1��Ϊʲô����Ϣϵͳ
-
�����
-
�첽���� �������ƽ̨,��ɱ���һ�����̻��Ϊ:1:?
���տ�����2:���������3:���ɶ�����4:����֪ͨ��5:�������� -
ͨ����Ϣϵͳ����ɱ�ҵ���ֿ�,�������账����ҵ����ں�����������;���̸�Ϊ:1:
���տ�����2:���������3:��Ϣϵͳ��4:���ɶ�����5:����֪ͨ��6:�������� -
�����Ŀ��� 1. �����ڽ��ܵ������,�Ͱ�������뵽��Ϣ�������� 2.��˵ķ������Ϣ���������ȡ������,��ɺ�������ɱ�������̡�Ȼ���ٸ��û����ؽ�����ŵ�:���������� ȱ��:�������̱���
2��Kafka���ĸ���
������:Producer ��Kafka��Ⱥ��������������:Consumer ��Kafka����ȥ��ȡ����,�������ݡ���������Kafka�����������������Լ�ȥ��ȥKafka�������������:topic����:partition Ĭ��һ��topic��һ������(partition),�Լ������ö������(������ɢ�洢�ڷ�������ͬ�ڵ���)
3��Kafka�ļ�Ⱥ�ܹ�
Kafka��Ⱥ��,һ��kafka����������һ��broker Topicֻ�����ϵĸ���,partition�ڴ����Ͼ�����Ϊһ��Ŀ¼Consumer Group:������ �������ݵ�ʱ��,������ָ��һ��group id,ָ��һ�����id�ٶ�����A�ͳ���Bָ����group id��һ��,��ô�������������ͬһ������������: ����,��һ������topicA����Aȥ���������topicA,��ô����B�Ͳ�����ȥ����topicA(����A�ͳ���B����һ��������) �ٱ������A�Ѿ�������topicA���������,���ڻ��������ٴ�����topicA������,�Dz����Ե�,��������ָ��һ��group id���Ժ�,�������ѡ���ͬ������֮��û��Ӱ�졣���������Զ���,���������Ƴ����Զ�����(��һ��)��Controller:Kafka�ڵ������һ�����ڵ㡣����zookeeper
4��Kafka����˳��д��֤д��������
kafkaд����:˳��д,��������д����ʱ,����������,û�����д�IJ���������: ���һ�����������̴ﵽһ���ĸ���,����Ҳ�ﵽһ��ת��,����������˳��д(��д)���ݵ��ٶȺ�д�ڴ���ٶȲ��������������Ϣ,����kafka������д��os cache �ڴ���,Ȼ��sync˳��д��������
5��Kafka�㿽�����Ʊ�֤�����ݸ�����
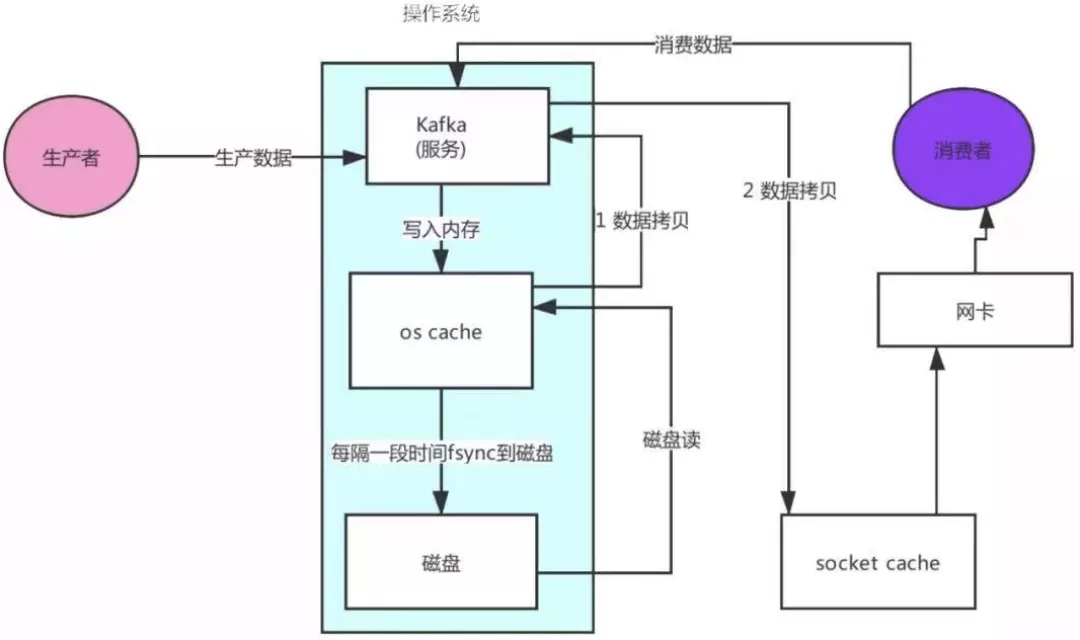
�����߶�ȡ��������:
-
�����߷��������kafka����
-
kafka����ȥos cache�����ȡ����(����û�о�ȥ���̶�ȡ����)
-
�Ӵ��̶�ȡ�����ݵ�os cache������
-
os cache�������ݵ�kafkaӦ�ó�����
-
kafka������(����)���͵�socket cache��
-
socket cacheͨ�����������������
kafka linux sendfile���� �� �㿽��
1.�����߷��������kafka���� 2.kafka����ȥos cache�����ȡ����(����û�о�ȥ���̶�ȡ����) 3.�Ӵ��̶�ȡ�����ݵ�os cache������ 4.os cacheֱ�ӽ����ݷ������� 5.ͨ�����������ݴ����������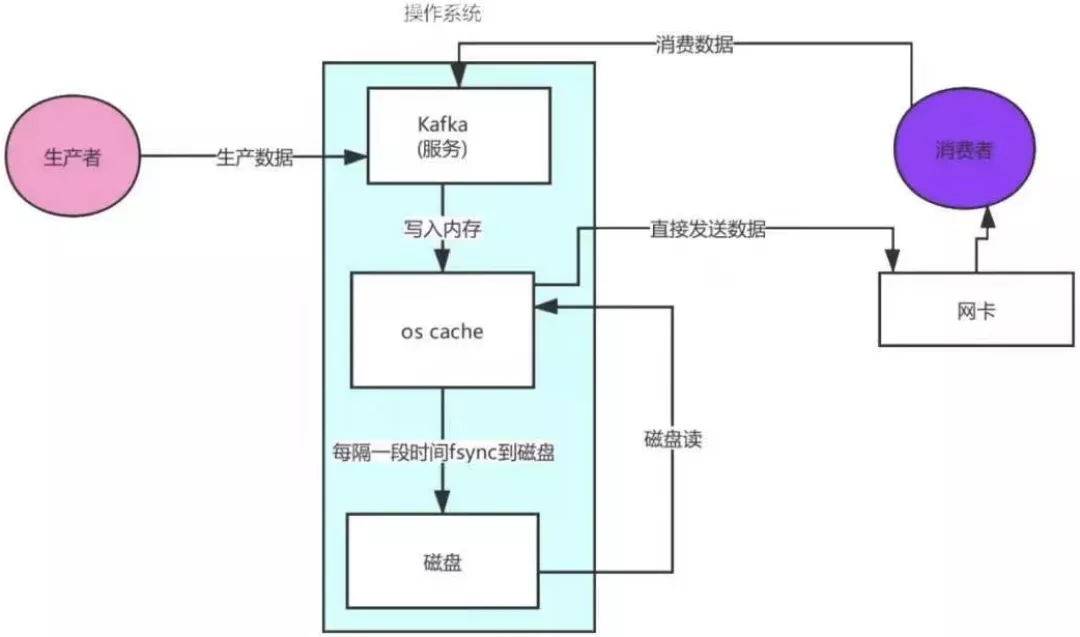
