���ƪ����MySQL��֪�ػ�:https://blog.csdn.net/jankin6/article/details/119540143
����Ŀ¼
- ��1��Hive����
- ��2��Hive��װ
- ��3��Hive��������
- ��4��DDL���ݶ���
- ��5��DML���ݲ���
- ��6��:����
��1��Hive����
1.1 ʲô��Hive
Hive:��Facebook��Դ������������ṹ����־������ͳ�ơ�
Hive�ǻ���Hadoop��һ�����ݲֿ�����,���Խ��ṹ���������ļ�ӳ��Ϊһ�ű�,���ṩ��SQL��ѯ���ܡ�
������:��HQLת����MapReduce����
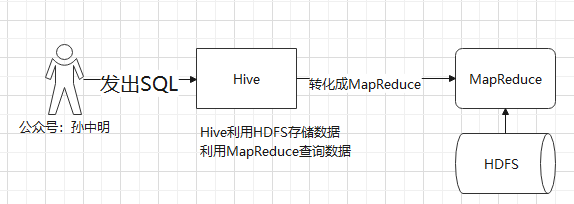
1)Hive���������ݴ洢��HDFS
2)Hive�������ݵײ��ʵ����MapReduce
3)ִ�г���������Yarn��
1.2 Hive����ȱ��
1.2.1 �ŵ�
-
�����ӿڲ�����SQL�,�ṩ���ٿ���������(����������)��
-
������ȥдMapReduce,���ٿ�����Ա��ѧϰ�ɱ���
-
Hive��ִ���ӳٱȽϸ�,���Hive���������ݷ���,��ʵʱ��Ҫ�ߵij��ϡ�
-
Hive�������ڴ���������,���ڴ���С����û������,��ΪHive��ִ���ӳٱȽϸߡ�
-
Hive֧���û��Զ�������,�û����Ը����Լ���������ʵ���Լ��ĺ�����
1.2.2 ȱ��
1.Hive��HQL������������
(1)����ʽ�㷨������
(2)�����ھ��治�ó�
2.Hive��Ч�ʱȽϵ�
(1)Hive�Զ����ɵ�MapReduce��ҵ,ͨ������²������ܻ�
(2)Hive���űȽ�����,���Ƚϴ�
1.3 Hive�ܹ�ԭ��
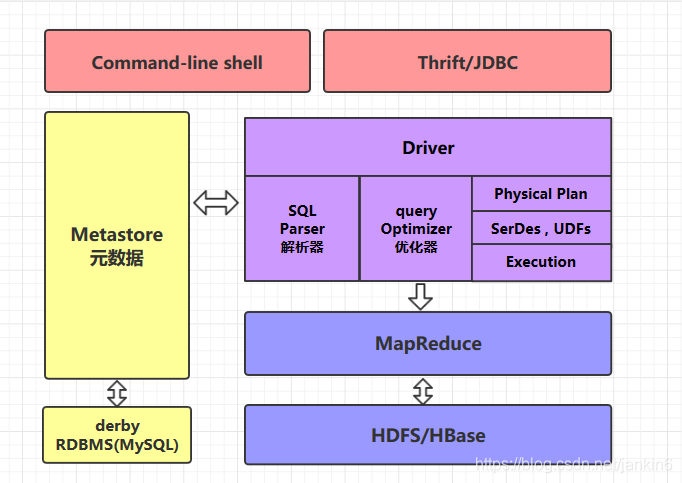
1.�û��ӿ�:Client
- CLI(hive shell)��
- JDBC/ODBC(java����hive)��driver url username password��
- WEBUI(���������hive)
2.Ԫ����:Metastore
Ԫ���ݰ���:�����������������ݿ�(Ĭ����default)������ӵ���ߡ���/�����ֶΡ���������(�Ƿ����ⲿ��)��������������Ŀ¼��;
Ĭ�ϴ洢���Դ���derby���ݿ���,�Ƽ�ʹ��MySQL�洢Metastore
3.Hadoop
ʹ��HDFS���д洢,ʹ��MapReduce���м��㡣
4.������:Driver���ص㡿
(1)������(SQL Parser):��SQL�ַ���ת���ɳ������AST,��һ��һ�㶼�õ��������߿����,����antlr;��AST���������,������Ƿ���ڡ��ֶ��Ƿ���ڡ�SQL�����Ƿ�����
(2)������(Physical Plan):��AST����������ִ�мƻ���
(3)�Ż���(Query Optimizer):����ִ�мƻ������Ż���
(4)ִ����(Execution):����ִ�мƻ�ת���ɿ������е������ƻ�������Hive��˵,����MR/Spark��
Hive ��ִ��һ�� HQL ��ʱ��,�ᾭ�����²���:
- �����:Antlr ���� SQL �������,��� SQL �ʷ�,�����,�� SQL ת��Ϊ���� ��� AST Tree;
- �������:���� AST Tree,�������ѯ�Ļ�����ɵ�Ԫ QueryBlock;
- ������ִ�мƻ�:���� QueryBlock,����Ϊִ�в����� OperatorTree;
- �Ż���ִ�мƻ�:�����Ż������� OperatorTree �任,�ϲ�����Ҫ�� ReduceSinkOperator,���� shuffle ������;
- ��������ִ�мƻ�:���� OperatorTree,����Ϊ MapReduce ����;
- �Ż�����ִ�мƻ�:�������Ż������� MapReduce ����ı任,�������յ�ִ�мƻ���
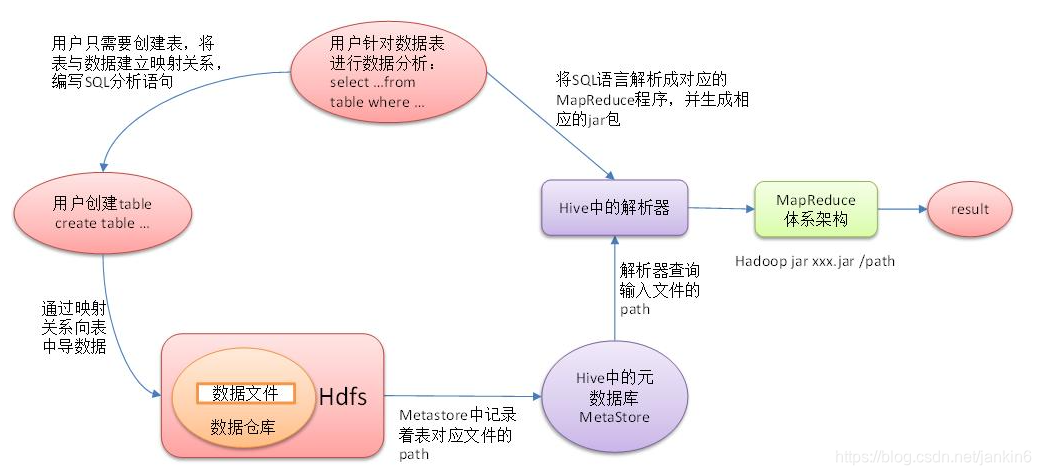
Hiveͨ�����û��ṩ��һϵ�н����ӿ�,���յ��û���ָ��(SQL),ʹ���Լ���Driver,���Ԫ����(MetaStore),����Щָ����MapReduce,�ύ��Hadoop��ִ��,���,��ִ�з��صĽ��������û������ӿڡ�
1.4 Hive�����ݿ�Ƚ�
���� Hive ����������SQL �IJ�ѯ���� HQL(Hive Query Language),��˺����� Hive ����Ϊ���ݿ⡣��ʵ�ӽṹ������,Hive �����ݿ����ӵ�����ƵIJ�ѯ����,��������֮�������Ľ��Ӷ������������ Hive �����ݿ�IJ��졣���ݿ�������� Online ��Ӧ����,����Hive ��Ϊ���ݲֿ����Ƶ�,�����һ��,�����ڴ�Ӧ�ýǶ����� Hive �����ԡ�
| ���� | Hive | MySQL |
|---|---|---|
| ��ѯ���� | ��SQL�IJ�ѯ����HQL | SQL |
| ���ݴ洢λ�� | �洢�� HDFS �� | ���豸���߱����ļ�ϵͳ�� |
| ���ݸ��� | ���ݲֿ�������Ƕ���д�ٵġ� ���,Hive�в���������ݵĸ�д | ���ݿ��е�����ͨ������Ҫ���������ĵ�, INSERT INTO �� VALUES �� UPDATE �� SET�����ݡ� |
| ���� | û�ж������е�ijЩKey��������,����ɨ���������� MapReduce ������, Hive ���Բ��з�������,��˼�ʹû������, | ���ݿ���,ͨ�������һ���������н�������, ��˶����������ض����������ݵķ���, ���ݿ�����кܸߵ�Ч��,�ϵ͵��ӳ١� �������ݵķ����ӳٽϸ�,������ Hive ���ʺ��������ݲ�ѯ�� |
| ִ�� | MapReduce | ִ������innodb |
| ִ���ӳ� | Hive �ڲ�ѯ���ݵ�ʱ��,����û������ ��Ҫɨ��������,����ӳٽϸߡ� | ��Ե�,���ݿ��ִ���ӳٽϵ͡� |
| ����չ�� | 666 ����������Hadoop ��Ⱥ�� Yahoo!,2009��Ĺ�ģ��4000 ̨�ڵ����� | �����ݿ����� ACID ������ϸ�����, ��չ�зdz����ޡ� Ŀǰ���Ƚ��IJ������ݿ� Oracle �������ϵ���չ����Ҳֻ��100̨���ҡ� |
| ���ݹ�ģ | �� | С |
��2��Hive��װ
2.1Hive��װ��ַ
1.Hive������ַ
http://hive.apache.org/
2.�ĵ��鿴��ַ
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3.���ص�ַ
http://archive.apache.org/dist/hive/
4.github��ַ
https://github.com/apache/hive
2.2 Hive��װ����
1.Hive��װ������
(1)��apache-hive-1.2.1-bin.tar.gz�ϴ���linux��/opt/softwareĿ¼��
(2)��ѹapache-hive-1.2.1-bin.tar.gz��/opt/module/Ŀ¼����
[root@locahost software]$ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
(3)��apache-hive-1.2.1-bin.tar.gz������Ϊhive
[root@locahost module]$ mv apache-hive-1.2.1-bin/ hive
(4)��/opt/module/hive/confĿ¼�µ�hive-env.sh.template����Ϊhive-env.sh
[root@locahost conf]$ mv hive-env.sh.template hive-env.sh
(5)����hive-env.sh�ļ�
(a)����HADOOP_HOME·��
export HADOOP_HOME=/opt/module/hadoop-2.7.2
(b)����HIVE_CONF_DIR·��
export HIVE_CONF_DIR=/opt/module/hive/conf
2.Hadoop��Ⱥ����
(1)��������hdfs��yarn
[root@locahost hadoop-2.7.2]$sbin/start-dfs.sh
[root@locahost hadoop-2.7.2]$sbin/start-yarn.sh
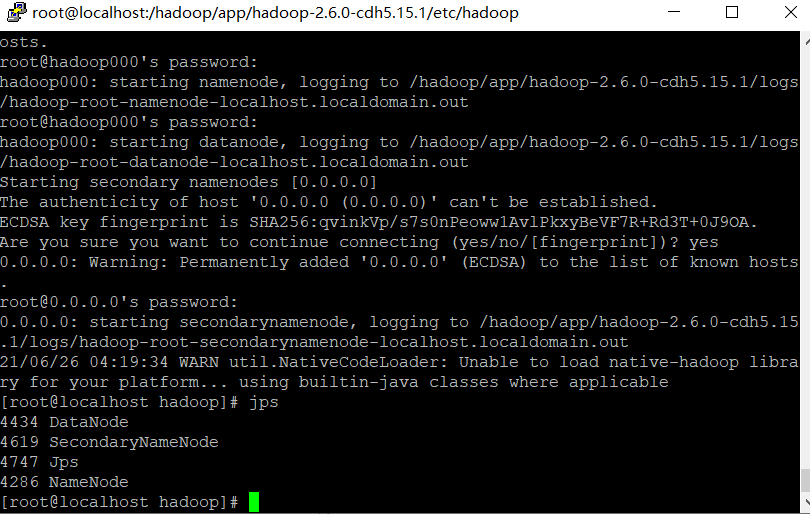
(2)��HDFS�ϴ���/tmp��/user/hive/warehouse����Ŀ¼�������ǵ�ͬ��Ȩ��д
[root@locahost hadoop-2.7.2]$ bin/hadoop fs -mkdir /tmp
[root@locahost hadoop-2.7.2]$ bin/hadoop fs -mkdir -p /user/hive/warehouse
[root@locahost hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /tmp
[root@locahost hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /user/hive/warehouse
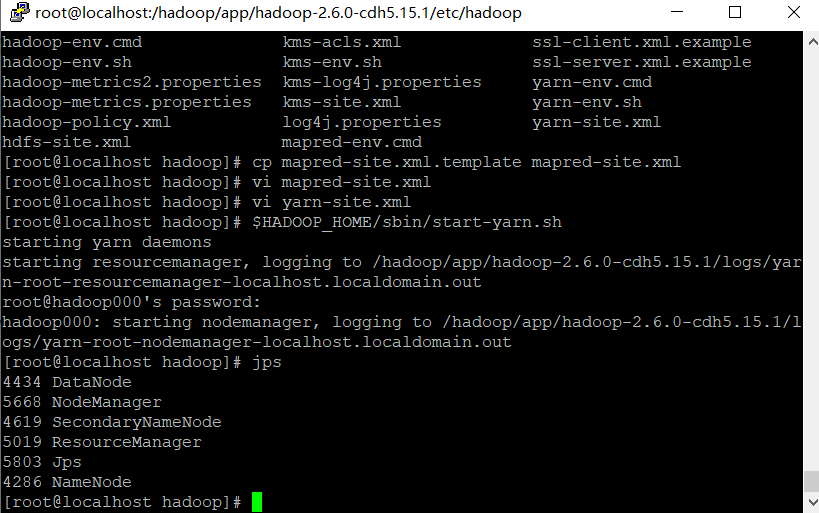
3.Hive��������
(1)����hive
[root@locahost hive]$ bin/hive
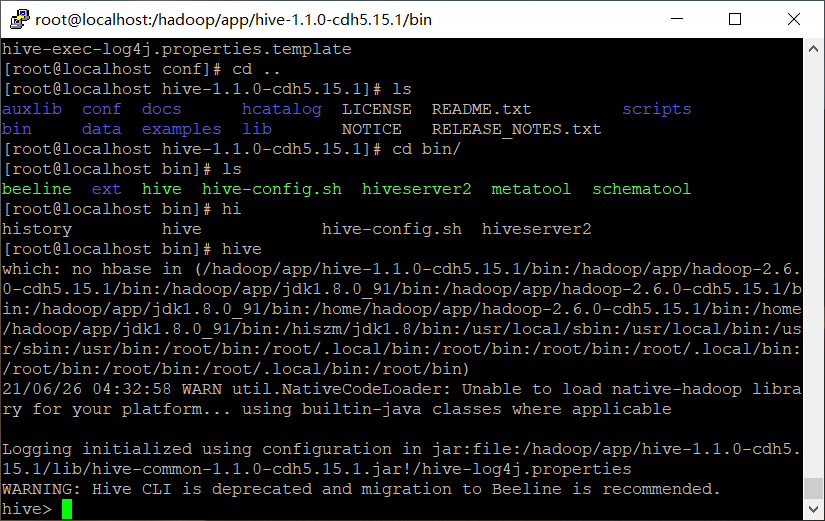
(2)�鿴���ݿ�
hive> show databases;
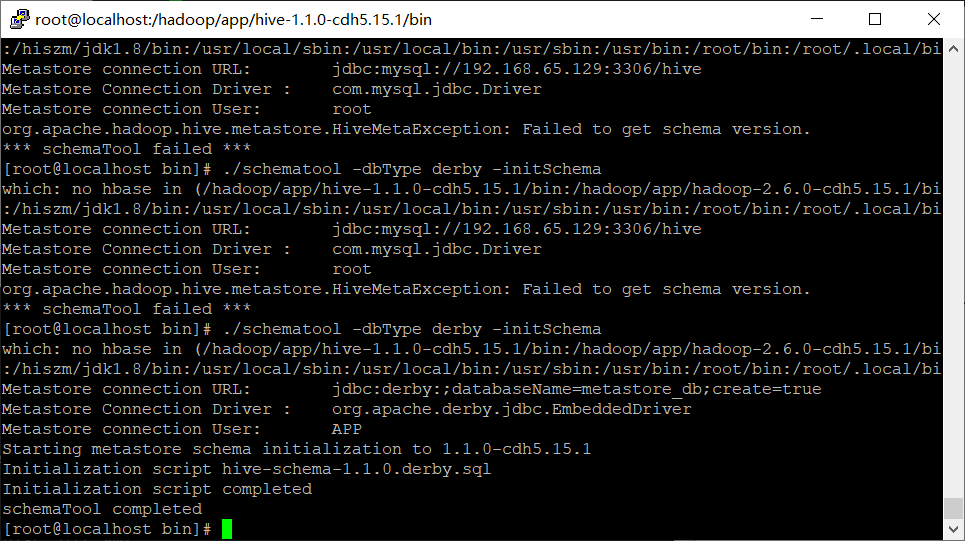
./schematool -dbType derby -initSchem
hive> show databases;
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
====
��ʼ�����ݿ⼴��
====
[root@localhost bin]# ./schematool -dbType derby -initSchema
which: no hbase in (/hadoop/app/hive-1.1.0-cdh5.15.1/bin:/hadoop/app/hadoop-2.6.0-cdh5.15.1/bi:/hiszm/jdk1.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/.local/bi
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 1.1.0-cdh5.15.1
Initialization script hive-schema-1.1.0.derby.sql
Initialization script completed
schemaTool completed
(3)��Ĭ�����ݿ�
hive> use default;
(4)��ʾdefault���ݿ��еı�
hive> show tables;
(5)����һ�ű�
hive> create table student(id int, name string);
(6)��ʾ���ݿ����м��ű�
hive> show tables;
(7)�鿴���Ľṹ
hive> desc student;
(8)����������
hive> insert into student values(1000,��ss��);
(9)��ѯ��������
hive> select * from student;
(10)�˳�hive
hive> quit;
schemaTool completed
[root@localhost bin]# hive
which: no hbase in (/hadoop/app/hive-1.1.0-cdh5.15.1/bin:/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin:/hadoop/app/jdk1.8.0_91/bin:/hiszm/jdk1.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/.local/bin:/root/bin)
21/06/26 05:19:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Logging initialized using configuration in jar:file:/hadoop/app/hive-1.1.0-cdh5.15.1/lib/hive-common-1.1.0-cdh5.15.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> show databases;
OK
default
Time taken: 3.22 seconds, Fetched: 1 row(s)
hive> use default
> ;
OK
Time taken: 0.043 seconds
hive> show tables;
OK
Time taken: 0.041 seconds
hive> create table student(id int, name string);
OK
Time taken: 0.326 seconds
hive> show tables;
OK
student
Time taken: 0.018 seconds, Fetched: 1 row(s)
hive> desc student;
OK
id int
name string
Time taken: 0.119 seconds, Fetched: 2 row(s)
hive> insert into student values(1000,"ss");
Query ID = root_20210626072828_6d53bcd2-305b-4c7a-950e-3185ef9d1b73
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1624695917121_0001, Tracking URL = http://localhost:8088/proxy/application_1624695917121_0001/
Kill Command = /hadoop/app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1624695917121_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2021-06-26 07:28:51,889 Stage-1 map = 0%, reduce = 0%
2021-06-26 07:28:57,038 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.21 sec
MapReduce Total cumulative CPU time: 2 seconds 210 msec
Ended Job = job_1624695917121_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop000:8020/user/hive/warehouse/student/.hive-staging_hive_2021-06-26_07-28-44_192_2202570064323571586-1/-ext-10000
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=1, totalSize=8, rawDataSize=7]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.21 sec HDFS Read: 3737 HDFS Write: 79 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 210 msec
OK
Time taken: 14.075 seconds
hive> select * from student;
OK
1000 ss
Time taken: 0.038 seconds, Fetched: 1 row(s)
hive>
2.3 �������ļ�����Hive����
����
������/opt/module/datas/student.txt���Ŀ¼�µ����ݵ��뵽hive��student(id int, name string)���С�
1.������
��/opt/module/datas���Ŀ¼��������
(1)��/opt/module/Ŀ¼�´���datas
[root@locahost module]$ mkdir datas
(2)��/opt/module/datas/Ŀ¼�´���student.txt�ļ�����������
[root@locahost datas]$ touch student.txt
[root@locahost datas]$ vi student.txt
1001 zhangshan
1002 lishi
1003 zhaoliu
ע����tab�������
2.Hiveʵ�ʲ���
(1)����hive
[root@locahost hive]$ bin/hive
(2)��ʾ���ݿ�
hive> show databases;
(3)ʹ��default���ݿ�
hive> use default;
(4)��ʾdefault���ݿ��еı�
hive> show tables;
(5)ɾ���Ѵ�����student��
hive> drop table student;
(6)����student��, �������ļ��ָ�����\t��
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
(7)����/opt/module/datas/student.txt �ļ���student���ݿ���С�
hive> load data local inpath '/opt/module/datas/student.txt' into table student;
(8)Hive��ѯ���
hive> select * from student;
OK
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.266 seconds, Fetched: 3 row(s)
3.����������
����һ���ͻ��˴�������hive,�����java.sql.SQLException�쳣��
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException:
Unable to instantiate
org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
? at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
? at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
? at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
? at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
? at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
? at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
? at java.lang.reflect.Method.invoke(Method.java:606)
? at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
? at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
? at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523)
? at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)
? at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132)
? at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
? at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
? at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024)
? at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503)
... 8 more
ԭ����,MetastoreĬ�ϴ洢���Դ���derby���ݿ���,�Ƽ�ʹ��MySQL�洢Metastore;
2.4 MySql��װ
2.4.1 ��װ����
1.�鿴mysql�Ƿ�װ,�����װ��,ж��mysql
? (1)�鿴
[root@locahost ����]# rpm -qa|grep mysql
mysql-libs-5.1.73-7.el6.x86_64
? (2)�
[root@locahost ����]# rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
2.��ѹmysql-libs.zip�ļ�����ǰĿ¼
[root@locahost software]# unzip mysql-libs.zip
[root@locahost software]# ls
mysql-libs.zip
mysql-libs
3.���뵽mysql-libs�ļ�����
[root@locahost mysql-libs]# ll
������ 76048
-rw-r�Cr--. 1 root root 18509960 3�� 26 2015 MySQL-client-5.6.24-1.el6.x86_64.rpm
-rw-r�Cr--. 1 root root 3575135 12�� 1 2013 mysql-connector-java-5.1.27.tar.gz
-rw-r�Cr--. 1 root root 55782196 3�� 26 2015 MySQL-server-5.6.24-1.el6.x86_64.rpm
2.4.2 ��װMySql������
1.��װmysql�����
[root@locahost mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
2.�鿴�������������
[root@locahost mysql-libs]# cat /root/.mysql_secret
OEXaQuS8IWkG19Xs YLxnB8x8fC7txIm6
3.�鿴mysql״̬
[root@locahost mysql-libs]# service mysql status
4.����mysql
[root@locahost mysql-libs]# service mysql start
2.4.3 ��װMySql�ͻ���
1.��װmysql�ͻ���
[root@locahost mysql-libs]# rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
2.����mysql
[root@locahost mysql-libs]# mysql -uroot -pOEXaQuS8IWkG19Xs
3.������
mysql>SET PASSWORD=PASSWORD(��000000��);
4.�˳�mysql
mysql>exit
2.4.4 MySql��user������������
����ֻҪ��root�û�+����,���κ������϶��ܵ�¼MySQL���ݿ⡣
1.����mysql
[root@locahost mysql-libs]# mysql -uroot -p000000
