文章目录
1. 什么是数据湖
准确来讲就是数据入湖中间件技术,它并不是一个存储或者计算引擎,它的存在就是更好的将存储和计算解耦,构建与存储格式之上的数据组织方式,并提供ACID(atomicity原子性、consistency一致性、isolation隔离性、durability持久性)能力,提供行级别的数据修改能力,确保schema的准确性,提供一定的schema扩展能力,
数据湖具有哪些能力,分为两个方面:
- 存储:
-
元数据修正以及行级数据修正
-
数据质量管控
-
异构数据入湖
- 计算:
-
流批计算融合
-
ACID
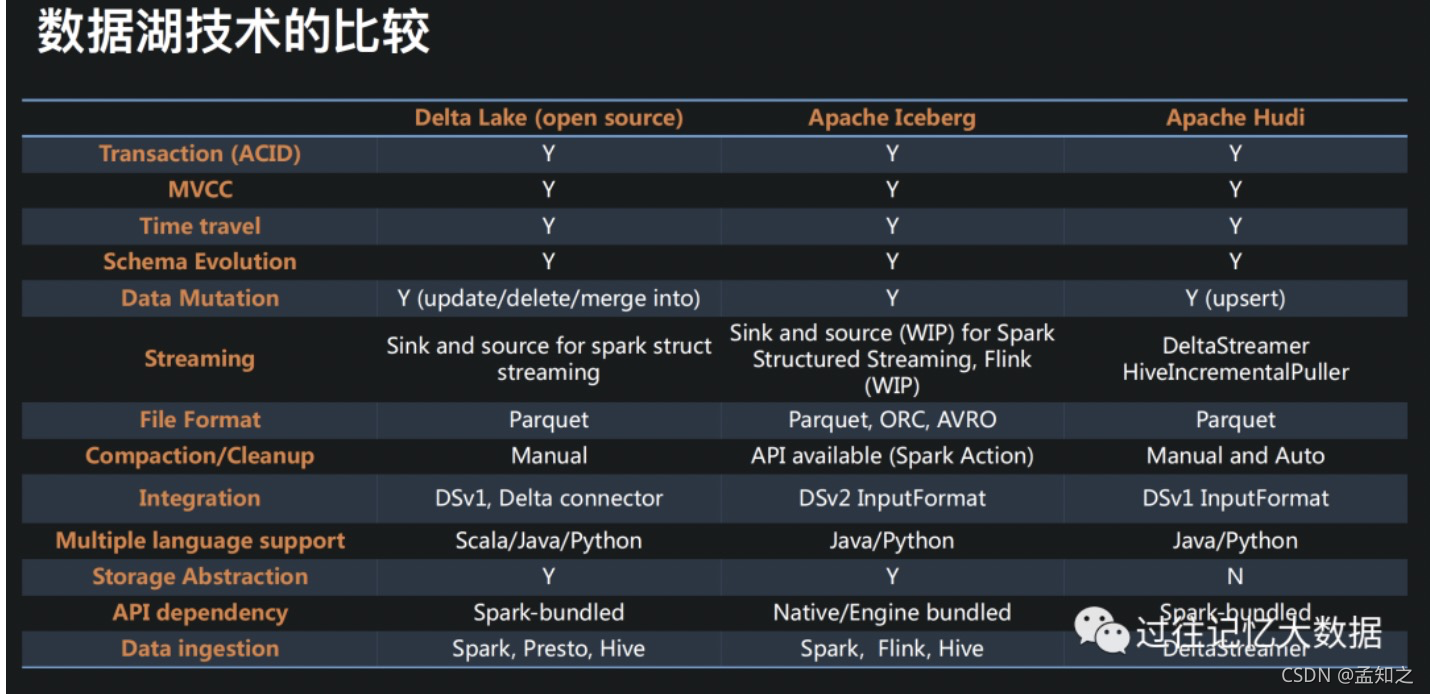
2. iceberg的特性
2.1 优化数据入库的流程
- 提供ACID事务能力,上游数据写入即可见,不影响当前数据处理任务。
技术细节:
-
事务性提交:
-
在写操作的时候,首先会记录当前元数据的版本-base version,然后创建新的元数据以及manifest文件,最后会原子性地将base version替换为新的版本。
-
原子性替换保证了线性的历史, 但原子性替换需要依赖元数据管理器所提供的能力和HDFS或是本地文件系统所提供的原子化的rename能力。
-
写操作基于乐观锁设计,因为大数据场景下,读比写的场景多,所以采用乐观锁的设计,回会假定当前没有其他的写操作,当遇到冲突则基于当前最新的元数据进行重试。
-
-
快照隔离:
-
读操作仅适用当前已生成的快照。
-
写操作会生成新的隔离快照,并在写完成后原子性提交。
-
- 提供upsert/merge into 能力,可以极大地缩小数据入库的能力
技术细节:
- 对于文件列表的所有修改都是原子操作:如在分区中追加数据,合并或是重写分区。同时也会此时记录表的结构,分区信息,参数等,生成变化轨迹文件,并始终向前迭代,即能实现跟踪老的快照,以确保能够回退。
2.2 支持更多的分析引擎
-
优秀的内核抽象使之不绑定于特定引擎,目前在支持的有spark,flink,persto,hive。
-
提供java native API,不用特定引擎也可以访问iceberg表。
2.3 统一数据存储和灵活的文件组织
-
提供基于流式的增量计算模型和基于批处理的全量表计算模型,批任务和流任务可以使用相同的存储模型(HDFS、OZONE),数据不再孤立。
-
iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。
