
1�������ڲ���,��ɾ���ñ���ʱ��,HDFS��Ӧ��Ŀ¼�ڵ�ᱻɾ��
2�������ⲿ��,��ɾ���ñ���ʱ��,HDFS��Ӧ��Ŀ¼�ڵ㲻��ɾ��
(��)����ʹ��
(1)
hive> use park;
hive> show tables;
OK
book
student
values__tmp__table__1
Time taken: 0.043 seconds, Fetched: 3 row(s)
hive> drop table student;
Moved: 'hdfs://hadoop01:9000/user/hive/warehouse/park.db/student' to trash at: hdfs://hadoop01:9000/user/root/.Trash/Current
OK
Time taken: 0.386 seconds
hive> create table student(id int,name string) row format delimited fields terminated by ' ';
hive> insert into student values (1,'zhagnsan');
(2)
hive> load data local inpath '/home/student' into table student;
Loading data to table park.student
Table park.student stats: [numFiles=2, numRows=0, totalSize=40, rawDataSize=0]
OK
Time taken: 0.183 seconds
hive> select * from student;
OK
1 zhagnsan
3 mayun
4 hafl
5 agkh
6 agkh

(3)�½�stu�ļ�,��д��һЩ���ݡ�Ȼ�����ϴ���dfs��

hive> select * from student;
OK
1 zhagnsan
7 wangmazi
8 bajie
3 mayun
4 hafl
5 agkh
6 agkh
(4)�½�teacher�ļ�,��д��һЩ���ݡ�Ȼ�����ϴ���dfs��(���ϴ�ǰ,�Ƚ����ļ���teacher)
(5)������һ���ϴ������ݴ����ⲿ��
hive> create external table teacher(id int,name string) row format delimited fields terminated by ' ' location '/teacher';
OK
Time taken: 0.11 seconds
hive> select * from teacher;
OK
1 shashibiya
2 aosaibai
Time taken: 0.055 seconds, Fetched: 2 row(s)
hive>
(6)�����ڲ���,��ɾ���ñ���ʱ��,HDFS��Ӧ��Ŀ¼�ڵ�ᱻɾ��
hive> drop table student;
Moved: 'hdfs://hadoop01:9000/user/hive/warehouse/park.db/student' to trash at: hdfs://hadoop01:9000/user/root/.Trash/Current
OK
Time taken: 0.131 seconds
hive>
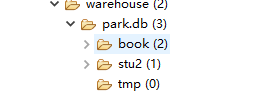
(7)�����ⲿ��,��ɾ���ñ���ʱ��,HDFS��Ӧ��Ŀ¼�ڵ㲻��ɾ��
hive> drop table teacher;
OK
Time taken: 0.101 seconds

(��)������
(��)����
1������������ͨ������ָ�����ֶ������Hive�IJ�ѯЧ��
2�����������ϴ�������,���������ӷ�����������ȫ����ѯ
(��)������ָ��
| ָ�� | ���� | ����˵�� |
|---|---|---|
| create | table book (id int, name string) partitioned by (country string) row format delimited fields terminated by �� '; | ����book��,��country ��Ϊ���� �ڴ���������ʱ,partitioned�ֶο��Բ����ֶ��б��С����ɵı����Զ��ͻ���и��ֶΡ� |
| load data local inpath ��/home/cn.txt�� overwrite into table book partition (country=��cn��); | �������ļ�cn.txt���ӵ�book����,�����ֶ�Ϊcn ��HDFS������category=cnĿ¼ | |
| select * from book where country =��cn��; | �鿴����Ϊcn������ | |
| ALTER TABLE book add PARTITION (country = ��jp��) location ��/user/hive/warehouse/park.db/book/country=jp��; | ��ָ����Ŀ¼����Ϊ�����ֶ� | |
| show partitions book | �鿴���� | |
| msck repair table book; | ������ | |
| alter table book drop partition(country=��cn��); | ɾ������ | |
| alter table book partition(category=��french��) rename to partition (category=��hh��); | �ķ��������� |
(��)����ʹ��
hive> create table book (id int, name string) partitioned by (country string) row format delimited fields terminated by ' ';
OK
Time taken: 0.084 seconds
�ڴ���2��
[root@hadoop01 ~]# cd /home/
[root@hadoop01 home]# vim cnbook
1 hongloumeng
2 shuihuzhuan
3 shanguoyanyi
4 xiyouji
�ڴ���1��
hive> load data local inpath '/home/cnbook' into table book partition (country='cn');
Loading data to table park.book partition (country=cn)
Partition park.book{country=cn} stats: [numFiles=1, numRows=0, totalSize=53, rawDataSize=0]
OK
Time taken: 1.554 seconds
hive> select * from book;
OK
1 hongloumeng cn
2 shuihuzhuan cn
3 shanguoyanyi cn
4 xiyouji cn
Time taken: 0.316 seconds, Fetched: 4 row(s)
hive> desc book;
OK
id int
name string
country string
# Partition Information
# col_name data_type comment
country string
Time taken: 0.091 seconds, Fetched: 8 row(s)
hive>
��eclipse�д���country=en�ļ���,����windows�б�дteacher���ϴ���hdfs�ϵĸոմ������ļ�����
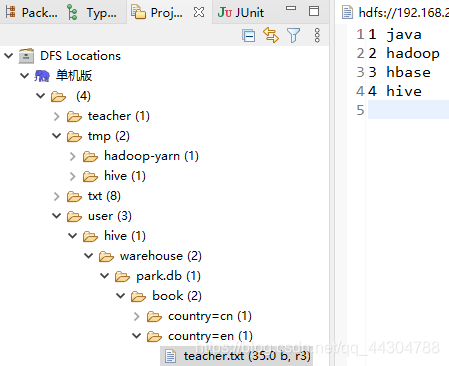
�ڴ���1��
hive> alter table book add partition(country='en') location '/user/hive/warehouse/park.db/book/country=en';
OK
Time taken: 0.076 seconds
hive> select * from book;
OK
1 hongloumeng cn
2 shuihuzhuan cn
3 shanguoyanyi cn
4 xiyouji cn
1 java en
2 hadoop en
3 hbase en
4 hive en
Time taken: 0.082 seconds, Fetched: 8 row(s)
hive> alter table book add partition(country='en') location '/user/hive/warehouse/park.db/book/country=en';
OK
Time taken: 0.076 seconds
hive> select * from book;
OK
1 hongloumeng cn
2 shuihuzhuan cn
3 shanguoyanyi cn
4 xiyouji cn
1 java en
2 hadoop en
3 hbase en
4 hive en
Time taken: 0.082 seconds, Fetched: 8 row(s)
hive>
��eclipse�д���country=jp�ļ���,����windows�б�дteacher���ϴ���hdfs�ϵĸոմ������ļ�����
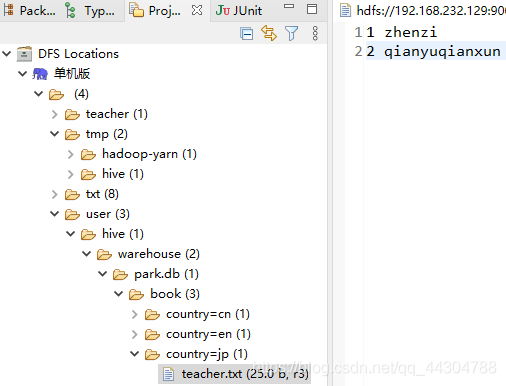
hive> msck repair table book;
OK
Partitions not in metastore: book:country=jp
Repair: Added partition to metastore book:country=jp
Time taken: 0.415 seconds, Fetched: 2 row(s)
hive> select * from book;
OK
1 hongloumeng cn
2 shuihuzhuan cn
3 shanguoyanyi cn
4 xiyouji cn
1 java en
2 hadoop en
3 hbase en
4 hive en
1 zhenzi jp
2 qianyuqianxun jp
Time taken: 0.482 seconds, Fetched: 10 row(s)
hive> alter table book drop partition(country='jp');
Moved: 'hdfs://hadoop01:9000/user/hive/warehouse/park.db/book/country=jp' to trash at: hdfs://hadoop01:9000/user/root/.Trash/Current
Dropped the partition country=jp
OK
Time taken: 0.555 seconds
hive> show partitions book;
OK
country=cn
country=en
Time ta
hive> alter table book partition(country='cn') rename to partition(country='china');
OK
Time taken: 0.304 seconds
hive> show partitions book;
OK
country=china
country=en
Time taken: 0.087 seconds, Fetched: 2 row(s)
hive>
(��)��Ͱ��
��Ͱ����Ĭ�ϲ�����
(��)����
1����Ͱ����һ�ָ�ϸ���ȵ����ݷ��䷽ʽ
2��һ�����ȿ��Է���Ҳ���Է�Ͱ
3����Ͱ����Ҫ������ʵ�����ݵij���,����������ݲ���
4����Ͱ��ͨ��hash��Ͱ�㷨,�����ݷַ��ڲ�ͬ��Ͱ(hdfs�е��ļ�)��,���������ȡ
5����Ͱ������Ĭ���Dz�������,��Ҫ�ֶ�����:set hive.enforce.bucketing=true;
6����Ͱ�����������ⲿ�ļ���ʽ��������,ֻ�ܴ�����һ�ű����ݵ���
(��)��Ͱ���
| ָ�� | ���� | ����˵�� |
|---|---|---|
