Elasticsearch���
ElasticsearchΪ�ͺ���?
Elaticsearch,���Ϊes, es��һ����Դ�ĸ���չ�ķֲ�ʽȫ�ļ�������,�����Խ���ʵʱ�Ĵ洢����������;������չ�Ժܺ�,������չ���ϰ�̨������,����PB��������ݡ�esҲʹ��Java������ʹ��Lucene��Ϊ�������ʵ�����������������Ĺ���,��������Ŀ����ͨ����RESTful API������Lucene�ĸ�����,�Ӷ���ȫ��������ü�
Elasticsearchʹ�ó���
**2013���,GitHub������Solr,**��ȡElasticSearch ����PB���������� ��GitHubʹ��ElasticSearch����20TB������,����13���ļ���1300���д��롱
**
ά���ٿ�:������elasticsearchΪ�����ĺ��������ܹ�
SoundCloud:��SoundCloudʹ��ElasticSearchΪ1.8���û��ṩ��ʱ������������������
**
�ٶ�:�ٶ�Ŀǰ�㷺ʹ��ElasticSearch��Ϊ�ı����ݷ���,�ɼ��ٶ����з������ϵĸ���ָ�����ݼ��û��Զ�������,ͨ���Ը������ݽ��ж�ά����չʾ,������λ����ʵ���쳣��ҵ������쳣��Ŀǰ���ǰٶ��ڲ�20���ҵ����(����casio���Ʒ��������ˡ�Ԥ�⡢�Ŀ⡢ֱ��š�Ǯ������ص�),����Ⱥ���100̨����,200��ES�ڵ�,ÿ�쵼��30TB+����
**
����ʹ��ES ��������32����ʵʱ��־
**
����ʹ��ES �����ڲ��Լ�����־�ɼ��ͷ�����ϵ
ElasticSearch�Ա�Solr
Solr ���� Zookeeper ���зֲ�ʽ����,�� Elasticsearch �������зֲ�ʽЭ����������;
Solr ֧�ָ����ʽ������,�� Elasticsearch ��֧��json�ļ���ʽ;
Solr �ٷ��ṩ�Ĺ��ܸ���,�� Elasticsearch ������ע���ں��Ĺ���,�����ܶ��е���������ṩ;
Solr �ڴ�ͳ������Ӧ���б��ֺ��� Elasticsearch,���ڴ���ʵʱ����Ӧ��ʱЧ�����Ե��� Elasticsearch
Elasticsearch�İ�װ������
��װ������
ElasticSearch��ΪLinux��Window�汾,����������Ҫѧϰ����ElasticSearch��Java�ͻ��˵�ʹ��,�������ǿγ���ʹ�õ��ǰ�װ��Ϊ����Window�汾,��Ŀ���ߺ�,��˾����ά��Ա�ᰲװLinux���ES����������ʹ�á�
ElasticSearch�Ĺٷ���ַ: https://www.elastic.co/products/elasticsearch




��װES����
Window���ElasticSearch�İ�װ�ܼ�,����Window���Tomcat,��ѹ������װ���,��ѹ���ElasticSearch��Ŀ¼�ṹ����:

��elasticsearch�����ļ�:config/elasticsearch.yml,����������������:
http.cors.enabled: true
http.cors.allow�\origin: "*"
�˲�Ϊ����elasticsearch��Խ����,�������װ�����elasticsearch-head�ǿ��Բ���,ֱ������
����ES����
���ElasticSearch�µ�binĿ¼�µ�elasticsearch.bat����,����̨��ʾ����־��Ϣ����:


ע��:9300��tcpͨѶ�˿�,��Ⱥ���TCPClient��ִ�иö˿�,9200��httpЭ���RESTful�ӿ� ��
ͨ�����������ElasticSearch������,�������·��ص�json��Ϣ,�������������ɹ�:

ע��:
ElasticSearch��ʹ��java������,�ұ��汾��es��Ҫ��jdk�汾Ҫ��1.8����,����װElasticSearch֮ǰ��֤JDK1.8+��װ���,����ȷ�����ú�JDK��������,��������ElasticSearchʧ�ܡ�
��װES��ͼ�λ�������
ElasticSearch��ͬ��Solr�Դ�ͼ�λ�����,���ǿ���ͨ����װElasticSearch��head���,���ͼ�λ������Ч��,����������ݵIJ鿴����װ����ķ�ʽ������,���߰�װ�ͱ��ذ�װ�����ĵ����ñ��ذ�װ��ʽ����head����İ�װ��elasticsearch-5-*���ϰ汾��װhead��Ҫ��װnode��grunt
1)����head���:https://github.com/mobz/elasticsearch-head

2)��elasticsearch-head-masterѹ������ѹ������Ŀ¼,����Ҫ��elasticsearch�İ�װĿ¼����
3)����nodejs:https://nodejs.org/en/download/���������Ѿ��ṩ��nodejs��װ����:˫����װ����,�����ͼ����:





��װ���,����ͨ��cmd����̨����:node -v �鿴�汾��

5)��grunt��װΪȫ������ ,Grunt�ǻ���Node.js����Ŀ��������
��cmd����̨����������ִ������:
npm install �\g grunt�\cli
ִ�н������ͼ:

6)����elasticsearch-head-masterĿ¼����head,��������ʾ������������:
nmp install
grunt server

7)�������,���� http://localhost:9100,��������ҳ��:

������ܳɹ����ӵ�es����,��Ҫ��ElasticSearch��configĿ¼�µ������ļ�:config/elasticsearch.yml,����������������:
http.cors.enabled: true
http.cors.allow-origin: "*"
Ȼ����������ElasticSearch����

ElasticSearch��ظ���
����
Elasticsearch�������ĵ�(document oriented)��,����ζ�������Դ洢����������ĵ�(document)��Ȼ�����������Ǵ洢,��������(index)ÿ���ĵ�������ʹ֮���Ա���������Elasticsearch��,����Զ��ĵ�(���dz��г��е�����)���������������������ˡ�Elasticsearch�ȴ�ͳ��ϵ�����ݿ�����:
Relational DB �\> Databases �\> Tables �\> Rows �\> Columns
Elasticsearch �\> Indices �\> Types �\> Documents �\> Fields
**
Elasticsearch���ĸ���
**
1.���� index(�൱��һ�����ݿ�)
һ����������һ��ӵ�м��������������ĵ��ļ��ϡ�����˵,�������һ���ͻ����ݵ�����,��һ����ƷĿ¼������,����һ���������ݵ�������һ��������һ����������ʶ(����ȫ����Сд��ĸ��),���ҵ�����Ҫ�Զ�Ӧ����������е��ĵ��������������������º�ɾ����ʱ��,��Ҫʹ�õ�������֡���һ����Ⱥ��,���Զ���������������
**
2. ���� type(�൱�����ݿ��е�һ�ű�)
��һ��������,����Զ���һ�ֻ�������͡�һ�����������������һ�����ϵķ���/����,��������ȫ����������ͨ��,��Ϊ����һ�鹲ͬ�ֶε��ĵ�����һ�����͡�����˵,���Ǽ�������Ӫһ������ƽ̨���ҽ������е����ݴ洢��һ�������С������������,�����Ϊ�û����ݶ���һ������,Ϊ�������ݶ�����һ������,��Ȼ,Ҳ����Ϊ�������ݶ�����һ�����͡�
**
3. �ֶ�Field
�൱�������ݱ����ֶ�,���ĵ����ݸ��ݲ�ͬ���Խ��еķ����ʶ
**
4. ӳ�� mapping
mapping�Ǵ������ݵķ�ʽ��������һЩ����,��ij���ֶε��������͡�Ĭ��ֵ�����������Ƿ������ȵ�,��Щ����ӳ������������õ�,������������es�������ݵ�һЩʹ�ù�������Ҳ����ӳ��,�������Ź��������ݶ�������ߺܴ�,��˲���Ҫ����ӳ��,������Ҫ˼����ν���ӳ����ܶ����ܸ��á�
**
5. �ĵ� document
һ���ĵ���һ���ɱ������Ļ�����Ϣ��Ԫ������,�����ӵ��ijһ���ͻ����ĵ�,ijһ����Ʒ��һ���ĵ�,��Ȼ,Ҳ����ӵ��ij��������һ���ĵ����ĵ���JSON(Javascript Object Notation)��ʽ����ʾ,��JSON��һ���������ڵĻ��������ݽ�����ʽ����һ��index/type����,����Դ洢�������ĵ���ע��,����һ���ĵ�,�����ϴ�����һ������֮��,�ĵ����뱻����/����һ��������type��
**
6. �ӽ�ʵʱ NRT
Elasticsearch��һ���ӽ�ʵʱ������ƽ̨������ζ��,������һ���ĵ�ֱ������ĵ��ܹ�����������һ�������ӳ�(ͨ����1������)
**
7. ��Ⱥ cluster
һ����Ⱥ������һ�������ڵ���֯��һ��,���ǹ�ͬ��������������,��һ���ṩ�������������ܡ�һ����Ⱥ��һ��Ψһ�����ֱ�ʶ,�������Ĭ�Ͼ��ǡ�elasticsearch���������������Ҫ��,��Ϊһ���ڵ�ֻ��ͨ��ָ��ij����Ⱥ������,�����������Ⱥ
**
8. �ڵ� node
һ���ڵ��Ǽ�Ⱥ�е�һ��������,��Ϊ��Ⱥ��һ����,���洢����,���뼯Ⱥ�������������������ͼ�Ⱥ����,һ���ڵ�Ҳ����һ����������ʶ��,Ĭ�������,���������һ�����������������ɫ������,������ֻ���������ʱ����ڵ㡣������ֶ��ڹ���������˵ͦ��Ҫ��,��Ϊ���������������,���ȥȷ�������е���Щ��������Ӧ��Elasticsearch��Ⱥ�е���Щ�ڵ㡣һ���ڵ����ͨ�����ü�Ⱥ���Ƶķ�ʽ������һ��ָ���ļ�Ⱥ��Ĭ�������,ÿ���ڵ㶼�ᱻ���ż��뵽һ��������elasticsearch���ļ�Ⱥ��,����ζ��,�������������������������ɸ��ڵ�,���ٶ������ܹ�����ֱ˴�,���ǽ����Զ����γɲ����뵽һ��������elasticsearch���ļ�Ⱥ�С���һ����Ⱥ��,ֻҪ����,����ӵ���������ڵ㡣����,�����ǰ���������û�������κ�Elasticsearch�ڵ�,��ʱ����һ���ڵ�,��Ĭ�ϴ���������һ��������elasticsearch���ļ�Ⱥ��
**
9. ��Ƭ���� shards&replicas
һ���������Դ洢�����������Ӳ�����ƵĴ������ݡ�����,һ������10���ĵ�������ռ��1TB�Ĵ��̿ռ�,����һ�ڵ㶼û��������Ĵ��̿ռ�;���ߵ����ڵ㴦����������,��Ӧ̫����Ϊ�˽���������,Elasticsearch�ṩ�˽��������ֳɶ�ݵ�����,��Щ�ݾͽ�����Ƭ�����㴴��һ��������ʱ��,�����ָ������Ҫ�ķ�Ƭ��������ÿ����Ƭ����Ҳ��һ���������Ʋ��Ҷ����ġ�������,��������������Ա����õ���Ⱥ�е��κνڵ��ϡ���Ƭ����Ҫ,��Ҫ���������ԭ��: 1)������ˮƽ�ָ�/��չ������������� 2)�������ڷ�Ƭ(DZ�ڵ�,λ�ڶ���ڵ���)֮�Ͻ��зֲ�ʽ�ġ����еIJ���,�����������/������������һ����Ƭ�����ֲ�,�����ĵ������ۺϻ���������,����ȫ��Elasticsearch������,������Ϊ�û�������˵,��Щ�������ġ���һ������/�ƵĻ�����,ʧ����ʱ�����ܷ���,��ij����Ƭ/�ڵ㲻֪��ô�ľʹ�������״̬,���������κ�ԭ��
��ʧ��,���������,��һ������ת�ƻ����Ƿdz����ò�����ǿ���Ƽ��ġ�Ϊ��Ŀ��Elasticsearch�����㴴����Ƭ��һ�ݻ��ݿ���,��Щ�����������Ʒ�Ƭ,����ֱ�ӽи��ơ�����֮������Ҫ,��������Ҫԭ��: �ڷ�Ƭ/�ڵ�ʧ�ܵ������,�ṩ�˸߿����ԡ���Ϊ���ԭ��,ע����Ʒ�
Ƭ�Ӳ���ԭ/��Ҫ(original/primary)��Ƭ����ͬһ�ڵ����Ƿdz���Ҫ�ġ���չ���������/������,��Ϊ�������������еĸ����ϲ������С���֮,ÿ���������Ա��ֳɶ����Ƭ��һ������Ҳ���Ա�����0��(��˼��û�и���)���Ρ�һ��������,ÿ����������������Ƭ(��Ϊ����Դ��ԭ���ķ�Ƭ)���Ʒ�Ƭ(����Ƭ�Ŀ���)֮�𡣷�Ƭ���Ƶ���������������������ʱ��ָ��������������֮��,��������κ�ʱ��̬�ظı临�Ƶ�����,�������º��ܸı��Ƭ��������Ĭ�������,Elasticsearch�е�ÿ����������Ƭ5������Ƭ��1������,����ζ��,�����ļ�Ⱥ�������������ڵ�,�������������5������Ƭ������5�����Ʒ�Ƭ(1����ȫ����),�����Ļ�ÿ�������ܹ�����10����Ƭ��
ElasticSearch�Ŀͻ��˲��� Postman�İ�װ��ʹ��
ʵ�ʿ�����,��Ҫ�����ַ�ʽ������Ϊelasticsearch����Ŀͻ���:
��һ��,elasticsearch-head���
�ڶ���,ʹ��elasticsearch�ṩ��Restful�ӿ�ֱ�ӷ���
������,ʹ��elasticsearch�ṩ��API���з���
ʲô��Postman?
һ��ķ������������Ĺ���
���岽��
1.��װPostman����
2.����Postman����
3.ע��Postman����
4.ʹ��Postman���߽���Restful�ӿڷ���
1.����Postman����
Postman����:https://www.getpostman.com

