втЭтЗЂЯж
ЧАСНЬьДђЫуЧЈвЦвЛЗнЪ§Он,здШЛЖјЯыЕНСЫApache Sqoop,ЫьДђПЊApacheЙйЭјбАевЯТдиСДНг,ЕЋЪЧОЙШЛУЛгаевЕНЫћЕФзйгАЁЃ

етВЛПЦбЇАЁ,ЧАМИИідТЛЙПДЕНЙ§РДзХ,гаЕуВЛЫРаФ,жБНгГЂЪдЕЧТНжБНгhttps://sqoop.apache.org/
Aapche SqoopЙйЭј
Project Sqoop has retired. For details please refer to its Attic page.
ApacheЛљН№ЛсРяОЙШЛЛЙгаЯюФПЭЫвлвЛЫЕ,заЯИПДСЫЯТ,дРДApache Sqoopдк2021Фъ6дТОЭвбОНјШыAtticСЫ,ОЭЪЧзюНќЕФЪТЧщЁЃВЛЙ§,ЁИAtticЁЙЪЧЩЖАЁ?ВЂУЛгаЬ§ЫЕЙ§;НјШыЕНAtticЕФЯюФПЛсеІбљ?,ЮвУЧМЬајЬНЫїЯТЁЃ

Apache AtticНщЩм
Apache AtticдРДОЭЯрЕБгкApacheЕФаЁКкЮн,ШчЙћApacheЭаЙмЕФЯюФПГЄЪБМфВЛЛюдО(ГЌЙ§2ФъУЛгаreleaseаТАцБО,УЛгаcommitterЁЂcontributerВЂЧвУЛгаЮДРДroadmap),ОЭЛсбЁдёНЋЯюФПвЦЖЏЕНAtticжа,етвВОЭЯрЕБгкApacheЕФЯюФПЙмРэСЫ,еЦЙмећИіЯюФПЕФЩњУќжмЦкЁЃ
SqoopвЦЖЏЕНAtticЕФЯюФПЖддлУЧгаЩЖгАЯьФи?
ФПЧАНЋSqoopзіЪ§ОнЧЈвЦЙЄОпЙЋЫОВЛдкЩйЪ§,ЕБSqoopвЦЖЏЕНAtticКѓ,ЕЅЕЅЪЙгУРДЫЕЪЧЭъШЋВЛЪмгАЯьЕФ;Apache AtticвРОЩЛсЬсЙЉДњТыПтЕФЯТди;ЕЋЪЧВЛЛсдйаоИДШЮКЮЕФbug,releaseаТАцБОСЫ,ВЂЧввВВЛЛсдйжиЦєЩчЧјЁЃ
ПДЕНетРяЦфЪЕОЭУЛгаетУДЛХСЫ,ЮвУЧЛЙФмМЬајгУ,ВЛЙ§ШчЙћгіЕНЮЪЬт,ЮвУЧжЛФмздМКНЈИіЗжжЇШЅfixСЫ,ДгВрУцРДЫЕ,вВФмЫЕУїSqoopдкФГИіНЧЖШЪЧГЩЙІЕФ,БЯОЙдјОГЩЮЊApacheЖЅМЖЯюФП,ШчЙћецЕФЪЧГЄЪБМфУЛгаrelease,гаПЩФмЪЧЫћШЗЪЕвбОЙЛГЩЪьСЫЁЃ
зМБИЙиБеAtticвГУцЕФЪБКђ,ЫГБуЩЈСЫвЛблдкAtticжаЕФЯюФП,ЛљБОЖМВЛШЯЪЖ,ЕЋвВПДЕНМИИіЪьЯЄЕФЩэгА,ШчChukwa,Sentry,EagleЁЃЯраХвВгаВЛЩйЙЋЫОдкЪЙгУ,БШШчЮвУЧЙЋЫОЛЙдкЪЙгУSentryЁЃЛЛИіНЧЖШ,ЯждкММЪѕПьЫйИќЕќЬЋбИЫйСЫ,ЫцзХЪБМфСїЪХ,УЛзМЙ§аЉФъHadoopЁЂSparkвВгаПЩФмУЛТфФиЁЃвдКѓЕФЪТЧщгжЫжЊЕРФи?УЛео,МЬајбЇАЩ,НёЬьЮвУЧЯШРДСФСФSqoopЁЃ
SqoopЖЈЮЛКЭЯжзД
МђЕЅРДЫЕSqoopЕФЖЈЮЛОЭЪЧHadoopЩњЬЌДцДЂКЭНсЙЙЛЏДцДЂжЎМфЕФЪ§ОнЧЈвЦЁЃЮвУЧБШНЯГЃМћЕФГЁОАОЭЪЧHDFS/HBase/HiveКЭMySql/OracleжЎМфЕФЪ§ОнЛЅЕМЁЃSqoopзїЮЊЪ§ОнДЋЪфЕФЧХСК,ЭЈЙ§ЖЈвхMapReduceЕФInPutFormatКЭOutPutFormatРДЖдНгдДДцДЂКЭФПЕФДцДЂЁЃ
зЂвтдкSqoopжаЩЯжЛЛсЩцМАMapReduceжаЕФMapНзЖЮ,ЖјВЛЛсгаReduceНзЖЮ
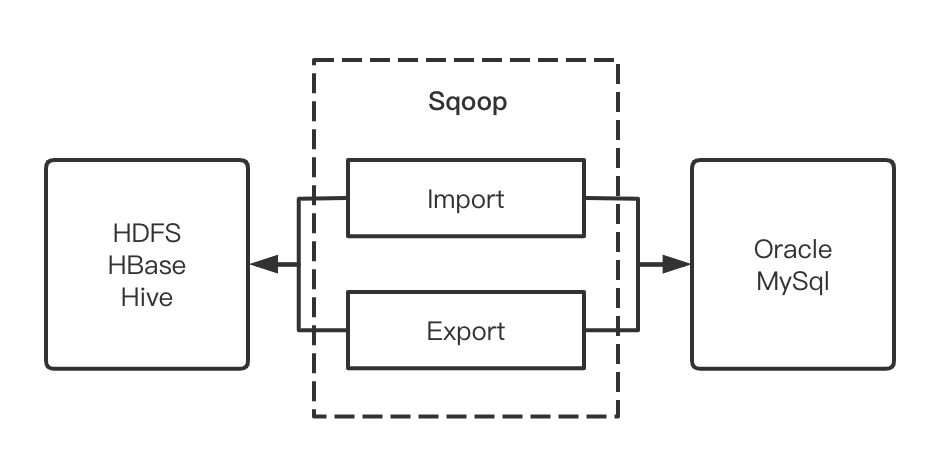
SqoopМмЙЙМђЭМ
ФПЧАSqoopзмЬхгаСНДѓАцБОЗжЮЊSqoop1КЭSqoop2,Sqoop1ЕФзюаТreleaseЪЧ1.4.7;Sqoop2ЕФзюаТreleaseЪЧ1.99.7;етРяШчЙћДѓМвЪЙгУЕФЛАЭЦМіЪЙгУSqoop1,ЖјSqoop2ЫфШЛдіМгСЫCLIКЭRest api,ЕЋЪЕМЪЩЯЪЧвЛИіАыГЩЦЗ,ИњSqoop1вВЭъШЋВЛМцШн,ВЂЧвЮоТлЪЧCDHЛЙЪЧжЎЧАApacheЖМЪЧВЛНЈвщЩњВњЪЙгУЕФ,здМКЫцБуЭцЭцЛЙПЩвдЁЃБОЦЊжївЊНщЩмЕФАцБОЛЙЪЧЛљгкSqoop1.
