ǰ��
����������ר����1000������㶨�����ݼ�����ϵ��,��ר��Ϊ����ԭ��,������ע����Դ,����ʹ���֮��������������æָ��,лл!
��ר��Ŀ¼�ṹ�������������1000������㶨�����ݼ�����ϵ
����

Apache Kylin ϵͳ���Է�Ϊ���߲�ѯ�����߹���������,�����ܹ���ͼ��ʾ,���ߖ�ѯ��ģ����Ҫ�����ϰ���,�����߹��������°�����
���߹���
�����������������߹����IJ��֡�
��ͼ�п��Կ���,����Դ�����,��Ҫ�� Hadoop/Hive/Kafka/RDBMS ,�����Ŵ��������û����ݡ�
����Ԫ���ݵĶ���,�·��������������Դ��ȡ����,������ Cube ��
�����Թ�ϵ������ʽ����,�ұ����������ģ��( Star Schema )��
Map Reduce �� Spark ����Ҫ�Ĺ�������,Kylin 4.0 �汾��Spark Engine ��Ψһ�Ĺ������档
������� Cube �������Ҳ�Ĵ洢������,ѡ�� Parquet ��Ϊ�洢��
�� 3.x �Լ�֮ǰ�İ汾��,kylin һֱʹ�� HBase ��Ϊ�洢���������� cube �����������Ԥ��������HBase ��Ϊ HDFS ֮��������������ݿ�,��ѯ�����Ѿ����DZȽ�����,��������Ȼ�������¼���ȱ��:
- HBase ������������ʽ�洢;
- HBase û�ж�������,Rowkey ����Ψһ������;
- HBase û�жԴ洢�����ݽ��б���,kylin �����Լ����ж����ݱ���Ĺ���;
- HBase ���ʺ����ϲ�����Զ�����;
- HBase ��ͬ�汾֮��� API �汾��ͬ,���ڼ���������(����,0.98,1.0,1.1,2.0);
- HBase ���ڲ�ͬ�Ĺ�Ӧ�̰汾,����֮���м��������⡣
�����������,��������˶�ʹ�� Apache Parquet + Spark ������ HBase ������,��������:
- Parquet ��һ�ֿ�Դ�����Ѿ������ȶ�����ʽ�洢��ʽ;
- Parquet ���Ƹ����Ѻ�,���Լ��ݸ����ļ�ϵͳ,���� HDFS��S3��Azure Blob store��Ali OSS ��;