6��Kafka��־�ֶα���
Kafka��һ������,һ������÷���;���紴����һ��topic_a,Ȼ����ʱ��ָ�������������������������ʵ����̨��������,�ᴴ������Ŀ¼��������1(kafka1)����Ŀ¼topic_a-0:��Ŀ¼�����������ļ�(�洢����),kafka���ݾ���message,���ݴ洢��log�ļ��.log��β�ľ�����־�ļ�,��kafka�а������ļ��ͽ�����־�ļ� ��һ����������Ĭ����n�����־�ļ�(�ֶδ洢),һ����־�ļ�Ĭ��1G��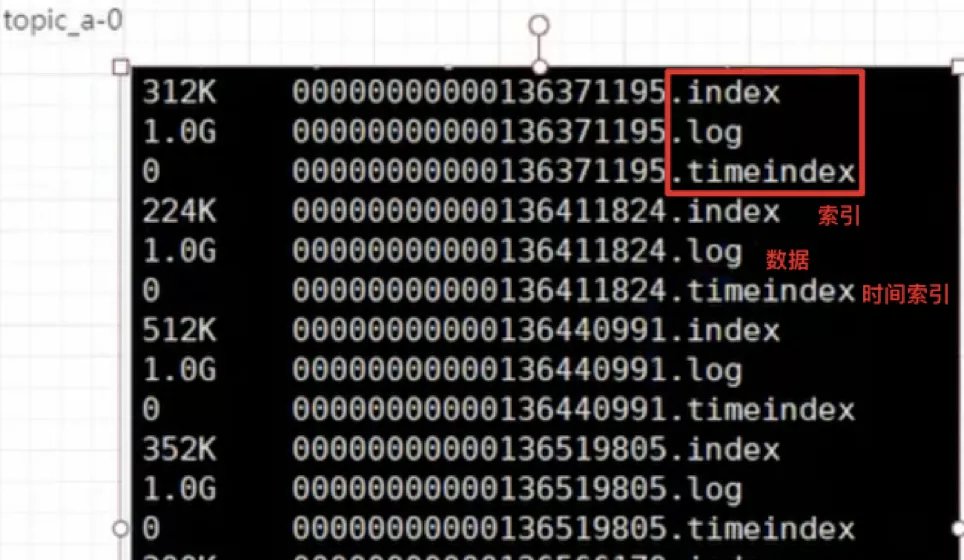 ������2(kafka2):����Ŀ¼topic_a-1: ������3(kafka3):����Ŀ¼topic_a-2:
������2(kafka2):����Ŀ¼topic_a-1: ������3(kafka3):����Ŀ¼topic_a-2:
7��Kafka���ֲ��Ҷ�λ����
???????? Kafka����ÿһ����Ϣ,�����Լ���offset(���ƫ����),����������������,��position Position:����λ��(���������ĸ��ط�)Ҳ����˵һ����Ϣ��������λ��:offset:���ƫ����(���λ��)position:��������λ��ϡ������:???????? Kafka�в�����ϡ�������ķ�ʽ��ȡ����,kafkaÿ��д����4k��С����־(.log),����index��д��һ����¼���������л���ö��ֲ���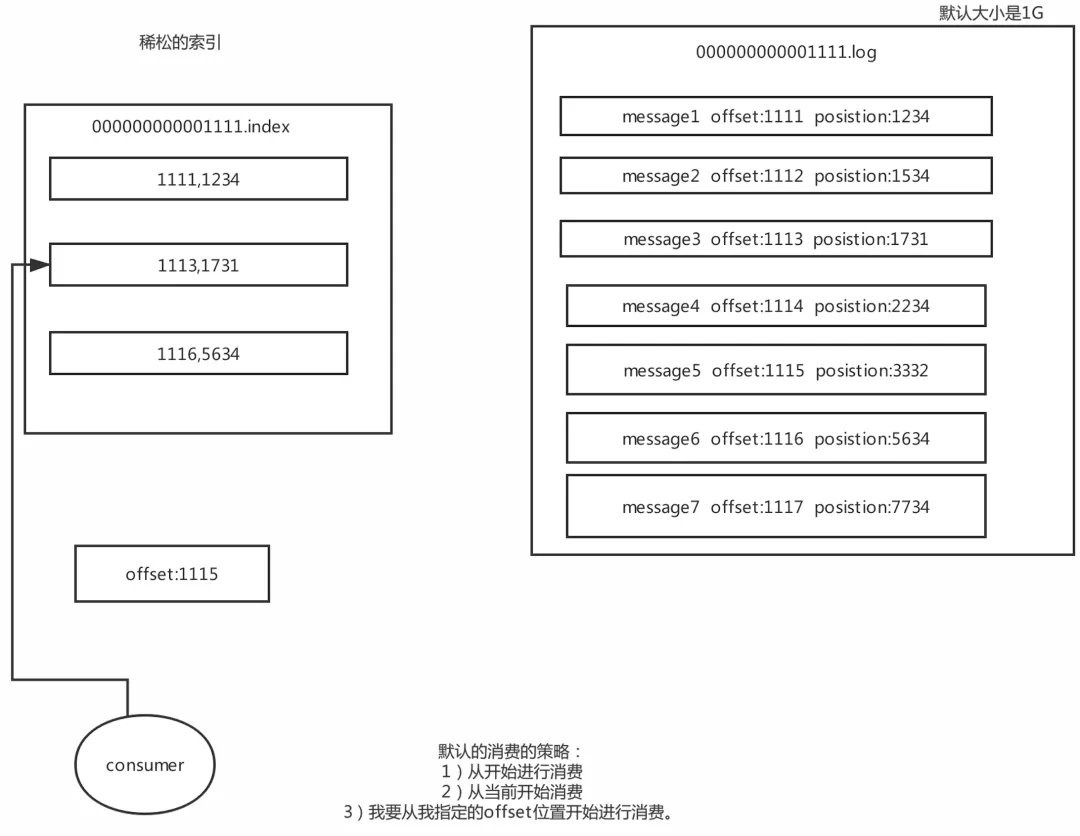
8���߲����������(���˽�NIO)
???????? ������Ʋ�����kafka�������õ�һ������,��Ҳ�DZ�֤Kafka�߲����������ܵ�ԭ��,��kafka���е���,�͵ö�kafkaԭ���Ƚ��˽�,������������Ʋ���
Reactor�������ģʽ1: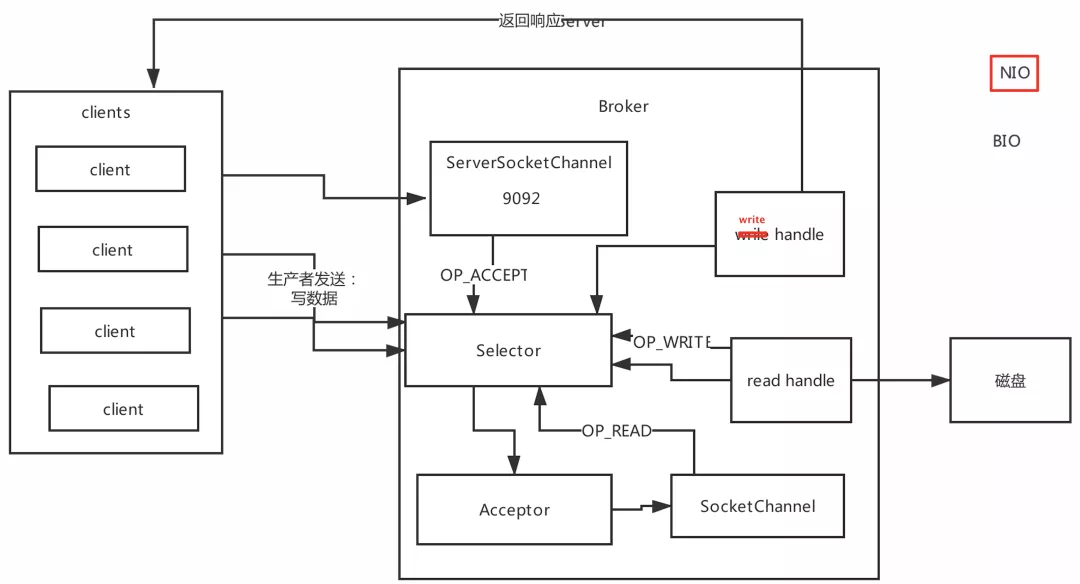 Reactor�������ģʽ2:
Reactor�������ģʽ2: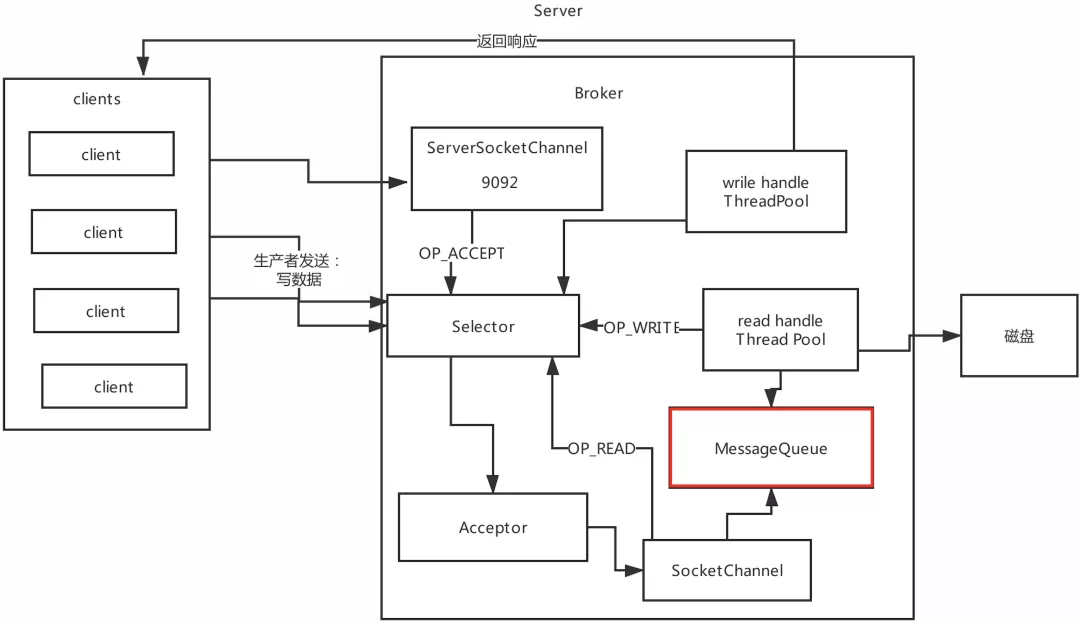 Reactor�������ģʽ3:
Reactor�������ģʽ3: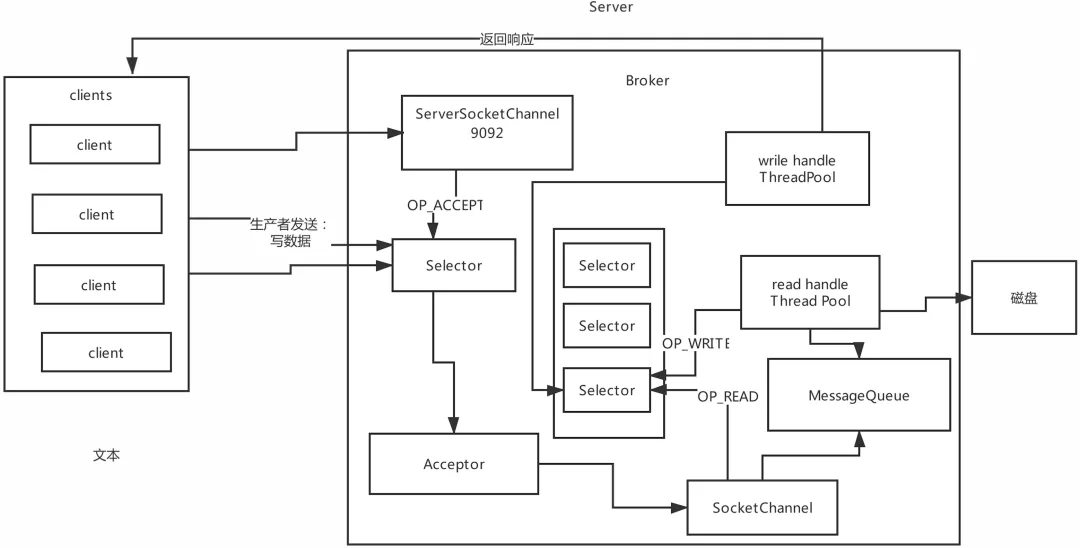 Kafka���߲����������:
Kafka���߲����������: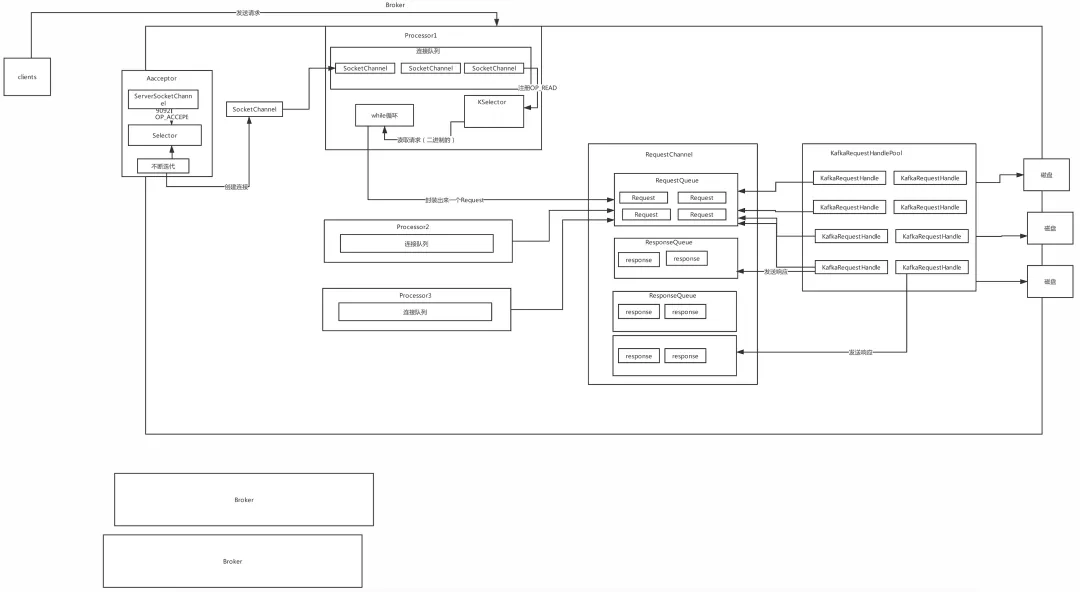
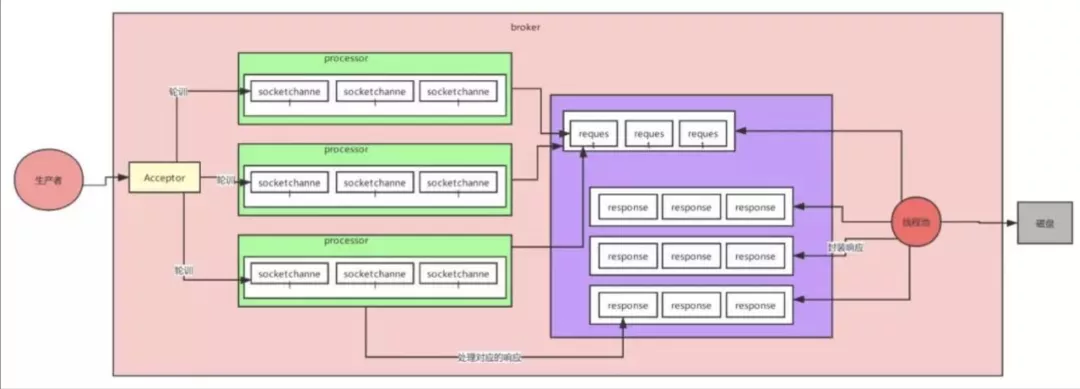
9��Kafka���ั����֤�߿���
��kafka����������и�����,ע:0.8��ǰ��û�и������Ƶ�����������ʱ,����ָ������,Ҳ����ָ�������������������н�ɫ��:leader partition:1��д���ݡ������ݲ������Ǵ�leader partitionȥ�����ġ�2����ά��һ��ISR(in-sync- replica )�б�,���ǻ����һ���Ĺ���ɾ��ISR�б������ֵ �����߷�����һ����Ϣ,��Ϣ����Ҫд�뵽leader partition�� д�����Ժ�,��Ҫ����Ϣд�뵽ISR�б��������������,д�����������Ϣ�ύ follower partition:��leader partitionͬ�����ݡ�
10������ܹ�˼��-�ܽ�
Kafka �� �߲������߿��á������� �߿���:�ั������ �߲���:����ܹ���� ����ܹ�:��selector -> ���߳� -> ���е����(NIO) ������:д����:
-
��������д�뵽OS Cache
-
д������������˳��д,���ܸܺ�
������:
-
����ϡ������,���ٶ�λ��Ҫ���ѵ�����
-
�㿽������ �������ݵĿ��� ������Ӧ�ó��������ϵͳ�������л�
11��Kafka���������
11.1 ��������
����ƽ̨,��Ҫÿ��10������Ҫ���͵�Kafka��Ⱥ���档���˷���,һ�������������ⶼ����10������ -> 24 ������,һ�������,ÿ���12:00 ������8:00 ���ʱ����ʵ��û�ж����������ġ�80%���������õ�����16Сʱ�Ĵ����ġ�16��Сʱ���� -> 8�ڵ�����16 * 0.2 = 3��Сʱ ������8�������80%������
Ҳ����˵6�ڵ������ǿ�3��Сʱ������ġ����Ǽ���һ�¸߷���ʱ���qps6��/3Сʱ =5.5��/s qps=5.5��
10������ * 50kb = 46T ÿ����Ҫ�洢46T������
һ�������,���Ƕ���������������?46T * 2 = 92T??Kafka������������б�����ʱ������,�������3������ݡ�92T * 3�� = 276T�����˵����50kb����˵һ����Ϣ����50kb����(����־�ϲ���,������־�ϲ���һ��),ͨ�������,һ����Ϣ�ͼ�b,Ҳ�п��ܾ��Ǽ����ֽڡ�
11.2 ��������������
1)���ȷ���һ������Ҫ��������������� ��Kafka mysql hadoop��Щ��Ⱥ���ʱ��,�����������涼��ʹ����������2)�߷�����Ҫ�����������ܵ�����ÿ��5.5���,��ʵһ��̨�����������ǿ��Կ�ס�ġ�һ�������,��������������ʱ��,�ǰ��ո߷��ڵ�4����ȥ�����������4���Ļ�,������Ǽ�Ⱥ������Ҫ���� 20��qps�������ӵļ�Ⱥ���DZȽϰ�ȫ�ļ�Ⱥ����ž���Ҫ5̨��������ÿ̨����4������
�����ܽ�:�㶨10������,�߷���5.5���qps,276T������,��Ҫ5̨��������
11.3 ����ѡ��
�㶨10������,�߷���5.5���qps,276T������,��Ҫ5̨��������1)SSD��̬Ӳ��,������Ҫ��ͨ�Ļ�еӲ��SSDӲ��:���ܱȽϺ�,���Ǽ۸�� SAS��:ij�������ܲ��Ǻܺ�,���DZȽϱ��ˡ�SSDӲ�����ܱȽϺ�,ָ�����������д�����ܱȽϺá��ʺ�MySQL������Ⱥ��������ʵ����˳��д�����ܸ�SAS�̲�ࡣkafka������:�����õ�˳��д���������Ǿ�����ͨ�ġ���еӲ�����Ϳ����ˡ�
2)��Ҫ��������ÿ̨��������Ҫ���ٿ���� 5̨������,һ����Ҫ276T ,��Լÿ̨������ ��Ҫ�洢60T�����ݡ����ǹ�˾����������������õ��� 11��Ӳ��,ÿ��Ӳ�� 7T��11 * 7T = 77T
77T * 5 ̨������ = 385T��
�����ܽ�:
�㶨10������,��Ҫ5̨������,11(SAS) * 7T
11.4 �ڴ�����
�㶨10������,��Ҫ5̨������,11(SAS) * 7T
���Ƿ���kafka��д���ݵ����� ���ǻ���os cache,���仰˵�������ǵ�os cashe������ô����kafka�Dz����൱�ھ��ǻ����ڴ�ȥ����,����ǻ����ڴ�ȥ����,���ܿ϶��ܺá��ڴ������ġ�1) �����ܶ���ڴ���ԴҪ�� os cache 2) Kafka�Ĵ����� ���ĵĴ����õ���scalaд��,�ͻ��˵Ĵ���javaд�ġ����ǻ���jvm���������ǻ�Ҫ��һ���ֵ��ڴ��jvm��Kafka�����,û�аѺܶ����ݽṹ������jvm���档�������ǵ����jvm����Ҫ̫����ڴ档���ݾ���,����10G�Ϳ�������
NameNode: jvm���滹����Ԫ����(��ʮG),JVMһ��Ҫ���úܴ������100G��
�����������10����������Ŀ,һ������100��topic��100 topic * 5 partition * 2 = 1000 partition һ��partition��ʵ���������������һ��Ŀ¼,���Ŀ¼������кܶ��.log���ļ���.log���Ǵ洢�����ļ�,Ĭ�������һ��.log�ļ��Ĵ�С��1G���������Ҫ��֤ 1000��partition �����µ�.log �ļ������� ��������ڴ�����,���ʱ�����ܾ�����á�1000 * 1G = 1000G�ڴ�. ����ֻ��Ҫ�ѵ�ǰ���µ����log ��֤�����25%�����µ��������ڴ����档250M * 1000 = 0.25 G* 1000 =250G���ڴ档
250�ڴ� / 5 = 50G�ڴ� 50G+10G = 60G�ڴ�
64G���ڴ�,�����4G,����ϵͳ�����Dz���Ҳ��Ҫ�ڴ档��ʵKafka��jvmҲ���Բ��ø���10G��ô�ࡣ��������64G�ǿ��Եġ���Ȼ����ܸ���128G���ڴ�ķ�����,�Ǿ���á�
�Ҹո�������ʱ���õĶ���һ��topic��5��partition,����������������Ƚϴ��topic,���ܻ���10��partition��
�ܽ�:�㶨10������,��Ҫ5̨������,11(SAS) * 7T ,��Ҫ64G���ڴ�(128G����)
11.5 CPUѹ������
����һ��ÿ̨��������Ҫ����cpu core(��Դ������)
����������Ҫ���ٸ�cpu ,���ݾ��ǿ����ǵķ��������ж����߳�ȥ�ܡ��߳̾�������cpu ȥ���еġ�������ǵ��̱߳Ƚ϶�,����cpu core�Ƚ���,�����Ļ�,���ǵĻ������ؾͻ�ܸ�,���ܲ��Ͳ��á�
����һ��,kafka��һ̨������ �����Ժ���ж����߳�?
Acceptor�߳� 1 processor�߳� 3 6~9���߳� ���������߳� 8�� 32���߳� ��ʱ�������߳�,��ȡ���ݵ��߳�,��ʱ���ISR�б��Ļ��� �ȵȡ����Դ��һ��Kafka�ķ������������Ժ�,����һ�ٶ���̡߳�
cpu core = 4��,һ����˵,��ʮ���߳�,�Ϳ϶���cpu �����ˡ�cpu core = 8��,Ӧ�ú����ɵ���֧�ּ�ʮ���̡߳�������ǵ��߳���100���,���߲��200��,��ô8 �� cpu core�Ǹ㲻���ġ����������������:CPU core = 16����������ԵĻ�,����32��cpu core �Ǿ���á�
����:kafka��Ⱥ,���ҲҪ��16��cpu core,����ܸ���32 cpu core�Ǿ��á�2cpu * 8 =16 cpu core 4cpu * 8 = 32 cpu core
�ܽ�:�㶨10������,��Ҫ5̨������,11(SAS) * 7T ,��Ҫ64G���ڴ�(128G����),��Ҫ16��cpu core(32������)
11.6 ������������
����������Ҫʲô������?һ��Ҫô��ǧ������(1G/s),���еľ�����������(10G/s)
�߷��ڵ�ʱ��?ÿ�����5.5�������ӿ��,5.5/5 =?��Լ��ÿ̨����������1�������ӿ�롣
����֮ǰ˵��,
10000?* 50kb = 488M ?Ҳ����ÿ��������,ÿ��Ҫ����488M�����ݡ����ݻ�Ҫ�и���,����֮���ͬ��
Ҳ���ߵ����������488 * 2 = 976m/s
˵��һ��:
???�ܶ˾������,һ������������û��50kb��ô���,���ǹ�˾����Ϊ�����������˷�װ������
???Ȼ��Ѷ������ݺϲ���һ����,�������ǵ�һ������Ż�����ô��
???