2.ע��Postman����

3.ʹ��Postman���߽���Restful�ӿڷ���

3.1ElasticSearch�Ľӿ��
curl �\X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' �\d '<BODY>'
| ���� | ���� |
|---|---|
| VERB | �ʵ��� HTTP ���� �� ν�� : GET �� POST �� PUT �� HEAD ���� DELETE �� |
| PROTOCOL | http ���� https (������� Elasticsearch ǰ����һ�� https ����) |
| HOST | Elasticsearch ��Ⱥ������ڵ��������,������ |
| localhost �������ػ����ϵĽڵ㡣 | |
| PORT | ���� Elasticsearch HTTP ����Ķ˿ں�,Ĭ���� 9200 �� |
| PATH | API ���ն�·��(���� _count �����ؼ�Ⱥ���ĵ�����)�� |
Path ���ܰ���������,��
��: _cluster/stats �� _nodes/stats/jvm �� |
| QUERY_STRING | �����ѡ�IJ�ѯ�ַ������� (���� ?pretty ����ʽ������� JSON ����ֵ,
ʹ��������Ķ�) |
| BODY | һ�� JSON ��ʽ�������� (���������Ҫ�Ļ�) |
**
3.2��������index��ӳ��mapping
���ǿ����ڴ�������ʱ����mapping��Ϣ,��ȻҲ�����ȴ�������Ȼ��������mapping��
����һ�������в�����maping��Ϣ,ֱ��ʹ��put��������һ������,Ȼ������mapping��Ϣ��
�����url:
�
ip:port/Ҫ������index������
POST http://127.0.0.1:9200/blog2/_mapping
Properties�ڲ��൱�ڶ����ֶ�:
{
"mappings": {
"properties":{
"id": {
"type": "long",
"store": true
}
}
}
}

��ͼ�λ�����鿴��֪�ɹ��Ĵ���������

3.3��������������Mapping
���ǿ����ڴ�������ʱ����mapping��Ϣ,��ȻҲ�����ȴ�������Ȼ��������mapping��
����һ�������в�����maping��Ϣ,ֱ��ʹ��put��������һ������,Ȼ������mapping��Ϣ��
�����url:
�
localhost:9200/test2/_mapping
_mapping:ִ�ж������ַ���
http://127.0.0.1:9200/blog2/_mapping
{
"properties":{
"id4": {
"type": "long",
"store": true
}
}
}

3.4ɾ������Mapping
ֻ�轫�����ij�delete����
�:
ip:port/index
��:ɾ��test2����
localhost:9200/test2



3.5�����ĵ�document
�:
**
post����
ip:9200/������/_doc/idֵ
��:
**
localhost:9200/test/_doc/2
������:
POST localhost:9200/blog1/_doce/1
{
"id":1,
"title":"ElasticSearch��һ������Lucene������������",
"content":"���ṩ��һ���ֲ�ʽ���û�������ȫ����������,����RESTful web�ӿڡ�Elasticsearch����Java
������,����ΪApache���������µĿ���Դ�뷢��,�ǵ�ǰ���е���ҵ���������档��������Ƽ�����,�ܹ��ﵽʵʱ
����,�ȶ�,�ɿ�,����,��װʹ�÷��㡣"
}
���ӵ��ֶ���Ҫ��Elasticsearch�е��ֶ���һ��,�����Ҳ�����Ӧ���ֶ���

�ɹ�����

3.6���ĵ�
**
�:
**
post����
ip:9200/������/_doc/idֵ
�����ĸո�idΪ1��document������


3.7ɾ���ĵ�document
�:
**
delete����
ip:9200/������/_doc/idֵ
����ɾ���ո�idΪ1��document��
**

3.8��ѯ�ĵ�-����id��ѯ
�:
Get����
ip:9200/������/_doc/idֵ
��:��ѯidΪ��docuemnt

3.9��ѯ�ĵ�-querystring��ѯ
**
�
_search:ִ�ж������ַ���
psot����
ip:9200/������/_doc/_search
������:
**
���������˼��ֻҪ����query��������е�һ���־ͷ��ض�Ӧdocument���ֶ�
default_fieldΪ��Ӧ���ֶ���
{
"query":{
"query_string":{
"default_field": "title",
"query":"������"
}
}
}

3.10��ѯ�ĵ�-term��ѯ
�
**
_search:ִ�ж������ַ���
**
psot����
ip:9200/������/_doc/_search
������
**
-termֻ����һ������һ�����ֵIJ�ѯ
{
"query":{
"term":{
"title":"��"
}
}
}
IK �ִ�����ElasticSearch����ʹ��
���߷ִ������ڵ�����
�ڽ����ַ�����ѯʱ,���Ƿ���ȥ����"����������"��"����"����������������;
���ڽ��д�����ѯʱ,��������"����"ȴû������������;
����ԭ����ElasticSearch�ı��ִ������µ�,�����Ǵ�������ʱ,�ֶ�ʹ�õ��DZ��ִ���:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,����� "���dz���Ա" ���зִ�
���ִ����ִ�Ч������:
�ִʽ��:
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard" //���ִ���
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard" //���ִ���
}
}
}
}
}
����� �����dz���Ա�� ���зִ�
���ִ����ִ�Ч������:
http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=���dz���Ա
�ִʽ��:
{
"tokens" : [
{
"token" : "��",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "��",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "��",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "��",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "Ա",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
��������Ҫ�ķִ�Ч����:�ҡ��ǡ�������Ա
�����Ļ�����Ҫ������֧�����õķ�������֧��,֧�����ķִʵķִ����кܶ�,word�ִ������Ҷ���ţ���̹ŷִʡ�Ansj�ִʵ�,�����dz��õĻ�������Ҫ���ܵ�IK�ִ�����
IK�ִ������
IKAnalyzer��һ����Դ��,����java���Կ����������������ķִʹ��߰�����2006��12���Ƴ�1.0�濪ʼ,IKAnalyzer�Ѿ��Ƴ� ��3����汾�����,�����Կ�Դ��ĿLuceneΪӦ�������,��ϴʵ�ִʺ��ķ������㷨�����ķִ�������°汾��IKAnalyzer3.0��չΪ ����Java�Ĺ��÷ִ����,������Lucene��Ŀ,ͬʱ�ṩ�˶�Lucene��Ĭ���Ż�ʵ�֡�
IK�ִ���3.0����������:
**1)**���������еġ����������ϸ�����з��㷨��,����60����/��ĸ��ٴ���������
**2)**�����˶��Ӵ���������ģʽ,֧��:Ӣ����ĸ(IP��ַ��Email��URL)������(����,��������������,��������,��ѧ������),���Ĵʻ�(��������������)�ȷִʴ�����
**3)**����Ӣ����֧�ֲ��Ǻܺ�,���ⷽ��Ĵ����Ƚ��鷳.������һ�β�ѯ,ͬʱ��֧�ָ��˴������Ż��Ĵʵ�洢,��С���ڴ�ռ�á�
**4)**֧���û��ʵ���չ���塣
**5)**���Luceneȫ�ļ����Ż��IJ�ѯ������IKQueryParser;������������㷨�Ż���ѯ�ؼ��ֵ������������,�ܼ�������Lucene�����������ʡ�
�ִ������ذ�װ
1)���ص�ַ:
https://github.com/medcl/elasticsearch-analysis-ik/releases
ѡ�����ӦElasticSearch�İ汾�������ذ�װ

2)��ѹ
����ѹ���elasticsearch�ļ��п�����elasticsearch-��Ӧ�汾\plugins��,���������ļ���Ϊanalysis-ik

3)��������ElasticSearch,���ɼ���IK�ִ���

����
IK�ṩ�������ִ��㷨ik_smart �� ik_max_word
���� ik_smart Ϊ�����з�,ik_max_wordΪ��ϸ���Ȼ���
���Ƿֱ�����һ��
1)��С�з�:
��postman��ַ�������ַ

������
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "����Ա",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
2)��ϸ�з�:
��postman��ַ�������ַ

������
{
"tokens": [
{
"token": "��",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "��",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "����Ա",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "����",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "Ա",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
������ӳ��mapping
ɾ��ԭ��blog1����

����blog1����,��ʱ�ִ���ʹ��ik_max_word
{
"properties": {
"id": {
"type": "long",
"store": true
},
"title": {
"type": "text",
"store": true,
"index":"true",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"true",
"analyzer":"ik_max_word"
}
}
}
�����ĵ�

�ٴβ���queryString��ѯ
�������������ַ�����Ϊ"����������",��ѯ


�������������ַ�����Ϊ"����",�ٴβ�ѯ


ElasticSearch��Ⱥ
����
ES��Ⱥ��һ�� P2P����(ʹ�� gossip Э��)�ķֲ�ʽϵͳ,���˼�Ⱥ״̬��������,�������е������Է��͵���Ⱥ������һ̨�ڵ���,����ڵ�����Լ��ҵ���Ҫת������Щ�ڵ�,����ֱ�Ӹ���Щ�ڵ�ͨ�š�����,������ܹ���������������˵,������Ⱥ����Ҫ�����ü������ Elasticsearch 2.0 ֮ǰ,���谭��������,������������ͬ cluster.name �Ľڵ㶼�Զ�������һ����Ⱥ�С�2.0 �汾֮��,���ڰ�ȫ�Ŀ��DZ�����������������ɵ��鷳,�� 2.0 �汾��ʼ,Ĭ�ϵ��Զ����ַ�ʽ��Ϊ�˵���(unicast)��ʽ���������ṩ��̨�ڵ�ĵ�ַ,ES ��������gossip router ��ɫ,������ɼ�Ⱥ�ķ��֡�������ֻ�� ES ��һ����С�Ĺ���,���� gossip router ��ɫ������Ҫ��������,ÿ�� ES �ڵ㶼���Ե��Ρ�����,���õ�����ʽ�ļ�Ⱥ,���ڵ㶼������ͬ�ļ����ڵ��б���Ϊ router���ɡ���Ⱥ�нڵ�����û������,һ����ڵ���2���ڵ�Ϳ��Կ����Ǽ�Ⱥ�ˡ�һ�㴦�ڸ����ܼ��߿��÷���������һ�㼯Ⱥ�еĽڵ���������3����3�����ϡ�
Elasticsearch��ظ���
1 .��Ⱥ cluster
һ����Ⱥ������һ�������ڵ���֯��һ��,���ǹ�ͬ��������������,��һ���ṩ�������������ܡ�һ����Ⱥ��һ��Ψһ�����ֱ�ʶ,�������Ĭ�Ͼ��ǡ�elasticsearch���������������Ҫ��,��Ϊһ���ڵ�ֻ��ͨ��ָ��ij����Ⱥ������,�����������Ⱥ
2. �ڵ� node
һ���ڵ��Ǽ�Ⱥ�е�һ��������,��Ϊ��Ⱥ��һ����,���洢����,���뼯Ⱥ���������������ܡ��ͼ�Ⱥ����,һ���ڵ�Ҳ����һ����������ʶ��,Ĭ�������,���������һ�����������������ɫ������,������ֻ���������ʱ����ڵ㡣������ֶ��ڹ���������˵ͦ��Ҫ��,��Ϊ���������������,���ȥȷ�������е���Щ��������Ӧ��Elasticsearch��Ⱥ�е���Щ�ڵ㡣
һ���ڵ����ͨ�����ü�Ⱥ���Ƶķ�ʽ������һ��ָ���ļ�Ⱥ��Ĭ�������,ÿ���ڵ㶼�ᱻ���ż��뵽һ��������elasticsearch���ļ�Ⱥ��,����ζ��,�������������������������ɸ��ڵ�,���ٶ������ܹ�����ֱ˴�,���ǽ����Զ����γɲ����뵽һ��������elasticsearch���ļ�Ⱥ�С�
��һ����Ⱥ��,ֻҪ����,����ӵ���������ڵ㡣����,�����ǰ���������û�������κ�Elasticsearch�ڵ�,��ʱ����һ���ڵ�,��Ĭ�ϴ���������һ��������elasticsearch���ļ�Ⱥ��
3. ��Ƭ���� shards&replicas
һ���������Դ洢�����������Ӳ�����ƵĴ������ݡ�����,һ������10���ĵ�������ռ��1TB�Ĵ��̿ռ�,����
һ�ڵ㶼û��������Ĵ��̿ռ�;���ߵ����ڵ㴦����������,��Ӧ̫����Ϊ�˽���������,Elasticsearch�ṩ
�˽��������ֳɶ�ݵ�����,��Щ�ݾͽ�����Ƭ�����㴴��һ��������ʱ��,�����ָ������Ҫ�ķ�Ƭ��������ÿ����Ƭ����Ҳ��һ���������Ʋ��Ҷ����ġ�������,��������������Ա����õ���Ⱥ�е��κνڵ��ϡ���Ƭ����Ҫ,��Ҫ���������ԭ��:
1)������ˮƽ�ָ�/��չ�������������
2)�������ڷ�Ƭ(DZ�ڵ�,λ�ڶ���ڵ���)֮�Ͻ��зֲ�ʽ�ġ����еIJ���,�����������/������������һ����Ƭ�����ֲ�,�����ĵ������ۺϻ���������,����ȫ��Elasticsearch������,������Ϊ�û�������˵,��Щ�������ġ�
��һ������/�ƵĻ�����,ʧ����ʱ�����ܷ���,��ij����Ƭ/�ڵ㲻֪��ô�ľʹ�������״̬,���������κ�ԭ����ʧ��,���������,��һ������ת�ƻ����Ƿdz����ò�����ǿ���Ƽ��ġ�Ϊ��Ŀ��,Elasticsearch�����㴴����Ƭ��һ�ݻ��ݿ���,��Щ�����������Ʒ�Ƭ,����ֱ�ӽи��ơ�
����֮������Ҫ,��������Ҫԭ��: �ڷ�Ƭ/�ڵ�ʧ�ܵ������,�ṩ�˸߿���������Ϊ���ԭ��,ע����Ʒ�Ƭ�Ӳ���ԭ/��Ҫ(original/primary)��Ƭ����ͬһ�ڵ����Ƿdz���Ҫ�ġ���չ���������/������,��Ϊ�������������еĸ����ϲ������С���֮,ÿ���������Ա��ֳɶ����Ƭ��һ������Ҳ���Ա�����0��(��˼��û�и���)���Ρ�һ��������,ÿ����������������Ƭ(��Ϊ����Դ��ԭ���ķ�Ƭ)���Ʒ�Ƭ(����Ƭ�Ŀ���)֮�𡣷�Ƭ���Ƶ���������������������ʱ��ָ��������������֮��,��������κ�ʱ��̬�ظı临�Ƶ�����,�������º��ܸı��Ƭ��������
Ĭ�������,Elasticsearch�е�ÿ����������Ƭ5������Ƭ��1������,����ζ��,�����ļ�Ⱥ�������������ڵ�,�������������5������Ƭ������5�����Ʒ�Ƭ(1����ȫ����),�����Ļ�ÿ�������ܹ�����10����Ƭ��
��Ⱥ�Ĵ
1.����̨elasticsearch������
����elasticsearch-cluster�ļ���,���ڲ���������elasticsearch����
2. ��ÿ̨����������
��elasticsearch-cluster\node*\config\elasticsearch.yml�����ļ�
node1�ڵ�:
# es-7.3.0-node-1
cluster.name: search-7.3.2
node.name: node-1
node.master: true
node.data: false
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
cluster.initial_master_nodes: ["node-1"]
node2�ڵ�:
# es-7.3.0-node-2
cluster.name: search-7.3.2
node.name: node-2
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node3�ڵ�:
# es-7.3.0-node-3
cluster.name: search-7.3.2
node.name: node-3
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
3. ���������ڵ������
˫��elasticsearch-cluster\node*\bin\elasticsearch.bat
�����ڵ�1:
�����ڵ�2:
�����ڵ�3:

4.��Ⱥ����
����������ӳ��
PUT localhost:9200/blog1
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
}
}
}
}
}
�����ĵ�
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch��һ������Lucene������������",
"content":"���ṩ��һ���ֲ�ʽ���û�������ȫ����������,����RESTful web�ӿڡ�Elasticsearch����Java������,����ΪApache���������µĿ���Դ�뷢��,�ǵ�ǰ���е���ҵ���������档��������Ƽ�����,�ܹ��ﵽʵʱ����,�ȶ�,�ɿ�,����,��װʹ�÷��㡣"
}
ʹ��elasticsearch-header�鿴��Ⱥ���

Java����Elasticsearch

1. ����
-
Elasticsearch�ǻ���Lucene������һ���ֲ�ʽȫ�ļ������,��Elasticsearch�д洢�ʹ�Elasticsearch�в�ѯ,��ʽ��json�� -
��
Elasticsearch�д洢����,��ʵ������es�е�index�����type�д洢json���͵����ݡ� -
elasticsearch�ṩ�˺ܶ����ԵĿͻ������ڲ���elasticsearch����,����:java��python��.net��JavaScript��PHP�ȡ�������Ҫ�������ʹ��java����������elasticsearch������elasticsearch�Ĺ������ṩ������java���Ե�API,һ����Java Transport Client,һ����Java REST Client��
Java Transport Client** �ǻ��� TCP Э�齻����,**��elasticsearch 7.0+�汾��ٷ�������ʹ��,��Elasticsearch 8.0�İ汾����ȫ�Ƴ�TransportClient
**Java REST Client�ǻ��� HTTP Э�齻��,**��Java REST Client�ַ�ΪJava Low Level REST Client��Java High Level REST Client
Java High Level REST Client����Java Low Level REST Client�Ļ��������˷�װ,ʹ���Ը����������Ͳ������ӱ����ķ�ʽ����elasticsearch����
�ٷ��Ƽ�ʹ��
Java High Level REST Client,��Ϊ��ʵ��ʹ����,Java Transport Client�ڴ�������»�������Ӳ��ȶ��������
�ǽ��������Ǿ�������elasticsearch�ṩ��Java High Level REST Client(���¼�Ƹ�REST�ͻ���)��һЩ�����IJ���,����IJ�����������Ķ�elasticsearch�Ĺٷ��ĵ�:[https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html)
2. ��
- ����:
Windows 10elasticsearch 7.91IDEAMavenJava 8
���ͻ�����Ҫ
Java 1.8��������Elasticsearch core��Ŀ
- ����:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.9.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.1</version>
</dependency>
3. ��ʼ��
- ʵ����Ҫ���� REST �ͼ��ͻ���������,������ʾ:
RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
- ���ͻ��˽����ڲ��������ڻ����ṩ��������ִ������ĵͼ��ͻ��ˡ��õͼ��ͻ���ά��һ�����ӳز�����һЩ�߳�,���,�����ܺõ���ɸ��ͻ���ʱ,��Ӧ�ùرոø��ͻ���,Ȼ��ر��ڲ��ͼ��ͻ������ͷ���Щ��Դ�������ͨ�� ����ʱ�����:
close
client.close();
���й� Java ���ͻ��˵ı��ĵ������ಿ����,ʵ��������Ϊ ��
RestHighLevelClientclient
����:
- ��ѯ
index����:
public static void main(String[] args) {
RestClientBuilder builder = RestClient.builder(
new HttpHost(
"127.0.0.1", //es���� IP
9200 // es �˿�http
)
);
RestHighLevelClient client = new RestHighLevelClient(builder);
GetRequest request = new GetRequest(
"blog1", //����
"1" //�ĵ�ID
);
//����Բ����ڵ�����ִ�л�ȡ����ʱ,��Ӧ404״̬��,������IOException,��Ҫ�����·�ʽ����:
GetResponse documentFields = null;
try {
documentFields = client.get(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
������Ϊ���������ڶ��׳����쳣���
}
System.out.println(documentFields);
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
- ��ѯ���:
{
"_index": "blog1",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"age": 1,
"country": "fuzhou",
"date": "2020-09-10",
"name": "ngitvusercancel"
}
}
������һ��������չʾ,�����dz����˽�ͨ��
Java�ĸ�restful�ͻ���������, �������ǽ��������Api�Ľ���
4. ���� API (Index Api)
4.1 ��������(Create Index API)
**
4.1.1 ����:
/*
* ��������.
* url:https://i-code.online/
*/
public static void main(String[] args) {
//����������Ϣ
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//������������ �������� student
CreateIndexRequest createIndexRequest = new CreateIndexRequest("student-1");
//��������ʱ����������֮��ص� �ض�����
createIndexRequest.settings(Settings.builder()
.put("index.number_of_shards",3) //��Ƭ��
.put("index.number_of_replicas",2) //������
);
//�����ĵ�����ӳ��
createIndexRequest.mapping("{\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"long\",\n" +
" \"store\": true\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": true,\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"content\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": true,\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
"}",
XContentType.JSON //����ӳ��,��Ҫ����һ��JSON�ַ���
);
//��ѡ����
//��ʱ,�ȴ����нڵ㱻ȷ��(ʹ��TimeValue��ʽ)
createIndexRequest.setTimeout(TimeValue.timeValueMinutes(1));
try {
//ͬ��ִ��
CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
//���ص�CreateIndexResponse���������й�ִ�еIJ�������Ϣ,������ʾ:
boolean acknowledged = createIndexResponse.isAcknowledged();//ָʾ�Ƿ����нڵ㶼��ȷ������
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();//ָʾ�Ƿ��ڳ�ʱ֮ǰΪ�����е�ÿ����Ƭ�����˱���ķ�Ƭ������
System.out.println("acknowledged:"+acknowledged);
System.out.println("shardsAcknowledged:"+shardsAcknowledged);
System.out.println(createIndexResponse.index());
} catch (IOException e) {
e.printStackTrace();
}
try {
//�رտͻ�������
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
������һ�� index �����Ĺ���,�����ϸ�ڲ���
api�������
4.1.2 ������������
- ��Ҫ����:
CreateIndexRequestindex
CreateIndexRequest request = new CreateIndexRequest("twitter");//<1>
<1>Ҫ��������
4.1.3 ��������
- ������ÿ�����������Ծ�������������ض����á�
//������������
request.settings(Settings.builder()
.put("index.number_of_shards", 3) //��Ƭ��
.put("index.number_of_replicas", 2)//������
);
4.1.4 ����ӳ��
- ���Դ�������,���������ĵ����͵�ӳ��
request.mapping(
"{\n" +
" "properties": {\n" +
" "message": {\n" +
" "type": "text"\n" +
" }\n" +
" }\n" +
"}", //<1> Ҫ���������
XContentType.JSON); //<2> �����͵�ӳ��,��Ϊ JSON �ַ����ṩ
<1>Ҫ���������
<2>�����͵�ӳ��,��ΪJSON�ַ����ṩ
- ����������ʾ��ʾ��֮��,�������Բ�ͬ�ķ�ʽ�ṩӳ��Դ:
String
Map<String, Object> message = new HashMap<>();
message.put("type", "text");
Map<String, Object> properties = new HashMap<>();
properties.put("message", message);
Map<String, Object> mapping = new HashMap<>();
mapping.put("properties", properties);
request.mapping(mapping); //����map��ӳ�伯��,�Զ�תΪ json
�ṩ�Զ�ת��Ϊ
JSON��ʽ��ӳ��ԴMap
���ַ�ʽ���Ƕ��,��ʹ�ù�����ע��Ƕ��,�����ǩǶ��:properties -> message -> type
XContentBuilder builder = XContentFactory.jsonBuilder(); // ʹ��XContentBuilder����������
builder.startObject();
{
builder.startObject("properties");
{
builder.startObject("message");
{
builder.field("type", "text");
}
builder.endObject();
}
builder.endObject();
}
builder.endObject();
ӳ����Ϊ�����ṩ��Դ,�����������ð�����,��������
JSON����XContentBuilder
4.1.5 ��������
- ��������������ʱ���ñ���
request.alias(new Alias("twitter_alias").filter(QueryBuilders.termQuery("user", "kimchy"))); //Ҫ����ı���
4.1.6 �ṩ����Դ
- ǰ�����Ƕ���һ��һ�������õ�,��ʵҲ�����ṩ����Դ,���������в���(ӳ�䡢���úͱ���):
request.source("{\n" +
" \"settings\" : {\n" +
" \"number_of_shards\" : 1,\n" +
" \"number_of_replicas\" : 0\n" +
" },\n" +
" \"mappings\" : {\n" +
" \"properties\" : {\n" +
" \"message\" : { \"type\" : \"text\" }\n" +
" }\n" +
" },\n" +
" \"aliases\" : {\n" +
" \"twitter_alias\" : {}\n" +
" }\n" +
"}", XContentType.JSON);
��Ϊ JSON �ַ����ṩ��Դ����Ҳ������Ϊ �� �ṩ��MapXContentBuilder
4.1.7 ��ѡ����
- ����ѡ���ṩ���²���:
request.setTimeout(TimeValue.timeValueMinutes(2));
��ʱ�Եȴ����нڵ㽫��������ȷ��Ϊ
TimeValue
request.setMasterTimeout(TimeValue.timeValueMinutes(1));
����Ϊ
TimeValue
request.waitForActiveShards(ActiveShardCount.from(2));
request.waitForActiveShards(ActiveShardCount.DEFAULT);
�ڴ�������
API������Ӧ֮ǰ�ȴ��Ļ��Ƭ������,��Ϊint
�ڴ�������API������Ӧ֮ǰ�ȴ��Ļ��Ƭ������,��ΪActiveShardCount
4.1.8 ͬ��ִ��
- �����з�ʽִ�� ʱ,�ͻ��˽��ȴ� ���� ,Ȼ���ټ���ִ�д���:
CreateIndexRequest CreateIndexResponse
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
ͬ�����ÿ��ܻ����� �ڸ� REST �ͻ����������� REST ��Ӧ������ᷢ��ʱ������������û�дӷ��������ص���Ӧ������¡�
IOException
�ڷ��������� �� �������������,���ͻ��˳��Է�����Ӧ���Ĵ�����ϸ��Ϣ,Ȼ����������,����ԭʼ��������Ϊ�����쳣��4xx 5xx ElasticsearchExceptionResponseException
4.1.9 �첽ִ��
- Ҳ�������첽��ʽִ�� ,�Ա�ͻ��˿���ֱ�ӷ��ء��û���Ҫָ�����ͨ������������������ݵ��첽��������������������Ӧ��DZ�ڹ���:
CreateIndexRequest
client.indices().createAsync(request, RequestOptions.DEFAULT, listener);
ִ�����ʱҪִ�к�Ҫʹ�õ�
CreateIndexRequest ActionListener
- �첽����������ֹ���������ء���ɺ�,���ִ�гɹ����,��ʹ��
onResponse�������� ,���ִ��ʧ��,��ʹ��onFailure�÷�����ʧ�ܷ�����Ԥ���쳣��ͬ��ִ�а�����ͬ��ActionListener
���͵�������������ʾ:
ActionListener<CreateIndexResponse> listener =
new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
//�ɹ�ִ��ʱ���á�
}
@Override
public void onFailure(Exception e) {
//������ʧ��ʱ����
}
};
4.1.10 ����������Ӧ
- ���ص����������й�ִ�в�������Ϣ,������ʾ:
CreateIndexResponse
boolean acknowledged = createIndexResponse.isAcknowledged(); // <1>
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged(); // <2>
<1> ָʾ���нڵ��Ƿ���ȷ������
<2> ָʾ�ڼ�ʱ֮ǰ�Ƿ�Ϊ�����е�ÿ����Ƭ��������ķ�Ƭ������
4.2 ɾ������(Delete Index Api)
4.2.1 ����:
/**
* ɾ������.
* url:https://i-code.online/
* @param args
*/
public static void main(String[] args) {
//1. �����ͻ���
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//2. ����DeleteIndexRequest ���� index(������) ����
DeleteIndexRequest request = new DeleteIndexRequest("student");
//��ʱ�Եȴ����нڵ�ȷ������ɾ�� ����Ϊ TimeValue ����
request.timeout(TimeValue.timeValueMinutes(1));
//����master�ڵ�ij�ʱʱ��(ʹ��TimeValue��ʽ)
request.masterNodeTimeout(TimeValue.timeValueMinutes(1));
try {
// ����delete
