Spark On Yarn环境部署测试(使用伪分布)
一、前提工作
- 安装了Hadoop伪分布,可以参考:Hadoop2.7.3环境搭建之伪分布式
- 安装spark伪分布,可参考:Spark Standalone单机模式环境搭建
二、配置Spark On Yarn
-
修改yarn-site.xml,添加如下信息
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> -
将spark的历史服务的日志目录重新指定到HDFS下:
1)在HDFS创建spark历史服务日志history目录即可,执行:
hdfs dfs -mkdir -p /training/spark-2.4.8-bin-hadoop2.7/history -
修改spark-env.sh,改成如下内容:
export JAVA_HOME=/training/jdk1.8.0_171 # 改成你自己的主机名称 export SPARK_MASTER_HOST=niit-master export SPARK_MASTER_PORT=7077 #history 配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history" # yarn YARN_CONF_DIR=/training/hadoop-2.7.3/etc/hadoop注意:
spark.history.fs.logDirectory路径改成hdfs上的路径,即hdfs://niit-master:9000/training/spark-2.4.8-bin-hadoop2.7/history -
修改spark-defaults.conf,改成如下内容:
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/history注意:
spark.eventLog.dir路径改成HDFS上的history路径,即hdfs://hadoop001:9000/training/spark-2.4.8-bin-hadoop2.7/history -
重启下Hadoop集群(如前面已经启动了spark就不需要启动spark)
1)首先检查下hadoop是否已经启动过了,如是,则需要先停止,执行:stop-all.sh
2)重启或者启动Hadoop,执行:start-all.sh -
启动spark历史服务(如前面已经启动了spark就不需要启动spark)
进入到spark的安装目录下,启动spark历史服务,执行:sbin/start-history-server.sh
三、运行Spark Pi案例
-
进入spark的安装目录下,执行如下命令提交程序到spark集群:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.8.jar 100 -
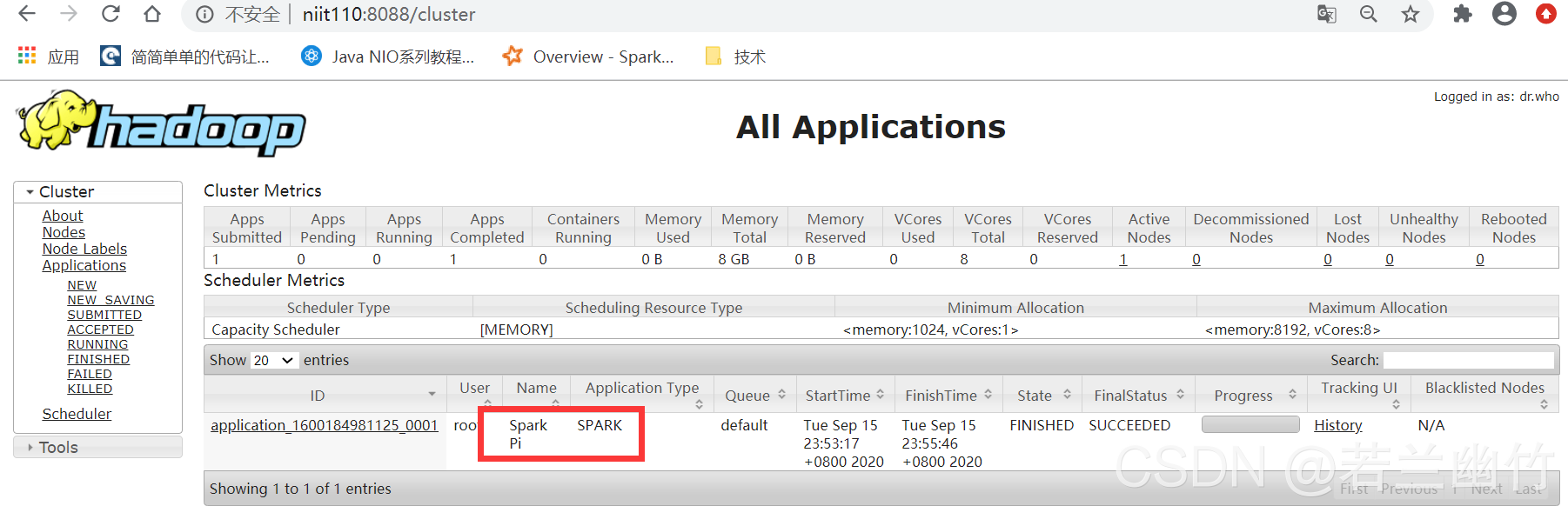
查看实验结果一: 可以在YARN的Web管理界面中看到有spark程序
-
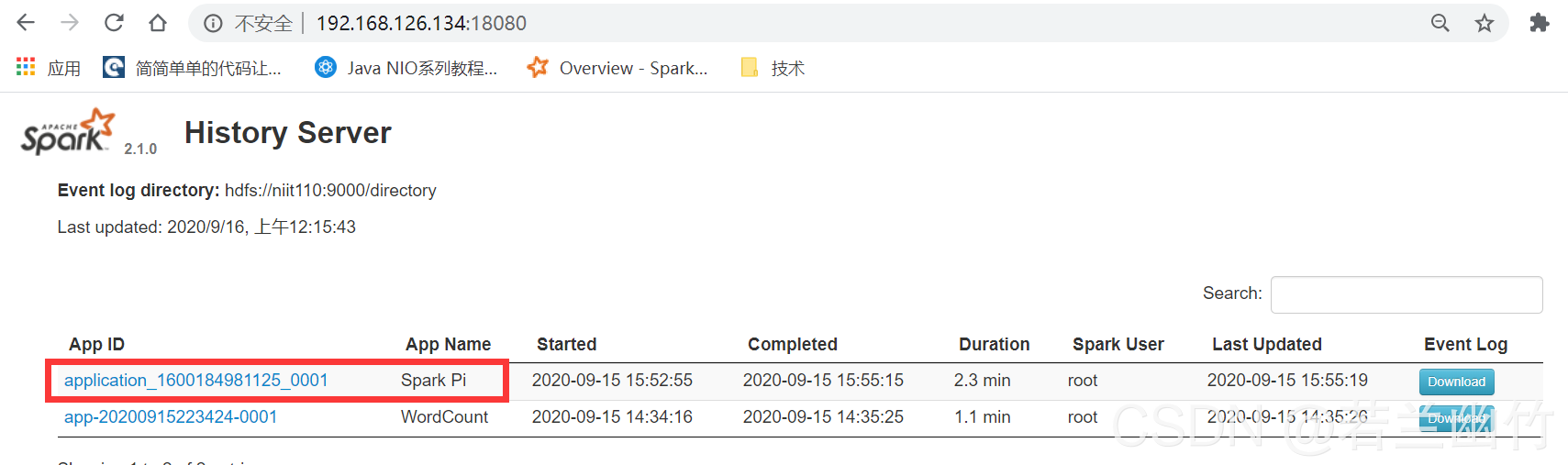
查看实验结果二:在Spark的历史服务Web界面中会看到如下信息: