四种在hive中都有排序和聚集的作用,但它们在执行时所启动的MR却各不相同。
1、order by
Order By:全局排序,只有一个 Reducer。
排序:
ASC(ascend): 升序(默认)
DESC(descend): 降序
按照薪资水平对员工升序排列:
hive (default)> select ename,sal from emp order by sal;
ename sal
SMITH 800.0
JAMES 950.0
ADAMS 1100.0
MARTIN 1250.0
WARD 1250.0
MILLER 1300.0
MILLER 1300.0
TURNER 1500.0
ALLEN 1600.0
CLARK 2450.0
BLAKE 2850.0
JONES 2975.0
2、sort by
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。
Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序,对全局结果集来说不是排序。
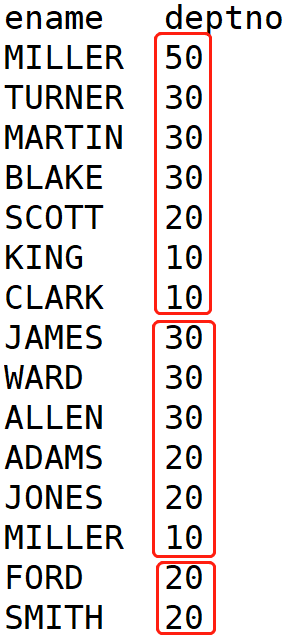
根据部门编号降序查看员工信息:
--设置 reduce
hive (default)> set mapreduce.job.reduces=3;
--查看设置 reduce个数
hive (default)> set mapreduce.job.reduces;
hive (default)> select ename, deptno from emp sort by deptno desc;
ename deptno
MILLER 50
TURNER 30
MARTIN 30
BLAKE 30
SCOTT 20
KING 10
CLARK 10
JAMES 30
WARD 30
ALLEN 30
ADAMS 20
JONES 20
MILLER 10
FORD 20
SMITH 20
三个reducer示意如下:
3、distribute by
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by 的效果。
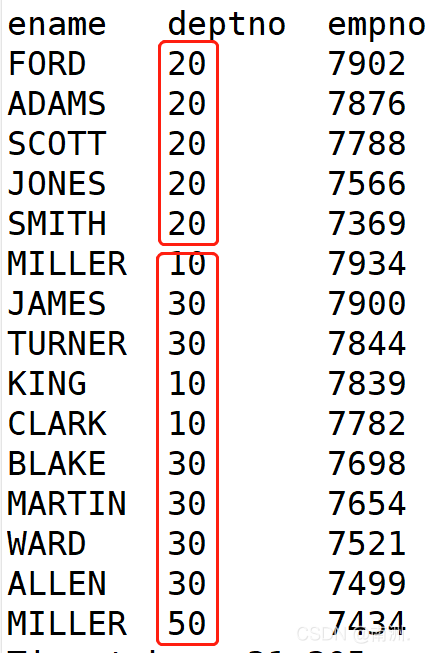
先按照部门编号分区,再按照员工编号降序排序:
hive (default)> set mapreduce.job.reduces=4;
hive (default)> select ename, deptno, empno from emp distribute by deptno sort by empno desc;
ename deptno empno
MILLER 10 7934
FORD 20 7902
JAMES 30 7900
ADAMS 20 7876
TURNER 30 7844
KING 10 7839
SCOTT 20 7788
CLARK 10 7782
BLAKE 30 7698
MARTIN 30 7654
JONES 20 7566
WARD 30 7521
ALLEN 30 7499
MILLER 50 7434
SMITH 20 7369
注意:
? distribute by 的分区规则是根据分区字段的 hash 码与 reduce 的个数进行模除后,余数相同的分到一个区。
? Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前。
如下图所示,上述结果按照模为0(20%4 =0)和模为2(10%4=2、30%4=2、50%4=2)两个分区,此外有空的分区(模为1和模为3的)。
4、cluster by
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC。
以下两种写法等价:
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;