˵��һ��:
???һ�������,�����Ĵ����Ǵﲻ������,�����ǧ������,�������õ�һ�����700M���ҡ�
???���������õ����,���ǻ���ʹ������������
???���ʹ�õ�������,�Ǿ��Ǻ����ɡ�
11.7 ��Ⱥ�滮
������ �滮�������ĸ��� �������̵ĸ���,ѡ��ʹ��ʲô���Ĵ��� �ڴ� cpu core �������Ǹ��ߴ��,�Ժ�Ҫ�ǹ�˾������ʲô����,������Դ������,������������,��Ұ����ҵ�˼·ȥ����
һ����Ϣ�Ĵ�С 50kb -> 1kb 500byte 1Mip ������ 192.168.0.100 hadoop1 192.168.0.101 hadoop2 192.168.0.102 hadoop3
�����Ĺ滮:kafka��Ⱥ�ܹ���ʱ��:����ʽ�ļܹ�:controller -> ͨ��zk��Ⱥ������������Ⱥ��Ԫ���ݡ�
-
zookeeper��Ⱥ hadoop1 hadoop2 hadoop3
-
kafka��Ⱥ ����������,���Dz�Ӧ�ð�kafka�ķ�����zk�ķ���װ��һ�𡣵�������������������ޡ���������kafka��ȺҲ�ǰ�װ��hadoop1 haadoop2 hadoop3
12��kafka��ά
12.1 ������ά���߽���
KafkaManager �� ҳ���������
12.2 ����������
����һ:topic������̫��,Ҫ����topic��
һ��ʼ���������ʱ��,����������,���ķ��������ࡣ
kafka-topics.sh?--create?--zookeeper?hadoop1:2181,hadoop2:2181,hadoop3:2181?--replication-factor?1?--partitions?1?--topic?test6
kafka-topics.sh?--alter?--zookeeper?hadoop1:2181,hadoop2:2181,ha
broker id:
hadoop1:0 hadoop2:1 hadoop3:2 ����һ��partition����������:partition0:a,b,c
a:leader partition b,c:follower partition
ISR:{a,b,c}���һ��follower���� ����10�� û����leader partitionȥ��ȡ����,��ô��������ʹ�ISR�б������Ƴ���
������:����topic���Ӹ�������
����Ժ���ҵ��������Ҫ���Ӹ������� vim test.json�ű�,������һ��json�ű�����
{��version��:1,��partitions��:[{��topic��:��test6��,��partition��:0,��replicas��:[0,1,2]},{��topic��:��test6��,��partition��:1,��replicas��:[0,1,2]},{��topic��:��test6��,��partition��:2,��replicas��:[0,1,2]}]}
ִ������json�ű�:
kafka-reassign-partitions.sh?--zookeeper?hadoop1:2181,hadoop2:2181,hadoop3:2181?--reassignment-json-file?test.json?--execute
������:���ز������topic,�ֶ�Ǩ��vi topics-to-move.json
{��topics��:?[{��topic��:?��test01��},?{��topic��:?��test02��}],?��version��:?1}?//?�������е�topic��д������
kafka-reassgin-partitions.sh?--zookeeper?hadoop1:2181,hadoop2:2181,hadoop3:2181?--topics-to-move-json-file?topics-to-move.json?--broker-list?��5,6��?--generate
???????? ?�������еİ����¼����broker������д������,�ͻ�˵�ǰ����е�partition���ȵķ�ɢ�ڸ���broker��,�����½�����broker��ʱ������һ��Ǩ�Ʒ���,���Ա��浽һ���ļ���ȥ:expand-cluster-reassignment.json
kafka-reassign-partitions.sh?--zookeeper?hadoop01:2181,hadoop02:2181,hadoop03:2181?--reassignment-json-file?expand-cluster-reassignment.json?--execute
kafka-reassign-partitions.sh?--zookeeper?hadoop01:2181,hadoop02:2181,hadoop03:2181?--reassignment-json-file?expand-cluster-reassignment.json?--verify
��������Ǩ�Ʋ���һ��Ҫ�����ϵͷ��ʱ������,��Ϊ�����ڻ���֮��Ǩ������,�dz���ռ�ô�����Դ�Cgenerate: ���ݸ����Topic�б���Broker�б�����Ǩ�Ƽƻ���generate����������������ϢǨ��,���ǽ���ϢǨ�Ƽƻ��������,��execute����ʹ�á��Cexecute: ���ݸ������ϢǨ�Ƽƻ�����Ǩ�ơ��Cverify: �����Ϣ�Ƿ��Ѿ�Ǩ����ɡ�
������:���ij��broker leader partition����
���������,���ǵ�leader partition�ڷ�����֮���Ǹ��ؾ��⡣hadoop1 4 hadoop2 1 hadoop3 1
���ڸ���ҵ�����������봴��topic,�������������Զ�����ͺ�����̬������, kafka�������Զ���leader partition���ȷ�ɢ�ڸ���������,�������Ա�֤ÿ̨�����Ķ�д���������Ǿ��ȵ� ����Ҳ������,�Ǿ������ijЩbroker崻�,�ᵼ��leader partition���ڼ����������ٲ��ּ�̨broker��, ��ᵼ��������̨broker�Ķ�д����ѹ������,����崻���broker����֮����folloer partition,��д����ܵ�, ��ɼ�Ⱥ���ز�������һ������,auto.leader.rebalance.enable,Ĭ����true, ÿ��300��(leader.imbalance.check.interval.seconds)���leader�����Ƿ�ƽ�� ���һ̨broker�ϵIJ������leader������10%,leader.imbalance.per.broker.percentage, �ͻ�����broker����ѡ�� ���ò���:auto.leader.rebalance.enable Ĭ����true leader.imbalance.per.broker.percentage: ÿ��broker�����IJ�ƽ���leader�ı��ʡ����ÿ��broker���������ֵ,�������ᴥ��leader��ƽ�⡣���ֵ��ʾ�ٷֱȡ�10% leader.imbalance.check.interval.seconds:Ĭ��ֵ300��
13��Kafka������
13.1 �����߷�����Ϣԭ��
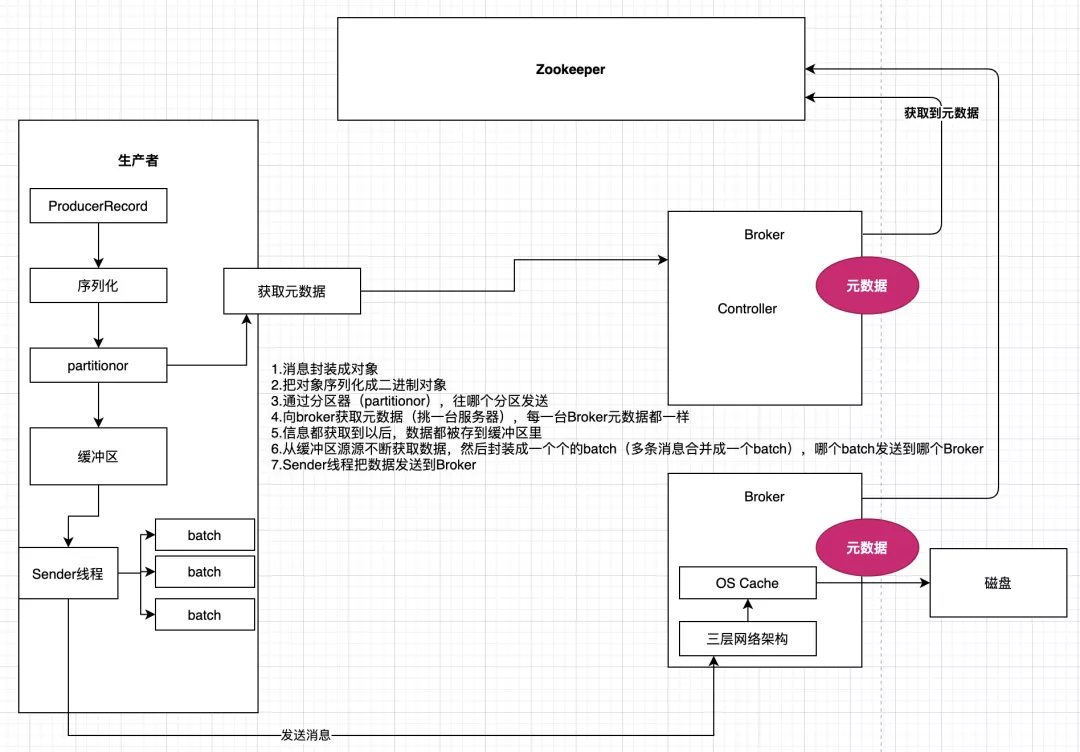
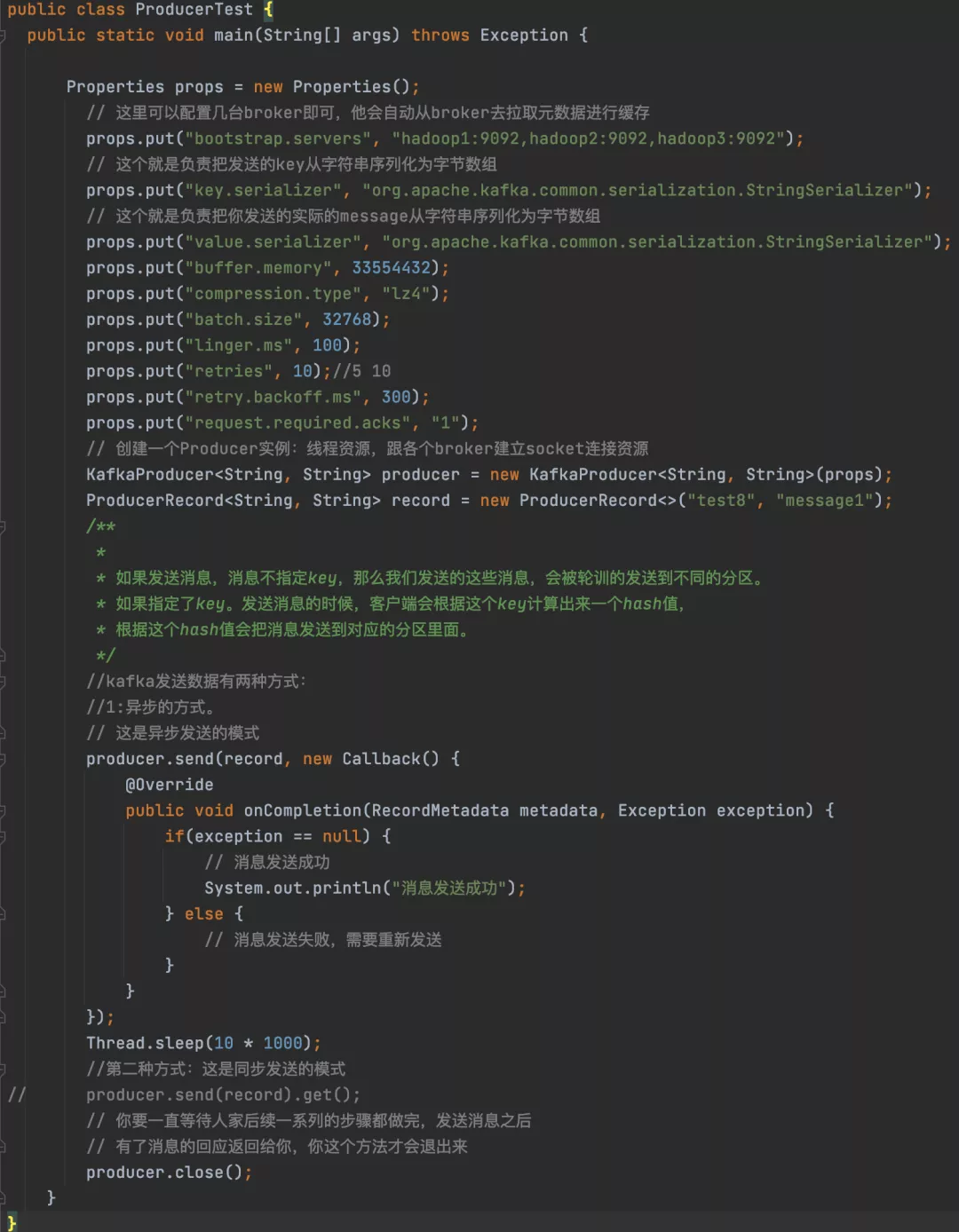