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.printf("isAcknowledged:%s", response.isAcknowledged());
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.2 ɾ����������
- ��Ҫ����:
DeleteIndexRequestindex
DeleteIndexRequest request = new DeleteIndexRequest("posts");//<1> <1> ����(index)��
<1> ����(index)��
4.2.3 ��ѡ����
- ����ѡ���ṩ���²���:
request.timeout(TimeValue.timeValueMinutes(2));
request.timeout("2m");
��ʱ�Եȴ����нڵ�ȷ������ɾ��Ϊ
TimeValue����
��ʱ�Եȴ����нڵ�ȷ������ɾ��ΪString����
request.masterNodeTimeout(TimeValue.timeValueMinutes(1));//����master�ڵ�ij�ʱʱ��(ʹ��TimeValue��ʽ)
request.masterNodeTimeout("1m");//����master�ڵ�ij�ʱʱ��(ʹ���ַ�����ʽ)
����master�ڵ�ij�ʱʱ��(ʹ��TimeValue��ʽ)
����master�ڵ�ij�ʱʱ��(ʹ���ַ�����ʽ)
request.indicesOptions(IndicesOptions.lenientExpandOpen());
���ÿ�����ν��������õ������Լ����չ��ͨ�������ʽIndicesOptions
4.2.4 ͬ��ִ��
- �����з�ʽִ��
DeleteIndexRequestʱ,�ͻ��˽��ȴ�DeleteIndexResponse���� ,Ȼ���ټ���ִ�д���:DeleteIndexRequestDeleteIndexResponse
AcknowledgedResponse deleteIndexResponse = client.indices().delete(request, RequestOptions.DEFAULT);
ͬ�����ÿ��ܻ����� �ڸ�
REST�ͻ�����������REST��Ӧ������ᷢ��ʱ������������û�дӷ��������ص���Ӧ������¡�IOException
�ڷ��������� �� �������������,���ͻ��˳��Է�����Ӧ���Ĵ�����ϸ��Ϣ,Ȼ����������,����ԭʼ��������Ϊ�����쳣��4xx 5xx ElasticsearchExceptionResponseException
4.2.5 �첽ִ��
- Ҳ�������첽��ʽִ�� ,�Ա�ͻ��˿���ֱ�ӷ��ء��û���Ҫָ�����ͨ������������������ݵ��첽ɾ������������������Ӧ��DZ�ڹ���:
DeleteIndexRequest
client.indices().deleteAsync(request, RequestOptions.DEFAULT, listener); //<1>
<1> ִ�����ʱҪִ�к�Ҫʹ�õ�DeleteIndexRequest ActionListener
�첽����������ֹ���������ء���ɺ�,���ִ�гɹ����,��ʹ�� ActionListener#onResponse �������� ,���ִ��ʧ��,��ʹ�� ActionListener# onFailure �÷�����ʧ�ܷ�����Ԥ���쳣��ͬ��ִ�а�����ͬ��
���͵�������������ʾ:delete-index
ActionListener<AcknowledgedResponse> listener =
new ActionListener<AcknowledgedResponse>() {
@Override
public void onResponse(AcknowledgedResponse deleteIndexResponse) {
//�ɹ�ִ��ʱ���á�
}
@Override
public void onFailure(Exception e) {
//������ʧ��ʱ���á�DeleteIndexRequest
}
};
4.2.6 ɾ��������Ӧ
- ���ص����������й�ִ�в�������Ϣ,������ʾ:
DeleteIndexResponse
boolean acknowledged = deleteIndexResponse.isAcknowledged(); //<1> ָʾ���нڵ��Ƿ���ȷ������
<1> ָʾ���нڵ��Ƿ���ȷ������
- ���δ�ҵ�����,������ :
ElasticsearchException
try {
DeleteIndexRequest request = new DeleteIndexRequest("does_not_exist");
client.indices().delete(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException exception) {
if (exception.status() == RestStatus.NOT_FOUND) {
//���δ�ҵ�Ҫɾ��������,�����""
}
}
���δ�ҵ�Ҫɾ��������,�����""
4.3 ��������(Index Exists Api)
4.3.1 ����:
/**
* �����Ƿ����Api
* url:www.i-code.online
* @param args
*/
public static void main(String[] args) {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//��������
GetIndexRequest request = new GetIndexRequest("student");
//<1> �Ƿ��ر�����Ϣ���Ǵ����ڵ����״̬
request.local(false);
//<2> ���ؽ��Ϊ�ʺ�����ĸ�ʽ
request.humanReadable(true);
try {
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
} catch (IOException e) {
e.printStackTrace();
}
}
4.3.2 ������������
- �� REST �ͻ���ʹ�� ��Index Exists API�������������DZ���ġ�
GetIndexRequest
GetIndexRequest request = new GetIndexRequest("twitter"); //<1> index ����
<1> index ����
4.3.3 ��ѡ����
- �������� API ���������¿�ѡ����,ͨ�� :
GetIndexRequest
request.local(false);//<1> �Ƿ��ر�����Ϣ���Ǵ����ڵ����״̬
request.humanReadable(true); //<2> ���ؽ��Ϊ�ʺ�����ĸ�ʽ
request.includeDefaults(false); //<3> �Ƿ�ÿ������������Ĭ������
request.indicesOptions(indicesOptions); //<4> ������ν��������õ������Լ����չ��ͨ�������ʽ
<1> �Ƿ��ر�����Ϣ���Ǵ����ڵ����״̬
<2> ���ؽ��Ϊ�ʺ�����ĸ�ʽ
<3> �Ƿ�ÿ������������Ĭ������
<4> ������ν��������õ������Լ����չ��ͨ�������ʽ
4.3.4 ͬ��ִ��
- �����з�ʽִ�� ʱ,�ͻ��˽��ȴ� ���� ,Ȼ���ټ���ִ�д���:
GetIndexRequestboolean
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
������ͬ������ͬ
4.3.5 �첽ִ��
-
Ҳ�������첽��ʽִ�� ,�Ա�ͻ��˿���ֱ�ӷ��ء��û���Ҫָ�����ͨ������������������ݵ��첽�������ڵķ�����������Ӧ��DZ�ڹ���:
GetIndexRequest
client.indices().existsAsync(request, RequestOptions.DEFAULT, listener);//<1>ִ�����ʱҪִ�к�Ҫʹ�õ� GetIndexRequest ActionListener
<1>ִ�����ʱҪִ�к�Ҫʹ�õ�
GetIndexRequestActionListener
�첽�Ĵ������������첽����ͬ,����ʵ��ActionListener�ķ���
4.3.6 ��Ӧ
- ��Ӧ��һ��ֵ,ָʾ����(������)�Ƿ���ڡ�
boolean
5. �ĵ� Api (Document APIs)
5.1 ���� API (Index Api)
5.1.1 ����:
- ���Ӽ�¼
private static void test02() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
//��������, ����index����
IndexRequest request = new IndexRequest("student");
//�����ģʽ,CREATE: ����ģʽ,����Ѿ������� Index:�������ٴ���,Ҳ������
request.opType(DocWriteRequest.OpType.INDEX);
String json = "{\n" +
" \"id\": 12,\n" +
" \"name\": \"admin\",\n" +
" \"content\": \"���Ĵ������������첽����ͬ,����ʵ��ActionListener �ķ���\"\n" +
"}";
request.id("1").source(
json,
XContentType.JSON
);
IndexResponse indexResponse = null;
try {
//���� index ����
indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.getVersion());
System.out.println(indexResponse.getIndex());
System.out.println(indexResponse.getId());
System.out.println(indexResponse.status());
} catch (ElasticsearchStatusException | IOException e) {
e.printStackTrace();
}
}
5.1.2 ��������
- ��Ҫ���²���:
IndexRequest
//��������, ����index����
IndexRequest request = new IndexRequest("student"); //<1> index ����
String json = "{\n" +
" \"id\": 12,\n" +
" \"name\": \"admin\",\n" +
" \"content\": \"���Ĵ������������첽����ͬ,����ʵ��ActionListener �ķ���\"\n" +
"}";
request
.id("1") // <2> ָ���ĵ� ID
.source(
json,
XContentType.JSON // <3> ָ����������,json
);
<1> index ����ָ��
<2> ������ĵ� ID
<3> ָ����������,json
�ṩ�ĵ�Դ
- ����������ʾ��ʾ��֮��,�������Բ�ͬ�ķ�ʽ�ṩ�ĵ�Դ:
String
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("id", 1);
jsonMap.put("name", "Admin);
jsonMap.put("content", "���Ĵ������������첽����ͬ");
IndexRequest indexRequest = new IndexRequest("student").id("1").source(jsonMap);
�ĵ�Դ��Ϊ �Զ�ת��Ϊ
JSON��ʽ��Map
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("id", 1);
builder.field("name", "admin);
builder.field("content", "trying out Elasticsearch");
}
builder.endObject();
IndexRequest indexRequest = new IndexRequest("student").id("1").source(builder);
�ĵ�Դ��Ϊ�����ṩ,�����������ð���������
JSON����XContentBuilder
IndexRequest indexRequest = new IndexRequest("student")
.id("1")
.source("id", 1,
"name", "admin",
"content", "trying out Elasticsearch");
��Ϊ��Կ���ṩ���ĵ�Դ,��Դ��ת��Ϊ JSON ��ʽObject
5.1.3 ��ѡ����
- ����ѡ���ṩ���²���:
request.routing("routing"); //<1>
<1> ·��ֵ
request.timeout(TimeValue.timeValueSeconds(1)); //<1>
request.timeout("1s"); // <2>
<1> ��ʱ�Եȴ�����Ƭ ��Ϊ TimeValue
<2> ��ʱ�Եȴ�����Ƭ ��Ϊ String
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL); //<1>
request.setRefreshPolicy("wait_for"); //<2>
<1> ������ˢ�� Ϊʵ��
WriteRequest.RefreshPolicy
<2> ������ˢ�� ΪString
request.version(2);
�汾
request.versionType(VersionType.EXTERNAL); //�汾����
�汾����
request.opType(DocWriteRequest.OpType.CREATE);//<1>
request.opType("create");//<2>
<1> ��Ϊֵ�ṩ�IJ�������
DocWriteRequest.OpType
<2> �ṩ�IJ������Ϳ����� ��(Ĭ��)Stringcreateindex
request.setPipeline("pipeline");
�������ĵ�֮ǰҪִ�еİ����ܵ�������
5.1.4 ͬ��ִ��
- �����з�ʽִ�� ʱ,�ͻ��˽��ȴ� ���� ,Ȼ���ټ���ִ�д���:
IndexRequestIndexResponse
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
- ͬ�����ÿ��ܻ����� �ڸ� REST �ͻ����������� REST ��Ӧ������ᷢ��ʱ������������û�дӷ��������ص���Ӧ������¡�
IOException - �ڷ��������� �� �������������,���ͻ��˳��Է�����Ӧ���Ĵ�����ϸ��Ϣ,Ȼ����������,����ԭʼ��������Ϊ�����쳣��
4xx 5xx ElasticsearchExceptionResponseException
5.1.5 �첽ִ��
- Ҳ�������첽��ʽִ�� ,�Ա�ͻ��˿���ֱ�ӷ��ء��û���Ҫָ�����ͨ������������������ݵ��첽����������������Ӧ��DZ�ڹ���:
IndexRequest
client.indexAsync(request, RequestOptions.DEFAULT, listener); //<1>
<1> ִ�����ʱҪִ�к�Ҫʹ�õ�
IndexRequestActionListener
- �첽����������ֹ���������ء���ɺ�,���ִ�гɹ����,��ʹ�� �������� ,���ִ��ʧ��,��ʹ�� �÷�����ʧ�ܷ�����Ԥ���쳣��ͬ��ִ�а�����ͬ��
ActionListeneronResponseonFailure - ���͵�������������ʾ:index
listener = new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
//<1> �ɹ�ִ��ʱ���á�
}
@Override
public void onFailure(Exception e) {
//<2> ������ʧ��ʱ���á�IndexRequest
}
};
<1> �ɹ�ִ��ʱ���á�
<2> ������ʧ��ʱ���á�> IndexRequest
5.1.6 ������Ӧ
- ���ص����������й�ִ�в�������Ϣ,������ʾ:
IndexResponse
String index = indexResponse.getIndex();
String id = indexResponse.getId();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
//<1>
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
//<2>
}
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
// <3>
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure :
shardInfo.getFailures()) {