2.��ʾ���ݿ�
mysql>show databases;
3.ʹ��mysql���ݿ�
mysql>use mysql;
4.չʾmysql���ݿ��е����б�
mysql>show tables;
5.չʾuser���Ľṹ
mysql>desc user;
6.��ѯuser��
mysql>select User, Host, Password from user;
7.��user��,��Host��������Ϊ%
mysql>update user set host=��%�� where host=��localhost��;
8.ɾ��root�û�������host
mysql>delete from user where Host=��locahost��;
mysql>delete from user where Host=��127.0.0.1��;
mysql>delete from user where Host=��::1��;
9.ˢ��
mysql>flush privileges;
10.�˳�
mysql>quit;
2.5 HiveԪ�������õ�MySql
2.5.1 ��������
1.��/opt/software/mysql-libsĿ¼�½�ѹmysql-connector-java-5.1.27.tar.gz������
[root@locahost mysql-libs]# tar -zxvf mysql-connector-java-5.1.27.tar.gz
2.����/opt/software/mysql-libs/mysql-connector-java-5.1.27Ŀ¼�µ�mysql-connector-java-5.1.27-bin.jar��/opt/module/hive/lib/
[root@locahost mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar
/opt/module/hive/lib/
2.5.2 ����Metastore��MySql
1.��/opt/module/hive/confĿ¼�´���һ��hive-site.xml
[root@locahost conf]$ touch hive-site.xml
[root@locahost conf]$ vi hive-site.xml
2.���ݹٷ��ĵ����ò���,�������ݵ�hive-site.xml�ļ���
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description></property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value><description>password to use against metastore database</description></property></configuration>
3.������Ϻ�,�������hive�쳣,�������������������(������,����������hadoop��Ⱥ)
2.5.3 �ര������Hive����
1.������MySQL
[root@locahost mysql-libs]$ mysql -uroot -p000000
�鿴�м������ݿ�
mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || test |+--------------------+
2.�ٴδ������,�ֱ�����hive
��ʼ������Դ
schematool -initSchema -dbTyper mysql -verbose
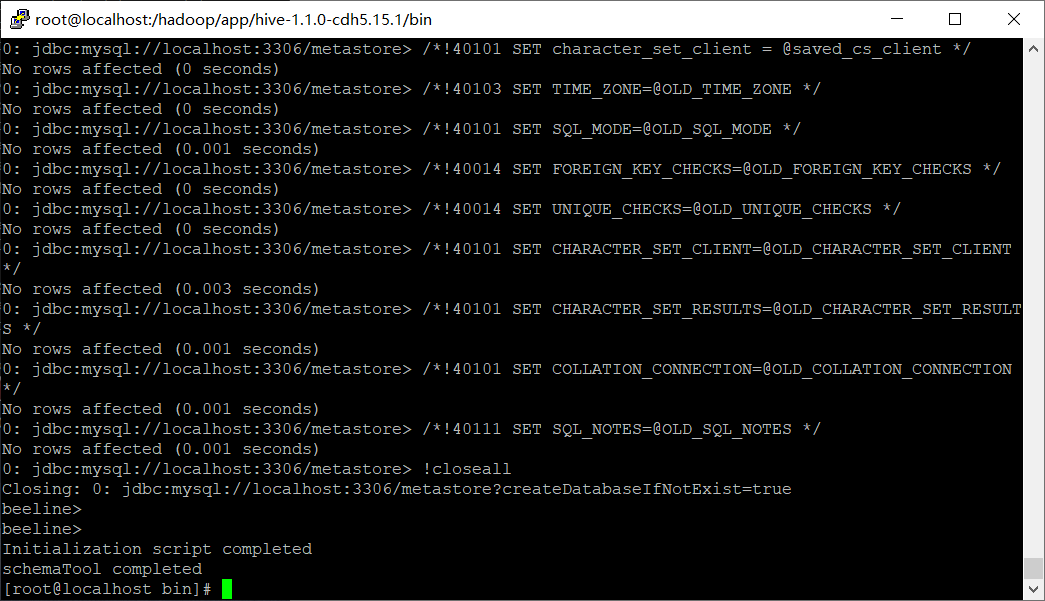
[root@locahost hive]$ bin/hive
3.����hive��,�ص�MySQL���ڲ鿴���ݿ�,��ʾ������metastore���ݿ�
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+--------------------+
[root@localhost conf]# cat hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
</property>
<!-- ����hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
</configuration>
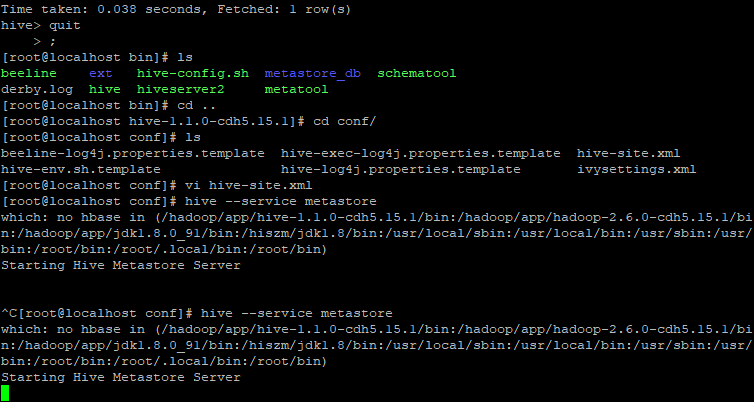
[root@localhost conf]# hive --service metastore
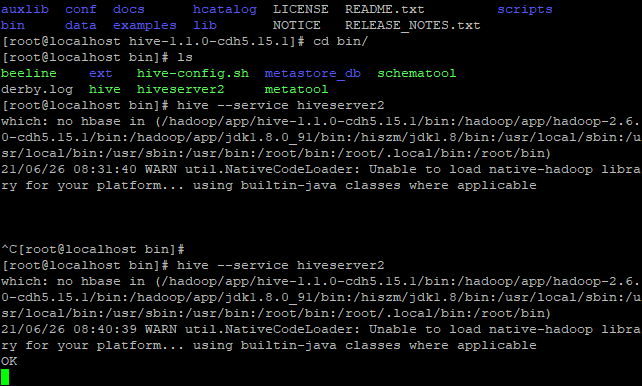
[root@localhost conf]# hive --service hiveserver2
[root@localhost bin]# touch hiveservices.sh
[root@localhost bin]# vi hiveservices.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#�������Ƿ���������,���� 1 Ϊ������,���� 2 Ϊ���̶˿�
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print
$2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -
d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1
&"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe ����������"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 ����������"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore �������"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 �������"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore ��������
����" || echo "Metastore ���������쳣"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 ������
������" || echo "HiveServer2 ���������쳣"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
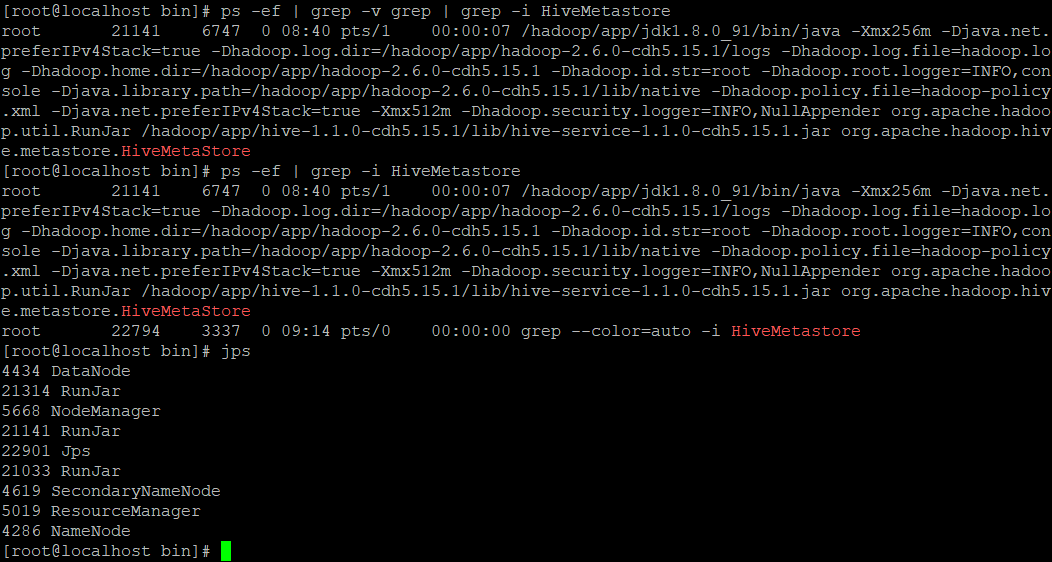
[root@localhost bin]# ps -ef | grep -v grep | grep -i HiveMetastoreroot 21141 6747 0 08:40 pts/1 00:00:07 /hadoop/app/jdk1.8.0_91/bin/java -Xmx256m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/hadoop/app/hadoop-2.6.0-cdh5.15.1 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/hadoop/app/hadoop-2.6.0-cdh5.15.1/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Xmx512m -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /hadoop/app/hive-1.1.0-cdh5.15.1/lib/hive-service-1.1.0-cdh5.15.1.jar org.apache.hadoop.hive.metastore.HiveMetaStore[root@localhost bin]# ps -ef | grep -i HiveMetastoreroot 21141 6747 0 08:40 pts/1 00:00:07 /hadoop/app/jdk1.8.0_91/bin/java -Xmx256m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/hadoop/app/hadoop-2.6.0-cdh5.15.1 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/hadoop/app/hadoop-2.6.0-cdh5.15.1/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Xmx512m -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /hadoop/app/hive-1.1.0-cdh5.15.1/lib/hive-service-1.1.0-cdh5.15.1.jar org.apache.hadoop.hive.metastore.HiveMetaStoreroot 22794 3337 0 09:14 pts/0 00:00:00 grep --color=auto -i HiveMetastore[root@localhost bin]#[root@localhost bin]# ps -ef | grep -v grep | grep -i HiveMetastore | awk '{print $2}'21141
2.6HiveJDBC����
����hiveserver2����
[root@localhost hive-1.1.0-cdh5.15.1]# tail -f -n 200 /tmp/root/hive.log
[root@localhost conf]# hive --service metastore
[root@locahost hive]$ bin/hiveserver2
[root@localhost conf]# hive --service hiveserver2
��Ҫ
����beeline
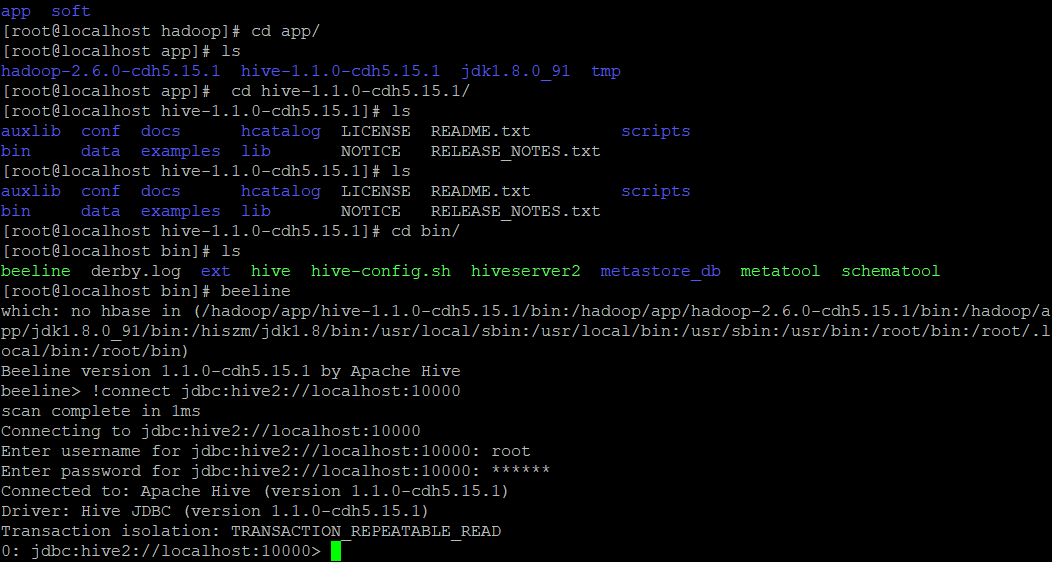
[root@locahost hive]$ bin/beeline jdbc:hive2://loaclhost:10000
����hiveserver
beeline> !connect jdbc:hive2://loaclhost:10000(�س�)Connecting to jdbc:hive2://locahost:10000Enter username for jdbc:hive2://locahost:10000: root(�س�)Enter password for jdbc:hive2://locahost:10000: (ֱ�ӻس�)Connected to: Apache Hive (version 1.2.1)Driver: Hive JDBC (version 1.2.1)Transaction isolation: TRANSACTION_REPEATABLE_READ0: jdbc:hive2://locahost:10000> show databases;+----------------+--+| database_name |+----------------+--+| default || hive_db2 |+----------------+--+
2.7 Hive���ý�������
[root@hadoop202 hive]$ nohup hive --service metastore 2>&1 &
[root@hadoop202 hive]$ nohup hive --service hiveserver2 2>&1 &
[root@localhost bin]# hive -help
which: no hbase in (/hadoop/app/hive-1.1.0-cdh5.15.1/bin:/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin:/hadoop/app/jdk1.8.0_91/bin:/hiszm/jdk1.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/.local/bin:/root/bin)
21/06/26 21:14:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