13.2 �����߷�����Ϣԭ��������������ʾ
13.3 �������������
�������������:����һ:buffer.memory:���÷�����Ϣ�Ļ�����,Ĭ��ֵ��33554432,����32MB ������:compression.type:Ĭ����none,��ѹ��,����Ҳ����ʹ��lz4ѹ��,Ч�ʻ��Dz�����,ѹ��֮����Լ�С������,����������,���ǻ�Ӵ�producer�˵�cpu���� ������:batch.size:����batch�Ĵ�С,���batch̫С,�ᵼ��Ƶ����������,�������½�;���batch̫��,�ᵼ��һ����Ϣ��Ҫ�ȴ��ܾò��ܱ����ͳ�ȥ,���һ����ڴ滺�����кܴ�ѹ��,�������ݻ������ڴ���,Ĭ��ֵ��:16384,����16kb,Ҳ����һ��batch����16kb�ͷ��ͳ�ȥ,һ����ʵ����������,���batch��ֵ��������һЩ������������,���һ���������ô���,�����ӳ١�һ�����һ����Ϣ��С�����á����������Ϣ�Ƚ��١����ʹ�õIJ���linger.ms,���ֵĬ����0,��˼������Ϣ��������������,�������Dz��Ե�,һ������һ��100����֮���,�����Ļ�����˵,�����Ϣ�����ͳ�ȥ�����һ��batch,���100������,���batch����16kb,��Ȼ�ͻᷢ�ͳ�ȥ��
13.4 ��δ����쳣
-
LeaderNotAvailableException:����������ij̨��������,��ʱleader����������,�ᵼ����д��ʧ��,Ҫ�ȴ�����follower�����л�Ϊleader����֮��,���ܼ���д��,��ʱ�������Է��ͼ���;���˵��ƽʱ����kafka��broker����,�϶��ᵼ��leader�л�,һ���ᵼ����д�뱨��,��LeaderNotAvailableException��
-
NotControllerException:���Ҳ��ͬ��,���˵Controller����Broker����,��ô��ʱ��������,��Ҫ�ȴ�Controller����ѡ��,��ʱҲ��һ���������Լ��ɡ�
-
NetworkException:�����쳣 timeout a. ����retries����,�����Զ����Ե� b. ����������Լ���֮���Dz���,�ͻ��ṩException��������������,���ǻ�ȡ���쳣�Ժ�,�ٶ������Ϣ���е������������ǻ��б��õ���·�����Ͳ��ɹ�����Ϣ���͵�Redis����д���ļ�ϵͳ��,�����Ƕ�����
13.5 ���Ի���
���Ի����һЩ����:
-
��Ϣ���ظ��е�ʱ��һЩleader�л�֮�������,��Ҫ��������,����retries����,������Ϣ���Իᵼ��,�ظ����͵�����,����˵���綶��һ�µ�������Ϊû�ɹ�,��������,��ʵ�˼Ҷ��ɹ���.
-
��Ϣ������Ϣ�����ǿ��ܵ�����Ϣ�������,��Ϊ����������������Ϣ�����ͳ�ȥ�ˡ����Կ���ʹ��"max.in.flight.requests.per.connection"��������Ϊ1, �������Ա�֤producerͬһʱ��ֻ�ܷ���һ����Ϣ���������Եļ��Ĭ����100����,��"retry.backoff.ms"���������� �������ڿ���������,�����Ի��ƻ����Ϳ��Ը㶨95%���쳣���⡣
13.6 ACK�������
producer�����õ� request.required.acks=0;ֻҪ�����ѷ��ͳ�ȥ,�����Ƿ�������,��������û��д�ɹ������ܺܺ�,����Ƕ�һЩ��־���з���,���Գ��ܶ����ݵ����,���������,���ܻ�ܺá�request.required.acks=1;����һ����Ϣ,��leader partitionд��ɹ��Ժ�,����д��ɹ����������ַ�ʽҲ�ж����ݵĿ��ܡ�request.required.acks=-1;��ҪISR�б�����,���и�����д���Ժ�,������Ϣ����д��ɹ���ISR:1��������1 leader partition 1 follower partition kafka�����:min.insync.replicas:1, ������Dz����õĻ�,Ĭ�����ֵ��1 һ��leader partition��ά��һ��ISR�б�,���ֵ��������ISR�б����� ���ٵ��м�������,�������ֵ��2,��ô��ISR�б�����ֻ��һ��������ʱ������������������ݵ�ʱ��ᱨ�������һ���������ݵķ���:���ݲ���ʧ�ķ���:1)�������� >=2 2)acks = -1 3)min.insync.replicas >=2 ���п��ܾ��Ƿ������쳣:���쳣���д���
13.7 �Զ������
����:1��û������key���ǵ���Ϣ�ͻᱻ��ѵ�ķ��͵���ͬ�ķ�����2��������keykafka�Դ��ķ�����,�����key�������һ��hashֵ,���hashֵ���Ӧijһ�����������key��ͬ��,��ôhashֵ��Ȼ��ͬ,key��ͬ��ֵ,��Ȼ�ǻᱻ���͵�ͬһ��������������Щ�Ƚ������ʱ��,���Ǿ���Ҫ�Զ������
public?class?HotDataPartitioner?implements?Partitioner?{
private?Random?random;
@Override
public?void?configure(Map<String,??>?configs)?{
random?=?new?Random();
}
@Override
public?int?partition(String?topic,?Object?keyObj,?byte[]?keyBytes,?Object?value,?byte[]?valueBytes,?Cluster?cluster)?{
String?key?=?(String)keyObj;
List?partitionInfoList?=?cluster.availablePartitionsForTopic(topic);
//��ȡ�������ĸ���?0,1,2
int?partitionCount?=?partitionInfoList.size();
//���һ������
int?hotDataPartition?=?partitionCount?-?1;
return?!key.contains(��hot_data��)???random.nextInt(partitionCount?-?1)?:?hotDataPartition;
}
}
���ʹ��:����������༴��:props.put(��partitioner.class��, ��com.zhss.HotDataPartitioner��);
13.8 �ۺϰ�����ʾ
14.1 ��������� groupid��ͬ������ͬһ�������� 1)ÿ��consumer��Ҫ����һ��consumer.group,����һ��������,topic��һ������ֻ������ һ���������µ�һ��consumer������,ÿ��consumer���ܻ����������,Ҳ�п���ij��consumerû�з��䵽�κη��� 2)�����Ҫʵ��һ���㲥��Ч��,��ֻ��Ҫʹ�ò�ͬ��group idȥ���ѾͿ��ԡ�topicA: partition0��partition1 groupA:consumer1:���� partition0 consuemr2:���� partition1 consuemr3:���Ѳ������� groupB: consuemr3:���ѵ�partition0��partition1 3)���consumer group��ij�������߹���,��ʱ���Զ��ѷ�������ķ�������������������,�������������,��ô�ֻ��һЩ�������½�������
14��Kafka������
14.1 ���������
groupid��ͬ������ͬһ�������� 1)ÿ��consumer��Ҫ����һ��consumer.group,����һ��������,topic��һ������ֻ������ һ���������µ�һ��consumer������,ÿ��consumer���ܻ����������,Ҳ�п���ij��consumerû�з��䵽�κη��� 2)�����Ҫʵ��һ���㲥��Ч��,��ֻ��Ҫʹ�ò�ͬ��group idȥ���ѾͿ��ԡ�topicA: partition0��partition1 groupA:consumer1:���� partition0 consuemr2:���� partition1 consuemr3:���Ѳ������� groupB: consuemr3:���ѵ�partition0��partition1 3)���consumer group��ij�������߹���,��ʱ���Զ��ѷ�������ķ�������������������,�������������,��ô�ֻ��һЩ�������½�������
14.2 ����������ʾ

14.3 ƫ��������
-
ÿ��consumer�ڴ������ݽṹ�����ÿ��topic��ÿ������������offset,���ڻ��ύoffset,�ϰ汾��д��zk,���������߲�������zk�Dz������ļܹ����,zk�����ֲ�ʽϵͳ��Э����,��������Ԫ���ݴ洢,���ܸ���߲�����д,��Ϊ���ݴ洢��
-
�����µİ汾�ύoffset����kafka�ڲ�topic:__consumer_offsets,�ύ��ȥ��ʱ��, key��group.id+topic+������,value���ǵ�ǰoffset��ֵ,ÿ��һ��ʱ��,kafka�ڲ�������topic����compact(�ϲ�),Ҳ����ÿ��group.id+topic+�����žͱ����������ݡ�
-
__consumer_offsets���ܻ���ո߲���������,����Ĭ�Ϸ���50��(leader partitiron -> 50 kafka),����������kafka������һ����ļ�Ⱥ,������50̨����,�Ϳ�����50̨��������offset�ύ������ѹ��. ������ -> broker�˵����� message -> ���� -> offset ˳����� ���Ķ���ʼ����?-> offset ������(offset)
14.4 ƫ������ع��߽���
-
webҳ�������һ����������(kafka Manager) ��bin/kafka-run-class.sh�ű�,��һ������JMX_PORT=9988?����kafka����
-
��һ������:��Ҫ��ص�consumer��ƫ����������һ��jar�� java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb �CoffsetStorage kafka \(���ݰ汾:ƫ��������kafka����kafka,����zookeeper����zookeeper) �Czk hadoop1:2181 �Cport 9004 �Crefresh 15.seconds �Cretain 2.days��
14.5 �����쳣��֪
heartbeat.interval.ms:consumer����ʱ����,�������coordinator������������֪��consumer�Ƿ������, Ȼ���������֮��,�ͻ�ͨ�������·�rebalance��ָ���������consumer֪ͨ���ǽ���rebalance�IJ��� session.timeout.ms:kafka�ʱ���֪����һ��consumer����Ϊ��������,Ĭ����10�� max.poll.interval.ms:���������poll����֮��,���������ʱ��,��ô�ͻ���Ϊ���consume��������̫����,�ᱻ�߳�������,�������������ȥ����,һ����˵���ҵ���������������þͿ����ˡ�
14.6 ���IJ�������
fetch.max.bytes:��ȡһ����Ϣ�����ֽ���,һ�㽨�����ô�һЩ,Ĭ����1M ��ʵ������֮ǰ����ط���������������ƵIJ���,��˼����˵һ����Ϣ����ܶ��?
-
Producer ���͵�����,һ����Ϣ�����, -> 10M
-
Broker �洢����,һ����Ϣ����ܽ��ܶ�� -> 10M
-
Consumer max.poll.records: һ��poll������Ϣ���������,Ĭ����500�� connection.max.idle.ms:consumer��broker��socket����������г�����һ����ʱ��,��ʱ�ͻ��Զ���������,�����´����Ѿ�Ҫ���½���socket����,�����������Ϊ-1,��Ҫȥ���� enable.auto.commit: �����Զ��ύƫ���� auto.commit.interval.ms: ÿ������ύһ��ƫ����,Ĭ��ֵ5000���� _consumer_offset auto.offset.reset:earliest ���������������ύ��offsetʱ,���ύ��offset��ʼ����;���ύ��offsetʱ,��ͷ��ʼ���� topica -> partition0:1000 partitino1:2000 latest ���������������ύ��offsetʱ,���ύ��offset��ʼ����;���ύ��offsetʱ,�����²����ĸ÷����µ����� none topic���������������ύ��offsetʱ,��offset��ʼ����;ֻҪ��һ���������������ύ��offset,���׳��쳣
14.7 �ۺϰ�����ʾ
���밸��:���ֵ���ƽ̨(������),�����û����ѵĽ��,���û����ǽ����ۼơ�����ϵͳ(������) -> Kafka��Ⱥ���淢������Ϣ����Աϵͳ(������) -> Kafak��Ⱥ����������Ϣ,����Ϣ���д�����
14.8 group coordinatorԭ��
������:�����������ʵ��rebalance��?�� ����coordinatorʵ��
-
ʲô��coordinator ÿ��consumer group����ѡ��һ��broker��Ϊ�Լ���coordinator,���Ǹ����������������ĸ��������ߵ�����,�Լ��ж��Ƿ�崻�,Ȼ����rebalance��
-
���ѡ��coordinator���� ���ȶ�groupId����hash(����),���Ŷ�__consumer_offsets�ķ�������ȡģ,Ĭ����50,_consumer_offsets�ķ���������ͨ��offsets.topic.num.partitions������,�ҵ������Ժ�,����������ڵ�broker��������coordinator����������˵:groupId,��myconsumer_group�� -> hashֵ(����)-> ��50ȡģ -> 8 __consumer_offsets ��������8�ŷ�������̨broker����,��һ̨����coordinator ��֪�����consumer group�µ����е��������ύoffset��ʱ�������ĸ�����ȥ�ύoffset,