String reason = failure.reason(); //<4>
}
}
<1> ����(�����Ҫ)�״δ����ĵ������
<2> ����(�����Ҫ)�ĵ�����д�����,��Ϊ���Ѿ�����
<3> �����ɹ���Ƭ�������ܷ�Ƭ�����
<4> ����DZ�ڵĹ���
- ������ڰ汾��ͻ,������ :
ElasticsearchException
IndexRequest request = new IndexRequest("posts")
.id("1")
.source("field", "value")
.setIfSeqNo(10L)
.setIfPrimaryTerm(20);
try {
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
//<1>
}
}
<1> �����쳣ָʾ���ذ汾��ͻ����
- ������Ϊ���Ѵ��ھ�����ͬ������ ID ���ĵ��������,��������ͬ�����:
opTypecreate
IndexRequest request = new IndexRequest("posts")
.id("1")
.source("field", "value")
.opType(DocWriteRequest.OpType.CREATE);
try {
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
} catch(ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
//<1>
}
}
<1>�����쳣ָʾ���ذ汾��ͻ����
5.2 ��ȡApi (Get API)
5.2.1 ����:
private static void test01(){
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200)));
GetRequest request = new GetRequest("student");
// Ϊ�ض��ֶ� ���� Դ����
String[] includs = {"name","id","content"};
String[] excluds = {"id"};
FetchSourceContext context = new FetchSourceContext(true,includs,excluds);
request.id("1").version(2).fetchSourceContext(context);
try {
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
if (documentFields.isExists()) {
//��������
System.out.println(documentFields.getIndex());
// ��ȡ�ĵ�Դ�� Map ���
System.out.println(documentFields.getSource());
// ��ȡԴ��Ϊ Map
System.out.println(documentFields.getSourceAsMap());
// ��ȡԴ��Ϊ bytes
System.out.println(documentFields.getSourceAsBytes());
}else {
System.out.println("�����ڸ�����");
}
} catch (IOException e) {
e.printStackTrace();
}
}
5.2.2 ��ȡ����
- ��Ҫ���²���:GetRequest
GetRequest getRequest = new GetRequest(
"posts", //<1>
"1"); //<1>
<1> ��������
<2> �ĵ� ID
5.2.3 ��ѡ����
- ����ѡ���ṩ���²���:
request.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);
����Դ����,Ĭ�����������
String[] includes = new String[]{"message", "*Date"};
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
Ϊ�ض��ֶ� ���� Դ����
includes: ����������������ֶ�
excludes: ��������ų����ֶ�
String[] includes = Strings.EMPTY_ARRAY;
String[] excludes = new String[]{"message"};
FetchSourceContext fetchSourceContext =
new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
Ϊ�ض��ֶ�����Դ�ų�
request.storedFields("message");
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
String message = getResponse.getField("message").getValue();
Ϊ�ض��洢�ֶ����ü���(Ҫ���ֶε����洢��ӳ����)
�����洢���ֶ�(Ҫ����ֶε����洢��ӳ����)message
request.routing("routing");
·��ֵ
request.preference("preference");
��ѡ��ֵ
request.realtime(false);
��ʵʱ��־����Ϊ(Ĭ�������)falsetrue
request.refresh(true);
�ڼ����ĵ�֮ǰִ��ˢ��(Ĭ�������)false
request.version(2);
�汾
request.versionType(VersionType.EXTERNAL);
�汾����
5.2.4 ͬ��ִ��
- �����з�ʽִ�� ʱ,�ͻ��˽��ȴ� ���� ,Ȼ���ټ���ִ�д���:
GetRequestGetResponse
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
-
ͬ�����ÿ��ܻ����� �ڸ� REST �ͻ����������� REST ��Ӧ������ᷢ��ʱ������������û�дӷ��������ص���Ӧ������¡�IOException
-
�ڷ��������� �� �������������,���ͻ��˳��Է�����Ӧ���Ĵ�����ϸ��Ϣ,Ȼ����������,����ԭʼ��������Ϊ�����쳣��4xx5xxElasticsearchExceptionResponseException
5.2.5 �첽ִ��
- Ҳ�������첽��ʽִ�� ,�Ա�ͻ��˿���ֱ�ӷ��ء��û���Ҫָ�����ͨ������������������ݵ��첽��ȡ������������Ӧ��DZ�ڹ���:
GetRequest
client.getAsync(request, RequestOptions.DEFAULT, listener);
ִ�����ʱҪִ�к�Ҫʹ�õ�
GetRequestActionListener
-
�첽����������ֹ���������ء���ɺ�,���ִ�гɹ����,��ʹ�� �������� ,���ִ��ʧ��,��ʹ�� �÷�����ʧ�ܷ�����Ԥ���쳣��ͬ��ִ�а�����ͬ��ActionListeneronResponseonFailure
-
���͵�������������ʾ:
get
ActionListener<GetResponse> listener = new ActionListener<GetResponse>() {
@Override
public void onResponse(GetResponse getResponse) {
//�ɹ�ִ��ʱ����
}
@Override
public void onFailure(Exception e) {
//������ʧ��ʱ���á�GetRequest
}
};
5.2.6 ��ȡ��Ӧ
- ���ص���������������ĵ�����Ԫ���ݺ����մ洢���ֶΡ�
GetResponse
String index = getResponse.getIndex();
String id = getResponse.getId();
if (getResponse.isExists()) {
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString(); // <1>
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); // <2>
byte[] sourceAsBytes = getResponse.getSourceAsBytes(); // <3>
} else {
// <4>
}
<1> ���ĵ�����Ϊ
String
<2> ���ĵ�����ΪMap<String, Object>
<3> ���ĵ�����Ϊbyte[]
<4> �����Ҳ����ĵ��ķ�������ע��,���ܷ��ص���Ӧ����״̬����,�����ص�����Ч��,�����������쳣��������Ӧ�������κ�Դ�ĵ�,�䷽�������ء�404 GetResponseisExistsfalse
- ���Բ����ڵ�����ִ�� get ����ʱ,��Ӧ����״̬����,����Ҫ�����·�ʽ����������������:
404 ElasticsearchException
GetRequest request = new GetRequest("does_not_exist", "1");
try {
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
//<1> ���������쳣,��Ϊ����������
}
}
<1> ���������쳣,��Ϊ����������
- ����������ض����ĵ��汾,���������ĵ����в�ͬ�İ汾��,�������汾��ͻ:
try {
GetRequest request = new GetRequest("posts", "1").version(2);
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException exception) {
if (exception.status() == RestStatus.CONFLICT) {
// <1>
}
}
<1> �����쳣ָʾ���ذ汾��ͻ����
6. ����
��ʵ�ܶ� Api ��ʹ�ö���������ͬ��,�������Dz��ٶ����� Api ���н���,��Ҫ�˽����ȫ����ȥ�����ĵ��鿴,�ĵ���ַ�������������С�
��¼
Elasticsearch7.XΪʲô�Ƴ�����(type)
Elasticsearch7.XΪʲô�Ƴ�����(type)
Elasticsearch7.XΪʲô�Ƴ�����(type)��Elasticsearch7.0.0���Ժ�汾���ٽ���_default_ ӳ�䡣��6.x�ﴴ����������Ȼ����Elasticsearch6.X֮ǰһ�������á�Types��7.0��API���DZ�������,�ڴ�������,����ӳ��,��ȡӳ��,����ģ��,��ȡģ��,��ȡ�ֶ�ӳ��API���Ų����ݵĸı䡣
ʲô������(type)?
��Elasticsearch�ĵ�һ�������汾����,ÿһ���ĵ������洢��һ��������������,����������һ��type,һ��ӳ�����ʹ�����һ�����������ĵ���ʵ�������,����,һ��twitter����������һ��user���ͺ�tweet���͡�
ÿ��ӳ�����Ͷ������Լ����ֶ�,����user���Ϳ�����һ��full_name�ֶ�,һ��user_name�ֶκ�һ��email�ֶ�,��һ��tweet���Ϳ�����һ��content�ֶ�,һ��tweet_at�ֶ�,��user����һ��һ��user_name�ֶΡ�
ÿһ���ĵ����Ͷ���һ��_typeԪ�ֶ����洢type����,���Ҹ���URL��ָ������������,��ѯ(����)������һ����������(type)��:
GET twitter/user,tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
_type�ֶ��������ĵ���_id�ֶ���������_uid�ֶ�,����������ͬ_id�IJ�ͬ���͵��ĵ����Դ���ͬһ�����������Ҳ���������ĵ���ĸ��ӹ�ϵ,����question���͵��ĵ�������anser�����ĵ��ĸ��ĵ���
Ϊʲô���ͱ��Ƴ���?
���,����˵"����"��ϵ���ݿ�ġ��⡱�����Ƶ�,�����͡��͡������ǶԵȵġ�
����һ������ȷ�ĶԱ�,�����˲���ȷ�ļ��衣�ڹ�ϵ�����ݿ���,"��"���������,һ������������к�����һ����������ͬ����û�й�ϵ,����Ӱ�졣�����������ֶβ��������ġ�
��һ��Elasticsearch������,���в�ͬ���͵�ͬ���ֶ��ڲ�ʹ�õ���ͬһ��lucene�ֶδ洢��Ҳ����˵,����������,user���͵�user_name�ֶκ�tweet���͵�user_name�ֶ��Ǵ洢��һ���ֶ����,�����������user_name������һ�����ֶζ��塣
����ܵ���һЩ����,������ϣ��ͬһ��������"deleted"�ֶ���һ���������Ǵ洢����ֵ,������һ��������洢����ֵ��
���,��ͬһ��������,�洢����С�����ֶ���ͬ����ȫ���ֶζ�����ͬ���ĵ�,�ᵼ������ϡ��,Ӱ��Lucene��Чѹ�����ݵ�������
��Ϊ��Щԭ��,���Ǿ�����Elasticsearch���Ƴ����͵ĸ��
Elasticsearch �Ƴ� type ֮���������
���� 7.0 �汾�ļ�������,type ���Ƴ�Ҳ��Խ��Խ����,�� 6.0 ��ʱ��,�Ѿ�Ĭ��ֻ��֧��һ������һ�� type ��,7.0 �汾������һ������ include_type_name ,�������е� API �� type ��ص�,��������� 7.0 Ĭ���� true,������ 8.0 ��ʱ��,��Ĭ�ϸij� false,Ҳ���Dz����� type ��Ϣ��,����� type �����Ƴ���һ�����ء�
�����ǿ������µ�ʹ�����ư�,�� include_type_name �������ó� false ��:
- ��������:PUT {index}/{type}/{id}
��Ҫ�ij�PUT {index}/_doc/{id} - Mapping ����:
PUT {index}/{type}/_mapping����PUT {index}/_mapping - ������ɾ�IJ������������ؽ������Ĺؼ���
_type�������Ƴ� - ���ӹ�ϵʹ��
join�ֶ�������
#��������
PUT twitter
{
"mappings": {
"_doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
}
#������
PUT twitter/_doc/user-kimchy
{
"type": "user",
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
#����
GET twitter/_search
{
"query": {
"bool": {
"must": {
"match": {
"user_name": "kimchy"
}
},
"filter": {
"match": {
"type": "tweet"
}
}
}
}
}
#�ؽ�����
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
�꾡�� Elasticsearch7.X ��װ����Ⱥ��̳�
���
�������� Elasticsearch (���ļ�� ES)������һ������:
Elasticsearch ��һ���ֲ�ʽ��RESTful �������������ݷ�������,�ܹ��������ӿ�ֳ��ĸ��������� ��Ϊ Elastic Stack �ĺ���,�����д洢��������,��������������֮���Լ�����֮��������
������Ҫ���� Elasticsearch ��Ⱥ�Ĵ��ͨ����һ̨�������ϴ��� 3 �� ES ʵ��������һ������� ES ��Ⱥ��
Elasticsearch/ES
�ٷ���Elasticsearch Reference �ṩ�˲�ͬ�汾���ĵ�����,������!
���Ӣ�ĵIJ��뿴,���ṩ�����İ�� Elasticsearch 2.x: Ȩ��ָ��,�汾�������µ�,�����˽��������Ҳ���а����ġ�
Elasticsearch 7.x ���������� OpenJDK �İ����������Ҫʹ�����Լ����úõ� Java �汾,��Ҫ���� JAVA_HOME �������� ���� �ο�
�ٷ��ĵ� Set up Elasticsearch �и��� OS �İ�װָ��,ҳ�� Installing Elasticsearch ���ṩ�˶��ְ�װ����Ӧ��ָ������!
����ѡ����ɫ��װ���ĵķ�ʽ(tar.gz)��װ��
����ʵ���������,������ͬһ̨������ģ��� 3 ���ڵ�,��װ ES ��Ⱥ��
��װ ES
������
{% note warning %}
����ʹ�� root �û����� es,����ᱨ��:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
{% endnote %}