| create table teacher(name string) clustered by (name) into 6 buckets row format delimited fields terminated by �� '; | ����teacher��,��name��Ϊ��Ͱ����,��Ϊ6��Ͱ | |
| insert overwrite table teacher select * from tmp; | ��tmp���е��������ӵ�teacher���� | ʵ�����Dz�����6���ļ����ڴ洢����Ͱ������ |
| select * from teacher tablesample(bucket 1 out of 3 on name); | ���г��� | ������ʽΪ:bucket x out of y on XXX:1��x��ʾ��������ʼͰ,����bucket 1 out of 3��ʾ�ӵ�1 ��Ͱ��ʼ��ȡ����; 2��y���������ı���,Ҫ�������Ͱ�������ӻ���������:a. ���Ͱ��Ϊ6,yΪ2,���ʾ��ȡ6/2=3��Ͱ�е�����; b. ���Ͱ��Ϊ6,yΪ3,���ʾ��ȡ6/3=2��Ͱ�е����� c. ���Ͱ��Ϊ6,yΪ12,���ʾ��ȡ6/12=0.5��Ͱ�е�����; 3�����Ͱ��Ϊ6,����Ϊbucket 1 out of 3 on id��ʾ�ӵ�1��Ͱ��ʼ����,��ȡ2��Ͱ������,���Գ�ȡ������Ϊ1��4Ͱ�е����� |
(��)��������(δ��� ����Ƶ����1)
(1)����
hive> set hive.enforce.bucketing=true;
(2)
hive> create table teacher(name string) clustered by (name) into 6 buckets row format delimited fields terminated by ' ';
OK
Time taken: 0.122 seconds
hive> create table tmp(name string) clustered by (name) into 6 buckets row format delimited fields terminated by ' ';
OK
Time taken: 0.049 seconds
hive> insert overwrite table teacher select * from tmp
(��)һЩ˵��
x out of y
x��ʾ���Ǵ�������ʼͰ
y���������ı���6/y=6/3=2��
2 out of 3�ӵڶ���Ͱ��ʼ��ȡ,һ����ȡ����Ͱ������

��������
(һ)�����IJ���
����С��λ��
hive> select round(4.17);
OK
4.0
Time taken: 0.07 seconds, Fetched: 1 row(s)
hive> select round(4.1742767537,3);
OK
4.174
Time taken: 0.043 seconds, Fetched: 1 row(s)
����ȡ��
hive> select floor(3.78);
OK
3
Time taken: 0.04 seconds, Fetched: 1 row(s)
����ȡ֤
hive> select ceil(3.1415926);
OK
4
����
hive> select log10(10);
OK
1.0
Time taken: 0.045 seconds, Fetched: 1 row(s)
����
hive> select sqrt(9);
OK
3.0
Time taken: 0.05 seconds, Fetched: 1 row(s)
����ֵ
hive> select abs(-2);
OK
2
Time taken: 0.039 seconds, Fetched: 1 row(s)
(��)����ת��
hive> select cast('1' as bigint);
OK
1
Time taken: 0.043 seconds, Fetched: 1 row(s)
��1970�����ھ����˶�����
hive> select unix_timestamp('2020-08-20','yyyy-MM-dd');
OK
1597852800
Time taken: 0.049 seconds, Fetched: 1 row(s)
hive> select to_date('2020-08-29 22:34:01');
OK
2020-08-29
Time taken: 0.055 seconds, Fetched: 1 row(s)
���ؾ���������
hive> select datediff('2021-08-23','2021-08-01') ;
OK
22
Time taken: 0.043 seconds, Fetched: 1 row(s)
hive>
(��)����
if�������ַ����������ų��հ��ַ�
hive> select if(3>5,true,false);
OK
false
Time taken: 0.086 seconds, Fetched: 1 row(s)
hive> select length('hello');
OK
5
Time taken: 0.042 seconds, Fetched: 1 row(s)
hive> select reverse('hello');
OK
olleh
Time taken: 0.043 seconds, Fetched: 1 row(s)
hive> select substr("nihaoya",3,3);
OK
hao
Time taken: 0.04 seconds, Fetched: 1 row(s)
hive> select trim(' niaho ');
OK
niaho
Time taken: 0.037 seconds, Fetched: 1 row(s)
hive>
(��)explod
(��)����
1��explode ������Խ�������,��ָ�������зֳ�����
2����explode�����з�,ע�����ֻ��һ��,������������string����,��Ϊֻ���ַ����Ͳ������з�
(��)����word.txt������ͳ��(δ��ɼ���Ƶ����1)
1�������ⲿ������hdfs��/wordĿ¼
create external table word (word string) location ��/word��;
2��ͨ��explode ���wod�����ݰ��ո�����з�
Select explode (split(word,�� ��))from word;
3�����з���ı���Ϊ�±����е���ͳ��
select name,count (name) from (select explode(split(word,�� ')) name from word) as word1 group by name;
(��)��������
hive> create external word(word string) row format delimited fields terminated by '|' location '/word';
hive> select * from word;
hive> select explode(split(word,' ')) from word;
hive> select name,count(name) from (select explode(split(word,' ')) from word)as word1;
(��)JDBC
(��)����
1��hiveʵ����jdbc�ӿ�,���Կ���ͨ��java�������
2��hive��jdbc������ʵ��Ӧ�����õIJ���,һ�㶼����HDFS������ļ������Ͻ����ⲿ�������в�ѯ����������jdbc�˽�һ�¼��ɡ�
(��)ʵ�ֲ���:
1���ڷ������˿���HiveServer����:sh hive --service hiveserver2 & (�Ժ�̨�߳�����)
[root@hadoop01 ~]# sh hive--service hiveserver2 &
[1] 12239
2���������ع���,����jar��:

����hive\libĿ¼�µ�hive-jdbc-1.2.0-standalone.jar
����hadoop-2.7.1\share\hadoop\common�µ�hadoop-common-2.7.1.jar
3����дjdbc����ִ��
package cn.edu.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import org.junit.Test;
public class HIveJdbcTest {
@Test
public void testConnect() throws ClassNotFoundException,SQLException{
//ע������
//ע�����ݿ�����,�õ�hive��jdbc,�������̶�д��
Class.forName("org.apache.hive.jdbc.HiveDriver");
//--��ȡ����
//����õ���hive2����,��дjdbc:hive2,�������hive��������ip�Լ��˿ں�,�˿ں�Ĭ����10000
Connection conn = DriverManager.getConnection( "jdbc:hive2://192.168.232.129:10000/park","root","root");
// --����ִ����
Statement stat = conn.createStatement();//--ִ��sql
//--�������
ResultSet rs = stat.executeQuery( "select* from tmp");
//--�������
while(rs.next()){
String id = rs.getString( "id");
String name = rs.getString( "name" ) ;
System.out.println("id: "+id+ "~"+ "name : "+name);
}
//--����
stat.close();
conn.close();
}
@Test
public void testCreate() throws ClassNotFoundException,SQLException{
//ע������
Class.forName("org.apache.hive.jdbc.HiveDriver");
//--��ȡ����
Connection conn = DriverManager.getConnection( "jdbc:hive2://192.168.232.129:10000/park","root","root");
// --����ִ����
Statement stat = conn.createStatement();//--ִ��sql
//--�������
//executeUpdate������:������,����в��������Լ�ɾ����
stat.executeUpdate( "create table stu2 (id int,name string)");
//--����
stat.close();
conn.close();
}
@Test
public void testInsert() throws ClassNotFoundException,SQLException{
//ע������
Class.forName("org.apache.hive.jdbc.HiveDriver");
//--��ȡ����
Connection conn = DriverManager.getConnection( "jdbc:hive2://192.168.232.129:10000/park","root","root");
// --����ִ����
Statement stat = conn.createStatement();//--ִ��sql
//--�������
stat.executeUpdate( "insert into stu2 values(1,'wangwu')");
//--����
stat.close();
conn.close();
}
}
4��ִ�н����֤
hive> show databases;
OK
default
park