- Parquet ���Ժܺõ��� Hadoop��Hive��Spark��Impala �ȼ���;
- Parquet ֧���Զ���������
���߲�ѯ
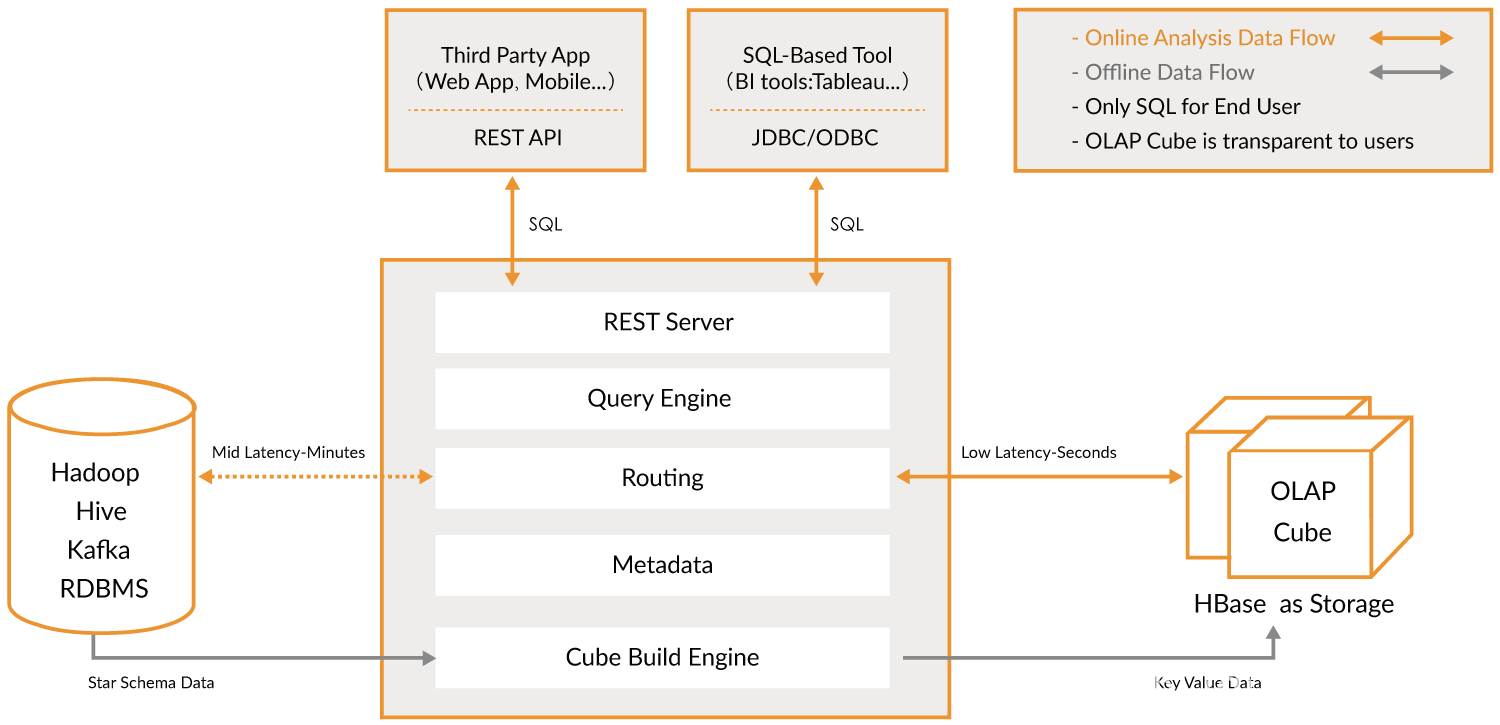
��������߹���֮��,�û����Դ��Ϸ���ѯϵͳ���� SQL ���Ж�ѯ������
Kyin �ṩ�˸��� RestAPI �� JDBC / ODBC �ӿڡ�
���۴��ĸ��ӿڽ���, SQL ���ն������� Rest �����,��ת������ѯ������д�����
������Ҫע�����, SQL ����ǻ�������Դ�Ĺ�ϵģ����д��,������ Cube ��
Kylin �����ʱ����Ԗ�ѯ�û������� Cube �ĸ���,����ʦֻ��Ҫ����Ĺ�ϵģ�;Ϳ���ʹ�� Kylin ,û�ж����ѧϰ�ż�,��ͳ�� SQL Ӧ��Ҳ������Ǩ�ơ�
��ѯ������� SQL ,���ɻ��ڹ�ϵ������ִ�мƻ�,Ȼ����ת��Ϊ���� Cube ������ִ�мƻ�,����ѯԤ�������ɵ� Cube �����������
�������̲������ԭʼ����Դ��
Apache Kylin 1.5 �汾�Ŀ���չ�ܹ�
Apache Kylin 1.5 �汾�����ˡ�����չ�ܹ����ĸ��
����չָ Kylin ���Զ�����Ҫ����������ģ�����������չ���滻��
Kylin ����������ģ��ֱ�������Դ�������������洢������
�����֮��,��Ϊ Hadoop �����һԱ,�����߷ֱ��� Hive �� MapReduce �� HBase ��
�������ƹ��ʹ�õ�����,�������û��������Ǿ����ڲ���֮����
����,ʵʱ�������ܻ�ϣ���� Kafka �������ݶ����Ǵ� Hive,�� Spark ��Ѹ������,��ʹ���Dz��ò����ǽ� MapReduce �滻Ϊ Spark ,���ڴ����� Cube �Ĺ����ٶ�,���� HBase ,���Ķ����ܿ��ܻ����� Cassandra �� Kudu �ȡ�
�ɼ�,�Ƿ���Խ�һ�ּ����滻Ϊ��һ�ּ����ѳ�Ϊһ�����������⡣
���� Kylin 1.5 �汾��ϵͳ�ܹ��������ع�,������Դ���������桢�洢����������������Ϊ�ӿڡ�
����û����Ը����Լ�����Ҫ�����ο���,�����е�һ�������滻Ϊ���ʺϵļ�����