-
支持Parquet,ORC,Avro行存列存兼顾
2.4 增量读取处理能力
-
支持用过流式方式读取增量数据
-
spark struck streaming支持
-
flink table source支持
3. 数据湖技术催生的新架构
3.1 原有方案
原有数仓的构建方案
-
复杂的增量入库方案来保证exactly-once和数据去重
-
利用HDFS rename操作的原子性和复杂的命名规则来保证一致性、可见性
-
利用调度引擎来构建依赖关系,避免读写冲突
所存在的问题:
-
架构复杂,设计多个不同系统的协调
-
架构的复杂性导致延迟明显,从数据产生到最终展示有较长的时延
-
需要支持exactly-once,并支持数据去重,导致入库方案异常复杂,增加运维难度。
3.2 新方案
如何利用iceberg改造原有方案:
-
原子语义结合flink 两阶段提交简化整体架构
-
iceberg格式是hive、spark兼容的可读写的表格式,可以直接使用,hive、spark进行处理,无需再次将数据导入数仓中
-
iceberg支持读写分离,写入并且commit后的数据下游立即可见,因为支持ACID,所以实时读取到新增的数据,降低整体时延
基于iceberg的数据湖的增量处理分析整体方案
- 数据入湖
- 利用flink+iceberg构建准实时数据接入层
- 湖上分析
-
利用flink,structured streaming进行增量计算
-
利用spark 3.0 SQL进行sql分析
使用数据湖技术催生的新架构有三个优点:
-
简化整体架构
-
降低端到端的延迟
-
赋予事务型能力
4. 新架构应用场景
业务场景:mysql的数据导入到hive中,这里就会出现一个问题,mysql的数据是实时变化的数据,那业务系统的数据怎么尽快反应到离线数仓呢?
通常的做法就是将一段时间内的新增数据或者全量数据写到数仓中,覆盖掉原先的数据。那实时数仓也会存在这个问题,如何反应实时的数据变化是一个比较困难的事情。现在市面上常用的基于binlog的数据采集工具像canal,maxwell,flink 从1.11起支持CDC的能力,spark structured streaming支持upsert和merge的能力,如果能将上游的增量数据实时的写入数仓,这不仅能降低端到端的时延,也能显著降低业务开销。
所以就可以构建基于iceberg的数据湖的增量处理分析系统,实现流批一体。