�����Ҫ�½��û��Ļ��������� sudo adduser es,�� es �û�������:sudo passwd es��
���� ES ��װ��
��װ�����ص�ַ:
- �ٷ�-Past Releases �����������ٶȹ���
- ��Ϊ����վ �����ٶȲ���,�Ƽ�
����IJ���ο� Set up Elasticsearch ? Installing Elasticsearch ? Install Elasticsearch from archive on Linux or MacOS,ѡ��İ�װ���� elasticsearch-7.3.0 �汾��
���ذ�װ��
wget https://mirrors.huaweicloud.com/elasticsearch/7.3.0/elasticsearch-7.3.0-linux-x86_64.tar.gz
wget https://mirrors.huaweicloud.com/elasticsearch/7.3.0/elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
# ��֤��װ����������,���û����,����� OK
shasum -a 512 -c elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-7.3.0-linux-x86_64.tar.gz
# ��Ŀ¼��������,��Ϊ�����ڵ�,�������� ES ��Ⱥʱ,��Ӧ������ ES ʵ��
cp -R elasticsearch-7.3.0 es-7.3.0-node-1
cp -R elasticsearch-7.3.0 es-7.3.0-node-2
mv elasticsearch-7.3.0 es-7.3.0-node-3
# ��Ϊ�� root �û��������� ES
chown -R es es-7.3.0*
{% note info %}
����� Mac ƽ̨,�����ذ� elasticsearch-{version}-darwin-x86_64.tar.gz��
MacOS Catalina �����һ������ ES ʱ,�ᵯ���Ի�����ֹ����,����Ҫ������-����ȫ��˽���������С�Ϊ����ֹ���ָ澯,�����������µ�����:xattr -d -r com.apple.quarantine <$ES_HOME or archive-or-directory>
{% endnote %}
$ES_HOME ��ָ ES �İ�װ�� tar ����ѹ����ļ���Ŀ¼��
��ѹ���Ŀ¼���:
.
������ bin # �����ƽű����Ŀ¼,���� elasticsearch ��ָ������һ�� node,���� elasticsearch-plugin ����װ plugins
������ config # ������ elasticsearch.yml �����ļ�
������ data # �ڵ��Ϸ����ÿ�� index/��Ƭ �������ļ�
������ lib
������ LICENSE.txt
������ logs
������ modules
������ NOTICE.txt
������ plugins # ����ļ���ŵ�λ��
������ README.textile
���� Elasticsearch
����������һ���ڵ�,���� ES ������ʵ��:
./bin/elasticsearch
���Ҫ�� ES ��Ϊ�ػ���������,������������ָ�� -d,ָ�� -p ����,������ ID ��¼�� pid �ļ�:
./bin/elasticsearch -d -p pid
��־�� $ES_HOME/logs Ŀ¼�С�
���Ҫֹͣ ES,�������µ�����:
pkill -F pid
���һ������״̬
curl -X GET "localhost:9200/?pretty"
������������з��� localhost:9200 ������,�᷵��:
{
"name": "node-1",
"cluster_name": "appsearch-7.3.2",
"cluster_uuid": "GlzI_v__QJ2s9ewAgomOqg",
"version": {
"number": "7.3.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "de777fa",
"build_date": "2019-07-24T18:30:11.767338Z",
"build_snapshot": false,
"lucene_version": "8.1.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
���������Զ�˷������ϲ���� ES,��ô,��ʱ���㱾�صĹ������ϻ�����ͨ :9200,��Ҫ�� ES ����������ò��ܷ���,���Ļ���ܡ�
ES �������
�����������õ�������Ҫ������:
Elasticsearch ��Ҫ�����������ļ�:
�����ļ���Ҫλ�� $ES_HOME/config Ŀ¼��,Ҳ����ͨ�� ES_PATH_CONF ������������
YAML ��������ʽ�ο�:
path:
data: /var/lib/elasticsearch
logs: /var/log/elasticsearch
����Ҳ�������·�ʽչƽ:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
JVM ����
JVM �������ÿ���ͨ�� jvm.options �ļ�(�Ƽ���ʽ)���� ES_JAVA_OPTS �����������ġ�
jvm.options �
$ES_HOME/config/jvm.options ��ͨ�� tar or zip ����װ
/etc/elasticsearch/jvm.options ��ͨ�� Debian or RPM packages
����Ҳ������������öѴ�С��
Ĭ�����,ES ���� JVM ʹ��һ����С�����Ϊ 1GB �Ķѡ����ǵ�����������,������þͱȽ���Ҫ��,ȷ�� ES ���㹻�ѿռ���á�
ES ʹ�� Xms(minimum heap size) �� Xmx(maxmimum heap size) ���öѴ�С����Ӧ�ý�������ֵ��Ϊͬ���Ĵ�С��
Xms �� Xmx ���ܴ������������ڴ�� 50%��
���õ�ʾ��:
-Xms2g
-Xmx2g
elasticsearch.yml ����
ES Ĭ�ϻ����λ�� $ES_HOME/config/elasticsearch.yml �������ļ���
��ע:�κ��ܹ�ͨ�������ļ����õ�����,������ͨ��������ʹ�� -E �������ָ��,����:
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1
cluster.name
cluster.name ���ü�Ⱥ���ơ�һ���ڵ�ֻ�ܼ���һ����Ⱥ��,Ĭ�ϵļ�Ⱥ������ elasticsearch��
cluster.name: search-7.3.2
{% note info %}
ȷ���ڵ�ļ�Ⱥ����Ҫ������ȷ,�������ܼ��뵽ͬһ����Ⱥ�С�����ʾ�����Զ����˼�Ⱥ����Ϊ appsearch-7.3.2��
{% endnote %}
node.name
node.name:��������ÿ���ڵ�����ơ������ṩ�ɶ��Ըߵ� ES ʵ������,��Ĭ�������ǻ����� hostname,�����Զ���:
node.name: node-1
ͬһ��Ⱥ�еĽڵ����Ʋ�����ͬ
network.host
network.host:���÷��ʵĵ�ַ��Ĭ�Ͻ����ڻػ���ַ 127.0.0.1 �� [::1]�������Ҫ�������������Ϸ����Լ���̬�������Ⱥ,������Ҫ�趨 ES ���а� Host,�ڵ���Ҫ�ǻػ��ĵ�ַ����������Ϊ�����Ĺ��� IP �� 0.0.0.0:
network.host: 0.0.0.0
������������ÿ����Ķ� Network Settings
http.port
http.port Ĭ�϶˿��� 9200 :
http.port: 9200
{% note warning %}
ע��:����ָ http �˿�,������� REST API �Խ� ES,��ô���Dz��õ� http Э��
{% endnote%}
transport.port
REST �ͻ���ͨ�� HTTP �������͵����� Elasticsearch ��Ⱥ,���ǽ��յ��ͻ�������Ľڵ㲻�����ǵ���������,ͨ�����뽫�䴫�ݸ������ڵ��Խ��н�һ����������ʹ�ô��������(transport networking layer)ִ�д˲�������������ڼ�Ⱥ�нڵ�֮��������ڲ�ͨ��,��Զ�̼�Ⱥ�ڵ������ͨ��,�Լ� Elasticsearch Java API �е� TransportClient��
transport.port �˿ڷ�Χ��Ĭ��Ϊ 9300-9400
transport.port: 9300
��ΪҪ��һ̨�����ϴ��������� ES ʵ��,������ȷָ��ÿ��ʵ���Ķ˿ڡ�
discovery.seed_hosts
discovery.seed_hosts:�������á���������Ҫ�ķ��ֺͼ�Ⱥ�γ�����,�Ա㼯Ⱥ�еĽڵ��ܹ��˴˷��ֲ���ѡ��һ�����ڵ㡣����/Important discovery and cluster formation settings
discovery.seed_hosts �������Ⱥʱ�Ƚ���Ҫ������,����������ǰ�ڵ�ʱ,���������ڵ�ij�ʼ�б���
���伴��,�����κ���������, ES �������õĻ��ص�ַ,����ɨ�豾�ض˿� 9300 - 9305,�Գ������ӵ�ͬһ�����������е������ڵ㡣 �������κ����ü����ṩ�Զ�Ⱥ�������顣
���Ҫ�����������ϵĽڵ���ɼ�Ⱥ,��������� discovery.seed_hosts,�����ṩ��Ⱥ�е����������б�(�����Ƿ��������ʸ�Ҫ���master-eligible���ҿ��ܴ��ڻ״̬���ҿɴ��,�Ա�Ѱַ���ֹ���)��������Ӧ����Ⱥ�������з��������ʸ�Ľڵ�ĵ�ַ���б��� ÿ����ַ������ IP ��ַ,Ҳ������ͨ�� DNS ����Ϊһ������ IP ��ַ��������(hostname)��
��һ���Ѿ��������Ⱥ�Ľڵ�����ʱ,���������֮ǰ��Ⱥ�еĽڵ�ͨ��,�ܿ��ܾͻᱨ������� master not discovered or elected yet, an election requires at least 2 nodes with ids from�����,����һ̨��������ģ������ ES ʵ��ʱ,�����������ȷָ���˶˿ںš�
���ü�Ⱥ��������ַ,����֮��Ⱥ������֮������Զ�����(���Դ��϶˿�,���� 127.0.0.1:9300):
discovery.seed_hosts: [��127.0.0.1:9300��,��127.0.0.1:9301��]
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
������������ [discovery.seed_hosts,discovery.seed_providers,cluster.initial_master_nodes] �е�һ����
cluster.initial_master_nodes
cluster.initial_master_nodes: ��ʼ�ĺ�ѡ master �ڵ��б�����ʼ���ڵ�Ӧͨ���� node.name ��ʶ,Ĭ��Ϊ����������ȷ�� cluster.initial_master_nodes �е�ֵ�� node.name ��ȫƥ�䡣
�״�����ȫ�µ� ES ��Ⱥʱ,�����һ����Ⱥ����/��Ⱥѡ��/cluster bootstrapping����,�ò���ȷ�����ڵ�һ��ѡ���еķ������ڵ��ʸ�Ľڵ㼯�ϡ��ڿ���ģʽ��,���û�н��з�������,�˲����ɽڵ㱾���Զ�ִ�С����������Զ������ӱ����Ͻ��Dz���ȫ��,��˵���������ģʽ�µ�һ������ȫ�µ�Ⱥ��ʱ,�������ʽ�г������ʸ�����ڵ㡣Ҳ����˵,��Ҫʹ�� cluster.initial_master_nodes ���������ø����ڵ��б�������������Ⱥ���½ڵ����ӵ����м�Ⱥʱ,�㲻Ӧʹ�ô�����
���°� 7.x �� ES ��,�� ES �ļ�Ⱥ����ϵͳ���˵���,������ discovery.zen.minimum_master_nodes ������Ƽ�Ⱥ���ѵ�����,ת���ɼ�Ⱥ��������,�����°�������һ���µļ�Ⱥ��ʱ����Ҫ�� cluster.initial_master_nodes ��ʼ����Ⱥ���ڵ��б������һ����Ⱥһ���γ�,�㲻�������ø�������,Ӧ���Ƴ�����������������Ǽ�Ⱥ��һ�δ���ʱ���õ�!��Ⱥ�γ�֮��,�������Ҳ�ᱻ���Ե�!
{% note warning %}cluster.initial_master_nodes �������������Ҫÿ���ڵ����ñ���һ��,���������,������е����ڵ�ر���,���ܻᵼ���������ڵ�Ҳ��رա���Ϊһ���ڵ��ʼ����ʱ�������������,���´�����ʱ���ǻ᳢�Ժ͵���ָ�������ڵ�����,������ʧ��ʱ,�Լ�Ҳ��ر�!
���,Ϊ�˱�֤������,Ԥ�������ڵ�Ľڵ㲻��ÿ�����涼���ø�������!��֤�е����ڵ��ϾͲ����ø�������,�����������ڵ����ʱ,���п��õ����ڵ㲻��һ��ҪȥѰ�ҳ�ʼ�ڵ��е����ڵ�!
{% endnote%}
���� cluster.initial_master_nodes ���Բ鿴��������:
Bootstrapping a cluster
Discovery and cluster formation settings
����
��Ⱥ����Ҫ�����������Ѿ����ܵIJ����,ͬʱҲ������һЩ�ĵ���չ�Ķ���ʵ�ʵ�����������,�������Ḵ�ӵ�,���油��һЩ������Ľ��ܡ���Ҫ˵������,�����һЩ���ü�ʹ������,ES �ļ�ȺҲ���Գɹ������ġ�
Elasticsearch ��Ⱥ�нڵ��ɫ�Ľ��� �������е� node.master ���������˽��ܡ�������ؽ��Ǽ���ʹ��,�����е� node.master/node.data/node.ingest ��������ҲûӰ�졣
������Ⱥʵ���������,������ͬһ̨�����ϴ������� ES ʵ����������Ⱥ,�ֱ���ȷָ������Щʵ���� http.port �� transport.port��discovery.seed_hosts��ȷָ��ʵ���Ķ˿ڶԲ��Լ�Ⱥ�ĸ߿����Ժܹؼ���
����������½ڵ����,�½ڵ�� discovery.seed_hosts û��Ҫ�������еĽڵ�,ֻҪ�����������Ⱥ�����еĽڵ���Ϣ,�½ڵ���ܷ���������Ⱥ�ˡ�
��Ⱥ����Ԥ��
�ֱ����es-7.3.0-node-1��es-7.3.0-node-2 �� es-7.3.0-node-3 ���ļ���,config/elasticsearch.yml ��������:
# es-7.3.0-node-1
cluster.name: search-7.3.2
node.name: node-1
node.master: true
node.data: false
node.ingest: false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
cluster.initial_master_nodes: ["node-1"]
# es-7.3.0-node-2
cluster.name: search-7.3.2
node.name: node-2
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
# es-7.3.0-node-3
cluster.name: search-7.3.2
node.name: node-3
node.master: true
node.data: true
node.ingest: false
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
node-1 �ڵ������һ�� master �ڵ�,������һ�����ݽڵ㡣
�������������,����ͨ������ egrep -v ��#|$�� config/elasticsearch.yml ��������
������ node-1 �ڵ�,��Ϊ�������˳�ʼ���ڵ���б�����ʱ��Ϳ���ʹ�� http://:9200/ ��������ˡ�Ȼ����һ���� node-2 �� node-3��ͨ������ http://127.0.0.1:9200/_cat/nodes �鿴��Ⱥ�Ƿ� OK:
192.168.3.112 25 87 13 4.29 dm - node-3
192.168.3.112 26 87 16 4.29 dm - node-2
192.168.3.112 35 87 16 4.29 m * node-1
http://127.0.0.1:9200/_nodes ������ʾ�ڵ�����������Ϣ
�����ʾ���:

����DZ�ʾ�ýڵ������ڵ�,ԲȦ��ʾ�ýڵ������ݽڵ�
��û�з���,�Ҳ�û�и� node-2 �� node-3 ��ȷָ���˿�,Ϊʲô��һ̨������Ҳ�ɹ��������������ڵ�?
��Ϊ Elasticsearch ��ȡ�� 9200~9299 �����Χ�ڵĶ˿�,��� 9200 ��ռ��,��ѡ�� 9201,�������ơ�
����:��ʵ,����һ���ķ���ģ�ⴴ����Ⱥ(�÷�����δ����,�����ο�)��
�������Ƚ��������е������ڵ�ֹͣ��,Ȼ����� es-7.3.0-node-1 �ļ�����:
mkdir -p data/data{1,2,3}
./bin/elasticsearch -E node.name=node-1 -E cluster.name=appsearch-7.3.2 -E path.data=data/data1 -E path.logs=logs/logs1 -d -p pid1
./bin/elasticsearch -E node.name=node-2 -E cluster.name=appsearch-7.3.2 -E path.data=data/data2 -E path.logs=logs/logs2 -E http.port=9201 -d -p pid2
./bin/elasticsearch -E node.name=node-3 -E cluster.name=appsearch-7.3.2 -E path.data=data/data3 -E path.logs=logs/logs3 -E http.port=9202 -d -p pid3
��װ���
./bin/elasticsearch-plugin install analysis-icu
��������װ��,��������������,�ٰ�װ:
Q1:[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
Q2:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
sudo vim /etc/security/limits.conf
������������
* soft nofile 300000
* hard nofile 300000
* soft nproc 102400
* soft memlock unlimited
* hard memlock unlimited
Q3:master_not_discovered_exception
���ڵ�ָ��������Ҫ��֤����,��ָ���˲����ڵĽڵ�����
�ܽ�
������ͨ�� tar ����ʽ��װ��,��װĿ¼��Լ��С����÷��㡣�� RPM ����װ�Ļ�,����ֱ���� systemctl ������鿴 ES ״̬�����������ȡ�
�ο�
Elasticsearch�����
learnku/Elasticsearch�����ĵ�-7.3�汾 �Ƽ�
ES-CN ����/Elasticsearch ��ȺЭ��ӭ����ʱ�� ���� ES7 �ļ�Ⱥ���ֻ��ƽ��ܽ�Ϊ��ϸ,�Ƽ�
������-CentOS7��ElasticSearch��װ��Ӽ� FAQ �а���
�ELFK��־�ɼ�ϵͳ
���١�Ubuntu � Elasticsearch 6 ��Ⱥ����
ELK �ܹ�֮ Elasticsearch �� Kibana ��װ����
ʹ�� ELK(Elasticsearch + Logstash + Kibana) ���־���з���ƽ̨ʵ��
�ְ��ֽ���,��CentOS�ϰ�װELK,���з�������־�ռ�
���Ļ���Elasticsearch7.X�����ϰ汾,7���°汾ע���ڲ����������ĵ�ʱ����Ҫ����_doc�ֶ�
һ��Rest�����
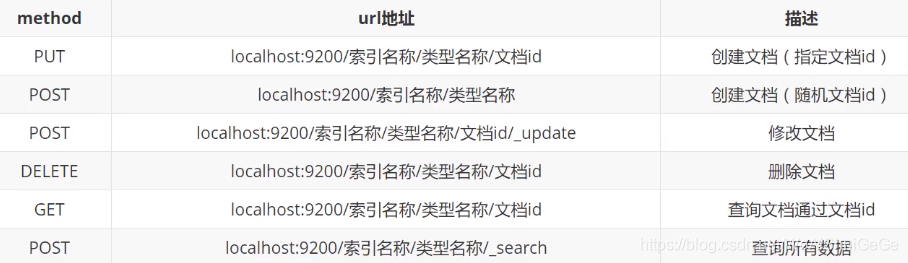
������������
1. ��������
PUT /index_name
{
"settings": {
"number_of_shards":2,
"number_of_replicas":1
},
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "keyword"
},
"age":{
"type": "long"
},
"desc":{
"type": "text"
},
"birthday":{
"type": "date"
}
}
}
}
settings�����кö�,����ֻд�˷�Ƭ����������
2. �������ֶ�
ע:ֻ�������ֶ�,����ɾ���ֶ�
POST /index_name/_mapping
{
"properties": {
"title":{
"type": "text"
}
}
}
3. ɾ������
DELETE /index_name
4. �鿴�����ֶ�����
GET /index_name/_mapping
5. ��������ת��,���������ݸ��Ƶ�������
POST /_reindex
{
"source": {
"index": "index_name_old"
},
"dest": {
"index": "index_name_new",(��ǰ������)
"version_type": "external"
}
}
6. �鿴�����б�-����״̬
GET _cat/health
7. �鿴�����б�-��ϸ��Ϣ
GET _cat/indices?v
8. �鿴ik�ִ����
GET _analyze
{
"analyzer": "ik_smart",
"text": "֧������֧����"
}
9. �鿴ik�ִ�,��ϸ���Ȼ���
GET _analyze
{
"analyzer": "ik_max_word",
"text": "֧������֧����"
}
�����ĵ�����
1. �����ĵ�PUT/POST
����:put�ĵ�����Ҫָ���ĵ�_id;post��ָ��,�ɲ�ָ��,��ָ������������һ��_id
**���1:**���û����ǰ�趨�������ֶ����Ͷ�ֱ�������ĵ�,es����ֶ����ݸ��Զ���������,���ֶλ����ò����ȥmapping��
**���2:**������ӵ������ֶ�����������ǰ�趨�������ֶ�����,�ɳɹ�,�����1������
**���3:**������ӵ������ֶ�����С����ǰ�趨�������ֶ�����,���ɳɹ���
putָ��id
PUT /index_name/_doc/1
{
"id":1001,
"name":"����",
"age":12,
"desc":"�ҵ���������",
"birthday":"2020-02-02"
}
postָ��id
POST /index_name/_doc/3
{
"id":1002,
"name":"����",
"age":12,
"desc":"�ҵ���������",
"birthday":"2020-02-02"
}
post��ָ��id,�Զ���_id
POST /index_name/_doc
{
"id":1003,
"name":"����",
"age":12,
"desc":"�ҵ���������",
"birthday":"2020-02-02"
}
2. ��ѯ�ĵ�
��ѯ�����ĵ�
GET ?/index_name/_search
��ѯָ���ĵ�
GET ?/index_name/_doc/1
3. ���ĵ�
ȫ��:PUT��POST������,ȫ���ֶξ��ᱻ�ĸ���
POST /index_name/_doc/1
{
"id":1005,
"name":"����",
"age":12,
"desc":"�ҵ���������",
"birthday":"2020-02-02"
}
������:POST,ֻ�IJ����ֶ�����
POST /index_name/_doc/1/_update
{
"doc":{
"name":"����"
}
}
4. ɾ���ĵ�
����idɾ��ָ���ĵ�
DELETE /index_name/_doc/1
5.���ָ������ȫ���ĵ�
POST index_name/_delete_by_query
{
"query": {"match_all": {}}
}
���ݲ�ѯ�������������ĵ�
POST index_name/_delete_by_query
{
"query":{
"bool":{
"filter":[
{
"range":{
"birthday":{
"gte":"2020-06-01 00:00:00",
"lt":"2020-07-01 00:00:00"
}
}
}
]
}
}
}
�ġ����Ӳ�ѯ
�������:matchƥ���ѯ��bool���ϲ�ѯ��term��ȷ��ѯ
Լ������:must��must_not��should��filter
1.?matchƥ���ѯ
��������match��desc��ѯ,��Ϊdesc��text���Ϳ��Խ��зִʲ�ѯ;name��keyword���ִ�,��֧�ִַʲ�ѯ��
ʵ��,����IJ�ѯ������ѯ��desc�а���"%��%" �� ��%��%�� �� "%��%"���ĵ���
ע:��������һ����,�ᱻ�ִ������ֿ�,�ۡ����������������ܲ�ܶ�,ȷʵ,��������match��ѯtext,��������
GET /index_name/_search
{
"query":{
"match":{
"desc":"���� ��"
}
}
}
2. bool���ϲ�ѯ,ͨ������must,should,must_not,filter
(1)must��must_not ������ѯ,��������,����mysql��and���÷�
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"desc":"�� ��"
}
},
{
"match": {
"age": 12
}
}
]
}
}
}
(2)should ������ѯ,��Ҫ����,�����ǻ��ߵĹ�ϵ,����mysql��or���÷�
GET /index_name/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"desc":"�� ��"
}
},
{
"match": {
"age": 12
}
}
]
}
}
}
(3)filter ���˲�ѯ
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"desc":"�� ��"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lt": 13
}
}
}
]
}
}
}
3. term��ȷ��ѯ: ͨ�������������о�ȷ����,�õ����
��matchԭ�����ȷ����ĵ�,ͨ���ִ������н���,Ȼ����ȥ�ĵ��в�ѯ��
��termֱ�ӽ��о�ȷ��ѯ,term�Ǵ�����ȫƥ��,Ҳ���Ǿ�ȷ��ѯ,����ǰ�����ٶ������ʽ��зִʲ�⡣
��match_phrase��������,Ҫ�����еķִʱ���ͬʱ�������ĵ���,ͬʱλ�ñ������һ�¡�
(1)��ѯ
GET /index_name/_search
{
"query": {
"term": {
"desc":"��"
}
}
}
(2)���������ϲ�ѯ
ע:term����ִʲ�ѯ,ֻ�Ǿ�ȷ��ѯ!!!����Ҫ������ ��С���� ���ĵ�
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"term": {
"desc": "��"
}
},
{
"term": {
"age": 11
}
}
]
}
}
}
terms��ʾ����������,�ô����� [ ] ������������,������MySql��in����
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"terms": {
"age": [
10,11,12
]
}
}
]
}
}
}
����
GET /index_name/_search
{
"query":{
"bool":{
"must": [
{
"terms": {
"desc": [
"��","��"
]
}
}
]
}
}
}
���ػ��,���Ҳ���õ��϶��
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"desc":"��"
}
},
{
"terms":{
"age":[
10,
11,
12
]
}
}
]
}
}
}
must��must_not���,����������������term ��?match�����IJ�ͬ����
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"name":"����"
}
}
],
"must_not":[
{
"term":{
"age":"10"
}
},
{
"match":{
"desc":"����"
}
}
]
}
}
}
����ע��must��should���е����:must��should������ֱ�Ӳ���,must��must_not����ֱ�Ӳ���
����,Ҫ�������С�������,����Ϊ12����߳�������Ϊ2020-02-03�ĸ�����Ϣ,һ��Ҫע���ˡ�
�ͺñ�: name=���� && age=15 || birthday=2020-02-03���ִ���һ��,���Dz��Եġ������ƺ�˵�Ĺ�ȥ,�����Ͻ�����ѧ�Ͽɲ���,���Ҿ�����mysql��Ҳ��������ôд,��Ϊand���ȼ�����or,����ִ��and��������,����mysql�п��Խ�����������,����Ϊ?where name=��������?and (age=12 or birthday=��2020-02-03��)��
�����д��: �����ǰ�age��birthday������should����,elasticsearchҲ���ϡ�
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"����"
}
}
],
"should":[
{
"match":{
"age":"12"
}
},
{
"match":{
"birthday":"2020-02-03"
}
}
]
}
}
}
��ȷ������:(name=���� && age=15) || (name=���� &&birthday=2020-02-03),
��ȷ��д��:�ȶ�should�ֳ����,�ٸ�ÿһ���������mustԼ��
GET /index_name/_search
{
"query":{
"bool":{
"should":[
{
"bool":{
"must":[
{
"term":{
"name":"����"
}
},
{
"term":{
"age":12
}
}
]
}
},
{
"bool":{
"must":[
{
"term":{
"name":"����"
}
},
{
"term":{
"birthday":"2020-02-03"
}
}
]
}
}
]
}
}
}
4. �ۺϲ�ѯcollapse��aggs,���ظ����ݽ����۵�(ȥ��)
GET /index_name/_search
{
"query":{
"bool":{
"must":[
{
"term":{
"moduleAttr":6424
}
},
{
"terms":{
"sortId":[1,72,101]
}
}
],
"filter":[
{
"range":{
"pubTime":{
"gte":"2020-07-11 09:13:04"
}
}
}
]
}
},
"sort":[
{
"pubTime":{
"order":"desc"
}
}
],
"collapse":{
"field":"contentId"
},
"size":20
}
����
GET index_name/_search
{
"query":{
"bool":{
"must":{
"terms":{
"websiteId":[
2141391797
]
}
},
"filter":{
"range":{
"pubTime":{
"gte":"2020-04-20 00:00:00",
"lte":"2020-07-31 23:59:59"
}
}
}
}
},
"aggs": {
"my_name(�Զ�������)": {
"terms": {
"field": "contentId"
}
}
},
"size":10
}
5. ������ѯ
Ĭ�ϸ�����ʽ��ѯ
GET /index_name/_search
{
"query":{
"match":{
"desc":"��������"
}
},
"highlight": {
"fields": {
"desc": {}
}
}
}
�Զ����������
GET /index_name/_search
{
"query":{
"match":{
"desc":"��������"
}
},
"highlight": {
"pre_tags": "<p style='color:red'>" ,
"post_tags": "</p>",
"fields": {
"desc": {}
}
}
}
6. ���˵�������ò�ѯɸѡ����:
���ϵ���,�ֱ���ֻ��ʾ��Ҫ���ص��ֶΡ���ѯ�������������ҳ��0ҳ��ʼsizeΪ2
GET /index_name/_search
{
"_source":{
"includes":[
"name",
"age",
"desc"
]
},
"query":{
"match":{
"name":"����"
}
},
"sort":[
{
"age":{
"order":"desc"
}
}
],
"from": 0,
"size": 2
}
�塢����������/ɾ��
1. ������_update_by_query
��desc�к��С�����������,desc��Ϊ����3�µ����ҽ��ܡ���
POST /index_name/_update_by_query
{
"script":{
"source":"ctx._source['desc']='��3�µ����ҽ���'"
},
"query":{
"bool":{
"must":[
{
"term":{
"desc":"��"
}
}
]
}
}
}
2. ����ɾ��_delete_by_query
��desc�к��С�3��������ɾ��
POST /index_name/_delete_by_query
{
"query":{
"bool":{
"must":[
{
"term":{
"desc":"3"
}
}
]
}
}
}
3.�����������
POST /index_name/_delete_by_query
{
"query": {"match_all": {}}
}
����Elasticsearch Painless Script
��������,��Elasticsearch 5.x ����Painless,ʹ��Elasticsearchӵ���˰�ȫ���ɿ��������ܽű��Ľ��������
����˵����֧��ͨ��Painless�ű����Եķ�ʽ,��es���в�ѯ���ġ�ɾ���Ȳ���,Ϊes�ṩ�˸�ǿ���һ�ֲ�����ʽ��
docֻ������_search�з��ʵ���������IJ���,ʹ�õ���ctx��
https://blog.csdn.net/u013613428/article/details/78134170#%E6%89%B9%E9%87%8F%E6%9B%B4%E6%96%B0
1. ������
POST /index_name/_update_by_query
{
"script":{
"lang":"painless",
"source":"ctx._source.title=params.newTitile",
"params":{
"newTitile":"��Ϊ�µ�titile"
}
},
"query":{
"bool":{
"filter":[
{
"range":{
"crawlTime":{
"gte":"2020-09-01 00:00:00",
"lt":"2020-09-03 00:00:00"
}
}
}
]
}
}
}
������title,��titile�����һ�䡰��һ������
POST /index_name/_update_by_query
{
"script":{
"lang":"painless",
"source":"ctx._source.title= ctx._source.title+'��һ����'"
},
"query":{
"bool":{
"filter":[
{
"range":{
"crawlTime":{
"gte":"2020-09-01 00:00:00",
"lt":"2020-09-03 00:00:00"
}
}
}
]
}
}
}
����������Ҳ����������,���ݹ����ĵ�,����replace��keyword�ֶ�,������,��֪����û�д�����Խ��͵ġ�
�ߡ���Ⱥ����
1. �鿴��Ⱥ�Ļ�������״̬
GET /_cat/health?v
2. �鿴��Ⱥ��ϸ״̬
GET _cluster/health?pretty
3. �鿴��Ⱥ�����еķ�Ƭ
GET /_cat/shards
**?4. �鿴��Ⱥ���нڵ�**
GET /_cat/nodes?v
5. �鿴��Ⱥ���нڵ���ϸ��Ϣ
GET _nodes/process?pretty
�ˡ��������ڹ���
��������Ҳ������kibana�п��ӻ�����
1. ������������
#(�Զ���������������article_ilm_policy)
PUT /_ilm/policy/article_ilm_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_docs":"50000000"
}
}
},
"warm":{
"min_age":"15d",
"actions":{
"allocate":{
"include":{
"box_type":"warm"
},
"number_of_replicas":0
},
"forcemerge":{
"max_num_segments":1
}
}
},
"cold":{
"min_age":"30d",
"actions":{
"allocate":{
"include":{
"box_type":"cold"
}
}
}
},
"delete":{
"min_age":"60d",
"actions":{
"delete":{
}
}
}
}
}
}
2. �鿴��������
GET /_ilm/policy/article_ilm_policy
3. ɾ����������
DELETE /_ilm/policy/article_ilm_policy
4. ����rollover����
POST index_name/_rollover/
{
"conditions": {
"max_docs": 1000,
"max_age": "7d",
"max_size": "5gb"
}
}
�š�����ģ�����
����ģ��Ҳ������kibana�п��ӻ�����
1. �鿴��ǰ����ģ��
GET _template
2. �鿴ָ��ģ�����
GET _template/article_ilm_template
3. ����ģ��,
��Ȼģ����settings����������Щ��������,����ָ���ִ���analysis����������,����Ϊ���������á�
//�趨����ģ��
PUT /_template/article_ilm_template
{
"index_patterns":[
"article*"(����ƥ�����,����articleΪǰ�������Դ�ģ�崴��,���Ҫд��,Ϲд����д�����������������Ҳ���ģ��)
],
"aliases": {
"article": {}(�涨�������ı���,������bug,���д�������������,�����������������rollover_alias�ظ���ͻ,����rolloverʧ��,���鲻д�������,��һ�����������ֶ���������)
},
"settings":{
"number_of_shards":9,(����Ƭ��)
"number_of_replicas":1,(������)
"index.lifecycle.name":"article_ilm_policy",(�涨��������ĸ���������)
"index.lifecycle.rollover_alias":"article",(�涨rollover��������)
"index.routing.allocation.include.box_type":"hot",(�����з����������������� Shard ���������䵽 Hot Nodes �ڵ���)
},
"mappings":{
"properties":{
"title":{
"type":"text"
}
}
}
}
4.?����
//д��Ͷ�ȡ,���Ǹ��ݹ�ͬ�ı���article���е�,���DZ���һ��
//���ñ���,����������ԵĻ�,������ѯ����article-test����
//��������д��д��"is_write_index":true ,������д������,��Ⱥֻ�ܹ涨һ��д�������
//��������,ָ������
PUT article-test(��Ҫ�ĵ�����)
{
"aliases":{
"article(����)":{
"is_write_index":true
}
}
}
//��һ��д��,�ı���,ָ������:
POST /_aliases
{
"actions":[
{
"add":{
"index":"article-test",(��Ҫ�ĵ�����)
"alias":"article",(����)
"is_write_index":true
}
}
]
}
5.·������
·�ɾ�����η����ĵ��������ڵ�,Ĭ��·�����ĵ���_id,ͨ����_id�㷨ȡ�ౣ֤ƽ��ɢ�����ݡ�
shard_num = hash(_routing) % num_primary_shards
���������ܾ�֮ǰ����1��ǰ������,�Ǿ�Ҫ��1��ǰʱ�俪ʼ��ѯ���нڵ������������,��ʵҲûë��,�����Ĵ�
��ʱ�������·�ɽ����Ż�,�趨·�ɲ���,��ͬ���ĵ����ǩһ��,��������ͬ·�ɵ��ĵ����䵽ͬһ�ڵ�,��ѯ/����Щ�ĵ���ʱ��Ҳ����·�ɲ���ȥ��,����ֻ�鲿�ֽڵ����ݾ��ܻ�ȡ��Ҫ�����ݡ�
�����÷�,��ʱ�����ײ�д,�ȸ�лճһƪ����
https://blog.csdn.net/u010454030/article/details/73554652
�����Ҿ���������������,����ģ��������·�ɱ��������,����mapping����·������,�������д���ĵ�������,����
routing_missing_exception
��ģ�������ȥ��,���������������