HBase四类主要操作
-
put:增加一行,修改一行;
-
get:获取指定行的所有信息,获取指定行和指定列族的所有column,获取指定column的几个版本等;
-
scan:获取指定行键范围的行;
-
delete:删除一行,指定rowkey,列族,指定column的多个版本;
put存储一行数据操作
1.客户端提交写请求:先将数据写入缓存,判断缓存是否满,若满则提交数据。(非每次put都进行rpc调用,而是批量缓存数据一次rpc发送到服务器)。
2.客户端确定数据所在的regionserver,批量提交数据到选中的regionserver,这里的批量是采用线程池的方式提交的,失败会重试。
3.regionserver接受数据,进行写入数据的底层实现。
delete删除数据
采用墓碑方式,先对删除的数据进行墓碑标记,相当于逻辑删除,是数据不可见,然后等待compact再进行删除。标记最新版本的数据,根据所要求的版本数,会对旧版本删除
标记主要通过type类型区分,当type为delete或delete column或delete family时,将不返回改行数据。
HBase过滤器
HBase过滤器时在regionserver端发生作用,数据从磁盘读入到regionserver然后进行过滤操作,过滤后的结果返回到客户端,这样节省了大量的网络io数据。
过滤器参数
要完成一个过滤的操作,至少需要两个参数。一个是抽象的操作符,Hbase提供了枚举类型的变量来表示这些抽象的操作符:LESS/LESS_OR_EQUAL/EQUAL/NOT_EUQAL等;另外一个就是具体的比较器(Comparator),代表具体的比较逻辑,可以提高字节级的比较、字符串级的比较等。
-
抽象操作符(比较运算符)
-
LESS <
-
LESS_OR_EQUAL <=
-
EQUAL =
-
NOT_EQUAL <>
-
GREATER_OR_EQUAL >=
-
GREATER >
-
NO_OP 排除所有
-
-
比较器(指定比较机制)
-
BinaryComparator 按字节索引顺序比较指定字节数组,采用 Bytes.compareTo(byte[])
-
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
-
NullComparator 判断给定的是否为空
-
BitComparator 按位比较
-
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非 EQUAL
-
SubstringComparator 判断提供的子串是否出现在 value 中
-
过滤器分类
- 比较过滤器
1.行键过滤器 rowFilter
Filter rowFilter = new RowFilter(CompareOp.GREATER, new BinaryComparator("95007".getBytes()));
scan.setFilter(rowFilter);
2.列簇过滤器 FamilyFilter
Filter familyFilter = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator("info".getBytes()));
scan.setFilter(familyFilter);
此外还有列过滤器 QualifierFilter、值过滤器 ValueFilter、时间戳过滤器 TimestampsFilter
- 专用过滤器
单列值过滤器 SingleColumnValueFilter ----会返回满足条件的整行
单列值排除器 SingleColumnValueExcludeFilter
前缀过滤器 PrefixFilter----针对行键
列前缀过滤器 ColumnPrefixFilter
- BloomFilter
BloomFilter对于HBase的随机读性能至关重要,对于get操作以及部分scan操作可以剔除掉不会用到的HFile文件,减少实际IO次数,提高随机读性能。
原理:
内部实则为一个bit数组,初始值均为0

假设一个数组中有x,y两个数字,经过多次的不同哈希算法,将其映射到对应index上,置为1.