1.��-e��������hive�Ľ�������ִ��sql���
[root@locahost hive]$ bin/hive -e ��select id from student;��
2.��-f��ִ�нű���sql���
- ��/opt/module/datasĿ¼�´���hivef.sql�ļ�
[root@locahost datas]$ touch hivef.sql
�ļ���д����ȷ��sql���
select *from student;
- ִ���ļ��е�sql���
[root@locahost hive]$ bin/hive -f /opt/module/datas/hivef.sql
- ִ���ļ��е�sql��䲢�����д���ļ���
[root@locahost hive]$ bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt
2.8 Hive�����������
1.�˳�hive����:
hive(default)>exit;hive(default)>quit;
���°��hive��û������,����ǰ�İ汾���е�:
exit:�������ύ����,���˳�;
quit:���ύ����,�˳�;
2.��hive cli���������β鿴hdfs�ļ�ϵͳ
hive(default)>dfs -ls /;
3.��hive cli���������β鿴�����ļ�ϵͳ
hive(default)>! ls /opt/module/datas;
4.�鿴��hive�������������ʷ����
? (1)���뵽��ǰ�û��ĸ�Ŀ¼/root��/home/root
? (2)�鿴. hivehistory�ļ�
[root@locahost ~]$ cat .hivehistory
2.9Hive������������
2.9.1 Hive���ݲֿ�λ������
? 1)Default���ݲֿ����ԭʼλ������hdfs�ϵ�:/user/hive/warehouse·���¡�
? 2)�ڲֿ�Ŀ¼��,û�ж�Ĭ�ϵ����ݿ�default�����ļ��С����ij�ű�����default���ݿ�,ֱ�������ݲֿ�Ŀ¼�´���һ���ļ��С�
? 3)��default���ݲֿ�ԭʼλ��(��hive-default.xml.template����������Ϣ������hive-site.xml�ļ���)��
<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property>
����ͬ���û���ִ��Ȩ��
bin/hdfs dfs -chmod g+w /user/hive/warehouse
2.9.2 ��ѯ����Ϣ��ʾ����
1)��hive-site.xml�ļ�����������������Ϣ,�Ϳ���ʵ����ʾ��ǰ���ݿ�,�Լ���ѯ����ͷ��Ϣ���á�
<property> <name>hive.cli.print.header</name> <value>true</value></property><property> <name>hive.cli.print.current.db</name> <value>true</value></property>
? 2)��������hive,�Ա�����ǰ����졣
[root@localhost conf]# vi hive-site.xml[root@localhost conf]# ../bin/hivewhich: no hbase in (/hadoop/app/hive-1.1.0-cdh5.15.1/bin:/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin:/hadoop/app/jdk1.8.0_91/bin:/hiszm/jdk1.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/.local/bin:/root/bin)21/06/26 21:30:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableLogging initialized using configuration in jar:file:/hadoop/app/hive-1.1.0-cdh5.15.1/lib/hive-common-1.1.0-cdh5.15.1.jar!/hive-log4j.propertiesWARNING: Hive CLI is deprecated and migration to Beeline is recommended.hive (default)>====================================֮ǰ==============================hive >======================================================================hive (default)> select * from student;OKstudent.id student.name1000 ss1000 ssTime taken: 0.047 seconds, Fetched: 2 row(s)hive (default====================================֮ǰ==============================hive > select * from student;OK1000 ss1000 ssTime taken: 0.047 seconds, Fetched: 2 row(s)======================================================================
2.9.3 Hive������־��Ϣ���á������Ե�û��Ҫ
[root@localhost tmp]# ls /tmp/root/dc5329d8-11c0-49ff-87f8-d76e83801e75 hive.logdc5329d8-11c0-49ff-87f8-d76e83801e752257204420012449420.pipeout operation_logsdc5329d8-11c0-49ff-87f8-d76e83801e753902258702291924058.pipeout[root@localhost tmp]# tail /tmp/root/hive.log2021-06-26 08:45:08,764 INFO [HiveServer2-Background-Pool: Thread-41]: ql.Driver (Driver.java:execute(1658)) - Executing command(queryId=root_20210626084545_674ddfa4-27e7-41a7-a6c7-bf25cea5b0c5): show databases2021-06-26 08:45:08,770 INFO [HiveServer2-Background-Pool: Thread-41]: ql.Driver (Driver.java:launchTask(2052)) - Starting task [Stage-0:DDL] in serial mode2021-06-26 08:45:08,816 INFO [HiveServer2-Background-Pool: Thread-41]: ql.Driver (Driver.java:execute(1960)) - Completed executing command(queryId=root_20210626084545_674ddfa4-27e7-41a7-a6c7-bf25cea5b0c5); Time taken: 0.052 seconds2021-06-26 08:45:08,816 INFO [HiveServer2-Background-Pool: Thread-41]: ql.Driver (SessionState.java:printInfo(1087)) - OK2021-06-26 09:38:35,711 WARN [pool-4-thread-1]: util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2021-06-26 09:38:38,790 INFO [main]: session.SessionState (SessionState.java:createPath(703)) - Created local directory: /tmp/dc5329d8-11c0-49ff-87f8-d76e83801e75_resources2021-06-26 09:38:38,802 INFO [main]: session.SessionState (SessionState.java:createPath(703)) - Created HDFS directory: /tmp/hive/root/dc5329d8-11c0-49ff-87f8-d76e83801e752021-06-26 09:38:38,806 INFO [main]: session.SessionState (SessionState.java:createPath(703)) - Created local directory: /tmp/root/dc5329d8-11c0-49ff-87f8-d76e83801e752021-06-26 09:38:38,808 INFO [main]: session.SessionState (SessionState.java:createPath(703)) - Created HDFS directory: /tmp/hive/root/dc5329d8-11c0-49ff-87f8-d76e83801e75/_tmp_space.db2021-06-26 09:38:38,809 INFO [main]: session.SessionState (SessionState.java:start(587)) - No Tez session required at this point. hive.execution.engine=mr.[root@localhost tmp]#
1.Hive��logĬ�ϴ����/tmp/root/hive.logĿ¼��(��ǰ�û�����)
2.��hive��log�����־��/opt/module/hive/logs
- ��/opt/module/hive/conf/hive-log4j.properties.template�ļ�����Ϊ
hive-log4j.properties[root@locahost conf]$ pwd/opt/module/hive/conf[root@locahost conf]$ mv hive-log4j.properties.template hive-log4j.properties
- ��hive-log4j.properties�ļ�����log���λ��
hive.log.dir=/opt/module/hive/logs
2.9.4 �������÷�ʽ
1.�鿴��ǰ���е�������Ϣ
hive>set;
2.�������������ַ�ʽ
- (1)�����ļ���ʽ
Ĭ�������ļ�:hive-default.xml
�û��Զ��������ļ�:hive-site.xml
ע��:�û��Զ������ûḲ��Ĭ�����á�
����,HiveҲ�����Hadoop������,��ΪHive����ΪHadoop�Ŀͻ���������,Hive�����ûḲ��Hadoop�����á�
�����ļ����趨�Ա�������������Hive���̶���Ч��
- (2)�����в�����ʽ
hive-default.xml ���������
����Hiveʱ,����������������-hiveconf param=value���趨������
����:
[root@locahost hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;# ע��:���Ա���hive������Ч# �鿴��������:hive (default)> set mapred.reduce.tasks;
- (3)����������ʽ
������HQL��ʹ��SET�ؼ����趨����
����:
hive (default)> set mapred.reduce.tasks=100;# ע��:���Ա���hive������Ч��# �鿴��������hive (default)> set mapred.reduce.tasks;