SqoopЧЈвЦдРэ
КЫаФТпМ
ећИіSqoopЕФЧЈвЦЙ§ГЬ,ЖМЛсЖдгІзХвЛИіMapReduceзївЕ,ЪЕМЪЩЯжЛгаMapНзЖЮ,ЖјЧЈвЦДѓжТЗжЮЊ5ИіВПЗж,ШчЯТЫљЪОЁЃ
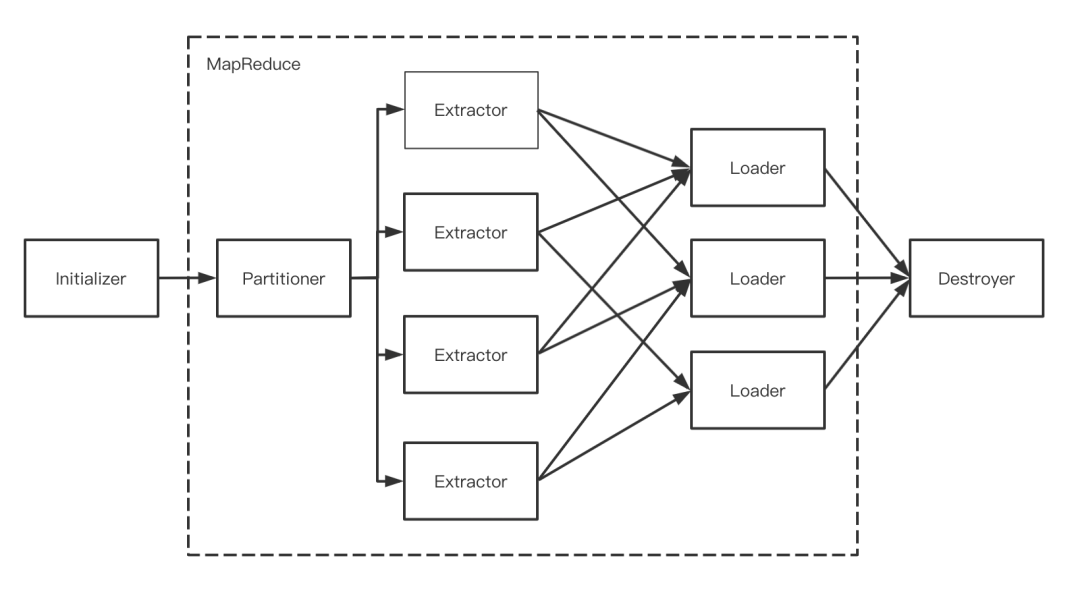
SqoopТпММђЭМ
ЁИInitializerЁЙ:ећИіSqoopЧЈвЦЕФГѕЪМЛЏНзЖЮ,ЭъГЩЧЈвЦЧАЕФзМБИЙЄзї,ШчСЌНгЪ§ОндД,ДДНЈСйЪББэ,ЬэМгвРРЕЕФjarАќЕШЁЃ
ЁИPartitionerЁЙ:дДЪ§ОнЗжЦЌ,ИљОнзївЕВЂЗЂЪ§РДОіЖЈдДЪ§ОнвЊЧаЗжЖрЩйЦЌЁЃ
ЁИExtractorЁЙ:ПЊЦєextractorЯпГЬ,ФкДцжаЙЙдьЪ§ОнаДШыЖгСажЎжа;
ЁИLoaderЁЙ:ПЊЦєloaderЯпГЬ,ДгЖгСажаЖСШЁЪ§ОнВЂаДШыЖдгІКѓЖЫ;
ЁИDestroyerЁЙ:ећИіЧЈвЦЕФЪеЮВЙЄзї,ЖЯПЊsqoopгыЪ§ОндДЕФСЌНг,ЭъГЩзЪдДЛиЪе;
СїГЬНтЮі
ЕБЧЈвЦШЮЮёЦєЖЏКѓ,ЪзЯШЛсНјШыГѕЪМЛЏВПЗж,ЪЙгУJDBCМьВщЕМШыЕФЪ§ОнБэ,МьЫїГіБэжаЕФЫљгаСавдМАСаЕФЪ§ОнРраЭ,ВЂНЋетаЉЪ§ОнРраЭгГЩфЮЊJavaЪ§ОнРраЭ,дкзЊЛЛКѓЕФMapReduceгІгУжаЪЙгУетаЉЖдгІЕФJavaРраЭРДБЃДцзжЖЮЕФжЕ,дкУПДЮSqoopЕФШЮЮёжДааЪБ,ДњТыЩњГЩЦїЪЙгУетаЉаХЯЂРДДДНЈЖдгІБэЕФРр,гУгкБЃДцДгБэжаГщШЁЕФМЧТМ,МДxxxx.javaЮФМўЁЃНєНгзХPartitionerЛсИљОн--split-byЛђеп-mжИЖЈећИіШЮЮёЕФЗжЦЌЪ§СП,ШчВЛжИЖЈФЌШЯЪЧ4ИіЗжЦЌ(УПвЛИіpartitionЖдгІзХвЛИіMapper),ШЛКѓБрвыГЩвЛИіБОЕиJarАќгУгкЬсНЛMapReduceзївЕЁЃЕБШЮЮёЬсНЛЕНМЏШККѓ,УПИіMapperЛсЗжБ№ЦєЖЏвЛИіExtractorЯпГЬКЭLoaderЯпГЬ,ећИіMapReduceЕФInputFormatЪЕМЪЩЯЪЧЭЈЙ§JDBCЖСШЁдЖЫЪ§ОнаДШыЕНContextжа,ЖјLoaderЯпГЬНЋДгContextжаЖСГіаДШыЖдгІЕФЪ§ОнзїЮЊOutPutFormatЧЈвЦЕФФПЕФЖЫЁЃЕБШЮЮёжДааЭъГЩКѓ,yarnзЪдДЪЭЗХ,ЫцжЎDestroyerЛиЪеЫљгагыЪ§ОндДЕФСЌНгЁЃетРяжївЊНВЪіЕФЪЧImportЕФЙ§ГЬ,ЖјexportСїГЬгыimportЪЎЗжЯрЫЦ,ЪЧАбЪ§ОнНтЮіЮЊвЛЬѕЬѕinsert гяОф,дкДЫВЛЙ§ЖрНтЮіЁЃ
SqoopЧЈвЦЪЕеН
ЧЁЗъБОШЫе§дкзіDorisЕНHiveЕФЧЈвЦВтЪд(DorisЪЧвЛИіЛљБОМцШнMySQLавщЕФOLAPв§Чц),ЪЕеНЮЇШЦDorisЕФНјааеЙПЊ
ЧЈвЦЧАзМБИ
-
JDK/ZooKeeper/HDFS/Yarn/HiveЕФВПЪ№ВЛЪЧБОЦЊжиЕу,ЭјЩЯЮФЕЕКмЖр,ПЩвдздааВЮПМВПЪ№ЁЃ
-
БОЦЌНВЪіЕФЪЧSqoop1,ИНЯТдиЕижЗhttp://archive.apache.org/dist/sqoop/ЁЃзЂвтSqoopВПЪ№ЕФЕФЪБКђашвЊЕМШыmysql-connector-java.jar,ЦфЫће§ГЃаоИФsqoop-env.shМДПЩ,змЬхSqoopЕФВПЪ№БШНЯМђЕЅЁЃ
-
ЮвУЧЯШРДПДПДDorisдДЖЫЪ§ОнБэИёЪНЁЃИУБэга3497079ЬѕЪ§Он
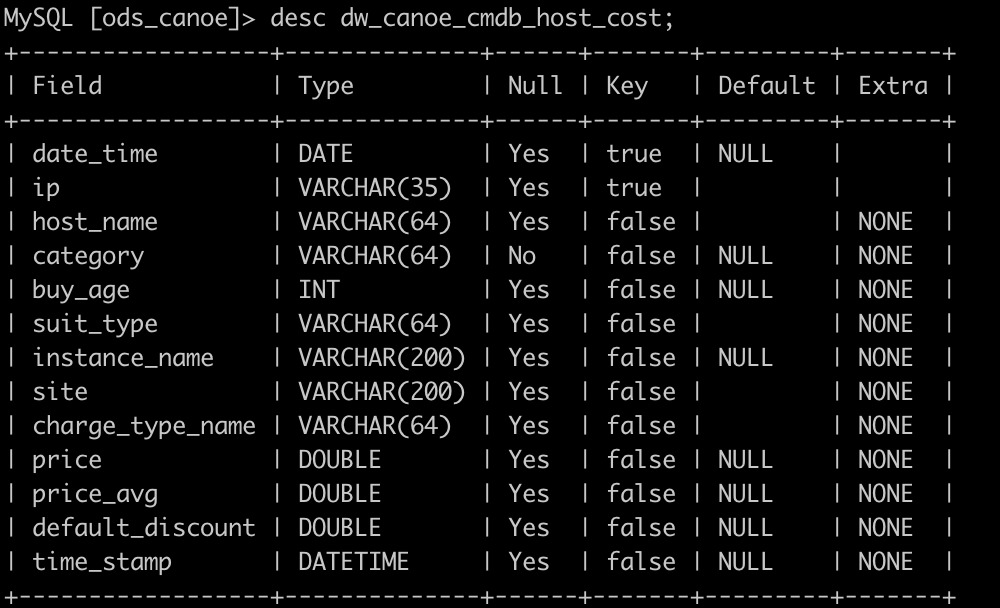
ПЊЪМЧЈвЦ
-
ЦєЖЏSqoopШЮЮёПЊЪМЧЈвЦ,ЛсЬсНЛMapReduceзївЕЕНYarnЩЯ,ЮвУЧзюжеЕФФПЕФЪЧНЋЪ§ОнТфЕиЕНHDFSЩЯЁЃ
sqoop??import??\
--connect?jdbc:mysql://Host:IP/ods_canoe??#?jdbcСЌНгЕижЗ
--username?user??#?гУЛЇ
--password?password??#?УмТы
--delete-target-dir??#?ЩОГ§ЖдгІHDFSФПТМЯТЕФЪ§Он
--target-dir?/Canoe??#?ЖдгІHDFSЕФФПТМЮЛжУ
--table?dw_canoe_cmdb_host_cost??#?дДЖЫЕФБэУћ
--split-by?buy_age?#??ИљОнbuy_ageзжЖЮНјааЧаЗж,зЂвтЪЧIntРраЭ
--compress??#?ЦєЖЏбЙЫѕ
--compression-codec?org.apache.hadoop.io.compress.SnappyCodec??#?ЪЙгУSnappyбЙЫѕ
-m?10??#?10ИіЗжЦЌМД10ИіMap
-
ЕБШЛЮвУЧПЩвдЪЙгУSqoopНЋDoirsжаЕФЪ§ОнжБНгЕМШыЕНhiveжа,ЕЋгЩгкDorisЪ§ОнИёЪНDATETIME,дкHiveжаЪЧВЛМцШнЕФ,вђДЫБОДЮУЛгаЪЙгУетжжЗНЗЈЁЃШчЙћЪ§ОнРраЭЦЅХф,ПЩвдЪЙгУШчЯТВЮЪ§жБНгЕМШыhiveЁЃ
--hive-import???#?Ъ§ОнЕМШыЕНhiveжа
--hive-table?testSqoop???#?hiveжаЕФБэУћ
--hive-database?default??#?hiveжаЕФПтУћ
-
MapReduceШЮЮёжДааЭъГЩКѓ,ЮвУЧМьВщЯТHDFSЪЧЗёгаЪ§ОнЩњГЩЁЃ
hadoop?fs?-ls?/Canoe
Found?11?items
-rw-r--r--???3?work?supergroup??????????0?2021-06-16?19:58?/Canoe/_SUCCESS
-rw-r--r--???3?work?supergroup???11978345?2021-06-16?19:58?/Canoe/part-m-00000.snappy
-rw-r--r--???3?work?supergroup???11694631?2021-06-16?19:58?/Canoe/part-m-00001.snappy
-rw-r--r--???3?work?supergroup????6726724?2021-06-16?19:57?/Canoe/part-m-00002.snappy
-rw-r--r--???3?work?supergroup???14511453?2021-06-16?19:58?/Canoe/part-m-00003.snappy
-rw-r--r--???3?work?supergroup???10708857?2021-06-16?19:58?/Canoe/part-m-00004.snappy
-rw-r--r--???3?work?supergroup????4459765?2021-06-16?19:57?/Canoe/part-m-00005.snappy
-rw-r--r--???3?work?supergroup????1289616?2021-06-16?19:57?/Canoe/part-m-00006.snappy
-rw-r--r--???3?work?supergroup??????94095?2021-06-16?19:57?/Canoe/part-m-00007.snappy
-rw-r--r--???3?work?supergroup????????999?2021-06-16?19:57?/Canoe/part-m-00008.snappy
-rw-r--r--???3?work?supergroup??????42111?2021-06-16?19:57?/Canoe/part-m-00009.snappy
HDFSНсЙћбщжЄ
-
гЩгкЮвЩшжУЕФЪЙгУSnappyИёЪННјаабЙЫѕ,ЮвУЧРДМьВщЯТЪЕМЪЕФааЪ§ЪЧЗёгыDorisжаЯрЭЌЁЃ
hadoop?fs?-text??/Canoe/*|wc?-l
21/05/16?19:58:54?INFO?compress.CodecPool:?Got?brand-new?decompressor?[.snappy]
3497079
Ъ§ОнЕМШыHive
-
бщжЄСЫHDFSЪ§ОнКѓ,ЮвУЧРДДДНЈHiveБэ,зЂвтетРягаСНжжбЁдё,
-
ДДНЈHiveЦеЭЈБэ,ШЛКѓНЋЪ§ОнLoadЕНБэжа
-
ДДНЈHiveЭтВПБэ,жЦЖЈЕНжЎЧАЕМГіЕФ/CanoeТЗОЖЯТ
ЁИhiveЦеЭЈБэЗНЪНЁЙ
hive>?CREATE???TABLE???`test_sqoop`?(
????>???`date_time`?date?,
????>???`ip`?varchar(35)??,
????>???`host_name`?varchar?(64)?,
????>???`category`?varchar?(64)?,
????>???`buy_age`?int??COMMENT?,
????>???`suit_type`?varchar(64)??,
????>???`instance_name`?varchar(200)?,
????>???`site`?varchar(200)?,
????>???`charge_type_name`?varchar(64)?,