Time taken: 0.022 seconds, Fetched: 2 row(s)
hive> use park;
OK
Time taken: 0.017 seconds
hive> show tables;
OK
book
stu2
student
teacher
tmp
Time taken: 0.04 seconds, Fetched: 5 row(s)
hive> select * from stu2;
OK
1 wangwu
Time taken: 0.377 seconds, Fetched: 1 row(s)
hive>
(��)spool
(��)����
1�� sqoop��Apache �ṩ�Ĺ���,����hdfs��ϵ�����ݿ�֮�����ݵĵ���͵���
2�����Դ�hdfs�������ݵ���ϵ�����ݿ�,Ҳ���Դӹ�ϵ�����ݿ�����ݵ�hdfs
(��)ʵ�ֲ���:
1����sqoop��װ��,������ַ:http://sqoop.apache.org
2������jdk����������Hadoop�Ļ�����������Ϊsqoop��ʹ���ǻ�ȥ�һ���������Ӧ��·��,�Ӷ���������
3����ѹSqoop�İ�װ��
4����Ҫ��Ҫ���ӵ����ݿ������������sqoop��libĿ¼��(�������õ���mysql���ݿ�)
5������ָ�����sqoop
(��)����ָ��(δ��� ����Ƶ����3)
| ˵�� | ָ��ʾ�� |
|---|---|
| �鿴mysql�������ݿ� | sh sqoop list-databases --connect jdbc:mysql://192.168.48.10:3306/ -username root -password root |
| �鿴ָ�����ݿ��µ����б� | sh sqoop list-tables --connect jdbc:mysql://hadoop02:3306/hive -username root -password root |
| ��ϵ�����ݿ� ->hdfs | ʵ�ֲ���:1������mysql���ݿ��test�����½���һ��tabx��,�������������:a. ����:create table tabx (id int,name varchar(20)); b.����:insert into tabx (id,name) values (1,��aaa��),(2,��bbb��),(3,��ccc��),(1,��ddd��),(2,��eee��),(3,��fff��); 2�����뵽sqoop��binĿ¼��,ִ�е������:sh sqoop import --connect jdbc:mysql://192.168.48.10:3306/test --username root --password root --table tabx --target-dir ��/sqoop/tabx�� --fields-terminated-by �� ���� (��������Ĭ�ϱ���ķָ��,�ú��ִ���)�� -m 1; |
| hdfs ->��ϵ�����ݿ� | ִ��:sh sqoop export --connect jdbc:mysql://192.168.48.10:3306/test --username root --password root --export-dir ��/sqoop�� --table student -m 1 --fields-terminated-by �� ���� 'ע:sqoopֻ�ܵ�������,�����Զ������������ڵ���֮ǰ,Ҫ����mysql���ݿ��ィ�ö�Ӧ�ı� |
| sh sqoop import -help | �鿴import�İ���ָ�� |
(��)����ʵ��
����������һЩ���⼰�������
(һ)Namenodeû������
1�����ȵ�������һ��namenode
hadoop-deamon.sh start namenode
2�����������������,���������
[root@hadoop01 current]# cd /home/software/hadoop-2.7.1/tmp/dfs/name/current/
[root@hadoop01 current]# cat seen_txid
[root@hadoop01 current]# cat VERSION
[root@hadoop01 current]# cd /home/software/hadoop-2.7.1/tmp/dfs/data/current/
[root@hadoop01 current]# cat VERSION
�۲�����VERSION�е�cluserId�Ƿ�һ�²�һ������cluserid(����һ���еĸ��Ƶ��ڶ�����)
3��һ���Ļ�,�鿴�ڴ�(namenode������Ҫ�϶��ڴ�)
free -m
��һ�»��� ������
echo 3 > /proc/sys/vm/drop_caches
4�������Dz��п�һ����־(�����)
[root@hadoop01 current]# cd /home/software/hadoop-2.7.1/tmp/dfs/name/current/
5�����ʵ�ڲ������¸�ʽ��,��ʽ��֮ǰ,��ɾ��tmp
(��)����junit��δ�ɹ�




(��)������̨����ʧ��
[root@hadoop01 bin]# sh hive--service hiveserver2 &
[1] 12738
[root@hadoop01 bin]# sh: hive--service: û���Ǹ��ļ���Ŀ¼
[1]+ Exit 127 sh hive--service hiveserver2
ʧ��ԭ��:����Ͽո�
[root@hadoop01 bin]# sh hive --service hiveserver2 &
[1] 12762
(��)java.sql.SQLException: The query did not generate a result set!
ԭ��,���д������create��insertӦʹ��executeUpdate����executeQuery��