���������趨��ʽ�����ȼ����ε������������ļ�<�����в���<����������ע��ijЩϵͳ���IJ���,����log4j��ص��趨,������ǰ���ַ�ʽ�趨,��Ϊ��Щ�����Ķ�ȡ�ڻỰ������ǰ�Ѿ�����ˡ�
count ��ִ��MR����
��3��Hive��������
3.1 ������������
��6-1
| Hive�������� | Java�������� | ���� | ���� |
|---|---|---|---|
| TINYINT | byte | 1byte������� | 20 |
| SMALINT | short | 2byte������� | 20 |
| INT | int | 4byte������� | 20 |
| BIGINT | long | 8byte������� | 20 |
| BOOLEAN | boolean | ��������,true����false | TRUE FALSE |
| FLOAT | float | �����ȸ����� | 3.14159 |
| DOUBLE | double | ˫���ȸ����� | 3.14159 |
| STRING | string | �ַ�ϵ�С�����ָ���ַ���������ʹ�õ����Ż���˫���š� | ��now is the time�� ��for all good men�� |
| TIMESTAMP | ʱ������ | ||
| BINARY | �ֽ����� |
����Hive��String�����൱�����ݿ��varchar����,��������һ���ɱ���ַ���,����������������������ܴ洢���ٸ��ַ�,�����������Դ洢2GB���ַ�����
3.2 ������������
��6-2
| �������� | ���� | �ʾ�� |
|---|---|---|
| STRUCT | ��c�����е�struct����,������ͨ�����㡱���ŷ���Ԫ�����ݡ�����,���ij���е�����������STRUCT{first STRING, last STRING},��ô��1��Ԫ�ؿ���ͨ���ֶ�.first�����á� | struct() |
| MAP | MAP��һ���-ֵ��Ԫ�鼯��,ʹ�������ʾ�����Է������ݡ�����,���ij���е�����������MAP,���м�->ֵ���ǡ�first��->��John���͡�last��->��Doe��,��ô����ͨ���ֶ���[��last��]��ȡ���һ��Ԫ�� | map() |
| ARRAY | ������һ�������ͬ���ͺ����Ƶı����ļ��ϡ���Щ������Ϊ�����Ԫ��,ÿ������Ԫ�ض���һ�����,��Ŵ��㿪ʼ������,����ֵΪ[��John��, ��Doe��],��ô��2��Ԫ�ؿ���ͨ��������[1]�������á� | Array() |
Hive�����ָ�����������ARRAY��MAP �� STRUCT��ARRAY��MAP��Java�е�Array��Map����,��STRUCT��C�����е�Struct����,����װ��һ�������ֶμ���,���������������������ε�Ƕ�ס�
����ʵ��
1) ����ij��������һ��,������JSON��ʽ����ʾ�����ݽṹ����Hive�·��ʵĸ�ʽΪ
{
"name": "songsong",
//�б�Array,
"friends": [
"bingbing" ,
"lili"
] ,
"children": {
//��ֵMap,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": {
//�ṹStruct,
"street": "hui long guan" ,
"city": "beijing"
}
}
2)�����������ݽṹ,������Hive�ﴴ����Ӧ�ı�,���������ݡ�
�������ز����ļ�test.txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijingyangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
ע��:MAP,STRUCT��ARRAY���Ԫ�ؼ��ϵ��������ͬһ���ַ���ʾ,�����á�_����
3)Hive�ϴ������Ա�test
create table test(name string, friends array<string>, children map<string,int>, address struct<street:string,city:string>) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';
�ֶν���:
row format delimited fields terminated by ',' -- �зָ���collection items terminated by '_' --MAP STRUCT �� ARRAY �ķָ���(���ݷָ����)map keys terminated by ':' -- MAP�е�key��value�ķָ���lines terminated by '\n'; -- �зָ���
[root@localhost ~]# mkdir -p /user/hive/warehouse
4)�����ı����ݵ����Ա�
hive (default)> load data local inpath ��/opt/module/datas/test.txt�� into table tes
5)�������ּ������������,���·ֱ���ARRAY,MAP,STRUCT�ķ��ʷ�ʽ
hive (default)> select friends[1],children['xiao song'],address.city from testwhere name="songsong";OK_c0 _c1 citylili 18 beijingTime taken: 0.076 seconds, Fetched: 1 row(s)
hive (default)> > create table test(name string, > friends array<string>, > children map<string,int>, > address struct<street:string,city:string>) > row format delimited > fields terminated by ',' > collection items terminated by '_' > map keys terminated by ':' > lines terminated by '\n';OKTime taken: 0.738 secondshive (default)> load data local inpath '/hadoop/data/text.txt' into table test;Loading data to table default.testTable default.test stats: [numFiles=1, totalSize=144]OKTime taken: 0.446 secondshive (default)> show tables;OKtab_namestudenttestTime taken: 0.021 seconds, Fetched: 2 row(s)hive (default)> desc test;OKcol_name data_type commentname stringfriends array<string>children map<string,int>address struct<street:string,city:string>Time taken: 0.067 seconds, Fetched: 4 row(s)hive (default)> select * from test;OKtest.name test.friends test.children test.addresssongsong ["bingbing","lili"] {"xiao song":18,"xiaoxiao song":19} {"street":"hui long guan","city":"beijing"}yangyang ["caicai","susu"] {"xiao yang":18,"xiaoxiao yang":19} {"street":"chao yang","city":"beijing"}Time taken: 0.155 seconds, Fetched: 2 row(s)hive (default)>
3.3 ����ת��
Hive��ԭ�����������ǿ��Խ�����ʽת����,������Java������ת��,����ij����ʽʹ��INT����,TINYINT���Զ�ת��ΪINT����,����Hive������з���ת��,����,ij����ʽʹ��TINYINT����,INT�����Զ�ת��ΪTINYINT����,���᷵�ش���,����ʹ��CAST������
1.��ʽ����ת����������
(1)�κ��������Ͷ�������ʽ��ת��Ϊһ����Χ���������,��TINYINT����ת����INT,INT����ת����BIGINT��
(2)�����������͡�FLOAT��STRING���Ͷ�������ʽ��ת����DOUBLE��
(3)TINYINT��SMALLINT��INT������ת��ΪFLOAT��
(4)BOOLEAN���Ͳ�����ת��Ϊ�κ����������͡�
2.����ʹ��CAST������ʾ������������ת��
����CAST(��1�� AS INT)�����ַ�����1�� ת��������1;���ǿ������ת��ʧ��,��ִ��CAST(��X�� AS INT),����ʽ���ؿ�ֵ NULL��
��4��DDL���ݶ���
���ݿ�ģʽ��������DDL(Data Definition Language),�������������ݿ���Ҫ�洢����ʵ����ʵ������ԡ�
4.1 �������ݿ�
1)����һ�����ݿ�,���ݿ���HDFS�ϵ�Ĭ�ϴ洢·����/user/hive/warehouse/*.db��
[root@localhost data]# hadoop fs -ls /user/hive/warehouse/21/06/26 22:59:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for you r platform... using builtin-java classes where applicableFound 5 itemsdrwxrwxrwx - root supergroup 0 2021-06-26 22:59 /user/hive/warehouse/db_hive.dbdrwxr-xr-x - root supergroup 0 2021-06-26 21:33 /user/hive/warehouse/studentdrwxrwxrwx - root supergroup 0 2021-06-26 22:57 /user/hive/warehouse/test-rw-r--r-- 1 root supergroup 144 2021-06-26 22:34 /user/hive/warehouse/test3-rw-r--r-- 1 root supergroup 144 2021-06-26 22:30 /user/hive/warehouse/text.txt[root@localhost data]#
hive (default)> create database db_hive;
2)����Ҫ���������ݿ��Ѿ����ڴ���,����if not exists�жϡ�(��д��)
hive (default)> create database db_hive;FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already existshive (default)> create database if not exists db_hive;
3)����һ�����ݿ�,ָ�����ݿ���HDFS�ϴ�ŵ�λ��
hive (default)> create database db_hive2 location '/db_hive2.db';

4.2 ��ѯ���ݿ�
4.2.1 ��ʾ���ݿ�
1.��ʾ���ݿ�
hive> show databases;
2.������ʾ��ѯ�����ݿ�
hive> show databases like 'db_hive*';OKdb_hivedb_hive_1
4.2.2 �鿴���ݿ�����
-- ��ʾ���ݿ���Ϣhive> desc database db_hive;OKdb_hive hdfs://locahost:9000/user/hive/warehouse/db_hive.db atguiguUSER -- ��ʾ���ݿ���ϸ��Ϣ,extendedhive> desc database extended db_hive;OKdb_hive hdfs://locahost:9000/user/hive/warehouse/db_hive.db root USER -- �л���ǰ���ݿ�hive (default)> use db_hive;
4.3.3 �л���ǰ���ݿ�
hive (default)> use db_hive;
4.3 �����ݿ�
�û�����ʹ��ALTER DATABASE����Ϊij�����ݿ��DBPROPERTIES���ü�-ֵ������ֵ,������������ݿ��������Ϣ�����ݿ������Ԫ������Ϣ���Dz��ɸ��ĵ�,�������ݿ��������ݿ����ڵ�Ŀ¼λ�á�
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');-- ��hive�в鿴�Ľ��hive> desc database extended db_hive;db_name comment location owner_name owner_type parametersdb_hive hdfs://locahost:8020/user/hive/warehouse/db_hive.db root USER {createtime=20170830}
4.4 ɾ�����ݿ�
-- ɾ�������ݿ�hive>drop database db_hive2;-- ���ɾ�������ݿⲻ����,��ò��� if exists�ж����ݿ��Ƿ����hive> drop database db_hive;FAILED: SemanticException [Error 10072]: Database does not exist: db_hivehive> drop database if exists db_hive2;-- ������ݿⲻΪ��,���Բ���cascade����,ǿ��ɾ��hive> drop database db_hive;FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)hive> drop database db_hive cascade;
4.5 �����������ص�
1.�����
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
2.�ֶν���˵��
(1)CREATE TABLE����һ��ָ�����ֵı��������ͬ���ֵı��Ѿ�����,���׳��쳣;�û������� IF NOT EXISTS ѡ������������쳣��
(2)EXTERNAL�ؼ��ֿ������û�����һ���ⲿ��,�ڽ�����ͬʱָ��һ��ָ��ʵ�����ݵ�·��(LOCATION),Hive�����ڲ���ʱ,�Ὣ�����ƶ������ݲֿ�ָ���·��;�������ⲿ��,����¼�������ڵ�·��,�������ݵ�λ�����κθı䡣��ɾ������ʱ��,�ڲ�����Ԫ���ݺ����ݻᱻһ��ɾ��,���ⲿ��ֻɾ��Ԫ����,��ɾ�����ݡ�
(3)COMMENT:Ϊ����������ע�͡�
(4)PARTITIONED BY����������
(5)CLUSTERED BY������Ͱ��
(6)SORTED BY������
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
�û��ڽ�����ʱ������Զ���SerDe����ʹ���Դ���SerDe�����û��ָ��ROW FORMAT ����ROW FORMAT DELIMITED,����ʹ���Դ���SerDe���ڽ�����ʱ��,�û�����ҪΪ��ָ����,�û���ָ�������е�ͬʱҲ��ָ���Զ����SerDe,Hiveͨ��SerDeȷ�����ľ�����е����ݡ�
SerDe��Serialize/Deserilize�ļ��,Ŀ�����������л��ͷ����л���
(8)STORED ASָ���洢�ļ�����
���õĴ洢�ļ�����:
SEQUENCEFILE(�����������ļ�)��
TEXTFILE(�ı�)��
RCFILE(��ʽ�洢��ʽ�ļ�)
����ļ������Ǵ��ı�,����ʹ��STORED AS TEXTFILE��
���������Ҫѹ��,ʹ�� STORED AS SEQUENCEFILE��
(9)LOCATION:ָ������HDFS�ϵĴ洢λ����
(10)LIKE�����û��������еı��ṹ,���Dz��������ݡ�
4.5.1 �����������ڲ���
Ĭ�ϴ����ı�������ν�Ĺ�����,��ʱҲ����Ϊ�ڲ�����
��Ϊ���ֱ�,Hive��(�����ٵ�)���������ݵ��������ڡ�HiveĬ������»Ὣ��Щ�������ݴ洢����������hive.metastore.warehouse.dir(����,/user/hive/warehouse)�������Ŀ¼����Ŀ¼�¡�
������ɾ��һ��������ʱ,HiveҲ��ɾ������������ݡ����������ʺϺ��������߹������ݡ�
-- ��ͨ������create table if not exists student2(id int, name string)row format delimited fields terminated by '\t'stored as textfile location '/user/hive/warehouse/student2';-- ���ݲ�ѯ���������(��ѯ�Ľ�������ӵ��´����ı���)create table if not exists student3 as select id, name from student;-- �����Ѿ����ڵı��ṹ������create table if not exists student4 like student;-- ��ѯ��������hive (default)> desc formatted student2;Table Type: MANAGED_TABLE
4.5.2 �ⲿ��
��Ϊ�����ⲿ��,����Hive������Ϊ����ȫӵ��������ݡ�ɾ���ñ�������ɾ�����������,������������Ԫ������Ϣ�ᱻɾ������
���������ⲿ����ʹ�ó���
ÿ�콫�ռ�������վ��־��������HDFS�ı��ļ������ⲿ��(ԭʼ��־��)�Ļ�������������ͳ�Ʒ���,�õ����м���������ʹ���ڲ����洢,����ͨ��SELECT+INSERT�����ڲ�����
3.����ʵ��
�ֱ����ź�Ա���ⲿ��,������е������ݡ�
(1)ԭʼ����
dept.txt
create table if not exists dept(deptno int,dname string,loc int)row format delimited fields terminated by '\t';10 ACCOUNTING 170020 RESEARCH 180030 SALES 190040 OPERATIONS 1700
emp.txt
create table if not exists emp(empno int,ename string,job string,mgr int,hiredate string, sal double, comm double,deptno int)row format delimited fields terminated by '\t';7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 307521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 307566 JONES MANAGER 7839 1981-4-2 2975.00 207654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 307698 BLAKE MANAGER 7839 1981-5-1 2850.00 307782 CLARK MANAGER 7839 1981-6-9 2450.00 107788 SCOTT ANALYST 7566 1987-4-19 3000.00 207839 KING PRESIDENT 1981-11-17 5000.00 107844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 307876 ADAMS CLERK 7788 1987-5-23 1100.00 207900 JAMES CLERK 7698 1981-12-3 950.00 307902 FORD ANALYST 7566 1981-12-3 3000.00 207934 MILLER CLERK 7782 1982-1-23 1300.00 10
-- �������-- �������ű�create external table if not exists default.dept(deptno int,dname string,loc int)row format delimited fields terminated by '\t';-- ����Ա����create external table if not exists default.emp(empno int,ename string,job string,mgr int,hiredate string, sal double, comm double,deptno int)row format delimited fields terminated by '\t';-- �鿴�����ı�hive (default)> show tables;OKtab_namedeptemp-- ���ⲿ���е�������-- ��������hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept;hive (default)> load data local inpath '/opt/module/datas/emp.txt' into table default.emp;��ѯ���hive (default)> select * from emp;hive (default)> select * from dept;-- �鿴����ʽ������hive (default)> desc formatted dept;Table Type: EXTERNAL_TABLE
4.5.3\���������ⲿ���Ļ���ת��
-- ��ѯ��������hive (default)> desc formatted student2;Table Type: MANAGED_TABLE(2)���ڲ���student2Ϊ�ⲿ��alter table student2 set tblproperties('EXTERNAL'='TRUE');-- ��ѯ��������hive (default)> desc formatted student2;Table Type: EXTERNAL_TABLE-- ���ⲿ��student2Ϊ�ڲ���alter table student2 set tblproperties('EXTERNAL'='FALSE');-- ��ѯ��������hive (default)> desc formatted student2;Table Type: MANAGED_TABLEע��:('EXTERNAL'='TRUE')��('EXTERNAL'='FALSE')Ϊ�̶�д��,���ִ�Сд!