????>???`price`?double??,
????>???`price_avg`?double?,
????>???`default_discount`?,
????>???`time_stamp`?date?)?#?зЂвтhiveжажЛгаdateРраЭ,УЛгаdatetimeРраЭ
????>?ROW?FORMAT?DELIMITED?FIELDS?TERMINATED?BY?","
hive>?load?data?inpath?'/Canoe'?overwrite?into?table?test_sqoop;
ЁИ2.hiveЭтВПБэЗНЪНЁЙ
hive>?CREATE??external?TABLE???`test_sqoop`?(
????>???`date_time`?date?,
????>???`ip`?varchar(35)??,
????>???`host_name`?varchar?(64)?,
????>???`category`?varchar?(64)?,
????>???`buy_age`?int??COMMENT?,
????>???`suit_type`?varchar(64)??,
????>???`instance_name`?varchar(200)?,
????>???`site`?varchar(200)?,
????>???`charge_type_name`?varchar(64)?,
????>???`price`?double??,
????>???`price_avg`?double?,
????>???`default_discount`?,
????>???`time_stamp`?date?)?#?зЂвтhiveжажЛгаdateРраЭ,УЛгаdatetimeРраЭ
????>?ROW?FORMAT?DELIMITED?FIELDS?TERMINATED?BY?","
????>?location?'/Canoe';
HiveНсЙћбщжЄ
hive>?select?count(*)?from?test_sqoop;
Query?ID?=?work_20210816200848_acbb8c1a-b114-4872-9e76-45f5420d02ba
Total?jobs?=?1
Launching?Job?1?out?of?1
Starting?Job?=?job_1595742917056_0028,?Tracking?URL?=?http://testjie01:23188/proxy/application_1595742917056_0028/
Hadoop?job?information?for?Stage-1:?number?of?mappers:?10;?number?of?reducers:?1
2021-06-16?20:08:56,677?Stage-1?map?=?0%,??reduce?=?0%
2021-06-16?20:09:02,938?Stage-1?map?=?50%,??reduce?=?0%,?Cumulative?CPU?22.88?sec
2021-06-16?20:09:03,975?Stage-1?map?=?90%,??reduce?=?0%,?Cumulative?CPU?37.03?sec
2021-06-16?20:09:05,010?Stage-1?map?=?100%,??reduce?=?0%,?Cumulative?CPU?39.51?sec