-
�������� 1)ÿ��consumer������JoinGroup����Coordinator, 2)Ȼ��Coordinator��һ��consumer group��ѡ��һ��consumer��Ϊleader, 3)��consumer group����������leader, 4)�������leader�Ḻ���ƶ����ѷ���, 5)ͨ��SyncGroup����Coordinator 6)����Coordinator�Ͱ����ѷ����·�������consumer,���ǻ��ָ���ķ����� leader broker��ʼ����socket�����Լ�������Ϣ
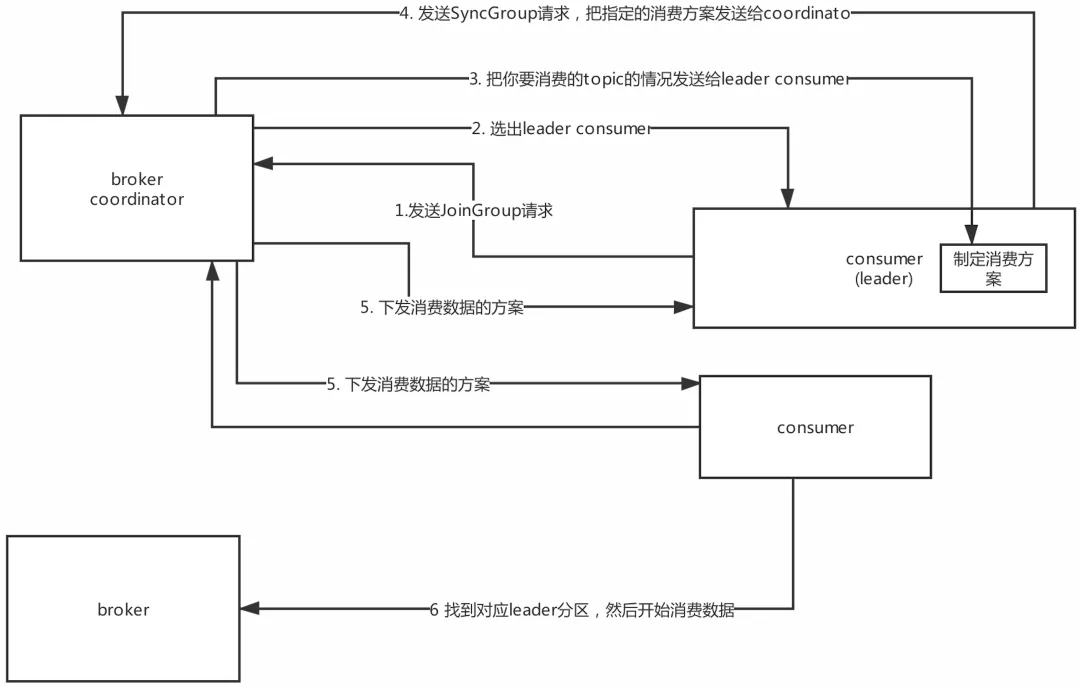
14.9 rebalance����
consumer group��coordinatorʵ����Rebalance
����������rebalance�IJ���:range��round-robin��sticky
�����������ѵ�һ��������12������:p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11 �������ǵ�������������������������
-
range���� range���Ծ��ǰ���partiton����ŷ�Χ p0~3 consumer1 p4~7 consumer2 p8~11 consumer3 Ĭ�Ͼ����������;
-
round-robin���� ������ѯ���� consumer1:0,3,6,9 consumer2:1,4,7,10 consumer3:2,5,8,11 ����ǰ��������������и�����:12 -> 2 ÿ������������6������
����consuemr1����:p0-5�����consumer2,p6-11�����consumer3 �����Ļ�,ԭ����consumer2�ϵĵ�p6,p7�����ͱ����䵽�� consumer3�ϡ�
-
sticky���� ���µ�һ��sticky����,����˵�����ܱ�֤��rebalance��ʱ��,��ԭ���������consumer �ķ���������������,Ȼ��Ѷ���ķ����پ��ȷ����ȥ,����������ά��ԭ���ķ�������IJ���
consumer1:0-3 consumer2: 4-7 consumer3: 8-11 ����consumer3���� consumer1:0-3,+8,9 consumer2: 4-7,+10,11
15��Broker����
15.1 Leo��hw����
-
Kafka�ĺ���ԭ��
-
���ȥ����һ����Ⱥ��Դ
-
���һ��kafka��Ⱥ -�� �����˼�һЩ��ά�����IJ�����
-
������(ʹ��,���ĵIJ���)
-
������(ԭ��,ʹ�õ�,���IJ���)
-
broker�ڲ���һЩԭ��
���ĵĸ���:LEO,HW LEO:�Ǹ�offsetƫ�����й�ϵ��
LEO:��kafka����,����leader partition����follower partitionͳһ����������(replica)��
ÿ��partition���յ�һ����Ϣ,��������Լ���LEO,Ҳ����log end offset,LEO��ʵ�������µ�offset + 1
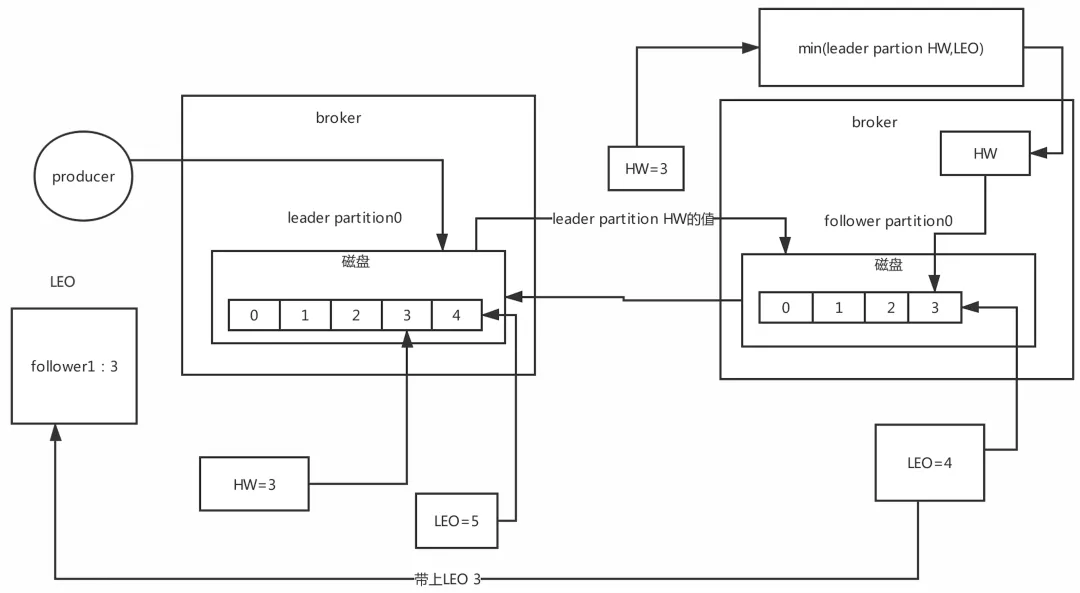
HW:��ˮλ LEO��һ������Ҫ�Ĺ��ܾ��Ǹ���HW,���follower��leader��LEOͬ����,��ʱHW�Ϳ��Ը��� HW֮ǰ�����ݶ��������ǿɼ�,��Ϣ����commit״̬��HW֮�����Ϣ���������Ѳ�����
15.2 Leo����
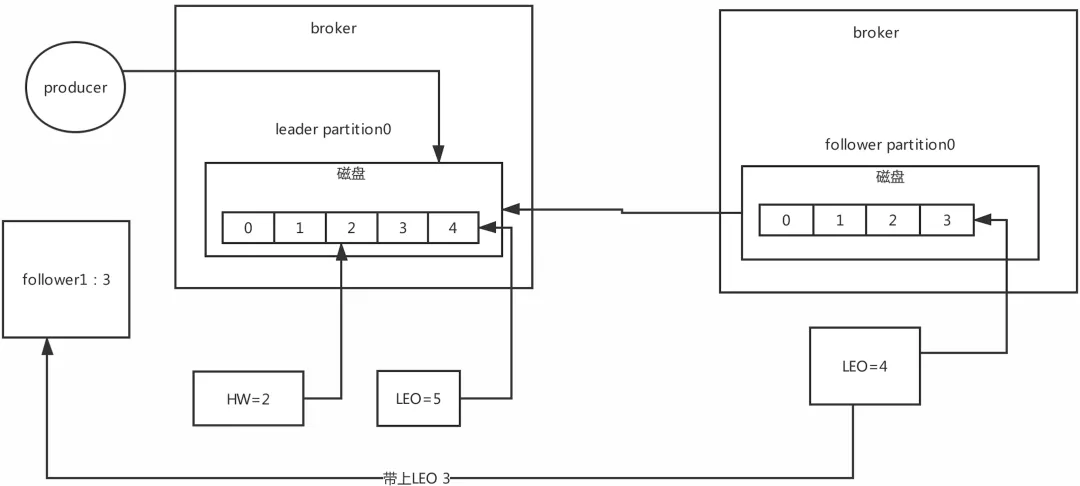
15.3 hw����
15.4 controller��ι���������Ⱥ
1: ����controller�� /controller/id 2:controller���������Ŀ¼:/broker/ids/ ������֪ broker������ /broker/topics/ ��������,���ǵ�ʱ������������,�ṩ�IJ���,ZK��ַ��/admin/reassign_partitions �����ط��� ����

15.5 ��ʱ����
kafka���ӳٵ��Ȼ���(��չ֪ʶ) �����ȿ�һ��kafka������Щ�ط���Ҫ������Ҫ�����ӳٵ��ȡ���һ����ʱ������:����˵producer��acks=-1,����ȴ�leader��follower��д����ܷ�����Ӧ����һ����ʱʱ��,Ĭ����30��(request.timeout.ms)��������Ҫ��д��һ�����ݵ�leader����֮��,�ͱ�����һ����ʱ����,����ʱ����30����ʱ���� �ŵ�DelayedOperationPurgatory(��ʱ������)�С�������30��֮ǰ�������follower��д�븱�������ش�����,��ô�������ͻᱻ�Զ���������,�Ϳ��Է�����Ӧ������ͻ�����, ����Ļ�,�����ʱ�����Լ�ָ���������30�뵽��,������˳�ʱʱ�䶼û�ȵ�,��ֱ�ӳ�ʱ�����쳣���ڶ�����ʱ������:follower��leader��ȡ��Ϣ��ʱ��,��������ǿյ�,��ʱ�ᴴ��һ����ʱ��ȡ���� ��ʱʱ�䵽��֮��(���絽��100ms),��follower����һ���յ�����,Ȼ��follower�ٴη��������ȡ��Ϣ, ���������ʱ�Ĺ�����(��û��100ms),leaderд������Ϣ,�������ͻ��Զ�����,�Զ�ִ����ȡ����
��������ʱ����,��Ҫȥ���ȡ�
15.6?ʱ���ֻ���
-
ʲô����Ҫ���ʱ����?Kafka�ڲ��кܶ���ʱ����,û�л���JDK Timer��ʵ��,�Ǹ������ɾ�������ʱ�临�Ӷ���O(nlogn), ���ǻ������Լ�д��ʱ������ʵ�ֵ�,ʱ�临�Ӷ���O(1),����ʱ���ֻ���,��ʱ��������ɾ��,O(1)
-
ʱ������ʲô?��ʵʱ����˵����ʵ����һ�����顣tickMs:ʱ���ּ�� 1ms wheelSize:ʱ���ִ�С 20 interval:timckMS * whellSize,һ��ʱ���ֵ��ܵ�ʱ���ȡ�20ms currentTime:��ʱʱ���ָ�롣a:��Ϊʱ������һ������,����Ҫ��ȡ�������ݵ�ʱ��,������index,ʱ�临�Ӷ���O(1) b:����ij��λ���϶�Ӧ������,�õ���˫�������洢��,��˫�������������,ɾ������,ʱ�临�Ӷ�Ҳ��O(1) ����:����һ��8ms�Ժ�Ҫִ�е����� 19ms 3.��㼶��ʱ���� ����:Ҫ����һ��110�����Ժ����е�����tickMs:ʱ���ּ�� 20ms wheelSize:ʱ���ִ�С 20 interval:timckMS * whellSize,һ��ʱ���ֵ��ܵ�ʱ���ȡ�20ms currentTime:��ʱʱ���ָ�롣��һ��ʱ����:1ms * 20 �ڶ���ʱ����:20ms * 20 ������ʱ����:400ms * 20