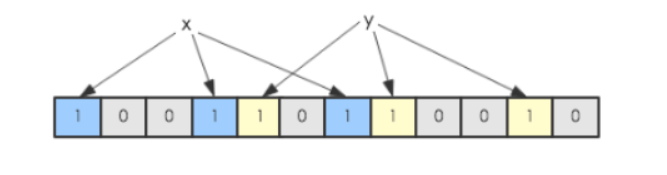
我们判断z在不在该数组中,只要看其经过相同的几次哈希算法之后,对应索引上是否为1,即可。(但有可能不在该数组的数字,经过哈希算法后,发现对应index上恰好为1,所以布隆过滤器只能保证不符合规则的元素一定不在该数组中,而符合规则的则不一定真的在该数组中。)
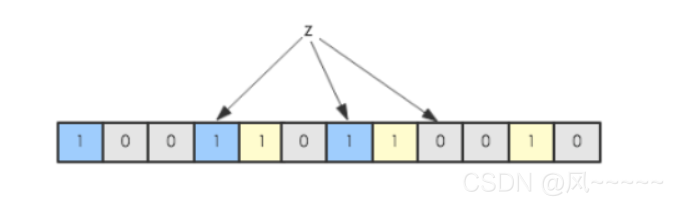
在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的查询时间。
由三部分构成
Bloom Block:Bloom数据块,存储Bloom的位数组
Bloom Index Block:Bloom数据块的索引
BloomFilter Meta Block:从HFile角度看bloom数据块的一些元数据信息,大小个数等等。
-
HBase中的每个HFile都有对应的位数组Bloom Block,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,scan或get请求进来之后对相应的KeyValue进行hash映射,如果在对应数组位上存在0,说明该scan或get请求查询的数据不在该HFile中。
-
当HFile很大时,Data Block 就会很多,同时KeyValue也会很多,需要映射入位数组的rowKey也会很多,所以为了保证准确率,位数组就会相应越大,那Bloom Block也会越大,为了解决这个问题就出现了Bloom Index Block,作用和 Data Index Block 类似,一个HFile中有多个Bloom Block(位数组),根据rowKey拆分,一部分连续的rowKey使用一个位数组。这样查询rowKey就要先经过Bloom Index Block(在内存中)定位到Bloom Block,再把Bloom Block加载到内存中,进行过滤。
HBase协处理器
过滤器减少服务端通过网络返回客户端的数据量,减少通讯开销,协处理器:HBase把部分计算移到数据的存放端。
协处理器分为两种:observer和endpoint。每种协处理器都有一个优先级,system,user,system的优先级高于user。协处理器按照处理范围可以分为系统级处理器(静态加载,处理所有表)和表级处理器(动态加载,一个表所有的region)。observer可以实现权限管理、优先级设置、监控、ddl控制、二级索引等功能;endpoint可以实现min、max、avg、sum、distinct、group by等聚合功能。
- observer协处理器。类似于传统数据库的触发器,当发生某一特定操作的时候触发observer。比如在客户端数据操作、wal相关操作、ddl表操作等前后提供钩子函数进行触发调用。从一次put请求操作来理解observer。CoprocessorHost类代表region管理observer的登记和执行。
1、客户端发出 put 请求
2、该请求被分派给合适的 RegionServer 和 region
3、coprocessorHost 拦截该请求,然后在该表上登记的每个 RegionObserver 上调用 prePut()
4、如果没有被 prePut()拦截,该请求继续送到 region,然后进行处理
5、region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut()
6、假如没有 postPut()拦截该响应,最终结果被返回给客户端
- Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行, 势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。
HBase的切分过程
-
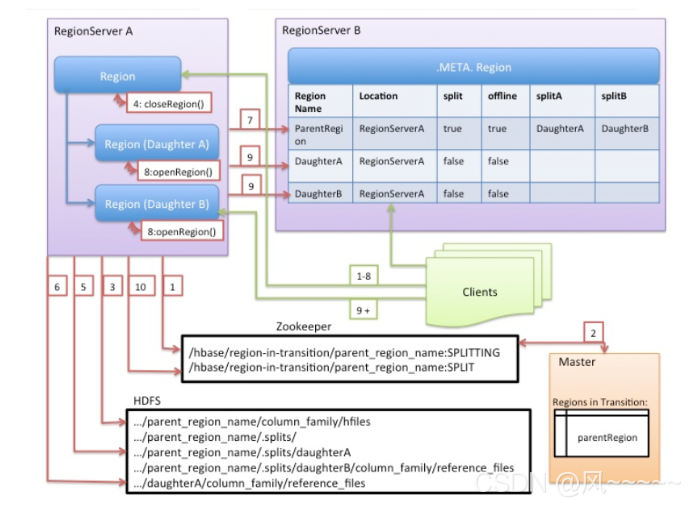
region server发起split。它会在zookeeper上创建一个节点,名称为/HBase/region-in-transition/region-name。状态为splitting。
-
因为master会监听/HBase/region-in-transition目录,所以他会得知split的发生
-
region server在夫region的HDFS目录下,创建一个叫做.split的子目录。
-
region server在服务内部将父region关闭,此时,所有的客户端访问父region的请求都会失败,并抛出NotServingRegionException异常。
-
region server在.split目录下创建子region的目录以及必要的数据结构。对于一个store file会常见两个reference file,并将reference file指向父region的文件。
-
region server创建真正的两个子region目录,并移动这些reference文件,形成真正的切分。
-
region server发送一个put请求到meta表,请求将父region在META中的状态设置成offline,并增加子region的信息。
-
region server同时打开两个子region接受请求。
-
region server将两个region加入到meta表中。此时,客户端会发现新的region,并可以向新的region发送请求。
-
region server将zookeeper上的/HBase/region-in-transition/region-name的状态改成split。master可以感知到split的完成。之后,balancer可以将子region分配到其他region server。
-
切分完成,垃圾清理。删除父region的相关的数据。
HBase优化方法
- 优化DataNode允许的最大文件打开数
属性:dfs.datanode.max.transfer.threads(同一时间操作大量的文件,提高该值)
- 优化延迟高的数据操作的等待时间
属性:dfs.image.transfer.timeout(防止socket被time out掉)
- 优化数据的写入效率
属性:
mapreduce.map.output.compress mapreduce.map.output.compress.codec
- 设置 RPC 监听数量(读写请求较多时,增加此值)
属性:Hbase.regionserver.handler.count
- 优化 HStore 文件大小
属性:hbase.hregion.max.filesize(防止一个region太大,导致map任务执行时间过长)
- 优化 HBase 客户端缓存
属性:hbase.client.write.buffer(用于指定 Hbase 客户端缓存,增大该值可以减少 RPC 调用次数,但是会消耗更多内存)
- 指定 scan.next 扫描 HBase 所获取的行数(用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大)
属性:hbase.client.scanner.caching
flush、compact、split 机制
- 当MemStore 达到阈值,将 Memstore 中的数据Flush进 Storefile;compact 机制则是把 flush 出来的小文件合并成大的 Storefile 文件。split 则是当 Region 达到阈值,会把过大的 Region 一分为二。
属性:hbase.hregion.memstore.flush.size:134217728
这个参数的作用是当单个 HRegion 内所有的 Memstore 大小总和超过指定值时,flush 该 HRegion 的所有 memstore。RegionServer 的 flush 是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发 OOM。 hbase.regionserver.global.memstore.upperLimit:0.4 hbase.regionserver.global.memstore.lowerLimit:0.38 即:当MemStore 使用内存总量达到hbase.regionserver.global.memstore.upperLimit 指定值时,将会有多个 MemStores flush 到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到 MemStore 使用内存略小于 lowerLimit。
若memstore太大,0.38至0.4的阈值中间内存太大,可能导致长期无法写入。
-
减少region分裂
- 根据rowkey设计来进行预建分区,减少region的动态分裂。
-
给HFile设定合适大小
- HFile是数据底层存储文件,在每个memstore进行刷新时会生成一个HFile,当HFile增加到一定程度时,会将属于一个region的HFile进行合并,这个步骤会带来开销但不可避免,但是合并的region大小如果大于设定的值,那么region会进行分裂。为了减少这样的无谓的I/O开销,建议估计项目数据量的大小,给HFile设定一个合适的值。
-
减少启止,HBase中存在频繁开去关闭带来的问题
-
关闭compaction,在闲时进行手动compaction。因为HBase中存在Minor Compaction 和 Major Compaction,合并就是I/O读写,大量的HFile进行肯定会带来I/O开销,甚至是I/O风暴,所以为了避免这种不受控制的意外发生,建议关闭自动Compaction,在闲时进行compaction。
-
当需要写入大量离线数据时建议使用BulkLoad。
-
-
减少数据量
-
开启过滤,提高查询速度,可以减少网络io
-
使用压缩,一般采用snappy和LZO压缩
-
-
合理设计
- 预分区、rowkey设计、列族设计
HBase中region server发生故障后的处理方法
- Hbase检测宕机是通过zookeeper实现的,正常情况region server会周期性向zookeeper发送心跳,一旦宕机,心跳就会停止,超过一定的时间,zookeeper就会认为regionserver宕机离线,并将该消息通知给region进行分组,切分到每个regionserver中,因此在回放前首先将HLog按照region进行分组,每个region的日志数据放在一起,方便后面按照region进行回收。这个分组的过程就称为HLog切分。然后再对region重新分配,并对其中的HLog进行回放将数据写入memstore刷写到磁盘,完成最终的数据恢复。