4.6 ������
������ʵ���Ͼ��Ƕ�Ӧһ��HDFS�ļ�ϵͳ�ϵĶ������ļ���,���ļ������Ǹ÷������е������ļ���Hive�еķ������Ƿ�Ŀ¼,��һ��������ݼ�����ҵ����Ҫ�ָ��С�����ݼ����ڲ�ѯʱͨ��WHERE�Ӿ��еı���ʽѡ���ѯ����Ҫ��ָ���ķ���,�����IJ�ѯЧ�ʻ���ߺܶࡣ
4.6.1 ��������������
1.���������(��Ҫ�������ڶ���־���й���)
/user/hive/warehouse/log_partition/20170702/20170702.log/user/hive/warehouse/log_partition/20170703/20170703.log/user/hive/warehouse/log_partition/20170704/20170704.log
2.�����������
hive (default)> create table dept_partition(deptno int, dname string, loc string)partitioned by (month string)row format delimited fields terminated by ��\t��;
3.�������ݵ���������
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201709');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201708');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201707��);

ͼ6-5 �������ݵ�������
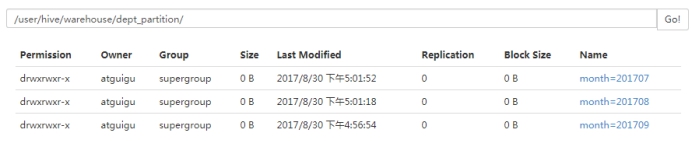
ͼ6-6 ������
4.��ѯ������������
? ��������ѯ
hive (default)> select * from dept_partition where month=��201709��;
��������ϲ�ѯ
hive (default)> select * from dept_partition where month=��201709��
? union
? select * from dept_partition where month=��201708��
? union
? select * from dept_partition where month=��201707��;
_u3.deptno _u3.dname _u3.loc _u3.month
10 ACCOUNTING NEW YORK 201707
10 ACCOUNTING NEW YORK 201708
10 ACCOUNTING NEW YORK 201709
20 RESEARCH DALLAS 201707
20 RESEARCH DALLAS 201708
20 RESEARCH DALLAS 201709
30 SALES CHICAGO 201707
30 SALES CHICAGO 201708
30 SALES CHICAGO 201709
40 OPERATIONS BOSTON 201707
40 OPERATIONS BOSTON 201708
40 OPERATIONS BOSTON 201709
5.���ӷ���
? ������������
hive (default)> alter table dept_partition add partition(month=��201706��) ;
? ͬʱ�����������
hive (default)> alter table dept_partition add partition(month=��201705��) partition(month=��201704��);
6.ɾ������
? ɾ����������
hive (default)> alter table dept_partition drop partition (month=��201704��);
ͬʱɾ���������
hive (default)> alter table dept_partition drop partition (month=��201705��), partition (month=��201706��);
7.�鿴�������ж��ٷ���
hive> show partitions dept_partition;
8.�鿴�������ṹ
hive> desc formatted dept_partition;
\# Partition Information
\# col_name data_type comment
month string
4.6.2 ������ע������
1.��������������
hive (default)> create table dept_partition2( deptno int, dname string, loc string ) partitioned by (month string, day string) row format delimited fields terminated by '\t';
2.�����ļ�������
(1)�������ݵ�������������
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table
default.dept_partition2 partition(month='201709', day='13');
(2)��ѯ��������
hive (default)> select * from dept_partition2 where month='201709' and day='13';
3.������ֱ���ϴ�������Ŀ¼��,�÷����������ݲ������������ַ�ʽ
(1)��ʽһ:�ϴ����ݺ���
? �ϴ�����
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=12;
hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201709/day=12;
? ��ѯ����(��ѯ�������ϴ�������)
hive (default)> select * from dept_partition2 where month='201709' and day='12';
ִ��������
hive> msck repair table dept_partition2;
�ٴβ�ѯ����
hive (default)> select * from dept_partition2 where month=��201709�� and day=��12��;
? (2)��ʽ��:�ϴ����ݺ����ӷ���
? �ϴ�����
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=11;
hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201709/day=11;
? ִ�����ӷ���
? hive (default)> alter table dept_partition2 add partition(month='201709',
day='11');
? ��ѯ����
hive (default)> select * from dept_partition2 where month=��201709�� and day=��11��;
? (3)��ʽ��:�����ļ��к�load���ݵ�����
? ����Ŀ¼
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=10;
�ϴ�����
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table
dept_partition2 partition(month='201709',day='10');
��ѯ����
hive (default)> select * from dept_partition2 where month='201709' and day='10';
4.6.3 hive��4������ʽ
- order byȫ������ȫ�����ݻ��ֵ�һ��reduce�ϡ���sql�е�order by����,��ͬ����,hive�е�order by���ϸ�ģʽ��,�����limit��
- sort by ÿ��mapreduce�ڲ�����
- distributed by��������,��sql�е�group by����,����sort by���ʹ��,distributed by����map�������reduce����λ���,sort by����reduce�е������������hiveҪ��distributed by��������sort by���֮ǰ��
- cluster by,��distributed by��sort by�ֶ���ͬ,������cluster by��������,��cluster by ���ܸ�desc,asc������:����������д
select a.* from (select * from test cluster by id ) a order by a.id;
4.7 �ı�
4.7.1 ��������
-- �ALTER TABLE table_name RENAME TO new_table_name-- ʵ�ٰ���hive (default)> alter table dept_partition2 rename to dept_partition3;
4.7.2 ���ӡ��ĺ�ɾ��������
���4.6.1����������������
4.7.3 ����/��/�滻����Ϣ
-- ������ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]-- ���Ӻ��滻��ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) ע:ADD�Ǵ�������һ�ֶ�,�ֶ�λ���������к���(partition��ǰ),REPLACE���DZ�ʾ�滻���������ֶΡ�-- ��ѯ���ṹhive> desc dept_partition;-- ������hive (default)> alter table dept_partition add columns(deptdesc string);-- ��ѯ���ṹhive> desc dept_partition;-- ������hive (default)> alter table dept_partition change column deptdesc desc int;-- ��ѯ���ṹhive> desc dept_partition;-- �滻�� columns ���б���hive (default)> alter table dept_partition replace columns(deptno string, dname string, loc string);-- ��ѯ���ṹhive> desc dept_partition;
4.8 ɾ����
hive (default)> drop table dept;-- ǿ��ɾ����Ϊ�յ����ݿ�hive (default)> drop table dept cascade;-- �Ƿ�������ݿ�hive> drop database if exists dept;
��5��DML���ݲ���
5.1 ���ݵ��롪�� ��Ҫ
5.1.1 �����װ������(Load)���� �ؼ�
1.�
hive> load data [local] inpath '/opt/module/datas/student.txt' overwrite | into table student [partition (partcol1=val1,��)]
(1)load data:��ʾ��������(2)local:��ʾ�ӱ��ؼ������ݵ�hive��;�����HDFS�������ݵ�hive��(3)inpath:��ʾ�������ݵ�·��(4)overwrite:��ʾ���DZ�����������,�����ʾ��(5)into table:��ʾ���ص����ű�(6)student:��ʾ����ı�(7)partition:��ʾ�ϴ���ָ������
2.ʵ�ٰ���
-- ����һ�ű�
hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';
-- ���ر����ļ���hive
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table default.student;
-- ����HDFS�ļ���hive��
-- �ϴ��ļ���HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;
-- ����HDFS������
hive (default)> load data inpath '/user/atguigu/hive/student.txt' into table default.student;
-- �������ݸ��DZ������е�����
-- �ϴ��ļ���HDFS
hive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;
-- �������ݸ��DZ������е�����
hive (default)> load data inpath '/user/atguigu/hive/student.txt' overwrite into table default.student;
5.1.2 ͨ����ѯ�������в�������(Insert)���� �ؼ�
-- ����һ�ŷ�����
hive (default)> create table student(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';
-- ������������
hive (default)> insert into table student partition(month='201709') values(1,'wangwu');
-- ����ģʽ����(���ݵ��ű���ѯ���)
hive (default)> insert overwrite table student partition(month='201708') select id, name from student where month='201709';
-- �����ģʽ(���ݶ��ű���ѯ���)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
5.1.3 ��ѯ����д���������������(As Select)
���4.5.1�´�������
���ݲ�ѯ���������(��ѯ�Ľ�������ӵ��´����ı���)
create table if not exists student3
as select id, name from student;
5.1.4 ������ʱͨ��Locationָ����������·�������ؼ�
-- ������,��ָ����hdfs�ϵ�λ��hive (default)> create table if not exists student5(id int, name string) row format delimited fields terminated by '\t' location '/user/hive/warehouse/student5';--�ϴ����ݵ�hdfs��hive (default)> dfs -put /opt/module/datas/student.txt/user/hive/warehouse/student5;-- ��ѯ����hive (default)> select * from student5;
5.1.5 Import���ݵ�ָ��Hive���С���ʹ�ò���
ע��:����export������,�ٽ����ݵ��롣
hive (default)> import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
5.2 ���ݵ���
5.2.1 Insert����
-- ����ѯ�Ľ������������
hive (default)> insert overwrite local directory '/opt/module/datas/export/student'
select * from student;
-- ����ѯ�Ľ����ʽ������������
hive(default)>insert overwrite local directory '/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