2021-06-16?20:09:08,131?Stage-1?map?=?100%,??reduce?=?100%,?Cumulative?CPU?42.16?sec
MapReduce?Total?cumulative?CPU?time:?42?seconds?160?msec
Ended?Job?=?job_1595742917056_0028
MapReduce?Jobs?Launched:
Stage-Stage-1:?Map:?10??Reduce:?1???Cumulative?CPU:?42.16?sec???HDFS?Read:?61581414?HDFS?Write:?8?SUCCESS
Total?MapReduce?CPU?Time?Spent:?42?seconds?160?msec
OK
349707
ЦфЫћгавтЫМЕФЙІФм
ЁИдіСПЭЌВНЁЙПЩвдЭЈЙ§sqoop jobДДНЈЁЂжДаавЛИіsqoopШЮЮё:ИљОндіСПзжЖЮ,МЧТМЩЯвЛДЮЕФзюДѓжЕ,УПДЮЭЌВНДѓгкИУжЕЕФЪ§ОндіСПЭЌВНЪ§ОнжСhive,ДДНЈШЮЮёКѓУПДЮжДааЛсздЖЏИќаТ--last-valueЕФжЕЁЃ
--incremental?append??#?діСПЭЌВН
--check-column?abc???#?МьВщЕФЕФзжЖЮ
--last-value?'xxxx-xx-xx?xx:xx:xx'
ЁИздЖЈвхЕМШыФкШнЁЙЪЙгУ --queryВЮЪ§,гУЛЇПЩвдИљОнашЧѓ,здЖЈвхЫљашЕФФкШнЁЃ
--query?'SELECT?a.*,?b.*?FROM?a?JOIN?b?on?(a.id?==?b.id)?WHERE?$CONDITIONS'?\
ЁИЧЈвЦМгЫйЁЙШчЙћЧЈвЦMySQLЕФЪ§Он,ПЩвдЬэМг--directВЮЪ§,ЪЙгУMySQLЕФmysqldumpШЅгХЛЏJDBCСЌНгЪ§ОнПтВПЗжЁЃ
ЁИЮДЬсНЛЪ§ОнВщбЏЁЙSqoop ЬсЙЉЖСШЁ read-uncommitted ЪТЮёЕФФмСІ,жЛашвЊДјЩЯВЮЪ§ --relaxed-isolation МДПЩ,ЙІФмЭІгавтЫМ,ЕЋетИіЮвЛЙУЛВтЪдЙ§,ШчЙћгаЪдЙ§ЕФЭЌбЇ,ПЩвдЮФФЉСєбдЁЃ
SqoopЕФвХКЖ
змЬхРДЫЕ,ећИіЧЈвЦЪЕеНЕФНсЙћЪЧЗћКЯдЄЦк,DoirsЧЈвЦHiveЭъГЩЁЃЫфШЛSqoopЙІФмЛЙЧПДѓЕФ,ЕЋвВгавЛаЉаЁвХКЖ,ШчЙћФГИіШЮЮёЪЇАмжиЪдЕФЛА,ЛсДцдкЪ§ОнжиИДЕФЮЪЬт,етЪБШчЙћвЊБЃжЄвЛжТадгявх,ашвЊЭЈЙ§ЖюЭтШЅжиВйзїЭъГЩ;ДЫЭтSqoopЧЈвЦЙ§ГЬжа,Ъ§ОнЪЕЪБаДШыМцШнадЛЙВЛЬЋКУЁЃЫфШЛSqoop2ПДзХЙцЛЎЪЧЭІЯуЕФ,КмвХКЖВЛСЫСЫжЎСЫ,гЩждЯЃЭћSqoopЕФЩчЧјПЩвддйајЭљШеЛдЛЭЁЃ
Bash wishes!!!
ЁИЭљЦкдДДЭЦМіЁЙ
ЁИЭљЦкзюМбЪЕМљЁЙ