select * from student;
-- ����ѯ�Ľ��������HDFS��(û��local)
hive (default)> insert overwrite directory '/user/root/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
5.2.2 Hadoop�����������
hive (default)> dfs -get /user/hive/warehouse/student/month=201709/000000_0
/opt/module/datas/export/student3.txt;
5.2.3 Hive Shell �����
�����:(hive -f/-e ִ�������߽ű� > file)
[root@locahost hive]$ bin/hive -e 'select * from default.student;' > /opt/module/datas/export/student4.txt;
5.2.4 Export������HDFS��
(defahiveult)> export table default.student to
'/user/hive/warehouse/export/student';
���ڹ�˾�ļ�Ⱥ֮���hive��Ǩ��
����5���ڵ�����,������,10�����ϵ�����Ȼ����������ߵķŵ�����
5.2.5 Sqoop����
�����γ�ר�Ž���
5.3 �����������(Truncate)
ע��:Truncateֻ��ɾ��������,����ɾ���ⲿ��������
hive (default)> truncate table student;
��6��:����
6.1�洢��ʽ
Hive ���� HDFS Ϊÿ�����ݿ��ϴ���һ��Ŀ¼,���ݿ��еı��Ǹ�Ŀ¼����Ŀ¼,���е����ݻ����ļ�����ʽ�洢�ڶ�Ӧ�ı�Ŀ¼�¡�Hive ֧�����¼����ļ��洢��ʽ:
| ��ʽ | ˵�� |
|---|---|
| TextFile | �洢Ϊ���ı��ļ��� ���� Hive Ĭ�ϵ��ļ��洢��ʽ�����ִ洢��ʽ���ݲ���ѹ��,���̿�����,���ݽ��������� |
| SequenceFile | SequenceFile �� Hadoop API �ṩ��һ�ֶ������ļ�,����������<key,value>����ʽ���л����ļ��С����ֶ������ļ��ڲ�ʹ�� Hadoop �ı��� Writable �ӿ�ʵ�����л��ͷ����л������� Hadoop API �е� MapFile �ǻ�����ݵġ�Hive �е� SequenceFile �̳��� Hadoop API �� SequenceFile,�������� key Ϊ��,ʹ�� value ���ʵ�ʵ�ֵ,������Ϊ�˱��� MR ������ map �ν��ж������������� |
| RCFile | RCFile �ļ���ʽ�� FaceBook ��Դ��һ�� Hive ���ļ��洢��ʽ,���Ƚ�����Ϊ��������,��ÿ�������ڵ����ݰ��д洢,ÿһ�е����ݶ��Ƿֿ��洢�� |
| ORC Files | ORC ����һ���̶�����չ�� RCFile,�Ƕ� RCFile ���Ż��� |
| Avro Files | Avro ��һ���������л�ϵͳ,�������֧�ִ��������ݽ�����Ӧ�á�������Ҫ�ص���:֧�ֶ��������л���ʽ,���Ա��,���ٵش�����������;��̬�����Ѻ�,Avro �ṩ�Ļ���ʹ��̬���Կ��Է���ش��� Avro ���ݡ� |
| Parquet | Parquet �ǻ��� Dremel ������ģ�ͺ��㷨ʵ�ֵ�,���������ҵ�����ʽ�洢��ʽ����ͨ�����н��и�Чѹ��������ı��뼼��,�Ӷ��ڽ��ʹ洢�ռ��ͬʱ����� IO Ч�ʡ� |
����ѹ����ʽ�� ORC �� Parquet ���ۺ�����ͻ��,ʹ�ý�Ϊ�㷺,�Ƽ�ʹ�������ָ�ʽ��
ͨ���ڴ�������ʱ��ʹ�� STORED AS ����ָ��:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
�����洢�ļ�����ָ����ʽ����:
- STORED AS TEXTFILE
- STORED AS SEQUENCEFILE
- STORED AS ORC
- STORED AS PARQUET
- STORED AS AVRO
- STORED AS RCFILE
6.2 �ڲ������ⲿ��
�ڲ����ֽ��������� (Managed/Internal Table),������ʱ�����κ�ָ��,Ĭ�ϴ����ľ����ڲ�������Ҫ�����ⲿ�� (External Table),����Ҫʹ�� External �������Ρ� �ڲ������ⲿ����Ҫ��������:
| �ڲ��� | �ⲿ�� | |
|---|---|---|
| ���ݴ洢λ�� | �ڲ������ݴ洢��λ���� hive.metastore.warehouse.dir ����ָ��,Ĭ������±������ݴ洢�� HDFS �� /user/hive/warehouse/���ݿ���.db/����/ Ŀ¼�� | �ⲿ�����ݵĴ洢λ�ô�����ʱ�� Location ����ָ��; |
| �������� | �ڵ������ݵ��ڲ���,�ڲ����������ƶ����Լ������ݲֿ�Ŀ¼��,���ݵ����������� Hive �����й��� | �ⲿ�����Ὣ�����ƶ����Լ������ݲֿ�Ŀ¼��,ֻ����Ԫ�����д洢�����ݵ�λ�� |
| ɾ���� | ɾ��Ԫ����(metadata)���ļ� | ֻɾ��Ԫ����(metadata) |
6.3hive���ŷ�ʽ
- Fetchץȡ:�Ѳ���ҪMR�������IJ�ѯ������óɲ�ִ��MR������������,none��ʾ����Fetch,���в�ѯ��ִ��MR����;more�ڽ���select/filter/limit��ѯʱ��������MR����;minimal��select/limit��ʱ������MR����,����filter������MR����
hive.fetch.task.conversion - ����ģʽ:��������������ر�С������ֱ���ڱ��ؽڵ��Ͻ��д���,�����ύ����Ⱥ������ģʽͨ���ж��ļ��Ĵ�С(Ĭ��128MB)���������ļ��ĸ���(Ĭ��4��)���ж��Ƿ��ڱ���ִ�С�
set hive.exec.mode.local.auto=true; //�������� mr
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.exec.mode.local.auto.input.files.max=10; - �����Ż�:�Ż��ֶ���join�����й��ˡ���������Ͱ����̬�����ȵȡ�
- ����������б:ͨ����������map��reduce����С�ļ��ϲ��ȷ�ʽ������֤���ؾ��⡣��Ϊ�˱�����Ϊmap��reduce����������������б,ͨ��Ҳ�����Ʋ�ִ�С�
- �Ʋ�ִ��:Ϊ�˱�����Ϊ�����BUG/���ز�����/��Դ�ֲ�������ԭ����ͬһ��ҵ��ijһ���������ٶȹ���,�����Ʋ�ִ��,Ϊ����������һ����������,ͬʱִ��,����������ɵļ�������Ϊ���ս������Ϊmap�˺�reduce�˵��Ʋ�ִ�С�
set mapreduce.map.speculative=true
set mapreduce.reduce.speculative=true - ����ִ��:��û��������ϵ��MR��������Ϊ����ִ��,��߶���������ʱ��Ч�ʡ�
set hive.exec.parallel=true ; // ����������ִ��
set hive.exec.parallel.thread.number=8; //Ĭ��ֵΪ8���������ͬʱ���� - �ϸ�ģʽ:Ϊ�˷�ֹһЩ�������IJ�ѯ����ִ�С�
hive.mapred.mode= strict - JVM����:���кܶ�С�ļ���ʱ��,ÿ������MR���Ὺ��һ��JVM����,JVMƵ���Ŀ����ر����Ĵ���������,�����ڴ���С�ļ���ʱ��,��������JVM����,��һ��JVM�������������ٹرա�
mapreduce.job.jvm.numtasks - ѹ��:ͨ��ѹ������Ŀ�����Ż������翪�� map �����ѹ�����Լ��� job �� map �� Reduce task �����ݴ�������
- ִ�мƻ�:Hive���ṩ�Ŀ��Բ鿴Hql����ִ�мƻ�,��ִ�мƻ��л����ɳ������,������л���ʾHQL���֮���������ϵ�Լ�ִ�й��̡�ͨ����Щִ�еĹ��̺��������Զ�HQL�������Ż���
6.4�ȹ��Ŀ�
(1) ʹ��schematool��ʼ�����ݿ�����ʱ
����:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
ͨ����������,������Hadoop��Hive��Guava�汾��һ������,��Ҫɾ��Hive�е�jar����ͬ������log4j-slf4j-impl-2.10.0.jar������hadoop�п�����
cd apache-hive-3.1.2-bin/lib/;rm guava-19.0.jar;rm log4j-slf4j-impl-2.10.0.jar
cp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar /home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar nick@slave1:/home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar nick@slave2:/home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar nick@slave3:/home/nick/apache-hive-3.1.2-bin/lib;cp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/log4j-1.2.17.jar /home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/log4j-1.2.17.jar nick@slave1:/home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/log4j-1.2.17.jar nick@slave2:/home/nick/apache-hive-3.1.2-bin/lib;scp /home/nick/hadoop-3.2.1/share/hadoop/common/lib/log4j-1.2.17.jar nick@slave3:/home/nick/apache-hive-3.1.2-bin/lib;
����HCatalogʱ,����/home/nick/apache-hive-3.1.2-bin/hcatalog/sbin/hcat_server.sh:��91: /home/nick/apache-hive-3.1.2-bin/hcatalog/sbin/��/var/log/hcat.out: û���Ǹ��ļ���Ŀ¼;
���:�������ļ�
beeline�д������ݿ�ʱ,����Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=anonymous, access=WRITE, inode=��/user/nick/warehouse��:nick:supergroup:drwxrwxr-x;
���:����дȨ��
beeline��ѯ��ʱ,����: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 1ee619c9-e587-4577-a03c-c9ef5f6eedb2 (state=42000,code=30041)
���:
Spark 2.0.0�Ѿ��������hive.metastore.warehouse.dirproperty inhive-site.xml,��Ϊʹ��spark.sql.warehouse.dirָʾ���ݲֿ���Ĭ�����ݿ�λ�á�
<property>
<name>spark.sql.warehouse.dir</name>
<value>/user/nick/warehouse</value>
<description>same with hive.metastore.warehouse.dir, which is deprecated in 2.0.0</description>
</property>
����hive-site.xml, core-site.xml (for security configuration), and hdfs-site.xml (for HDFS configuration) file in conf/,Ȼ������Spark��Ⱥ��
beeline��ѯ��ʱ,���� Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause. (state=42000,code=2)
����:��Ҫ��־�鿴ϸ��hive �Chiveconf hive.root.logger=DEBUG,console
�ҵ�����http://master:8088/cluster/app/application_1592471815985_0004
�����׳��쳣:�Ҳ��������������� org.apache.spark.deploy.yarn.ExecutorLauncher
��������,����������û����Spark���ʵ���,��Ҫ��spark-defaults.conf������spark.yarn.jars hdfs://master:8020/spark-jars/*
ԭ��:������HDFS·�������jarû�ҵ�
���:����ʹ��beeline����,��̽��
��Ҫʹ��hive�������,����
����spark history serverʱ����
java.io.FileNotFoundException: Log directory specified does not exist: file:/tmp/spark-events Did you configure the correct one through spark.history.fs.logDirectory?
��spark-env.sh������ spark.history.fs.logDirectory������Ӧ��ִ�к���־
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=20 -Dspark.history.fs.logDirectory=hdfs://master:8020/spark-log"
����spark history serverʱ����,Ŀ¼�Ҳ���
���:HDFSĿ¼��Ĭ��ǰΪ/user/nick,��Ҫ����������ʽ����,�������ҵ�����̽��ȥ�������
����
http://www.hiszm.cn/
https://hopefulnick.github.io/2020/05/27/200527Hive%E5%85%A5%E9%97%A8/
https://seawaylee.github.io/2017/07/02/%E5%A4%A7%E6%95%B0%E6%8D%AE/Hive/Hive%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%EF%BC%88%E4%B8%80%EF%BC%89-%20%E8%AF%A6%E8%A7%A3Hive/
http://www.atguigu.com/
https://monkeyip.github.io/2019/04/30/Hive%E7%9F%A5%E8%AF%86%E7%82%B9%E6%80%BB%E7%BB%93/
https://dunwu.github.io/bigdata-tutorial/hive/hive-quickstart.html#%E5%A4%8D%E6%9D%82%E7%B1%BB%E5%9E%8B
